
模型的快速及持续发展,离不开对模型所有权及数据隐私的保护。
最近,在全球 AI 顶会 AAAI 2025 期间,蚂蚁数科、浙江大学、利物浦大学和华东师范大学联合团队提出了一种创新的跨域微调框架 Scale OT,可以实现在模型性能无损的前提下,将模型隐私保护效果提升 50%。相比于知识蒸馏技术,还降低了 90%的算力消耗,为百亿级参数模型的跨域微调提供了一种高效和轻量化的解决方案。
为同时保护模型产权与数据隐私,目前业内采用的主流方案是"跨域微调"。主流的跨域微调方法存在显著局限性:其一,其“均匀抽积木”式的处理方式容易造成模型关键层的缺失,从而导致模型性能显著下降;其二,若采用蒸馏技术来弥补性能损失,计算成本几乎与重新训练一个中型模型相当。此外,现有方法在隐私保护方面缺乏灵活性,难以根据不同场景需求动态调整隐私保护强度。
据蚂蚁数科技术团队介绍,ScaleOT 提出了三大创新思路,有效地实现了在模型性能与隐私安全之间的平衡。首先是对大模型智能层的重要性进行评估,用强化学习给大模型做扫描,自动识别哪些层对当前任务最关键,动态保留模型“核心层”,有效降低模型性能损耗。其次,对保留的模型原始层做“打码”,让攻击者无法通过中间层复原原始模型,可以在性能几乎无损的情况下,显著提升隐私保护强度。最后,该框架还可以根据不同场景需求进行灵活组装,实现隐私强度可调节。
蚂蚁数科技术团队这一创新的大模型隐私微调算法,为大模型隐私保护提供了新颖的思路与解决方案。目前,该算法已经融入蚂蚁数科旗下的摩斯大模型隐私保护产品中,并已成为国内首批通过信通院大模型可信执行环境产品专项测试的产品之一。
以下是对这篇论文的完整技术解读:

论文地址:https://arxiv.org/pdf/2412.09812
如图 2(b) 所示,跨域微调不是使用完整的模型进行训练,而是允许数据所有者使用模型所有者提供的有损压缩仿真器进行微调,但这种范式有个缺点:会让数据所有者得到的仿真器的性能较差。然后,训练得到的适配器会被返回给模型所有者,并被插入到完整模型中,以创建一个高性能的微调模型。特别需要指出,数据所有者和模型所有者端之间的模型性能差异是模型隐私的关键因素,这会促使下游用户使用微调的完整模型。
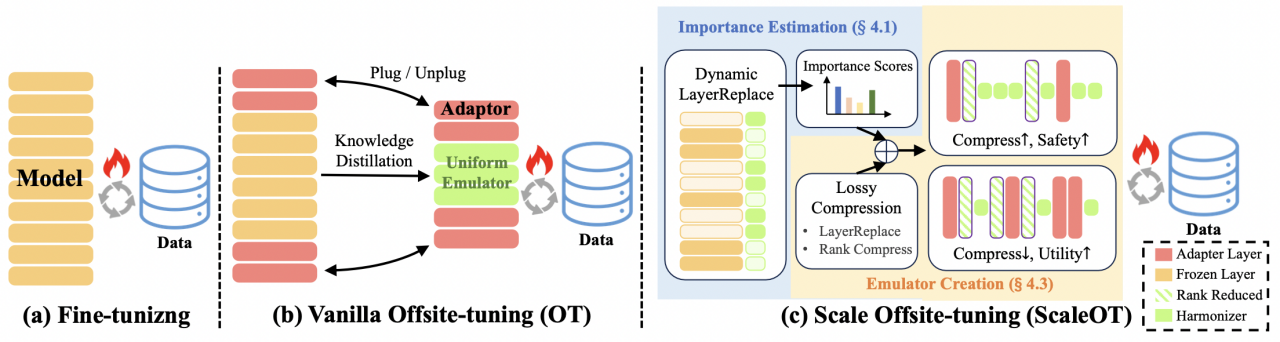
(图注)图 2:(a) 微调(Fine-tuning)需要访问完整的模型参数,并且要求数据与模型位于同一位置。(b) Vanilla OT(Xiao, Lin, and Han 2023)允许下游用户在经过有损压缩的模拟器上微调适配器(adapter),然后将适配器返回。然而,知识蒸馏(Knowledge Distillation)(Sanh et al. 2019; Hinton, Vinyals, and Dean 2015)的成本非常高,限制了其应用范围。(c)提出的 ScaleOT 引入了一种基于层级重要性感知的压缩方法——动态层替换(Dynamic LayerReplace),为下游任务调优提供了隐私-效用-可扩展的模拟器。
因此,跨域微调的主要难题在于高效压缩 LLM,通过在维持性能差异的同时提升适应版完整模型,从而实现对模型隐私的保护。
遵循跨域微调策略,原生 OT 方法采用的策略是 Uniform LayerDrop(均匀层丢弃),从完整模型中均匀地删除一部分层,如图 1(a)所示。
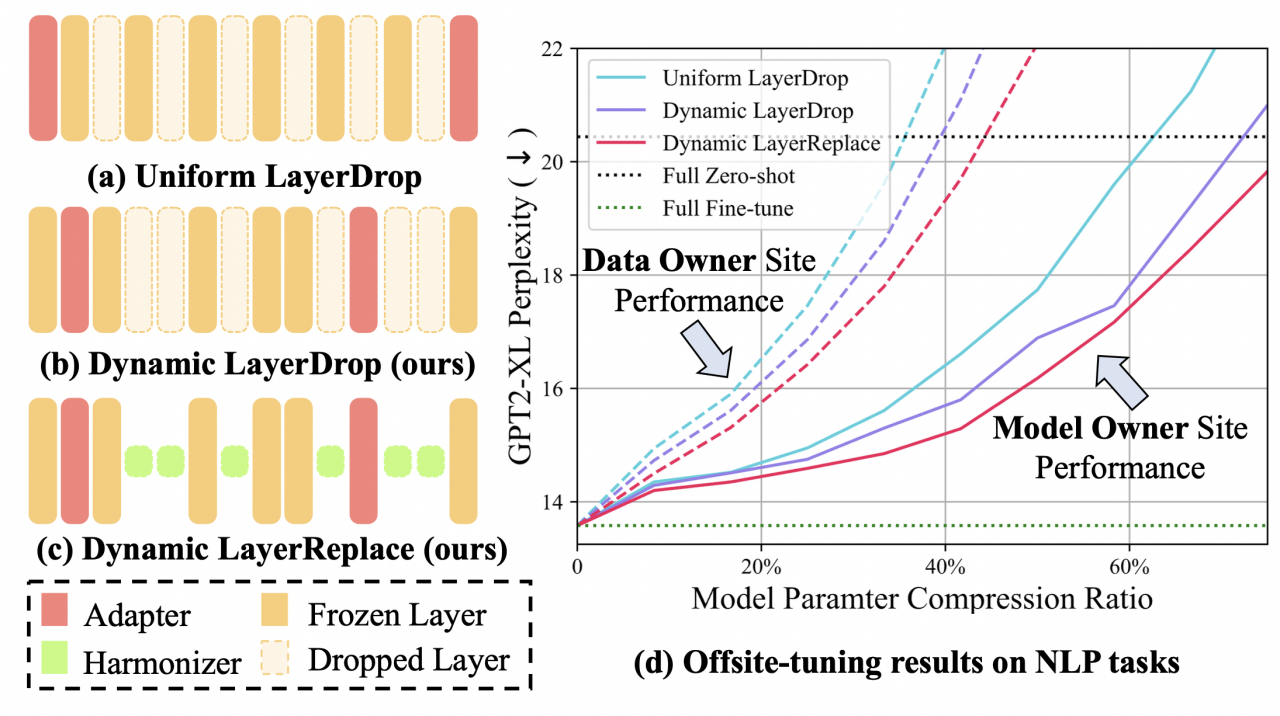
(图注)图 1:分层压缩策略比较。(a)Uniform LayerDrop;(b)带估计的重要性分数的 Dynamic LayerDrop;(c)带协调器的 Dynamic LayerReplace;(d)使用不同压缩比的结果。新方法在所有者端实现了更好的性能,同时保持了性能差异。
然而,尽管大型模型中的许多参数是冗余的,但每层的重要性差异很大,这种均匀删除可能会导致适应后的完整模型的性能下降。此外,直接的层删除会导致被删除层的输入和输出隐藏空间之间错位,这也会导致所有者端的性能下降。虽然知识蒸馏可以缓解这个问题,但训练一个所需的仿真器的成本至少是 LLM 大小的一半,这意味着巨大的训练成本为提供具有不同压缩比的仿真器带来了重大缺陷。
ScaleOT 实现:框架设计和创建过程
如图 2(c) 所示,该框架由两个阶段组成:重要性估计和仿真器生成。
对于第一阶段,团队提出了一种基于重要性感知型层替换的算法 Dynamic LayerReplace,该算法需要使用一种强化学习方法来确定 LLM 中每一层的重要性。同时,对于不太重要的层,动态选择并训练一组可训练的协调器作为替代,这些协调器是轻量级网络,可用于更好地实现剩余层的对齐。
在第二阶段,根据学习到的重要性得分,可将原始模型层及其对应的协调器以各种方式组合到一起,从而得到仿真器(emulator),同时还能在模型所有者端维持令人满意的性能,如图 1(d) 所示。
根据实践经验发现,如果使用秩分解来进一步地压缩剩余的模型层,还可以更好地实现隐私保护,同时模型的性能下降也不会太多。基于这一观察,该团队提出了选择性秩压缩(SRC)方法。
团队进行了大量实验,涉及多个模型和数据集,最终证明新提出的方法确实优于之前的方法,同时还能调整压缩后仿真器模型的大小以及 SRC 中的秩约简率。因此,这些新方法的有效性和可行性都得到了验证。
总结起来,这项研究做出了三大贡献:
提出了一种灵活的方法,可为跨域微调得到多种大小的压缩版模型:提出了一种重要性感知型有损压缩算法 Dynamic LayerReplace,该算法面向使用 LLM 的跨域微调,可通过强化学习和协调器来扩展仿真器。这些组件可以实现灵活的多种规模的压缩模型生成。
仅需一点点微调性能下降,就能通过进一步的压缩获得更好的隐私:新提出的选择性秩压缩策略仅需少量性能损失就能进一步提升模型隐私。
全面的实验表明,新提出的 ScaleOT 优于当前最佳方法。
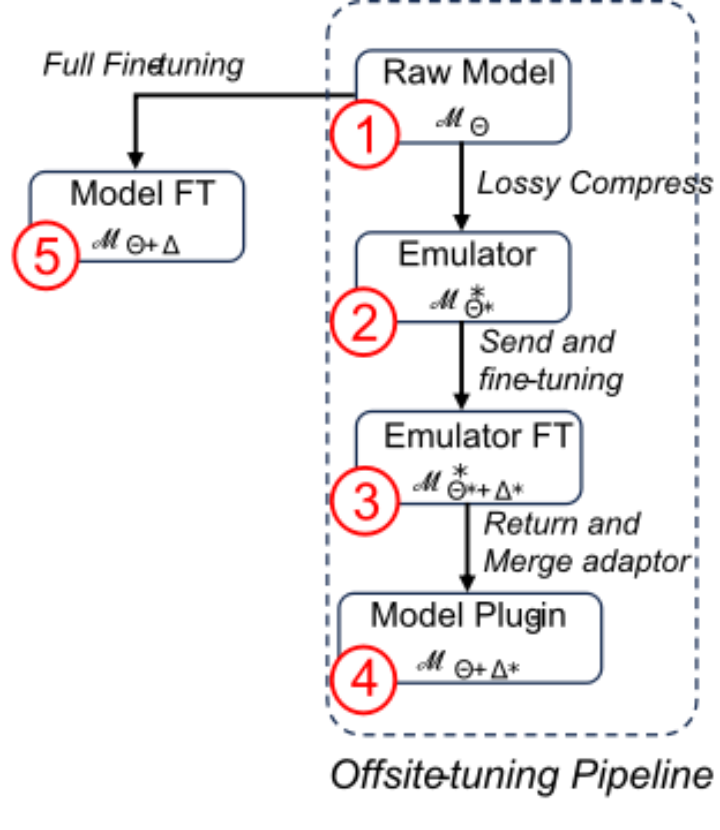
(图注)图:offsitetuning 训练过程中产生的不同模型。
在研究中,考虑到隐私问题阻止了数据和 LLM 的所有者之间共享和共存数据及模型。目标是在不访问模型所有者的模型权重的情况下,使用数据所有者的数据来调整模型。从预训练的模型①开始,以及下游数据集 D,该团队在下游数据上微调这个模型,以实现
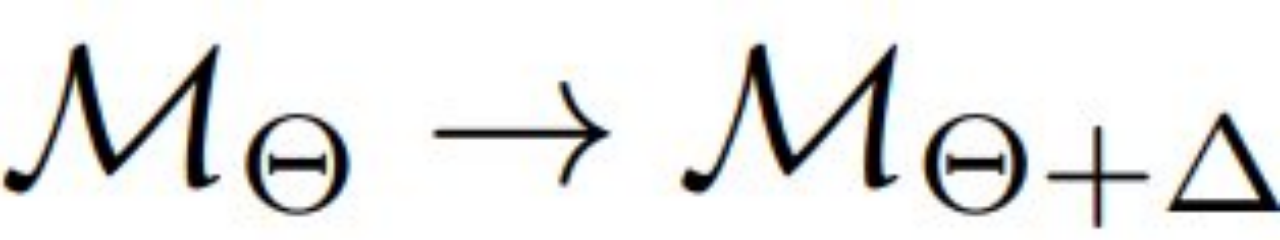
得到模型⑤,其中
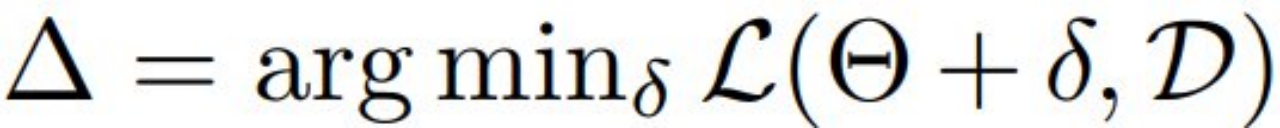
该团队的目标是通过找到一个比模型①更小、更弱的替代模型模型②(称为仿真器),来促进隐私迁移学习。这种方法可确保与下游用户共享模型②不会威胁到 LLM 的所有权。然后,数据所有者使用他们的数据集对替代模型进行微调,得到模型③。该团队希望,通过将训练好的权重重新整合到原始模型中得到模型④,几乎可以复制模型⑤,从而消除了直接模型①的需求。
一个有效的跨域微调应该满足以下条件:1)模型① < 模型④,以使微调过程成为必要。2)模型③ <模型④,以阻止下游用户使用微调后的仿真器。3)模型④ ≈模型⑤,以鼓励下游用户使用模型④。
基于 Transformer 架构设计跨域微调,更强的实用性
这篇论文关注的重点是基于 Transformer 架构来设计跨域微调。
这里需要将每个 Transformer 层视为一个基本单元,而 LLM 可以表示成 M = {m_1, m_2, . . . , m_n},其中 n 是总层数。该团队的新方法需要将 M 分成两个组件:一个紧凑型的可训练适应器 A 和模型的其余部分 E。层索引的集合可以定义成满足此条件:
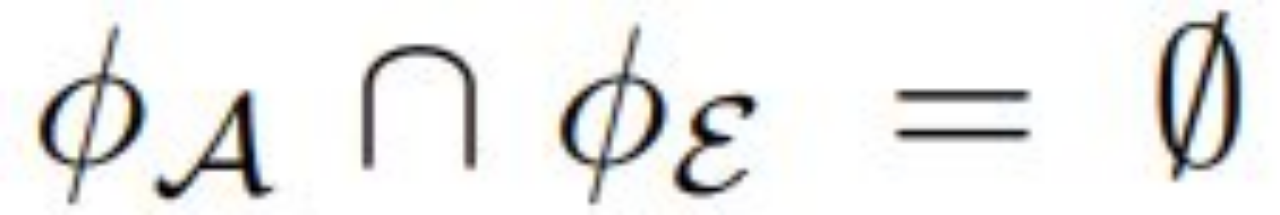
为了保护模型的隐私,需要对保持不变的组件 E 执行一次有损压缩,这会得到一个仿真器 E*,从而可通过更新 A 来促进模型微调。
待完成在数据所有者端的训练后,更新后的适应器 A′ 会被返回到模型所有者端并替换 M 中的原来的 A。于是可将最终更新后的 LLM 表示为 M′ = [A′, E]。值得注意的是,有损压缩必定会限制下游用户的 [A′, E∗] 模型性能,但却实现了对模型所有权的保护。
这篇论文解决了该问题的两个关键:获得 A 和 E 的适当划分以及实现从 E 到 E∗ 的更好压缩,从而实现有效的微调并保持隐私。
对于前者,该团队在模型层上引入了重要性分数(importance score),可用于引导 A 和 E 的选择。具体而言,在用轻量级网络动态替换原始层的过程中,可通过强化学习来估计重要性分数。
这些轻量级网络(称为协调器/harmonizer)可以进一步用作 E 中各层的替代,从而提高完整版已适应模型的性能。此外,对于 E 中被协调器替换的其余层,该团队还提出了选择性秩压缩(selective rank compression)方法,该方法在保持完整版已适应模型性能的同时还能保证更好的隐私。
重要性感知型动态层替换
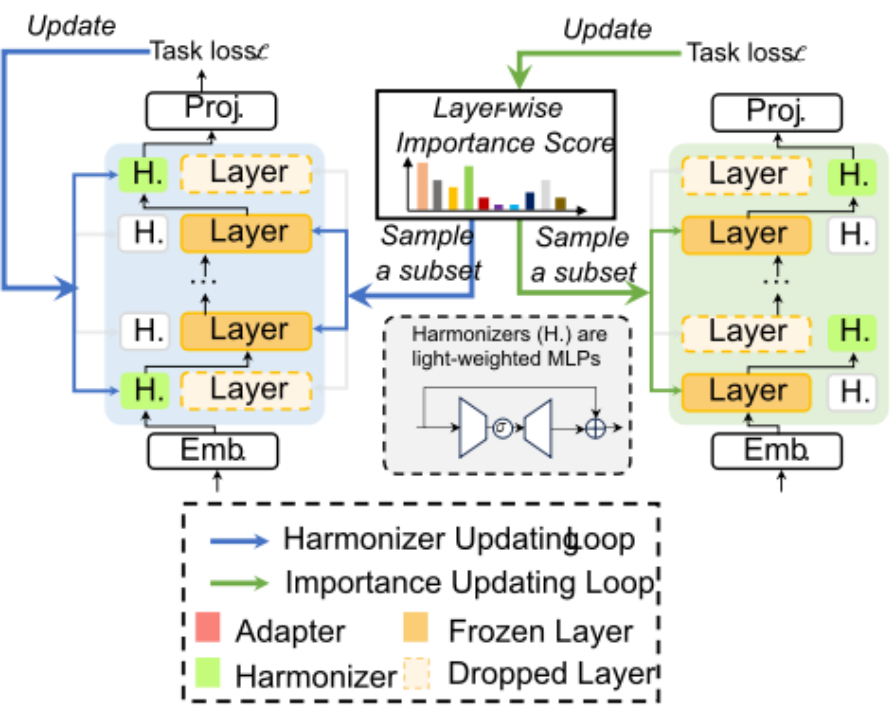
(图注)图动态层替换算法展示。
该团队提出了一种全新的基于层替换的压缩算法:Dynamic LayerReplace(动态层替换)。其目标是估计 LLM 中每层的重要性,并用轻量级网络(称为协调器)替换不太重要的层,以保持层之间的语义一致性。为此,他们采用了一种双过程方法,包含了协调器更新循环和重要性更新循环。
在协调器更新循环中,根据重要性评分,选择部分完整层替换为和谐器,然后使用深度学习(DL)来通过梯度下降训练协调器。在重要性更新循环中,每层的重要性评分通过借鉴强化学习中的 K 臂赌博机问题进行更新。
在训练结束时,我们可以获得一组用于层替换的协调器,以及估计的逐层重要性评分。它们将用于随后的可扩展仿真器生成阶段。
选择性秩压缩
该团队通过大量研究发现,大语言模型的参数数量远超过实际需要,即使去掉一部分参数也不会显著影响模型的整体性能。
基于这一发现,该团队提出了一种通过低秩近似压缩仿真器权重的方法来增强模型的隐私保护功能。当权重的高阶分量被降低时,仿真器的表达能力会相应减弱,从而产生更大的性能差距。同时,剩余的低阶权重分量仍然可以为调优过程中的适配器更新提供近似梯度方向。
Transformer 模型的每一层主要由两个部分组成:多头自注意力层(MHSA)和前馈神经网络层(FFN)。MHSA 负责处理词元之间的交互,而 FFN 则进一步处理单个词元内的信息转换。为了提升表达能力,FFN 的隐藏维度通常设置得很高,是输入输出维度的 2.5 到 4 倍。
考虑到 FFN 本身就具有高秩的特性,该团队提出了一种策略——只对 MHSA 层的权重进行秩压缩,以增强模型的隐私保护。
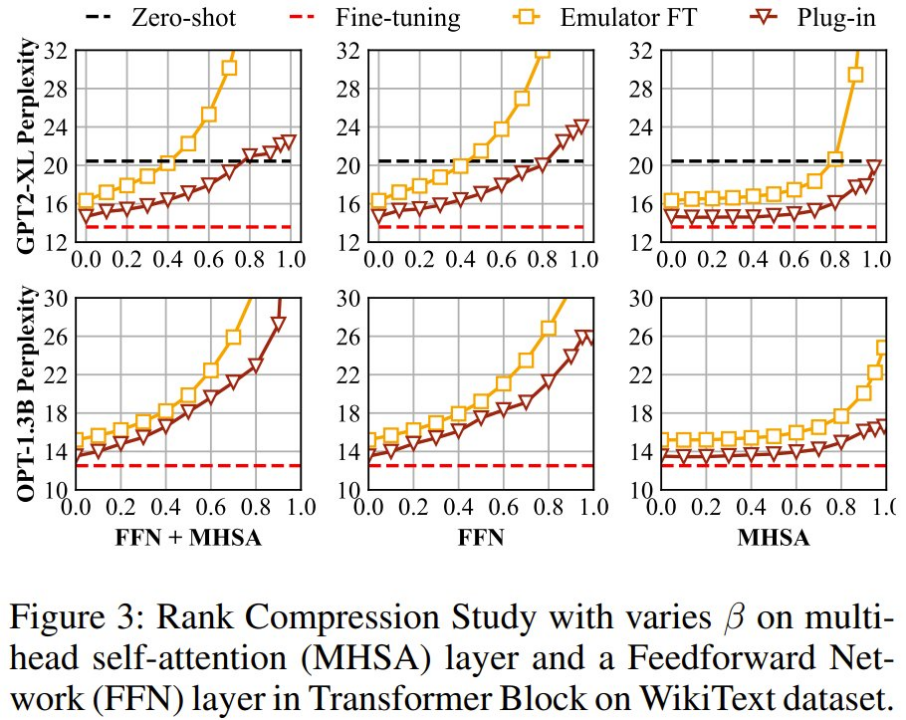
如图 3 所示,实验表明,如果对所有层(MHSA+FFN)或仅对 FFN 进行秩压缩,都会导致模型和数据性能的指数级下降。相比之下,仅对 MHSA 层进行秩压缩时。虽然会使仿真器性能快速下降,但对插件性能的影响较小,尤其是在压缩比大于 0.6 时。因此,研究团队选择了对仿真器中的 MHSA 层进行秩压缩的策略。
创建保护隐私且实用的仿真器
既要满足保护隐私,还具备扩展性的仿真器的设计基于三个核心参数:调整层数量(Na)、协调器替换比例(α)和结构秩压缩比例(β)。这些参数共同决定了如何使用大语言模型(M)、重要性分数(S)和协调器(H)来创建仿真器(E),从而在保护隐私和保持模型性能之间取得平衡。
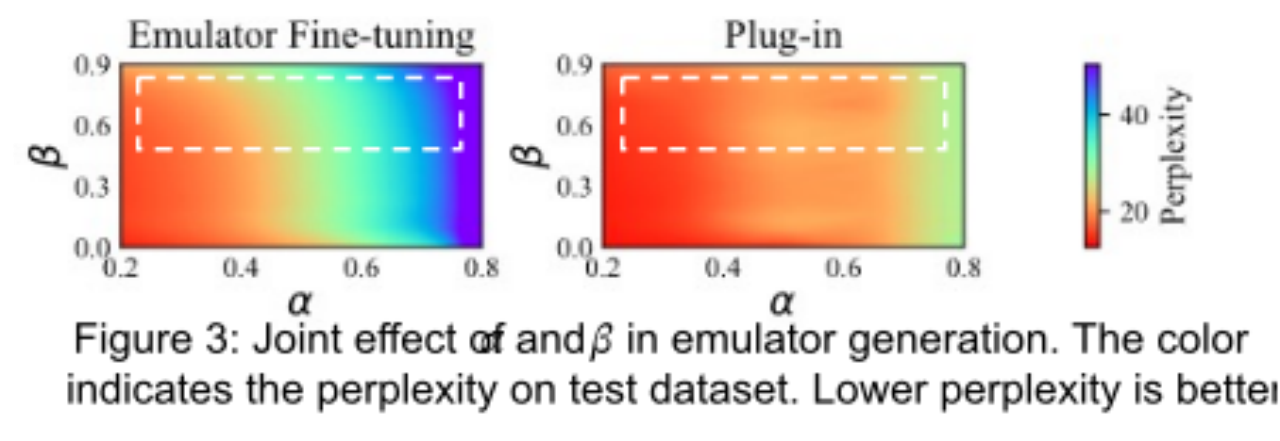
如图 3 所示,我们在虚线框内确定了一个适合生成有效模拟器用于异地调优的广泛区域。通过调整这两个参数,可以创建具有低压缩率的仿真器器,以实现卓越的 plug-in 性能(甚至与完全微调相比可达到无损),或者采用较高的压缩率以增强模型隐私性。
ScaleOT 效果评估:更好的性能,更优的模型隐私
该团队首先在中等大小的模型(包括 GPT2-XL 和 OPT-1.3B,大约 10 亿参数量)上评估了他们提出的 ScaleOT,如表 1 所示。所有方法都满足了跨域微调的条件,即插件的性能超过了完整模型的零样本和仿真器微调的性能。此外,没有 SRC 的 ScaleOT 几乎实现了与完整微调相当的无损性能。这突出了动态层替换与基线 OT 中使用的 Uniform LayerDrop 相比的有效性。
值得注意的是,由于选择了重要的层进行更新,插件的性能可以超过直接在 LLM 上进行微调的性能,这得益于稀疏训练带来的更好收敛性。最后,SRC 的加入显著降低了仿真器零样本和微调的性能,平均降低了 9.2%和 2.2%,而插件的性能几乎没有下降。总体而言,ScaleOT 不仅实现了更好的性能,还确保了良好的模型隐私。
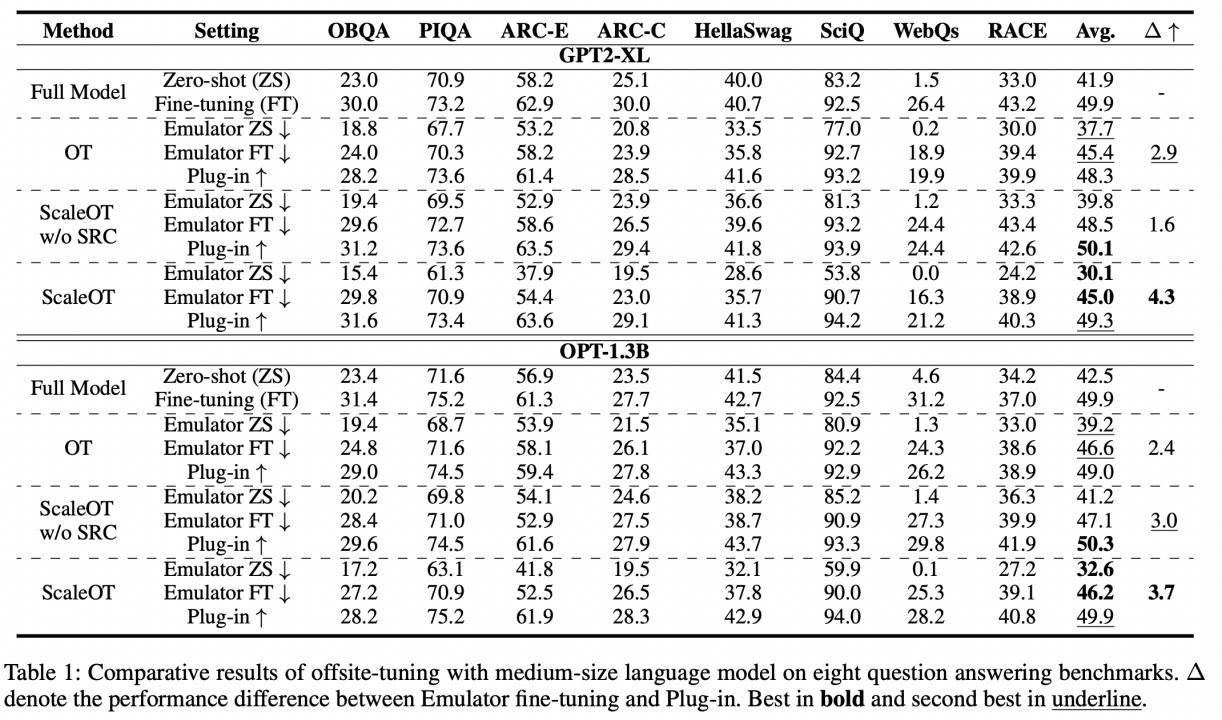
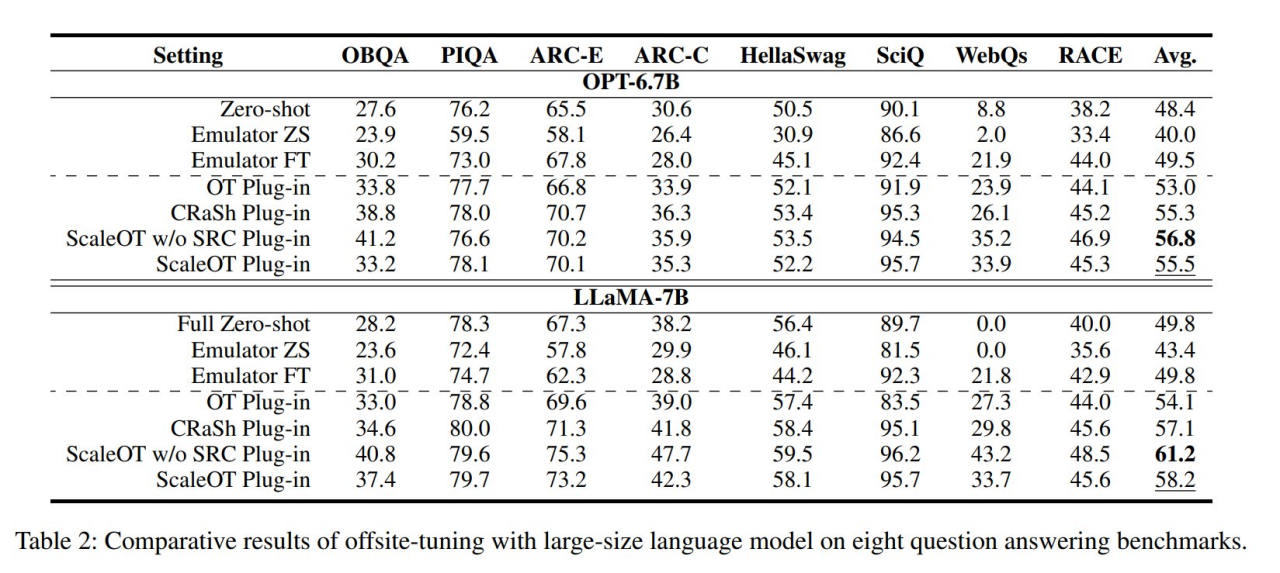
随后,该团队验证了他们提出的 ScaleOT 在更大的 LLM 上的有效性,包括拥有大约 70 亿参数的 OPT-6.7B 和 LLaMA-7B。如表 2 所示,由于在有限的硬件上无法执行知识蒸馏,OT 未能达到令人满意的性能。CRaSh 通过 LayerSharing 提高了性能,但由于压缩后无法完全恢复性能,导致结果并不理想。相比之下,ScaleOT 使得大型模型的压缩变得可行,仅需要在压缩阶段训练大约 1-2%的参数。值得注意的是,该团队提出的方法在 WebQs 任务上实现了强大的插件性能,其中零样本准确率为零,突显了其在新的下游应用中的潜力。此外,ScaleOT 取得了值得称赞的结果,表明其有效性并不局限于特定的模型大小。这使得 ScaleOT 成为增强不同规模模型跨域微调结果的有价值策略。
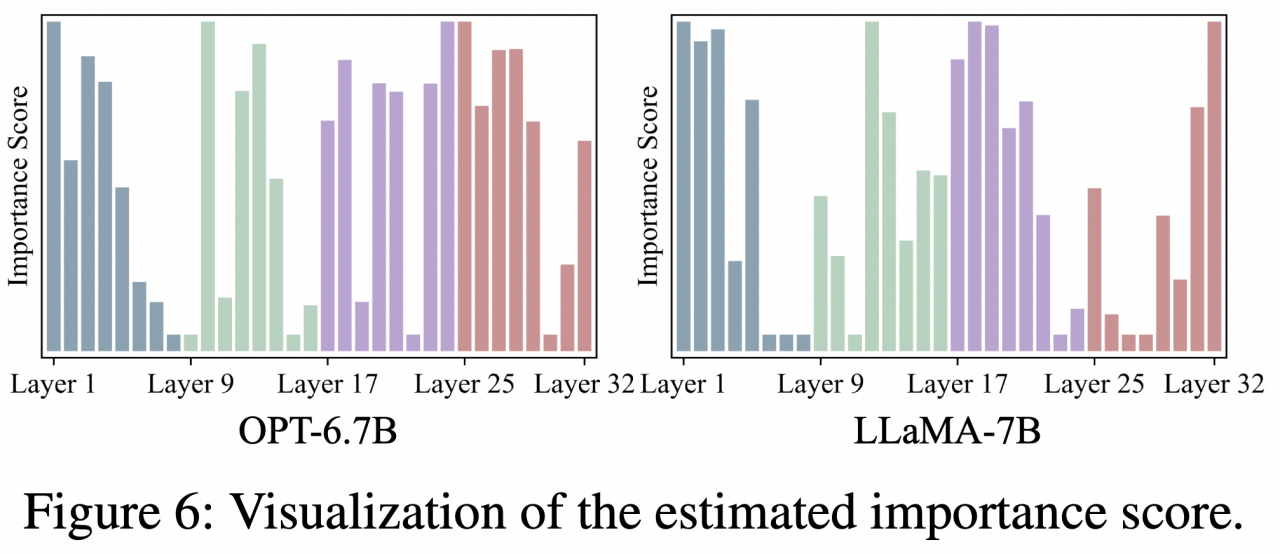
重要性得分
该团队对 OPT-6.7B 和 LLaMA-7B 的估计重要性得分进行了可视化,如图 6 所示。可以明显看出,在不同网络中,重要性分布存在相当大的差异。然而,一个一致的模式出现了:第一层具有显著的重要性。这一发现与 OT 的观察结果相呼应,尽管缺乏明确的解释。
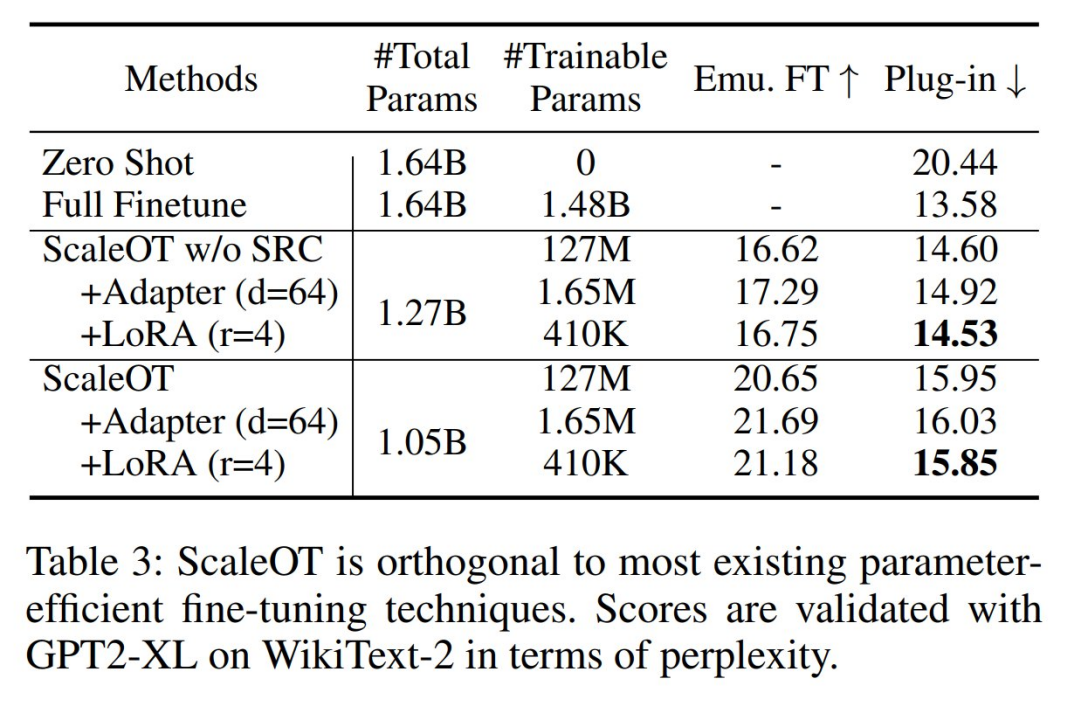
与参数高效微调的正交性
根据设计,ScaleOT 能与参数高效微调(PEFT)方法无缝集成,从而形成一种综合方法,显著减少可训练参数并提升效率。这可以通过在调整层中使用 PEFT 方法来实现,包括 Adapter-tuning 和 LoRA 等策略。如表 3 所示,该团队观察到 Adapter-tuning 和 LoRA 在保持插件性能的同时大幅减少了可训练参数。
蚂蚁数科技术团队这一全新的大模型隐私微调算法,有效攻克在仿真器生成时计算复杂度高、模型隐私安全性不足等难题,成功为大模型隐私保护提供了新颖的思路与解决方案。
该创新源自蚂蚁数科在 AI 隐私安全领域的持续投入与实践,这一算法也已融入摩斯大模型隐私保护产品,该产品是信通院首批通过大模型可信执行环境产品专项测试的厂商。




