
近期,Apache Kylin 5 周年在线庆典顺利结束,来自汽车之家的实时计算平台负责人 邸星星 老师为大家介绍了 Apache Kylin 在汽车之家的升级历程,以及在实时多维分析方面的实践,最后也展望了对 Kylin 4.0 版本的期待。

以下是邸星星老师的现场分享实录。
Apache Kylin 在汽车之家的升级演进
近年来,面对大数据量与终端用户的不断增长,2016 年的时候我们梳理了针对多维分析引擎的选型需求:
面临千亿,乃至万亿数据量的情况下,要达到秒级或者亚秒级的查询响应。
需要满足相对较高的查询吞吐量以及较高的可用性,当时汽车之家的数据主要是基于离线数据来做多维分析。
Kylin 在汽车之家的升级历程
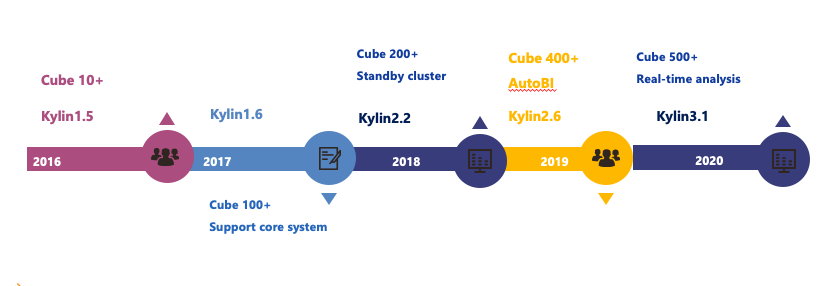
Kylin 过往 5 年里主要的发展里程碑
2016 年初,汽车之家正式启用 Kylin 1.5 版本
此时共有 10+ Cube,主要支持部门内的少量数据分析,同时用作技术验证。
2017 年,内部正式上线 Kylin 1.6 版本,并逐步承接线上业务
累计有 100+ Cube,2017 年底使用 Kylin 支持了汽车之家的战略级商业化数据产品。
2018 年,升级到 Kylin 2.2 版本 ,支持 Spark 引擎做构建,同时对 HBase 集群做了 T+1 备份
在极端情况下,如果 HBase 集群发生故障,可以把用户的查询请求路由到备用集群里来保障业务正常运行。
2019 年,升级到 Kylin 2.6 版本,并在内部多个 BU 推广使用
Cube 数量达到了 400+ ,另外公司内部也研发了 BI 产品,也可以支持 Kylin 作为它的查询引擎。
2020 年,将 Kylin 升级到 3.1 版本,主要来做实时多维分析的应用

可以看到目前集群规模大概有 500+Cube,20000+个 Segment,有 15 万左右的 HBase Region,存储在 300T 左右,每天的查询请求在 20 万以上,使用 Kylin 95% 的响应时间会在 2 秒以内返回结果。
Kylin 在实时多维分析方面的应用
1)Kylin Real-time OLAP 架构
Kylin 3.0 版本开始提供实时分析能力,主要是引入了两个角色,一个是 Coordinator,另一个是 Receiver。Coordinator 主要是负责协调,做一些分配,启动、停止这样的工作。Coordinator 是一个真实的一个计算节点。同时,Kylin 会抽象 Replica Set 的概念,就是把两个 Receiver 看作一组,当作一组 Replica Set,然后这两个 Receiver 做的是一样的事情,他们计算的是一样的数据,也提供同样的查询,当一个 Receiver 挂掉的时候,整体的查询是不会受影响的,相当于是做了一个 Receiver 层面的高可用。
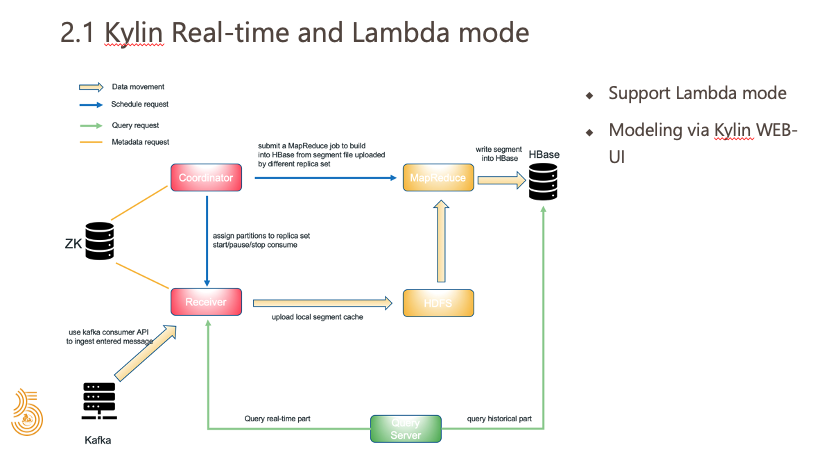
2)Kylin 如何支持批流一体?
接下来谈谈流批一体这个概念,目前流批一体的概念比较流行。 Kylin 因为支持实时 Cube 的 Lambda 模式,我们在页面上做一次建模,然后把它定义为 Lambda 模式,那它实时的数据会从 Kafka 里面实时消费出来,然后去支持实时的查询。 当离线的数据准备好之后,可以通过构建当天的离线数据去覆盖实时结果,也就是说 Kylin 能自动纠正实时计算的结果,这样就很好的解决了离线和实时的开发体系不统一的问题。 比如说用 Flink 做实时计算,然后用 Hive 做离线计算,其实是两套开发体系,而且有可能是两个不同的开发人员;使用 Kylin 的时候完全可以由一个开发人员完成,在 Kylin 的页面上来做正常的建模,就可以做到批流一体的多维分析, 这其实也降低了人力的浪费,同时也能保证数据口径是完全一致的。
3)汽车之家在实时方面遇到的挑战
再来说下汽车之家在实时方面现在面临的 3 个问题。
首先 Kylin 的 Receiver 节点和之前的 Job 以及 Query 节点都不太一样,因为它既负责实时的计算,又要负责查询,而且是查询本地磁盘上的数据,所以负担比较重。当面临越来越多实时业务的时候,可能需要维护一个比较大的 Receiver 集群,这样对我们来说的这个维护成本会是一个大问题。
另外, Receiver 本身不只是服务于某一个 Cube,一个 Receiver 进程里面可能会支持好几个 Cube 的计算,假如某一个 Cube 的数据量突然激增,或者某个 Cube 的数据有一些问题,就可能会影响到这个 Receiver 进程本身的稳定性,所以隔离方面其实也不是特别好。
最后说下弹性伸缩这块,如果单个 topic 的数据量激增的时候,要怎么去快速的做扩容,然后等它的访问量下去之后,是不是可以快速的做缩容?
之前的方式都是需要手动去做调整,维护成本就会相应增加。
4)Receiver on Kubernetes 解决方案介绍
目前 Kylin 在做的云原生,我们就自然地想到了可以和 K8s 做集成来解决这些问题。
目前我们是在内部引入了一个 Kubernetes Resource Manager 的角色,然后由它去和 K8s 集群做交互,来动态申请相应的资源。
下图是目前我们正在做的和 K8s 集成的整体架构,我们做的改造主要集中在前面几步,后面这几步,包括查询这些基本没有改动。
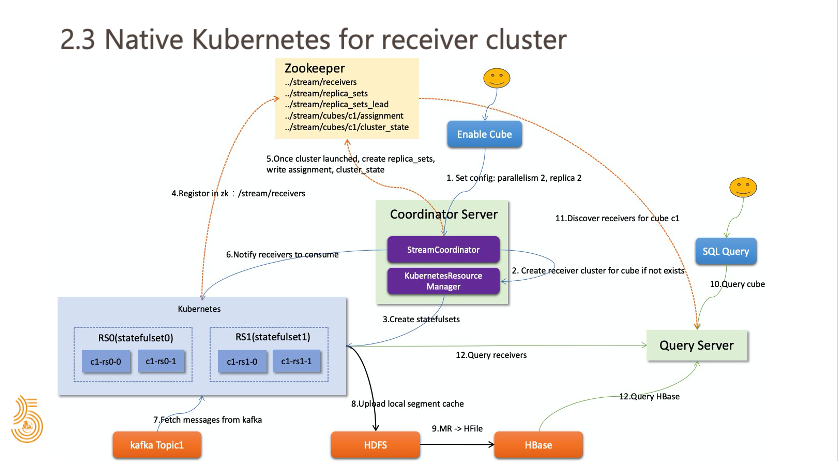
我们在 Coordinator 内部引入了一个组件,就是 Kubernetes Resource Manager,当用户完成建模后,在 Enable Cube 的时候,会根据配置判断这个 Cube 是不是需要去创建一个独立的 Receiver 集群(Streaming Cluster),如果需要独立的 Receiver 集群,Coordinator 会根据配置好的并行度、副本数、CPU、内存等基本参数,通过 Kubernetes Resource Manager 和 K8s 去做交互,动态创建 Cube 所需要的 Reciever 集群。
这中间有一个映射关系,Kylin 里面的一个 Replica Set 会对应 K8s 里面的一个 StatefulSet,每个 StatefulSet 里面会有对应副本个数的 Receiver 实例,这个例子中我们设置的并行度为 2,副本数为 2,那么就会有 2 个 StatefulSet,每个 StatefulSet 里会有 2 个 Receiver 实例。当 Kubernetes Resource Manager 把 Receiver 实例都启动成功后,Receiver 会自动注册到 ZK 中,同时会写入 Cube 名称,声明这个 Receiver 是属于哪一个 Cube 的。
当 Coordinator 发现 Cube 所需的 Receiver 都启动完毕以后,会创建 Replica Set,并进行 assign 操作,同时把 Cluster state 置为 ready 状态,最后向 Cube 对应的所有 Receiver 发送 REST 请求,通知这些 Receiver 开始消费数据,至此整个 Enable Cube 的过程就结束了。
简单回顾一下,通过和 K8s 集成已经解决了前面提到弹性伸缩的问题,我们不再需要维护一个很大的 Streaming Cluster,Streaming Cluster 可以是 Cube 级别的,每个 Cube 会对应一个独立的 Streaming Cluster,资源在不同的 Cube 间是相互隔离的,并且资源可以方便的动态伸缩。比如说用户想要增加资源,调大了并行度,那么 Coordinator 会识别到这个扩容事件,去动态的再创建一组 StatefulSet 和 Kylin Replica Set,进行重新分配,完成扩容。
目前这一套架构已经在我们的准生产环境跑通了,然后接下来会上线支持一些我们内部的业务,运行稳定之后会逐步在各条业务线推广。
对 Kylin 4.0 的展望
最后来说下对 Kylin4.0 的展望,Kylin 4.0 主要是往云原生方向发展,主要有两块大的改进:
全栈化 Spark,脱离 Hadoop 组件做查询 ,这是云原生的基础;同时使用 Spark 引擎做查询还有一个额外的好处,就是之前用 Calcite 会有查询单点的问题,用 Spark 的话就可以很好地解决这个难点。
Kylin on Parquet,基于列式存储有很高的 IO 效率,也能一定程度上提供查询的稳定性 ,对比 HBase 是一个有状态的存储,但是 Parquet 只是一个文件格式,所以查询的链路上也会更加轻量级。去 HBase 后也不再需要额外的运维成本来维护 HBase。
综上,我们非常期待 Kylin 4.0 GA 的发布。
作者介绍:
邸星星,汽车之家实时计算平台负责人,长期从事实时计算与数据分析领域的平台建设工作,致力于为公司提供大规模、高效、稳定的计算与查询服务。
本文转载自公众号 apachekylin(ID:ApacheKylin)。
原文链接:




