
本文最初发表于Baeldung网站,由 InfoQ 中文站翻译分享。
引言
在本教程中,我们将会研究LangChain的细节,这是一个利用语言模型开发应用程序的框架。首先,我们会介绍有关语言模型的基本概念,这将对本教程有一定的辅助作用。
尽管 LangChain 主要提供了 Python 和 JavaScript/TypeScript 语言的版本,但是也有在 Java 中使用 LangChain 的可选方案。我们将会讨论组成 LangChain 框架的构建基块,然后在 Java 中进行实验。
背景
在深入探讨为何需要一个框架来构建语言模型驱动的应用程序之前,我们必须首先了解什么是语言模型,除此之外,我们还会介绍在使用语言模型时遇到的一些典型的复杂问题。
大语言模型
语言模型是自然语言的一个概率模型,可以生成一系列单词的概率。大语言模型(LLM)是以规模庞大为特征的一种语言模型。它们是人工智能网络,可能会有数十亿个参数。
LLM 通常会使用自监督和半监督学习技术,在大量无标记的数据上进行预训练。然后,使用微调和提示工程等各种技术对预训练模型进行调整,使其适用于特定的任务:
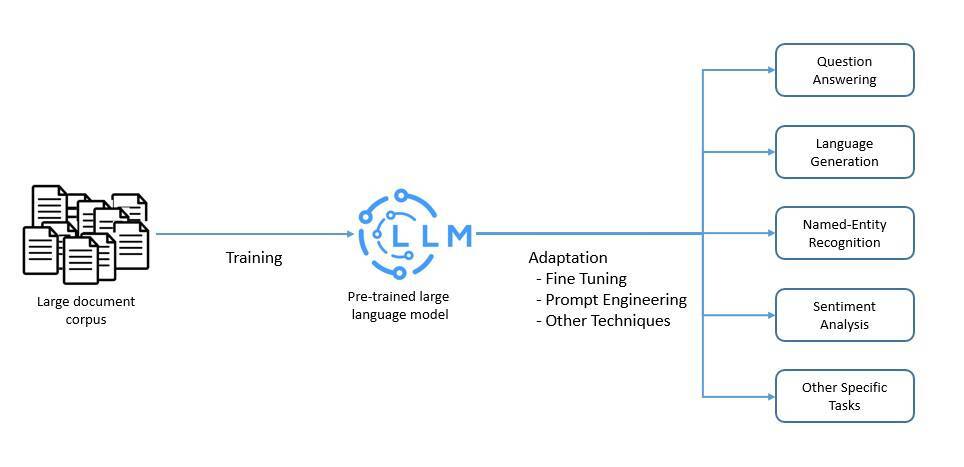
这些 LLM 能够执行多种自然语言处理任务,如语言翻译和内容摘要。它们还能完成内容创建等生成型任务。因此,它们在问题回答这样的应用中极具价值。
几乎所有主流的云服务提供商都在它们的软件产品中加入了大语言模型。例如,微软Azure提供了 Llama 2 和 OpenAI GPT-4 等 LLM。Amazon Bedrock提供了来自 AI21 Labs、Anthropic、Cohere、Meta 和 Stability AI 的模型。
提示工程
LLM 是在大量文本数据集上训练的基础模型。因此,它们可以捕获人类语言内在的语法和语义。但是,我们必须对其进行调整,以便于让其执行我们希望它们执行的特定任务。
提示工程是调整 LLM 最快的方法之一。这是一个构建文本的过程,文本可以被 LLM 解释和理解。在这里,我们使用自然语言文本来描述希望 LLM 执行的任务:
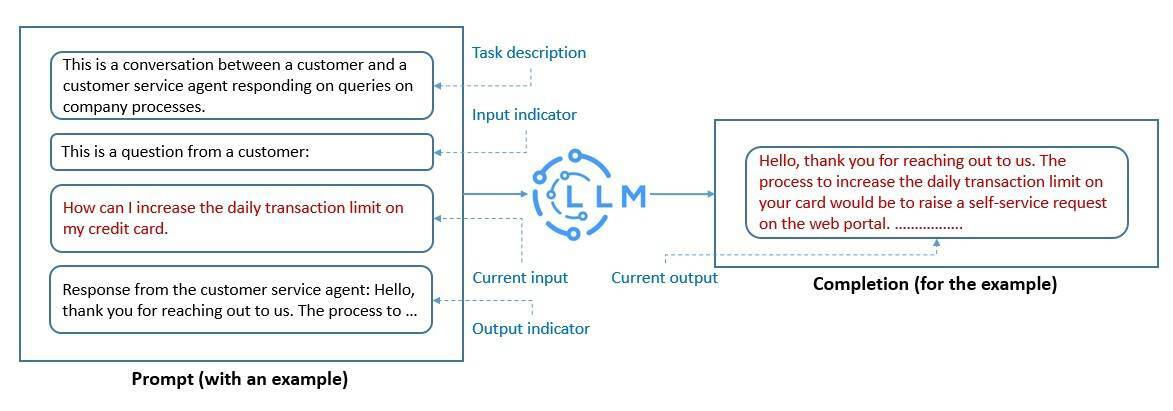
我们创建的提示有助于 LLM 执行上下文内的学习,这种学习是临时性的。我们可以使用提示工程来促进 LLM 的安全使用,并构建新的能力,比如利用领域知识和外部工具来增强 LLM。
这是一个活跃的研究领域,新技术层出不穷。但是,像思路链(chain-of-thought)提示这样的技术已经非常流行。该技术的理念是让 LLM 在给出最终答案之前,通过一系列的中间步骤来解决问题。
词嵌入
正如我们看到的,LLM 能够处理大量的自然语言文本。如果我们将自然语言中的单词表示为词嵌入(word embedding),那么 LLM 的性能就会大大提高。这是一种实值向量(real-valued vector),能够对单词的含义进行编码。
通常,词嵌入是通过Tomáš Mikolov的Word2vec或斯坦福大学的GloVe等算法生成的。GloVe 是一种无监督学习算法,根据语料库中全局的单词-单词间共现(co-occurrence)统计数据进行训练:
在提示工程中,我们将提示转换为词嵌入,使模型能够更好地理解提示并做出响应。除此之外,它还有助于增强我们提供给模型的上下文,使它们能够提供更多符合上下文的答案。
例如,我们可以从现有的数据集生成词嵌入,并将其存储到向量数据库中。此外,我们还可以使用用户提供的输入对该向量数据库执行语义搜索。然后,我们将搜索结果作为模型的附加上下文。
使用 LangChain 的 LLM 技术栈
正如我们已经看到的,创建有效的提示是在所有应用中成功利用 LLM 的关键因素。这包括让与语言模型的交互具有上下文感知的能力,并且能够依靠语言模型进行推理。
为此,我们需要执行多项任务,包括创建提示模板、调用语言模型以及从多个数据源向语言模型提供用户特定的数据。为了简化这些任务,我们需要一个像 LangChain 这样的框架,将其作为 LLM 技术栈的一部分:
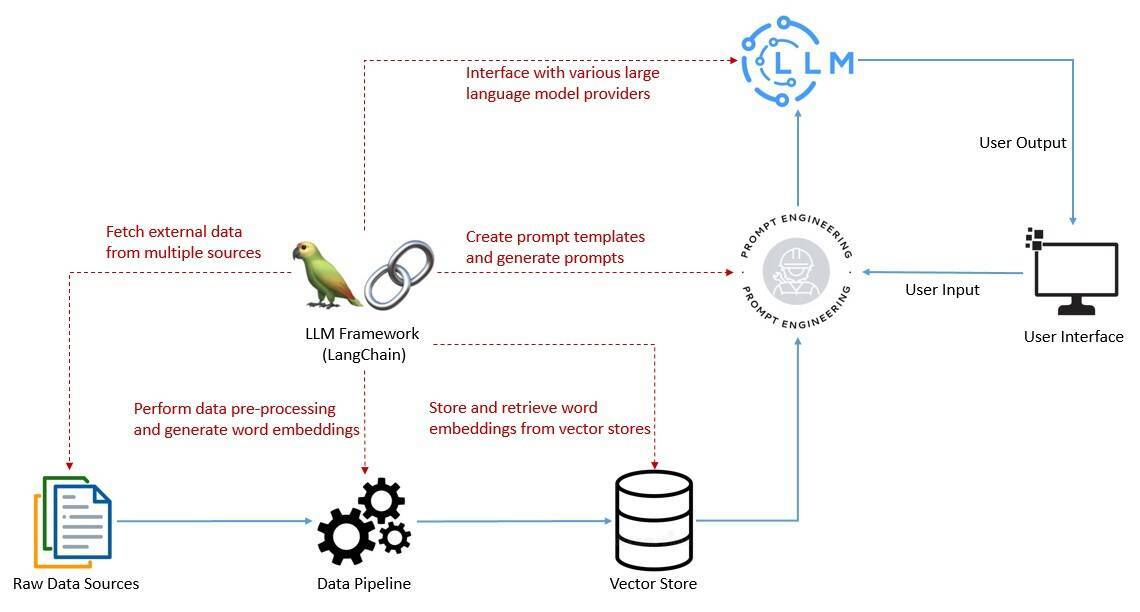
在开发需要链接多个语言模型的应用,并且需要调用过去与语言模型交互生成的信息时,该框架会非常有用。此外,还有一些更复杂的用例,涉及到将语言模型作为推理引擎。
最后,我们还可以执行日志记录、监控、流式处理以及其他必要的维护和故障排除任务。LLM 技术栈正在快速发展,以解决其中的许多问题。不过,LangChain 正在迅速成为 LLM 技术栈的重要组成部分。
面向 Java 的 LangChain
LangChain在 2022 年以开源项目的形式启动,并很快在社区的支持下赢得了广泛关注。它最初由 Harrison Chase 用 Python 语言开发,很快就成为人工智能领域发展最快的初创公司之一。
2023 年初,继 Python 版本后,LangChain 又推出了 JavaScript/TypeScript 版本。它很快就变得非常流行,并开始支持多种 JavaScript 环境,如 Node.js、Web 浏览器、CloudFlare Worker、Vercel/Next.js、Deno 和 Supabase Edge 函数。
遗憾的是,目前还没有适用于 Java/Spring 应用的 LangChain 官方 Java 版本。不过,有一个名为LangChain4j的 LangChain Java 社区版本。它适用于 Java 8 或更高版本,支持 Spring Boot 2 和 3。
LangChain 的各种依赖可以从Maven中央仓库获取。我们可能需要在应用程序中添加一个或多个依赖项,这取决于我们要使用的特性:
<dependency> <groupId>dev.langchain4j</groupId> <artifactId>langchain4j</artifactId> <version>0.23.0</version></dependency>例如,在本教程的后续章节中,我们还将需要一些依赖,以便于继续支持与OpenAI模型集成、提供嵌入式支持以及类似all-MiniLM-L6-v2的句子转换器(sentence-transformer)模型。
LangChain4j 的设计目标与 LangChain 相同,它提供了一个简单而一致的抽象层以及众多的实现。它已经支持多个语言模型供应商(如 OpenAI)和嵌入数据存储商(如 Pinecone)。
不过,由于 LangChain 和 LangChain4j 都在快速发展,Python 或 JS/TS 版本支持的特性可能在 Java 版本中还不存在。不过,基本概念、一般结构和词汇在很大程度上是相同的。
LangChain 的构建基块
LangChain 以模块组件的形式为我们提供了多个有价值的提议。模块化组件提供了有用的抽象,以及一系列用于处理语言模型的实现。我们以 Java 为例,讨论其中的一些模块。
模型 I/O
在使用任何语言模型时,我们都需要与之进行交互的能力。LangChain 提供了必要的构建基块,比如模板化提示以及动态选择和管理模型输入的能力。同时,我们还可以使用输出解析器从模型输出中提取信息:
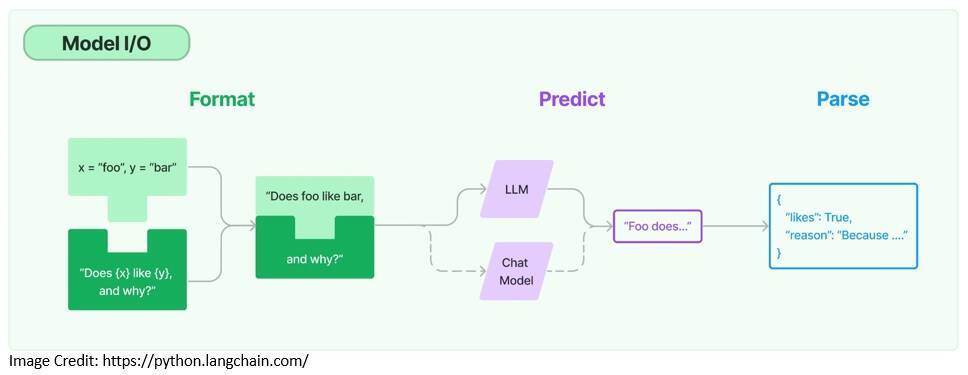
提示模板是为语言模型生成提示的预定义配方,可能包括说明、few-shot样例和特定的上下文:
PromptTemplate promptTemplate = PromptTemplate .from("Tell me a {{adjective}} joke about {{content}}..");Map<String, Object> variables = new HashMap<>();variables.put("adjective", "funny");variables.put("content", "computers");Prompt prompt = promptTemplate.apply(variables);
在这里,我们创建了一个可以接受多个变量的提示模板。这些变量是我们从用户输入中接收到的,并输入到提示模板中。
LangChain 支持与两种模型集成,即语言模型和聊天模型。聊天模型也由语言模型支持,但提供聊天的能力:
ChatLanguageModel model = OpenAiChatModel.builder() .apiKey(<OPENAI_API_KEY>) .modelName(GPT_3_5_TURBO) .temperature(0.3) .build();String response = model.generate(prompt.text());在这里,使用特定的 OpenAI 模型和相关的 API 秘钥创建了一个聊天模型。我们可以通过免费注册从 OpenAI 获取 API 秘钥。参数 temperature 用来控制模型输出的随机性。
最后,语言模型的输出可能不够结构化,不足以进行展示。LangChain 提供的输出解析器可以帮助我们对语言模型的响应进行结构化处理,例如,以 Java 的 POJO 的形式从输出中提取信息。
记忆内存
通常,利用 LLM 的应用程序都会有一个对话界面。所有对话的一个重要方面就是要能够参考对话早期引入的信息。存储过去交互信息的能力被称为记忆内存(memory):
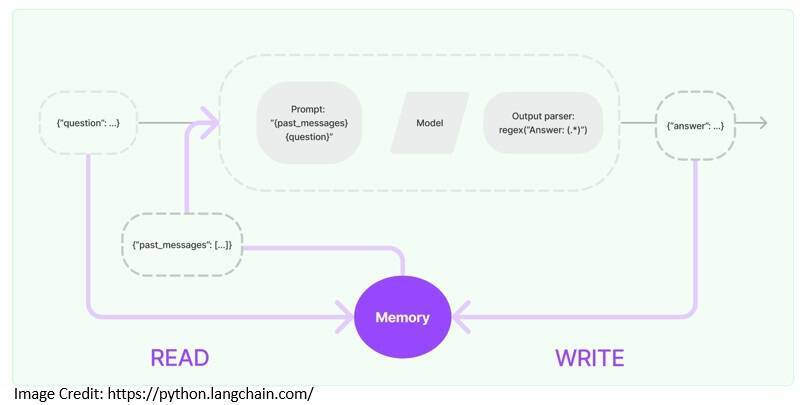
LangChain 提供了为应用程序添加记忆内存的关键功能。我们需要从记忆内存中读取信息的能力,以增强用户的输入。然后,我们需要将当前运行的输入和输出写入记忆内存的能力:
ChatMemory chatMemory = TokenWindowChatMemory .withMaxTokens(300, new OpenAiTokenizer(GPT_3_5_TURBO));chatMemory.add(userMessage("Hello, my name is Kumar"));AiMessage answer = model.generate(chatMemory.messages()).content();System.out.println(answer.text()); // Hello Kumar! How can I assist you today?chatMemory.add(answer);chatMemory.add(userMessage("What is my name?"));AiMessage answerWithName = model.generate(chatMemory.messages()).content();System.out.println(answer.text()); // Your name is Kumar.chatMemory.add(answerWithName);在这里,我们使用TokenWindowChatMemory实现了一个固定窗口的聊天内存,它允许我们读写与语言模型交换的聊天信息。
LangChain 还提供了更复杂的数据结构和算法,以便于从记忆内存中返回选定的信息,而不是所有的信息。例如,它支持返回过去几条信息的摘要,或者只返回与当前运行相关的信息。
检索
大语言模型通常是在大量的文本语料库中训练出来的。因此,它们在一般任务中相当高效,但是在特定领域任务中可能就没有那么有用了。因此,我们需要检索相关的外部数据,并在生成步骤将其传递给语言模型。
这个过程被称为“检索增强生成(Retrieval Augmented Generation,RAG)”。它有助于将模型建立在相关的准确信息之上,并让我们深入了解模型的生成过程。LangChain 为创建 RAG 应用程序提供了必要的构建基块:
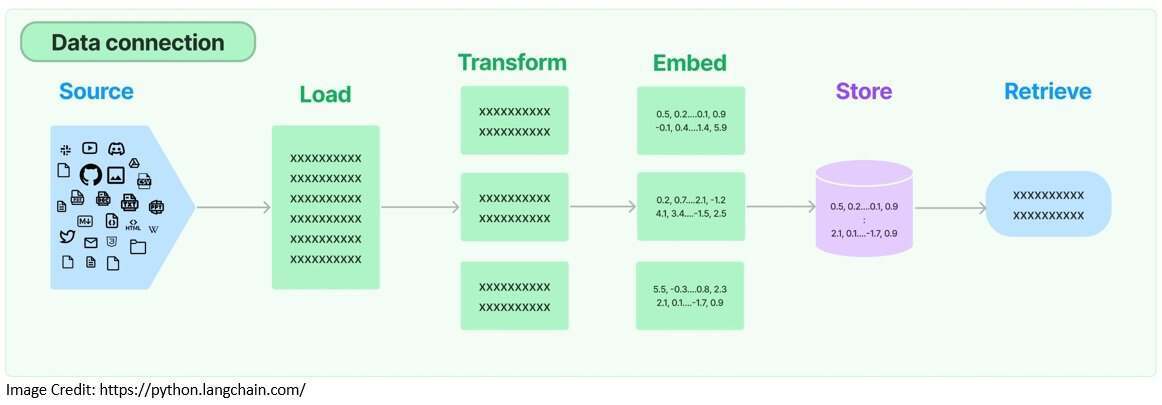
首先,LangChain 提供了文档加载器,用于从存储位置检索文档。其次,还提供了用于准备文档的转换器(transformer),以便于进一步的处理。例如,我们可以让它将大文档拆分为小块:
Document document = FileSystemDocumentLoader.loadDocument("simpson's_adventures.txt");DocumentSplitter splitter = DocumentSplitters.recursive(100, 0, new OpenAiTokenizer(GPT_3_5_TURBO));List<TextSegment> segments = splitter.split(document);在这里,我们使用FileSystemDocumentLoader从文件系统加载文档。然后,使用OpenAiTokenizer将文档拆分为小块。
为了提高检索效率,通常会将文档转换为嵌入内容,并将其存储在向量数据库中。LangChain 支持多种嵌入式提供商和方法,并且能够与几乎所有的向量存储集成:
EmbeddingModel embeddingModel = new AllMiniLmL6V2EmbeddingModel();List<Embedding> embeddings = embeddingModel.embedAll(segments).content();EmbeddingStore<TextSegment> embeddingStore = new InMemoryEmbeddingStore<>();embeddingStore.addAll(embeddings, segments);在这里,我们使AllMiniLmL6V2EmbeddingModel创建文档片段的嵌入内容。然后,我们将嵌入内容存储在基于内存的向量存储中。
现在,我们已经将外部数据以嵌入的形式保存在向量存储中了,并且做好准备进行检索了。LangChain 支持多种检索算法,如简单的语义搜索以及复杂的复合检索:
String question = "Who is Simpson?";//The assumption here is that the answer to this question is contained in the document we processed earlier.Embedding questionEmbedding = embeddingModel.embed(question).content();int maxResults = 3;double minScore = 0.7;List<EmbeddingMatch<TextSegment>> relevantEmbeddings = embeddingStore .findRelevant(questionEmbedding, maxResults, minScore);我们创建了用户问题的嵌入,然后使用问题嵌入从向量存储中检索相关的匹配项。现在,我们可以将检索到的匹配项作为上下文进行发送,将其添加到我们想要发送给模型的提示中。
LangChain 的复杂应用
到目前为止,我们已经了解了如何使用单个组件创建基于语言模型的应用程序。LangChain 还提供了用于创建更复杂应用的组件。例如,我们可以使用链和代理来构建功能更强的自适应应用。
链
一般来讲,应用程序需要按照特定顺序调用多个组件。这就是 LangChain 中所说的链(chain)。它简化了复杂应用程序的开发过程,使得调试、维护和改进都变得更加容易。
它对于组合多个链以形成更复杂的应用程序也很有用,因为这些应用可能需要与多个语言模型交互。LangChain 提供了创建此类链的便捷方法,并提供了很多预构建的链:
ConversationalRetrievalChain chain = ConversationalRetrievalChain.builder() .chatLanguageModel(chatModel) .retriever(EmbeddingStoreRetriever.from(embeddingStore, embeddingModel)) .chatMemory(MessageWindowChatMemory.withMaxMessages(10)) .promptTemplate(PromptTemplate .from("Answer the following question to the best of your ability: {{question}}\n\nBase your answer on the following information:\n{{information}}")) .build();在这里,我们使用了一个预构建的链ConversationalRetreivalChain,它允许我们使用聊天模型、检索器、记忆内存和提示模板。现在,我们只需要使用该链就可以执行用户查询:
String answer = chain.execute("Who is Simpson?");链自带默认的记忆内存和提示模板。创建自定义链也很容易。创建链的功能使得复杂应用程序的模块化实现变得更加容易。
代理
LangChain 还提供了更强大的结构,如代理(agent)。与链不同的是,代理使用语言模型作为推理引擎来决定采取哪些行动以及行动的顺序。我们还可以让代理访问恰当的工具,以执行必要的行为。
在 LangChain4j 中,代理是作为 AI 服务的形式来使用的,可以用来声明式地定义复杂的行为。我们看一下是否能够以工具的形式为 AI 服务提供一个计算器,并使语言模型能够执行运算。
首先,我们定义一个具有基本计算器功能的类,并使用自然语言描述每个功能,以便于模型理解:
public class AIServiceWithCalculator { static class Calculator { @Tool("Calculates the length of a string") int stringLength(String s) { return s.length(); } @Tool("Calculates the sum of two numbers") int add(int a, int b) { return a + b; } }然后,我们定义 AI 服务的接口,并以此为基础进行构建。这个接口非常简单,但是它也能描述更复杂的行为:
interface Assistant { String chat(String userMessage);}现在,我们使用刚刚定义的接口和创建的工具,通过 LangChain4j 提供的构建器工厂创建一个 AI 服务:
Assistant assistant = AiServices.builder(Assistant.class) .chatLanguageModel(OpenAiChatModel.withApiKey(<OPENAI_API_KEY>)) .tools(new Calculator()) .chatMemory(MessageWindowChatMemory.withMaxMessages(10)) .build();就是这么简单!现在,我们可以开始向语言模型发送一些包含计算的问题了:
String question = "What is the sum of the numbers of letters in the words \"language\" and \"model\"?";String answer = assistant.chat(question);System.out.prtintln(answer); // The sum of the numbers of letters in the words "language" and "model" is 13. 运行这段代码后,我们会发现语言模型现在可以执行计算了。
需要注意的是,语言模型在执行一些需要它们具有时间和空间的概念或执行复杂运算程序的任务时会遇到困难。不过,我们可以随时通过为模型补充必要的工具来解决这个问题。
结论
在本教程中,我们介绍了利用大语言模型创建应用程序的一些基本元素。此外,我们还讨论了将 LangChain 这样的框架作为开发此类应用程序的技术栈的一部分的价值。
基于此,我们探索了 LangChain4j 的一些核心要素,LangChain4j 是 LangChain 的 Java 版本。这些库会在未来迅速发展。但是,它们也已让开发由语言模型驱动的应用程序的过程变得更加成熟而有趣!
读者可以在GitHub上查看本文的完整源代码。




