
导读:湖仓一体架构融合了数据湖的低成本、高扩展性,以及数据仓库的高性能、强数据治理能力,高效应对大数据时代的挑战。为助力企业实现湖仓一体的建设,Apache Doris 提出了数据无界和湖仓无界核心理念,并结合自身特性,助力企业加速从 0 到 1 构建湖仓体系,降低转型过程中的风险和成本。本文将对湖仓一体演进及 Apache Doris 湖仓一体方案进行介绍。
在过去的数年间,数据分析技术栈经历了许多重要变革,从最初数据仓库概念的诞生,到数据湖的兴起,进而演进到湖仓一体解决方案。这一技术路线的演进,反映出现代企业在数据分析领域对性能、实时性、一致性、开放性、统一管理方面的需求不断增强。
湖仓一体的演进
传统数据仓库的出现
在企业信息化发展初期、业务流程数字化的不断推进下,积累的数据愈发繁杂。管理层亟需快速整理这些数据,清晰洞察业务状况以精准决策,在此背景下催生了数据仓库。
数据仓库的核心目标是助力商业智能(BI)决策,将分散于各业务系统的结构化数据抽取、转换、加载(ETL)至集中存储库。数据仓库的显著优势包括:
高效的结构化数据分析:严格的 Schema 设计确保数据高质量,为后续处理和分析奠定坚实基础;列式存储可以提高特定查询的效率;精心设计的专用数据格式,能够更好适应结构化数据的特点和分析需求;存算一体架构减少了数据传输的开销,提升了分析性能。
成熟的 SQL 查询支持:基于关系模型的数据仓库完美适配 SQL 语言,相关人员可运用熟悉的查询语句,快速检索、统计、分析数据及生成各类报表,满足企业经营分析、销售趋势预测等方面的需求。
数据一致性保障:通过集中式存储与管理,数据仓库在严格的事务处理机制下能够确保数据的准确性与一致性,避免冗余和不一致带来的分析误差,为企业提供可靠的数据依据。
伴随互联网普及、物联网兴起,非结构化数据(如时序数据、图片、视频、文档)大量涌现,传统数据仓库无论从扩展性、成本,还是对非结构化数据的支持方面都难以承载新的需求,企业迫切寻求更高性价比的存储分析方案。同时,数据科学与机器学习的蓬勃发展推动了探索式分析需求,催生了数据湖技术的出现。
数据湖的兴起
Google 在大数据领域的开创性研究成果 —— Google 文件系统(GFS)、MapReduce 和 BigTable,犹如灯塔般引领了全球大数据技术的蓬勃发展之路,基于 Hadoop 的技术架构和生态系统自此诞生,催生了数据湖这一概念。Hadoop 使得在低成本的商用服务器上进行大数据处理成为可能,它能够很好支持以下应用场景:
超大规模数据处理:通过分布式存储和并行计算技术,可以在通用计算节点上进行高效地大规模数据处理,避免了依赖特殊硬件带来的高昂成本。
多模态数据支持与低成本存储:不同于传统数仓需要严格的表模式定义,数据湖能够以原始格式存储任意数量和类型的数据。通过 Schema-on-Read 机制,可在读取时再进行模式定义,最大限度地保留数据价值。这种灵活性尤其适用于图像、音视频和日志等信息,提供了更为敏捷的探索性分析能力。此外,依托于对象存储,不仅降低了存储成本,还实现了极高的可扩展性。
多模态计算:利用不同的计算引擎,在同一份数据集上执行包括 SQL 查询、机器学习、AI 训练等不同计算任务,满足多样化的数据处理需求。
“数据湖”这个名称生动诠释了企业数据状态:大量原始数据汇聚在一个统一的存储底座中形成“湖”,然后在湖上构建各类系统进行数据分析和处理。随着技术的发展,数据湖也逐渐形成了以存储、计算、元数据为主的三层架构,为后续的湖仓一体发展奠定了基础。
存储层: 数据湖通常使用分布式文件系统或者对象存储进行数据存储,比如 HDFS、AWS S3、Azure Blob Storage、阿里云 OSS、华为云 OBS、腾讯云 COS 等。它们提供几乎无限的存储容量,具备高可用性、低成本等优势,企业可按需使用。数据以原始格式存储,避免了传统数据仓库复杂的数据建模与结构化过程,为后续多样化的数据处理需求提供了灵活的基础。
计算层: 存储的数据允许被不同计算引擎访问,多引擎相互合作可满足不同场景下的数据处理速度与灵活性要求,如 Hive 引入 HiveQL,通过 SQL 进行批量数据加工处理;Spark 支持批处理、流处理、机器学习等多种计算场景;Presto 则专注交互式查询,快速响应复杂的即席查询请求。
元数据层: 以 Hive Metastore 为代表的元数据服务,记录了数据湖中的表结构、分区信息、数据存储位置等关键元数据,使得不同的计算引擎与工具能够基于统一的元数据理解数据,实现数据共享与协同处理,是维持数据湖有序运行的重要组件。
数据处理的新挑战
数据仓库和数据湖技术经过多年的发展,在各自领域都发挥的重要作用。这里简要总结了两类系统在不同技术方面的对比。随着企业对数据实时性、准确性、开放性等需求的日益增加,传统数据仓库和数据湖都各自面临来自不同方面的挑战:
传统数据仓库:
数据实时性匮乏:在电商大促和实时监控场景下,企业要求达到秒级甚至亚秒级的数据洞察能力。数据仓库基于静态的 ETL(Extract, Transform, Load)过程,难以处理持续变更的数据,无法满足实时决策的需求。例如,物流企业追踪货物的实时轨迹变更很难依靠传统的数据仓库来实现。
半结构化与非结构化挑战:社交媒体、医疗影像等领域充斥半结构化、非结构化数据,数据仓库固定 Schema 管理无法灵活适配,存储、索引、访问效率低下,像医疗科研分析海量病历文本与影像时,传统仓库束手无策。
数据湖:
性能瓶颈:面对分析师即时查询、业务人员自助探索需求,Spark/Hive 批处理在交互式、低延迟分析上乏力。如金融风控人员需实时核验交易风险,数据湖分析引擎延迟阻碍及时决策,亟需高性能计算引擎(如基于内存优化、向量化执行)加速数据处理。
事务性保证缺失:数据湖系统通常都会抛弃操作的事务性,以此来换取更为灵活的数据处理方式以及更好的扩展性。但由于缺乏事务性保证,数据的一致性和完整性可能会受到影响,在进行复杂的数据操作和处理时,可能会出现数据不一致或者数据丢失的情况。这对于一些对数据准确性要求较高的应用场景来说,可能会带来一定的风险和挑战。
数据治理危机:数据湖开放写入的特性,易引入低质量、不一致数据,若缺乏有效治理,“数据湖” 将沦为 “数据沼泽”,企业难以基于可信数据洞察,如多源数据汇聚的数据湖,因格式、定义差异常出现数据冲突。
由于数据仓库和数据湖各自擅长的领域不同,因此大多数企业会同时维护数据仓库和数据湖两套系统,以满足不同的业务需求。但随之而来的是数据在两套系统中冗余存储、在不同系统间重复传输、使用体验不一、数据孤岛等诸多问题。在上述背景下,如何融合数据仓库和数据湖的优势,成为了现代数据栈的发展趋势。
湖仓一体架构:融合与创新
湖仓一体是将数据湖和数据仓库的优势相结合的数据管理系统。为现代企业提供可扩展的存储和处理能力,避免处理不同工作负载的孤立系统,帮助企业建立单一数据源,消除冗余成本并确保数据新鲜度。随着近些年对湖仓融合的探索,湖仓一体架构也逐渐形成了以下结构范式,每一个层级都具有其独特的作用和价值,在融合数据仓库和数据湖的优势的同时,也解决了湖仓割裂的问题。
存储层:坚实基座 湖仓一体架构继承了数据湖时代分布式存储的优势,以 HDFS 或云对象存储为基础,确保数据的低成本、高可用存储。数据以原始格式或开放文件格式(如 Parquet、ORC)存入存储层,这些格式具备高效的压缩比与列存储特性,在数据读取时能够快速定位所需列数据,减少不必要的 I/O 开销,为后续数据处理提供高性能访问基础。
开放数据格式:灵活互通 在湖仓一体架构下,Parquet、ORC 等开放文件格式广泛应用于数据存储,保障了数据在不同计算引擎间的通用性。同时,Iceberg、Hudi、Delta Lake 等开放表格式发挥关键作用,它们不仅支持数据的近实时更新、高效的快照管理,还兼容 SQL 标准,使得数据既可以像传统数据库表一样进行事务性操作,又能充分利用数据湖的分布式存储与弹性计算优势,实现数据在数据湖与数据仓库场景间的无缝切换,为实时数据处理与历史数据分析提供统一的数据基础。
计算引擎:多元协同 计算层面整合了 Spark、Flink、Presto、Doris 等多样的计算引擎,各引擎各司其职。Spark 凭借其丰富的 API 与强大的批处理、机器学习,处理大规模数据复杂任务能力;Flink 聚焦实时流计算,保障数据实时性处理需求;Presto、Doris 针对交互式查询优化,快速响应用户即时的数据探索请求。通过统一的调度与资源管理,不同引擎可以共享存储资源,协同处理复杂的数据工作流,满足企业从实时监控到深度分析的全方位计算需求。
元数据管理:统一中枢 从早期的 Hive Metastore 演进到如 Unity Catalog、Apache Gravitino 这样的新一代元数据管理系统,湖仓一体架构实现了元数据的大一统。统一元数据管理支持跨多云、多集群环境下的元数据集中管理,提供统一的命名空间、全局的数据目录,无论数据存储在何处,使用何种计算引擎,用户都能通过统一的 API 进行快速检索、理解与访问数据。同时,元数据服务也在权限管理、审计、数据血缘追踪方面不断加强,帮助企业完成高质量的数据资产管理。
湖仓一体架构的出现,融合了数据湖的低成本、高扩展性与数据仓库的高性能、强数据治理能力,从而实现对大数据时代各类数据的高效、安全、质量可控的存储和处理分析。同时,通过标准化的数据格式和元数据管理,统一了实时、历史数据,批处理和流处理,正在逐步成为企业大数据解决方案新的标准。
Apache Doris:湖仓一体转型方案
Apache Doris 自 2.1 版本以来,Apache Doris 在湖仓一体场景的能力得到了显著提升与完善。
企业在推进湖仓一体化建设时,面临新系统选型、原有系统整合与升级等多重挑战。这一过程不仅涉及不同系统之间的选型困境,还包括数据格式转换、新接口适配、系统间的平滑切换,以及部门间的人力协调、权限移交与合规等问题。因此,企业亟需一个可操作的步骤,以逐步实现湖仓一体化。
为了更好的帮助企业完成湖仓一体的建设,Apache Doris 结合自身特性,提出了【数据无界】和【湖仓无界】核心理念,旨在帮助企业快速完成湖仓一体转型,降低转型过程中的风险和成本。
数据无界:打破数据边界
在构建湖仓一体化架构时,企业首先面临数据分析的统一接入难题。Apache Doris 作为高性能湖仓计算引擎,不仅提供统一的查询加速服务,还能有效简化系统架构,让数据价值触手可及。
灵活的数据接入
Apache Doris 通过可扩展的连接器框架,支持主流数据系统和数据格式接入,并提供基于 SQL 的统一数据分析能力,用户能够在不改变现有数据架构的情况下,轻松实现跨平台的数据查询与分析。
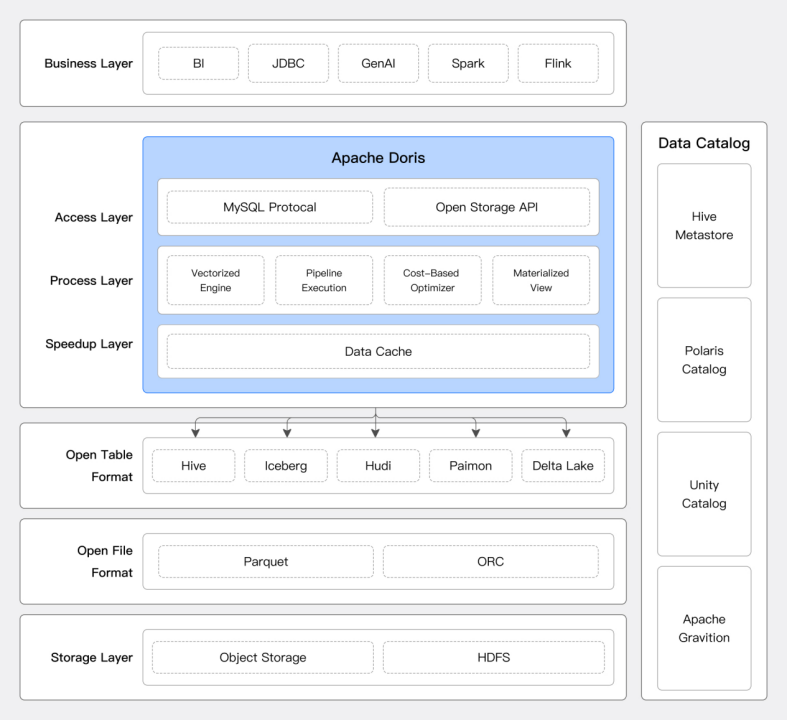
数据源连接器:无论是 Hive、Iceberg、Hudi 、Paimon,还是支持 JDBC 协议的数据库系统,Doris 均能轻松连接并高效提取数据。对于湖仓系统,Apache Doris 可从元数据服务中获取数据表的结构和分布信息,进行合理的查询规划,并利用 MPP 架构扫描和计算分布式数据。Doris 支持的数据源及其对应的元数据管理和存储系统如下:
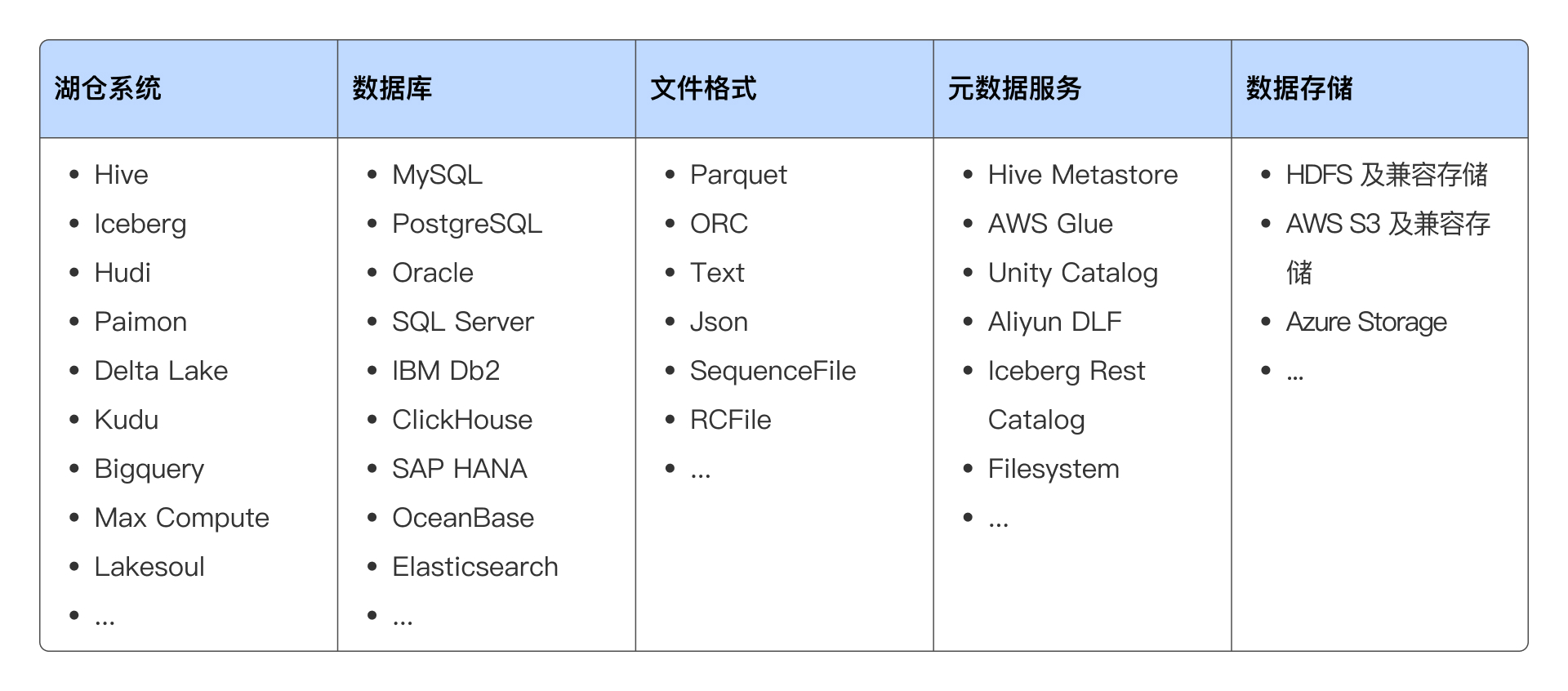
可扩展的连接器框架:Doris 提供良好的扩展性框架,帮助开发人员快速对接企业内部特有的数据源,实现数据快速互通。
Doris 定义了标准的数据目录(Catalog)、数据库(Database)、数据表(Table)三个层级,开发人员可以方便的映射到所需对接的数据源层级。Doris 同时提供标准的元数据服务和数据读取服务的接口,开发人员只需按照接口定义实现对应的访问逻辑,即可完成数据源的对接。
Doris 兼容 Trino Connector 插件,可直接将 Trino 插件包部署到 Doris 集群,经过少量配置即可访问对应的数据源。Doris 目前已经完成了 Kudu、Bigquery、Delta Lake、Kafka、Redis 等数据源的对接。
便捷的跨源数据处理:Doris 支持在运行时直接创建多个数据源连接器,可使用 SQL 对这些数据源进行联邦查询。比如用户可以将 Hive 中的事实表数据与 MySQL 中的维度表数据进行关联查询:
SELECT h.id, m.name FROM hive.db.hive_table h JOIN mysql.db.mysql_table m ON h.id = m.id;结合 Doris 内置的作业调度能力,还可以创建定时任务,进一步简化系统复杂度。比如用户可以将上述查询的结果,设定为每小时执行一次的例行任务,并将每次的结果,写入一张 Iceberg 表:
CREATE JOB schedule_load ON SCHEDULE EVERY 1 HOUR DO INSERT INTO iceberg.db.ice_table SELECT h.id, m.name FROM hive.db.hive_table h JOIN mysql.db.mysql_table m ON h.id = m.id;高性能的数据处理
企业在湖仓一体化转型过程中,对数据分析的性能需求是最根本且迫切的。Doris 作为分析型数据仓库,在数据处理和计算方面做了大量优化,并提供了丰富的查询加速功能:
执行引擎: Apache Doris 执行引擎基于 MPP 执行框架和 Pipeline 数据处理模型,能够很好的在多机多核的分布式环境下快速处理海量数据。同时,得益于完全的向量化执行算子,在计算性能方面 Apache Doris 在 TPC-DS 等标准评测数据集中处于领先地位。
查询优化器: Apache Doris 能通过查询优化器自动优化和处理复杂的 SQL 请求。查询优化器针对多表关联、聚合、排序、分页等多种复杂 SQL 算子进行了深度优化,充分利用代价模型和关系代数变化,自动获取较优或最优的逻辑执行计划和物理执行计划,极大降低用户编写 SQL 的难度,提升易用性和性能。
缓存加速与 IO 优化: 对外部数据源的访问,通常是网络访问,因此存在延迟高、稳定性差等问题。Apache Doris 提供了丰富的缓存机制,并在缓存的类型、时效性、策略方面都做了大量的优化,充分利用内存和本地高速磁盘,提升热点数据的分析性能。同时,针对网络 IO 高吞吐、低 IOPS、高延迟的特性,Doris 也进行了针对性的优化,可以提供媲美本地数据的外部数据源访问性能。
物化视图与透明加速: Apache Doris 提供丰富的物化视图更新策略,支持全量和分区级别的增量刷新,以降低构建成本并提升时效性。除手动刷新外,Doris 还支持定时刷新和数据驱动刷新,进一步降低维护成本并提高数据一致性。物化视图还具备透明加速功能,查询优化器能够自动路由到合适的物化视图,实现无缝查询加速。此外,Doris 的物化视图采用高性能存储格式,通过列存、压缩和智能索引技术,提供高效的数据访问能力,能够作为数据缓存的替代方案,提升查询效率。
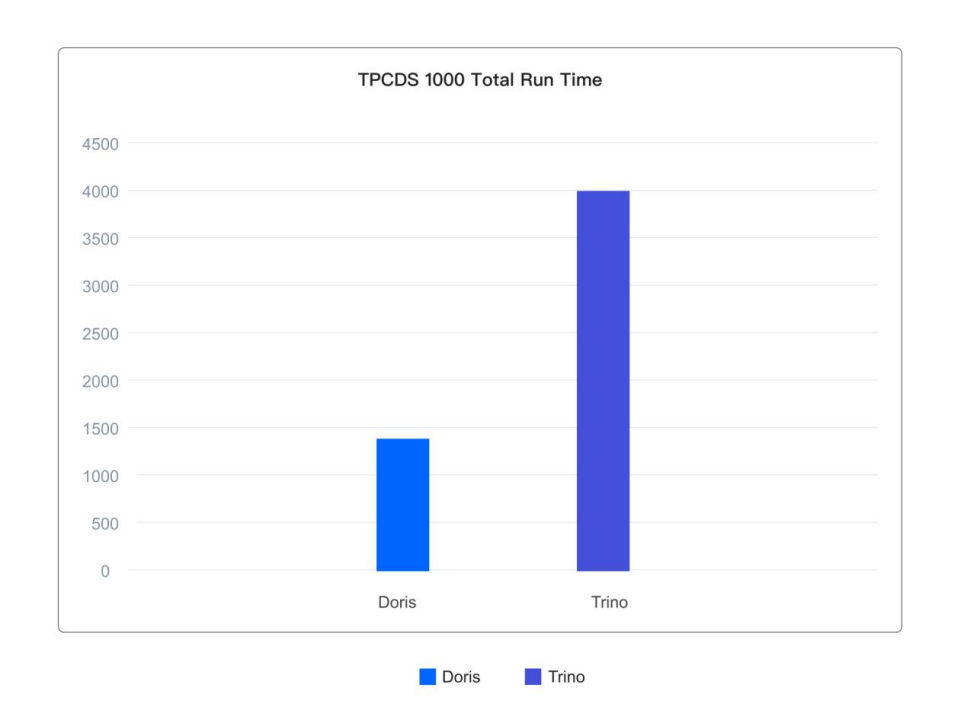
如下所示,在基于 Iceberg 表格式的 1TB 的 TPCDS 标准测试集上,Doris 执行 99 个查询的总体运行耗时仅为 Trino 的 1/3。
实际用户场景中,Doris 在使用一半资源的情况下,相比 Presto 平均查询延迟降低了 20%,95 分位延迟更是降低 50%。 在提升用户体验的同时,极大降低了资源成本。
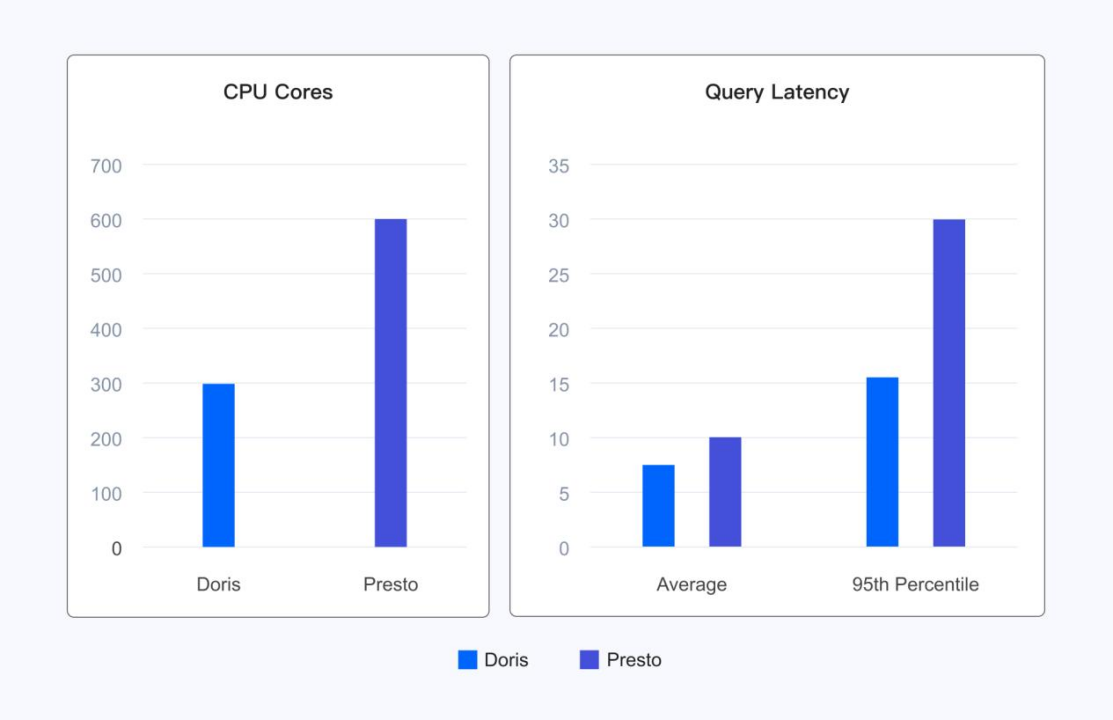
便捷的业务迁移
在企业整合多个数据源并实现湖仓一体转型的过程中,迁移业务的 SQL 查询到 Doris 是一项挑战,因为不同系统的 SQL 方言在语法和函数支持上存在差异。若没有合适的迁移方案,业务侧可能需要进行大量改造以适应新系统的 SQL 语法。
为了解决这个问题,Doris 提供了 SQL 转换服务,允许用户直接使用其他系统的 SQL 方言进行数据查询。转换服务会将这些 SQL 方言转换为 Doris SQL,极大降低了用户的迁移成本。目前,Doris 支持 Presto/Trino、Hive、PostgreSQL 和 Clickhouse 等常见查询引擎的 SQL 方言转换,在某些实际用户场景中,兼容率可达到 99%以上。
湖仓无界:打破系统边界
面对多系统并存带来的挑战,湖仓一体化转型的第二步便是架构整合、以减少需维护的系统数量。 这不仅有利于降低架构复杂性,同时可解决数据一致性和管理一致性的问题。接下来我们从系统架构、功能等多维度介绍基于 Doris 的湖仓一体架构整合方案。
现代化的部署架构
自 3.0 版本以来,Apache Doris 支持面向云原生的存算分离架构。这一架构凭借低成本和高弹性的特点,能够有效提高资源利用率,实现计算和存储的独立扩展。这对于湖仓一体化至关重要,为企业提供了灵活的资源管理方式,使其能够更高效地应对大规模数据分析需求。
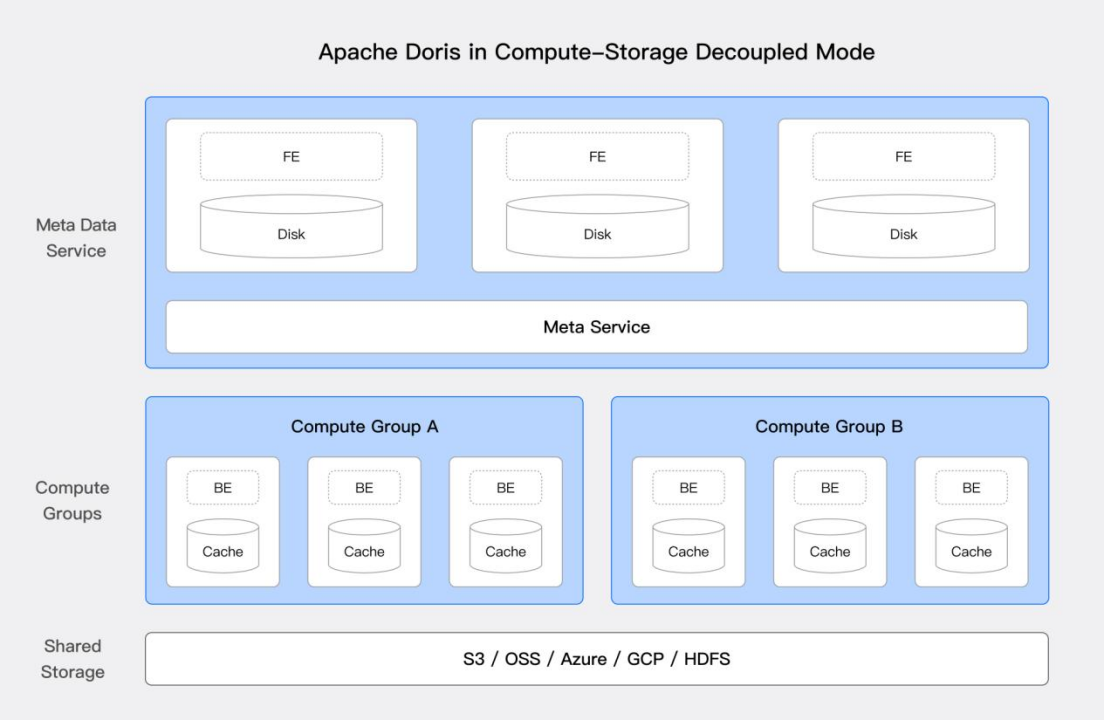
上图是 Doris 存算分离的系统架构,对计算与存储进行了解耦,计算节点不再存储主数据,底层共享存储层(HDFS 与对象存储)作为统一的数据主存储空间,并支持计算资源和存储资源独立扩缩容。存算分离架构为湖仓一体解决方案带来了显著的优势:
低成本存储: 存储和计算资源可独立扩展,企业可以根据需要增加存储容量而不必增加计算资源。同时,通过使用云上的对象存储,企业可以享受更低的存储成本和更高的可用性,对于比例相对较低的热点数据,依然可以使用本地高速磁盘进行缓存。
唯一可信来源: 所有数据都存储在统一的存储层中,同一份数据供不同的计算集群访问和处理,确保数据的一致性和完整性,也减少数据同步和重复存储的复杂性。
负载多样性: 可以根据不同的工作负载需求动态调配计算资源,支持批处理、实时分析和机器学习等多种应用场景。通过分离存储和计算,企业可以更灵活地优化资源使用,确保在不同负载下的高效运行。
丰富的数据存储和管理功能
主流的数据湖格式,如 Iceberg 和 Hudi,通过标准化的数据表格式规范,为数据湖提供了灵活高效的存储和管理方式。Apache Doris 不仅支持这些主流湖格式,还具备自身的存储格式,能够满足相应的需求,并提供更丰富的功能和更高的性能。
半结构化数据支持: Doris 原生支持 JSON、Variant 等半结构化数据类型,提供 Schemaless 的数据管理体验,节省了用户转换、清洗数据的开销。用户可以直接导入任意 JSON 格式的数据,Doris 会自动解析并以高效的列格式存储,适应复杂的数据分析需求。
数据更新的支持: Doris 提供近实时的数据更新能力,也支持对变更数据的高效分析。此外,基于部分列更新能力,用户也可以在 Doris 内完成多流合并宽表的操作,进一步简化数据链路。
丰富的数据索引: Doris 可以通过前缀索引、倒排索引来快速命中数据,也可通过跳数索引、BloomFilter 索引进行快速数据跳过。在存算分离/湖仓场景下,能显著减少本地或网络 IO,是数据分析场景的查询加速利器。
实时数据和批数据写入: Doris 支持通过微批方式进行高频数据写入,同时也可批量加载预先生成的数据。同时,通过 MVCC 的数据管理方式,可在同一份数据上存储和处理实时数据和历史数据。
开放性
数据湖的开放性对湖仓一体架构的重要性不言而喻。它是高效整合和管理数据的关键因素,也是影响湖仓一体架构性能和成本的主要因素之一。在【01 数据无界:打破数据便捷】章节中,已经介绍了 Doris 对开放表格式、文件格式等系统的支持。
此外, Apache Doris 自身存储的数据同样拥有良好的开放性。Doris 提供了开放存储 API,并基于 Arrow Flight SQL 协议实现了高速数据链路,具备 Arrow Flight 的速度优势以及 JDBC/ODBC 的易用性。 基于该接口,用户可以使用 Python/Java/Spark/Flink 的 ABDC 客户端访问 Doris 中存储的数据。
与开放文件格式相比,开放存储 API 屏蔽了底层的文件格式的具体实现,Doris 可以通过自身存储格式中的高级特性,如丰富的索引机制来加速数据访问。同时,上层的计算引擎无需对底层存储格式的变更或新特性进行适配,所有支持的该协议的计算引擎都可以同步享受到新特性带来的收益。
结束语
以上是对湖仓一体演进及 Apache Doris 湖仓一体方案的完整介绍。在下一篇文章中,我们将以“湖仓分析加速”、“多源联邦分析”、“湖仓数据处理”这三个典型场景为例,分享 Apache Doris 湖仓一体方案的最佳实践。 结合实际问题,详细分享使用指南及带来的效果。




