
号称引发 OpenAI“内讧”的 Q* 与 Q-Learning 究竟是什么?
最近一周,全球科技界都在关注 OpenAI“宫斗大戏”,随着 CEO Sam Altman 和总裁兼联合创始人 Greg Brockman 正式回归,这场大戏似乎终于落下了帷幕。但对于“宫斗”导火索,外界一直众说纷纭。
日前,有消息称,引发 OpenAI 内讧的根源是其一项神秘的重大突破——Q*。
据路透社报道,一位消息人士表示,OpenAI 公司 CTO Mira Murati 曾亲口证实,Q*(读作 Q Star)才是针对 Altman 采取逼宫行动的源动力,而且连董事会主席 Greg Brockman 也被排除在外,导致其随后用辞职向 OpenAI 表达了抗议。
Q* 到底是什么?又有什么值得关注?答案很简单:它可能代表着 AI 未来发展的一条可能路径。
Q-Learning 与 Q* 算法
据悉,Q* 指向两种不同的理论:其一代表 Q-Learning,其二则是马里兰反演证明过程系统(MRPPS)中提出的 Q* 算法。要想理解 Q* 的潜在影响,首先要明确这二者之间有何差异。
理论一: Q-Learning
Q-Learning 属于强化学习的一种,指 AI 通过反复试验来掌握决策能力。在 Q-Learning 当中,智能体通过估计动作-状态组合间的“质量”来学习如何做出决策。
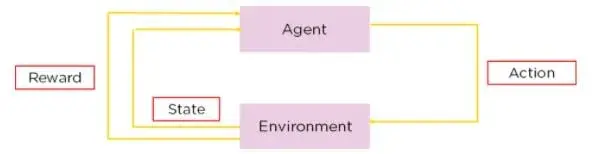
这种方法与当前 OpenAI 的技术(即人类反馈强化学习,简称 RLHF)的最大区别,在于前者并不依赖于人类交互,而能够自行完成所有操作。
想象一台机器人正在迷宫中行走。通过 Q-Learning,它将学会尝试不同的路线以找到通往出口的最快路径。当它接近出口时,就能获得由自己预先设定的正奖励,而遇到死胡同时则获得负奖励。随着时间推移和反复试验,机器人就会制定出一种策略(即 Q-table),包含它在迷宫中各个位置上的下一步最佳行动。整个过程完全自主,单纯依赖于机器人同实际环境间的交互。
而如果机器人使用 RLHF,那么当它到达每个路口时,都可能由人类介入干预、评判机器人的选择是否明智,而非由智能体自行发现问题。
这种反馈可以是直接命令(左转)、建议(优先选择光照更充足的路径)或者对机器人选择的评价(选得对,或者选错了)等多种形式。
在 Q-Learning 当中,Q* 代表着期望状态。在该状态下,智能体确切知晓每种状态下所应采取的最佳行动,并能随时间推移最大化其总体预期奖励。用数学术语来说,就是满足贝尔曼方程。
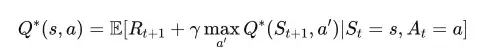
早在今年 5 月,OpenAI 就曾发表一篇文章,称他们“训练出一套模型,不同于简单奖励正确的最终答案,该模型可以奖励每个正确的推理步骤,从而在解决数学问题方面表现出极高的水平。”如果他们确实是使用 Q-Learning 或者类似的方法实现了这个目标,则意味着 ChatGPT 将能解决各种以往难以应对的复杂问题和任务。
理论二:来自 MRPPS 的 Q* 算法
Q* 算法是马里兰反演证明过程系统(MRPPS)中的一部分。这是 AI 领域一种复杂的定理证明方法,主要应用在问答系统当中。
相关研究论文写道,“Q* 算法在搜索空间中生成节点,使用语义和句法信息来指导搜索。语义允许终止当前路径,并探索其他更可能通往成功的路径。”

解释此过程的一种方法,就是设想一位虚拟版的福尔摩斯打算解决一个复杂的案件。他需要收集线索(语义信息)并将其串连成逻辑(句法信息)以得出结论。Q* 算法在 AI 领域的作用也差不多,就是结合语义和句法信息来勾勒出复杂问题的解决过程。
如果走的是这个路子,就代表 OpenAI 距离用 AI 模型理解现实又向前迈进了一步。换言之,在现有的文本提示之外,OpenAI 已经越来越像《钢铁侠》中的贾维斯或者《蝙蝠侠》中的蝙蝠计算机。
总结来讲,Q-Learning 是指 AI 从与所处环境的交互中学习,而 Q* 算法则更多强调如何提高 AI 的演绎能力。理解了这些区别,我们才有机会进一步讨论 OpenAI Q* 成果的潜在影响。二者在推动 AI 发展方面都有着巨大的潜力,但应用思路和实际效果却又大相径庭。
当然,所有这些还都只是猜测,因为 OpenAI 官方并没有出面解释这个概念,甚至没有证实或否认 Q* 的存在。
Q* 将带来哪些影响?
传闻中的 OpenAI Q* 可能会引发广泛且多样的影响。如果它真是 Q-learning 的某种高级形式,也许意味着 AI 将在复杂环境下获得飞跃性的自主学习与适应能力,从而解决一系列全新问题。迷一进步将大大增强 AI 根据不断变化的条件做出瞬间决策的能力,从而将自动驾驶汽车等技术推向新的高度。
而另一方面,如果 Q* 代表的是 MRPPS 中的 Q* 算法,则可能标志着 AI 的演绎推理和问题解决能力迈上了新的台阶。这主要作用于需要深入分析思维的领域,例如法律分析、复杂的数据解释乃至医学诊断等。
无论正确答案如何,Q* 可能都代表着 AI 发展史上的又一重大进步,也符合 OpenAI 内部爆发的这场关于技术意义的激烈冲突。它将让我们更直观、更高效、更准确地处理以往需要高水平专业人才才能解决的现实问题。而且伴随这些进步,人们对于 AI 伦理、安全性、以及日益强大的 AI 力量对于人类日常生活乃至整个社会的影响也开始产生新的疑问和担忧。
Q* 的潜在优点:
更快、更好地解决问题:如果 Q* 属于 Q-learning 或者 Q* 算法的高级形式,则有望让 AI 系统获得更强大的复杂问题解决能力,从而推动医疗保健、金融及环境管理等行业的进一步发展。
更好的人机协作能力:拥有更先进的学习或演绎能力的 AI 将有望增强人类工作,从而在研究、创新和日常任务中提高协作效率。
自动化迎来新高峰:Q* 有望建立起更加复杂、精妙的自动化技术,提高生产力水平,并创造出新的行业与就业机会。
Q* 的风险和担忧:
道德和安全问题:随着 AI 系统变得愈发先进,确保它们以符合道德就安全要求的方式运作也变得越来越具有挑战性。种种意想不到的风险也将接踵而至,例如 AI 可能做出与人类价值观不相符的行动决策。
隐私与安全:随着 AI 愈发先进,隐私和数据安全问题也将不断升级。能够深入理解数据并与数据交互的 AI 一旦遭到滥用,后果将难以估量。想象一下,当我们向家人说出善意的谎言时,AI 很可能基于诚实原则而将其戳破。
经济影响:自动化与 AI 能力的增强可能会彻底消灭某些岗位甚至是特定行业,强迫整个社会找到新的劳动力培养方式。如果 AI 已经能够完成大部分工作,人类在劳动力市场上将变得毫无意义。
价值观错位:AI 系统可能会制定与人类意图相背、甚至有损人类福祉的目标或行动方法,最终造成有害结果。想象一下,清洁机器人可能会为了保持整洁而丢弃用户的重要文件,甚至通过“干掉”主人的方式让房间永不杂乱。
AGI 即将成为现实?
对于神秘的 Q*,有观点认为,在追求通用人工智能(AGI)的过程中,Q* 将发挥关键作用。
所谓 AGI,是指机器能够在各种任务中表现出类似于人类的理解、学习和智能应用水平。作为 AI 的一种形式,AGI 可以将自己的经验从一个领域推广到另一领域,从而展现出真正的适应性和多功能性。虽然当前 Q* 与 AGI 之间还有很大距离,但 Q* 有可能代表着特定 AI 功能的重大进展。
网友 Sebb 认为,AGI 将在未来 6 到 24 个月内实现,这已经成为一种必然。“一切阻止都将是徒劳的,我们必须马上为此做好准备,并考虑到某些人带着恶意参与这场人类历史上意义最为深远的技术发明。我们人类是否真是生物史上最先进的进化物种,可能将在这场颠覆中给出证明。”
也有网友对此感到担忧,网友 m4callik 称自己“要怀疑 Sam 的动机了,而且会从不同的角度看待最近的这场 OpenAI 闹剧”,“事态正飞速变化,比任何人想象的都要快。我绝对不希望让微软、Larry Summers 或者什么 Salesforce 前 CEO 来决定某项成果是否属于 AGI。让那帮能靠 AI 商业潜力赚大钱的既得利益者来判断 AGI 是否实现,就像让裁判员亲自下场比赛一样,毫无公信力可言。”
网友 Browsergpts.com 则认为,目前争论的焦点并不在于 AGI 本身,而是在表达对领导决策和安全协议的担忧。“AGI 有望彻底改变社会的方方面面,所以我们必须为它给人类各领域造成的影响做好准备,这才是关键中的关键。AGI 就像一把机会之钥,只要转动一下就能带来巨大的收益,同时也造成巨大的风险。必须采取强有力的安全措施来保证其得到妥善使用。
作为 AI 领域的领导者,Sam 和其他 OpenAI 董事肩负着应对这一复杂局面的使命。我相信他们正在尽最大努力实现安全过渡,但在推动 AGI 技术发展的过程中,我们也得采取必要的预防措施——毕竟对于这样一项重量级、变革性技术,也许根本没有任何亡羊补牢的余地。”
不过,如今的 Q* 系统既无自我意识,也无法超越其预训练数据和人类设定算法的边界。所以必须承认,Q* 还远没有达到威胁人类的地步。虽然 Q* 确实是一大飞跃,但它距离 AGI 还很遥远、人类目前仍然安全无忧。
参考链接:
https://decrypt.co/207413/what-is-q-star-q-learning-agi-openai
https://community.openai.com/t/what-is-q-and-when-we-will-hear-more/521343?filter=summary




