
背景
在闲鱼技术探究 Flutter 工程一体化的过程中,为了做到最好的开发体验,需要无缝衔接 FaaS 端代码与业务 Flutter 代码,一份代码既可以在 FaaS 部署,也可以直接引入在业务代码主工程中,使之真正做到工程一体。
为了实现这一目标我们对两部分代码通过 RPC 调用的方式实现了代码解耦,而工程解耦依赖于 Flutter/Dart 在编译过程中的 Tree-Shaking 机制。为了避免踩坑,我们需要了解,整个 Tree-Shaking 是怎么起作用的。本篇文章结合 Flutter Engine 源码对这一过程进行了简单的探究。
前置知识
Tree Shaking 是一种死代码消除(Dead Code Elimination)技术,这一想法起源于 20 世纪 90 年代的 LISP。其思想是:一个程序所有可能的执行流程都可以用函数调用的树来表示,这样就可以消除那些从未被调用的函数。该算法最先被应用到 Google Closure Tools 中的 JavaScript 中,然后被应用到同样由 Google 编写的 dart2js 编译器中。在 Flutter 中,同样有这样的 Tree Shaking 机制来减小最终产出的包大小。Flutter 提供了三种构建模式,针对每个不同的模式,Flutter 编译器对产出的二进制文件有不同优化,Tree-Shaking 机制并不会在 debug 模式中触发。在 Profile/Release 模式下编译的 AOT 产物中,有几个比较重要的产物可以让我们更直观地看到 Tree-Shaking 机制在发挥作用:
app.dill : 这就是 dart 代码通过 build 的产物,为二进制的字节码,可以通过
strings看到里面的内容,其实就是我们 dart 代码的源码。snapshot_blob.bin.d : 这个文件里面是所有参与编译的 dart 文件的集合,包括我们自己的业务代码、
pubspec.yaml中定义的三方库的代码、以及我们业务代码中 import 进来的所有 flutter 或者 dart 原生package的代码。
Tree Shaking 机制探究
最小化 Demo 初探
我们写一个最简单的例子,代码如下:

代码非常简单,里面包含了一个没有被使用的 _unused 方法。下面我们在 Profile 模式下进行编译,通过 DevTools 来查看最终编译的产物,如下图所示
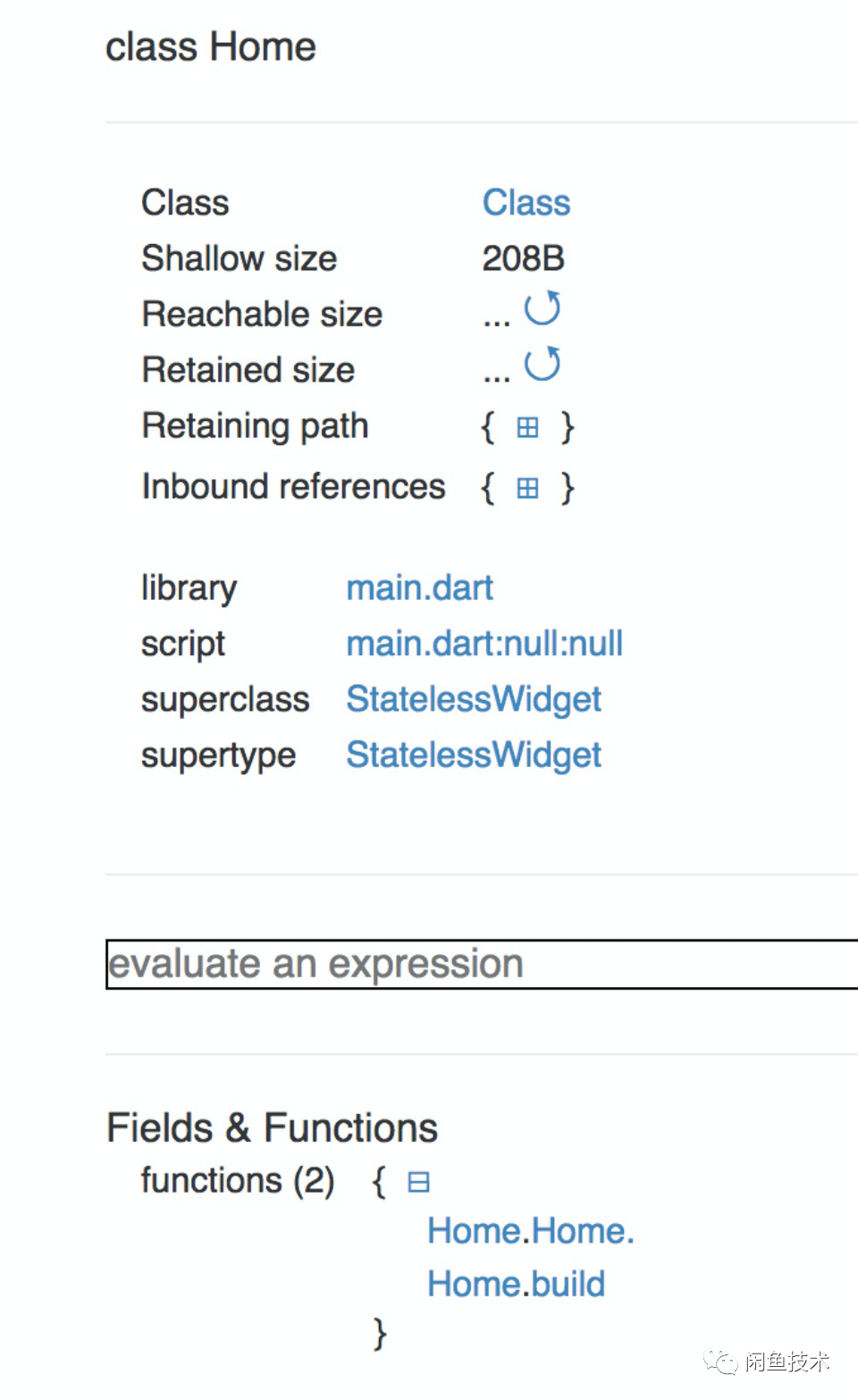
可以看到,在 Funtions 中,并没有 _unused方法,说明在编译过程中,这段无用的代码被“摇”掉了。实际上除了 Function 之外,Flutter 编译过程中对于引入的 lib,import 的 dart 文件都有相似的 Tree-Shaking 处理。下面深入代码来看看,这究竟是怎么做到。
代码解析
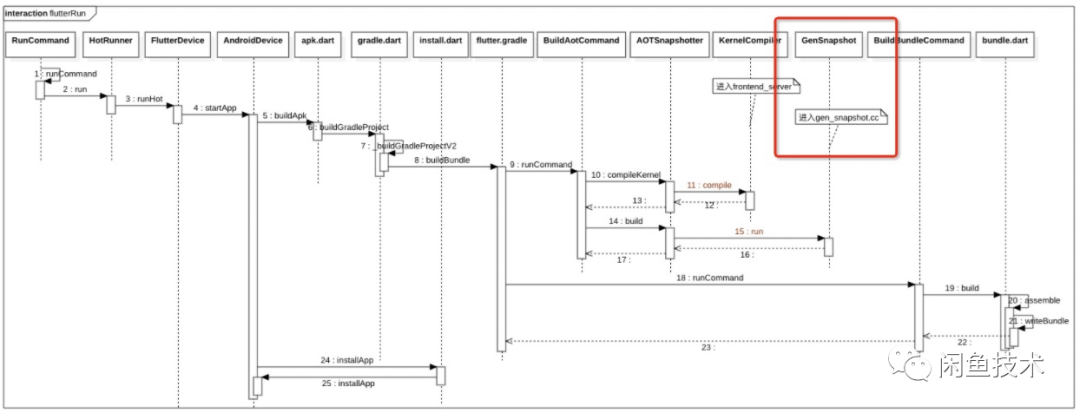
这里借用 Gityuan 前辈的 flutter run 命令执行的时序图,整个编译流程会比较长,在 GenSnapshot.run() 方法会调用 gensnapshot 这个二进制可执行文件(对应的源码在目录 thirdparty/dart/runtime/bin/gensnapshot.cc),生成机器码。
用放大镜来看看 gensnapshot 内部的执行过程:
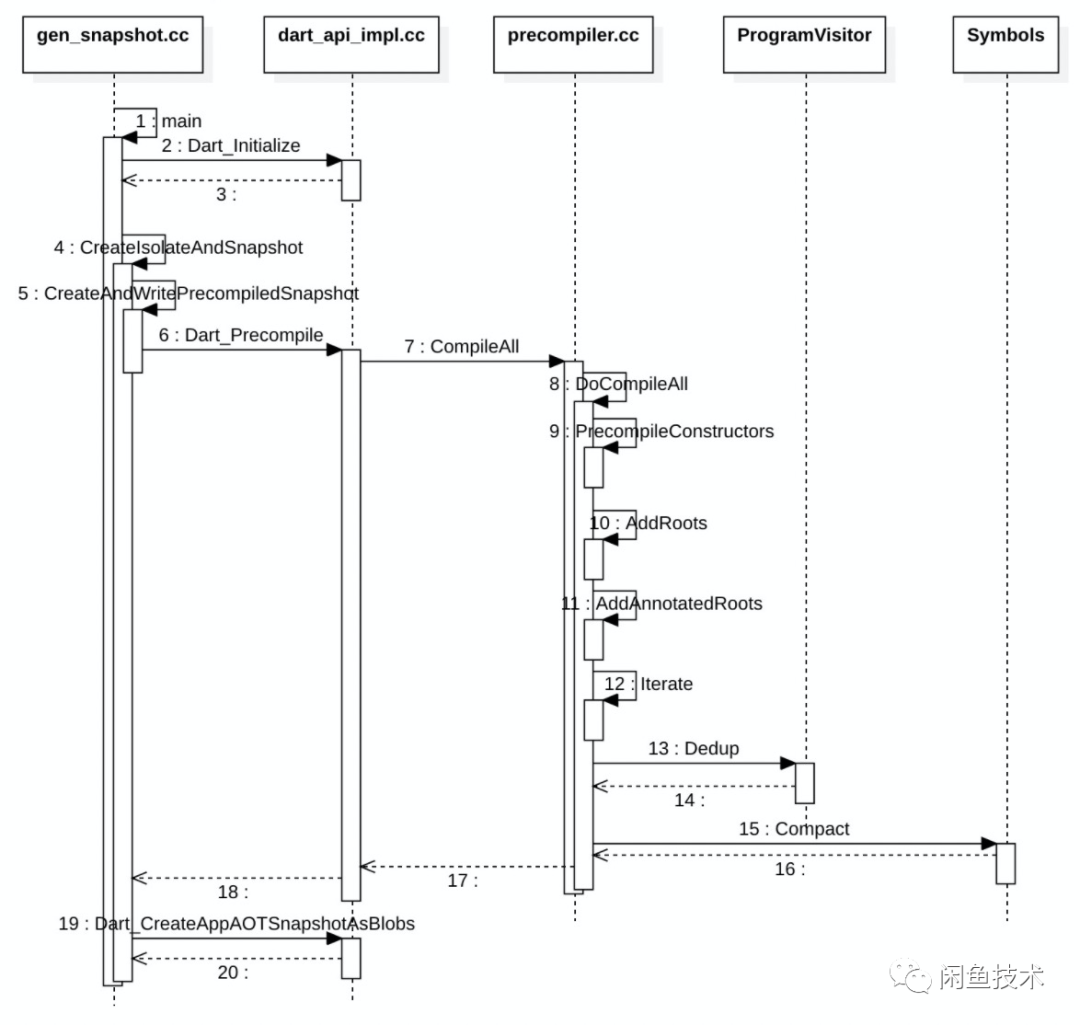
tree-shaking 机制就发生在其中的编译阶段,即 CompileAll() 方法。下面我们深入到代码去一步一步探究,Flutter 编译器是怎么对代码做裁剪的。
源代码路径是 third_party/dart/runtime/vm/compiler/aot/precompiler.cc,读者也可以自行对照查询。
编译阶段
首先是必备的准备工作,需要将对象池保留到 AOT 编译结束,因此这里必须使用能存活那么久的句柄,使用了 StackZone。

为了使用类层次结构分析 (CHA),在编译前需要确保类的层次结构稳定,同时确保查找入口点时不会因为函数的类还没有最终确定而漏掉函数。CHA 是一种编译器优化,可根据对类层次结构的分析结果,将虚拟调用去虚拟化为直接调用。

预编译构造函数,计算优化指令数等信息,可以用于内联函数。

下一步生成桩代码,通过 StubCode::InterpretCall 得到的 code 来获取它的对象池,再利用 StubCode::Build 等一系列方法系列方法获取的结果保存在 object_store。收集动态函数的方法名,之后通过 AddRoots() 方法,从 C++发生的分配和调用的起点添加为根, 同时通过 AddAnnotatedRoots() 方法将所有以 @pragma(’vm:entry-point’)为标注的也添加为根。

之后,代码开始编译, Iterate() 是编译最为核心的地方。在这里会以上面找到的根作为目标,遍历添加该目标的调用者。

在该方法内部,主要的调用链如下:
ProcessFunction
==> CompileFunction
==> PrecompileFunctionHelper
==> PrecompileParsedFunctionHelper.Compile
至此,编译完成之后开始进入 Tree-Shaking 阶段,对无用代码进行简化。
Tree shaking 阶段
在上面的编译过程中,函数/类等调用信息已经进行了输出,根据这些信息,让编译器可以知道,具体哪一些是不必要的代码。这里以对 Function 的处理为例进行讲解:
TraceForRetainedFunctions();
在这个方法中,取得 Library、Class 等句柄之后,以 Library 为单位,对每个包内的代码进行处理,会遍历所有类中的 Functions 进行处理。
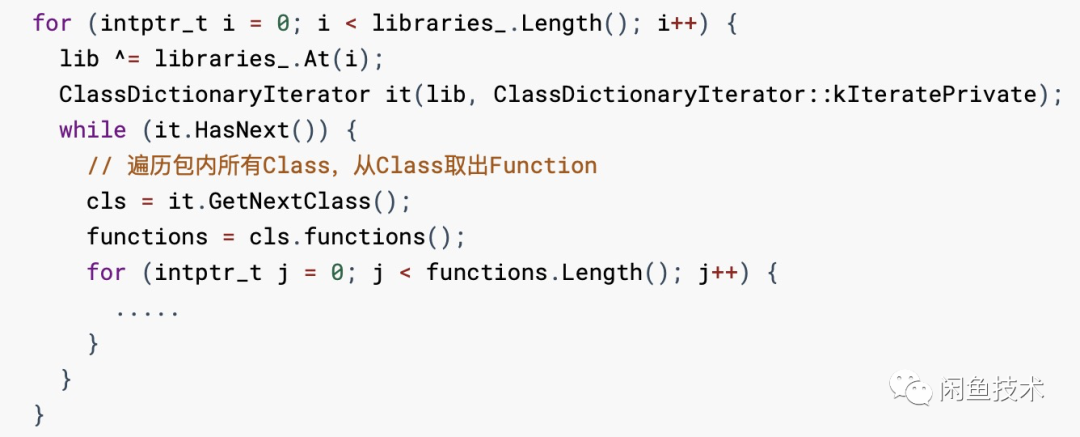
通过 AddTypesOf(constFunction&function) 方法,将调用到的函数添加到 functions_to_retain_ 池中,同时对 Function 中的类型参数做了读取,通过 AddType 方法,将这些类型参数添加到对应的 typeargs_to_retain_ 池和 typestoretain_ 池中,用于类型信息的 TreeShaking(分别对应 DropTypeArguments 和 DropTypeParameters)。
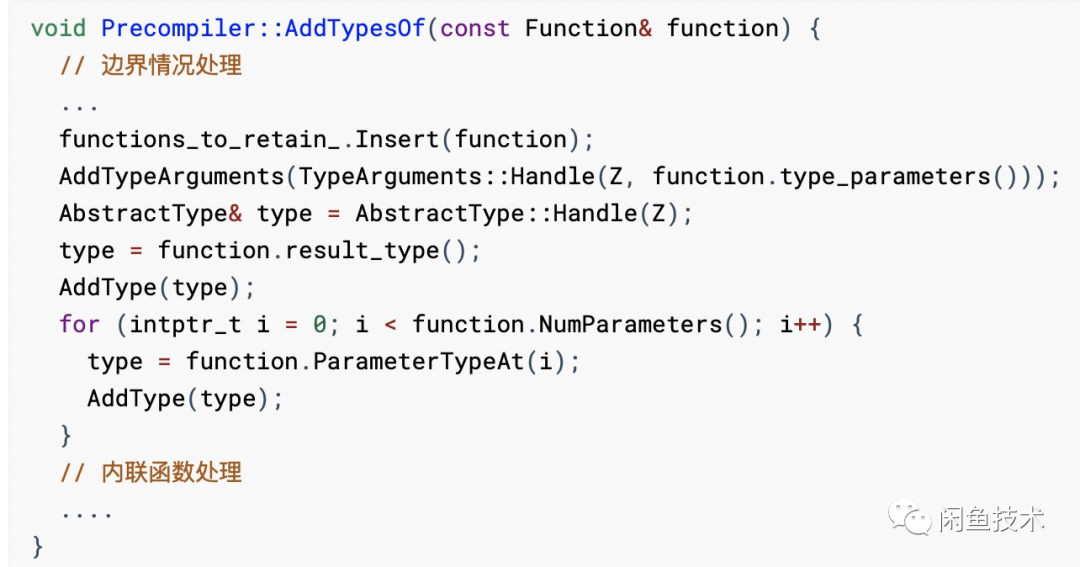
Class 信息在同名方法
AddTypesOf(constClass&cls)中进行处理,处理过程比较类似,这里不做赘述,感兴趣的读者可以自行查阅
FinalizeDispatchTable();
这个方法里面,会确保在执行 Drop 方法之前建立用于序列化调度表的条目,因为编译器后续可能会清除对 Code 对象的引用。同时删除调度表生成器,以确保在这之后不再尝试添加新条目。
ReplaceFunctionStaticCallEntries();
在这个方法里通过声明的匿名内部类 StaticCallTableEntryFixer ,对静态函数调用入口做了替换。
Drop
接下来,会执行一系列的 Drop 方法。这些方法会去掉多余的方法、字段、类、库等,如下所示:
DropFunctions();
DropFields();
DropTypes();
DropTypeParameters();
DropTypeArguments();
DropMetadata();
DropLibraryEntries();
DropClasses();
DropLibraries();
具体调用时序如下图所示:
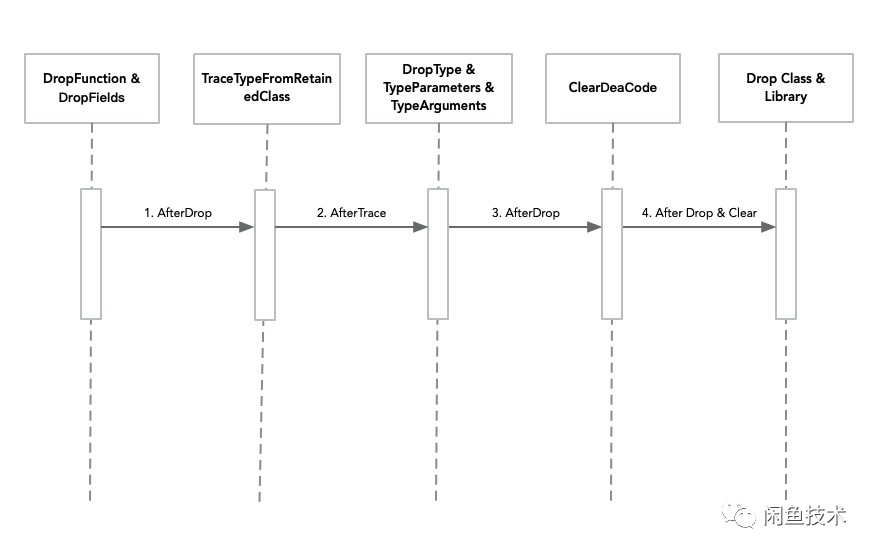
由于这些方法的内部实现思路有很多相似之处,这里针对 Function 的方法 DropFunctions 为例来说明。
在该方法中,核心是通过以上提到 functions_to_retain_ 池,对 Function 是否有根调用者进行判断, 如果池中不包含 Function 对象,说明这是可以舍弃的 Function。之后,将剩下的 Function 重新写回 Class,并更新 Class 的调用表。
在方法内部声明了 drop_function 函数来“摇掉”Function。

之后使用对所有的代码中的 Function 进行遍历, 使用上面声明的 drop_function 对无用的 Function 代码进行标记和删除。

将需要被保留的 Funtion 重新写进所属 Class 中:

重新生成类的调用表,同时对调用表中的可能存在的无用 Function 进行兜底删除:

最后是一些内联函数等边界情况的处理,这里不再赘述。在完成 Drop 阶段之后,可以被丢掉的代码已经进入了删除池中,后面进入编译的收尾阶段,进一步减小二进制文件大小。
收尾阶段
在 Tree-Shaking 结束之后,进入编译收尾工作,包括代码混淆,垃圾回收等。

值得注意的是 Dedup 这个方法,关键代码代码如下:

在该方法内进行很多重复数据删除工作;在 AOT 模式下,binder 是在 Tree Shaking 之后运行的,在此期间,所有的目标都已经被编译,因此 binder 会用对目标的直接调用代替所有的静态调用,进一步减小了编译产物二进制文件。至此所有的编译工作完成,Tree-Shaking 完成了他的使命。
拓展
在 Flutter 1.20 版本,通过 Tree-Shaking 机制移除在工程中未使用到的 icon fonts,进一步缩小了包大小(100KB 左右),不过该方法的实现并不在以上说明的编译阶段,而是在 build_system 里,对 assets 进行了优化。相关的 PR 在 github.com/flutter/flutte/pull/49737 可以查看。
小结
本文主要结合 Flutter Engine 源代码,从编译阶段出发,探究了在过程中 Tree-Shaking 的运行机制。由于这样一个机制的存在,为工程解耦提供了理论基础,让工程一体化的实现更为简单,同时对我们进一步优化包大小有启发。
本文转载自公众号闲鱼技术(ID:XYtech_Alibaba)。
原文链接:




