
整理 | 华卫、核子可乐
一家中国 AI 初创公司创建出被用户称作 “真正的‘Open’AI ”的人工智能模型。
昨晚,DeepSeek 发布了最新系列模型 DeepSeek-V3 首个版本并同步开源。该模型可以处理一系列基于文本的工作负载和任务,如编码、翻译以及根据描述性提示撰写论文和电子邮件。根据 DeepSeek 的内部基准测试,DeepSeek V3 的性能优于可下载的 “公开 ”可用模型和只能通过 API 访问的 “封闭 ”人工智能模型。
在编程竞赛平台 Codeforces 主办的编码竞赛子集中,DeepSeek 的表现优于 Meta 的 Llama 3.1 405B、OpenAI 的 GPT-4o 和阿里巴巴的 Qwen 2.5 72B 等模型。DeepSeek V3 还在 Aider Polyglot 测试中击败了竞争对手,该测试旨在衡量模型是否能成功编写新代码,并将其整合到现有代码中。
“综合评估表明,DeepSeek-V3 已成为目前可用的最强大的开源模型,其性能可与 GPT-4o 和 Claude-3.5-Sonnet 等领先的闭源模型相媲美。”DeepSeek 表示。
6710 亿参数,训练规模不到 600 万美元
根据该公司的许可协议,这套新模型可以通过 Hugging Face 获取,其参数规模达到 6710 亿,但会使用混合专家架构以保证仅激活选定的参数,以便准确高效地处理给定任务。目前,DeepSeek-V3 代码可通过 GitHub 基于 MIT 许可进行获取;企业亦可通过类似 ChatGPT 的 DeepSeek Chat 平台测试这套新模型,并访问 API 以供商业使用。
模型权重下载和更多本地部署信息可参考:https://huggingface.co/deepseek-ai/DeepSeek-V3-Base
GitHub 链接:https://github.com/deepseek-ai/DeepSeek-V3
与其前代成果 DeepSeek-V2 一样,这款最新超大型模型使用同样的基础架构,围绕多头潜在注意力(MLA)与 DeepSeekMoE 构建而成。这种方法确保其始终保持高效的训练与推理能力,同时配合有针对性的共享“专家”(即大模型内各独立且体量较小的神经网络)为各个 token 相应激活总计 6710 亿参数中的 370 亿个。
除了利用基础架构保证 DeepSeek-V3 拥有强大性能之外,DeepSeek 方面还发布了另外两项进一步提高模型表现的创新。
首先是辅助无损负载均衡策略,用以动态监控并调整专家负载,以均衡方式加以使用,保证不会损害模型的整体性能。其二则是多 token 预测(MTP),这允许模型同时预测多个未来 token。这项创新不仅提高了训练效率,还使得模型的执行速度提高了三倍,每秒可生成 60 个 token。
该公司在详细介绍新模型的技术论文中写道,“在预训练期间,我们在 14.8 T 高质量且多样化的 token 上训练了 DeepSeek-V3……接下来,我们对 DeepSeek-V3 进行了分两个阶段的上下文长度扩展。在第一阶段,最大上下文长度扩展至 32K;在第二阶段,则进一步扩展至 128K。在此之后,我们在 DeepSeek-V3 的基础模型之上进行后训练,包括监督微调(SFT)和强化学习(RL),以确保其与人类偏好保持一致并持续深挖模型潜力。在后训练阶段,我们从 DeepSeekR1 系列模型中蒸馏推理能力,同时谨慎地在模型精度与生成结果长度之间保持平衡。”
值得注意的是,在训练阶段,DeepSeek 使用了多项硬件及算法优化方法,包括 FP8 混合精度训练框架以及用于管线并行的 DualPipe 算法,旨在降低流程运行成本。据介绍,通过算法和工程上的创新,DeepSeek-V3 的生成吐字速度从 20 TPS 大幅提高至 60 TPS,相比 V2.5 模型实现了 3 倍的提升。
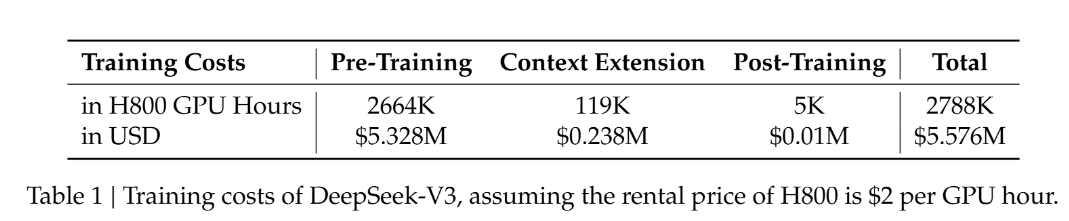
总体而言,该公司称,DeepSeek-V3 的全部训练任务在约 278.8 万个 H800 GPU 小时内就能完成。假设租赁价格为每 GPU 每小时租金为 2 美元,则约为 557 万美元,这比以往大语言模型动辄上亿美元的预训练成本明显要低得多。例如,Llama-3.1 模型的训练投入估计超过 5 亿美元。
曾是 OpenAI 创始成员之一的 AI 科学家 Andrej Karpathy 也被 DeepSeek-V3 的超低训练成本所震惊,“在资源限制下,它将是一个非常令人印象深刻的研究和工程展示。”他表示,这种级别的能力应该需要接近 16K GPU 的集群,而现在提出的集群更多的是 100K GPU 左右。这是否意味着前沿 LLM 不需要大型 GPU 集群?
“资源约束是一件美好的事情。在竞争激烈的 AI 竞争领域中,生存本能是取得突破的主要驱动力。”曾师从李飞飞教授、如今领导英伟达具身 AI 团队的高级研究科学家 Jim Fan 称。
此外,也有网友就 DeepSeek-V3 采用 H800 GPU 达到的低训练成本讨论到美国芯片出口管制的问题。Kaggle 大神、数据科学家 Bojan Tunguz 这样评价道,“所有对高端半导体的出口禁令实际上可能以可以想象的‘最糟糕’的方式适得其反。它们似乎迫使中国研究人员比原本更聪明、更节省资源。这似乎也证实了我自己的假设,即我们离拥有 AI 的 ML 部分的最佳算法还差得很远。”
效果和价格“吊打”一众模型
尽管训练成本低廉,但 DeepSeek-V3 仍一跃成为当前市面上最强的开源大模型。
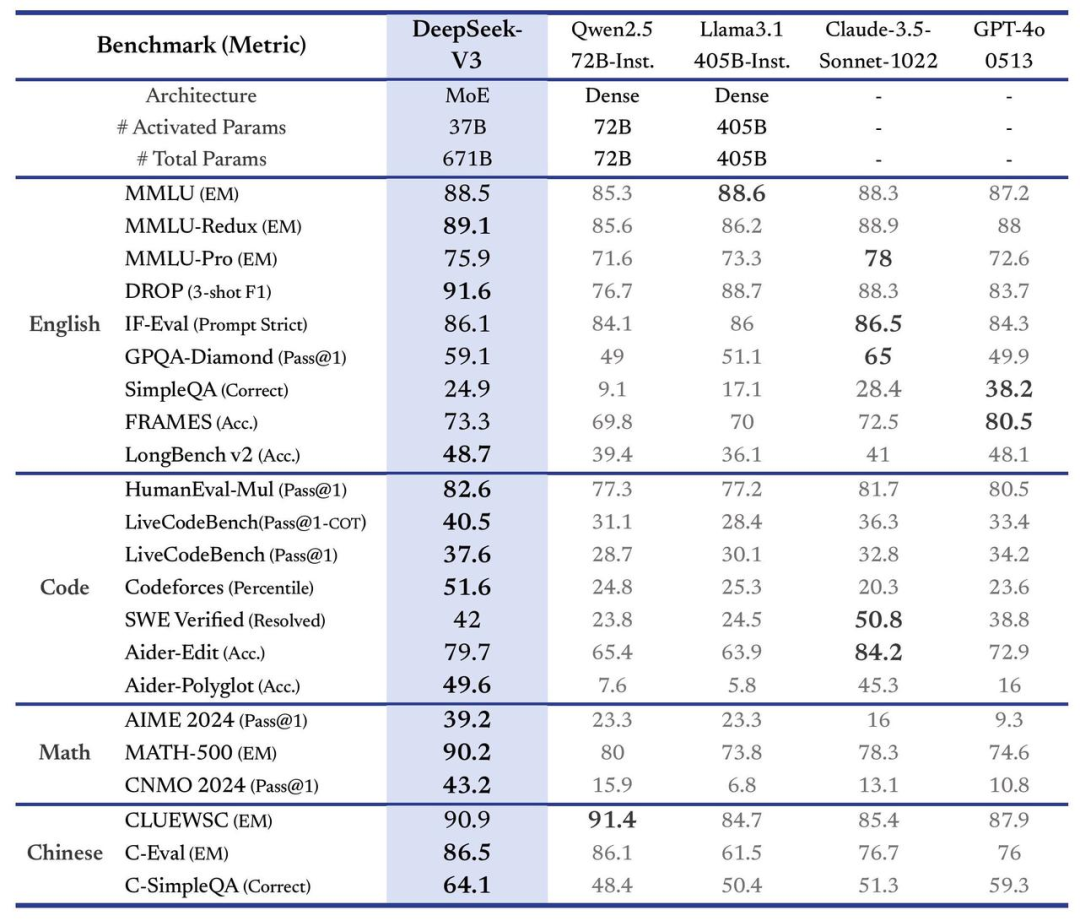
该公司运行了多项基准测试以比较其 AI 性能,并指出 DeepSeek-V3 以令人信服的表现优于其他领先开放模型,包括 Llama-3.1-405B 以及通义千问的 Qwen 2.5-72B,其甚至在大多数基准测试中都优于闭源 GPT-4o 模型,仅在以英语为中心的 SimpleQA 和 FRAMES 测试中稍逊一筹。OpenAI 模型分别得到 38.2 分和 80.5 分,而 DeepSeek-V3 则为 24.9 分和 73.3 分。
并且,DeepSeek-V3 的表现在以中文和数学为中心的基准测试中尤其突出,得分高于所有同类大模型。在 Math-500 测试中,其得分高达 90.2,远高于排名第二的 Qwen 的 80 分。目前,能够挑战 DeepSeek-V3 的模型可能只有 Anthropic 的 OpenAI 的 o1 和 Claude 3.5 Sonnet。
据悉,o1 在 GPQA Diamond(博士级科学问题)基准测试中获得了 76% 的分数,而 DeepSeek 则以 59.1% 的分数落后。o1 的完整版在多项基准测试中击败了 DeepSeek。Claude 3.5 Sonnet 在 MMLU-Pro、IF-Eval、GPQA-Diamond、SWE Verified 和 Aider-Edit 测试中以更高的分数超越了 DeepSeek-V3。
目前,DeepSeek 为 DeepSeek-V3 API 设定的价格与上一代 DeepSeek-V2 相同,即每百万输入 tokens 0.1 元(缓存命中)/ 1 元(缓存未命中)、每百万输出 tokens 2 元。但在明年 2 月 8 日之后,计费标准将调整为每百万输入 tokens 0.5 元(缓存命中)/ 2 元(缓存未命中),每百万输出 tokens 8 元。
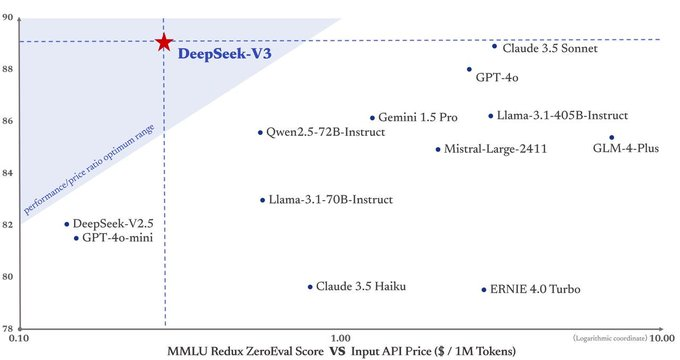
而 DeepSeek v3 的价格也获得了不少用户的好评。有中国网友称 DeepSeek v3 是“国产之光”,也有国外的网友认为 DeepSeek v3 的性价比“更上一层楼”,并表示,“人们不应低估 LLM 价格合理的重要性,这样它们才能真正为每个人所用,这些模型也才能被广泛接受。”还有网友说,“DeepSeek 根本不是盲目的和你打价格战,它是真的便宜。”
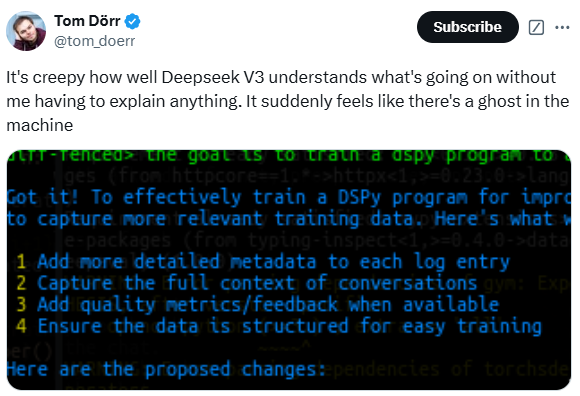
并且,第一波实测 DeepSeek v3 的用户都对其难以置信。一位用户表示,“Deepseek V3 在我不需要解释任何事情的情况下就理解了正在发生的事情。”
还有一位用户把此前一个抛给 O1 和 Gemini 2.0 但 O1 没答对的“史上最难的高考数学题”发给了 DeepSeek v3,该模型不仅可以回答这个问题,而且解决方案更简单。
参考链接:
https://analyticsindiamag.com/ai-news-updates/deepseek-v3-is-the-best-open-source-ai-model/




