
大数据已经成为当代经济增长的重要驱动力
数字经济,已经成为当今经济发展中非常重要的一部分。
与农业经济、工业经济如出一辙,数字经济活动需要土地、劳动力、资本、技术以及相应配套基础设施。不同之处在于:第一,很多要素都需要数字化;第二,会产生“数据”这一新的生产要素。
在数据要素市场化配置上升为国家政策的当下,大数据已经成为推动经济高质量发展的新动能。由于物联网,工业互联网和各种智能设备的广泛应用,智能化设备所产生的数据日益庞大。而要支撑如此体量和类型多样的数据采集,存储, 应用及市场化离不开大数据技术。
大数据技术仍然只有少数大型企业能掌握
时至今日,大数据概念不再晦涩,其技术已经发展了近 20 年。网络新闻,线上购物,互联网打车等场景都是大数据常见的应用。
然而在产业侧,企业对大数据的应用落地却不尽如人意。大数据技术栈的复杂性和落地成本让绝大部分中小企业望而生畏。
有不少盲目上马数据平台/数据中台项目的企业最后竹篮打水一场空,为什么企业应用大数据技术如此之难呢?让我们通过两个典型的数据平台案例来一探究竟。
案例 1:大数据营销系统
大数据营销系统常见于互联网行业,零售行业,金融行业。
核心是在平台采集大量用户行为信息后,对用户喜好打上一定标签,同时把同类型的广告或者产品分发到对应类别用户终端上,以提升整体销量或者广告点击率。构建这类大数据营销应用相当复杂。
典型的营销数据平台架构如下图所示。
其中分成离线和实时两套链路。离线链路负责大批量的数据计算,例如对历史存量的订单或者用户行为进行分析。实时链路负责对流式的数据进行快速的数据分析,例如用户的点击流,浏览行为等等。
这套架构涉及到的核心组件需要 6-10 个,周边组件多达数十个。数据的存储产生多份冗余,流转链路中的可靠性经常无法得到保证。由此,数据工程师经常耗费大量时间检查数据一致性。
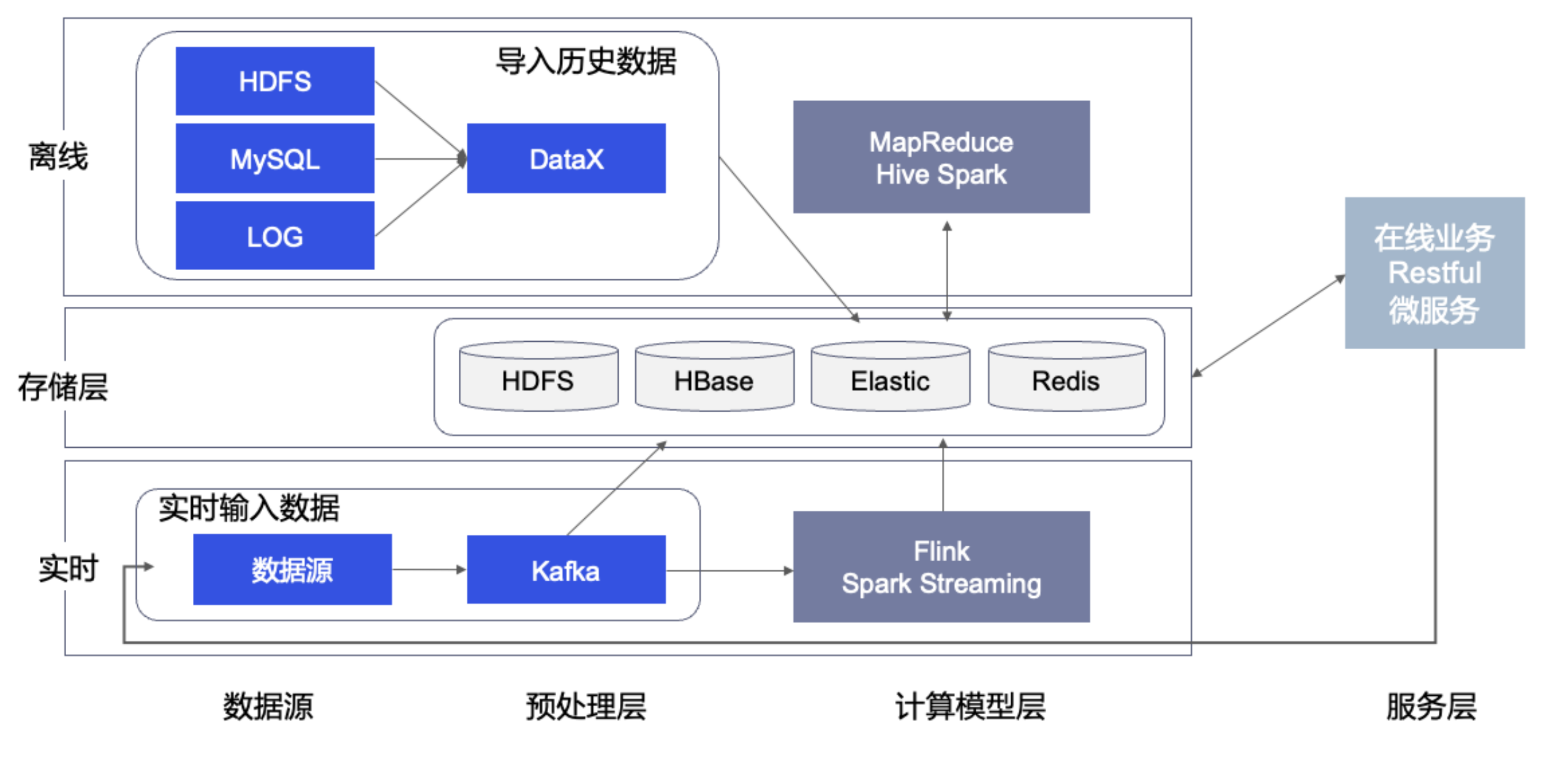
图典型营销大数据平台技术架构
做这样一个营销大数据平台,团队配置难度更甚架构构建,往往需要两个团队的 20 多位专业工程师来共同建设。
团队一负责数据基础,如果将大数据应用类比成餐厅,这就是建房子和装修厨房的团队。团队二负责数据应用,对餐厅来说,这就是做菜和上菜的团队。
如此,团队配置的成本必然是非常高昂。在腾讯、阿里这种顶级互联网公司中,内部冠有“数据平台”名字的团队就有数个,少的团队 10-20 人,多的团队高达数百人。
案例 2:智能制造数据中台
自“中国制造 2025”提出,数字化转型和实践走到今天,取得了非常多成果,也带来了很多新的挑战。
近年来由于政策的驱动和行业认知的进步,大量的智能制造项目开始上马。在“中台思想”的流行下,经常会同时上马一个数据中台子项目。打造智能制造数据中台,难度也是非常大的。
我们来看下图中展示的一个典型的制造业企业的整体 IT 系统架构和其中需要用到的数据库组件。

图制造业典型 IT 系统架构
在底层与生产设备打交道的是自动控制系统,为了采集高频的设备数据,制造业企业往往会用到如 PI 这样的专用实时数据库或者 InfluxDB 这样的时序数据库。
其次是制造执行的 MES 系统,MES 系统是将人员,物料,设备等进行有效协作和管理的系统。因此往往依赖于一个或多个关系型数据库,一般预算较高的用 Oracle,SQL Server,预算较低的用开源的 MySQL,PostgreSQL。
再上层是企业的 ERP 系统,其中会涉及更多维度的数据,包括供应链,销售,库存,财务等等。而这个也依赖于强大的关系型数据库,根据预算从 SAP Hana,Oracle 到 MySQL 都很常见。
最上层就是各种所谓的 BI 智能化应用,包括各类指标报表的监控,各类产量,质量,耗能等分析应用,甚至一些机器学习预测算法应用。
要实现一整套智能制造的数据中台就需要将上述多层的 IT 系统进行打通,将其中多个业务数据库的数据汇聚上来,同时建立多条 ETL 管道将相关的数据进行集成和处理,同时选用不同的数据库组件进行高性能或者海量分析应用。下图是一个典型的智能制造数据中台架构。
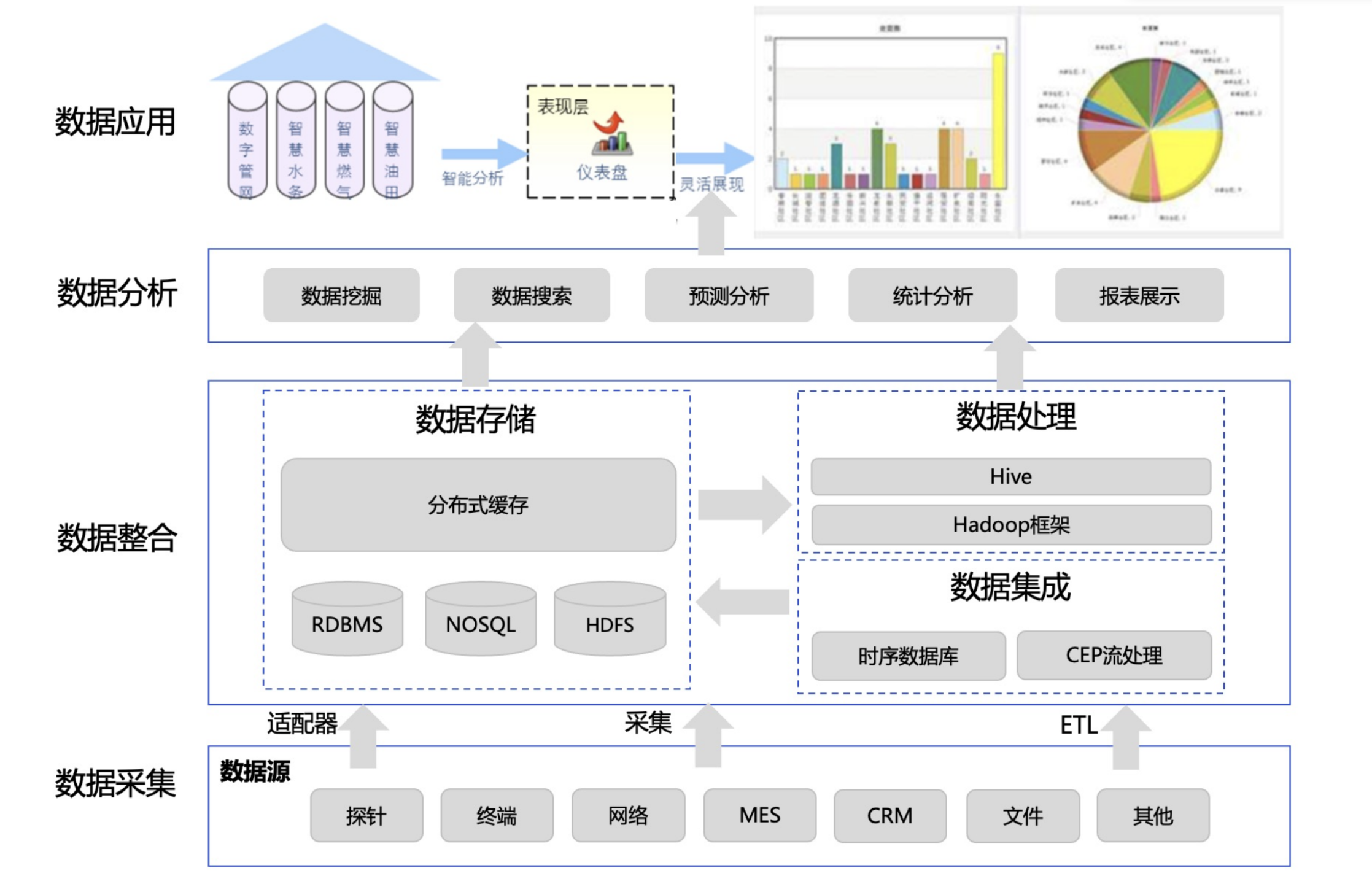
图智能制造数据中台架构
建设这样一套数据中台实际上与之前营销大数据的案例类似,组件繁多与数据流转的问题同样也存在,而且在另外几个方面甚至会更有挑战。
第一,制造业的某些应用往往有非常强的实时性要求,因为产线每停一段时间就会有很大的经济损失,因此可能某个查询或者分析必须在很短的时间里出结果。
第二,制造业中设备所产生的数据类型非常丰富,其中只有少量数据是结构化的,还有数据是文本,二进制图片等非结构化数据。
第三,制造业往往对 IT 预算卡的很严,通常无法给予比较高的服务器采购预算,建设团队必须在很有限的底层硬件资源中实现既定的功能。
第四,制造业并不具备如互联网一样充分的 IT 人员供给,在互联网行业中应用相同技术和架构的技术人才获取门槛更加难以克服。
这一切都注定了在制造业中应用大数据技术是一个挑战度更高的课题,只有极少数头部企业能将大数据应用到一定程度。而广大的中小制造型企业就更加无法享受到大数据技术带来的收益。
大数据系统的普遍痛点
通过以上两个行业大数据应用案例,我们可以看到,当前的大数据技术架构普遍有如下 3 类痛点:
1、 昂贵
公司建设一个大数据平台最少需要一支十人以上的有经验的数据平台与应用的工程师团队。而这样的工程师本身在行业里都是稀缺资源,大多集中在互联网和科技行业,传统行业即使花大价钱也很难吸引这类团队。
2、复杂
平均一个公司建设一个大数据平台需要引入至少 5 个数据组件。大量组件是开源项目,并没有完整的商业支持,企业需要自己花力气去调研和学习这些组件。而且每种数据组件都有自己的 API 接口、语言和事务模型,都要各自安装、监控、补丁和升级。工程师需要花大量时间维护这套架构。企业的内部人员也并非一成不变,复杂的技术栈让平台的运行状态对人员变化更加敏感。
3、低效
企业建设大数据平台的目的还是为了更好的挖掘数据价值,对业务进行赋能。过于复杂的大数据架构将导致建设周期过长,很多企业管理层开始寄希望于大数据快速能让业务增长,但发现光搭建技术架构和梳理数据就需要半年甚至更长的时间,很快就失去耐心砍掉项目。此外,过去底层架构的复杂,让基于大数据平台的业务应用很难快速迭代。
这些痛点,都导致了当前的大数据技术架构是只有少数大型企业才能“用的起,玩的转”的“高级定制时装”,离行业的普适依然道阻且长。
大数据技术的发展历程
大数据技术的应用现状如此复杂,我们不禁要追问,大数据技术是如何逐步发展至今的?以史为鉴,也许我们能找着规律与解法。
自从计算机诞生以来,就有了数据应用。最早是纸带、卡片等物理介质,后来发展出了文件系统,但是这些手段都无法满足数据的增长,以及多用户共享数据和快速检索数据的需求。数据库应运而生。
最早的数据库所使用的典型数据模型主要有层次数据模型和网状数据模型,它们可以解决一定的数据存储和管理问题,但是在数据独立性和和抽象级别上仍有较大的欠缺。1970 年,IBM 的研究员 Edgar F.Codd 发表了几篇关于关系数据模型的论文,奠定了关系型数据库的基础。
随着几个经典的关系型数据库产品 Ingres(后来演变成 Postgres), Oracle, DB2 的诞生,关系型数据库成为了整个数据管理行业的主流。传统关系型数据库始终维持了非常简洁的架构,它划分了业务处理和数据处理的边界,业务逻辑由业务代码实现,数据处理逻辑由数据库实现,两者之间使用标准 SQL。
而 2000 年以来,随着大型互联网公司的崛起,传统关系型数据库的水平扩展能力不足,无法满足海量数据的处理要求。为解决这个矛盾,在最初的关系型数据库基础上,发展出大数据技术体系以满足高性能查询、可扩展性、海量数据处理等需求。
企业在实际场景使用时,构建数据平台要同时用到几种技术栈的组合。比如下图这张常见的大数据平台架构图。
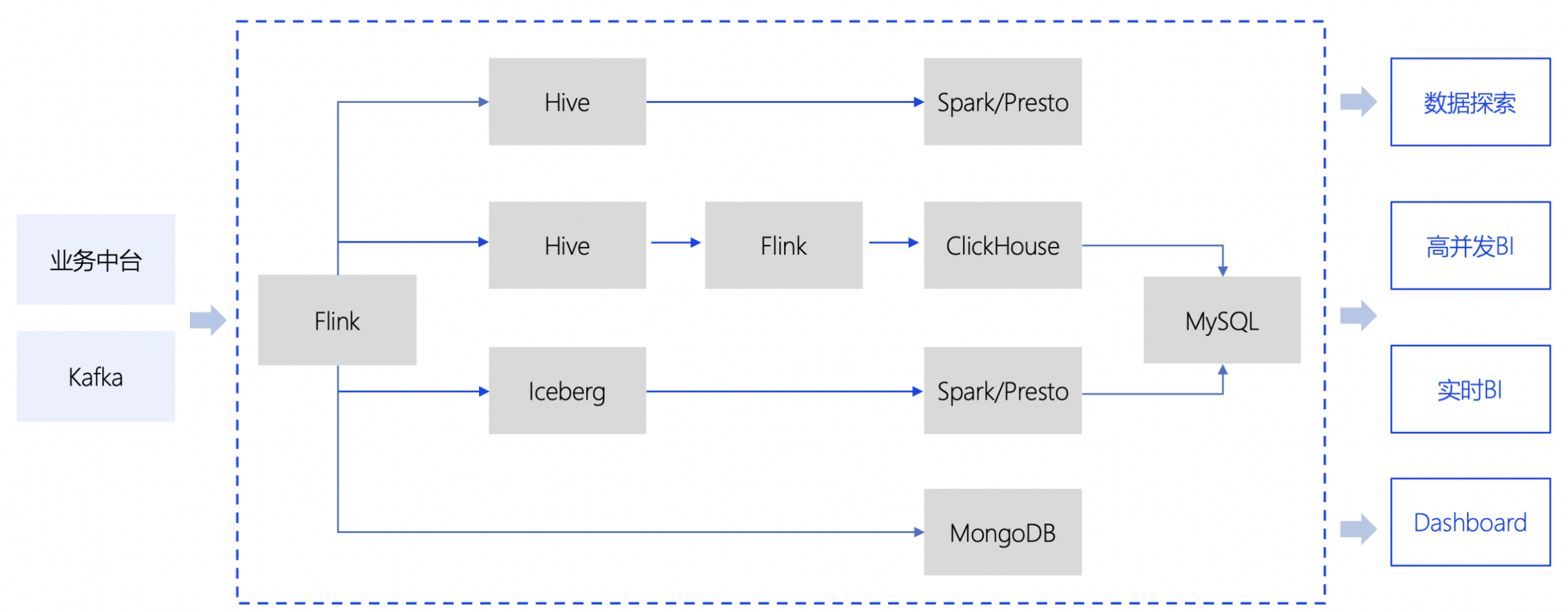
图当前常见大数据平台架构图
面对如此复杂的系统,促使我们思考。最初的关系型数据库系统里仅仅通过 SQL 就隔离和解耦了数据处理和业务模块。简洁、令人怀念。
今天,为了解决数据处理的问题,业务人员不得不直面数据处理的问题,不断从大数据社区里引入一个又一个开源组件,通过一些“胶水”代码,将它们组合起来,才能完成数据处理任务。这样的开发体系和复杂的技术栈,对于业务开发人员要求很高,而企业需要维护这些系统所付出的各种成本也非常高。
超融合数据库是实现大数据技术普惠的必然选择
纵观大数据的发展历史,我们可以看到,之所以大数据技术只能被少数大型企业所玩转,本质原因在于大数据技术本身的复杂性。
那破局之道在何处呢?答案还是在大数据技术本身。我们回到数据库诞生的初衷:解决数据和业务的隔离问题,将数据处理的归数据库,将业务处理的归应用。
重新把数据处理和业务处理解耦开,才能让大数据技术变得像当年互联网上风靡的 LAMP(Linux+Apache+MySQL+PHP)一样简单而普惠。
而要做到这一点,目前有三条技术路线:
第一条技术路线,在众多大数据组件的基础上,根据需要处理业务的特点,抽象一层通用的接口。把复杂的数据处理封装在通用接口之下,业务人员只使用通用接口来解决业务问题。可以一定程度缓解前面提到的各种问题,但是由于底层使用的还是现在大数据体系下的组件,难以高效整合,且一旦业务发生变化,之前的抽象就可能发生变化。因此大部分项目在系统可靠性、兼容性和可维护性以及数据冗余度、一致性和实时性等方面,无法令人满意。
第二条技术路线是在数据库层面提供整合,即传统的多模数据库。通过在多种数据库组件的上面,封装一层,提供统一对外的 SQL 接口,让开发者使用起来像用一个数据库一样,从而大幅简化系统设计复杂度。查询时如果需要多模查询,就是把查询打到几个数据库组件上进行联邦查询。这个方案风格,比较类似于分布式 OLTP 数据库里面的分库分表中间件的方案。由于背后的多个数据库组件在日志、事务、一致性和高可用等实现方式并不相同,导致这种强行“缝合”的多模数据库并不好用。
第三条技术路线是提供融合型数据库产品。业内在这个方向上已经取得了一些进展,许多产品已经出现了能力互相融合的情况。2014 年,Gartner 提出了 HTAP 的概念,以 Greenplum,TiDB 和 Oceanbase 为代表的数据库系统都具备 HTAP 能力:同时支持交易和分析型操作的支持,在确保事务能力的同时提供实时的数据分析能力。2021 年的 DTCC 大会上,更有国内的数据库厂商提出了超融合时序数据库的概念:融合了传统的关系型数据库、时序数据库和分析型数据库为一体。由此可见,数据库产品不断走向融合的历史趋势已经形成。
也正是在第三条技术路线的指引下,成立于 2021 年的矩阵起源公司致力于打造 MatrixOne 超融合异构云原生数据库,为开发者、商业和组织打造极简的大数据建设工具。在思考了当前大数据体系的问题和未来数据处理技术的发展趋势之后,我们认为新一代的超融合数据库应该具备以下的能力:
用户交互方式上,能够支持标准的 SQL 操作
支持业务场景上,能够支持 TP、AP,也就是 HTAP 的能力
处理负载方式上,要能够同时支持流和批量两种计算,也就是流批一体的能力
支持数据类型上,要能够支持时序数据、时空数据和机器学习特征数据等多种负载,也就是多模的能力
除去确保高可用的数据副本,尽量避免在系统内引入冗余
可提供强一致的分布式事务;可根据业务规模,提供在线水平扩展支持海量数据存储
存算分离,存储节点、计算节点、元数据节点甚至调度节点全部解耦,都可以独立扩缩容
一套方案支持在公有云和私有化部署,公有云部署是云原生架构,支持云上的廉价共享存储和容器编排,且能做到公有云部署和私有化部署互联互通,真正做到云边协同,甚至云边一体。
如果用一句话来描述其能力的话,可以这样总结:流批一体,TP / AP 一体,云边一体。那么,有这样能力的超融合数据库系统,给我们带来的是什么?
用户无需为了解决海量数据分析,搭建如此复杂的一套大数据平台,从而极大简化了系统复杂度
单一系统,更加稳定,运维更加容易,技术人员的学习成本更低,用户体验更好
避免冗余存储,冗余传输,冗余处理,降低硬件投入成本
融合多功能数据库引擎,兼顾性能与功能
而之前给出的复杂大数据平台架构,就可以简化为:

图理想的数据平台架构图
数据库与大数据技术已经发展数十年,在技术上已经枝繁叶茂,但是随着数据规模的增大,用户处理数据的难度也越来越大。
我们相信超融合数据库的出现,将能有效的解决当前的这一矛盾。16 年前数据库领域的图灵奖获得者 Michael Stonebraker 提出了一套数据库系统无法适用所有数据处理场景的论断,也就是"One size doesn't fit all"。但是,在那篇文章的最后,Stonebraker 展望了未来数据库系统架构的几个演进方向,其中最后一个也是我们认同的方向:从头开始设计和实现一个可以适合多种场景的数据库系统。16 年后的今天,我们认为新一代超融合数据库可以做到 "One size doesn't fit all, but most"。
未来企业应用超融合数据库建设大数据平台会像使用关系型数据库一样简单,超融合数据库也是真正实现大数据技术普惠的必然选择。




