
在 FreeWheel 的核心业务系统中,我们使用 MySQL 来存储数据。但随着数据量的不断增加,原有数据库已经无法满足如今的业务需求。经过前期大量的调研,我们决定将 MySQL 中的部分表迁移到 AWS Dynamodb 中。本文主要介绍从关系型数据库平顺迁移到非关系型数据库的实践经验。
业务挑战
最初我们使用 asset 表来存储客户的视频库存信息,但是随着时间的推移,系统中的 asset 表体量越来越大。目前,asset 表以及相关附属表已经占用了全部数据库 50%以上的存储,服务中使用的表联查操作以及复杂 SQL 操作都会使数据库的性能骤降,从而导致应用服务性能变差。在此情况下,我们不得不开始考虑拆表或者数据库迁移,其中拆表的方法并不能长久地解决这个问题。同时为了提升性能以及扩展性、降低成本,我们最终选择将 asset 及其相关表迁移出 MySQL 数据库。
主流非关系型数据库对比及选型
由于我们的业务需求要求在高并发下的读写速度以及良好的可扩展性,并且不需要强一致性,所以我们最终决定使用非关系型数据库来存储 asset 以及相关数据。
在非关系型数据库中,我们选取了几种主流的数据库进行对比。这里列出其中应用较为广泛的 MongoDB 以及 DynamoDB 进行对比,如下表所示。
根据上述对比,基于 DynamoDB 有着更加完善的安全服务及灾备容错能力,并且与 FreeWheel 的 AWS 云服务相匹配,因此我们最终决定选用 DynamoDB 作为迁移的数据库对象。下面主要介绍下 DynamoDB 的技术特性。
DynamoDB 技术特性
AWS DynamoDB 是一种完全托管的无服务器(Serverless)类型的 NoSQL 数据库,可以通过 HTTP API 来使用。同时它提供了托管的内存缓存,比较适用于需要存储大量数据并且同时要求低延迟的应用服务。
DynamoDB 有几个关键概念,它是由表(tables)、数据项(items)和每项数据的属性(attributes)来构成的。 表是数据项的集合,不同类型的数据项都可以放到一张表里。下图展示了这些关键概念的构成关系。
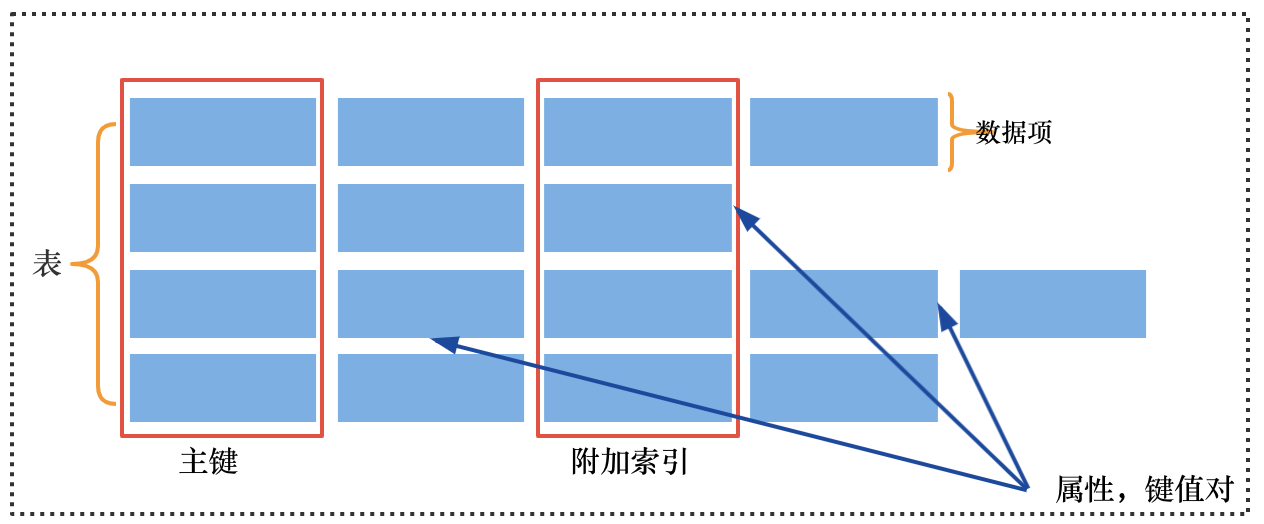
每条数据(item)在表里就是一条记录,包含了多个属性(Attributes)。在表里,每条数据由主键(Primary Key)唯一确定。每条数据类似于关系型数据库表中的某一行或者多行的集合。数据的属性组合成了每条数据,每条数据由多个数据属性构成。属性类似于关系型数据库表中的列。DynamoDB 要求每一项数据都至少包含构成该数据主键的属性。
表中的每项数据由主键唯一标识。在创建表的时候,必须定义由哪些属性构成主键。除了必要的主键以外,DynamoDB 还提供附加索引(Secondary Index)来满足不同的查询模式。比如我们经常会用到的 GSI(global secondary index),使用不同的属性来构成索引达到更高效的查询。
迁移方案设计
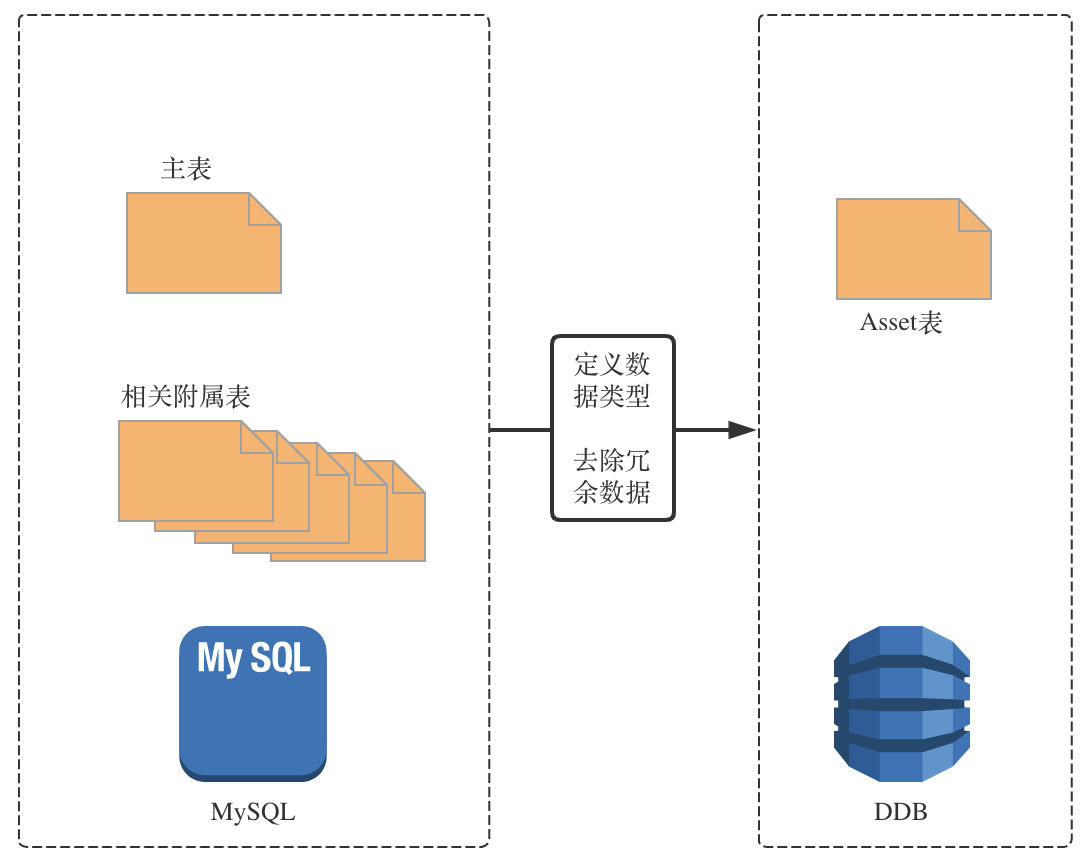
从关系型数据库转变到非关系型数据库,我们需要重新定义新的数据模型。在设计新模型时,主要需要考虑的是新表中每项数据的属性以及迁移后的数据模型能否继续支持原有的业务需求。
与关系型数据库不同的是,DynamoDB 中的表类似于表的集合,经常会用来存储不同类型的数据,所以在结合 DynamoDB 的的特性以及原有的数据特点以及业务需求,我们将 MySQL 中的数十张表统一成了一张表,将之前不同表的不同 colomn 进行了重新整合,定义为新表中的属性,具体如下图所示。
在迁移每张表的过程中,首先我们将原来在 MySQL 中需要迁移的相关表的 SQL 语句都整理了出来,利用之前所设计的主键以及附加索引将这些 SQL 语句对应到 DynamoDB 中各个 API。下面以 asset 表中的一些字段为例。
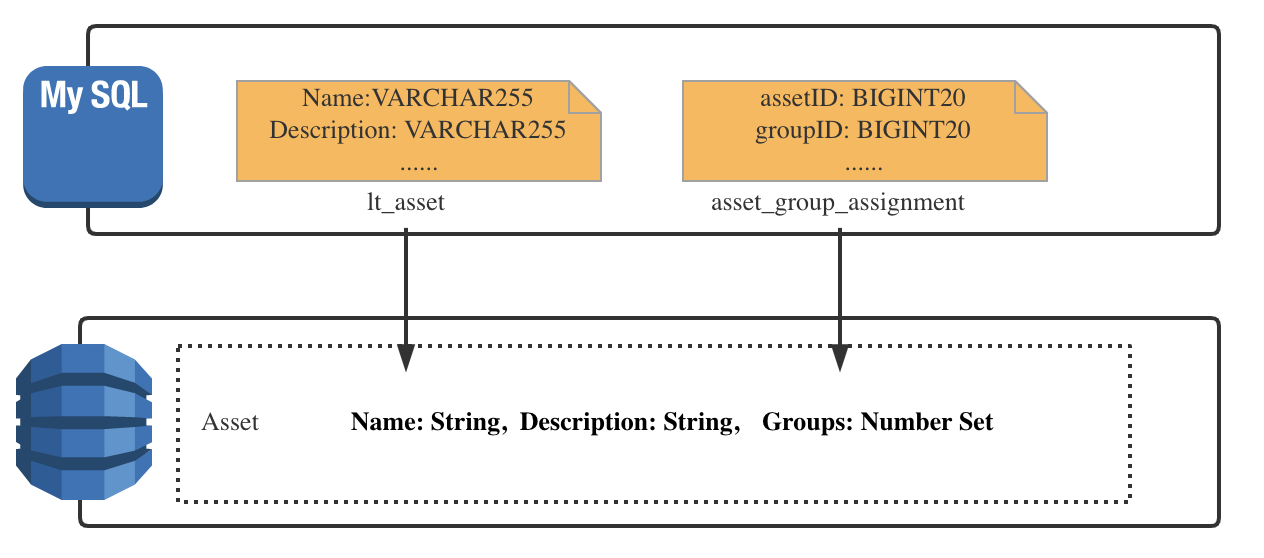
如上图所示,在 MySQL 中 asset 表有 name、description 等列,asset_group_assignment 表中有 assetId、groupId 等列。在迁移到 DynamoDB 后,这些列变成了每条 item 记录的属性值,同时从上图中也可以看到其数据存储类型的改变,例如原来 asset 表中 name 这一列存储的是 varchar 类型,groupid 与 assetid 都为 bigInt 类型,到 DynamoDB 中分别对应为 String 类型和 Number Set 类型。
在对新的数据表结构以及模型定义完成后,我们还需要定义其中各种属性的主键以及根据我们的业务需求来定义其中的附加索引。比如在 MySQL 中我们有这样的业务场景,select * from asset where xx_id = '123' ,如果 xx_id 不是主键的话,我们就需要将 xx_id 这一属性定义成为附加索引来满足我们的查询需求。
用户无感知平顺迁移的实现
在部署上线的过程中,为了确保数据库迁移过程的服务质量,并且让用户对此做到无感知,我们花了很大功夫将整个迁移过程分为大致三个步骤(如下图所示):
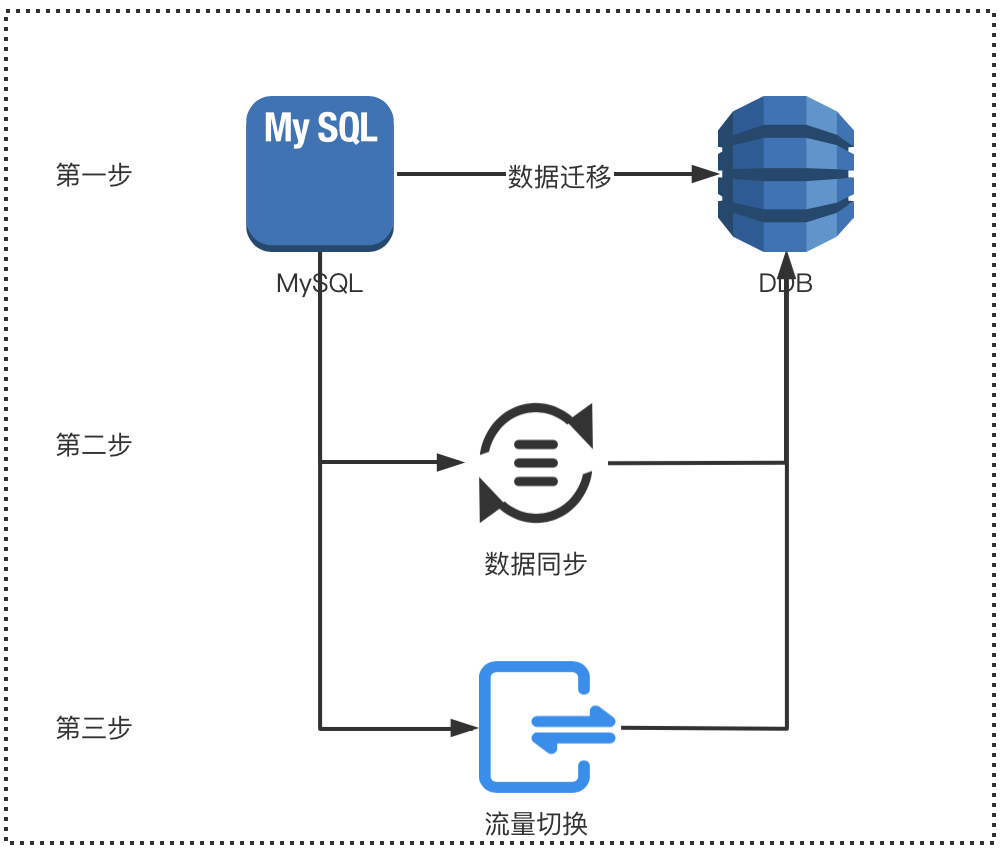
数据迁移:
首先先将 MySQL 中的数据进行迁移到 DynamoDB 中,这时所有的流量还读写原来的 MySQL;
数据同步:
接下来我们部署了一个后台 job 专门用于将 MySQL 的数据同步更新到 DynamoDB 中,这样两边的数据就保持了一致;
流量切换:
之后便可以让一些只读的应用服务来在 DynamoDB 与 MySQL 之间切换流量进行测试,从而验证数据迁移的正确性;最后就是一些读写的应用服务来进行流量的切换,我们通过程序中添加一个 runtime 的开关来实时的进行逐步的流量切换。
为了保证在迁移过程中做到不停服的效果,我们保留了所有传统 MySQL 的业务逻辑,程序中通过 runtime 的开关来判断当前系统是读写 MySQL 还是 DynamoDB。所有的上层服务都会支持这个逻辑从而判断开关的状态进而判定读写的数据源是 MySQL 还是 DynamoDB。而开发人员则可以通过实时更新开关的状态,从而在遇到问题的时候,及时在两个数据源 MySQL 与 DynamoDB 之间进行切换,从而避免用户问题的产生。
在流量切换过程中,分为三种状态:
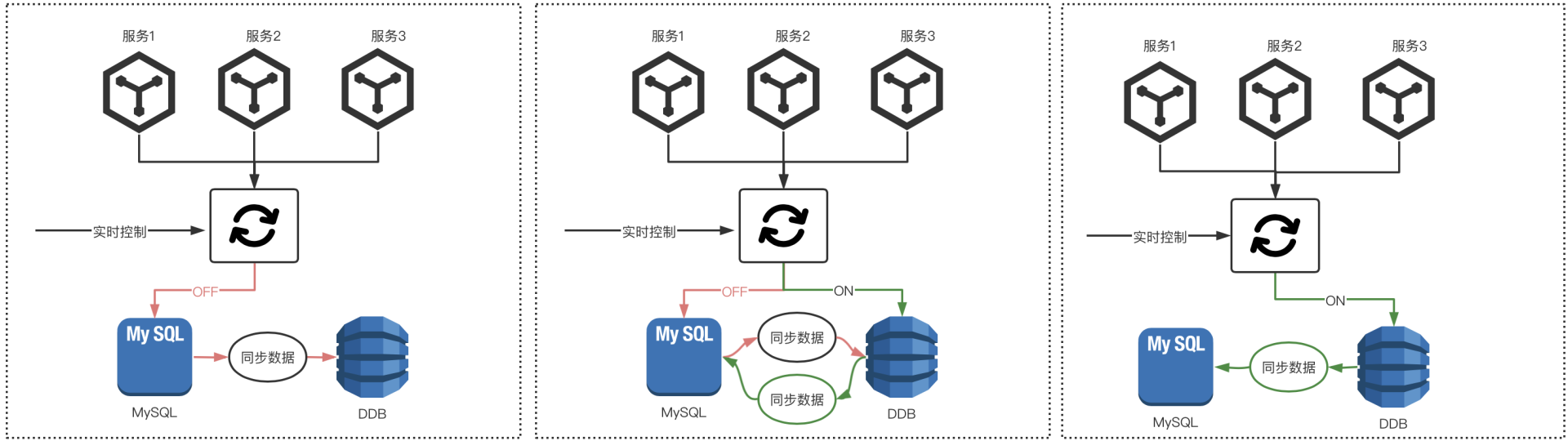
第一个状态是开始切流量之前此时所有服务的读写还在 MySQL 中,DynamoDB 可以看作为一个 back up 的数据库。在这个阶段中,我们将所有写入 MySQL 的数据同步到 DynamoDB 中。
接下来,我们将流量逐渐从 MySQL 中切换到 DynamoDB 中。如果是关闭开关的流量,所有应用服务还是会读写 MySQL,并将 MySQL 的数据同步到 DynamoDB 中。如果打开开关的流量,则所有应用服务都会读写 DynamoDB 并且将 DynamoDB 的数据同步回 MySQL,从而保证 MySQL 和 DynamoDB 中的数据是一致的,以应对出现问题后的迁移回滚操作。
最后,在迁移后并测试验证后,这时所有应用服务流量都切换到了 DynamoDB,此时 DynamoDB 的数据仍然会同步到 MySQL,这时 MySQL 就可以看作另一个 back up 数据库以备不时之需。至此,我们就完成了整个数据迁移工作。
迁移中遇到的问题及解决方案
关系型与非关系型数据库不论是在数据存储类型上还是对数据的操作上都存在着很大差别,这就导致我们在对数据库操作的接口实现上会有明显的不同。
下面主要列出我们在实践过程中所发现的由于两种数据库的特性的不同之处所带来的一些变化。
存储类型的变化
由于我们的核心业务系统使用的语言是 Golang,所以在从 MySQL 到 DynamoDB 的迁移实现过程中,由于数据存储类型的变化,微服务程序中需要重新按照 DynamoDB 中的数据类型重新定义数据结构。
NO SQL 的转变
在迁移的具体实现中,首先我们将原来在 MySQL 中需要迁移的相关表的 SQL 语句都整理了出来,利用之前所设计的主键以及附加索引将这些 SQL 语句对应到 DynamoDB 中各个 API。这个过程中我们发现 NoSQL 带来的性能提升还是很大的,比如原来在 MySQL 中一个更新需求涉及到多张表可能需要建立几个甚至更多的数据库链接,而在 DynamoDB 中只要一个数据库操作就能完成整条记录的更新。
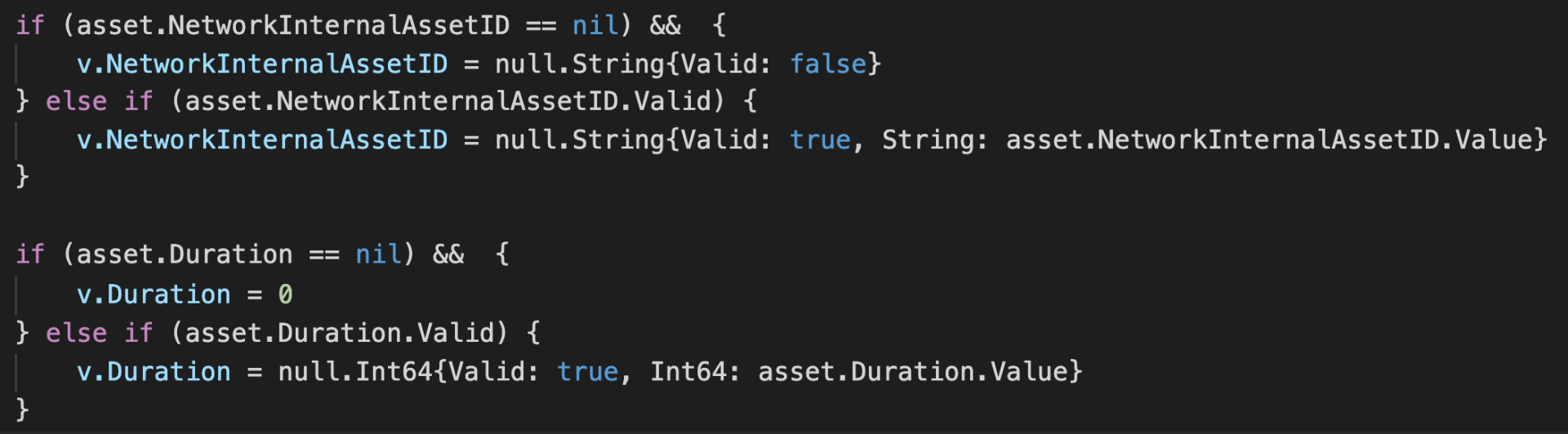
默认值的变化
在 MySQL 中是有默认值的,而在 DynamoDB 是没有默认值存在的,如果不传某种属性的写入,该条记录则没有对应属性。为了 MySQL 中所留下的默认值的业务需求,我们在 DynamoDB 的写入时也做了相应的处理,具体如下图所示。如果该属性的类型是 string 时, 当没有传入这种属性时,默认写入 Null 值,如果该属性的类型时 int,当没有传入改属性时默认写入 0。
大小写敏感的变化
在迁移前的业务系统的在查询过程中是大小写不敏感的(linux 系统下 MySQL 默认情况是大小写不敏感的),在迁移之后,DynamoDB 是默认大小写敏感的,因此为了仍然能够满足大小写不敏感这一业务需求,我们专门为需要大小写不敏感的属性改成了全部小写作为一个新的属性定义在存储结构中来满足需求。
自增 ID 的变化
DynamoDB 不支持自增 ID, 但是我们传统的业务需要支持,所以我们需要在业务层面加了一张表来实现自增 ID。
除了上述由于数据库特点不一致所带来的实现上的变化之外,我们在迁移的过程中也发现了一些由于 DynamoDB 的限制所引发的一些问题。
数据一致性问题
在并发测试的过程中,我们发现了这样一种现象。以下图为例,当有两个请求同时操作一条记录 asset1 时,我们预期的结果是 asset1 的 groups 在两个请求之后在原有的基础增加两个请求所添加的值,但实际上只添加了一个。
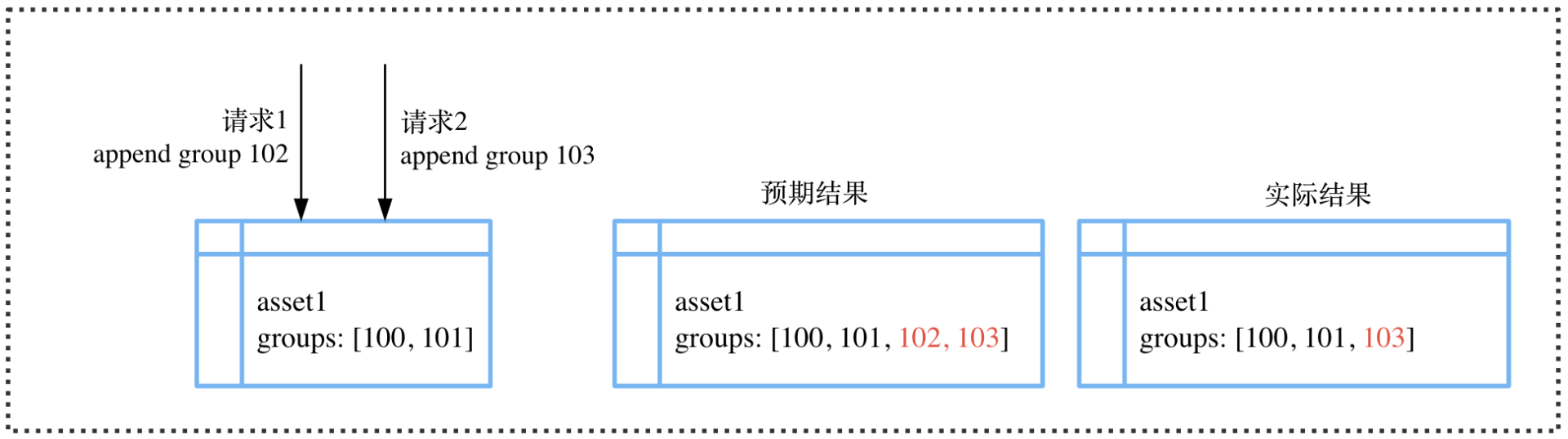
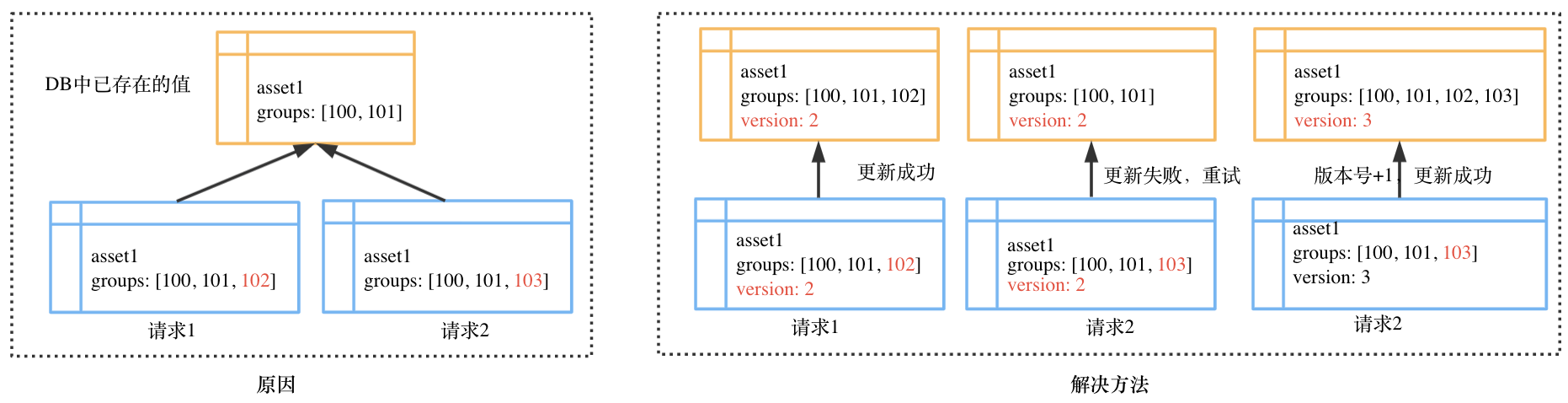
这个现象是由于请求 2 本该读到的记录应该是请求 1 更新之后的记录,但因为两个并发请求同时读到的都是更新之前的记录,所以最终更新成的值也就不是我们预期的值。说到底,其实就是想要达到强一致性读的效果,但实际上是最终一致性。因为 DynamoDB 使用的是最终一致性读取,虽然它也提供了一个 ConsistentRead 参数来支持强一致性读取,但是只有主键支持,全局二级索引是不支持强一致性读取的。所以我们在表中加了 version 这一属性来控制同时写入的顺序问题。
GSI delay 导致的问题
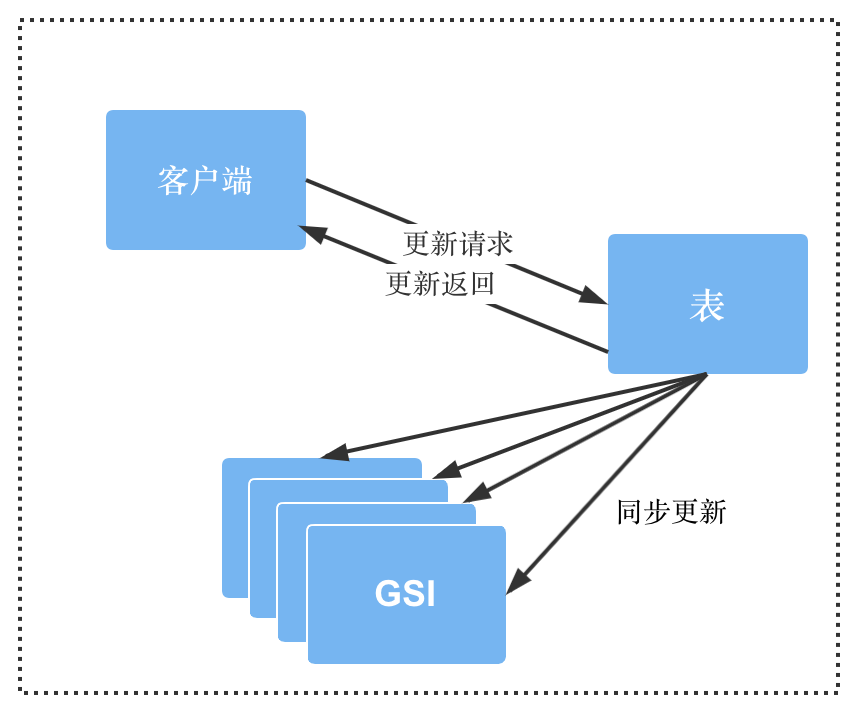
在开发完成后做压力测试时,我们发现调用创建新记录的接口总是会出现失败的情况。原因是当客户端发起创建新记录的请求后,服务端会先在主表中创建数据,然后会通过 GSI 拿到新创建的这条记录。在这种情况下,有万分之五的概率会拿不到新创建的数据,因为 DynamoDB 主表到其 GSI 的同步过程存在延时(如下图所示),AWS 官方给出的数据是豪秒级的延时。针对这一问题,我们在服务端增加了重试逻辑,如果没有拿到新创建的数据,最多会重试三次。
DynamoDB 数据大小的限制
在极限值的测试中我们发现,在更新一个 asset 的别名属性时,其属性的类型是数组,当其个数超过 1000 个的时候会发生更新失败的现象。通过查阅 DynamoDB 的官方文档,我们发现对于 DynamoDB 的每个属性的 value,DynamoDB 都是有大小限制的,占用内存不能超过 400KB。当然这只是在测试极限值时发现的问题,实际业务中并不会出现这样的情况,但为了以防出现问题,我们也在实际的业务中添加了验证的业务逻辑,并提前通知了客户这一变化。
DynamoDB 的事务问题
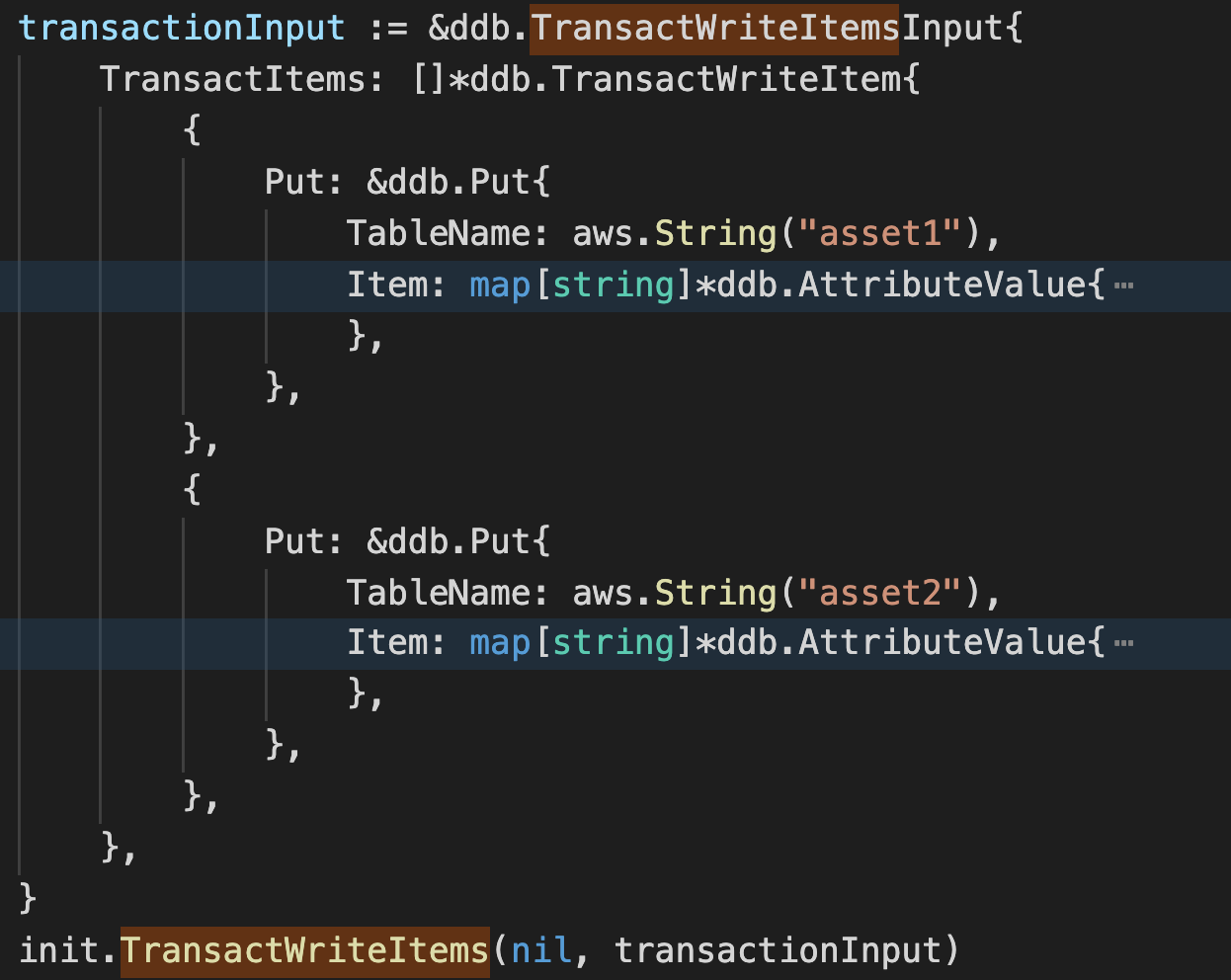
起初我们使用 DynamoDB 官方提供的 TransactWriteItems API 来处理多张表同时更新的事务问题,示例代码如下图所示。但在并发测试的过程中我们发现,如果同时操作非常多的记录的情况下,服务会报错。原因是目前 DynamoDB 的事务还不支持超过 25 个以上的 item 写入操作。所以当遇到要同时操作 25 个以上 item 的写入时,我们放弃了原生提供的事务方法,通过加悲观锁以及补偿的方式实现了此种业务需求。
DynamoDB 的 Cost 问题
在使用 DynamoDB 时一定要注意花销问题。如上表所示,DynamoDB 中每百万写入容量单位 WCU 花费 1.25$, 每 1KB 数据的写入会花费 1WCU, 如果是事务会加倍。每百万的读取容量单位 RCU 花费 0.25$,每 4KB 的读会花费 0.5 个 RCU,如果是强一致性读会加倍。所以在使用 DynamoDB 时,如果不是必须的操作,需要尽量避免使用强一致性读,并且通过尽可能将多次写操作合并为一次操作来减少写入的花销。
结语
通过团队的共同努力,我们在数个月的时间内完成了从 MySQL 到 DynamoDB 的数据存储迁移,也见证了迁移之后所带来的应用服务及数据库性能所带来的巨大提升,下图为迁移前和迁移后的同一接口的请求时间对比,可以看到迁移前 Duration 平均为 90ms,而迁移后的 Duration 降为平均 50ms,降低了近 50%。

在完成迁移后,我们也不断发现一些问题,例如跨数据库的 transaction 处理以及对 DynamoDB 的数据进行复杂查询等等,未来我们也会针对这些问题继续探索解决办法并不断改进。
作者介绍:
岳京典,毕业于北京邮电大学,目前就职于 FreeWheel 核心业务团队。致力于 Golang 系统开发、微服务架构等,热衷于新技术的分享与探索。




