
统计数据
在深入介绍 Netflix 的架构之前,我们首先看一些重要的统计数据,它们是系统设计的基础:
Netflix 应用程序每天有大约 4000 亿个事件;
在高峰期,每秒要处理大约 800 万个事件和 17GB 数据;
有超过 2 亿名订阅用户;
订阅用户分布在全球 200 多个国家;
支持 2000+设备;
每位用户平均每天观看 5 个视频;
视频平均大小为 500 MB;
平均每天从后台上传 1000 个视频;
每天上传所需的存储空间为:1000 * 500 MB = 500 GB(大概)
5 年内所需的总存储空间为:500 GB * 5 * 365 = 912.5 TB
在 Netflix 上线一个视频
Netflix 从制作公司获得高质量的视频和内容。然而,Netflix 支持 2000 多种设备,每种设备都需要不同的分辨率和格式。
对于同一部电影,Netflix 要准备多种不同的视频,而且还要为每一种视频准备多个拥有不同分辨率的副本,然后根据用户的网速和设备确定向他们提供何种视频质量的视频。为了实现这一目标,Netflix 将原始视频切分成不同的小块,并使用 AWS 提供的并行工作者进程将它们转换成不同的格式(如 mp4、3gp 等)和不同的分辨率(如 4k、1080p 等)。这个过程称为转码。
经过转码之后,同一部电影就有了多个文件副本。它们会被传输到世界各地不同地方的每一台 Open Connect 服务器上。
云服务
Open Connect —— Open Connect 或 Netflix CDN 是一个分布在不同地理位置的分布式服务器网络。同一电影文件的不同副本会被传输到每个 Open Connect 服务器上。Open Connect 主要负责 Netflix 的视频流。当你点击播放按钮,Netflix 会从距离你最近的 Open Connect 服务器把视频提供给你,从而提供更快、更好的体验。此外,这还增加了整个系统的可扩展性。这些服务器被称为 Open Connect Appliances(OCA)。
注意:上面的 912.5 TB 并不包括存储这些副本的存储空间。
AWS —— 除了视频流,Netflix 几乎所有业务都使用 AWS。这包括在线存储、推荐引擎、视频转码、数据库和分析。
当用户点击播放按钮时,Netflix 会分析网速或连接稳定性,然后找出离用户最近、最合适的 Open Connect 服务器。Netflix 会根据设备和屏幕的大小将正确的视频格式以流的方式传输到用户的设备中。
Netflix 的后端架构
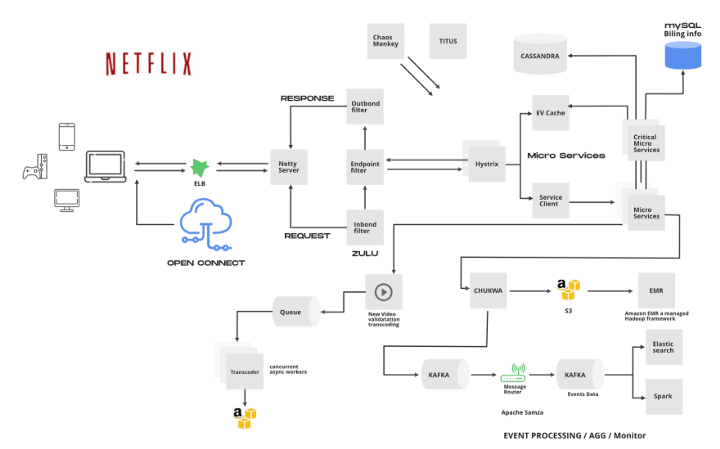
除了视频流之外,Netflix 的所有业务都由其后端服务处理,包括上线新内容、处理视频、将视频分发到位于世界各地的服务器,以及管理网络流量。
来自客户的请求被发送到 AWS Elastic 负载均衡器,后者是一个 2 层架构:
1.第 1 层:来自 ELB 的请求会首先到达这一层。该层负责基于 DNS 的轮询调度在不同的区域之间平衡负载。
2.第 2 层:该层包含一组负载均衡实例。这些实例在同一区域内的多个实例之间通过轮循方式实现负载均衡。
ELB 将此请求转发到 API 网关。Netflix 使用运行在 AWS EC2 实例上的 ZUUL 作为 API 网关。ZUUL 是由 Netflix 开发的一个库,主要用途包括:动态路由、监控和安全。ZUUL 根据查询参数、URL 和路径进行路由。
Netflix 基于一系列服务构建。使用服务集合构建应用程序的方式被称为微服务架构。在这种架构中,服务之间相互独立。
从设备和网站发起的所有请求都要经过 ZUUL 才能到达 Netflix 流媒体应用程序的后端。ZUUL 根据用户请求将其路由到特定的服务。例如,如果用户试图登录,则将请求发送到身份验证服务。
Netflix 架构具有复杂的分布式结构。这种结构有很多优点,也存在一些依赖关系。例如,一台服务器可能要依赖于另一台服务器的输出才能工作。这些服务器之间的依赖关系可能会导致延迟,如果其中一台服务器停止工作,还可能导致单点故障。
对于上述问题,Netflix 使用了 Hystrix。Hystrix 是 Netflix 开发的一个功能非常强大的库,它能使微服务之间彼此隔离,从而将失败数降至最低。Hystrix 是通过隔离服务之间的访问点来实现的。Hystrix 的用途包括:快速失败和快速恢复、准实时监视、预警和操作控制,减少通过第三方客户端库访问(通常通过网络)依赖项时可能产生的延迟和故障,避免复杂分布式系统中的级联故障。
用户活动和历史数据会被发送到流处理管道,用于后续的电影推荐。
这些数据还会被发送到 AWS、Hadoop、Cassandra 等大数据处理工具做进一步处理。
Netflix 使用的数据库
Netflix 使用了两种不同的数据库:
MySQL
Cassandra
MySQL
对于账单信息、用户信息和交易信息等数据,因为需要遵从 ACID,所以 Netflix 使用 MySQL 来存储。Netflix 的 MySQL 采用了主-主设置,部署在 Amazon 的大型 EC2 实例上。
在主-主设置中,主主节点的写入会被复制到另一个主节点。只有当主主节点和远程主节点的写操作都确认后,才会发送写入确认信息。这确保了数据的高可用性。
Netflix 为每个节点(本地和跨区域)设置了读副本,确保了高可用性和可扩展性。
Cassandra
Netflix 使用 Cassandra 是因为它的可扩展性、无单点故障和跨区域部署。总之,一个全局 Cassandra 集群就可以既为应用程序提供服务,又跨多个地理位置异步复制数据。
Netflix 的 Cassandra 数据模型:
50+ Cassandra 集群
500+ 节点
日备份数据量 30TB
单节点每秒写入次数 250k
Kafka 和 Apache Chukwa 在 Netflix 的应用
如上所述,Netflix 基于一系列微服务构建,这些微服务共同为用户提供许多服务。
通常,在微服务架构中,一定的失败率是可以接受的。不过,有些失败可能会导致更大的问题。任何一个微服务调用的失败都可能导致大量计算不同步,并可能导致数据差个几百万美元。那还会导致可用性问题和盲点,让你无法有效地追踪数据并回答用户关于什么导致了数据不匹配的问题。
上述问题的解决方案是重新考虑服务的交互方式,将一系列同步请求替换为异步事件交换。这样做有以下好处:
1. 我们的基础设施变成了天生异步的;
2. 我们的应用程序变成了松耦合的,错误的可追溯性得到改进。
Netflix 使用 Apache Kafka 来满足事件、消息和流处理需求。
Apache Kafka 以发布/订阅模型为基础。Netflix 的服务将它们的更改作为事件发布到消息总线上,然后由另一个对该消息感兴趣的服务消费,用于调整其自身的状态。
这使我们能够跟踪服务状态更改是否同步,如果不同步,那么它们需要多长时间才能完成同步。在管理大型服务依赖图时,这种洞察非常有用。
基于事件的通信和去中心化消费帮助我们克服了在大型同步调用图中经常看到的问题(如上所述)。
Apache Chukwa
Apache Chukwa 是一个开源的数据收集系统,可用于监控复杂的分布式系统。Chukwa 收集来自不同微服务的事件,并将其写入 Hadoop 文件序列格式。Chukwa 还为 Kafka 提供流量,以便将事件上传到不同的目标,如 S3、Elastic 搜索等。
ElasticSearch
Netflix 使用 Elastic 搜索来提供客户支持服务、数据可视化和错误检测。例如,如果用户不能播放视频,那么播放团队将使用 Elastic 搜索来查找问题的原因。它还用于跟踪资源使用情况及检测注册或登录问题。




