
全球网络安全领导厂商 Palo Alto Networks 每天处理 TB 级的网络安全事件。他们每秒分析、关联和响应数百万个事件——使用了许多不同的 Schema,有许多不同类型的事件,这些事件是由许多不同的传感器和数据源上报的。他们面临的一个挑战是如何知道哪些事件实际上是从不同角度描述了同一个网络“故事”。
一般来说,要做到这一点,既需要一个数据库来存储事件,也需要一个消息队列来通知数据使用者有新事件进入系统。但是,为了降低在他们的系统中部署另一个有状态组件的成本和运营开销,Palo Alto Networks 的工程团队决定采用一种不同的方法。
本文探讨了 Palo Alto Networks 为什么以及如何完全移除了一个项目(负责实时关联事件)的消息队列层。Palo Alto Networks 决定不使用 Kafka,而是使用他们的低延迟分布式数据库 ScyllaDB 作为事件数据存储和消息队列,从而消除对 Kafka 的依赖。本文以 Palo Alto Networks 首席软件工程师 Daniel Belenky 最近在 ScyllaDB 峰会上分享的内容为基础。
Palo Alto Networks 在 2022 年 ScyllaDB 峰会上贡献的内容可以随时观看(https://www.scylladb.com/presentations/stream-processing-with-scylladb-no-message-queue-involved/)。读者也可以在这里(https://www.scylladb.com/scylla-summit-2022/presentations/)观看 2022 年 ScyllaDB 峰会的其他视频和幻灯片。
背景:事件无处不在
Belenky 的团队开发了初始数据管道,用于接收来自其他数据源的数据,并清理数据、处理数据、为系统其他部分的进一步分析做好准备。他们的首要任务之一是建立准确的故事。Belenky 解释说:“我们从多个不同的数据源接收多种事件。这些数据源有可能从不同的网络点描述了相同的网络会话。我们需要知道多个事件——比如一个来自防火墙的事件、一个来自端点的事件、一个来自云供应商的事件——是否从不同的角度讲述了同一个故事。”他们的最终目标是为所有相关的事件及其关键细节生成一个核心增强事件。
例如,假设路由器的传感器生成了一条消息(这里是两次 DNS 查询)。然后,一秒钟后,一个定制系统发送了一条消息,表明有一人执行了登录操作,另一个人执行了注册操作。8 分钟后,第 3 个传感器又发送了另一个事件:一些 HTTP 日志。这些在不同时间到达的事件实际上可能描述了相同的会话和相同的网络活动。
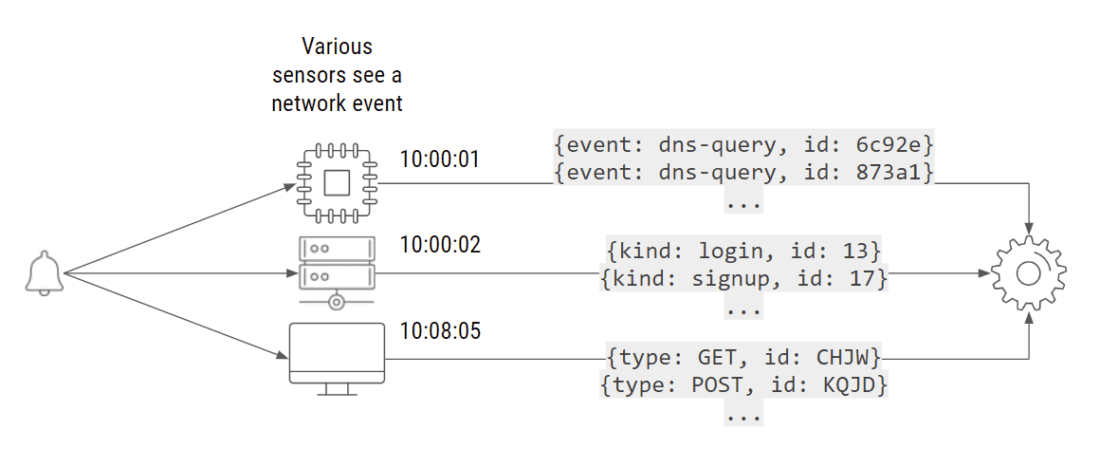
不同的事件可能以不同的方式描述了相同的网络活动
系统在不同的时间接收到不同设备上报的数据,并将其规范化为系统其他部分可以处理的规范形式。但有一个问题:这导致程序了数百万个规范但不相关的事件。这些离散的事件中有大量的数据,但当前还不清楚网络上到底发生了什么以及哪些事件值得关注。
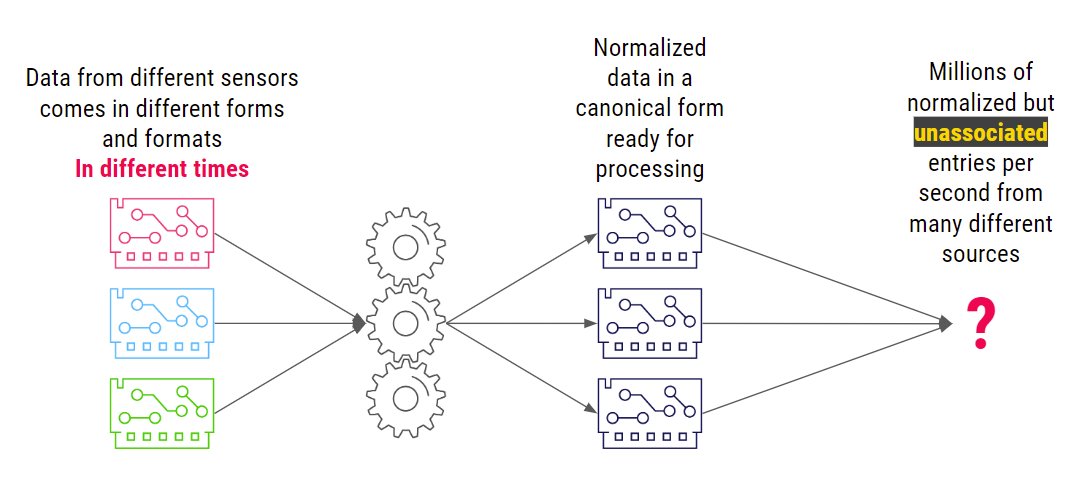
Palo Alto Networks 需要一种将不相关的事件分组为有意义的网络活动故事的方法
从事件到故事的演变
为什么将描述相同网络会话的离散事件关联起来如此困难?
不同传感器之间的时钟倾斜:传感器可能位于不同的数据中心、计算机和网络之间,因此它们的时钟可能无法同步到毫秒级别。
需要管理数以千计的部署:因为业务的需要,Palo Alto Networks 为每一个客户提供了单独的部署。这意味着他们的解决方案必须针对各种情况进行优化,从每秒处理字节级别的小型部署到每秒处理 GB 级别的大型部署。
不同传感器的会话视角:不同的传感器可以代表同一会话的不同视角。一个传感器的消息可能上报了从 A 点到 B 点的交易,而另一个可能从相反的方向上报同一交易。
对数据丢失零容忍:对于网络安全解决方案,数据丢失可能意味着有未被检测到的威胁,这不是 Palo Alto Networks 能够接受的。
连续无序的数据流:传感器在不同的时间发送数据,事件时间(发生事件的时间)不一定与摄取时间(事件发送到系统的时间)或处理时间(开始处理事件的时间)相同。
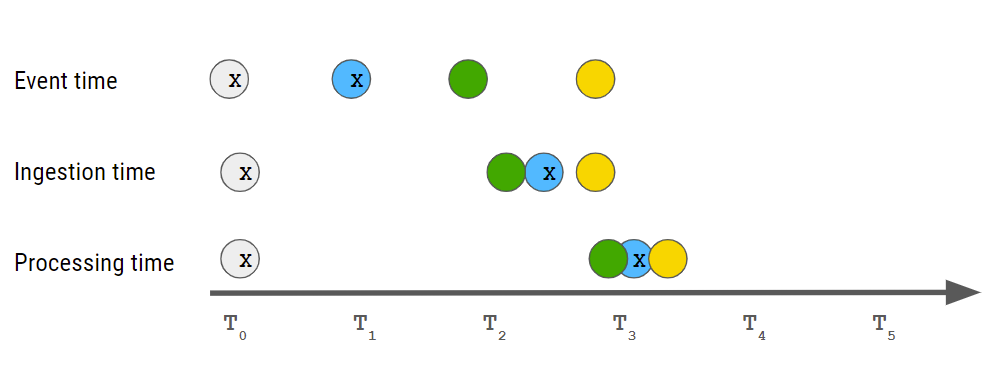
灰色事件与一个故事有关,蓝色事件与另一个故事有关。虽然灰色事件是按顺序接收的,但蓝色事件不是
从应用程序的角度来看,需要做些什么才能将数以百万计的离散事件转换成清晰的故事,从而帮助 Palo Alto Networks 保护他们的客户?从技术角度来看,系统需要:
接收事件流;
等待一段时间,让相关事件都到达;
决定哪些事件是相互关联的;
发布结果。
此外,还有两个关键的业务需求需要解决。Belenky 解释说:“我们需要为每个客户提供单租户部署,以提供完全的隔离。我们需要以合理的成本支持从每小时 KB 级别到每秒 GB 级别的部署。”
Belenky 和他的团队实现并评估了 4 种不同的架构方案来应对这一挑战:
关系型数据库;
NoSQL+消息队列;
NoSQL+云托管消息队列;
NoSQL。
让我们来逐个看一看每种实现。
方案 1:关系型数据库
使用关系数据库是最直接的解决方案,也是最容易实现的。规范化的数据直接存储在关系数据库中,一些定期任务执行复杂的查询,确定哪些事件属于同一个故事,然后发布结果,让系统的其他部分可以根据需要作出响应。
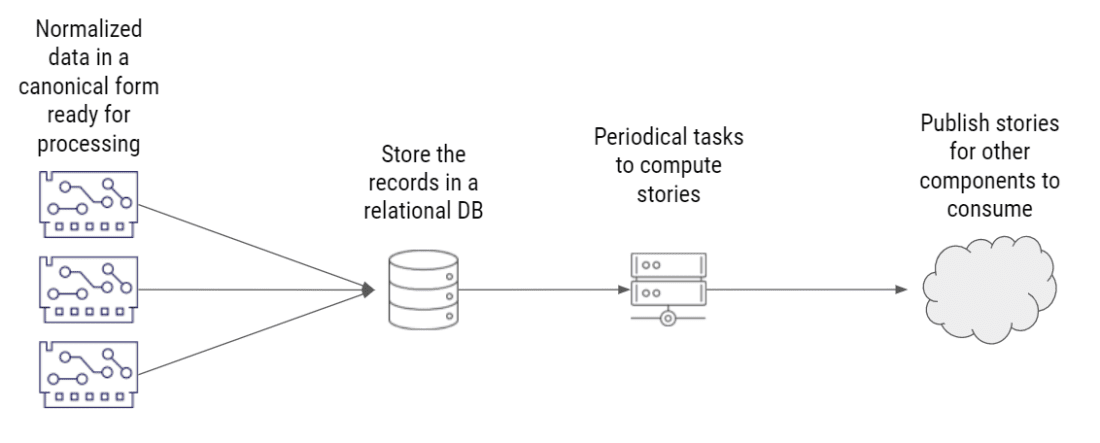
方案 1:关系型数据库
优点
实现相对简单。Palo Alto Networks 部署了一个数据库,编写了一些查询,但不需要为相关故事实现复杂的逻辑。
缺点
由于这种方法要求他们在其生态系统中部署和维护一个新的关系型数据库,因此会造成相当大的运营开销。随着时间的推移,成本还会继续增加。
性能有限,因为关系型数据库查询比 ScyllaDB 等低延迟 NoSQL 数据库的查询要慢。
它们会带来更高的运营成本,因为复杂的查询需要更多的 CPU,因此成本更高。
方案 2:NoSQL+消息队列
接下来,他们实现了另一个解决方案,将 ScyllaDB 作为 NoSQL 数据存储,将 Kafka 作为消息队列。与第一个解决方案一样,规范化的数据存储在数据库中——但这次是 NoSQL 数据库而不是关系型数据库。与此同时,他们还发布了后续用于从数据库获取事件记录的键。每一行记录表示一个来自不同来源的事件。
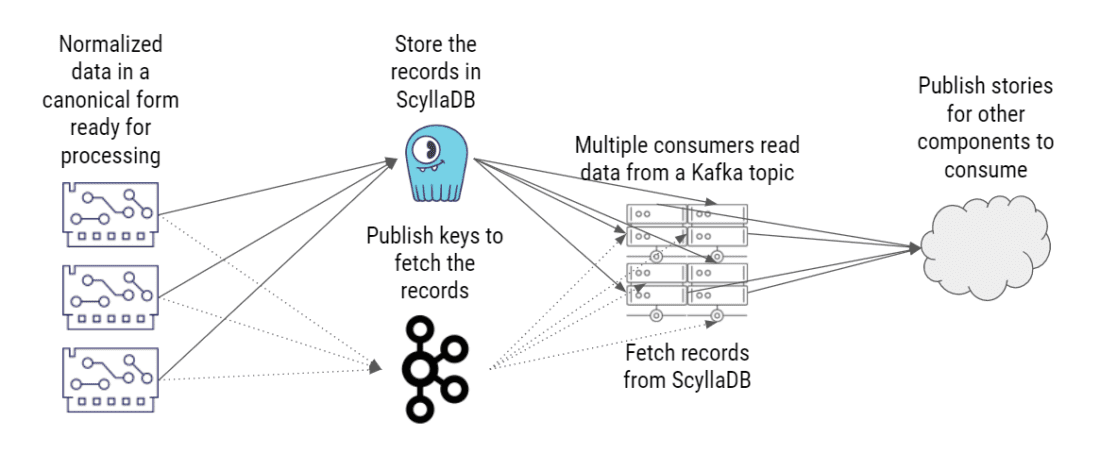
方案 2:NoSQL+消息队列
多个消费者从 Kafka 主题读取数据。同样,这些数据只包含键——刚好足够让数据使用者从数据库中获取这些记录对应的数据。然后,数据使用者从数据库中获得实际的记录数据,通过确定这些事件之间的关系来构建故事,并发布故事,让其他系统组件可以使用它们。
为什么不直接在 Kafka 上存储和发布这些记录?Belenky 解释说:“问题是这些记录可能很大,有几兆字节大小。出于性能方面的考虑,我们无法把它们存储在 Kafka 中。为了满足我们的性能预期,Kafka 必须重度使用内存,但我们没有太多的内存可以给它。”
优点
与执行批处理查询的关系型数据库相比,吞吐量更高;
少维护一个数据库(ScyllaDB 已经在 Palo Alto Networks 广泛使用)。
缺点
需要实现复杂的逻辑来识别相关性和构建故事;
复杂的架构和部署,数据被并发送到 Kafka 和数据库;
为每一个客户提供一个隔离的部署意味着要维护数千个 Kafka 部署。即使最小的客户也需要两到三个 Kafka 实例。
方案 3:NoSQL+云托管消息队列
这个方案与前一个基本相同,唯一的例外是他们用云托管队列取代了 Kafka。
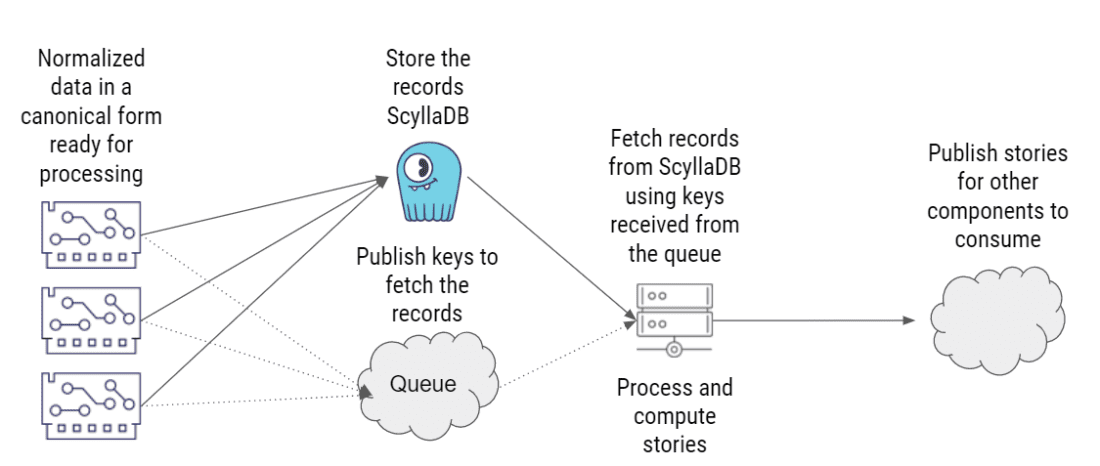
方案 3:NoSQL+云托管消息队列
优点
与执行批处理查询的关系型数据库相比,吞吐量更高;
少维护一个数据库(ScyllaDB 已经在 Palo Alto Networks 广泛使用);
不需要维护 Kafka 部署。
缺点
需要实现复杂的逻辑来识别相关性和构建故事;
与 Kafka 相比,性能要慢得多。
他们很快就放弃了这个方案,因为它在两个方面表现得很糟糕:糟糕的性能和高度的复杂性。
方案 4:NoSQL(ScyllaDB)
最终,最适合他们的解决方案是不带消息队列的 ScyllaDB。
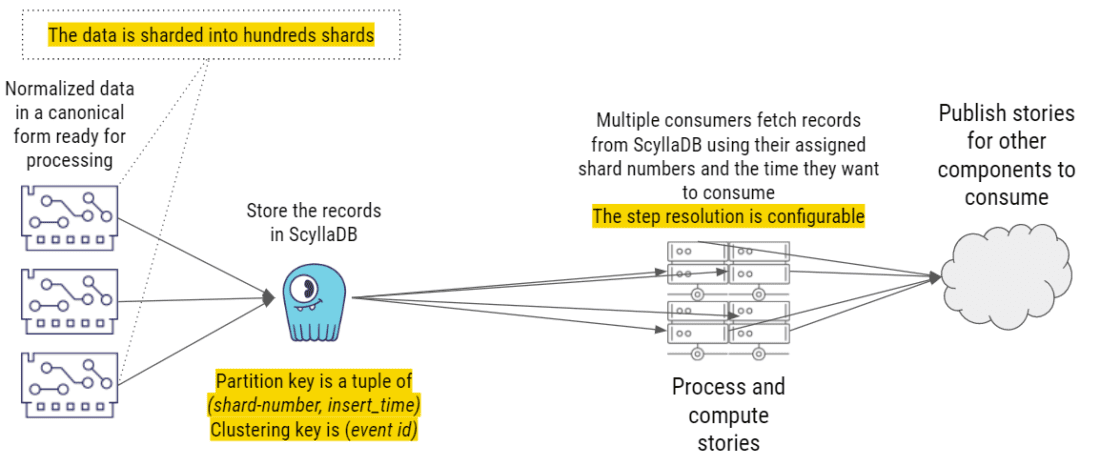
方案 4:NoSQL(ScyllaDB)
与前面的所有解决方案一样,它从规范化数据开始,将数据分割成数百个分片。这些记录只被保存到一个地方:ScyllaDB。分区键就是分片序号,不同的 Worker 节点可以并行处理不同的分片。insert_time 是具有一定精度的时间戳——最多精确到秒。event_id 是数据键,用于稍后获取特定的事件。
Belenky 解释说:“我们有多个数据使用者从 ScyllaDB 获取记录。它们通过查询告诉 ScyllaDB:‘给我这个分区、这个分片的所有数据,以及给定的时间戳。’ScyllaDB 将所有记录返回给它们,它们计算出故事,然后将故事发布给系统的其他部分或其他组件使用。”
优点
由于他们已经部署了很多 ScyllaDB,所以不需要向他们的生态系统添加任何新技术;
与关系型数据库相比,吞吐量更高;
性能与 Kafka 解决方案相当;
不需要添加或维护 Kafka 部署。
缺点
代码变得更加复杂;
生产者和消费者必须有同步的时钟(达到一定的精度)。
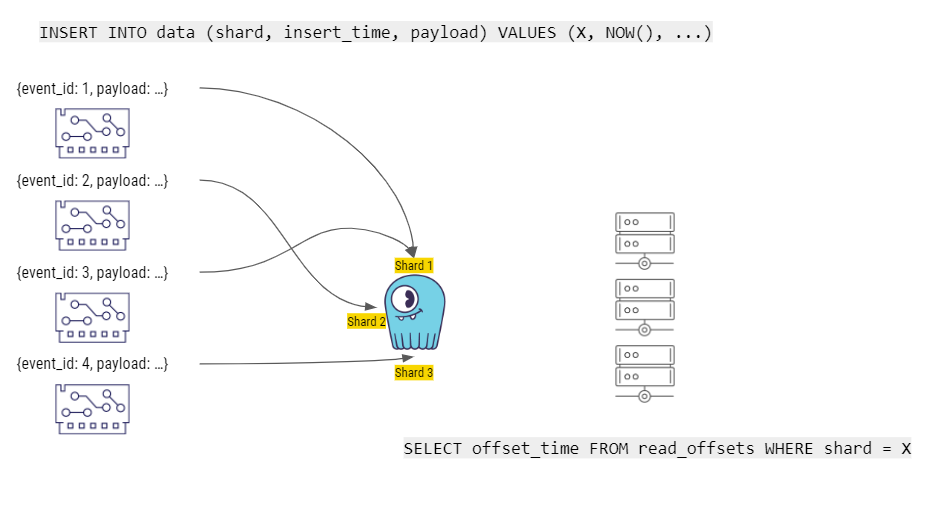
最后,让我们来更深入地了解这个解决方案的工作原理。下图的右侧显示了 Palo Alto Networks 内部构建故事的“Worker”组件。当 Worker 组件启动时,它们会查询 ScyllaDB。数据库里有一张特殊的表,叫作 read_offset,它是每一个 Worker 组件存储其最后一个偏移量(读取数据时的最后一个时间戳)的地方。然后,ScyllaDB 返回每一个分片的最后一个状态。例如,分片 1 的 read_offset 是 1000,分片 2 和分片 3 有不同的偏移量。
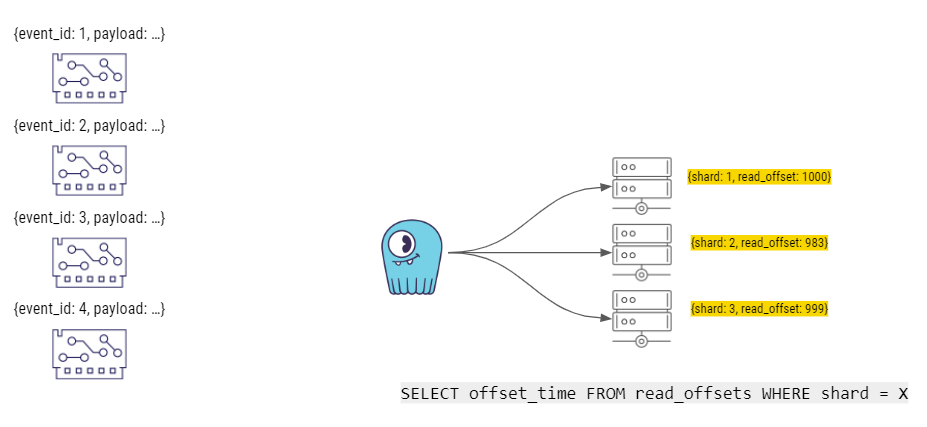
然后,事件生产者运行语句,将数据(包括 event_id 和实际的有效负荷)插入到 ScyllaDB 的分片中。
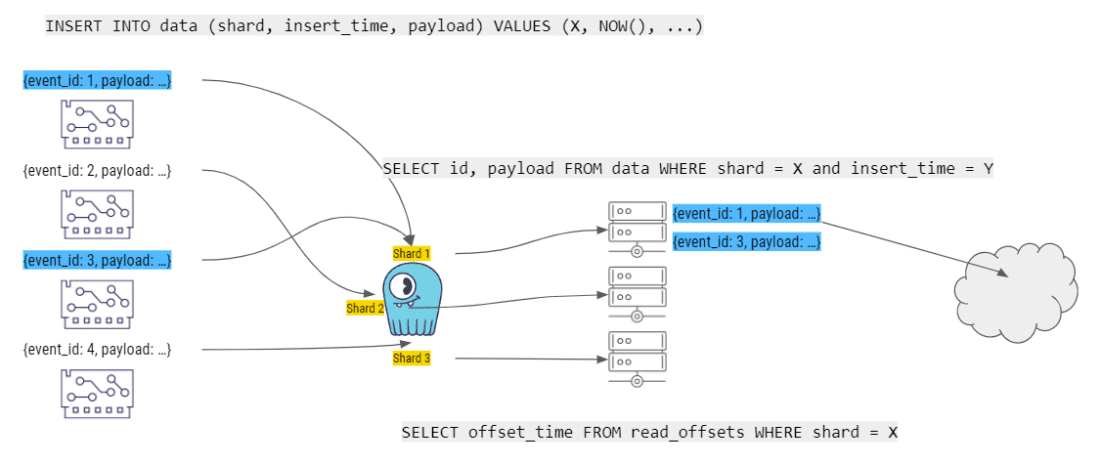
接下来,(持续运行的)Worker 从 ScyllaDB 获取数据,计算故事,并将故事提供给消费者。
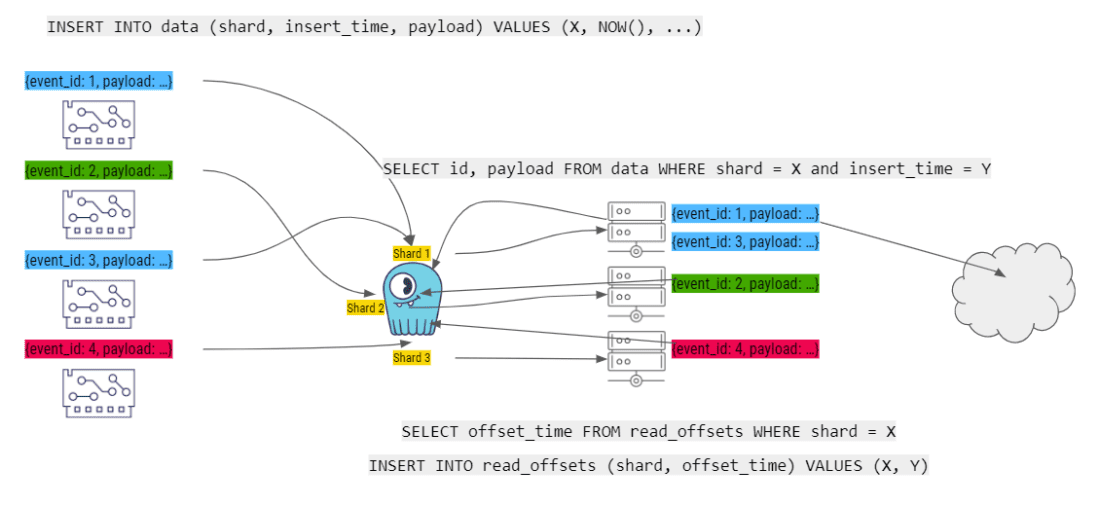
当每一个 Worker 完成一个故事的计算时,它将最后一个 read_offset 提交给 ScyllaDB。
当下一个事件到达时,它被添加到 ScyllaDB 分片中,并由 Worker 处理……然后循环继续。
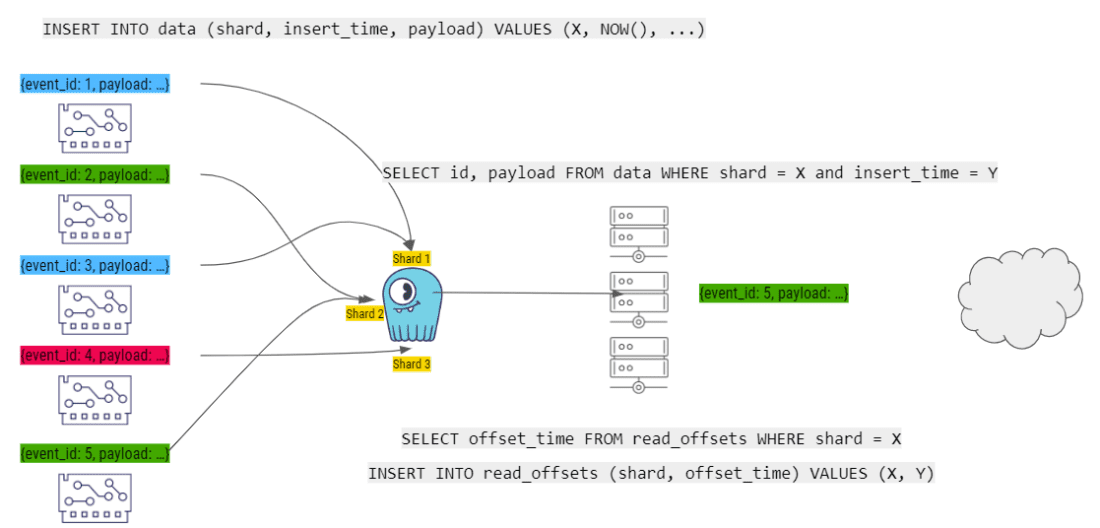
最终结果
最终的结果怎么样?Belenky 总结说:“实际上,我们已经能够大幅降低运营成本。我们降低了操作的复杂性,因为我们没有添加另一个系统——我们实际上还从我们的部署中删除了一个系统(Kafka)。我们提升了系统性能,从而降低了运营成本。”




