
本文最初发表于 Medium 博客,经原作者 Walid Saba 博士授权,InfoQ 中文站翻译并分享。
背景
基于三个技术(理论上的、科学上的)原因,由数据驱动 / 定量 / 统计 / 机器学习的方法(我统称为 BERT 学(BERTology)),是完全毫无希望的、徒劳的努力,至少在语言理解方面是如此。我明白,这是个很大的主张,特别是鉴于当前的趋势、媒体的误导性宣传,以及科技巨头们在这一完全有缺陷的范式上花费了巨额资金。正如我在自己的出版物、研讨会和帖子中所反复提到的那样,人们常常跟我说:“但是,所有那些人真的都错了吗?”好吧,现在我要统一地回答:“是的,他们确实可能都错了。”我是以伟大的数学家 / 逻辑学家波特兰·罗素(Bertrand Russell)的智慧说出这番话的。罗素曾经这样说过:
一个观点已被广泛持有的事实并不能证明它不是荒谬绝伦的。(The fact that an opinion has been widely held is no evidence whatsoever that it is not utterly absurd.)
然而,在开始之前,我们必须强调,我们的讨论是针对 BERT 学在 NLU(自然语言理解,Natural Language Understanding)的使用,这里的“U”(Understanding,理解)是至关重要的,也就是说,正如下面将要阐述的那样,BERT 学可能在某些自然语言处理任务中很有用(如文本摘要、搜索、关键短语提取、文本相似性和 / 或聚类等),因为这些任务都是以某种形式“压缩”的,而机器学习能够成功地应用于这些任务。但是,我们认为自然语言处理(本质上只是文本处理)和自然语言理解是截然不同的两个问题。或许就人类的思想理解而言,自然语言理解应该被人类思想理解(Human Thought Understanding,HuTU)所取代,因为自然语言理解涉及理解我们语言语句背后的思想(你可能也想阅读这篇讨论这一具体问题的短文《NLU 并非 NLP++》(NLU is not NLP++))。
因此,总结一下我们的介绍:我们在这里要辩护的主张是,BERT 学对自然语言理解来说是徒劳的(事实上,它是无关紧要的),而且这一主张并不涉及自然语言处理的某些任务,而只涉及到对特定于普通口语的真正理解,这种理解就像我们每天与甚至不认识的人、或者与没有任何领域特定知识的年幼儿童进行交谈时所做的那样!
现在,我们可以开始谈正事了。
MTP:文字缺失现象
让我们首先从描述一种现象开始,这种现象是自然语言理解中所有挑战的核心,我们称之为“文字缺失现象”(Missing Text Phenomenon。MTP)。
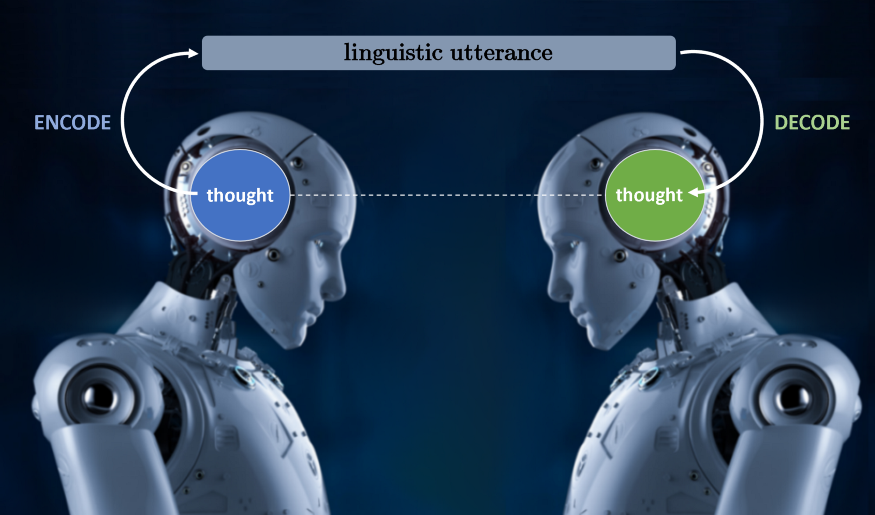
语言交流如上图所示:讲者将思想“编码”成某种语言的语句(使用某种语言),然后听者将这个语言“解码”成(希望)讲者想要传达的思想!这一过程就是自然语言理解中的“理解”,也就是说,理解语言语句背后的思想正是在解码过程中所发生的事情。而这些恰恰是自然语言理解困难的原因。让我来详述。
在这种复杂的交流中,有两种可能的优化或有效交流的方法:(i)讲者可以压缩(并最小化)在思想编码中发送的信息量,并希望听者在解码(解压缩)过程中做一些额外的工作;或者(ii)讲者将做艰苦的工作并发送所有需要的信息来传达思想,这将使听者几乎无事可做(有关此过程的完整描述,请参见此文《语言结构文化演变中的压缩与交流》(Compression and communication in the cultural evolution of linguistic structure)。这一过程的自然演变,似乎已经形成了适当的平衡,使讲者和听者的总工作量都得到了优化。这种优化导致讲者只需最少的可能信息进行编码,而忽略了可以安全地假定为听者可用的所有其他信息。我们往往忽略的信息通常是我们可以放心地认为讲者和听者都可用的信息,而这正是我们通常所说的共同背景知识的信息。
为了理解这一过程的复杂性,请考虑以下(未经优化)的交流:

显然,我们肯定不会这样交流。事实上,上述思想通常是这样表达的:
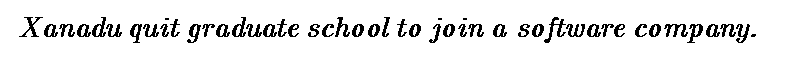
这条短得多的信息,也就是我们通常说话的方式,传达了与那条长信息相同的思想。因为我们都知道了,所以我们没有明确地陈述所有其他的东西。

也就是说,为了有效地交流,我们不能假定我们都知道的东西!正因为如此,我们都会倾向于忽略同样的信息——因为我们都知道每个人都知道什么,这就是“共同”背景知识。这种天才的优化过程,人类在大约 20 万年的进化过程中发展起来的,并且非常有效,而这恰恰是因为我们都知道我们所知道的一切。在人工智能 / 自然语言理解领域中,问题就出在这里。机器并不知道我们遗漏了什么,因为它们不知道我们所知道的一切。那最终结果是什么?自然语言理解是非常困难的,因为一个软件程序要想完全理解我们语言表达背后的意思,就必须能够以某种方式“发现”人们在语言交流中假定和忽略的一切。实际上,这是自然语言理解面临的挑战(而不是解析、词干分析、词性标注等等)。事实上,自然语言理解面临着一些众所周知的挑战——而这些问题在计算语言学中经常被提及。我在这里展示(只是其中的一部分)用红色高亮显示的缺失文字:

在自然语言理解中,所有上述众所周知的挑战都是源于这样一个事实:即挑战就是发现(或揭示)那些缺失的信息,并隐式地假定这些信息是共享的、共同的背景知识。
既然我们(希望如此)确信,由于文字缺失现象,自然语言理解是困难的,也就是说,因为我们日常话语中的普通口语被高度(如果不是最佳的话)压缩,因此在“理解”方面的挑战在于将缺失的文字进行解压缩(或揭示),我可以说出第一个技术原因:为什么 BERT 学与自然语言理解不相关。
(机器)可学习性(ML)和可压缩性(COMP)之间的等价性已经在数学上建立起来了。也就是说,已经确定了只有当数据是高度可压缩的(即数据有大量冗余)时,才能从数据集中实现可学习性,反之亦然(参见这篇文章《从压缩的角度谈统计学习》(On statistical learning via the lens of compression)和 2019 年发表在《自然》(Nature)杂志上的重要文章《可学习性不可判定》(Learnability can be Undecidable)),但是文字缺失现象告诉我们,自然语言理解是一个关于解压缩的问题。以下是我们所掌握的情况:

原因 1 证毕。
内涵(带有“s”)
内涵(Intension)是我要讨论的另一个现象,在我讨论第二个证据之前,即 BERT 学甚至与自然语言理解不相关。我将从所谓的内涵三角形说起,如下面的例子所示:
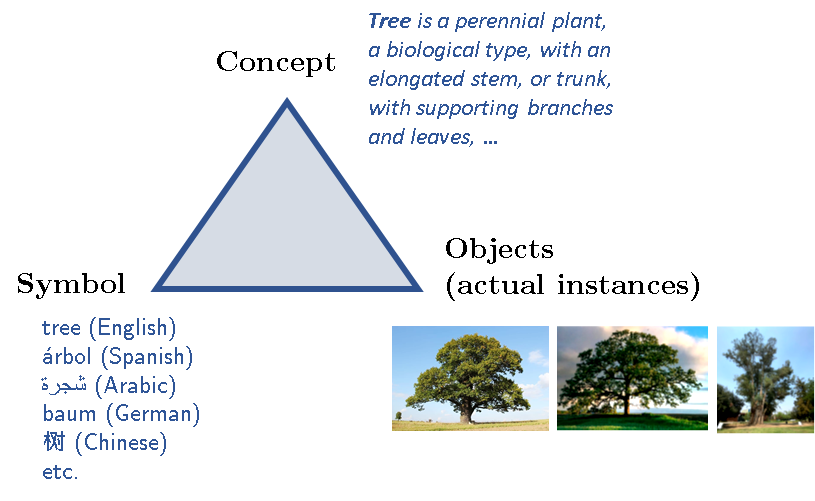
所以,每一个“事物”(或者说每一个认知对象)都有三个部分:一个指代某一概念的符号,而这个概念(有时)有实例。有时候我会说,因为“独角兽”这个概念并没有“实际的”例子,至少在我们生活的世界里是如此!这个概念本身就是它所有潜在实例的理想化模板(因此它接近柏拉图的理想化形式!)你可以想象,哲学家、逻辑学家和认知科学家如何在几个世纪以来一直在争论概念的本质及其定义方式。不管争议有多大,我们都可以达成一个共识:一个概念(通常由某个符号 / 标签所指代),是由一组属性定义的,或许还包括公理和既定事实等。然而,概念并不同于实际(不完美的)实例。这同样适用于完美的数学世界。因此,举例来说,虽然下面的算术表达式都有同样的扩展,但是它们的内涵却不相同:
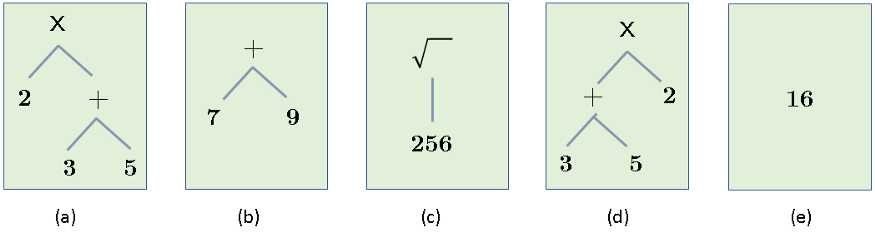
所以,虽然所有表达式的结果都为 16,因此在某种意义上是相等的(它们的 VALUE),但这只是它们的一个属性而已。事实上,上面的表达式还有其他一些属性,比如其句法结构(这就是为什么 (a) 和 (d) 不同),运算符的数量,操作数的数量等等。VALUE(只是一个属性)被称为扩展,而所有属性的集合就是内涵。而在应用科学(工程学、经济学等等)中,如果它们的 VALUE 相等,我们就可以放心地认为它们是相等的,但在认知(尤其是语言理解)中,这种相等就失效了。下面是一个简单的例子:
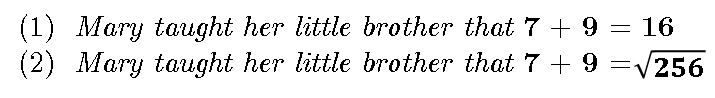
假定 (1) 为真,也就是说,假设 (1) 确实发生了,而且我们也亲眼目睹了这一事实。不过,这并不意味着我们就可以假设 (2) 为真。尽管我们所做的只是将 (1) 中的“16”替换为(假定)等于它的值。那么发生了什么事儿?我们用一个假定与之相等的对象替换了一个真实语句中的一个对象,然后我们从真实的对象中推断出了一些不真实的对象!事实是这样的:尽管在自然科学中,我们可以轻易地用一个等于它的属性来替换一个对象,但这在认知中却是行不通的!下面是另一个示例:

通过简单地将“the tutor of Alexander the Great”替换为阈值相等的值,即“Aristotle”,我们就得到了 (2),这显然是荒谬的。同样,虽然“the tutor of Alexander the Great”和“Aristotle”在某种意义上是等同的,但这两个思想对象在许多其他方面却是不同的。
我不再赘述对于什么是“内涵”,以及它在高级推理,尤其是在自然语言理解中的重要性。有兴趣的读者可以看看这篇短文《在自然语言理解中,忽视内涵,自负风险》(In NLU, you ignore intenSion at your peril),我在这篇文章曾引用过其他参考资料。
那么,从这场关于“内涵”的讨论中,有哪些观点呢?在自然语言中,内涵现象是非常普遍的,这是因为语言所传达的思想对象具有不可忽视的内涵性。但是,在所有的变体中,语料库都是一个纯粹的外延扩展,只能处理扩展(数值),因此它不能对内涵进行建模或解释,也就不能对语言中的各种现象进行建模。
原因 2 证毕。
顺带一提,BERT 学是一种纯粹的可扩展范式,它并不能解释“内涵”,这是深度学习中所谓的“对抗性样本”的来源。这个问题与这样一个事实有关:一旦张量(高维向量)合称为一个张量,结果张量现在可以用无限多种方式分解为分量(这意味着分解是不可判定的),也就是说,一旦输入张量合成,我们就失去了原始结构(简单地说:10 可以是 2×5 的值,但也可以是 8+1+1 的结果,9+1+0 的结果等等)。神经网络总是会受到对抗性样本的攻击,因为通过反向优化,我们总是可以在任何层上获得预期的输出,而不是从预期的组件获得预期的输出。但这是另外一个讨论了,不在本文范畴之内。
统计学意义
虚词是语料库中最主要的统计学意义的问题之一,在语料库中,虚词只能被忽略,而被称为“停用词”。这些词在每个上下文中都具有相同的概率,因此必须将其删除,因为它们会扰乱整个概率空间。但是,不管 BERT 学家喜欢与否,虚词都是那些最终将最终意义粘合在一起的词。看看下面这对句子的区别就知道了。
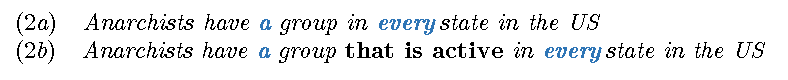
在 (2a) 中,我们指的是 50 个组,而在 (2b) 中只有 1 个。我们如何理解量词、介词、情态动词等,会极大改变目标语(和意图)的意义,因此,如果不考虑虚词的话,就不可能有任何真正的语言理解。而且,在 BERT 学中,这些虚词也不能(适当地)进行建模。
我们本可以到此为止,那就是原因 3 证毕,我们证明了 BERT 学甚至与自然语言理解不相关。但是还有很多……
从本质上说,BERT 学是一种基于在数据中发现某种模式(相关性)的范式。因此,这种范式要求自然语言中的各种现象在统计学上存在显著的差异,否则它们将被视为本质上是相同的。但是,要考虑以下几点(有关这些例子的讨论,请参见《Winograd 模式挑战》(The Winograd Schema Challenge)和《论 Winograd 模式:将语言理解置于数据 - 信息 - 知识连续体中》(On the Winograd Schema: Situating Language Understanding in the Data-Information-Knowledge Continuum),因为它与 Winograd 模式挑战相关):

请注意,像“small”和“big”(或“open”和“close”等)的反义词 / 对立词在相同的上下文中具有相等的概率。因此,(1a) 和 (1b) 在统计学上是等效的,但即使对于一个 4 岁的孩子 (1a) 和 (1b) 来说也有很大的不同:(1a) 中的“it”指的是“the suitcase”,而 (1b) 中的“it”指的是“the trophy”。基本上,在简单的语言中,(1a) 和 (1b) 在统计学上的等价的,尽管在语义上相距甚远。因此,统计学分析并不能对语义进行建模(甚至近似也不能)——就这么简单!
但是,让我们看看,如果坚持使用 BERT 学来学习正确解析这类结构中的“it”,我们需要多少个样本。首先,在 BERT 学中,并没有类型的概念(也没有任何符号知识)。因此,下面的情况都是不同的。
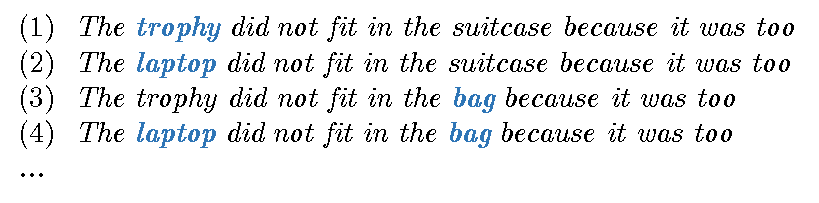
也就是说,在 BERT 学中,没有类型层次结构允许我们将“big”、“suitcase”、“briefcase”等概括为“container”的所有子类型。因此,在纯数据驱动的范式中,上述每一个都是不同的,必须分开来看。如果我们将上述模式的所有轻微句法差异加上语义差异(比如将“because”更改为“thought”,这也将正确的指称项更改为“it”),那么粗略的计算就会告诉我们,BERT 学系统将需要类似上述的 4 千万个变体,而所有这些仅仅是为了在 (1) 中的结构中解析类似“it”的指称项。假如有的话,这在计算上是不可信的。正如 Fodor 和 Pylyshyn 曾经引用著名的认知科学家 George Miller 的名言:为了捕捉自然语言理解系统所需要的所有句法和语义变化,神经网络可能需要的特征数量比宇宙中的原子数量还要多。(我会向任何对认知科学感兴趣的读者推荐这篇经典而精彩的论文:《联结主义与认知架构:批判性分析》(Connectionism and Cognitive Architecture: A: Critical Analysis))。
为总结本节,自然语言中通常没有统计学意义上可以解释不通的解释,而这正是因为证明统计显著性所需的信息并不在数据中,而是在其他地方可以获得的信息,在上面的例子中,所需的信息是这样的:not{FIT(x,y)},则 LARGER(y,x) 比 LARGER(x,y) 更有可能。简而言之,BERT 学中唯一的信息来源必须是可以从数据中获得的信息,但通常正确解释所需的信息并不在数据中,你甚至都找不到数据中不存在的信息。
至此,原因 3 证毕。
结语
我已经讨论了三个原因,证明了 BERT 学甚至与自然语言理解不相关(尽管它可能在本质上是压缩任务的文本处理任务)。以上三个原因中的每一个都足以让这列名为 BERT 学的失控列车停下来。
自然语言可不仅仅是数据!
作者介绍:
Walid Saba 博士,ONTOLOGIK.AI 首席人工智能科学家。
原文链接:
https://medium.com/ontologik/time-to-put-an-end-to-BERTology-or-ml-dl-is-not-even-relevant-to-nlu-e5ba6fc53403




