
推荐系统的本质是信息过滤,多个信息漏斗将用户最感兴趣的内容逐步呈现在用户面前,如图 1 所示(《爱奇艺短视频推荐之粗排模型优化历程》)。召回阶段作为首个漏斗从多个维度将海量视频中用户可能感兴趣的内容滤出交给后续排序技术处理,它直接决定着后续推荐结果的效果上限。本文主要介绍爱奇艺随刻推荐团队多兴趣召回技术的发展历程。相比于其他召回技术,多兴趣召回技术能够同时挖掘出用户的多个潜在兴趣,在个性化推荐系统中突破传统的“千人千面”而达到“千人万面”效果。

图 1 视频推荐系统主要流程[1]
技术背景:如何召回“好苗子”,打破信息茧房
优秀的视频推荐系统可以精准地将视频分发给兴趣相匹配的用户,这个过程可以类比为优秀运动员经过层层选拔最终在世界大赛成功登顶,而召回阶段则相当于运动员年少时期的初次面对的市队选拔。
优秀的国家队教练固然业务水平精湛,但若没有天赋迥异的好苗子,也难以培养出世界级冠军选手;排序技术固然能够通过大量特征和精巧网络将效果提升,但若召回的所有视频本身质量不佳,那排序技术效果的上限将会提前锁死。因此,国家队教练需要多个省市的运动人才作为选拔来源,排序技术需要多个召回源作为待排序内容。
谈到召回技术,熟悉推荐的同学将举出诸多策略与算法,例如策略包括考虑内容关联的频繁项集挖掘 Apriori 等、考虑用户与内容相关性的召回 itemCF 等、基于协同过滤的召回 SVD 等;算法包括将内容变为 embedding 后再进行近邻检索的 item2vec 和 node2vec、应用内容理解的 CDML 召回以及近年来兴起的 GNN 召回等。
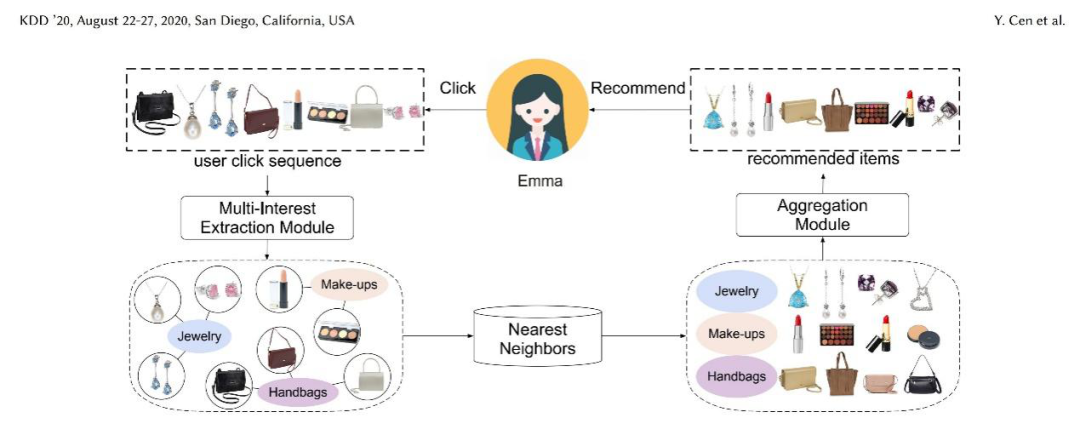
图 2 多兴趣召回主要流程[2]
如图 2 所示,多兴趣召回技术类似其他召回技术都依赖着用户过往的历史行为,但不同点在于多兴趣召回技术可以学习到用户的多个兴趣表示,将个性化推荐的“千人千面”升级为“千人万面”,每一个兴趣表示都能根据最近邻搜索得到相应的视频成为召回源。一方面,多兴趣召回技术符合多数用户拥有不同志趣和爱好的现实情况,能够让推荐结果精准且丰富,能够防止内容同质化带来观感疲劳;另一方面,除了挖掘用户的已有兴趣,多兴趣召回技术不断挖掘出用户自己从未发现的潜在新兴趣,防止传统推荐算法造成的“信息茧房”现象,让爱奇艺线上海量的文化资源呈现给用户。
同时,由于爱奇艺旗下丰富的产品矩阵,往往一个用户会同时使用包括爱奇艺基线、随刻、奇异果等多种产品。在多端用户行为混合训练的情况下,往往能够抽取出用户在不同端的不同兴趣、不同端用户的共同兴趣。这些兴趣往往能够帮助用户找到自己喜爱的社区与圈子,完成产品间的渗透打通和爱奇艺产品矩阵的复合生态建设。爱奇艺短视频推荐现在使用到的多兴趣召回技术有聚类多兴趣召回、MOE 多兴趣召回、单激活多兴趣召回。本文将依次进行介绍。
聚类多兴趣召回
聚类多兴趣召回的主要优点在于不用训练复杂的神经网络,只需利用线上其他深度学习的 embedding 即可形成多个兴趣向量(例如较为成熟的 node2vec,item2vec 等 video embedding 空间),时间和空间代价都较小。主要理论依据为 KDD2020 提出的兴趣聚类方法 PinnerSage[3]。(是不是和 PinSage 名字很像,但它与图神经网络没有太大关系)。
PinnerSage 聚类多兴趣召回是传统 ii 召回基础上结合聚类方法的新型策略。传统的 ii 召回中往往有两种做法:1,选择用户短期历史行为的每个视频,进行多次 ANN 查找选出近邻视频,这样的做法不仅时间成本高而且推出视频同质化严重。2,将用户短期历史行为的所有视频 embedding 进行 pooling 形成代表用户的 user embedding,再进行 ANN 近邻查找,这样的方式能一定程度的融合信息减少时间空间代价,但很容易造成信息损失, pooling 出的 embedding 如图 3 所示很可能差了十万八千里。
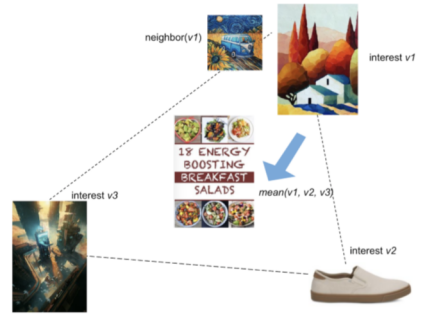
图 3
PinnerSage 则取两者之长,对用户历史行为中的视频进行聚类分组,pooling 形成多个兴趣向量。聚类既避免了多次 ANN 带来的压力,也能一定程度上避免信息损失。PinnerSage 聚类多兴趣召回分为两步走:
a. 聚类过程。如图 4 所示,对用户观看过的所有视频进行聚类操作,Pinnersage 聚类采用了 hierarchical clustering 聚类方法,并不需要像 K-Means 设置初始类别数,而是首先将每一个视频均看作一类,接下来每两类开始合并,若合并后组内 variance 增加最少则可以将两类合并为一类,直到 variance 超过阈值即停止。

图 4
b. 取出 embedding 过程。PinnerSage 依然不对类内视频 embedding 取平均,而是选择类内的一个视频 embedding 作为类(兴趣簇)的代表,该视频 embedding 需满足与类内所有视频 embedding 距离之和最小。再利用这些代表用户兴趣的 embedding 们进行 ANN 即可。
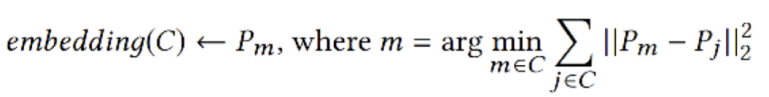
聚类多兴趣召回通过简单的策略便形成了用户多个兴趣,时间代价较少。但由于依赖其他算法形成的 embedding 空间,学习到的多个兴趣 embedding 很容易有偏,推出内容趋于高热难以满足个性化。因此,团队继续向深度学习领域的多兴趣网络进发。
MOE 多兴趣召回
双塔模型是业界比较主流的召回模型,但是双塔模型在实际场景中效果有限。因此团队将双塔中的用户侧的塔结构进行修改,引入类似于 MOE[4]的结构,提取多个向量表示用户潜在的兴趣,从而获得了极大提升。其中 MOE 是多目标学习中使用广泛的经典结构,根据数据进行分离训练多个专家模型,我们最终将多个专家模型的输出作为用户兴趣向量,通过与视频侧提取的向量分别计算内积得到最相似的一个用户向量参与损失的计算。
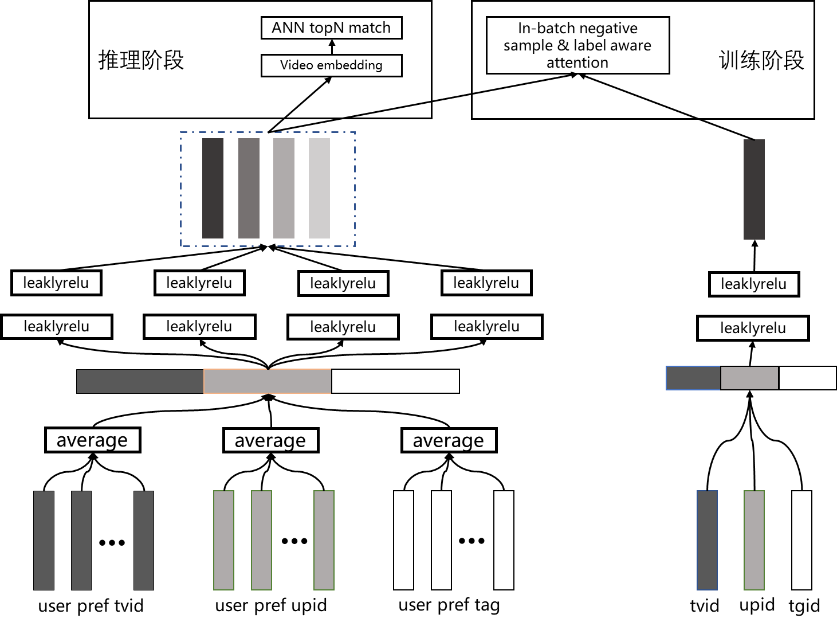
图 5
MOE 多塔结构如图 5 所示,左边为用户侧 MOE 多塔部分,右边为视频侧单塔部分。模型的实现细节包括:
a. 用户侧的输入主要是用户的偏好序列,包括用户偏好的视频 id 序列、上传者 id 序列与内容标签(tag)序列,序列特征经过 embedding 处理与 average pooling 操作后得到不同的向量,拼接之后组成 MOE 多塔的输入,经过 MOE 多塔计算后得到多个向量表示用户潜在的多个兴趣。
b. 视频侧为单塔结构,输入为用户交互过的视频 id、上传者 id 与内容标签(tag)特征,经过 embedding 提取和拼接之后使用单塔结构提取信息。
c. 在 loss 计算上,由于召回是从千万级的视频库中寻找出用户可能感兴趣的几百条视频,因此实际样本中负样本空间十分巨大。为了增加模型对负样本的筛选能力和提升模型负采样的效率,我们在模型中使用 batch 内负采样,将 batch 内其他样本作为当前样本的负样本,同时使用 focal loss 损失函数来提升模型对难样本的识别能力。
经过修改之后的 MOE 多塔模型上线之后,单召回源的点击率和人均观看时长得到极大提升(全端 CTR 提升 0.64%,召回源推出视频 CTR 比全端高出 28%,展均播放时长比全端高出 45%)。
经过修改之后的 MOE 多塔模型上线之后,单召回源的点击率和人均观看时长得到极大提升。但是 MOE 多塔共享底层的输入,仅仅使用简单的 DNN 网络提取不同的向量,导致多个塔之间的区分度比较低,多向量中冗余较多难以优化;此外用户序列特征中实际包含的位置信息对用户比较重要,当前模型难以利用,因此我们希望通过其他的网络来加以利用。
4.单激活多兴趣召回
单激活多兴趣召回从 19 年开始便被工业界使用,其中最绕不开的是阿里提出的 MIND[3],其利用胶囊网络对用户序列进行动态路由收集多兴趣的方法在测试集上取得爆炸效果,激起了整个工业界对多兴趣网络的探索热情。随刻推荐团队也进行了探索。
4.1 单激活多兴趣召回初版
基于 MIND 等网络的启发,团队进行了单激活多兴趣网络的初版探索,网络结构如图 5 所示。在 MIND 网络中,采用了胶囊网络来抓取用户的兴趣,胶囊网络可以很好的同时捕捉观看的序列顺序信息和视频间的相关性,但由于结构较为复杂计算开销较大,且观看顺序仅单个维度即可表示不需要网络对位置信息太过敏感,因此团队选择 transformer 结构进行代替以保证训练速度。
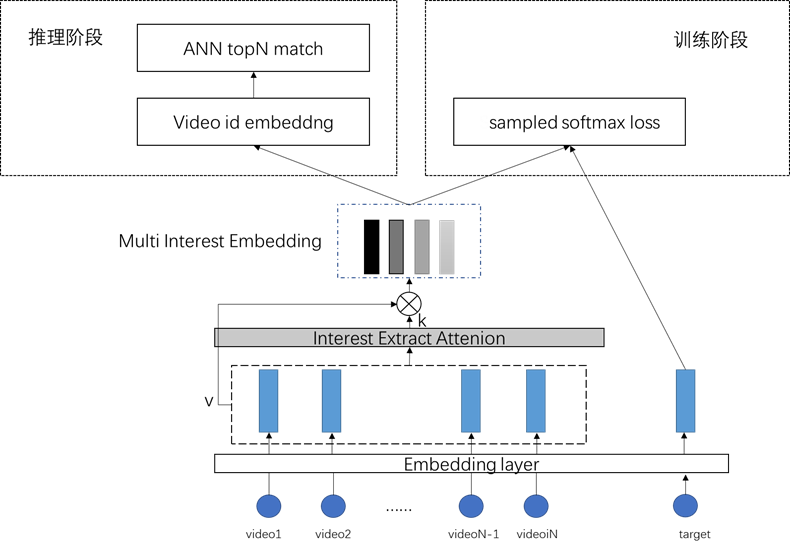
图 6
大致流程为:
a. 截取用户观看视频 id 序列{V1,…VN}作为 sample,第 N+1 个视频作为 target 输入网络,经过 video embedding 层后形成 embedding 序列 E={E1,E2,..EN}。
b. E 经过 transformer 构造的兴趣抽取层得到多个兴趣向量 M,取|Mi|最大的兴趣向量与 target 视频的 embedding 进行 sampled softmax loss 负采样,因此每次训练实际上只激活一个通道的兴趣向量。
c. 模型训练好后在推理阶段,取出用户所有兴趣向量,逐个进行 ANN 检索得到召回结果。
初版虽然结构简单,但上线后效果较好,极大提升消费指标、视频覆盖度和多样性。然而初版也存在着不同兴趣向量召回结果重复度较高、特征较少、即时性差等问题,因此也产生了多个版本的演变。
4.2 disagreement-regularzation 多兴趣召回
4.2 中兴趣向量间无任何约束,因此容易出现兴趣向量过于相似的问题,因此在损失函数上需要施加正则项。鉴于初版多兴趣召回主要部分为 transformer,团队在不改变网络结构的情况下使用三种正则函数进行探索[4]。
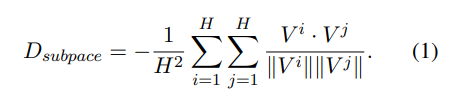
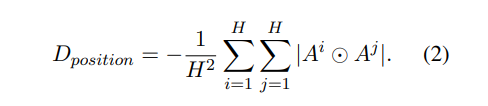
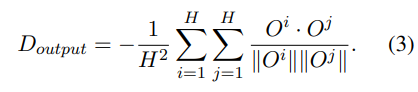
图 7
如图 7 所示,分别对学习到的视频 embedding(公式 1),Attention(公式 2),兴趣向量(公式 3)进行正则化约束。在实际生产环境中发现,直接对兴趣向量进行正则化约束能达到最优效果。
4.3 容量动态化多兴趣召回
不同用户往往呈现不同的兴趣发散性,因此兴趣向量数应该是一个弹性指标而非超参数,在 4.1 与 4.2 的基础上,如图 8 所示在网络结构中引入兴趣激活记录表。
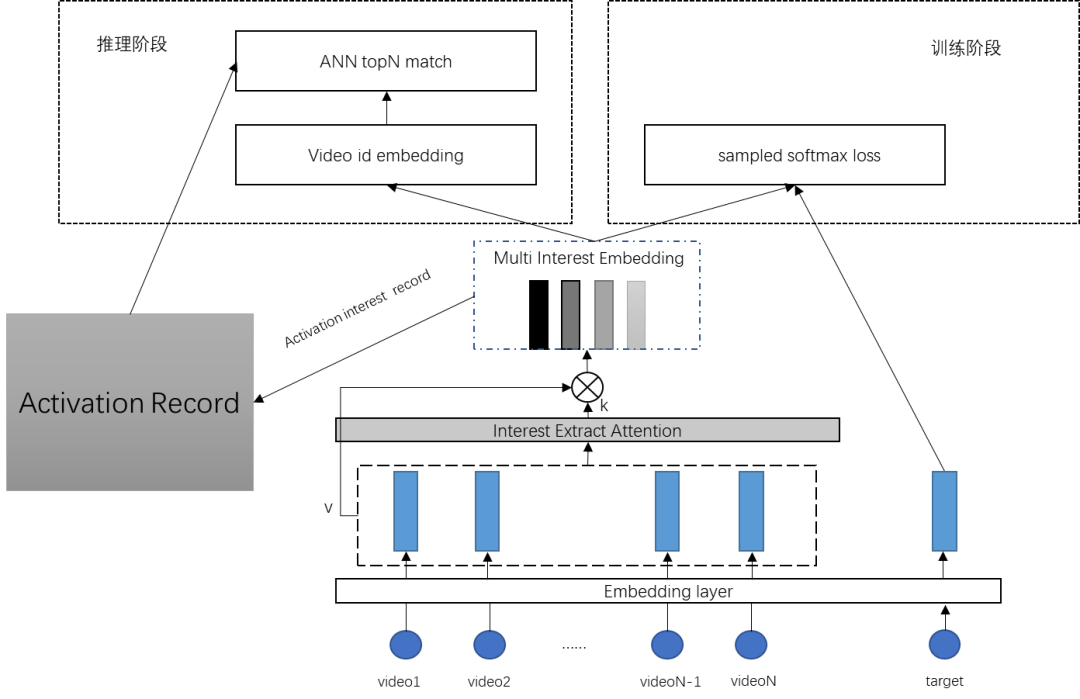
图 8
训练过程中每当用户有任何兴趣向量被激活时,记录表均会记录这次激活。推理阶段,回溯激活表情况,将用户未激活或激活较少的兴趣向量剔除,以达到兴趣数动态化的目的,从而匹配不同用户兴趣发散性存在差异的现实情况。
4.4 多模态特征多兴趣召回
4.1-4.3 中,多兴趣召回仅使用到视频 id 特征,学习效果依然有限,因此在后续版本的发展中,将上传者和内容标签(tag)融入训练成为主要方向。如图 9 所示,为网络主要结构。
Transformer 部分与 4.1-4.3 中大致相同,不同点在于训练样本加入上传者和内容标签(tag)特征后经过 embedding 和 pooling 部分再进入 transformer 中。值得注意的有两点:
loss 部分依然只对视频 id 的 embedding 进行负采样(与 MIND 等结构不同),这样的目的是让视频 id 的全部 embedding 可以进入负采样中,而不用折中使用 batch 内负采样,能够让最终推理阶段主要使用 video id embedding 更加精准(推理阶段 ANN 部分不会使用 tag 与 uploader)。
一个视频往往有多个内容标签(tag),因此在对内容标签(tag)做 embedding 时需要对所有内容标签(tag)做 embedding 操作后进行一次 pooling。
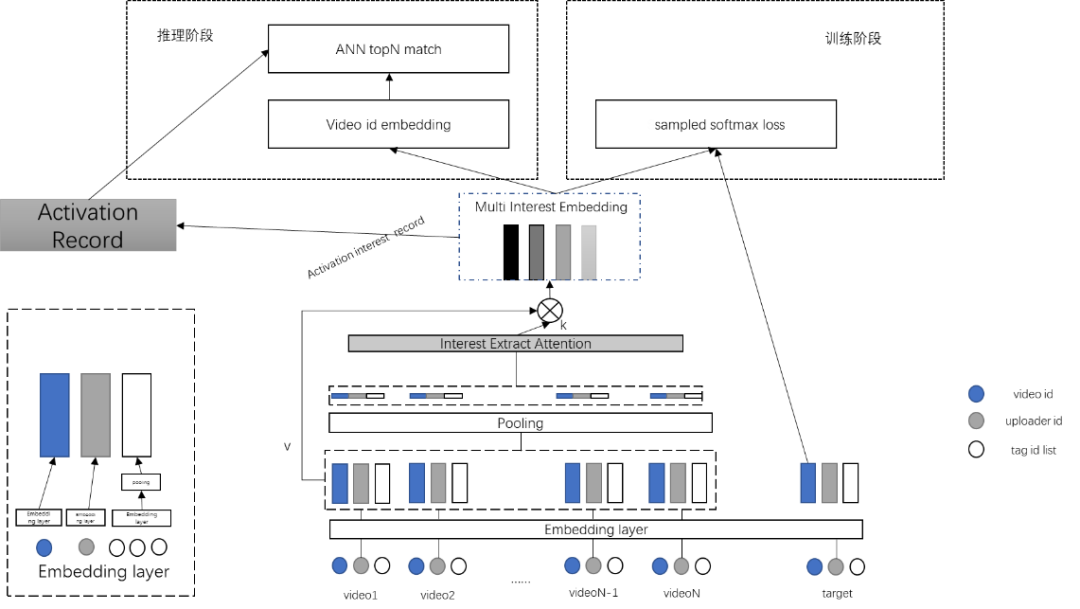
图 9
4.5 小结
如 4.1-4.4 所示,单激活多兴趣网络进行了多次演变过程,一次次改进后的应用带来了非常显著的效果,全端 CTR 显著提升 2%,全端时长提升 1.5%,人均播放提升 1.5%;特别是在推出视频的多样性上,直接提升 4%以上。
同时作为一个老少皆宜的内容平台,在爱奇艺一直存在着以家庭为单位,不同年龄段用户使用同一账号的情况,因此同一账号下的历史行为往往来自各个年龄阶段,用户历史行为的复杂性给推荐带来了难题。而单激活多兴趣网络的兴趣向量在学习过程的采样中具随机性、在数学呈现上具正交性,这就使得兴趣向量的搜索范围能够召回不同年龄段所喜爱的海量视频。
单激活多兴趣网络现在也是学术热点之一,希望能够有更多的研究者提出新的 idea 让推荐技术继续大放异彩。
总结与展望
本文已经大致展现了爱奇艺短视频推荐召回技术中多兴趣召回的发展情况。多兴趣召回最大的亮点,在于可以抽取一个用户的多种兴趣,让曾经“千人千面”的画像迈入“千人万面”的高维空间,让推荐结果同时提升精准度和丰富度,同时也有兴趣试探,避免用户走入信息茧房。同时该技术也在爱奇艺产品矩阵复合生态建设与用户历史行为复杂性问题解决方案的前路上一直探索。
本文也认为多兴趣召回依然有可以优化的方向:
在行为序列的选取上,大部分的多兴趣策略与网络依然只考虑到用户的观看历史,如果能够运用事件知识图谱,将用户在平台上的搜索、订阅等行为一起纳入训练数据中,应该可以抓取用户更多的兴趣与倾向。
在负反馈信息的处理上,多兴趣召回尚无应对之策。视频中的许多点踩、消极评论、不喜欢、取消关注等行为尚且未融入到多兴趣召回中,这些信息对指导兴趣网络的也至关重要,后期该方向将成为重点工作。
在用户的静态信息与偏好特征的整合上,亦有很大的应用空间。这部分特征的组合能够很好地和排序目标对齐,提升召回源质量和排序效果上限。
参考文献
[1] 2021-2-26 期,如何提升链路目标一致性?爱奇艺短视频推荐之粗排模型优化历程
[2] AdityaPal, et al. PinnerSage: Multi-Modal User Embedding Framework for Recommendations at Pinterest. KDD 2020
[3] Jiaqi Ma, et al. Modeling Task Relationships in Multi-task Learning with Multi-gate Mixture-of-Experts. KDD 2018
[4] Yukuo Cen, et al. Controllable Multi-Interest Framework for Recommendation.KDD 2020.
[5] Chao Li, et al.Multi-Interest Network with Dynamic Routing for Recommendation at Tmall. CIKM 2019.
[6] Jian Li, et al. Multi-Head Attention with Disagreement Regularization. EMNLP 2018
本文转载自:爱奇艺技术产品团队(ID:iQIYI-TP)




