
7 月 4 日,2024 世界人工智能大会暨人工智能全球治理高级别会议(WAIC 2024)在上海开幕。上海人工智能实验室主任、首席科学家,清华大学惠妍讲席教授,衔远科技创始人周伯文在 WAIC 2024 科学前沿主论坛上发表开场报告。以下为报告全文:
尊敬的各位领导、各位来宾,大家下午好。我是上海人工智能实验室周伯文,非常有幸在这个隆重的场合下代表实验室与大家进行主旨分享。我的报告主题是《通专融合:通用人工智能前沿探索与价值实现》。自 21 世纪初以来,我们进入了以人工智能的兴起为代表,并逐步走向通用人工智能的第四次工业革命,因此又称为智能化时代。这一时代的特点是知识发现加速,人类能力的边界得以拓展,产业的数字化和智能化持续升级,从而带来生产范式的变革。通用人工智能对于人、工具、资源、技术等生产力要素具有广泛赋能的特性,可以显著提升其他生产力,因此我们说它是新质生产力的重要引擎,是“生产力的生产力”。
AGI 路径的思考
我本人深入思考通用人工智能始于 2015、2016 年。2016 年 AlphaGo 击败了人类的世界冠军,大家开始讨论通用人工智能什么时候会到来。坦率讲当时大家对 AGI 是缺乏认识的,但我在思考什么样的研究可以导致 AGI。我们需要回答很多问题,例如,什么时候 AGI 会来,AGI 会怎么来,我们要如何防御,如何让 AGI 变得更好等。那时候大家都知道了 AGI 是什么,但不知道怎么做。对应 AGI 我创造了两个词:ANI 狭义人工智能和 ABI 广义人工智能。右边就是我当时的 PPT 原版。

通向 AGI 的必经之路是 ABI,即广义人工智能。从学术上我给出了严格的定义:自监督、端对端、从判别式走向生成式。
回头来看,2022 年 ChatGPT 出现的时候基本上实现了这三个要素,也就说 2022 年底开始我们已经进入了 ABI 的时代。但 2016 年未能预测出大模型的一些要素,例如模型的涌现能力。站在 2024 年的节点上,如果要做同样的思考讨论,那么接下来,AGI 应该是一种怎样的达成路径,这是我们所有研究者和从业者都必须思考的问题。
这里提供一个我们的思考视角:实现 AGI 的路径应该是二维的,而非一维的。回看发展历史,在 2016、2017 年以前,人工智能在专业能力上拥有非常迅猛的进展。从“深蓝”到“AlphaGo”,人工智能因一次次击败“地表最强人类”而成为新闻的主体。但当时的巨大挑战在于,这些模型不具备泛化能力,只能在专有的任务上表现突出。在 2017 年 Transformer 提出以后,我们看到的是大模型在泛化能力上的“狂飙”。但大模型当前的另一个挑战是,在专业能力的进展上极其缓慢。同时带来的能源消耗、数据消耗、资源消耗均在让人思考,这条路径是通向 AGI 的有效路径吗?
Sam Altman 曾提到,GPT-4 的专业能力,大概相当于 10%-15%的专业人士,即使到未来的 GPT-5,预期将会提高四到五个点,也就是说将用指数级的能源消耗增长换来缓慢的专业能力提升。
在这里我们想提出一个判断:人工智能 AGI 落地会有一个高价值区域,同时要求模型兼备很强的泛化能力和足够的专业性。这个区域离原点最近的位置,我们把它叫做通专融合的“价值引爆点”。根据对历史生产力提升的分析,我们认为处在这个点的大模型,在专业能力上应超过 90%的专业人类,同时具备强泛化能力,即 ABI 的能力。谁先进入高价值区域,即意味着谁的能力更强,拥有更多的场景和数据飞轮,并因此更早拥有自我进化迭代的能力。
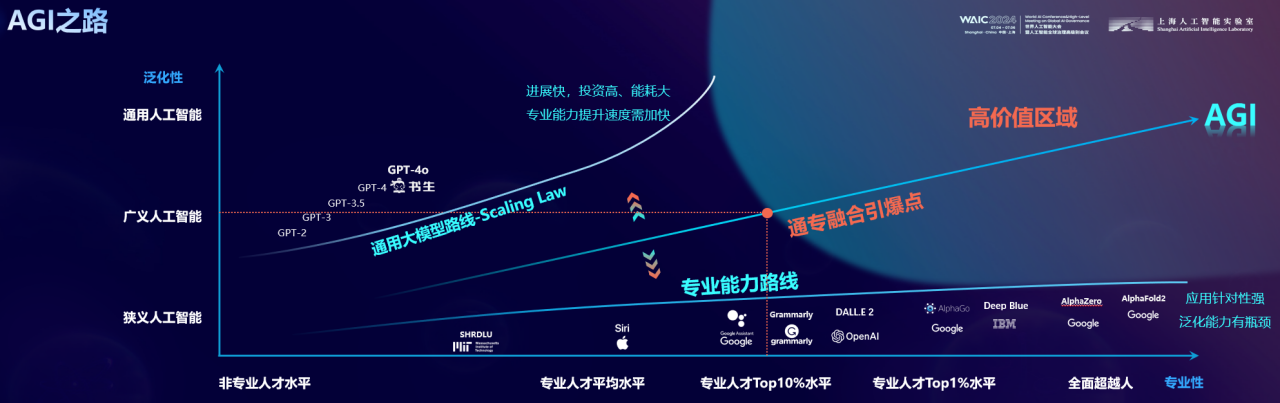
强泛化之上的专业能力是 AI 皇冠上的明珠:通专融合新范式
强泛化之上的专业能力是 AI 皇冠上的明珠,通专融合的发展新范式。瞄准构建一个既具有泛化性又具备专业能力的 AI 系统,这样的系统能够更高效、更好地适应和解决现实世界中的复杂问题。实现这一目标需要一个完整的技术体系,它包含三层重点工作:
基础模型层:我们专注于更高效地构建通用泛化能力,尤其是其高阶能力,如数理、因果推理等。通过高质量数据的清洗和合成,研发高性能训练框架、高效的模型架构。一部分这样的原始创新体现在我们的书生·浦语大语言模型、书生·万象多模态模型等基础模型,并在数学和推理等高阶能力上实现了突破。但我们还有很多工作要做。
融合协同层:这一层负责将泛化性和专业性有效地结合起来。我们采用多路线协同的算法和技术,构建比肩人类优秀水平的专业能力。我们的原创工作包括高密度监督信号的生成、复杂任务规划,以及新的架构来实现系统 1(即快速、直觉反应的系统)和系统 2(慢速、逻辑分析的系统)之间的交互。通过这些技术,AI 能够在复杂环境中做出决策,将复杂任务分解为更易管理的子任务,制定行动计划,并有效地协调多个智能体,以实现群体智能的涌现。
自主进化与交互层:在这一层,我们强调 AI 的自主探索和反馈闭环的重要性。AI 系统需要能够在真实或仿真世界中自主地收集数据、学习并适应环境。通过与环境的交互,AI 能够获得反馈,这些反馈对于其自我进化至关重要。自主进化与交互层使 AI 能够进行具身自主学习,最终对世界模型有更深刻的理解并与之交互,完成开放世界任务。
接下来,我分别介绍在这个框架下的几项前沿进展。
更高效地构建通用基础模型
为更高效地构建通用基础模型,实验室在并行训练及软硬适配协同、高效数据处理、新型架构及推理增强等方面进行了一系列原创的探索。
例如,在长序列并行训练方面,我们实现了性能突破,较国际知名的框架 Megatron 高达 4 倍。我们研发的大模型训练系统,基于真实训练需求不断沉淀技术能力,已连续两年获得计算机系统顶会 ASPLOS 杰出论文奖及最佳论文奖。
在基础模型方面,通过稀缺数据的合成与增广,实验室最新的大语言模型书生·浦语 2.5,实现了综合性能比肩开源大模型参数的性能。
多模态大模型书生·万象,通过渐进式对齐、向量链接等创新技术,构建以更少算力资源训练高性能大模型的道路。以 260 亿参数,达到了在关键评测中比肩 GPT-4 的水平。
模型通用泛化能力与专业能力融合
围绕构造通用模型的高阶专业能力,我介绍两项代表性成果。
首先,是关于大模型专业推理能力。最近大家可能看到过这个新闻:“AI 参加高考,数学全不及格”。这些 AI 考生里面,也包含了我们的书生·浦语,它在其中拿到了数学的最高分 75 分。这要得益于我们的开源数学模型,它沉淀了密集过程监督、模型辅助的思维链校验、多轮强化自训练、文本推理和代码解释器联合迭代等一系列技术,具备了良好的自然语言推理、代码解题及形式化数学语言性能,所以能以 200 亿参数在高考数学上超过 GPT-4o,我们不但效果最好,而且参数体量最小、能源消耗最低。
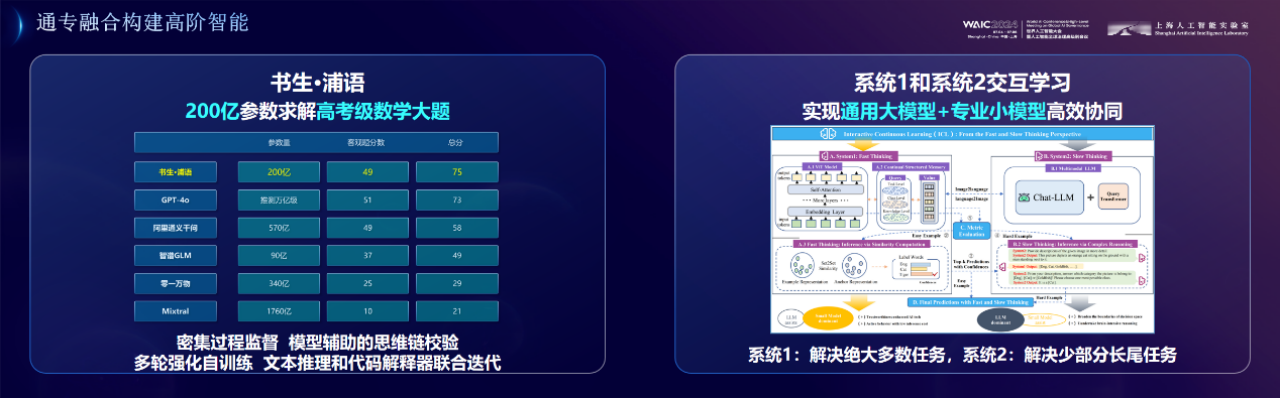
第二项是关于新的系统架构,我们原创提出模拟人脑的系统 1 与系统 2 架构来实现通专融合。大家知道系统 1 是人脑的快决策,反映的是长期训练下的专业能力;系统 2 是慢系统,体现的是深度思考下的泛化能力。我们今年的这篇 CVPR 论文通过设计系统 1 与系统 2 的协同模式,提出了交互式持续学习新概念,让通用模型与专业模型能互相学习,通过通专融合来更高效、更专业地解决问题。同一个架构在图像识别、专业文本生成方面都获得了很好的效果。
具身自主探索与世界模型
具身自主探索是实现通专融合的有效手段,也是理解物理世界的 AGI 的必经之路。但具身智能绝不仅仅是大模型加机器人的应用,而是物理世界的反馈需要及时进化大模型。我们光靠看书或看视频,永远学不会游泳,你得亲身扎到水里才能学会。大模型得通过机器人,扎进现实世界,才能真正理解物理世界。
为帮助建立世界模型,我们构建了“软硬虚实”一体的机器人训练场——“浦源·桃源”,同时攻关具身智能的“大脑”与“小脑”。“浦源·桃源”是首个城市级的具身智能数字训练场,构建了集场景数据、工具链、具身模型评测三位一体的开源具身智能研究平台。作为大模型与机器人的连接层,涵盖 89 种功能性场景、10 万+高质量可交互数据,有望解决领域内数据匮乏、评测困难的问题。
在大脑方面,我们通过具身智能体自身状态认知、复杂任务分解分配、底层技能协同控制三方面创新,首次实现了大模型驱动的无人机、机械臂、机器狗三种异构智能体协同。在小脑方面,我们通过 GPU 高性能并行仿真和强化学习,可以高效实现机器人在真实世界里快速学习,并完成高难度动作。我们发现,单卡 1 小时的训练就能实现真实世界 380 天的训练效果。
无人驾驶可以理解为一个具身智能体。我们提出了开源且通用的自动驾驶视频预测模型 GenAD,类似于自动驾驶领域的“SORA”,能够根据一张照片输入,生成后续较高质量、连续、多样化、符合物理世界规律的未来世界预测,并可泛化到任意场景,被多种驾驶行为操控。
通专融合实践:科学发现
对于科学发现领域,通专融合无疑也有着巨大的潜在价值。
2023 年初,Nature 曾发表过一篇封面文章,展示了对科研论文发展现状的悲观态度,指出“科学进步正在‘降速’”。文章认为,近年来科研论文数量激增,但没有颠覆性创新。因为科学本身的发展规律便是不断深入,每个学科形成了信息茧房,不同学科之间壁垒增加。对于顶尖科学家来说,即使穷尽一生也没有办法掌握一个学科所有的知识。这就启发我们需要新的科研组织方式来适配学科信息茧房,这也需要科研工作者与时俱进,采用 AI 工具赋能科研、加速创新。
由于大模型内部压缩着世界知识,同时具备不确定性生成的特性,因此有可能帮助我们打破不同学科领域知识茧房,进行创新式探索。我们认为大模型的不确定性和幻觉生成,并不总是它的缺陷,而是它的一个特点。合理利用这种特点,通过人机协同有助于促进科研创新。
事实上,就人类科学家而言,通过“做梦”找到研究思路的例子也不胜其数,最典型的就是,德国有机化学家奥古斯特·凯库勒梦见衔尾蛇,进而发现苯环结构。
我们探讨了大模型在生物医学领域的知识发现问题,针对最新的医学文献构建知识发现测试集,并对于最先进的大模型进行评测。我们发现大模型能够提出新的生物医学知识假设,并在最新的文献中得以验证。
这里给出一个我们发现新假设过程的简单示例:我们将已有的背景知识输入到 2023 年 1 月发布的大模型,并让大模型生成可能的假设。大模型提出的假设中,第一条假设是背景已知信息,还不是新的知识;但是第二条假设是之前文献中所没有的。两个月后,这条假设在 2023 年 3 月发表的论文中得到了验证。
这只是一个非常简单的例子,但已经显示出大模型具有很大的潜力,可以促进科研知识发现,并且能够提出新的有价值的未知假设。
通过通专融合,AI 不只可以提出科学假设,还可以掌握科学知识、分析实验结果、预测科学现象。进而在反思的基础上,提升 AI 提出科学假设的能力。
在掌握科学知识方面,我们基于大语言基座模型能力进行专项能力强化,分别在化学和育种两个方向构建了首个开源大模型——书生·化学和书生·丰登;
在分析实验结果方面,我们研发的晶体结构解析算法 AI4XRD 具备专家级的准确率,并将解析时间从小时级降低到秒级;
在预测科学现象方面,我们训练并持续迭代了风乌气象大模型,在全球中期气象预报上具有当前世界领先的时间和空间分辨率;
在提出科学假设方面,我们提出“人在环路大模型多智能体与工具协同”概念框架,对于科学假设的链路进行升级。构建了 AI 分析师、AI 工程师、AI 科学家和 AI 批判家多种角色,接入工具调用能力来协同提出新的假设。
下一代 AI for Science
为什么提出一个好问题在科研中如此重要?早在 1900 年,德国数学家大卫·希尔伯特(David Hilbert)提出了著名的“23 个问题”,引领了数学很多子领域数百年的发展。在科学上,提出一个好问题往往比解决问题更重要。希尔伯特还有一句名言,这也是他的墓志铭:“We must know. We will know.”我们必须知道。我们终将知道。今天,我们踏上通专融合的路线,探索通用人工智能 AGI 的未来,展望下一代的 AI for Science,更可以从这句话中汲取灵感和激励。对于可信 AGI 的未来,正如我今天上午在全体大会的演讲,我们的态度是坚定而积极的:We must be there. We will be there!我们必须达成,我们终将抵达。
我今天站在这里也非常感慨,想起了去年汤晓鸥老师在 WAIC 大会上提到我们原创的成果、我们年轻的科学家,提到了我们的书生大模型。正是我们实验室一群有创造力的年轻科学家,让我们坚信:We must be there and we will be there!




