
阿里云操作系统团队、阿里云数据库团队以及上海交通大学新兴并行计算研究中心一起合作的论文 “Async-fork: Mitigating Query Latency Spikes Incurred by the Fork-based Snapshot Mechanism from the OS Level” 被数据库系统领域顶会 Very Large Data Bases Conferences (VLDB)录用为长论文。VLDB 从 1975 年开始举办,属于计算机数据库系统领域顶级会议(CCF A 类),平均录用率为 18.6%。
摘要
得益于超快的查询速度,内存键值对数据库(In-memory key-value store, 下称 IMKVS)被广泛使用于延迟敏感的在线应用程序中。
为了支持数据持久化,流行的 IMKVS(例如 Redis 与 KeyDB)使用系统调用 fork 定期获取内存数据的快照。然而,这种基于 fork 的快照机制可能会引发在快照生成期间到达的查询延迟大幅增加,进而影响在线程序的服务质量。这是因为 IMKVS 引擎在调用 fork 期间陷入内核态,为了保证数据的一致性,在此期间无法处理用户查询请求。而当 IMKVS 内存占用较大时,fork 调用过程耗时非常长。
为此,我们优化了 fork,这可以在不修改 IMKVS 的基础上,解决快照期间查询延迟大幅增加的问题。
具体而言,我们设计了一个新的 fork(称为 Async-fork),将 fork 调用过程中最耗时的页表拷贝部分从父进程移动到子进程,父进程因而可以快速返回用户态处理用户查询,子进程则在此期间完成页表拷贝。为了保持父子进程之间的数据一致性,我们设计了一套高效的主动同步机制。实验结果表明,与 Linux 中的默认 fork 相比,Async-fork 显著减少了快照期间到达请求的尾延迟(在 8GB IMKVS 实例上,p99 延迟减少了 81.76%;在 64GB 的实例上 p99 延迟减少了 99.84%)。
问题介绍
对于 IMKVS 而言,由于所有数据都驻留在内存中,数据持久化是实现数据备份与容灾的关键功能。流行的 IMKVS(Redis 与 KeyDB)实现数据持久化的方式是使用系统调用 fork 获取内存中数据在某时间点上的快照,并将快照转储到硬盘中。
如图 1(a)所示,父进程调用 fork 创建子进程,而子进程保有与父进程在调用 fork 的时刻相同的数据。随后,子进程在后台将数据写入硬盘,而父进程则继续处理用户的查询请求。尽管这样的快照机制已经将繁重的 IO 任务从父进程委派给子进程,但仍然可能导致在 fork 调用期间到达的请求的延迟激增(例如,图 1(a)中在 T0 时刻到达的请求)。
这是因为父进程在调用 fork 期间陷入内核态,无法处理用户查询请求。因为 fork 调用的耗时随进程内存的占用增大而增大,延迟激增的现象随 IMKVS 内存占用的增大而变得更为严重。实验表明,在 64GB 的 Redis 实例上,非快照期间请求的 p99 延迟与最大延迟分别为 0.08ms 与 6.46ms,而在快照期间请求的 p99 延迟与最大延迟分别为 911.95ms 与 1204.78ms。
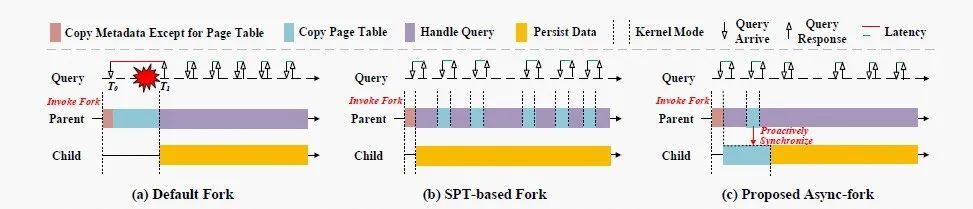
在默认 fork 的调用过程中,父进程需要将许多进程元数据(例如文件描述符、信号量、页表等)复制到子进程,而页表的复制是其中最耗时的部分(占据 fork 调用耗时的 97% 以上)。先前的研究者提出了基于共享页表的 fork 优化方法,这种方法建议以写时复制(Copy-on-write, 下称 CoW)的方式在父子进程之间共享页表。
如图 1(b)所示,在共享页表方案中,页表复制不在 fork 调用期间进行,而是在将来发生修改时再进行复制。虽然共享页表能够很大程度上解决延迟激增问题,但我们的分析表明这样的设计在 IMKVS 中导致父进程从 fork 调用中返回用户态后频繁中断陷入内核态完成页表复制,对性能造成了不利影响。此外,共享页表还引入了数据泄漏漏洞,这个漏洞可能导致子进程持有与父进程不一致的数据,破坏了快照一致性。因此,共享页表方法不适用于解决延迟激增问题。
Async-fork 的核心思想与挑战
我们提出了另一种 fork 的优化方法(称为 Async-fork),总体设计思路如图 1(c)所示。Async-fork 设计的核心思想是将复制页表的工作从父进程转移到子进程。这可以缩短父进程调用 fork 时陷入内核态的时间,能够尽快返回用户态处理用户的查询请求,从而解决延迟激增问题;另一方面,还确保了父进程和子进程都具有独占页表,从而避免引入数据泄漏漏洞。
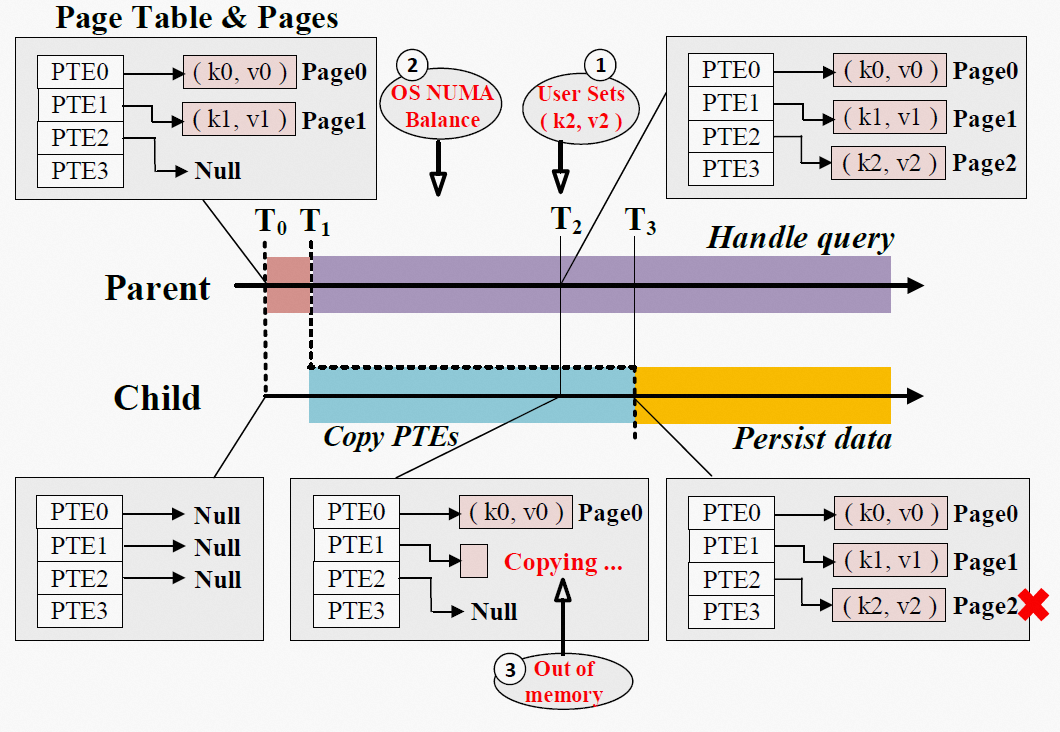
然而,实现上述设计并非易事。如图 2 所示,我们面临的首要挑战是页表的异步操作可能导致快照不一致。以图 2 中的①为例,IMKVS 在 T0 时刻拍摄快照,而某个用户请求在 T2 时刻向 IMKVS 插入了新的键值对(k2, v2),这导致父进程修改它的页表项(PTE2)。当这个被修改的页表项尚未被子进程复制时,新插入的键值对将被子进程最终写入硬盘,破坏了快照一致性。因此,我们在 Async-fork 中设计了一种主动同步机制,使父进程在修改页表项前,主动将被修改的页表项复制到子进程。
实际上,除了用户请求可能导致页表项修改外,操作系统中的许多内存操作都会引起页表项修改。例如,操作系统会定期在 NUMA 节点之间迁移页面,导致涉及的页表项被修改为不可访问(图 2 中的②)。因此,主动同步机制必须捕获父进程中所有可能的页表项修改操作,以严格保证一致性。
另一方面,Async-fork 执行的过程中可能会出现错误。例如,由于内存不足,子进程可能无法复制页表项(图 2 中的③)。因此,我们在 Async-fork 中加入了错误处理。如果 Async-fork 执行的过程中发生错误,我们保证将父进程恢复到它调用 Async-fork 之前的状态。
Async-fork 的设计详解
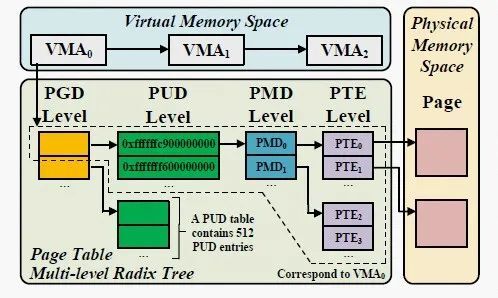
在详解 Async-fork 的设计之前,首先简要介绍 Linux 虚拟内存的相关知识。进程有自己的虚拟内存空间,Linux 使用一组虚拟内存区域(Virtual memory area, 下称 VMA)来描述进程的虚拟内存空间。一个 VMA 描述虚拟内存空间中的一片连续区域。页表是用于将虚拟内存映射到物理内存的数据结构。页表由若干页表项(Page table entry,下称 PTE)组成,PTE 维护着虚拟地址到物理地址的转换信息和访问权限。
为了降低内存成本,页表以多级基数树的方式存储,而 PTE 位于最后一级的叶节点,如图 3 所示。页表最多有五级,从上到下依次为 PGD 级、P4D 级、PUD 级、PMD 级和 PTE 级。由于 P4D 通常是禁用的,因此我们在本文中仅关注其他四级。每级中的一个节点是一个物理页,它是一个存储了若干项的表。每个项包含一个物理页的地址,而该物理页将作为下一级节点。当页大小设置为 4KB 时,每个级别中的表包含 512 个项。对于一个 VMA,存在一系列与之对应的 PTE,它们翻译了这个 VMA 中的所有虚拟地址,我们将这些 PTE 称为“VMA 的 PTE”,而“VMA 的 PMD 项”则是树中这些 PTE 的所有父级 PMD 项的集合。
运行过程
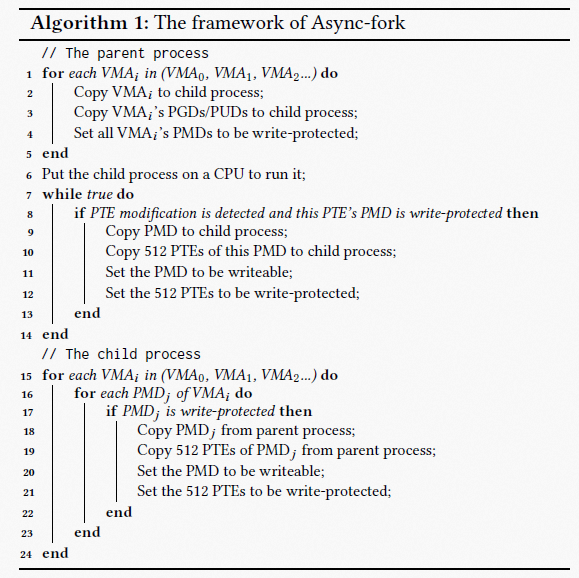
算法 1 描述了 Async-fork 中父进程与子进程的运行过程。在默认 fork 中,父进程遍历每个 VMA,将每个 VMA 复制到子进程,并自上而下地复制该 VMA 对应的页表项到子进程。在 Async-fork 中,父进程同样遵循上述过程,但只负责将 PGD、PUD 这两级的项复制到子进程(Line 1 to Line 5)。
随后,父进程将子进程放置到某个 CPU 上使子进程开始运行,而父进程返回到用户态(Line 7 to Line 14),如果在此期间检测到了 PTE 修改,则会触发主动同步机制,该机制用以确保 PTE 在修改前被复制到子进程,我们将在下文详解主动同步机制。对于子进程而言,它遍历每个 VMA,并从父进程复制 PMD 项和 PTE(Line 15 to Line 24)。
主动同步机制
父进程返回用户态后,父进程的 PTE 可能被修改。由于只有父进程能够感知到这些修改,有两种方式可以确保该 PTE 被修改前被复制到子进程:
1) 父进程主动地将该 PTE 复制到子进程,随后执行修改。
2) 父进程通知子进程复制该 PTE,等待复制完成,随后执行修改。由于这两种方式都会导致父进程等待且等待时间相同,我们选择了前一种方式。
当一个 PTE 将被修改时(如何检测 PTE 修改将在下文详解),我们选择让父进程不仅复制这一个 PTE,还同时将位于同一个表上的所有 PTE(一共 512 个 PTE),连同它的父级 PMD 项复制到子进程。以图 4 为例,所有 PGD 与 PUD 条目均已被复制到子进程,而父进程中的 PTE1 将被修改。此时,父进程会将 PMD2、PTE0、PTE1 都复制到子进程。
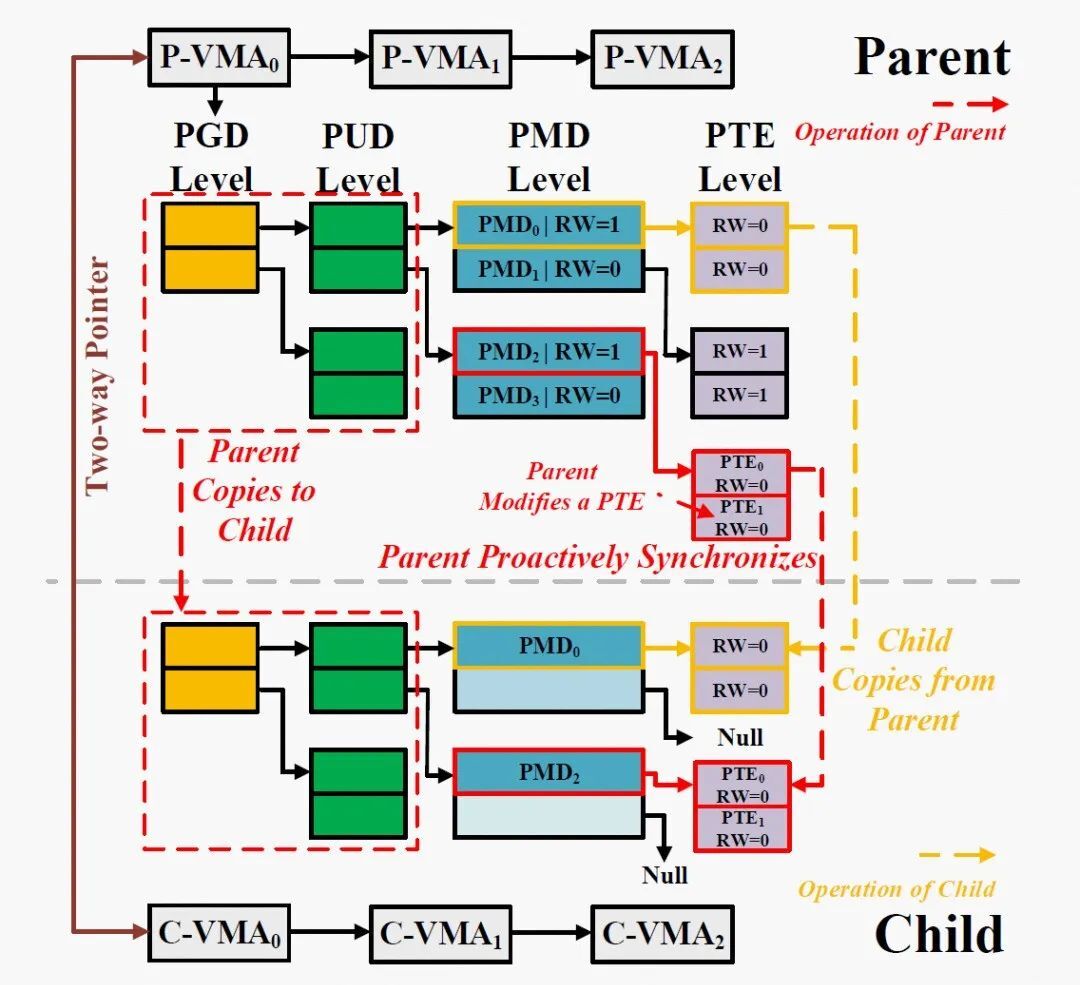
避免重复复制——实际上,即使父进程中的 PTE 发生修改,也并不是总是需要将其复制给子进程,因为子进程可能已经复制过这个 PTE 了。为避免不必要的复制,我们使用 PMD 项上的 RW 位来标记是否被复制。具体而言,当父进程第一次返回用户态时,它所有 PMD 项被设置为写保护(RW=0),代表这个 PMD 项以及它指向的 512 个 PTE 尚未被复制到子进程。当子进程复制一个 PMD 项时,通过检查这个 PMD 是否为写保护,即可判断该 PMD 是否已经被复制到子进程。如果尚未被复制,子进程将复制这个 PMD,以及它指向的 512 个 PTE。
在完成这个过程后,子进程将父进程中的该 PMD 设置为可写(RW=1),代表这个 PMD 项以及它指向的 512 个 PTE 已经被复制到子进程。当父进程触发主动同步时,也通过检查 PMD 项是否为写保护判断是否被复制,并在完成复制后将 PMD 项设置为可写。由于在复制 PMD 项和 PTE 时,父进程和子进程都锁定 PTE 表,因此它们不会同时复制同一 PMD 项指向的 PTE。
检测 PTE 修改——PTE 的修改既可能由用户操作导致,也可能由操作系统的内存操作导致。我们将 PTE 的修改分为两类:
1)VMA 级的修改。有些操作作用于特定的 VMA,包括创建、合并、删除 VMA 等。VMA 的修改也可能导致 VMA 的 PTE 被修改。例如,用户发送查询删除大量键值对, 然后 IMKVS(父进程)通过 munmap 回收对应的虚拟内存空间。
2) PMD 级的修改。例如,父进程的页可能因为内存不足被 OOM killer 回收。在 VMA 级的修改中,多个 PMD 项被涉及,而在 PMD 级的修改中仅有一个 PMD 项被涉及。表 1 总结了这些操作,并列出了这些操作中发生修改行为的函数(checkpoint)。

我们在这些函数中插入了代码实现 PTE 修改检测。一旦这些函数被执行,父进程检查修改是否涉及未复制的 PMD 项和 PTE(通过检查 PMD 是否写保护),并将未复制的项复制到子进程。在 VMA 级的修改中,如果一个 VMA 描述了相当大的虚拟内存空间,父进程可能会花费相对较长的时间遍历检查这个 VMA 的 PMD 项。
为了减小检查开销,我们在父子进程的 VMA 上引入双向指针,帮助父进程快速判断一个 VMA 的所有页表项是否已经复制到子进程。每个 VMA 数据结构中被添加了一个指针,在 Async-fork 调用时由父进程初始化。父进程 VMA 中的指针指向子进程的 VMA,而子进程 VMA 中的指针指向父进程的 VMA,如图 4 所示。
通过这种方式,双向指针在父子进程的 VMA 间创建了连接。如果一个 VMA 的所有页表项都被复制到子进程,则连接被断开。具体而言,如果在子进程复制一个 VMA 的 PMD 项和 PTE 的过程中,父进程中未发生 VMA 级的修改,则子进程在复制操作完成后断开连接。否则,意味着父进程中发生了 VMA 级的修改,父进程将负责复制这个 VMA 的 PMD 项和 PTE 到子进程,并在复制完成后断开连接。
通过这种方式,当父进程中发生 VMA 级的修改时,父进程可以首先检查该 VMA 的指针连接,以快速判断该 VMA 的页表项是否已被全部复制。对于页表项已经全部被复制的 VMA,父进程不再需要检查它的所有 PMD 项。双向指针还用于错误处理,将在下文描述。
错误处理
Async-fork 在复制页表时涉及到内存分配,因此会发生错误。例如,由于内存不足,进程可能无法申请到新的 PTE 表。当错误发生时,我们应该将父进程恢复到它调用 Async-fork 之前的状态,即确保父进程不会因为失败调用了 Async-fork 而发生改变。
在 Async-fork 中,父进程 PMD 项目的 RW 位可能会被修改。因此,当发生错误时,我们需要将 PMD 项全部回滚为可写。错误可能发生在:1) 父进程复制 PGD 项与 PUD 项时,2) 子进程复制 PMD 项与 PTE 时,以及 3) 在父进程触发主动同步期间。
对于第一种情况,父进程负责回滚所有写保护的 PMD。对于第二种情况,子进程负责回滚所有剩余的未复制的 PMD 项目,随后发送 SIGKILL 信号。当子进程返回用户态时,将接收到该信号并被杀死。对于第三种情况,父进程仅负责回滚正在复制的 VMA 中的 PMD 项,然后将错误代码存储到该 VMA 的双向指针中。子进程在复制 VMA 的 PMD 项与 PTE 之前(或完成复制之后),都会检查 VMA 中的双向指针中是否存在错误码。如果子进程遇到错误码,它立即停止复制,并执行第二种情况的错误处理行为。这样可以避免错误处理过程中父子进程之间的锁争用。
Async-fork 的实现及优化
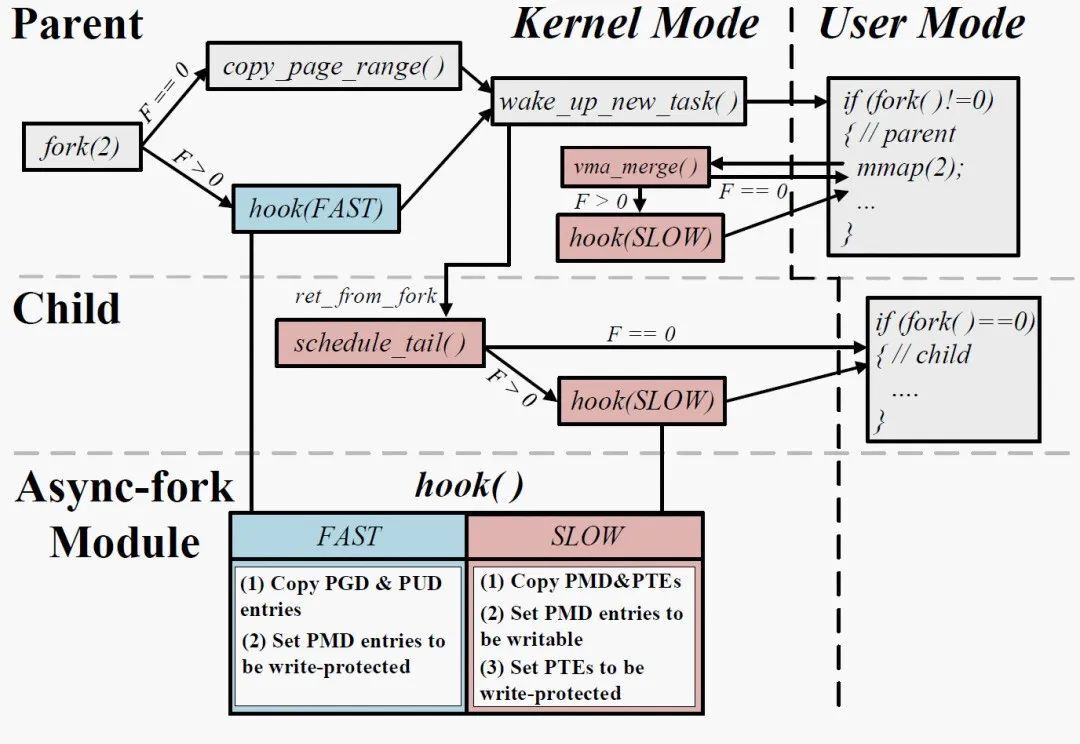
图 5 描述了 Async-fork 在 Linux 中的实现。我们向 fork 调用路径与内存子系统中的一些函数插入了钩子(hook)函数,钩子函数的函数体则封装到内核模块中。模块化实现允许维护者在运行时随时插入、卸载模块,以随时修改 Async-fork。钩子函数由默认 fork 调用路径上的 copy_page_range 函数改进而来,它通过接收一个参数(Fast 或 Slow)来控制页表复制行为。
灵活性——Async-fork 并没有实现为一个新的系统调用,而是集成在默认 fork 中,用户可以在不修改程序原源码的情况下使用 Async-fork。我们提供了一个接口以供用户选择使用默认 fork 或 Async-fork。具体而言,我们将该接口暴露到内存 cgroup 中。当用户将进程加入内存 cgroup 组后,可以向接口写入 0(使用默认 fork)或者正整数(使用 Async-fork)以选择调用 fork 的方式。
额外开销——Async-fork 引入的额外开销来自向每个进程中的各 VMA 中添加指针(8B),因此额外的内存开销是 VMA 的数量乘以 8B,这样的开销通常可以忽略不计。
多架构支持——我们将 Async-fork 实现在 x86 与 ARM64 上。事实上,Async-fork 可以实现在任何支持 hierarchical attributes 页表的架构上。
性能优化——我们注意到当父进程触发主动同步时,父进程会陷入内核态,从而影响父进程的性能。一种减少主动同步触发的方法是加速子进程的页表复制过程,这是因为主动同步仅可能在子进程复制页表期间发生。子进程复制页表的过程越短,父进程触发主动同步的概率越低。由于进程的 VMA 是相互独立的,我们可以在子进程中启用多个内核线程并行复制各 VMA 的页表项,并获得接近线性的加速比。启动多个内核线程可能消耗额外的 CPU 资源,我们因此让这些线程周期性地检查是否应该被抢占并放弃 CPU 资源(通过调用 cond_resched 函数),以减少对其他正常进程的干扰。用户可以通过向内存 cgroup 组中暴露的接口写入正整数,以控制启用的内核线程数量。
实验数据分析
实验设置

我们首先在单机上(实验环境如上表所示)验证了 Async-fork 的有效性,其次在本节末尾的实验评估了 Async-fork 在真实生产环境中的效果。我们在流行的 IMKVS(Redis-5.0.10 和 KeyDB-6.2.0)上验证 Async-fork 的有效性,并选择了 Redis benchmark 和 Memtier benchmark 模拟多种场景的工作负载。
实验关注在快照期间到达的请求的尾延迟(p99 延迟和最大延迟)。选取了最新的基于共享页表的 fork 优化技术 On-demand-fork(ODF)作为对比。在 ODF 中,由于页表在父子进程间共享,进程每次对共享数据的修改都会触发 PMD 项与 PTE 的拷贝(页表 CoW),本文对 ODF 中的这种开销进行了分析。本文没有展示 Async-fork 与系统中默认 fork 进行对比的结果,因为在所有场景中,Async-fork 都至少十倍优于默认 fork,在部分场景甚至百倍优于默认 fork。
整体性能评估
尾延迟
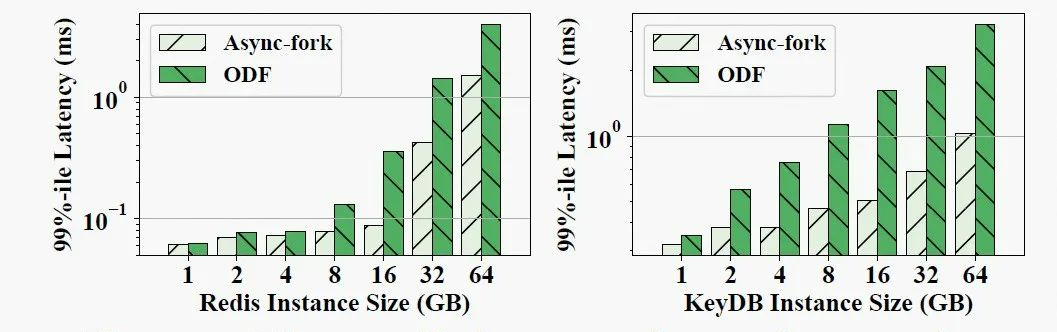
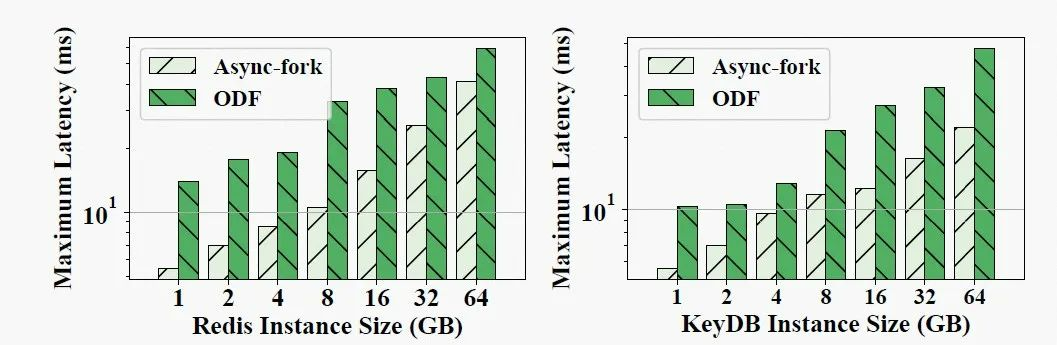
图 6 和图 7 分别展示了使用 Redis benchmark 生成写密集负载,在 Redis 和 KeyDB 中使用 ODF 和 Async-fork 生成快照时,快照期间到达请求的 p99 延迟和最大延迟。在 p99 延迟方面,Async-fork 在所有场景中都优于 ODF,并且当实例变大时,两者的性能差距会增加。例如,在 64GB 实例上运行,使用 ODF 时请求的 p99 延迟为 3.96ms (Redis) 和 3.24ms (KeyDB),而 Async-fork 将 p99 延迟减少到 1.5ms(Redis,-61.9%)和 1.03ms(KeyDB,- 68.3%)。
在最大延迟方面,Async-fork 依然优于 ODF,即使实例大小为 1GB。对于一个 1GB 的 IMKVS 实例,使用 ODF 时最大延迟分别为 13.93ms (Redis) 和 10.24ms (KeyDB),而 Async-fork 将其减少到 5.43ms (Redis,-60.97%) 和 5.64ms (KeyDB, -44.95%)。
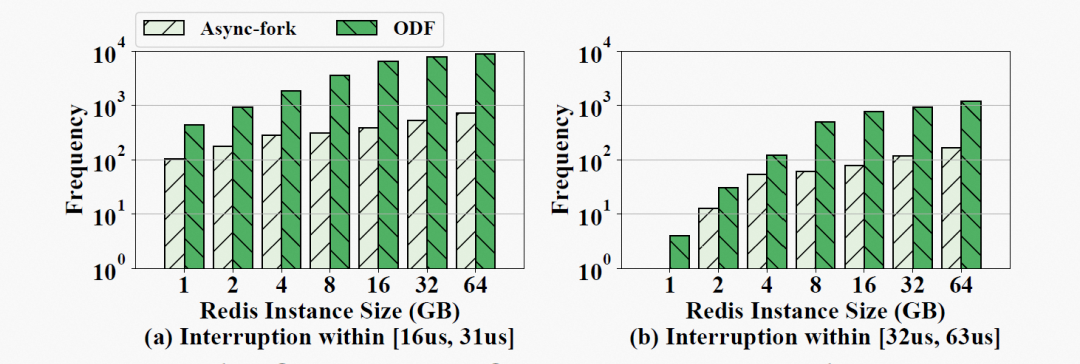
在快照期间,IMKVS(父进程)可能会中断陷入内核态,停止处理用户请求,这将损害 IMKVS 性能。Async-fork 的中断是由于父进程触发主动同步导致,而 ODF 的中断是页表 CoW 引起的。我们使用 bcc 工具统计了快照期间父进程的中断次数,以及每次中断的持续时间,以分析 Async-fork 优于 ODF 的原因。bcc 的统计结果以直方图显示(图 8),中断时长主要落在[16𝑢𝑠, 31𝑢𝑠] 和 [32𝑢𝑠, 63𝑢𝑠] 两个区间。
图 8 (a) 与 (b) 分别展示了不同 Redis 实例大小下,中断时长落在[16us, 31us]和[32us, 63us]的中断次数。我们可以发现 Async-fork 显著减少了父进程进入内核态的中断次数。例如,在 16GB 实例中,ODF 导致了 7348 此中断,而将中断次数降低到 446 次。Async-fork 大大减少了中断的原因是因为中断只有在子进程复制 PMD 项与 PTE 时才可能发生。而在 ODF 中,在子进程完成数据持久化(向硬盘写入所有数据)之前,父进程都可能会发生中断。一般来说,数据持久化的过程需要数十秒,而复制 PMD 项与 PTE 所需的时间不超过 2 秒。在相同的工作负载下,使用 ODF 时父进程更容易中断。
消融实验
读/写密集场景
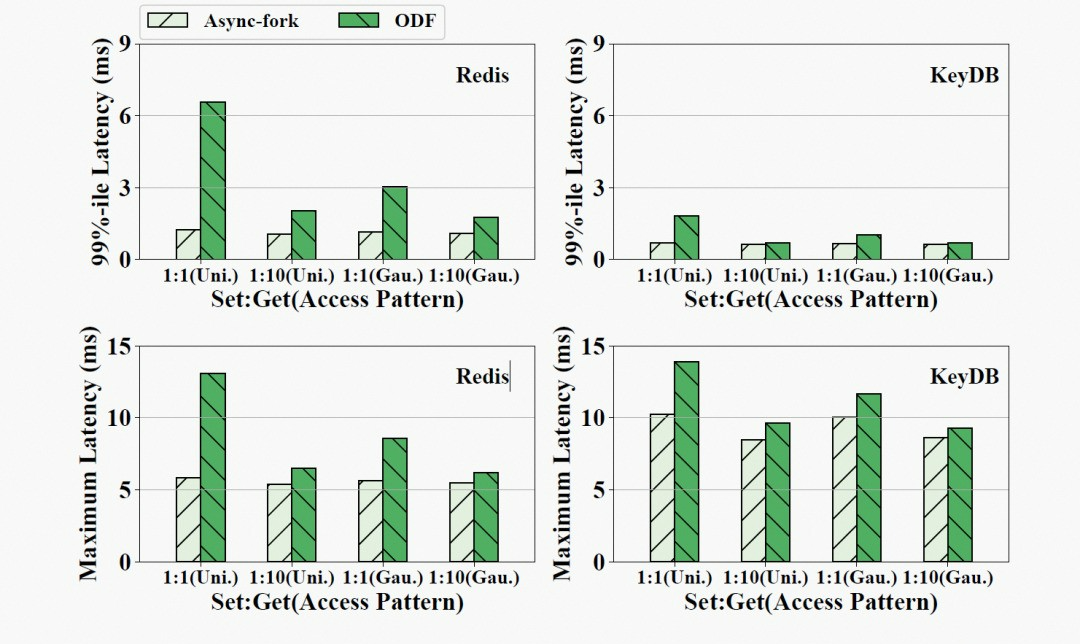
图 9 展示使用 Memtier benchmark 生成不同读写模式的四种工作负载的结果。图中“1:1 (Uni.)”代表读写比为 1:1 的均匀分布工作负载,而“1:10 (Gau.)”是读写比为 1:10 的高斯分布工作负载。从图中可见,Async-fork 在各种负载均优于 ODF。Asycn-fork 带来的收益在写请求更多的负载中表现得更为明显,这是因为父进程在读密集型的工作负载中仅需要复制少量的页表项。一般来说,Async-fork 更适合写密集的工作负载。在子进程生命周期内被修改的内存越多,Async-fork 带来的收益越多。
客户端连接数
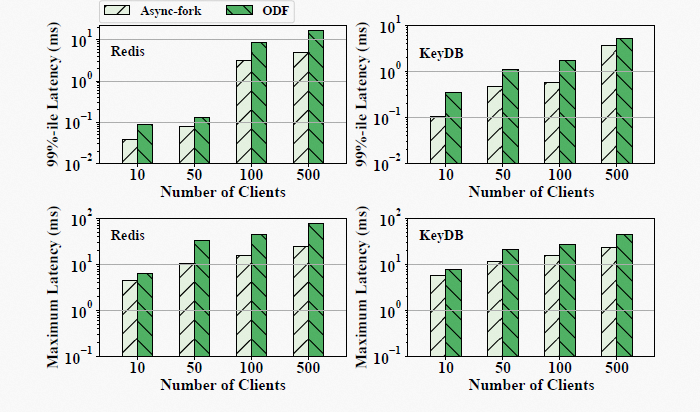
图 10 展示了在 Redis benchmark 生成的写密集负载中使用不同数量客户端连接 IMKVS 的结果。Async-fork 依然显著优于 ODF,而性能差距随着客户端数量的增加而增加。这是因为当客户端数量增加时,更多请求会同时到达 IMKVS,导致更多的 PTE 被修改,叠加排队效应,父进程中断的时间会变得更长。
用于并行复制的内核线程数
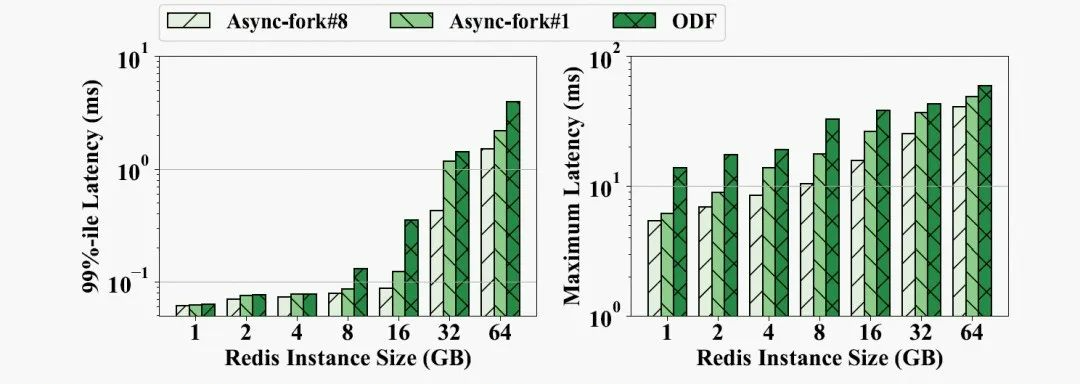
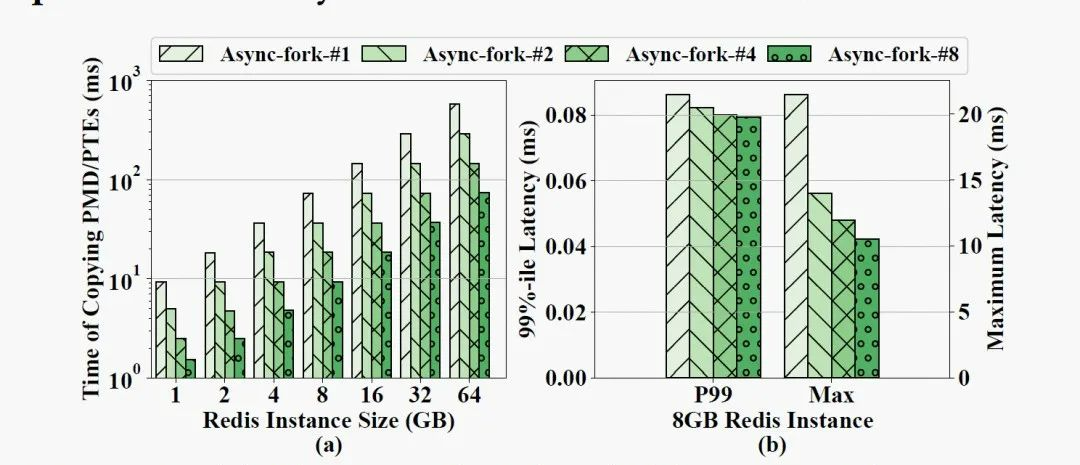
在 Async-fork 中,可以启用多个内核线程在子进程中并行复制 PMD 项与 PTE。图 11 显示了在不同 Redis 实例大小下快照期间请求的 p99 延迟和最大延迟。Async-fork-#i 代表总共使用 i 个线程并行复制的结果。观察发现,Async-fork-#1(仅子进程自己)仍然带来比 ODF 更低的延迟。与 ODF 相比,最大延迟平均降低了 34.3%。
另一方面,使用更多线程(Async-fork-#8)可以进一步降低延迟。这是因为子进程越早完成 PMD 项与 PTE 的复制,父进程触发主动同步的概率就越低。图 12(a) 显示了子进程使用不同数量的内核线程复制 PMD 项与 PTE 所花费的时间,而图 12(b) 显示了 8GB Redis 实例中相应的 p99 延迟和最大延迟。正如我们所见,使用更多的内核线程有效地减少了在子进程执行复制的时间,而这个时间越短则相应的延迟越低。
Fork 调用时长
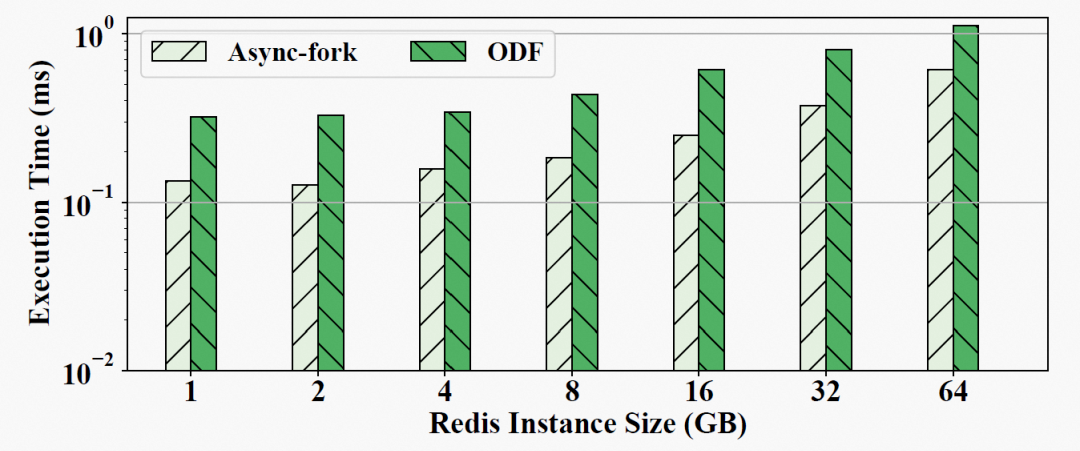
父进程 fork 调用的持续时间极大地影响了快照期间请求的延迟。图 13 显示了父进程在不同 Redis 实例大小下从 Async-fork 和 ODF 调用中返回的时间。在 64GB 的实例中,父进程从 Async-fork 中返回用时 0.61ms,从 ODF 中返回用时 1.1ms(而从默认 fork 中返回用时可达 600ms)。还可以观察到 Async-fork 的执行比 ODF 稍快,一个可能的原因是 ODF 为实现页表 CoW 需要引入额外计数器,从而导致了初始化的额外时间成本。
生产环境中的效果
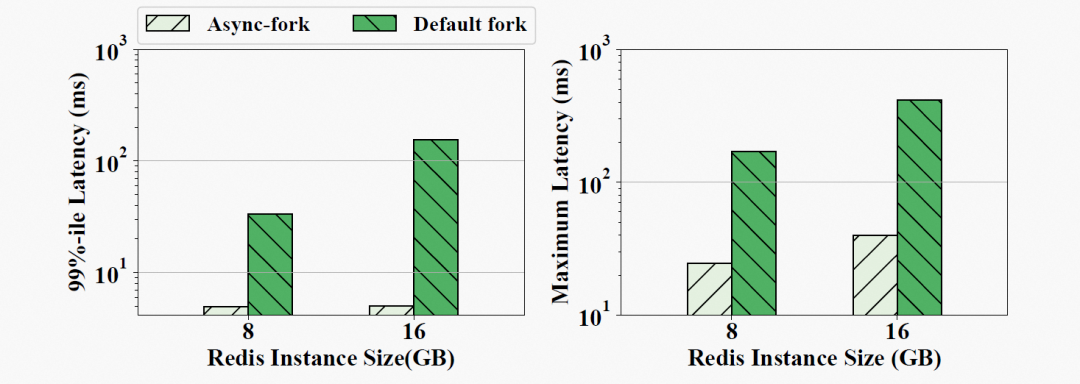
Async-fork 已部署在我们的 Redis 生产环境中。我们在公有云中租用一个 Redis 服务器来评估生产环境中的 Async-fork 使用效果。租用的 Redis 服务器有 16GB 内存和 80GB SSD。我们还租用了另一台具有 4 个 vCPU 和 16GB 的 ECS 作为客户端运行 Redis benchmark。
图 14 展示了使用默认 fork 和 Async-fork 时,快照期间到达请求的 p99 延迟和最大延迟。对于一个 8GB 的实例,请求的 p99 延迟从 33.29 ms 减少到 4.92 ms,最大延迟从 169.57 ms 减少到 24.63 ms。对于 16GB 的实例,前者从 155.69ms 减少到 5.02ms,而后者从 415.19ms 减少到 40.04ms。
总结
本文关注于内存键值对数据库在使用 fork 拍摄快照时引起的请求尾延迟激增问题,并从操作系统的角度解决了该问题。通过对 fork 的深入分析,本文揭示了它对数据库请求延迟的造成影响原因,并针对大内存实例的场景提出了优化方法——Async-fork。
Async-fork 设计的核心思想在于将复制页表的工作从父进程转移到子进程来。为保证一致性,我们设计了高效的主动同步机制。Async-fork 在 Linux 内核中实现并部署于 Redis 生产环境中。实验结果表明,Async-fork 可以显著降低快照期间的请求尾延迟。与默认 fork 相比,在 8GB 实例中减少 81.76% 的尾延迟,在 64GB 实例中减少 99.84% 的尾延迟。




