
本文整理自微软亚洲研究院研发工程师张鑫在 QCon 2023 的演讲分享,主题为“基于 NNI 的 Transformer 系列模型压缩实践”。
分享从四个方面展开。第一部分介绍一站式 AutoML 工具 NNI,第二部分介绍模型压缩模块,第三部分介绍基于 Transformer 系列模型的压缩实践,最后是结论。
前言
大家上午好,我叫张鑫,是微软亚洲研究院的一名研发工程师。今天非常荣幸能够站在这里和大家分享我们的工作,今天分享的大主题是机器学习模型效率与易用性,下面我将基于 NNI 的 Transformer 系列模型压缩实践为大家进行介绍,我将从以下 4 个方面为大家进行介绍。
首先我将向大家介绍 NNI 这个一站式的自动机器学习工具,接下来我将和大家一起分析一下大模型的发展现状,并向大家介绍一下 NNI 中模型压缩模块的 Pipeline 及各方法的运行原理。随后我们将使用 NNI 中的模型压缩模块,在 Transformer 系列模型上进行一系列的压缩实践。在这个板块中,我们将首先和大家一起回顾一下 Transformer 的模型结构,并对 Transformer 系列的模型进行分析。接下来我们会给出详细的压缩流程和具体的实验结果,最后进行总结。
NNI:一站式 AutoML 工具

NNI 是一个开源的自动机器学习工具,它非常容易安装,且与现有的工具包环境兼容,用户在使用 NNI 时无需修改现有的 Python 代码即可轻松使用。同时 NNI 还为用户提供了简单的命令行和可视化的工具支持。NNI 中包含了多种主流算法,其能快速适应最先进的算法,具有极强的可扩展性,能够轻松集成自主开发的算法,我们可以把开发的算法部署到不同的平台上,尤其是云端。

下面我们看一下 NNI 的具体模块构成。如图所示可以看到 NNI 中主要包含 4 个主要模块,第一个是神经网络架构搜索,也就是现在说的 NAS,其致力于为给定的任务寻找最优的网络结构。
第二个是超参调优模块,也就是这里的 HPO 模块,即致力于用较少次数的尝试帮助用户自动化调优参数,以提升模型的性能。
第三个是模型压缩模块,其致力于在尽可能少的降低模型精度的情况下,尽量的减少模型的参数和计算复杂度,以获得较低的计算延时。
最后一个是特征工程模块,其致力于为机器学习算法抽取重要的特征,同时 NNI 也为用户提供了命令行工具和可视化的 Web 界面,以帮助用户批量化管理实验。
此外 NNI 还提供了对多种计算资源的支持,如远程子服务组训练平台等,最大可能地方便用户的使用。
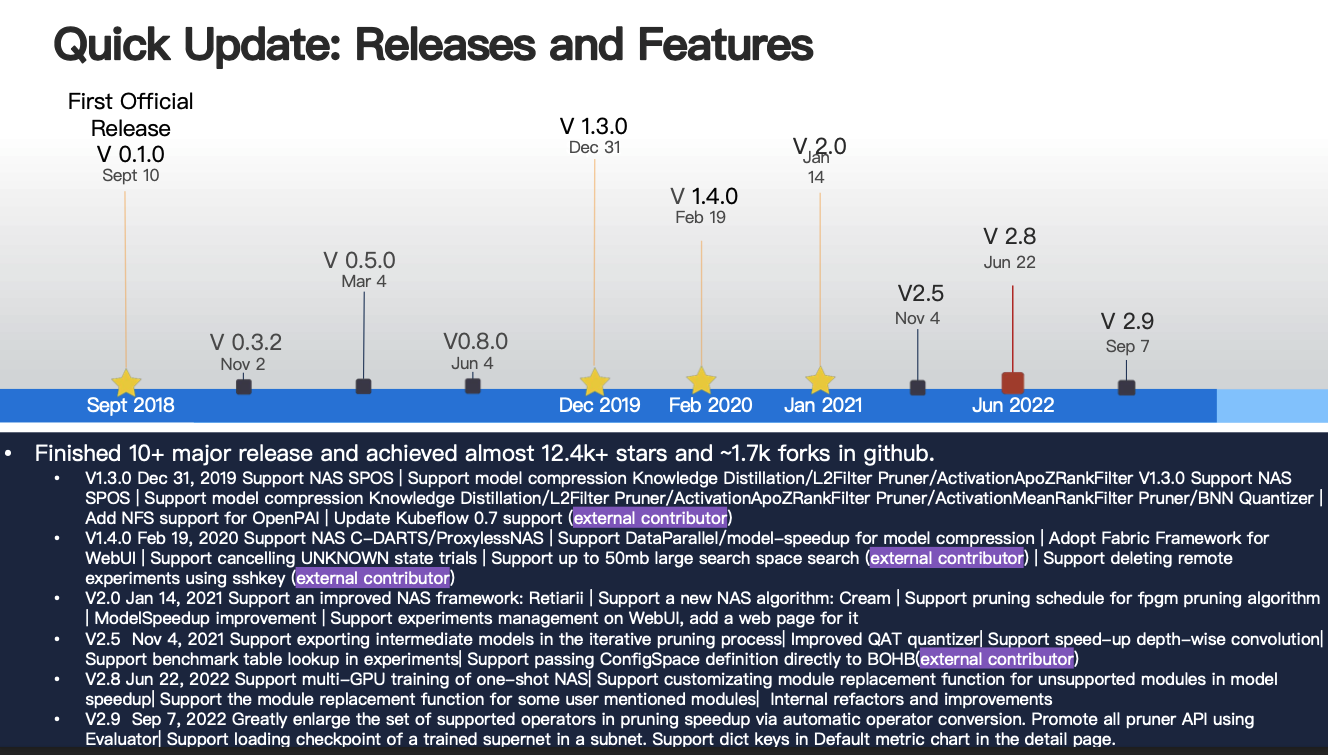
本次重点向大家介绍我们的模型压缩模块,自 2018 年以来 NNI 已发布了多个版本,其凭借着强大的功能和易用性,在 GitHub 上已收获了 12.4k 的 Star,合约 1.7k 的 Folk,在即将发布的 v3.0 版本中,我们的大部分模块也将迎来重大更新,特别是我们 NNI 中的模型压缩模块,其在现有的量化剪枝模块的基础上,进一步引入了蒸馏模块,实现了蒸馏、剪枝、量化的一体化。
模型压缩模块
大模型发展现状
在正式介绍模型压缩模块的工作原理前,让我们先一起来看一下大模型的发展现状,大规模预训练模型在人工智能领域扮演着重要的角色,其极大地推动了各领域的发展,然而随着模型规模的爆炸式增长,现有的计算资源已经越来越难以负担大规模模型的学习。
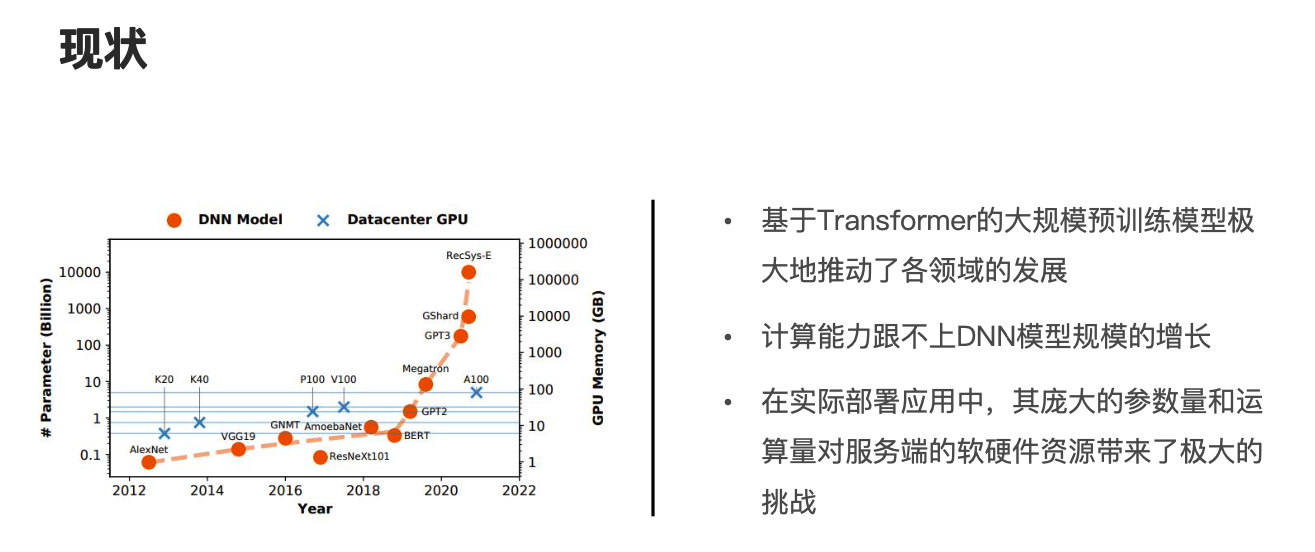
图片来源:https://arxiv.org/pdf/2202.01306.pdf
如图所示,我们可以看到从 BERT 到 GPT3 再到 GShard,其模型参数从几亿规模逐渐爆炸式增长到了千亿、万亿级别。
同时我们可以发现在实际的部署应用中,其庞大的参数量和运算量对服务端的软硬件资源带来了极大的挑战,因此模型压缩成为了模型部署前不可缺少的重要环节。
然而由于模型压缩的技术和方法的多样性,且涉及模型推理延迟的编译优化,使得模型压缩过程变得繁琐而复杂,因此为了打通从模型压缩到模型加速的整个流程,我们开发了 NNI 的模型压缩模块,即包含了当前主流的模型压缩算法,剪枝量化和蒸馏,下面分别简单介绍一下这三种方法。

量化方法是对模型中的权重激活从高精度转化为低精度的过程,比如说将模型中的权重从 float32 转化为整型 int8,那么考虑到模型中存在大量的冗余参数,即使去除这部分的冗余参数,也不会影响模型的拟合能力。
因此可以使用剪枝的方法去除模型中的冗余参数,从而降低模型的参数量。
而蒸馏的方法则是让小模型,也就是这里的学生模型去学习大模型,也就是教师模型中的有效知识,从而提升自身的泛化能力。
模型压缩模块的 Pipeline 及各方法的运行原理
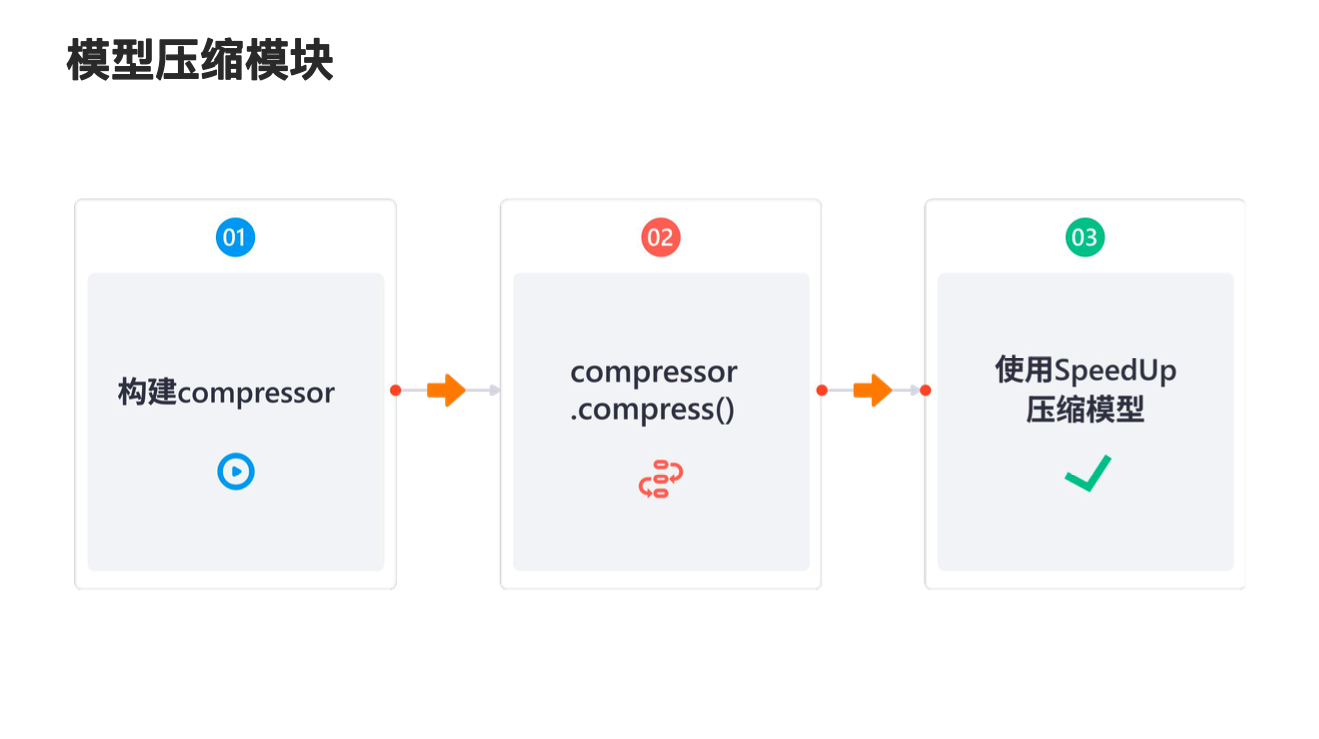
下面让我们来详细看一下模型压缩模块是怎么工作的。对于用户而言,使用 NNI 的模型压缩模块是非常容易的,只需要三步,如图所示,这里我们统一将量化、蒸馏、剪枝方法称为 compressor。对于用户而言,首先只需要根据自己具体的任务选择构建合适的 compressor 实例,接下来只需要调用 compressor.compress() 函数即可执行模型的整个模拟压缩过程。
最后我们在使用 NNI 中的 SpeedUp 模块对模型进行压缩,实现真正意义上减少模型的参数量,下面对这三块进行讲解。
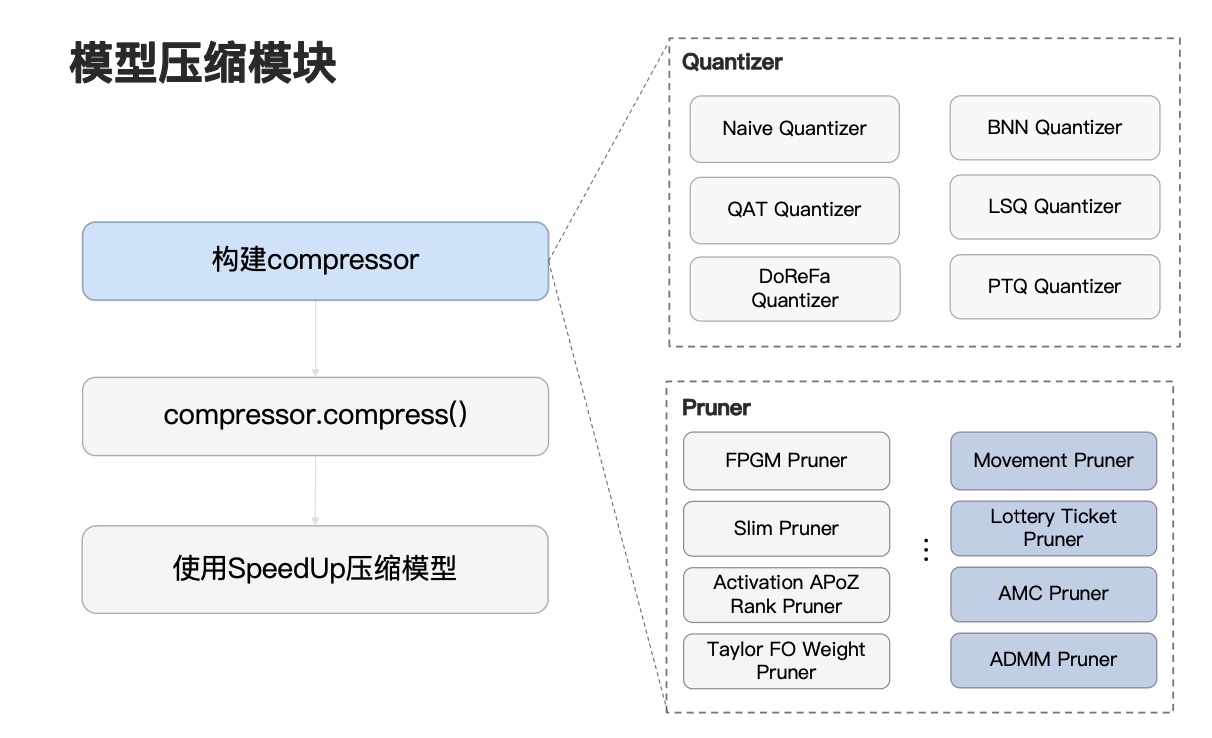
在 NNI 中构建一个 compressor 实例对用户来说是非常容易的,在 NNI 的剪枝量化模块,我们已经集成了大量的前沿算法,比如说在剪枝中,我们为用户提供了 ADMM、Slim、Taylor、Movement 等多种前沿剪枝算法,又如在量化中,我们也为用户提供了诸如 QAT、LSQ、PTQ 等多种前沿量化算法,对于用户而言,只需要根据自己的具体任务,选择相应的方法进行实例化即可。
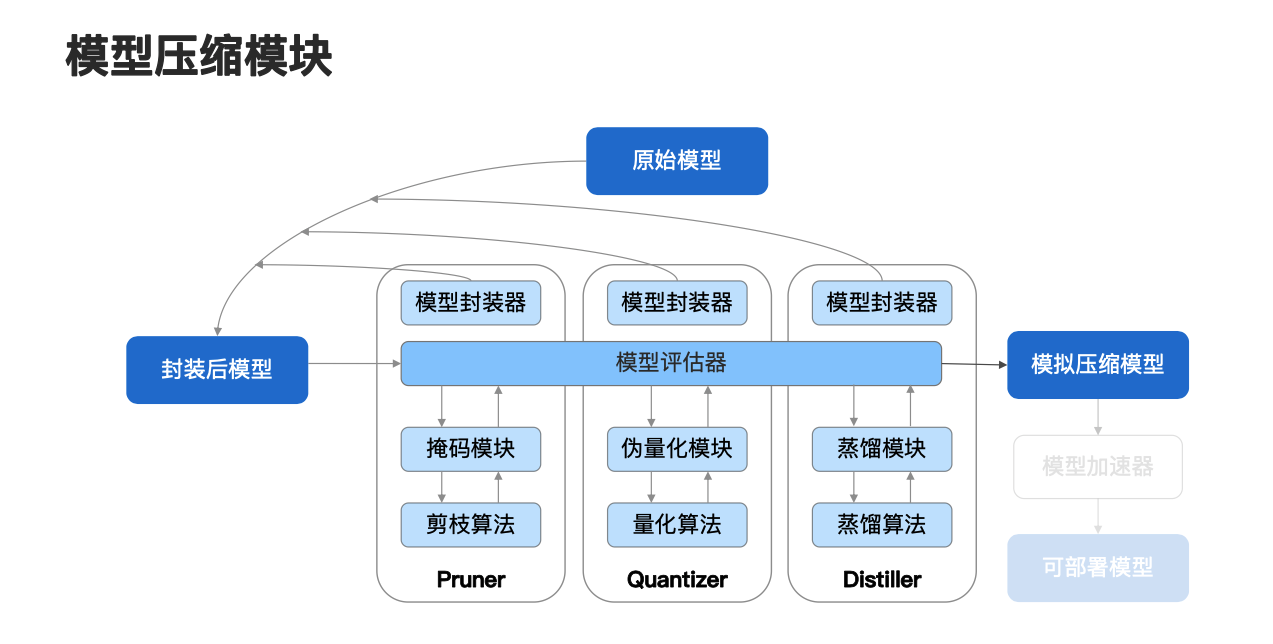
那么在创建了相应的 compressor 实例之后,我们只需要调用 compressor.compress() 函数,即可执行模型的模拟压缩过程。那么它具体是怎么工作的?大家可以看一下上图,对于一个原始模型,NNI 中的模型压缩模块首先会使用模型封装器对原始模型进行封装,并将封装后的模型传入模型评估器中,并和相应方法的模块进行交互,重复上述过程并返回一个模拟后的压缩模型,这就是我们整个模型的模拟压缩过程。
这里不同方法对应着不同的交互模块,比如说从图上可以看到,在剪枝方法中它对应的就是掩码模块和剪枝算法,在量化中它对应的就是伪量化模块和量化算法,而在蒸馏中对应的就是蒸馏模块和蒸馏算法,下面以剪枝来说明整个模型的模拟压缩过程。
首先对于封装后的模型将其传入模型评估器中,我们使用相应的掩码模块,收集模型目标值的有效信息,并将该有效信息传递给剪枝算法,剪枝算法根据具体的算法流程会对掩码进行计算和更新,并将更新后的值回传给掩码模块,在掩码模块这里,对目标直径用掩码进行更新,并将更新后的掩码回传给模型评估器,参与计算过程。
重复上述过程就是我们整个模型的模拟压缩过程,这是从整体结构上来看,下面我们从一个更细腻度的角度来看这个问题。
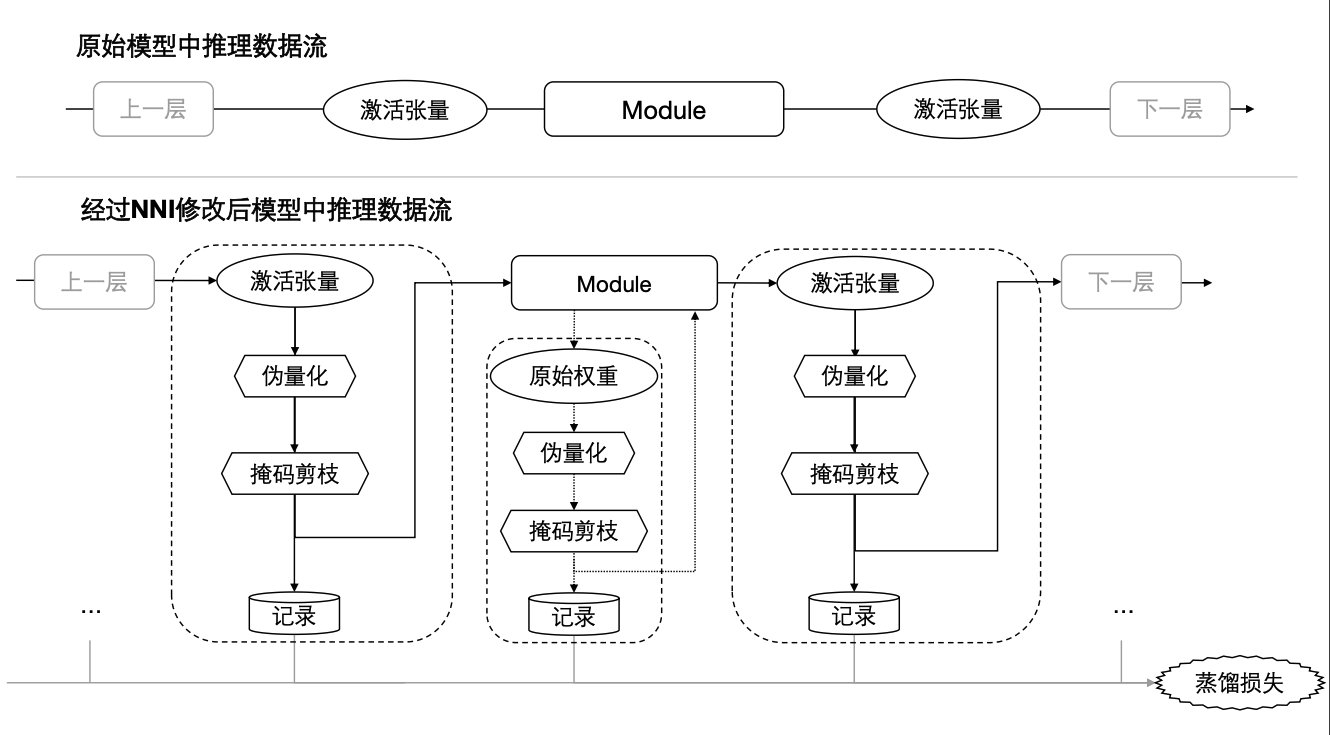
我们现在着眼于模型中的一个子 Module,来看一下当我们使用具体的压缩方法后,它的推理数据流具体是怎么做的。
首先我们可以看一下图中最上面部分,先看一下原始模型中的推理数据流是怎么做的。首先从上一层中传入一个激活张量到当前 Module 中,当前 Module 会使用传入的激活张量和参数进行运算,并输出一个激活张量到下一层。那么经过 NNI 修改后,模型中的推理数据流又是怎么做的?如图所示,首先对于从上一层中传入的激活张量,我们需要使用相应的压缩方法对它进行更新,比如说如果我们使用的是量化方法,那么就用这里图上的伪量化模块对激活张量进行更新,如果我们使用的是剪枝方法,就直接用掩码剪枝模块对激活张量进行更新,如果我们用的是蒸馏方法,那么我们只需将激活张量记录下来即可,将更新后的激活张量传入到 Module 当中,并对 Module 中的参数,也就是图中的原始权重,采用类似的方法进行更新,得到更新后的参数,将更新后的参数和刚刚更新后的激活张量进行一个运算,并输出一个激活张量,并对输出的激活张量进行类似的操作,并将更新后的激活张量传入到下一层。
我们对比上下两个图可以发现,当我们使用压缩方法后,和之前原始的推理数据流的差异就在于,我们对输入输出的激活张量以及模型的参数,使用相应的压缩方法进行了更新,而不同的压缩方法所使用的更新方式是有所不同的,这里对应的就是图上的伪量化、掩码、剪枝和记录,那么他们具体是怎么工作的?下面让我们具体来看一下。
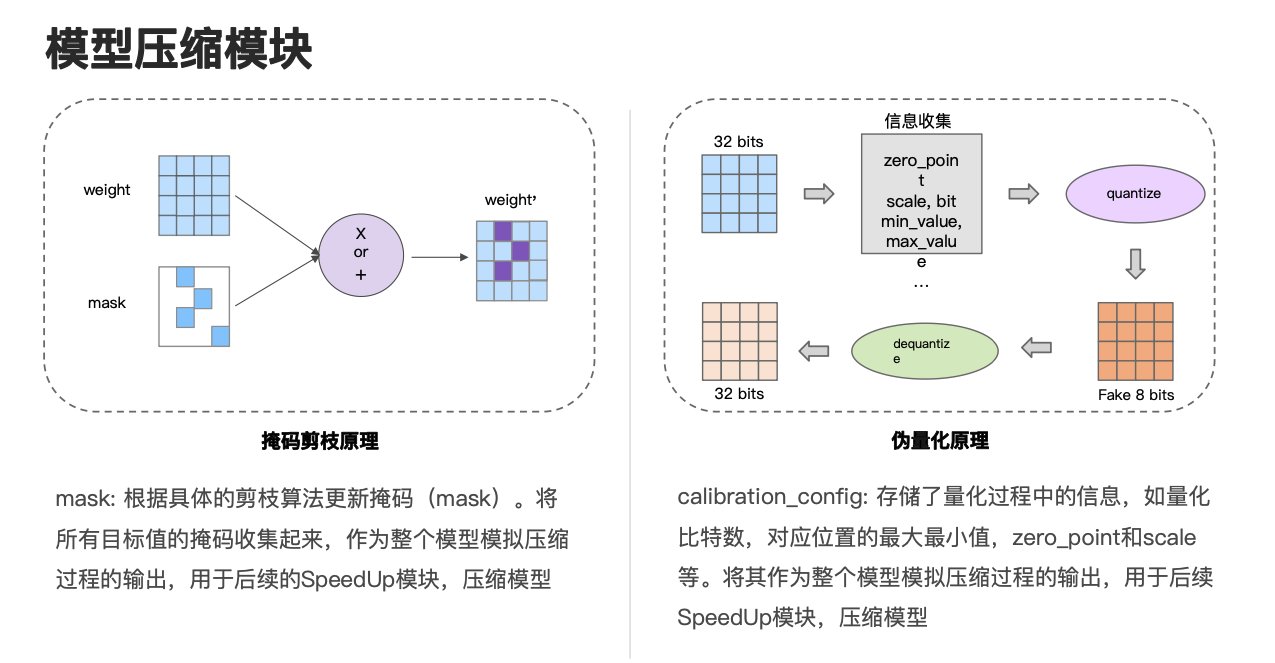
首先向大家介绍一下掩码剪枝的工作原理。在前面我们已经提到,通过具体的算法,我们会使用具体的剪枝算法更新相应的掩码,更新后的掩码就对应图上的 mask,并将更新后的掩码和我们的目标值,也就是图上的 weight 进行运算,得到更新后的目标值,也就是这里的 weight',这里的更新方式做的运算有两种,一种是乘法,一种是加法,具体用乘法还是加法取决于具体的 OP。我们会将所有目标值的掩码收集起来,作为整个模型模拟压缩过程的输出,以用于后续的 SpeedUp 模块压缩模型。
接下来向大家介绍我们的伪量化模块,大家可以看一下右边的图,首先我们传入一个 32 Bit 的目标值,在伪量化模块中,我们先会对它进行信息收集,比如说我们会收集目标值的最大最小值,包括它要量化的比特数等信息,并根据这些信息去计算它的 zero_point 和 scale 等信息,并利用这这些信息对目标值进行量化,以得到一个目标值的范围在 8 比特,目标数据类型仍然为 32 比特的值,也就是图上的 Fake 8 bits,我们接下来会对其再反量化,就又重新得到了一个 32 比特的值,这就是伪量化模块的工作流程。
在这个过程中,我们会将伪量化模块收集到的部分信息存储在 Calibration_config 中,并将其作为整个模型模拟压缩过程的输出,以用于后续 SpeedUp 模块去压缩模型。
下面来看一下蒸馏的具体工作方式,因为蒸馏方法它其实和量化还有剪枝有所不同,蒸馏的目标主要是让小模型学习大模型中的有效知识,因此在记录模块中,只需要将目标值记录存储下来即可。
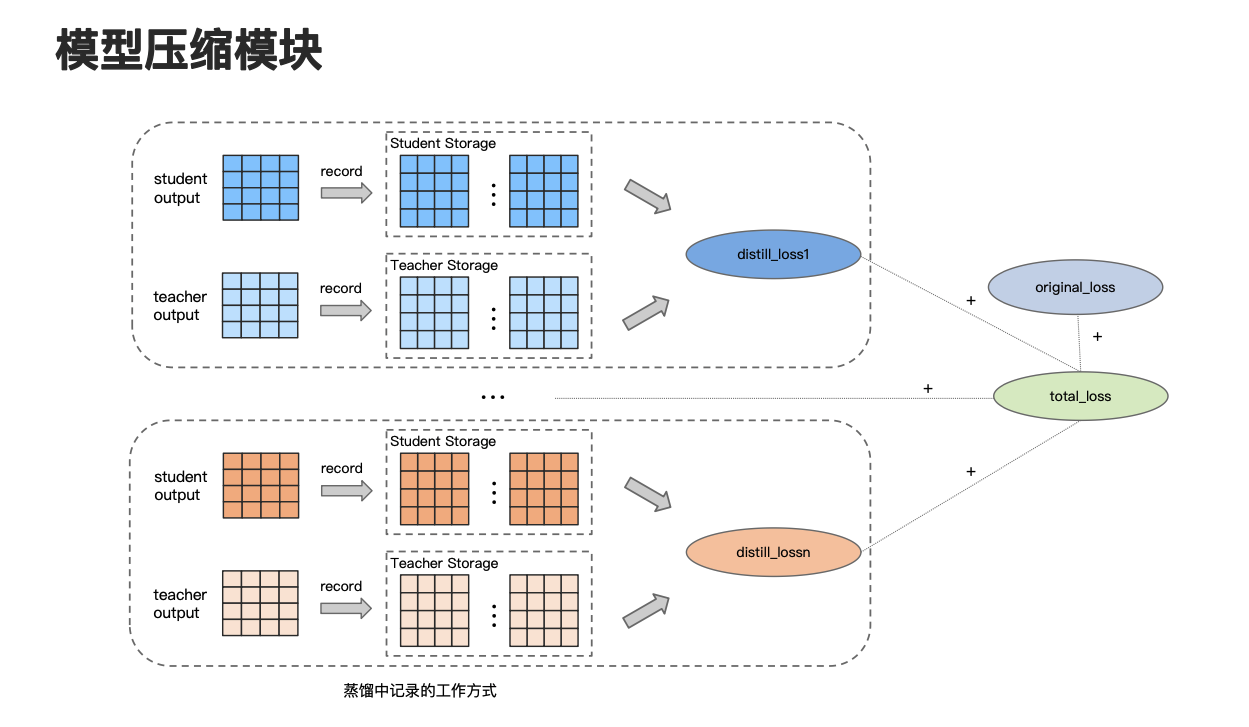
可以看一下这个图,比如说第一个虚线框里,我们需要分别把学生模型和教师模型中的有效值和目标值收集下来,并根据存储的信息计算相应的蒸馏 loss,将所有的蒸馏 loss 和原始的 loss 进行加权求和,就可以得到总 loss。
在介绍了模型的模拟压缩过程后,接下来看一下最后一步,使用 SpeedUp 模块压缩模型, SpeedUp 模块是用于剪枝或者量化后对模型的实际压缩过程。这里举例说明一下,比如说在我们常用的剪枝算法中,常规做法是直接将冗余参数的值置为 0,此时参数的维度没有改变,参数量也并没有改变,但是如果我们调用 SpeedUp 模块的话,它能够将冗余参数从参数中移除,从而实现真正意义上的减小模型的参数量,减小模型参数的一个实际维度。那么它具体是怎么工作的呢?下面我们用剪枝进行举例,看一下在剪枝过程中 SpeedUp 的具体流程。
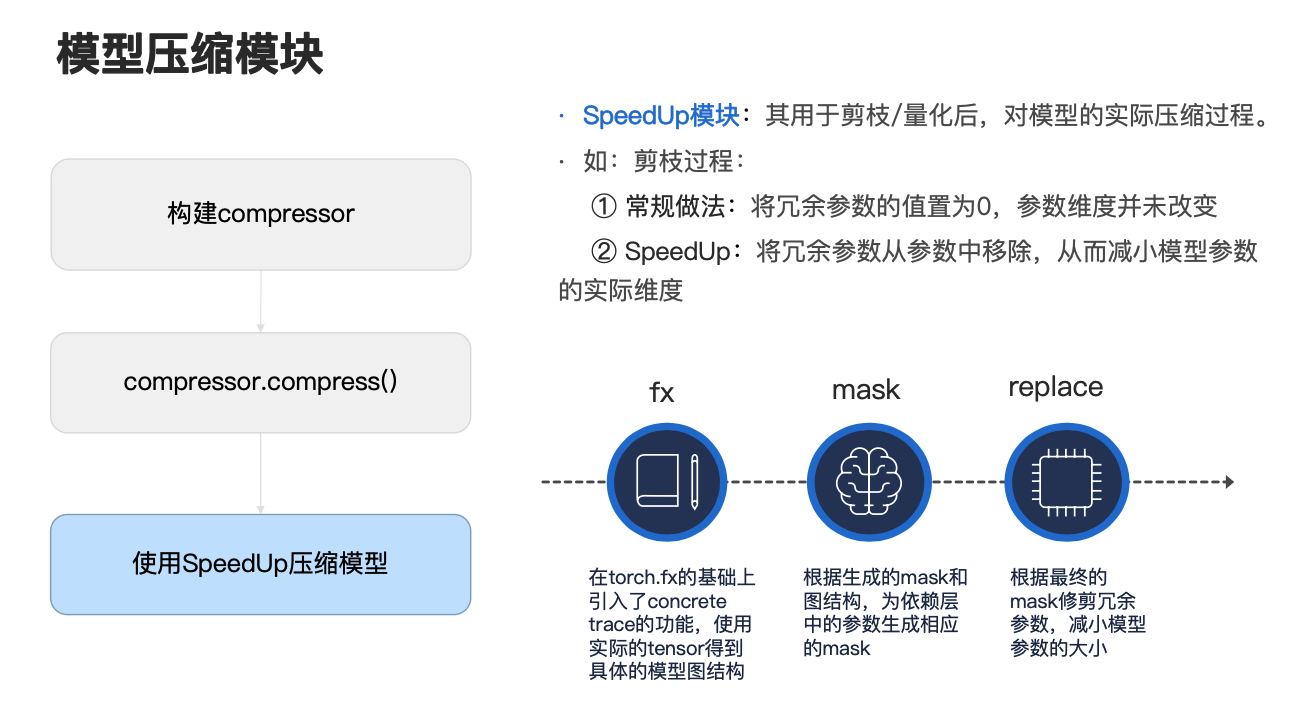
大家可以看一下右下方这个图,首先我们的 SpeedUp 模块它在 torch.fx 的基础上引入了 concrete trace 的功能,因此我们可以使用实际的 tensor 以得到具体的模型图结构。接下来我们会根据得到的具体的模型图结构和在左边这个图第二步的模拟压缩过程所拿到的掩码,为依赖层中的参数生成相应的掩码,这里说明一下,因为在一个模型中,参数的维度在上下层之间是存在依赖关系的,因此如果我们对当前模型参数的维度进行修剪的话,那么我们就需要把上下间存在依赖关系的模型的相应维度也进行修剪,这样才能保证剪枝后的模型仍然能够正常使用。
最后我们会根据最终的掩码修剪冗余的参数,以减小模型参数的大小。这里我们 NNI 里目前已支持 PyTorch 中绝大部分运算,对于尚未支持的运算,用户只需自己定义一个替换函数就可以正常使用。
基于 Transformer 系列模型的压缩实践
在介绍了我们模型压缩模块的工作原理后,下面让我们在 Transformer 系列模型上进行一些压缩实践。
Transformer 模型结构
图片来源:https://arxiv.org/pdf/2202.01306.pdf
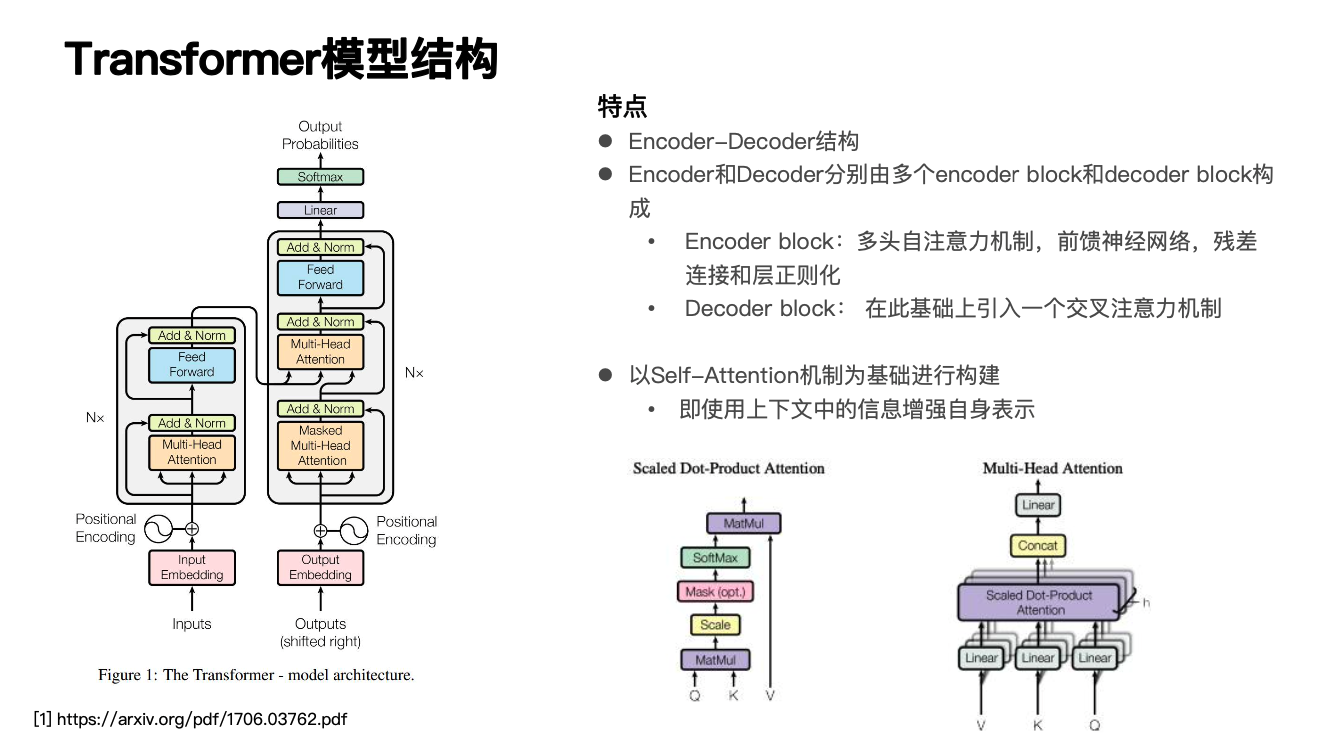
在正式介绍我们的压缩实践流程前,让我们先一起来回顾一下 Transformer 的模型结构。可以看到左边这个图,如图所示是 Transformer 主要由嵌入层、编码器和解码器构成,我们这里重点说一下它的编码器和解码器结构。先看左边图的左半部分,可以看到编码器是由 n 个 block 堆叠而成,每个 block 中主要由一个多头自注意力机制和前馈神经网络单元所构成,那么它的多头自注意力机制其实是 Transformer 里比较核心的部分,因为它能够让 Transformer 在训练时实现并行计算,那么它具体是怎么工作的?首先我们从名字拆解一下,多头自注意力机制说明是自己对自己的关注,因此它的 Query、Key、Value,也就是在右下图的 Q、K、V,它们都是自身,然后另外一个多头则是为了捕获多个粒度的信息,以增强隐藏层的状态表示。
可以看一下右下方这个图,它的大概流程是比如说对 Query、Key、Value,也就是在右下图的 Q、K、V,分别经过线性层做一个运算,接下来会对 Q 和 K 做一个运算,以得到当前位置对上下文中每个位置的一个关注程度的分数,我们会基于该分数和 Value 进行加权求和,从而实现用上下文中的隐藏层状态表示,去增强当前位置的隐藏层状态表示。
那么我们回到 Transformer 的结构图,可以发现右边这部分解码器的结构和编码器的结构是非常类似的,它也是由 n 个 block 堆叠而成,但它在编码器的基础上进一步还引入了一个交叉注意力机制模块,这个模块和自注意力模块的差别就在于此时它的 Query 是解码器的隐藏层状态表示,而它的 Key 和 Value 则是编码器的隐藏层状态表示。这样做的好处是我们能够用编码器的隐藏层状态表示去增强当前解码器的隐藏层状态表示。
Transformer 系列模型分析
图片来源:https://arxiv.org/pdf/2002.11985.pdf
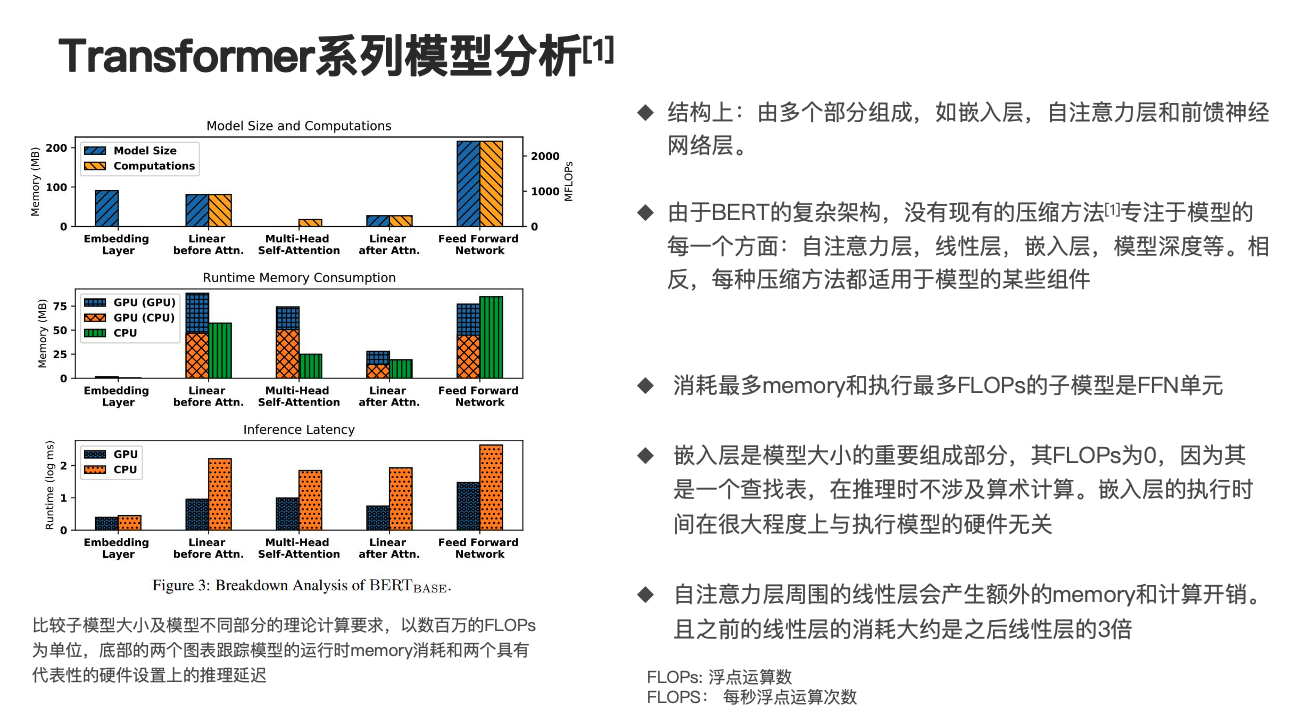
从上面的分析可以发现 Transformer 的结构稍微复杂一些,由多个部分组成,比如说嵌入层、自注意力层和前馈神经网络层,那么我们进一步对 Transformer 系列模型 BERT 进行分析,大家可以看一下左边这个图,有研究者对 Bert-base 在长度为 256 的句子上进行了推理,以比较子模型大小及模型不同部分的理论要求,其以数百万的 FLOPs 为单位,底部的两个图表则跟踪了模型运行时的 memory 消耗和两个具有代表性硬件设置上的推理延迟。
我们分析这个图可以发现消耗最多 memory 和执行最多 FLOPs 的子模型是 FFN 单元,这里的 FFN 就是我们说的前馈神经网络,而嵌入层是模型大小的重要组成部分,其 FLOPs 虽然为 0,因为它是一个查找表过程,在推理时不涉及任何算术计算,因此嵌入层的执行时间在很大程度上与执行模型的硬件无关。
最后我们会发现自注意力层周围的线性层会产生额外的 memory 和计算开销,且之前的线性层的消耗大约是之后线性层消耗的三倍。
大家可以从第二个图前面有一个 Linear before Attn 和 Linear after Attn 看出来,该研究者进一步指出,由于 BERT 的复杂架构,没有现有的压缩方法专注于模型的每一个方面,比如说自注意力层、线性层、嵌入层、模型深度等,相反每种压缩方法都适用于模型的某些组件,这就为 Transformer 系列模型的压缩带来了一定的困难性和繁琐性。
NNI 对于 Transformer 系列模型压缩的优势
然而幸运的是我们的 NNI 模块它是天然的适用于 Transformer 系列模型压缩的,NNI 中的模型压缩模块,它具有易用的算法框架,并且它集量化、剪枝及蒸馏于一体,三种方法都能够联合使用,同时它拥有大量的前沿算法,能够非常方便地针对模型的不同部分使用不同的算法。另外 NNI 还为用户提供了 SpeedUp 模块,其能够实现真正意义上的减少模型的参数量,打通了从模型压缩到模型加速的整个流程。NNI 还为用户提供了详细的 tutorial 和文档教程,帮助用户快速上手使用。
压缩流程实践
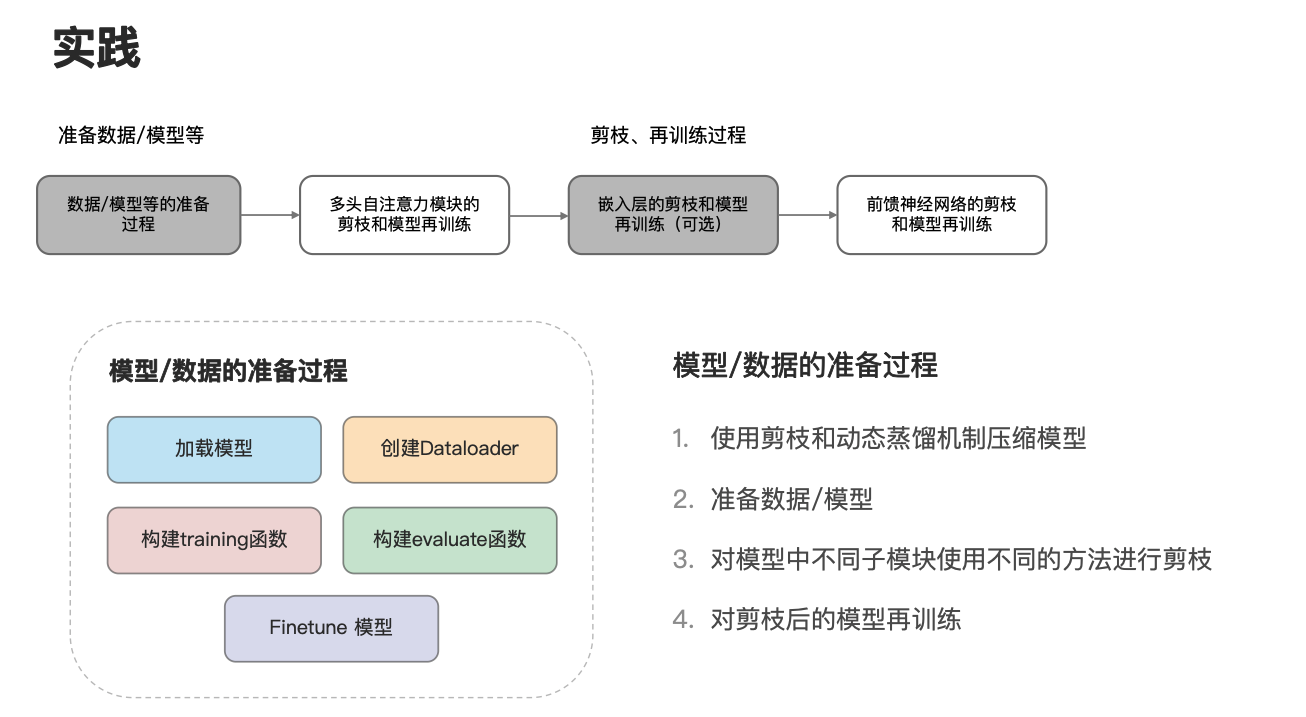
下面让我们来看一下我们具体的实践流程,从之前的分析我们可以发现,前馈神经网络层是消耗最多内存和执行最多 FLOPs 的子单元,因此我们需要对前馈神经网络进行压缩。
另外我们还考虑对多头自注意力模块和嵌入层进行压缩,在本次实践中我们将主要采用剪枝的方法对模型进行压缩,同时为了避免在模型压缩后损失过多的精度,我们将对压缩后的模型再训练。
这里的模型再训练有两种方式,第一种是直接对模型进行 fine-tune,另外一种是用动态蒸馏机制对模型进行再训练。
下面我们统一用动态蒸馏机制进行讲解,总的实践流程可分为 4 步,如图所示,首先我们需要准备数据模型等,接下来需要针对多头自注意力模块、嵌入层及前馈神经网络分别进行剪枝和再训练。这里说明一下这里的多头自注意力模块的剪枝和模型再训练,在后续中也可以指代对 Transformer 中 Decoder 的交叉注意力模块的剪枝和模型再训练。
先看一下模型数据的准备过程。如图所示,首先我们需要加载或者创建一个模型,接下来选择合适的数据集,并创建相应的 Dataloader,接下来构建相应的训练评估函数,并对模型进行 Finetune。
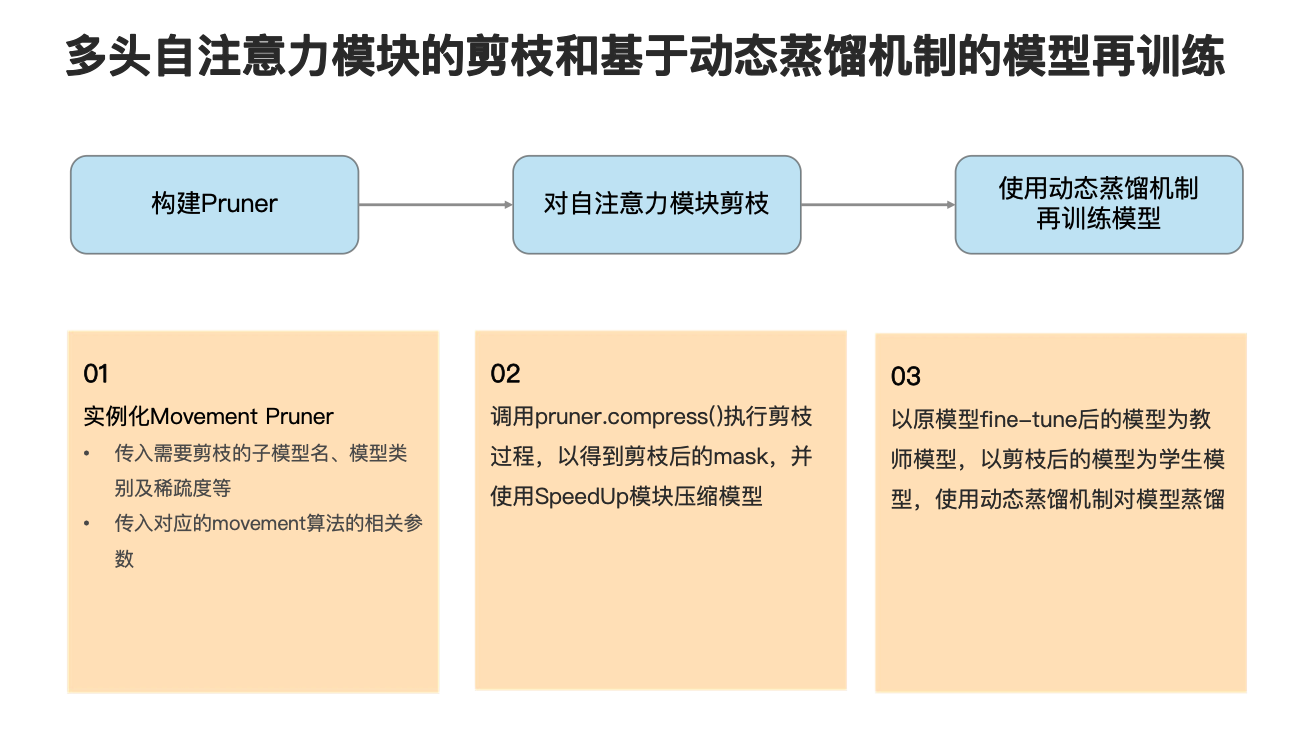
下面来看一下多头自注意力模块的剪枝和再训练过程。该过程可分为三步,如图所示,首先需要构建相应的 Pruner 实例,也就是刚刚提到的 compressor 实例,接下来需要对自注意力模块进行剪枝,最后是使用动态蒸馏机制再训练模型,下面进行一一说明。
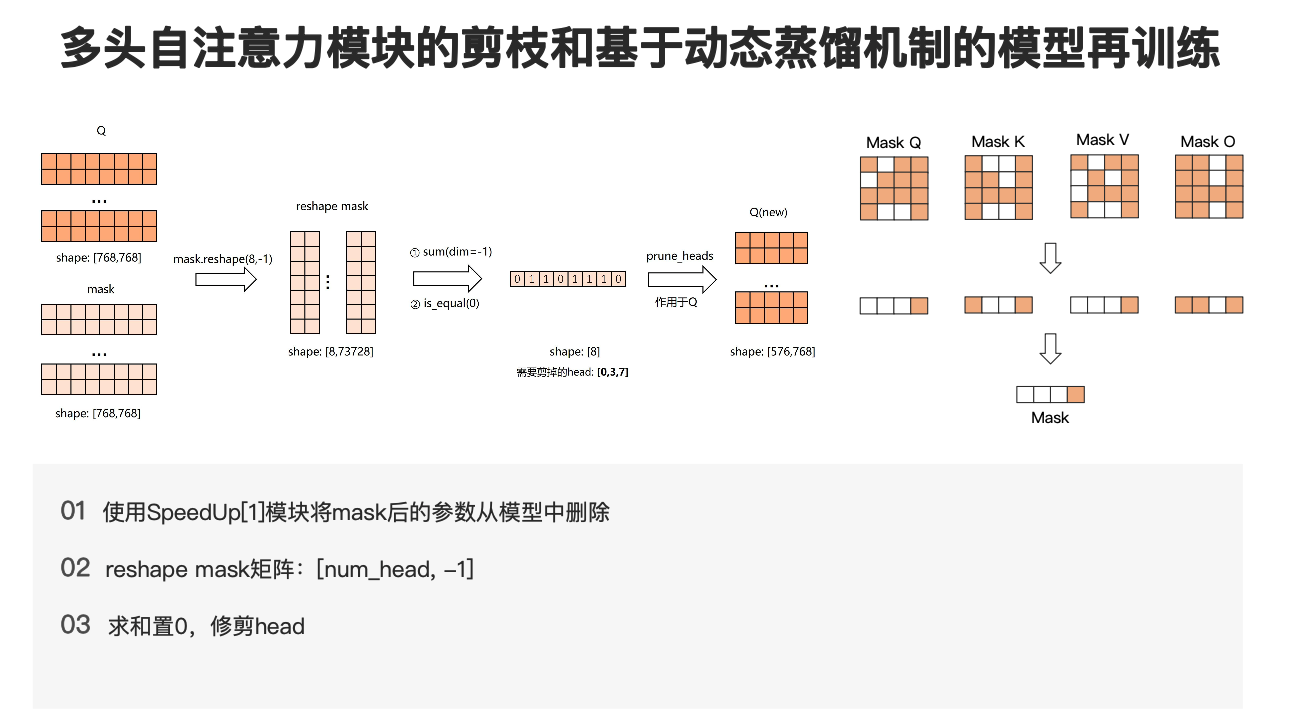
首先在对多头自注意力模块进行剪枝中,使用了 Movement 剪枝算法,因此我们将需要剪枝的子模型名、模型类别及稀疏度,以及 Movement 算法的一些参数传入,以实例化一个 Movement Pruner。这里说明一下在 Movement 算法中有两种模式,一种是 soft 模式,一种是 hard 模式,在 soft 模式下我们根据 threshold 对模型进行修剪,因此我们无法精确控制剪枝后模型的稀疏度,而在 hard 模式下,剪枝后模型的稀疏度就是我们的目标稀疏度。
接下来我们会调用 pruner.compress() 以执行剪枝过程,得到剪枝后的 mask 将这个掩码 mask 传入 SpeedUp 模块用于后续的模型压缩过程。
最后我们以原模型 fine-tune 后的模型为教师模型,以剪枝后的模型为学生模型,使用动态蒸馏机制,对模型进行蒸馏,尽可能的恢复模型的性能。
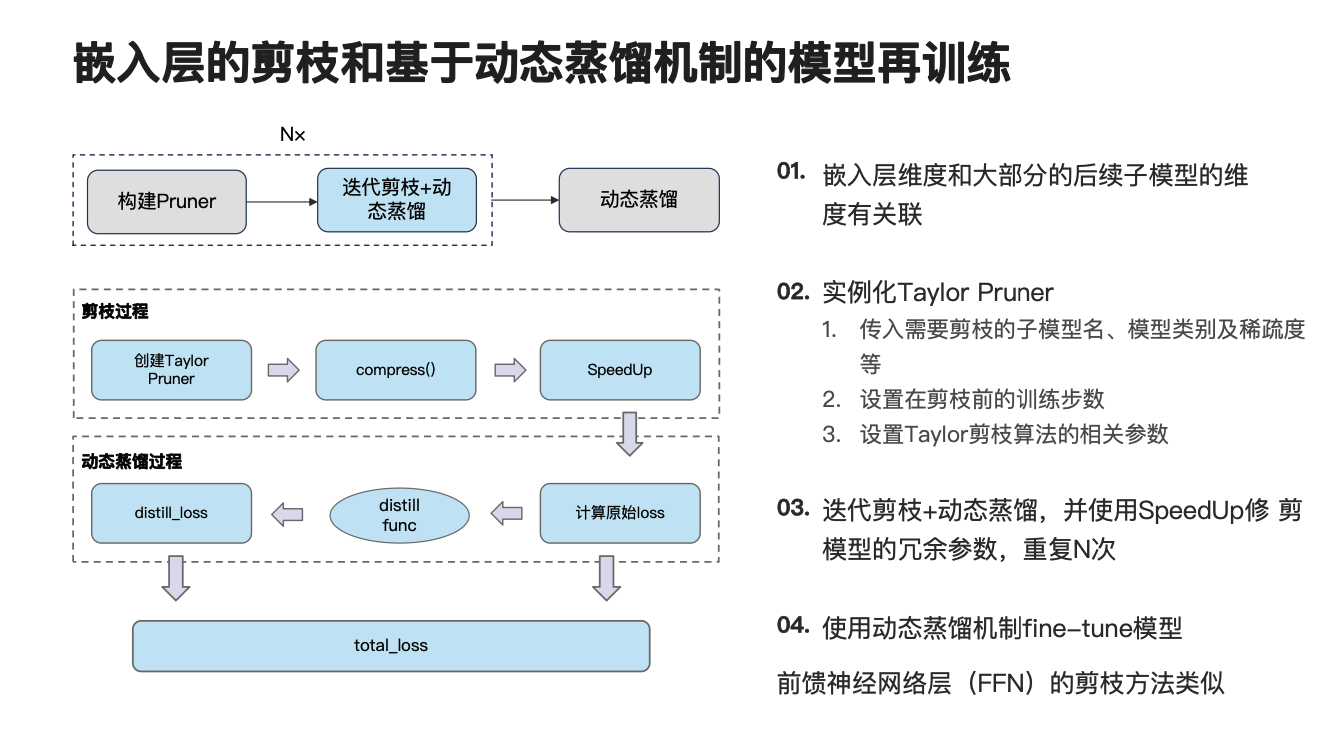
下面再让我们来看一下嵌入层的剪枝和模型再训练过程。该过程可分为两步,第一步算是迭代剪枝加动态蒸馏,要重复 n 次。第二个是动态蒸馏过程。先来看第一步,如左下角的图所示,在对嵌入层的剪枝过程中,我们使用的是 Taylor 剪枝方法,因此我们首先先创建一个 Taylor Pruner 的实例,接下来调用一个 compress() 函数执行模型的模拟压缩过程,并将模拟压缩过程所生成的掩码传入到 SpeedUp 模块中。接下来会使用一个蒸馏函数,以计算一个蒸馏 loss,并将蒸馏 loss 和原始 loss 进行加权求和,得到总 loss,考虑到前馈神经网络的剪枝方法和再训练方法比较类似,这里不再赘述。
实验结果
下面来看一些实验结果。首先这次实验主要在 BERT、T5、和 ViT 模型上进行了实验,其中 BERT 使用了完整的流程,而 ViT 则没有对嵌入层进行剪枝,T5 则在 ViT 的基础上直接对模型进行 fine-tune,执行模型再训练过程,下面对实验结果进行一一分析和讲解。
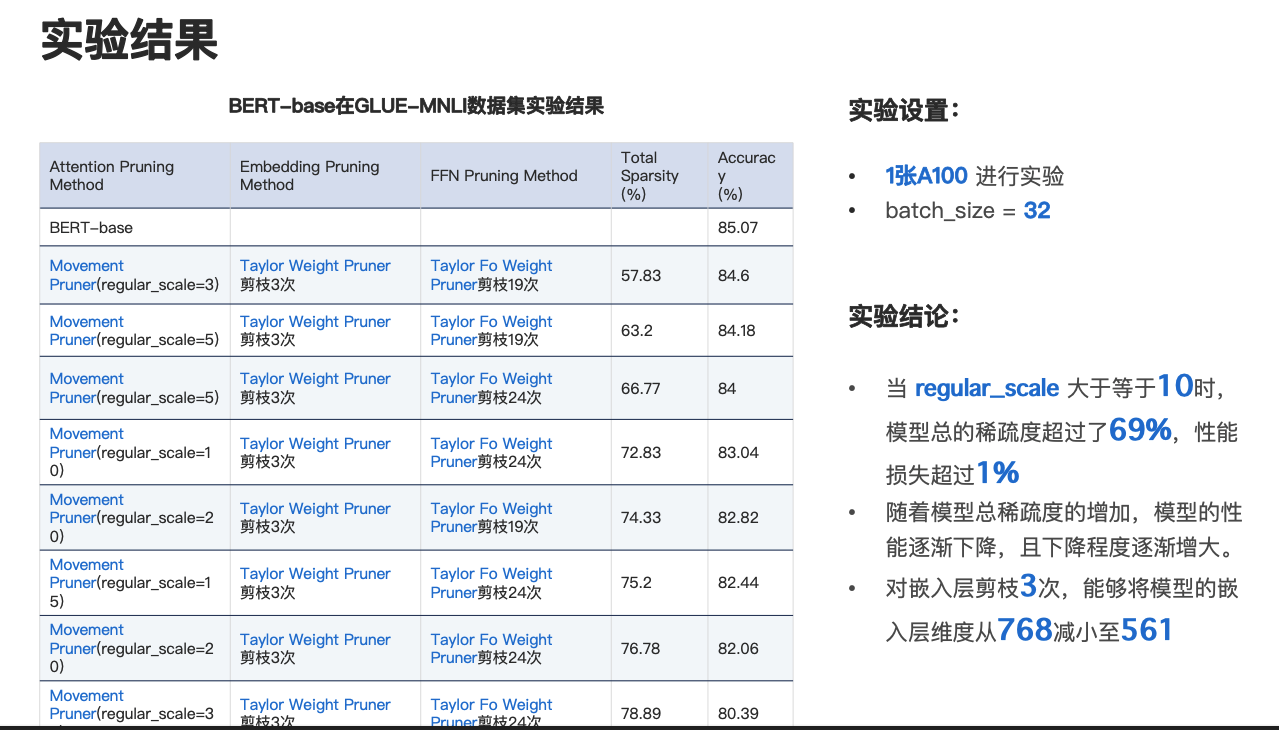
首先大家可以看一下,这是 BERT-base 在 GLUE-MNLI 数据集的实验结果,在对 BERT 进行实验时,我们使用了一张 A100 进行实验,并将 batch_size 设置为 32。先看一下这个表格,它的第一列说的是自注意力模块的剪枝方法,这里主要用的是 movement Pruner 剪枝方法。
这里通过控制 movement 算法中的 regular_scale 参数去控制对多头自注意力模块的剪枝程度,regular_scale 参数越大,多头自注意力模块的稀疏度就越高。第二个是我们对嵌入层的剪枝方法,这里我们使用 Taylor 剪枝方法对嵌入层进行剪枝,并且迭代剪枝三次。对于前馈神经网络,我们仍然使用 Taylor 方法进行剪枝,并且迭代剪枝 19 次或者 24 次,倒数第二列是总稀疏度的百分比。
图片来源:https://github.com/huggingface/nn_pruning
https://github.com/princeton-nlp/CoFiPruning
大家可以看一下上图这个计算公式,它是用原模型的大小减去压缩后模型的大小,并将它们的差值比上原模型的大小。最后一列是准确率的百分比,从实验结果可以发现当 regular_scale 大于等于 10 时,模型总的稀疏度能够超过 69%,性能损失超过 1%,随着模型总稀疏度的增加,模型的性能是逐渐下降的,且下降程度是逐渐增大的。
当我们对嵌入层剪枝三次时,能够将模型的嵌入层维度从 768 减小至 561,这在一定程度上也减小了模型的参数量。
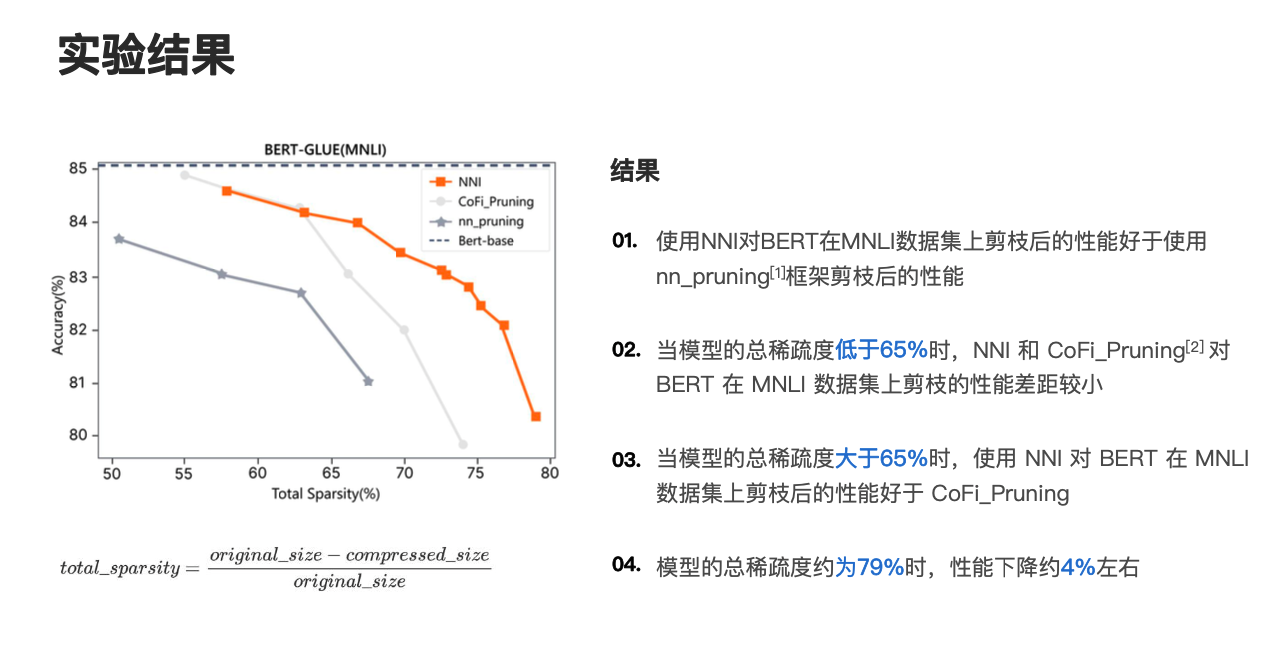
进一步和其他两个平台的实验结果进行对比,也就是 CoFi_Pruning 和 nn_pruning,nn_pruning 是 huggingface 旗下的,CoFi_Pruning 是陈丹琪 ACL'22 的一篇论文里的一个结果。这两个都是目前用的比较多的,我们可以对比看一下左边这个图,它的横坐标是总的稀疏度的百分比,纵坐标是准确率的百分比,其中最上面那根线是直接 BERT base 在不剪枝的情况下,直接在 MNLI 数据集上 fine-tune 后的性能。
最左边这根线是 nn_pruning 的实验结果,这条比较浅的线是 CoFi_Pruning 的实验结果,橙色那根线是 NNI 的实验结果,我们分别对比看看,首先看 nn_pruning 的实验结果和 NNI 的实验结果对比,可以发现使用 NNI 对 BERT 在 MNLI 数据集上剪枝后的性能好于使用 nn_pruning 框架剪枝后的性能。
如果对比 CoFi_Pruning 和 NNI 的话,会发现当模型的总稀疏度低于 65% 时,NNI 和 CoFi_Pruning 对 BERT 在 MNLI 数据集上的性能差异是比较小的,也就是在这个点的分界线之前,它们的差异是很小的,但是当模型总稀疏度大于 65% 时,使用 NNI 对 BERT 在 MNLI 数据集上剪枝后的性能是好于 CoFi_Pruning 的。同时我们只看 NNI 这条线,会发现当模型总的稀疏度约为 79% 时,性能下降约为 4% 左右。这里再额外补充一句,因为我们用的是总稀疏度,对应一般论文里编码器里的稀疏度,应该已经超过了 90%。
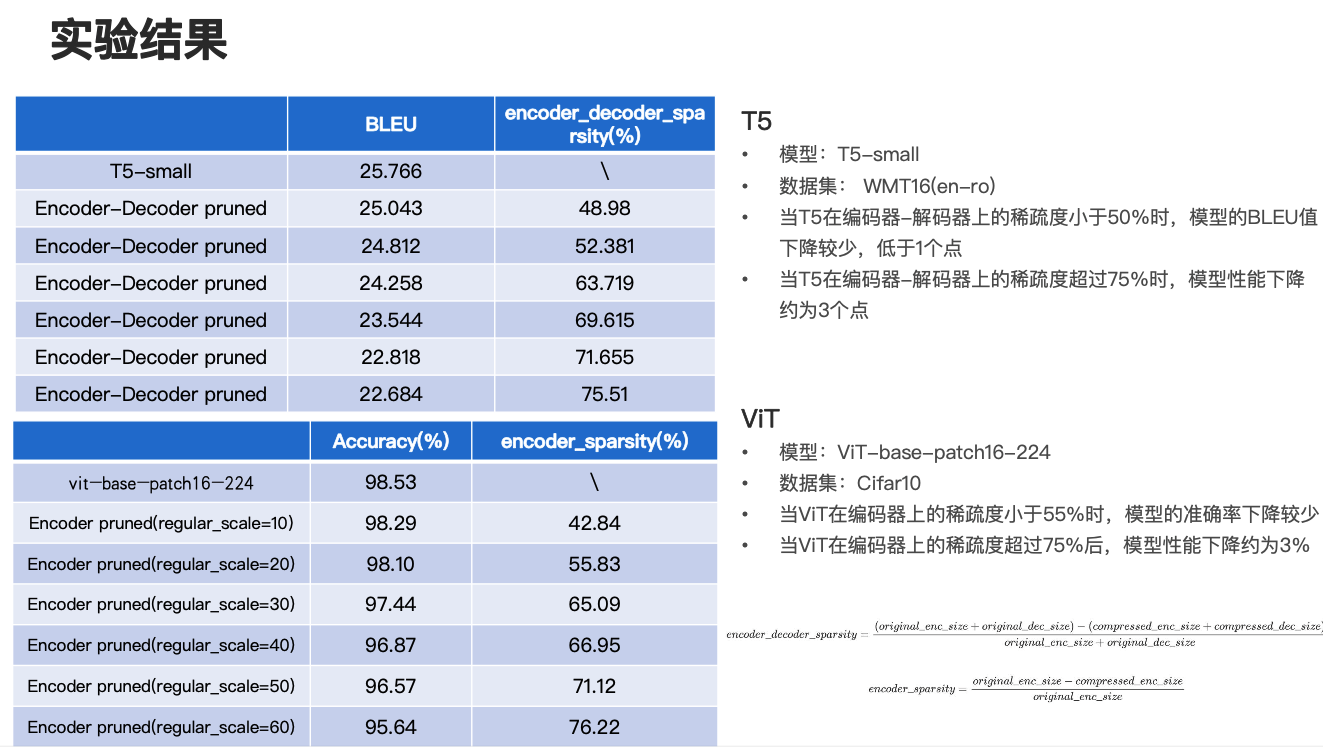
下面再来看一下 T5 和 ViT 上的实验结果。首先看 T5 的实验结果,我们使用的是 T5-small 模型,并且在一个翻译任务 WMT16(en-ro) ,英文翻俄文的数据集上进行评估,实验结果如上面的表所示,在这个过程中我们对它的编码器解码器都进行了剪枝,第二列是它的 BLEU 值,最后一列是它的编码器和解码器的稀疏度。
看左下角的公式,大概说一下编码器解码器的稀疏度,主要是用原始模型编码器和解码器的稀疏度之和,减去压缩后模型编码器和解码器的稀疏度之和,用它们两个的差值比上原始模型编码器和解码器的稀疏度之和。
可以看到表格第一行是 T5-small 的结果,同样的,这一行的结果也对应着如果直接用 T5-small 在这个数据集上 fine-tune 它的一个实验结果,由实验结果可以发现当 T5 在编码器解码器上的稀疏度小于 50% 时,模型的 BLEU 值下降比较少,低于一个点,而当 T5 在编码器解码器上的稀疏度超过 75% 时,模型的性能下降约为三个点。
再看一下 ViT 的实验结果,我们主要使用 vit-base-patch16-224 模型,主要使用 Cifar10 数据集进行评估,整个实验结果可以看左下方这个表格,同样它的第二列是准确率的百分比,最后一列是编码器的稀疏度百分比,计算公式和之前的计算公式是类似的,编码器的稀疏度就等于原始模型编码器的稀疏度减去压缩后模型编码器的稀疏度,用它们的差值比上原始模型编码器的大小。
可以看一下第一行仍然是在这个模型不做压缩的情况下,直接 fine-tune 它的一个效果。第一列当中有一个 regular_scale 参数,这个和之前的参数是一样的,都是用来控制多头自注意力模块的稀疏度的。从实验结果可以发现,当 ViT 在编码器上的稀疏度小于 55% 时,模型的准确率下降比较少,但是当 ViT 在编码器上的稀疏度超过 75% 时,模型性能下降约为 3% 左右。
平台对比

我们把模型压缩模块中的剪枝模块和现在主流的两个平台,nn_pruning 和 CoFi_Pruning 进行了对比,主要考察以下几个指标,第一个是它们是否具有详实的实验表现,第二个是它们是否有像 SpeedUp 模块一样的工具,能够真正意义上的压缩模型。第三个是它们是否有详实的教程实例,以及它们支持模型的类别,包括还有它们所包含的剪枝算法的种类。
大家可以看一下这个表,从表里可以发现 NNI 具有完整的教程实例,有详实的实验表现,和前面两个平台最大的差异在于它有一个 SpeedUp 模块,能够真正意义上减小模型的参数量,打通从模型压缩到模型加速的整个流程。同时 NNI 现在支持 BERT、RoBerta、GPT、BART、T5、 ViT 等多种主流模型,而反观其它两个平台,所支持的模型是非常有限的。最后 NNI 还为用户提供了 16 种前沿剪枝算法,它具有较强的通用性。
结论
从上面的分析可以发现,NNI 的压缩模块,它通过统一的框架融合了模型压缩的多种技术与方法,打通了从模型压缩到模型加速的整个流程,NNI 的模型压缩模块能够联合使用量化、蒸馏、及剪枝方法,并能够非常方便的针对模型的不同部分使用不同的压缩算法,其具有非常强的通用性。
通过对 Transformer 系列模型的压缩,我们发现了既能降低模型参数量和计算量,又能保持模型比较高精度的剪枝步骤和算法组合,在 BERT-MNLI 上获得了超越 SOTA 的模型剪枝结果,在 ViT-Cifar10 和 T5-WMT16(en-ro) 上也取得了较好的效果。
三年多以来,NNI 一直在不断探索,不断更新,以更好的适应技术的发展,提升用户体验。在即将发布的 v3.0 版本中,NNI 的模型压缩模块将引入蒸馏模块,支持剪枝、量化和蒸馏的一体化,同时面向延迟敏感类模型的 NAS 也将支持更多的应用场景,更精简更友好的编程接口和调试体验,更强劲的算法性能。除此之外,还有许多其它有趣的更新,欢迎大家持续关注,也欢迎大家为我们 NNI 社区贡献一份自己的力量,谢谢大家。




