
2018 年底,vivo AI 研究院为了解决统一高性能训练环境、大规模分布式训练、计算资源的高效利用调度等痛点,着手建设 AI 计算平台。经过四年多的持续迭代,平台建设和落地取得了很大进展,成为 vivo AI 领域的核心基础平台。平台从当初服务深度学习训练为主,到现在演进成包含 VTraining、VServing、VContainer 三大模块,对外提供模型训练、模型推理和容器化能力的基础设施。平台的容器集群有数千个节点,拥有超过数百 PFLOPS 的 GPU 算力。集群里同时运行着数千个训练任务和数百个在线服务。本文是vivo AI计算平台实战系列文章之一,主要分享了平台在资源配额管理方面的实践。
背景
K8s 提供了原生的 ResourceQuota 资源配额管理功能,基于命名空间进行配额管理,简单易用。但是随着平台资源使用场景变得越来越复杂,例如多层级业务组织配额、针对具体 CPU 核和 GPU 卡的型号配额、资源使用时长配额等,ResourceQuota 变得难以应对,平台面临业务资源争抢、配额管理成本增加、定位问题效率变低等问题。
本文主要介绍平台在 K8s 集群资源配额管理过程中遇到的问题,以及如何实现符合需求的配额管理组件:BizGroupResourceQuota —— 业务组资源配额(简称 bizrq),用于支撑平台对复杂资源使用场景的配额管控。
ResourceQuota 资源配额管理遇到的问题
在使用 ResourceQuota 做资源配额管理时,有以下 4 个问题比较突出:
1、无法满足有层级的业务组织架构的资源配额管理
ResourceQuota 不能很好地应用于树状的业务组织架构场景,因为命名空间是扁平的,在实际场景中,我们希望将资源配额由父业务组到子业务组进行逐级下发分配。
2、以 pod 对象的粒度限额可能导致只有部分 pod 创建成功
ResourceQuota 是以 pod 对象的粒度来进行资源限额的,正常情况下在线服务或离线任务的部署,例如 deployment、argo rollout、tfjob 等,都需要批量创建 pod,可能会造成一部分 pod 由于额度不足而创建失败的情形,导致部署无法完成甚至失败,我们希望要么全部 pod 都创建成功,要么直接拒绝部署并提示资源额度不足,提升部署体验。
3、无法针对具体 CPU 核和 GPU 卡的型号进行配额管理
ResourceQuota 管理配额的资源粒度太粗,无法针对具体 CPU 核和 GPU 卡的型号进行配额管理,在实际场景中,不同的 CPU、GPU 型号的性能、成本差异很大,需要分开进行限额。例如我们会将 CPU 机器划分为 A1、A2、A3、A4 等机型,GPU 机器也有 T4、V100、A30、A100 等机型,他们的性能和成本都是有差异的。
4、无法限制资源使用时长
ResourceQuota 仅能限制当前时刻资源的已使用额度不能超过配额,但是并不能限制对资源的使用时长。在某些离线的深度模型训练场景,业务对 CPU、GPU 资源争抢比较激烈,某些业务组希望能按 CPU 核时或 GPU 卡时的方式,给团队成员发放资源配额,比如每人每周发放 1000 GPU 卡时,表示可以用 10 张卡跑 100 小时,也可用 20 张卡跑 50 小时,以此类推。
BizGroupResourceQuota 分级配额管理方案
针对 ResourceQuota 配额管理所面临的 4 个问题,我们设计了 BizGroupResourceQuota 配额管理 —— 业务组资源配额管理方案,后文简称为 bizrq。接下来,我们介绍一下 bizrq 方案。
我们通过 K8s crd(Custom Resource Define)来自定义 bizrq 资源对象(如下图 bizrq 配额示例),从而定义 bizrq 的实现方案:
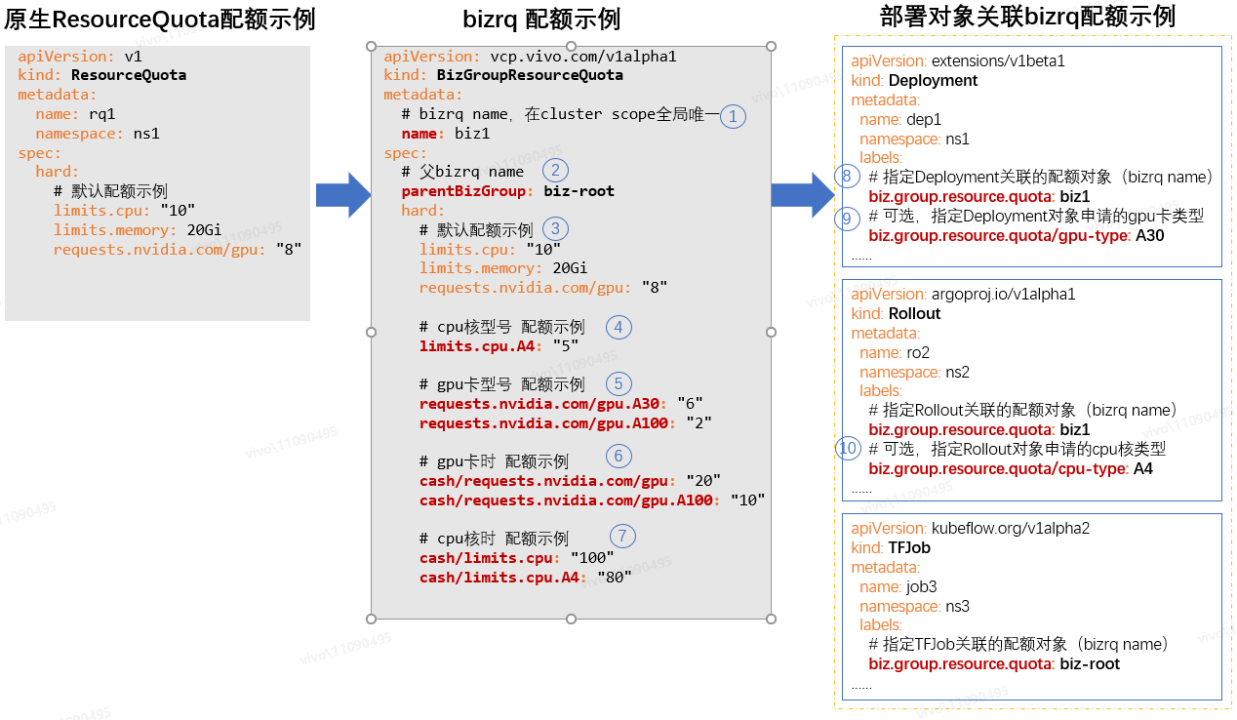
如上图配额示例所示,下面分别解释一下 bizrq 配额方案的特点:
① bizrq name
bizrq name 在 cluster scope 全局唯一,bizrq 配额对象是集群范围的,不跟命名空间相关联。在实际业务场景中,bizrq name 可以跟业务组 ID 对应起来,便于实现基于树状的业务组织架构的配额管理。
②父 bizrq name
父 bizrq name 表示当前 bizrq 的父级业务组的 bizrq 配额对象名称,假如父 bizrq name 值设置了空字符串"",则表示当前 bizrq 是 root 节点。当创建非 root 的 bizrq 配额对象时,子 bizrq 的资源配额要从父 bizrq 的剩余额度中申请,并需要满足相关约束条件才能创建成功,后面也会介绍实现原理。这样就可以按常见的业务组织架构来管理配额,构成一颗“bizrq 树”:

③默认配额示例
默认配额示例跟 ResourceQuota 的资源额度配置和限额效果是一致的,bizrq 借鉴了 ResourceQuota 的实现,保持了一致的配置风格和使用体验。
④CPU 核型号配额示例
bizrq 支持将 CPU 核配额限制到具体型号,具体型号资源的已使用额度,也会累加到前缀相同的通用资源配额的已使用额度里,它们是可以结合使用的,如果都配置了则限额会同时生效。这样即保留了原生 ResourceQuota 的限额功能,又新增了不同型号资源的限额。
举例说明,比如将 limits.cpu 配额设置为 10 核,limits.cpu.A4 配额设置为 4 核,它们一开始已使用额度都是 0 核,当我们的部署对象申请了 4 核的 A4 后,那么 limits.cpu 和 limits.cpu.A4 的已使用额度都会累加上这 4 核,因为 bizrq 会判断 limits.cpu 是 limits.cpu.A4 的前缀资源,属于通用资源类型,所以要一并计算。另外,此时业务组不能再申请 A4 型号的 cpu 资源了,因为 limits.cpu.A4 的剩余额度为 0,不过 limits.cpu 剩余额度还有 6 核,所以还可以申请非 A4 型号的 CPU 资源。
那么我们能否将 limits.cpu 配额设置为 10 核,将 limits.cpu.A4 配额设置为 100 核呢(limits.cpu < limits.cpu.A4)?是可以这样配置的,但是将 limits.cpu.A4 配置为 100 核没有意义,因为申请 A4 型号的 CPU 资源时,bizrq 也会分析前缀相同的 limits.cpu 的剩余额度是否足够,如果额度不足那么任何型号的 CPU 资源都不能申请成功。
⑤GPU 卡型号配额示例
bizrq 支持将 GPU 卡配额限制到具体型号,具体型号资源的已使用额度,也会累加到前缀相同的通用资源的已使用额度里,它们是可以结合使用的,跟上面介绍的 CPU 核型号的限额行为也是一致的。
⑥GPU 卡时配额示例,⑦CPU 核时配额示例
bizrq 支持虚拟 cash 机制,可以给业务组分配 CPU 核时、GPU 卡时等“虚拟的货币”,比如给某个业务组分配 100CPU 核时:“cash/limits.cpu: 100”,(注意前缀 “cash/” 的表示)表示这个业务组的业务可以用 1 个 CPU 核跑 100 小时,也可以用 2 个 CPU 核跑 50 小时,还可以用 100 个 CPU 核跑 1 小时,GPU 卡时的定义可以类比。
⑧指定 Deployment 关联的配额对象(bizrq name)
bizrq 限额不以 pod 对象为粒度进行限额,而是以 deployment、argo rollout、tfjob 等上层部署对象的粒度来限额,需要通过部署对象 label “biz.group.resource.quota”来关联 bizrq 配额对象(注意不是通过命名空间进行关联,因为 bizrq 是 cluster scope 的)。
通过拦截上层部署对象的创建、更新操作进行资源额度的校验(通过 validating webhook 拦截,后文会介绍实现原理),当关联 bizrq 的剩余资源额度充足时,允许上层对象的创建;当剩余资源额度不足时,拒绝上层对象的创建,从而防止只有部分 pod 创建成功的情形。
⑨⑩指定部署对象关联的配额对象(bizrq name)
为了达到具体的 CPU 核型号或 GPU 卡型号的限额目的,也要给部署对象打上声明具体的资源型号的 label,例如:biz.group.resource.quota/cpu-type: "A4",表示部署对象申请的是 A4 型号的 CPU 核;或 GPU 卡型号的 label,例如:biz.group.resource.quota/gpu-type: "A30",表示部署对象申请的是 A30 型号的 GPU 卡。
备注:bizrq 同样支持具体的内存类型的限额,使用方式与 CPU 核、GPU 卡类型的限额类似,比如可以设置 limits.memory.A4 的额度,然后给部署对象打上声明具体的资源型号的 label:biz.group.resource.quota/memory-type: "A4" 即可。
配额机制实现原理
bizrq 方案在 ResourceQuota 所支持的基础资源配额的基础上,增加了(1)父子关系的表示,(2)CPU 核和 GPU 卡型号的限额,(3)核时、卡时的限额,(4)针对上层的部署资源对象进行额度校验,而不是针对单个 pod;同时 bizrq 对象的配置风格和 ResourceQuota 对象的配置风格是一样的,易于配置和理解。所以 bizrq 分级配额的实现思路应该也是可以借鉴 ResourceQuota 的,在分析 bizrq 实现前,我们先分析下 ResourceQuota 的实现原理,以便借鉴官方优秀的实现思路。
原生 ResourceQuota 实现
整体架构
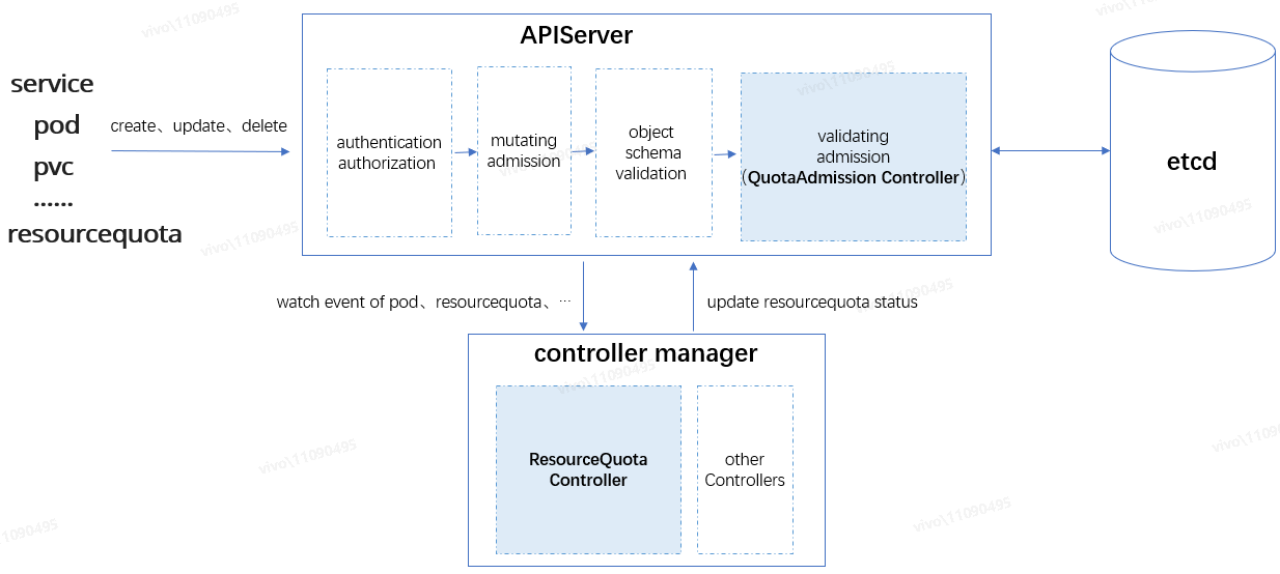
如上图所示,APIServer 接收到资源对象请求后,由访问控制链路中的处理器按顺序进行处理,请求顺利通过访问控制链路的处理后,资源对象的变更才允许被持久化到 etcd,它们依次是认证(authentication)→鉴权(authorization)→变更准入控制(mutating admission)→对象 Schema 校验(object schema validation)→验证准入控制(validating admission)→etcd 持久化,我们需要重点关注“准入控制”环节:
· 变更准入控制(mutating admission):对请求的资源对象进行变更。例如内置的 ServiceAccount admission controller,会将 pod 的默认 ServiceAccount 设为 default,并为每个容器添加 volumeMounts,挂载至 /var/run/secrets/kubernetes.io/serviceaccount,以便在 pod 内部可以读取到身份信息来访问当前集群的 apiserver。变更准入控制是可扩展的,我们可以通过配置 mutating admission webhooks 将自定义的逻辑加入到变更准入控制链路中;
· 验证准入控制(validating admission):对请求的资源对象进行各种验证。此环节不会去变更资源对象,而是做一些逻辑校验,例如接下来要分析的 QuotaAdmission Controller,会拦截 pod 的创建请求,计算 pod 里容器申请的资源增量是否会导致超额。验证准入控制也是可扩展的,我们可以通过配置 validating admission webhooks 将自定义的逻辑加入到验证准入控制链路中。
如上图所示,ResourceQuota 限额机制主要由两个组件组成:
· ResourceQuota Controller:ResourceQuota Controller 是内置在 controller manager 众多 Controllers 中的一个,主要负责监听资源对象,如 pod、service 等变更事件,也包括 ResourceQuota 对象的变更事件,以便及时刷新关联的 ResourceQuota 的 status 状态;
· QuotaAdmission Controller:QuotaAdmission 是内置在 apiserver 请求访问控制链路验证准入控制环节的控制器,QuotaAdmission 主要负责拦截资源对象的创建、更新请求,对关联 ResourceQuota 的额度进行校验。
下面以 Pod 对象的限额为例,分析 ResourceQuota 限额机制原理。其他资源,比如 service、pvc 等对象限额的实现思路基本一致,只不过不同对象有不同的资源计算逻辑实现(Evaluator)。
ResourceQuota Controller
当集群的 controller manager 进程启动后,选主成功的那个 controller manager leader 就会将包括 ResourceQuota Controller 在内的所有内置的 Controller 跑起来,ResourceQuota Controller 会以生产者-消费者的模式,不断刷新集群命名空间的 ResourceQuota 对象的资源使用状态:

作为任务生产者,为了及时把需要刷新状态的 ResourceQuota 放到任务队列,ResourceQuota Controller 主要做了以下 3 件事情:
· 监听 pod 对象的事件,当监听到 pod 由占用资源状态变更为不占资源状态时,比如 status 由 terminating 变为 Failed、Succeeded 状态,或者 pod 被删除时,会将 pod 所在命名空间下关联的所有 ResourceQuota 放入任务队列;
· 监听 ResourceQuota 对象的创建、spec.Hard 更新(注意会忽略 status 更新事件,主要是为了将 spec.Hard 刷新到 status.Hard)、delete 等事件,将对应的 ResourceQuota 放入任务队列;
· 定时(默认 5m,可配置)把集群所有的 ResourceQuota 放入任务队列,确保 ResourceQuota 的状态最终是跟命名空间实际资源使用情况一致的,不会因为各种异常情况而出现长期不一致的状态。
作为任务消费者,ResourceQuota Controller 会为任务队列启动若干 worker 协程(默认 5 个,可配置),不断从任务队列取出 ResourceQuota,计算 ResourceQuota 所在命名空间所有 pod 的容器配置的资源量来刷新 ResourceQuota 的状态信息。
QuotaAdmission Controller
对于 pod 的限额,QuotaAdmission 只会拦截 Pod create 操作,不会拦截 update 操作,因为当部署对象的 pod 容器资源申请被变更后,原 pod 是会被删除并且创建新 pod 的,pod 的删除操作也不用拦截,因为删除操作肯定不会导致超额。
当 QuotaAdmission 拦截到 Pod 的创建操作后,会找出对应命名空间所有相关联的 ResourceQuota,并分析创建 pod 会不会造成资源使用超额,只要有一个 ResourceQuota 会超额,那么就拒绝创建操作。如果所有的 ResourceQuota 都不会超额,那么先尝试更新 ResourceQuota 状态,即是将此个 pod 的容器配置的资源量累加到 ResourceQuota status.Used 里,更新成功后,放行此次 pod 操作。
问题分析
总的来说,ResourceQuota Controller 负责监听各类对象的变更事件,以便能及时刷新对应的 ResourceQuota status 状态,而 QuotaAdmission 则负责拦截对象操作,做资源额度的校验。有几个比较关键的问题我们需要分析一下,这几个问题也是 bizrq 实现的关键点:
1、ResourceQuota status 的并发安全问题
ResourceQuota Controller 会不断刷新 ResourceQuota status 里各类资源使用量,所有 apiserver 进程的 QuotaAdmission 也会根据 ResourceQuota status 校验是否超额,并将校验通过的 pod 资源增量累加到 ResourceQuota status.Used,所以 status 的更新是非常频繁的,这就会导致并发安全问题:
假设某个业务组 CPU 配额有 10 核,已使用量为 1 核,业务 A 和业务 B 同时请求申请 5 核,此时对剩余额度的校验都是足够的(剩余 CPU 核数为 10-1=9),两个请求都会将 CPU 已使用量更新为 1+5=6 核,并且都申请成功,这将导致限额失效,因为实际的资源申请已经超额了(1+5+5=11 核)。
解决办法通常有以下 3 种方式:
· 方式 1:将所有对 status 的访问逻辑打包成任务放入队列,并通过单点保证全局按顺序进行处理;
· 方式 2:将所有对 status 的访问逻辑加锁,获取到锁才可以进行处理,保证任何时刻都不会有并发的访问;
· 方式 3:通过乐观锁来确保对 status 的访问是安全的。
ResourceQuota 采用的是第三种方式,方式 1、2 都要引入额外的辅助手段,比如分布式队列、分布式锁,并且同一时刻只能处理一个请求,效率比较低下,容易造成处理延时,此外还要考虑 ResourceQuota Controller 跟 QuotaAdmission Controller 的协同(都会更新 ResourceQuota status.Used),在限额场景实现起来不是那么简洁高效,而方式 3 可以直接基于 K8s 的乐观锁来达到目的,是最简洁高效的方式。
K8s 乐观锁实现原理
K8s 乐观锁的实现,有两个前提:
· 一是 K8s 资源对象的 resourceVersion 是基于 etcd 的 revision,revision 的值是全局单调递增的,对任何 key 的修改都会使其自增;
· 二是 apiserver 需要通过 etcd 的事务 API,即 clientv3.KV.Txn(ctx).If(cmp1, cmp2, ......).Then(op1, op2, ......).Else(op1, op2, ......),来实现事务性的比较更新操作。
具体流程示例如下:
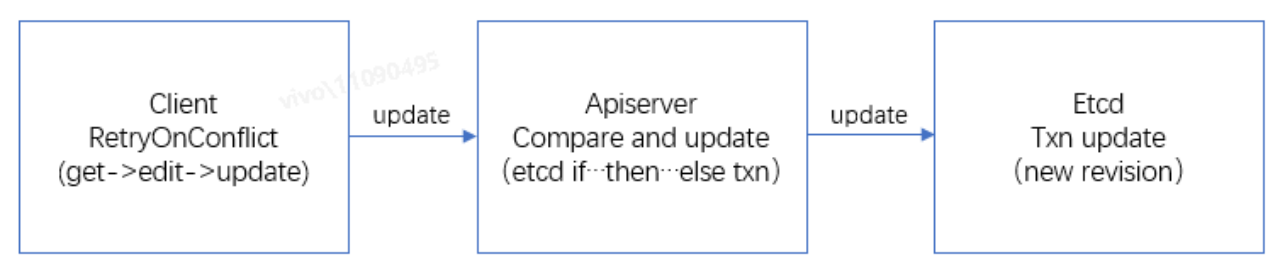
· 第 1 步:client 端从 apiserver 查询出对象 obj 的值 d0,对应的 resourceVersion 为 v0;
· 第 2 步:client 端本地处理业务逻辑后,调用 apiserver 更新接口,尝试将对象 obj 的值 d0 更新为 dx;
· 第 3 步:apiserver 接受到 client 端请求后,通过 etcd 的 if...then...else 事务接口,判断在 etcd 里对象 obj 的 resourceVersion 值是否还是 v0,如果还是 v0,表示对象 obj 没被修改过,则将对象 obj 的值更新为 dx,并为对象 obj 生成最新的 resourceVersion 值 v1;如果 etcd 发现对象 obj 的 resourceVersion 值已经不是 v0,那么表示对象 obj 已经被修改过,此时 apiserver 将返回更新失败;
· 第 4 步:对于 client 端,apiserver 返回更新成功时,对象 obj 已经被成功更新,可以继续处理别的业务逻辑;如果 apiserver 返回更新失败,那么可以选择重试,即重复 1~4 步的操作,直到对象 obj 被成功。
apiserver 的更新操作实现函数:

相对于方式 2 的锁(悲观锁),乐观锁不用去锁整个请求操作,所有请求可以并行处理,更新数据的操作可以同时进行,但是只有一个请求能更新成功,所以一般会对失败的操作进行重试,比如 QuotaAdmission 拦截的用户请求,加了重试机制,重试多次不成功才返回失败,在并发量不是非常大,或者读多写少的场景都可以大大提升并发处理效率。
QuotaAdmission 中乐观锁重试机制实现函数是 checkQuotas,感兴趣可自行阅读源码:

另外,更新冲突在所难免,客户端可以借助 client-go 的 util 函数 RetryOnConflict 来实现失败重试:
https://github.com/kubernetes/client-go/blob/kubernetes-1.20.5/util/retry/util.go

2、超额问题
问题:QuotaAdmission 校验 pod 创建是否超额时,查询出来的 ResourceQuota 的 status.Used 状态能否反映命名空间下资源最新实际使用量,会不会造成超额情形?
问题分析:
由于 ResourceQuota Controller 和 QuotaAdmission 都会不断刷新 ResourceQuota 的 status.Used 状态,并且 QuotaAdmission 基本是通过 informer cache 来获取 ResourceQuota 的,informer 监听会有延迟,所以校验额度时查询的 ResourceQuota status 状态可能并不是准确反映命名空间下资源最新实际使用量,概括起来有以下 3 种不一致的情况:
· (1)informer 事件监听延迟,查询到的可能不是 etcd 最新的 ResourceQuota;
· (2)即使查询到的是 etcd 最新的 ResourceQuota,在额度校验过程中,ResourceQuota 也有可能先被别的请求或被 ResourceQuota controller 修改掉,那么 ResourceQuota 数据也是“过期”的;
· (3)即使查询到的是 etcd 最新的 ResourceQuota,并且在额度校验过程中,ResourceQuota 数据没有被修改,这个查询出来的 etcd 最新的 ResourceQuota,也有可能不是最新的数据,因为 ResourceQuota controller 刷新 ResourceQuota 可能不是那么及时。
对于(1)、(2)这两种情形,由于 QuotaAdmission 基于 K8s 乐观锁做 ResourceQuota 资源额度的校验及状态更新,如果 ResourceQuota 不是 etcd 最新的,那么更新 ResourceQuota 状态时会失败,QuotaAdmission 将进行重试,这样就能保证只有用最新的 ResourceQuota 来做额度校验,资源申请请求才能被通过;
对于(3)情形,ResourceQuota controller 刷新 ResourceQuota 可能不及时,但也不会造成超额,因为资源使用量的增加(例如 pod 创建操作)都是要通过 QuotaAdmission 拦截校验并通过乐观锁机制将资源增量更新到 ResourceQuota,ResourceQuota controller 刷新 ResourceQuota 不及时,只会导致当前 etcd 最新 ResourceQuota 的剩余额度比实际“偏小”(例如 pod 由 terminating 变为 Failed、Succeeded 状态,或者 pod 被删除等情形),所以符合我们限额的目的。
当然,如果手动把配额调小,那可能会人为造成超额现象,比如原先 CPU 配额 10 核,已使用 9 核,此时手动把配额改成 8 核,那么 QuotaAdmission 对于之后的 pod 创建的额度校验肯定因为已经超额,不会通过操作了,不过这个是预期可理解的,在实际业务场景也有用处。
3、全局刷新问题
问题:为什么要定时全量刷新集群所有的 ResourceQuota 状态?
问题分析:
· 定时全量刷新可以防止某些异常导致的 ResourceQuota status 跟实际的资源使用状态不一致的情形,保证状态回归一致性。例如 QuotaAdmission 更新了 ResourceQuota 后(额度校验通过后),实际的资源操作由于遇到异常而没有成功的情形(如 pod 创建操作在后续环节失败的场景);
· 不过由于 ResourceQuota Controller 会不断更新 ResourceQuota,在额度校验通过后到实际资源操作被持久化前这段时间内(这段时间很短),ResourceQuota 可能会被 ResourceQuota Controller 更新回旧值,如果后续有新的资源申请操作,就可能造成超额情形,不过出现这个问题的几率应该很小,通过业务层补偿处理(比如超额告警、回收资源)即可。
关于 ResourceQuota Controller 和 QuotaAdmission 的代码细节,感兴趣可以自行阅读:
https://github.com/kubernetes/kubernetes/blob/v1.20.5/cmd/kube-controller-manager/app/core.go


bizrq 实现
在分析了 ResourceQuota 的实现原理后,我们再看看如何实现 bizrq 的限额方案。
整体架构
参考 ResourceQuota 的实现,我们可以将 bizrq 按功能职责划分成 3 个模块:
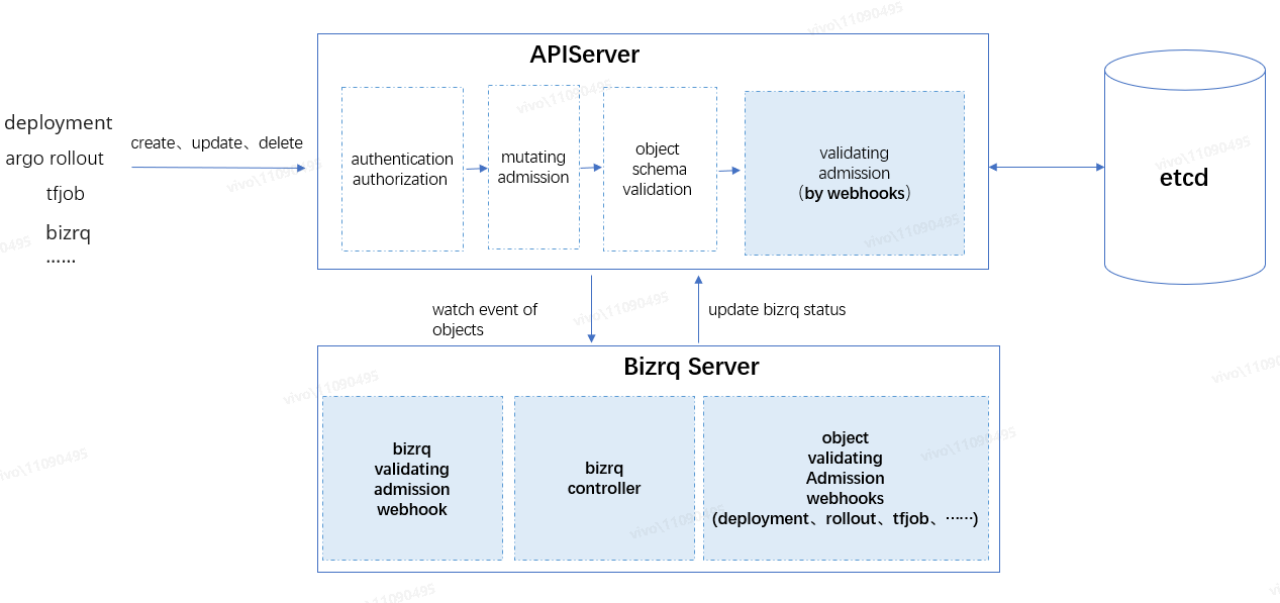
bizrq controller
负责监听相关事件,及时刷新 bizrq 状态以及定时(默认 5m)刷新整个集群的 bizrq 状态。
· 监听 bizrq 的创建、更新(Spec.Hard 变更),及时刷新 bizrq status;
· 监听部署对象,例如 deployment、argo rollout、tfjob 等对象的更新(这里仅监听 biz.group.resource.quota label 配置的更新)、删除事件,及时刷新关联的 bizrq status。
bizrq validating admission webhook(server)
基于 apiserver 的验证准入控制 webhook,负责拦截 bizrq 的增删改事件,做 bizrq 本身以及 bizrq parent 相关的约束性校验,从而实现分级配额。
· 拦截创建事件:对 bizrq name 做重名校验,确保 cluster scope 全局唯一;然后进行父 bizrq 校验;
· 拦截更新事件:确保父 parentBizGroup 字段不能变更,不能更改父 bizrq;然后进行父 bizrq 校验;
· 拦截删除事件:确保只能删除叶子节点的 bizrq,防止不小心将一棵树上所有的 bizrq 删除;然后进行父 bizrq 校验;
· 父 bizrq 校验:校验非 root bizrq(Spec.ParentBizGroup 字段不为 "")的父 bizrq 的相关约束条件是否满足:
o 父 bizrq 必须已存在;
o 子 bizrq 必须包含父 bizrq 配额配置的所有资源类型名称 key(Spec.Hard 的 key 集合),父 bizrq 的配额配置是子 bizrq 配额配置的子集,例如父 bizrq 包含 limits.cpu.A4,则创建子 bizrq 时也必须包含 limits.cpu.A4;
o 父 bizrq 的剩余额度必须足够,子 bizrq 申请的额度是从父 bizrq 里扣取的额度。如果父 bizrq 不会超额,则先更新父 bizrq 的 status,更新成功才表示从父 bizrq 申请到了额度。
object validating admission webhooks(server)
基于 apiserver 的验证准入控制 webhook,负责拦截需要限额的资源对象的创建和更新事件,例如 deployment、argo rollout、tfjob 等对象的拦截,做额度校验,从而实现部署对象的限额校验,而不是 pod 对象粒度的校验。
拦截到部署对象的请求时,从部署对象提取出以下信息,就能计算各类资源的增量:
· 资源型号(如果有指定具体型号的话),从 label biz.group.resource.quota/cpu-type 或 biz.group.resource.quota/gpu-type 提取;
· 部署对象的副本数(obj.Spec.Replicas);
· PodTemplateSpec,用来计算容器配置的资源量。
然后再判断部署对象的请求是否会导致关联的 bizrq 超额(从 label biz.group.resource.quota 提取关联的 bizrq name),如果 bizrq 不会超额,那么先尝试更新 bizrq 资源使用状态,更新成功后,放行此次请求操作。
关于核时、卡时的限额实现
controller 会不断刷新 bizrq 的 status,bizrq 的 status 跟 ResourceQuota 的 status 有点不一样,bizrq 的 status 添加了一些辅助信息,用来计算核时、卡时的使用状态(cash 额度使用状态):
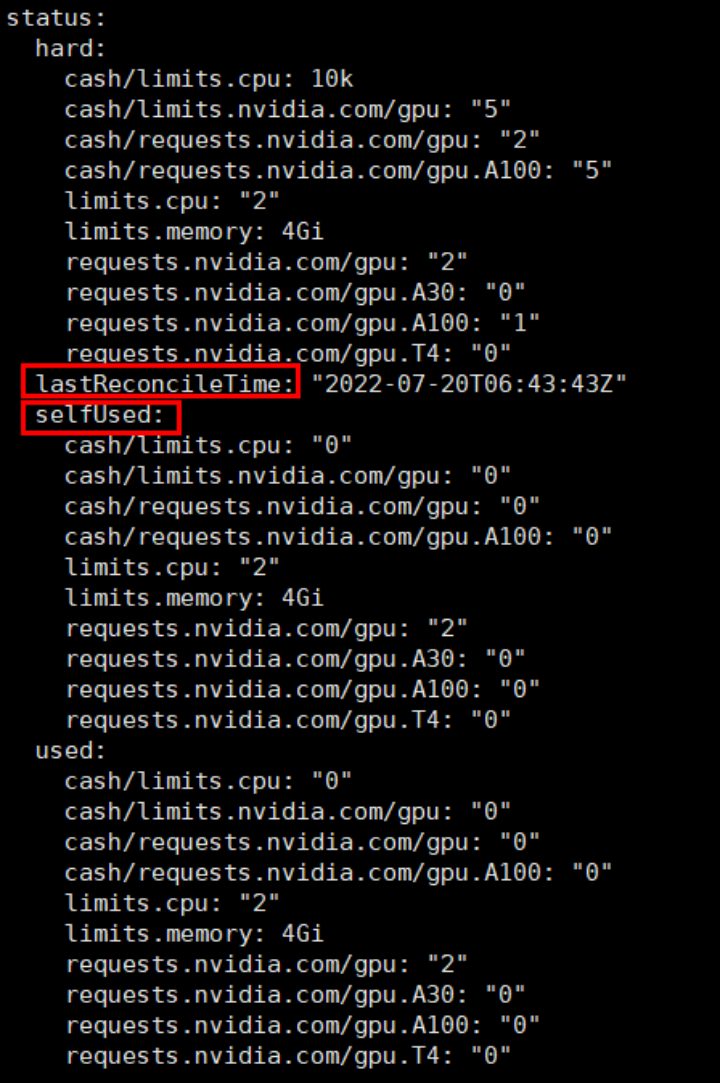
对比 ResourceQuota 的 status:
· bizrq status 包含了 ResourceQuota 也有的 hard、used 字段;
· 增加 selfUsed 字段来记录 bizrq 本身(业务组本身)已使用资源量,selfUsed 不包含子 bizrq 所申请的配额,并满足关系:selfUsed + 子 bizrq 申请的配额 = used;
· 增加 lastReconcileTime 字段来记录 controller 最后一次刷新 bizrq status 的时间,因为计算核时、卡时是要基于资源量乘于使用时间来计算的,而且是要基于 selfUsed 累加的。计算 cash 时,controller 会将部署对象包含的所有 pod 查询出来,然后结合 lastReconcileTime、pod 开始占用资源的时间点(成功调度到节点上)、pod 释放资源的时间点(比如 Succeeded、Failed),再结合 pod 容器配置的资源量,从而计算出整个 bizrq 业务组较准确的 cash 使用量。注意 cash 的计算不是百分百精确的,有些情形,例如 pod 被删除了,那么下个计算周期这个 pod 的 cash 就不会累加到 status 了,不过由于 controller 更新 status 的频率很高(最迟每 5m 更新一次),所以少量误差并不会影响大部分业务场景下的 cash 限额的需求;
· object validating admission webhooks 拦截到请求后进行核时、卡时的额度校验时,判断 bizrq.status.used 里相关资源类型的 cash(如 cash/limits.cpu)是否已经大于等于 bizrq.status.hard 里配置的配额,是则表示 cash 已经超额,直接拒绝拦截的请求即可;
· 另外,当 cash 已经超额时,并不能强制把相应业务组正在运行的业务停掉,而是可以通过监控告警的等手段通知到业务方,由业务方自行决定如何处置。
开发工具简介
kubebuilder
Kubebuilder 是一个基于 CRD 搭建 controller、admission webhook server 脚手架的工具,可以按 K8s 社区推荐的方式来扩展实现业务组件,让用户聚焦业务层逻辑,底层通用的逻辑已经直接集成到脚手架里。
bizrq 主要用到了 kubebuilder 的以下核心组件/功能:
· manager:负责管理 controller、webhook server 的生命周期,初始化 clients、caches,当我们要集成不同资源对象的 client、cache 时,只需写一行代码将资源对象的 schema 注册一下就可以了;
· caches:根据注册的 scheme(schema 维护了 GVK 与对应 Go types 的映射) 同步 apiserver 中所有关心的 GVK(对象类型)的 GVR(对象实例),维护 GVK -> Informer 的映射;
· clients:封装了对象的增删改查操作接口,执行查询操作时,底层会通过 cache 查询,执行变更类操作时,底层会访问 apiserver;
· indexer:可以通过 indexer 给 cache 加索引提升本地查询效率,例如实现 bizrq 功能时,可以通过建立父子关系索引,方便通过父查找所有子 bizrq;
· controller:controller 的脚手架,提供脚手架让业务层只需要关注感兴趣的事件(任务生产),及实现 Reconcile 方法(任务消费),以便对 crd 定义的对象进行状态调和;
· webhook server:webhook server 的脚手架,业务层只需要实现 Handler 接口,以便对拦截的请求做处理。
code-generator
实现了 bizrq 组件之后,可以通过 code-generator 工具生成 bizrq 的 informer、lister、clientset 等客户端代码,以便其他应用进行集成:
· client-gen:生成 crd 对象的标准操作方法:get、list、create、update、patch、delete、deleteCollection、watch 等;
· informer-gen: 生成监听 crd 对象相关事件的 informer;
· lister-gen: 生成缓存层只读的 get、list 方法。
落地情况及后续规划
目前 bizrq 分级配额管理方案已经在平台的在线业务场景全面落地,我们基于 bizrq 组件,对在线业务的 argo rollout 部署对象进行拦截和额度校验,结合在线业务场景中的“项目-服务-流水线”等层级的配额管理需求,实现了分级配额管理界面,让用户可以自行管理各层级的资源配额,从而解决业务资源争抢、减轻了平台资源管理压力、提高了相关问题的定位和解决效率。
后续我们将持续完善 bizrq 组件的功能,例如:
· 以插件式的方式支持更多种类对象的拦截和额度校验(例如离线训练任务 tfjob、有状态部署对象 statefulset 等),从而使 bizrq 分级配额管理组件能落地到更多的离在线业务场景中;
· 完善自动扩缩容(HPA)场景下的额度校验。目前我们是通过分析用户 HPA 配置的最大副本数是否会导致超额,来判断用户配置的值是否合理,后续可以给 bizrq 增加一个 validating admission webhook,通过拦截 scale 对象的方式来进行额度校验,从而让校验逻辑更加健壮、完整。
另外,我们也会结合实际的业务场景,完善上层功能的使用体验。例如优化资源额度的迁入迁出、借用流程;完善资源碎片分析、给业务推荐更加合理的部署资源套餐等能力,提升用户资源配额管理的体验和效率。
作者介绍:
刘东阳,vivo AI 研究院计算平台组的资深工程师,曾就职于金蝶、蚂蚁金服等公司;关注 K8s、容器等云原生技术。




