
本文最初发表于For Else网站,经原作者 Jeff Carter 许可,由 InfoQ 中文站翻译分享。
前段时间,AWS 发生宕机事故,很多服务中断。从架构角度,我们如何去应对这种宕机,网上有很多相关讨论。但是这些讨论太复杂,并且在成本、复杂性和权衡方面差异很大。所以,我决定简要介绍其中的一种方法。
多云
首先,就是关于多云价值的讨论。它的理念就是在多个云中运行你的应用。
通过将负载分散到多个供应商,我们就能在其中的某一个供应商出现故障的时候得以幸免于难。在理论上,这种方式听起来很不错!当然,两家云厂商不会同时宕机。但是,在实践中,由于种种原因,在应用层面这样做是很困难的:
每种云的基础设施是不同的
部署的复杂性会大幅度增加
两者之间的带宽费用相当高昂
鉴于此,多云架构并不是高可用的可行方案(少数的边缘情况除外)。
多 Region
接下来,是关于多 Region 的讨论。AWS Region 是由多个可用区(availability zone,AZ)组成的,每个 AZ 是一个或多个的数据中心,它们具有独立的电源、网络和连接。在一个 Region 的多个 AZ 中运行能提供高可用性,但是无法提供灾难恢复(Disaster Recovery,DR)功能。为实现这一点,我们需要多个 Region。一个非常简略的多 Region 结构如下所示:
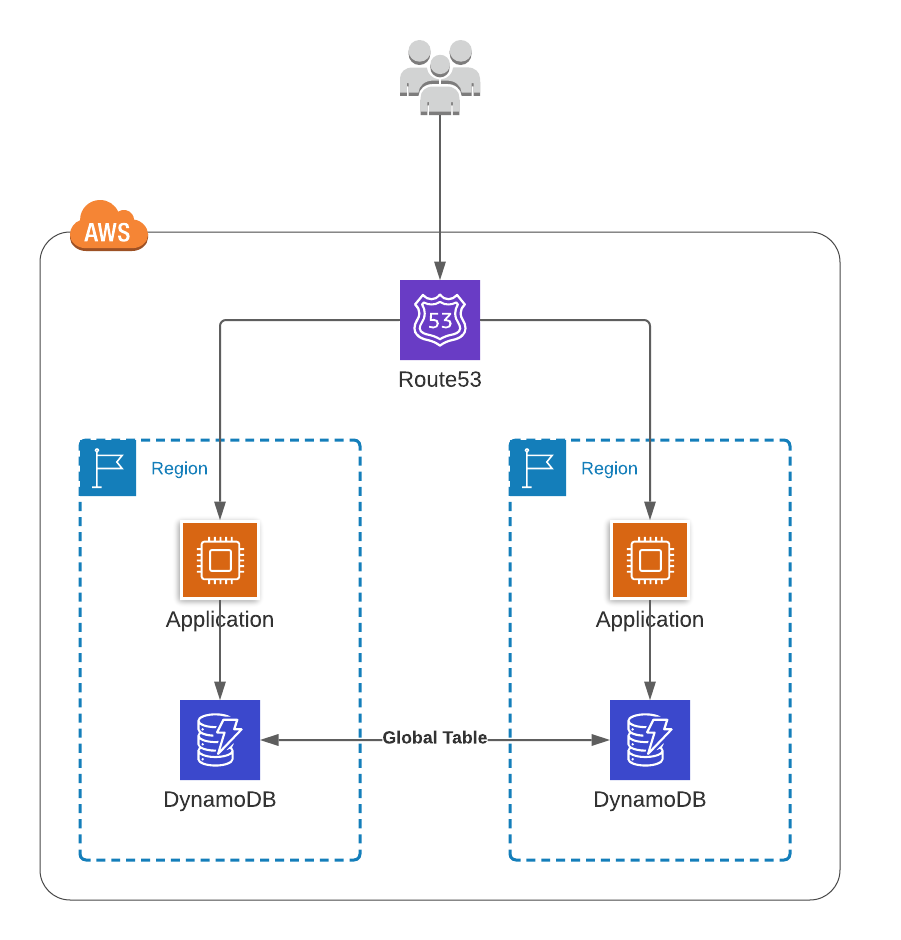
这种方式解决了多云架构的多个问题:
应用依然在同一个云中运行,所以基础设施保持不变
Region 是完全独立的,因此能获得同样的可用性优势
Region 之间的带宽费用要比云之间的费用低得多
但令人遗憾的是,大多数的评论都是围绕 Active-Active 的多 Region。也就是将负载同时分布到多个 Region,这带来了很多关于持久化同步方面的复杂性。同时,这种方式也会增加部署方面的复杂性,并且很多地方都很容易出错,甚至它本身的停机时间比 AWS 导致的宕机时间可能还要长。
多 Region DR
这是一种常被忽视的方案。它的理念是在同一时间只有一个 Region 处于活跃状态,在发生灾难的时候,另外一个备用的 Region 能接管系统的功能(因此是 DR)。这种方式和上面所述方案的收益是一样的,但是它能极大地规避全 Active-Active 架构的复杂性。在这种架构下,备用 Region 不用完全构建,只需要复制持久化数据即可。
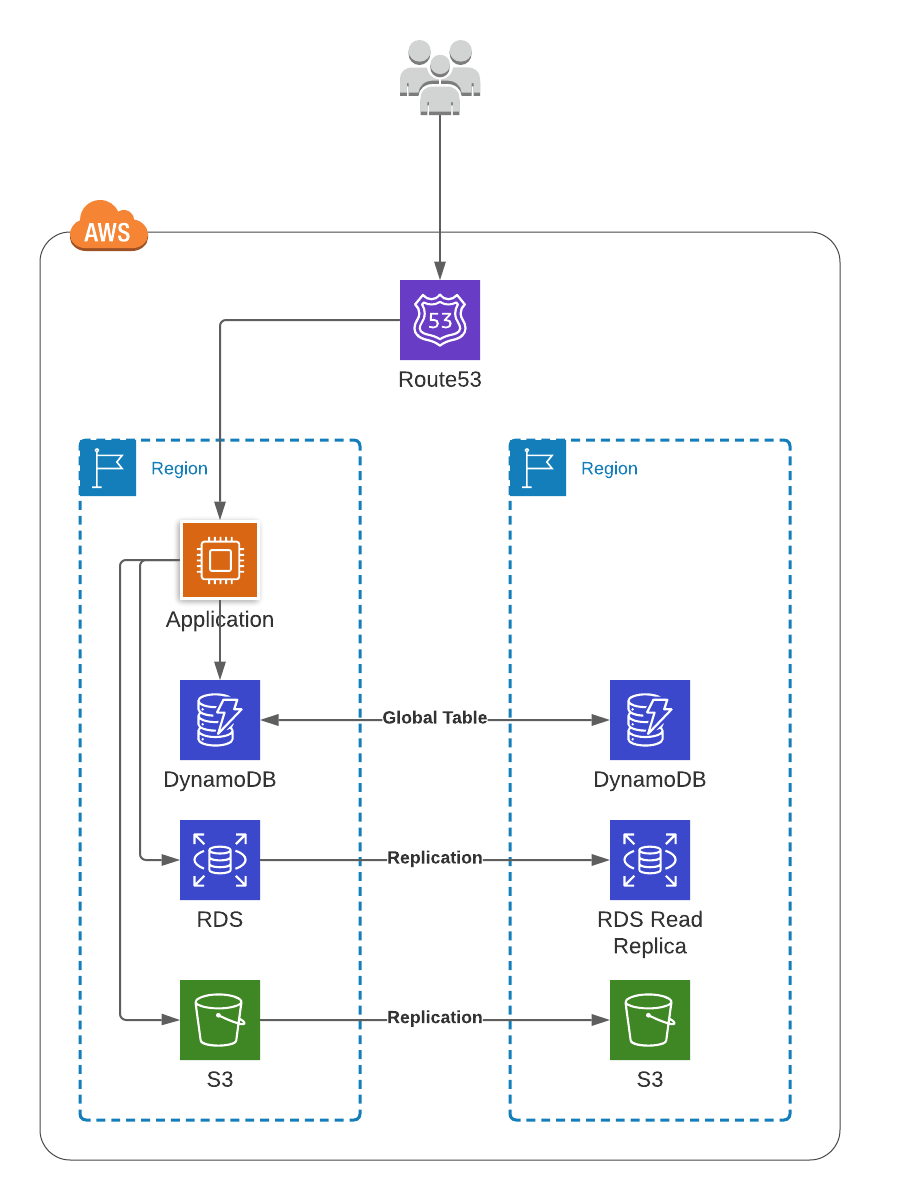
但是,稍等,在发生灾难时,部署完整的应用栈难道不需要一段时间吗?是的,是这样的,不过这是允许的!对大多数常见的中断场景来说,高可用是通过使用多 AZ 实现的,这种方式就足够了。如果整个 Region 出现问题,就像我们前段时间在 AWS 上所看到的那样,花费小于一个小时的时间从备份中建立一个新的应用栈,仍然要比大于八个小时的中断更可取。这个过程可以通过自动化的方式来进行简化,但即便是手动的(但经过了实践检验)操作,有可选的备用方案也是很重要的。
所以,我们更深入地探讨一下这种架构:
应用程序像平常那样部署在主 Region 中
使用 AWS 托管的服务、备份和副本实现数据持久化,这通常只需要一两个配置即可:
在不同的 Region 中为 RDS 添加一个读副本
创建 Dynamo DB global 表
启用 S3 bucket 副本
在进行故障恢复的时候,将应用程序部署在其他的 Region 上,并更新 DNS 的设置
这一过程要定期进行测试
这是一个银弹吗?绝不是。它并不适用于任何类型的工作负载,也绝对不可能适用于任何类型的宕机。然而,它是一个相对简单的方案,并且有一定的成本效益。
总结
总之,中断肯定是会发生的,这丝毫不会降低 AWS 的价值,但是这确实表明了良好架构和规划的重要性。我们可以设计一些非常昂贵和复杂的系统来缓解这些中断,但这对大多数客户来说是过犹不及和不切实际的。幸运的是,我们还有一些其他的选择,它们可能会提供一个“足够有效”的解决方案,并有合理的权衡,这应该成为在 AWS 上开展工作时的“最佳实践”。
原文链接:
https://www.forelse.io/posts/architectures-for-mitigating-aws-outages




