
出品|InfoQ 《大模型领航者》
访谈主持|霍太稳,极客邦科技创始人兼 CEO
访谈嘉宾|韦青,微软中国首席技术官
作者|褚杏娟
“Satya 刚上任 CEO 时,就跟微软的员工说,‘在技术行业没有人尊重传统,只尊重创新。”微软中国首席技术官韦青说道。
船大难掉头,同样对于有着近 50 年历史、20 多万员工的微软来说,创新并不容易。但是,微软这次却无疑走在了全球 AIGC 转型之路的最前沿。
微软早早就将 GPT 系列模型全面集成到了自家的产品体系中:Github Copilot、Office 及 PC 端等,在 OpenAI 的几次重大发布对部分企业造成打击时,微软只需要专心搞应用。微软确实也取得了漂亮的财报表现,比如 GitHub 年收入已达 20 亿美元,其中 Copilot 占收入增长的 40 % 以上,这已经比当初收购整个 GitHub 的规模还要大。
正如韦青所说,“大家看到的只是冰山一角,实际上,背后是积攒了可能几十年带来的成果。”
OpenAI 与微软的合作可以追溯到 2016 年。2021 年 Build 大会上,Satya 表示将“世界上最强大的语言模型”GPT-3 引入到了 Power Platform 上。2022 年的 Build 大会上,Satya 直接提到了 OpenAI 的名字,并把 GPT、DALL-E、Codex 纳入微软 Models as Platforms 服务的一部分。
Satya Nadella 2021 年、2022 年(从左到右)Build 大会的 keynote 演讲
但两者的合作只是微软 AIGC 转型的其中一面,对于普通开发者来说,更宝贵的应该是微软亲身实践的心得。在这次访谈里,韦青向我们介绍了一个更加务实、创新的微软。
为什么是微软
“我们不再只是讨论大模型、算力和存储这些了,已经不是那个阶段了。”
韦青加入微软至今已经 20 多年的时间,先后负责了移动产品、Windows 产品等。见证了互联网这么多年的变迁,他对这次 AIGC 转型的感想是:人的思想转型是最难的。
就拿微软的研发工程师来说,他们对 AIGC 的认识也是随着自己对各种应用的不断深入而持续刷新的。
具体地,比如微软 Fabric 工程师最开始的想法是“AI for Data”,可以理解为“AI +”,即将 AI 放入现有产品体系来改进数据处理。基于此,他们推出了第一版产品并获得了很大的成功。
但在开发第二版产品时,工程师们便意识到不能再继续沿用同样的方法。第二版产品的核心理念是“Data for AI”,对应地,可以理解为“AI*”。乘法与加法的思维方式有着本质的不同,乘法意味着内化,而不仅仅是增加,也就是说不仅仅要将 AI 应用到现有流程中,而是要为了新工具将现有流程进行重构。
虽然冲在了大模型应用的前头,但微软内部并没有神化大模型。Microsoft Azure 首席技术官 Mark Russinovich 评论大模型是“junior employee”,即学了很多知识、主观能动性很强、记忆力也超强,但是一个非常幼稚的员工。
要让这个员工知道怎么帮你干活,就需要“your data”来训练,否则它不知道你的喜好、边界。而用户能够使用的大模型就是用自己数据调整过的“小模型”。
微软的另一层考虑是,大模型的应用不应该被限制。“不存在只有谁能用谁不能用、大型机可以用边缘不能用等情况,函数调用要因人、因事、因地制宜。”因此,当概率模型不能起作用时候,工具就要通过调用软件、功能、函数等发挥作用。这也是为什么微软大力研发小模型的原因之一。
“当你不能用大模型或断网的时候,Phi 就是本地解决方式。Phi-3 作为一个边缘模型,在基座模型和 tool chain 之间,起到了非常重要的承前启后作用。”韦青说道。

韦青习惯于用系统工程方式考虑问题,有前提条件约束地思考,看到“水桶的短板”。他否认所谓要么是大模型时代、要么就是小模型时代等各种绝对的说法。“模型并不是越大就越好。大模型之所以大,是因为它们有更多的人造神经元,能够记住更多的知识,但这也会带来所谓的‘知识的诅咒’。”
在他看来,人们需要的不是一个无所不知的模型,而是一个能够理解自己喜好,并提供个性化建议的模型,这样的模型能够告诉我们“下周应该做什么”就足够了。当人们偶尔会对某个特定话题感兴趣时,则可以利用大模型来获取信息。
因此,人们身边的小模型除了能够调度本地应用,还要在必要时能够调用云端大模型,云端某个大模型可能擅长回答人文问题,而另一个擅长回答科学问题,可以通过分工合作提供更加精准和个性化的服务。
“这才是未来大家想要的,而微软 Azure 架构就是在为这种方式做准备,即将所有模型集中在一起构成一个庞大的系统。”韦青介绍道。
要利用好各种工具,算力、存储和网络通信都是必要的。如果网络通信存在延迟,就需要中央模型和边缘模型结合,边缘模型需要相应的数据支持,而有了数据就可以开发出自己的 Copilot。
以 Azure 为支点,微软构建了从基础设施、数据、工具到应用程序的完整技术堆栈来支持 AI 用户。与此同时,微软还加大了投入,将大约一半资本支出用于建设和租赁数据中心,剩下的部分主要用于购买服务器,但其投入速度依然跟不上市场需求。
微软全球向世界各地用户提供了“AI 全家桶”,但这应该算是云厂商的基本操作。微软现在已经进入下一阶段:向计算要效率,比如在提供针对大模型的计算能力时,微软甚至会对生成 token 的计算方式进行优化。
“我们现在做的是最大化人工智能的计算效率。”韦青说道,“不仅仅是计算,所有针对 AI 特点的数据流动,包括 prompt、KVQ 等,还涉及不同精度的计算,比如浮点数、16 位整数、8 位整数或 4 位整数等,都是优化目标。”
如何最大化算力的利用效率,并以最节能的方式进行计算,关键在于找到最有效的计算方法,以及如何以最小的实验成本生成所需的结果。“这并不意味着精度越高越好,而是要找到最适合当前任务的精度水平。”韦青提醒道。
超强工具的另一面
“一阴一阳谓之道”,任何事物都包含着对立统一的规律。
某个特别强大的工具开始被普遍使用时,了解它的负面影响是必要的,这就是负责任的 AI(Responsible AI)的核心理念,因为太强的话一定有弱点,比如公平性、透明性和可追溯性。

“世界上没有 100% 完美的事物,我们生活的是一个充满概率的世界。”在韦青看来,如果出了事故,责任在于人而非工具,人们要做的就是在充满概率性的波动中找到确定性。
“即使是现在,起码我认识的许多工程师在开发那些很厉害的工具时,他们都会秉持一个最基本的、第一性认知原则,即在开发一个特别强大的工具时,我必须知道它的弱点。”韦青补充道,“同样地,当听到有人说某事物非常糟糕时,我们也应该看到它积极的一面。只有看到了一个所谓不好事物的积极面,才能更有信心地作出评价。”
微软在 2019 年之前意识到这些工具变得越来越强大时,率先成立了 Responsible AI 团队。“有些公司可能会认为这是在浪费钱,但实际上,公司是社会的一部分。当公司开发出一款强大的工具时,如果不能确保其被负责任地使用,就可能遭到反噬。”韦青说道。
大模型应用启示
“现在早已经过了还在分析、还在想、还在空谈的时候了,全世界大量的企业和个人都已经进入了实用态。”
“模型不是你的产品,模型是你产品的一部分(model is not your product,model is part of your product)”Satya 在 2022 年 Build 大会上说道,这其实就蕴含了微软对大模型应用的理解。
韦青把大模型比作公有发电厂,它的任务就是发电。但只是发电的话,并不足以让大模型应用普及。
“人们并不能直接使用电子,电子需要被整合到电器中才能被使用。同理,这些 token 被整合到各种应用中,尤其是边缘计算领域,如 AIPC 等,大模型应用才会变得流行起来。”韦青解释道。这其实意味着,大模型要普及就得变成一种本地能力为个人使用。
如今,一些模型厂商开始卷入 token 的价格竞争。在韦青看来,大模型价格高低的问题就像问木材这种原材料的价格是贵还是便宜。木材可以按重量出售,但加工后的产品很难用同样的方式定价,木制工艺品、木家具等价格都不一样。
因此,价格竞争虽然有一定的意义,但问题在于大模型这种“电”还是没有直接产生价值。“当前的生成视频、图片和进行问答只是初级阶段,绝不是这些技术的最终目标。”韦青说道。
而要实现从 token 到应用的质变,意味着要做流程重构。
依然以电力应用为例,百年前的电烤面包机和电动洗衣机插头实际上是灯座,因为当时的人们没有意识到除了电灯之外,电力还可以做更多的应用,因此设计之初没有留有足够的插座,如果要将插座安装在墙内就需要修改设计图。
同样,大模型应用的普及也需要“修改设计图”,这对企业来说就意味着对现有流程进行重构。
但是,如果把各种流程拆开来看,这与 AI 既有关系,又没关系。
梳理现有流程、重构流程,确保每个节点都能进行数字化数据采集,这是第一步。这个阶段确保了企业能够不断产生数据来表征流程模型。
那么,接下来的问题就是:大多数公司都拥有大量数据,这些数据能否都被用来学习并提取知识?
数据要包含信息才有意义,而信息如果没被有效利用就没有价值,之后通过各种比对和分析,信息才会产生洞察力,进而形成知识。但事实上,大部分数据在收集时并不是为了机器学习,因此许多公司虽然拥有大量数据,但当要求 CTO、CIO 建立一个模型时却不知所措。
韦青对此给出的解答是,“他们需要重新考虑从数据到信息的转化过程,这取决于企业的目标是仅仅实现数字化和信息化,还是真正建立机器知识?而机器知识又是为了什么服务?”他解释称,对于数据、信息、知识和智慧的服务,如果要清晰地应用这一轮的 AI 模型,就需要有明确的目标,否则就会失去方向。
韦青提醒道,上述工作完成后,最重要的是通过 RLHF 给这些学习内容赋予人类的期望,在此基础上进行不断优化和微调。“使用这些模型后,人们会意识到,将数据转化为信息,再通过机器学习形成知识,是为了解决人类不想做、不能做、不爱做或做不好的事情。这些事情大多是重复性的,要求精确但不一定需要创意。”
此外,韦青从工程师角度提醒一个企业大模型纳入应用的前提。
首先,要对问题进行类似几何原理的定义和论证,然后将一个特别泛泛的问题拆分为若干个小问题。比如出版业是指受众获取、经营、内容制作,还是未来的发展方向?这些都是不同的问题,需要分别拆解和定义。
其次,要有公设。比如出版社是在中国、欧洲还是美国,数字出版还是纸质出版等。然后,要有公理、论证。只要结果,而不考虑前提的定义、公设和工程约束,是非常危险的。有了上述前提,我们然后才能进行推断,而这种推断遵循 DIKW 金字塔的结构。
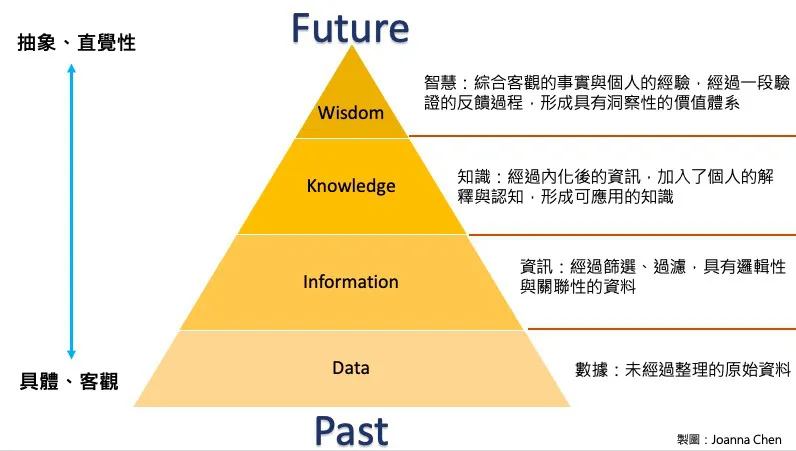
上述步骤跟 AI 其实没关系,但只有上面的这些基础工作完成后,讨论 AI 在某个行业中的作用才有意义。
对 AI 认知的极限,关键在人
“拥有了上面所有要素后,我们会意识到,技术是一方面,更重要的是人的问题。”
大模型的快速发展,让人无比期待 OpenAI 能赶紧发布更先进的模型 GPT-5。韦青并没有给出大家想要的爆料,相反,他发出了自己的疑问:难道因为 5 比 4 大,就意味着 5 一定比 4 好吗?
“这实际上是一个没有意义的问题(大的不一定是好的)。关键在于社会民众对机器智能能力的需求达到了什么程度,届时一定会出现与这个需求相匹配的服务。”这是韦青的答案。
他结合自己的经验说道,“如果你真的在一个产品团队中工作,尤其是在那些全球顶级的产品团队,只要参与过产品开发你就会明白一个事实:没有人能确切地知道下一步会发生什么。”
韦青认为,对于我们所有人来说,接下来真正的挑战不仅仅是技术,真正限制在于我们的意识。他用了一句很哲学的话来总结:我们越接近真相的核心,就会发现我们离真相越远。
他举了两个例子。比如,2017 年人工智能战胜围棋选手,严重打击了顶尖选手:机器告诉我们,人类下了 2,000 年围棋,但连围棋的皮毛都没摸着。又比如,我们以为自己最远只能骑自行车到北京香山登上其最高峰香炉峰(又称鬼见愁),然后就认为自己登上了世界最高峰鬼见愁,但其实同时代已经有人用更先进的工具到了真正的最高峰珠穆朗玛峰。
“不能因为你到不了就认为不存在、认为人类无法达到。我们的寿命和思想经历是有限的。”韦青说道。
当前我们被限制的一个表现是:在产品开发中,人们又把自己当作机器来对待。
“很多时候,我们根本没有意识到我们不知道,结果机器刚刚把我们带到一个认知的边界,很多人就绝望了,认为机器将完全超越我们。我觉得不是这样。我们才到‘鬼见愁’,就争论机器要不要代替人类、人类有没有未来,这反映了人们已经被局限了。我们没有意识到,我们不应该将人视为机器。人天生不需要做机器做的事。”
在韦青看来,人类最大的特点在于擅长制定规则和“破坏”规则(这里的“破坏”是指创新和优化规则),而机器恰恰特别擅长于理解和严格执行规则。按照这个逻辑,人类本来就应该负责发号施令,让机器去做那些重复性和规则性强的工作,并在机器完成后不断改进,来保持人类的创新优势。
韦青眼中的人工智能边界是“极大、极小,极远、极近”的。极大就是宇宙,比如 AI for Science,只是生成图片和视频是不够,它会在生产力和科学上有巨大突破;极小是量子,比如把材料、药物分子等重新组合,带来更好的效果。极远是太空旅行,极近就是认识自己。
给程序员的一些建议
如今,韦青依然坚持自己动手去写代码,虽然无法编写大型软件,但仍然要保持手感。当我们把目光放到更细分的程序员群体,coding 出身的韦青也给出了自己判断和建议。
作为几十年的软件开发者,韦青经历了纯手工撸代码的时代,现在也开始尝试代码生成工具。
多年前,他想要自己手搓一个基础的多层神经元模型,以便深入了解更多神经元架构的细节,但因为工作繁忙而未能实现。几年后他便使用 Copilot 辅助编写,“没有进行任何优化,没有针对内存或数据位移做任何处理,只是用 C 语言直接实现了”:
我们首先共同定义了数据结构,然后列出了 CNN 所需的所有函数定义,包括 ReLU、Sigmoid 等激活函数,以及矩阵乘法等。我们还列出了这些函数的导数和偏导数,然后一起实现。实现完成后,我们构建了一个测试用例,并运行了这个用例。整个过程大约花费了一个小时,写了大约 2000 行代码,而且每个函数都是正确的。虽然还需要进行一些调整,但效率非常高。
“如果我们的程序员也能够这样工作,那该有多好。”韦青感叹道,“但是,如果程序员不了解网络结构的底层知识,仅仅依赖于 Tensorflow 或 PyTorch 等工具,那么也是无法有效完成任务的。”
要达到这样的水平,需要开发者对数学,特别是机器学习领域的知识有深入的了解。
韦青认为,未来的趋势就是,程序员要在两端都非常强大:既要有扎实的底层知识,也要对行业需求有清晰的认识。虽然中间的实现部分也很重要,但最关键的是要保持对基础数学建模能力和行业需求的深刻理解。
这意味着,对程序员来说,只擅长写代码已经不够了。
韦青回忆起多年前了解到的一家日本软件公司,高级软件工程师只写伪代码,其完成逻辑描述后,让所谓的“码农”去写将 UML(统一建模语言)。无论客户要求使用 C 语言、Java 还是 C#,“码农”都能根据伪代码转换成相应的代码,但他们并不能真正理解行业。
编写伪代码的人是那些既了解行业知识,又懂得基本逻辑描述的人,而真正编写 C、Python 等代码的工作其实可以交给机器完成。韦青说道,“我们应该从码农升级为程序员,程序员的水准是达到架构师的水平,即具备行业知识,并能够用逻辑方式表征这些知识。”
结束语
Satya 不建议微软称自己为 leader(领先者),而是用 Incumbent(现任者)。现任者把人从创新者窘境中拉出来,等着后面 challenger(挑战者)来超越。韦青将其解读为“胜不骄、败不馁”。
而对于未来,韦青借用 Ilya Sutskever 的话来总结:尽量能够比这个时代超前半步,但也别超前太多。“因为现在所有对技术的不足都是马后炮,但超前多一点点看,大部分问题都很快会被解决。”这是一种更加务实的态度。
如今,这场 AIGC 竞赛还没有结束,微软能否继续坚守自己 Incumbent 的位置,我们拭目以待。




