
导读:中信银行信用卡中心每日新增日志数据 140 亿条(80TB),全量归档日志量超 40PB,早期基于 Elasticsearch 构建的日志云平台,面临存储成本高、实时写入性能差、文本检索慢以及日志分析能力不足等问题。因此使用 Apache Doris 替换 Elasticsearch,实现资源投入降低 50%、查询速度提升 2~4 倍,同时显著提高了运维效率。
本文转录自陈地长(中信信用卡中心信息技术部 高级工程师)在 Doris Summit Asia 2024 上的演讲,经编辑整理。
中信银行信用卡中心(以下简称“卡中心”)隶属于中信银行,致力于为广大消费者提供涵盖支付结算、消费信贷、中收增值和特色权益的“金融+生活”全方位服务。卡中心构建了高端、商旅、年轻、商超、车主及零售六大主流产品体系,形成了产品、渠道、经营、合规风控和服务五大经营体系,综合实力在股份制银行中名列前茅。
为确保业务系统的稳定运行、提升运维效率和用户体验,卡中心建立了大规模的日志云分析平台。该平台不仅需支持实时监控和故障排查,还需满足金融监管对日志审计的严格要求。目前,平台每日新增日志数据突破 140 亿条、80TB,全量归档日志量超 40PB。
早期基于 Elasticsearch 构建的日志云平台面临存储成本高、实时写入性能差、文本检索慢以及日志分析能力不足等问题。因此,卡中心决定引入 Apache Doris 替换 Elasticsearch,实现资源投入降低 50%、查询速度提升 2~4 倍,同时显著提高了运维效率。
日志数据分析运维需求背景
在当前日益复杂的业务需求下,催生出了各种复杂的应用系统,这些应用系统分布在 Linux、Windows 等多种操作系统之上,同时依赖于各种网络设备、安全设备、中间件和数据库等服务,这些软硬件运行时每天可产生的日志量能达到 TB 级别。一旦系统运行出现异常,就需要通过分析日志进行问题排查。
日志的存在原本是通过其所记录多样化的数据、关键信息来帮助我们更好了解系统的运行状态。然而,面对卡中心每日新增 TB 级别日志数据,当系统异常时,日志格式的多样性同样也给数据分析带来极大的困难,主要挑战如下:
格式难以统一:日志数据以自由文本形式呈现,尽管相较于结构化数据信息更丰富,但其半结构化特性在数据分析和监控方面带来较大挑战。
日志分析需求难以满足:日志种类繁多、分析需求各异。对不同业务、数据库和中间件全面分析与监控时,面临诸多挑战。
运维效率低:出现问题时,运维工程师需要逐台登录服务器查看日志,效率低下,人为排障可能引发额外风险。
缺乏可视化展示:常规日志分析方法无法以可视化展示,难以满足统计分析和业务指标趋势监控等更高水平的管理需求。
难以评估影响范围:难以通过事件及其相关的软硬件日志了解对业务的影响,也无法对大量运行历史数据关联分析。
基于 Elasticsearch 的日志云平台
为确保业务系统的稳定运行,提升运维效率和用户体验,卡中心早期基于 Elasticsearch 构建日志云平台。整体采用 ELK 技术栈,支持应用日志、基础组件、中间件、数据库日志的存储与分析。架构图如下:
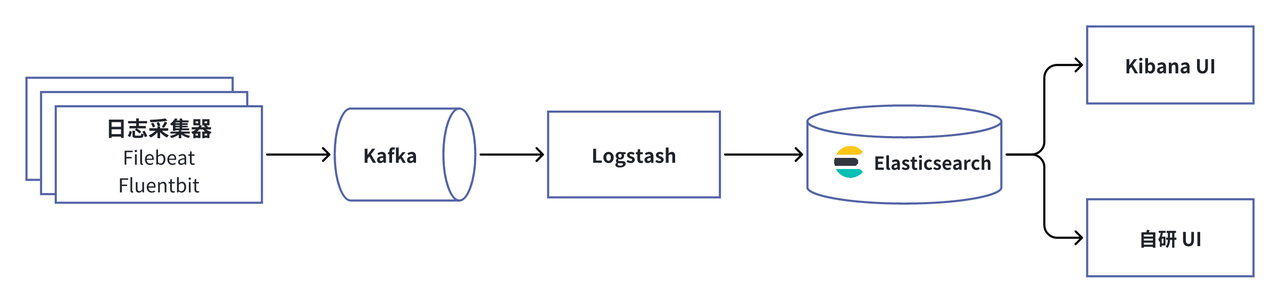
日志数据通过 Filebeat 采集到 Kafka ,经过 Logstash 处理后存储到 Elasticsearch 中。通过 Kibana UI 和自研 UI ,为开发和运维人员提供日志搜索以及全链路日志查询等服务。
存在的问题:
存储成本高:在降本增效大背景下,业务对降低存储成本的需求日益迫切。然而,由于 Elasticsearch 会对正排、倒排、列存等多份数据存储,给降本提效带来一定的挑战。
高吞吐实时写入性能差:面对每天大量的新增数据,要求日志云平台具备 GB/s、百万条/s 的高吞吐写入能力,并保证数据秒级写入延迟,确保数据的实时性和可用性,但随着数据量的增长 Elasticsearch 很难满足。
日志数据分析能力不足:Elasticsearch 分析能力较弱,只支持简单的单表分析,而不支持多表 Join、子查询、视图等复杂分析,难以满足愈发复杂的日志分析需求。
Doris VS Elasticsearch 性能评测
通过调研业界日志存储领域的新进展,发现 Apache Doris 有明显的优势:
高吞吐、低延迟日志写入:支持每天百 TB 级、GB/s 级日志数据持续稳定写入,同时保持延迟 1s 以内,确保数据的实时性和高效性。
海量日志数据低成本存储:支持 PB 级海量数据的存储,相较于 Elasticsearch 的存储成本可节省 60% 到 80%,并支持将冷数据存储到 S3/HDFS 等低成本存储介质,存储成本可再降 50%。
高性能日志全文检索:支持倒排索引和全文检索,对于日志场景中常见的查询(如关键词检索明细,趋势分析等)能够实现秒级响应,为用户提供极致的查询体验。
强大的日志分析能力:支持检索、聚合、多表 JOIN、子查询、UDF、逻辑视图、物化视图等多种数据分析能力,满足复杂的数据处理分析需求。
开放、易用的上下游生态:上游通过 HTTP API 对接常见的日志数据源,下游通过标准 MySQL 协议和语法对接可视化分析页面,为用户打造全方位的日志存储和分析生态。
易维护、高可用集群管理:支持完善的分布式集群管理,支持在线扩缩容等操作,无需停止服务即可进行集群升级。
为更进一步验证其性能,卡中心基于 httplogs 数据集和实际日志数据对 Doris 和 Elasticsearch 进行了性能测试,测试结果显示:
在相同日志量下,Doris 相较于 Elasticsearch 表现优异:磁盘占用空间下降了 58%,日志写入峰值提升 32%,查询耗时缩短了 38%。此外,Elasticsearch 使用了 9 台 16 核 32G 的服务器,Doris 只用了 4 台 8 核 32G 服务器,CPU 资源仅是 Elasticsearch 的 1/4。

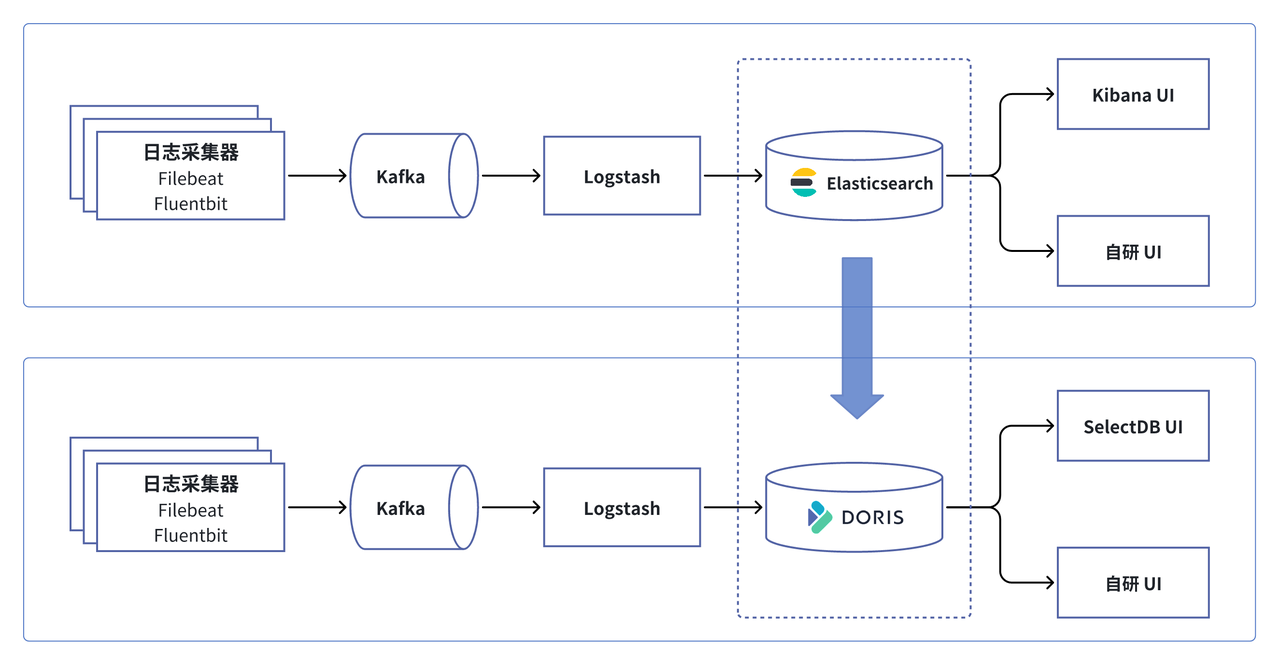
基于 Apache Doris 的全新日志云平台
综合上述对比及测试结果,卡中心决定引入 Apache Doris 进行升级,替换早期架构中的 Elasticsearch。基于 Doris 提供日志的统一采集、清洗、计算、存储、检索、监控和分析等多项服务,实现一站式日志管理与分析。同时,Kibana UI 被替换为 SelectDB UI,基于 Doris 自研 UI 更贴合卡中心业务的需求。
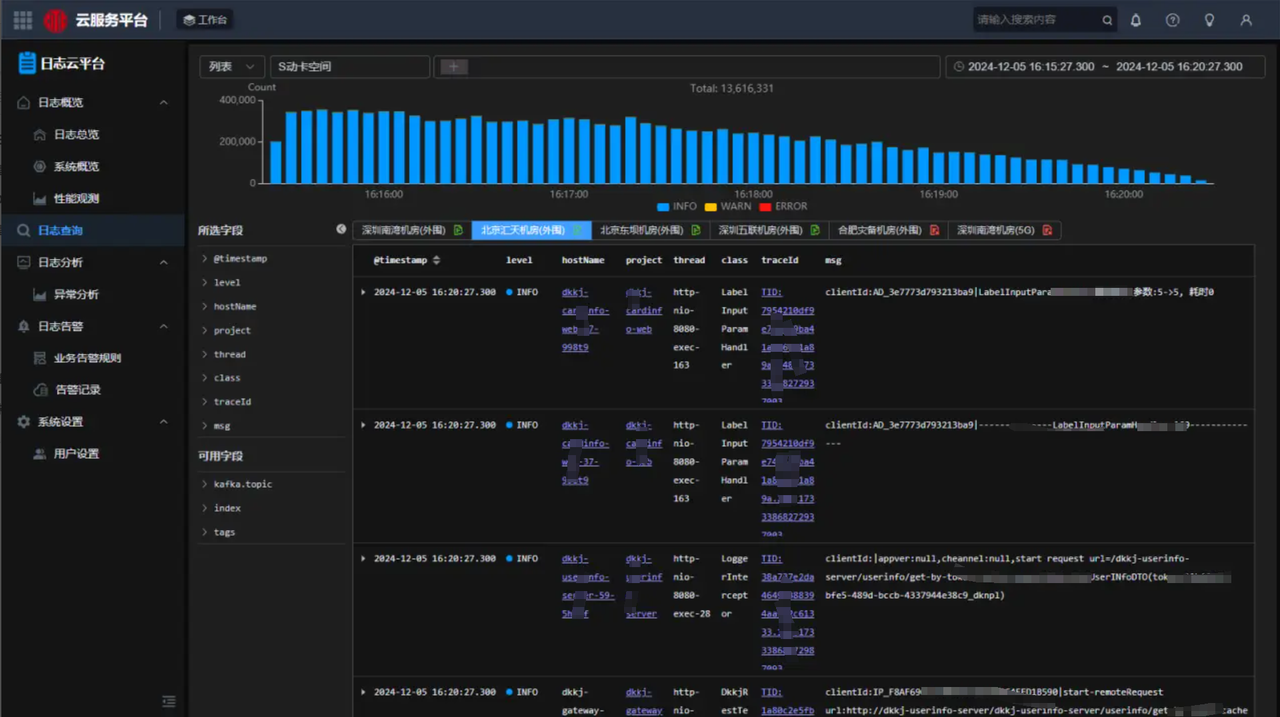
01 统一日志云查询入口
当前日志云集群规模约为 19 套,如果每套集群都有不同的查询入口,查询过程将显得尤为繁琐。因此,卡中心基于 Doris 建立了统一的日志云查询入口,用户可以在同一 UI 下查询不同机房和系统的日志。
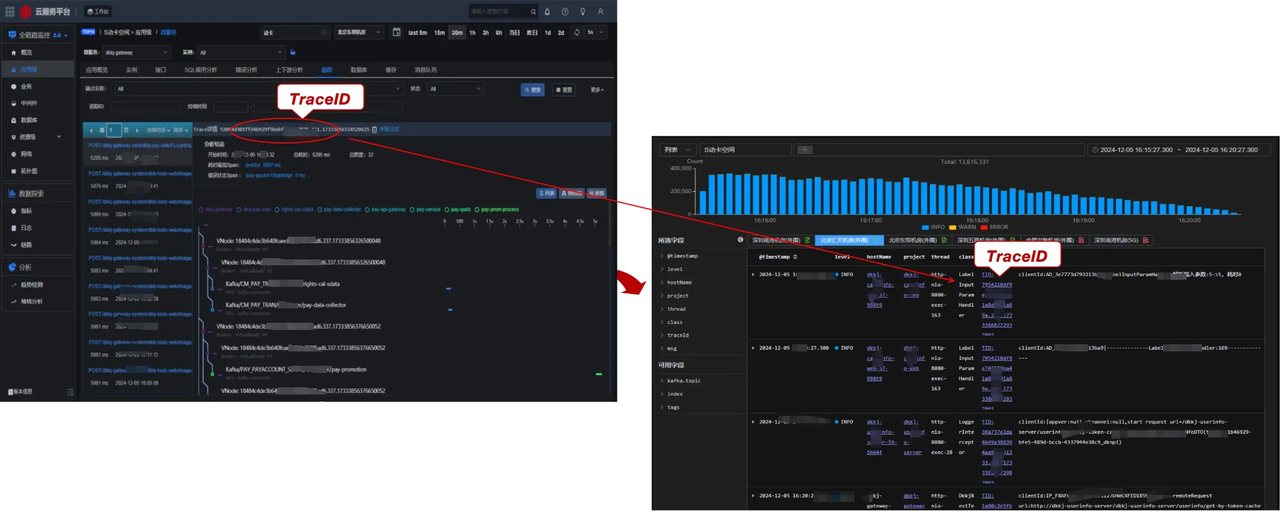
02 基于日志的链路分析
卡中心整合了全链路监控体系的三大要素:指标、链路和日志,并基于 Doris 实现了日志链路分析及透传功能。可将全链路监控中的链路追踪 ID(Trace ID)传递到日志云查询 UI,使双向串联成为可能。
具体来说,每笔请求链路可自动与日志明细关联绑定,用户可查看每笔流量日志的整体上下游信息,并在每个阶段的对象上获取相关日志,实现从链路到日志、日志到链路的穿透式查询。此外,当发现错误链路或耗时链路时,可对关联日志明细进行分析,打通排障最后一公里。
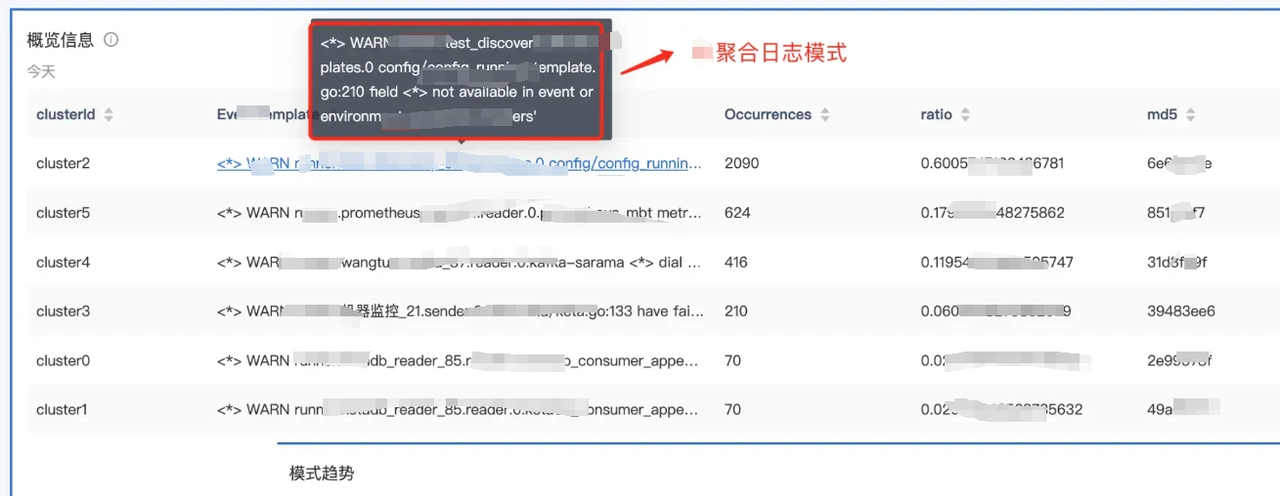
03 日志模式异常
为更好处理日志模式异常的问题,卡中心进一步开发了日志识别模版系统,可自动找出非预期的日志模式问题。
在日常运维排查中,注意到系统上线后,可能因潜在变更引发突发性问题,这些问题通常通过错误日志来体现。值得说明的是,这些错误日志的模式可能因变更而不同,例如,某些错误在变更前的系统中未曾出现,而在变更后却频繁出现,且其增长趋势与以往截然不同。
因此,利用该模板系统能够精准识别异常日志,并通过实时的告警推送机制,及时通知相关人员。这一功能不仅能够帮助我们提前发现系统中潜在的问题,还能够显著提升问题响应速度,确保系统的稳定运行。
04 优化实践
在日志云场景中,使用 Apache Doris 构建新一代日志云存储分析平台,经过长时间的测试和验证,总结出以下一些优化经验。
表结构优化:
基于时间字段的分区设计,开启动态分区,提升数据管理和查询能力。
设置基于冷热分离数据保留策略。
设置基于磁盘属性的热数据写策略,SSD 盘用于热数据写,提高写入能力。
使用 ZSTD 数据压缩算法,有效降低数据存储空间。
合理设计字段索引,对于高基数字段使用 BloomFilter 索引,需要全文检索的字段使用倒排索引。
配置项优化:
Compaction 优化,加大 Compaction 线程数:
max_cumu_compaction_threads增大写入端刷新前缓冲区大小:
write_buffer_size。开启 tablet 均衡策略:
enable_round_robin_create_tablet增大单个 tablet 版本数,提高写入能力:
max_tablet_version_num
数据写入优化:
开启单副本导入,先写入一个副本,其他副本数据从第一个副本拉取,导入性能提升 200%
开启单 tablet 导入,减少多个 tablet 写入时带来的文件读写开销。
提高单次导入的数据量,一次写入 100MB 左右。
使用收益
以一个机房集群投产为例,基于 Doris 的日志存储与分析平台上线后,相较于原有的 Elasticsearch 架构,成功减少了日志冗余存储,提高了日志数据存储效率,同时提供了强大且高效的日志检索与分析服务。以下是以东坝机房为例的具体收益:
资源投入节省 50%: CPU 使用率使用率约为 50%,整体资源使用率仅为之前的 1/2。原先同样数据规模,写入 Elasticsearch 需要 10TB 空间,采用 ZSTD 压缩技术,写入 Doris 规模仅需要 4TB 。
查询提速 2~4 倍: 新架构以更低的 CPU 资源消耗带来了 2~4 倍的查询效率提升。
增强日志可观测能力: 通过穿透链路、指标、告警等平台,提升了日志模式识别、分类聚合、日志收敛与异常分析等可观测能力。
提高运维效率: 新平台提供极易安装和部署的程序,以及易于操作的管理工具,简化了服务、配置、监控和告警等操作,显著提高了集群的扩缩容灵活性。
未来展望
未来卡中心将持续迭代日志系统, 并重点从以下几方面发力:
广泛推广 Doris:持续推进剩余机房 Elasticsearch 替换成 Doris,推进剩余的日志云 Elasticsearch 集群替换成 Doris。
丰富日志导入预处理能力:增加日志采样和结构化等预处理功能,进一步提升数据的易用性和存储性价比。
增强 Tracing 能力:打通监控、告警、Tracing 和日志等数据的可观测性系统,以提供全方位的运维洞察。
基于大模型的 AIOps:持续探索智能运维的最佳实践,包括日志异常监测、故障预测和故障诊断等。
扩大 Doris 使用范围:除了日志场景,Doris 将逐步引入数据分析和大数据处理场景,增强湖仓一体的能力建设。




