
携程在 2016 年左右开始应用 Kylin 的解决方案。在 2018 年的 5、6 月份,我作为小白接手了 Kylin,逐渐琢磨、踩坑,折腾折腾就过来了。我将介绍 Kylin 在携程这一年的发展历程,碰到的挑战,以及解决的问题。
背景
1 早期架构
下图是携程早期的 OLAP 结构,比较简单。有两个应用,一个是 BI 分析报表工具,另一个是自助分析的 Adhoc 平台,下层主要是 Hive,技术比较单一。Hive 是比较慢的运行引擎,但是很稳定。期间我们也使用过 Shark,但 Shark 维护成本比较高,所以后面也被替换掉了。文件存储用的是 HDFS。整个架构是比较简单的,搭建过程中成本也比较低。
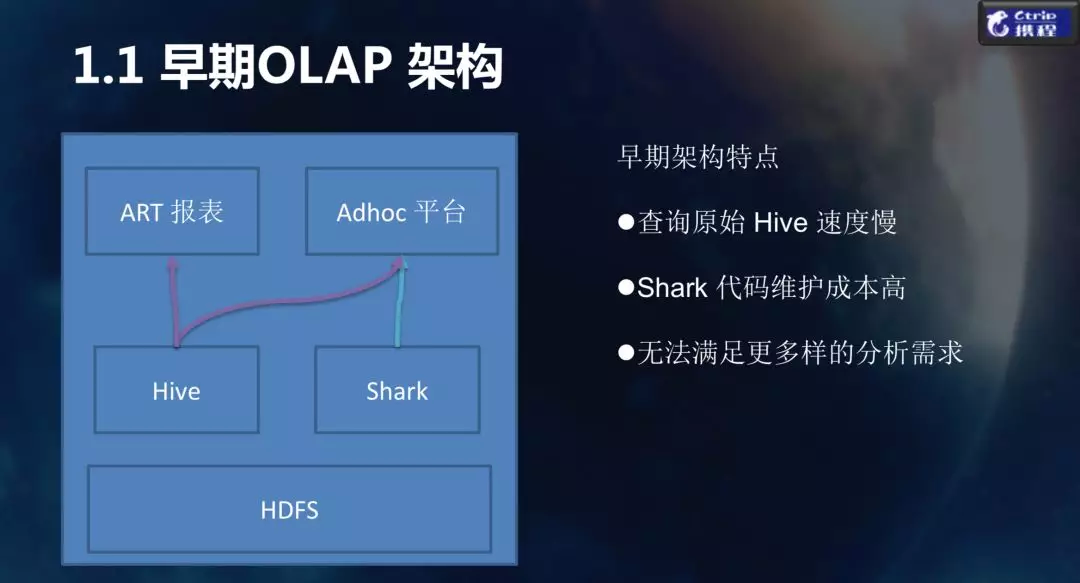
早期架构的特点:一个字 慢! 两字 很慢! 三个字 非常慢!!!
2 技术选型
随着业务需求的多样化发展,我们团队引入了许多 OLAP 引擎,其中也包括了 Kylin。这里我们重点介绍下选择 Kylin 所考虑的几个方面:
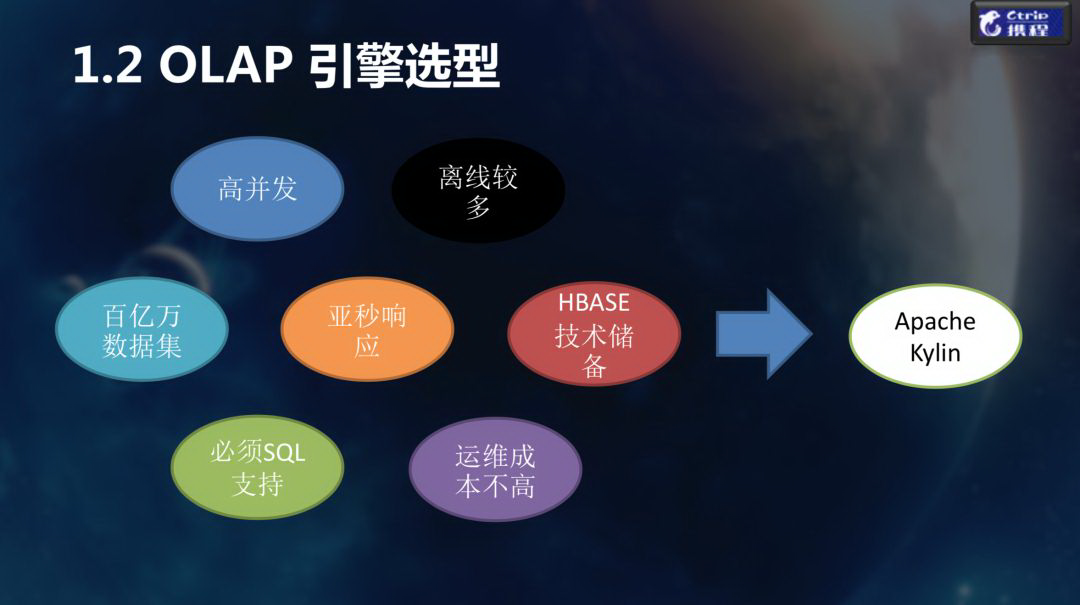
百亿数据集支持:
首先对我们来说,海量数据的支持必不可少的。因为很多的用户向我们抱怨,由于携程早期都是采用微软的解决方案,几乎没办法支撑百亿级的数据分析,即便使用 Hive,也需要等待很长时间才能得到结果。
SQL 支持:
很多的分析人员之前使用的 SQL Server, 所以即使迁移到新的技术也希望能保留使用 SQL 的习惯。
亚秒级响应:
还有很多的用户反馈,他们需要更快的响应速度,Hive、Spark SQL 响应只能达到分钟级别,MPP 数据库像 Presto、ClickHouse 也只能做到秒级,毫秒级是很困难的。
高并发:
在一定的用户规模下,并发查询的场景非常普遍。仅仅通过扩容是非常消耗机器资源的,一定规模下维护成本也很高。而且,传统的 MPP 会随着并发度升高,性能出现急剧的下降。就拿 Presto 来说,一般单个查询消耗 10 s,如果同时压 100 个并发,就出不了结果。Kylin 在这一方面的表现好很多。
HBase 的技术储备:
携程有大量使用 HBase 的场景,在我们大数据团队中有精通 HBase 的开发人员,而 Kylin 的存储采用 HBase,所以运维起来我们会更得心应手。
离线多:
携程目前离线分析的场景比较多,Kylin 在离线分析场景下属于比较成熟的解决方案,所以我们选择了 Kylin。
当前架构
首先我们先看一下目前 Kylin 在携程的使用规模。

Cube 的数量现在稳定在 300 多个,覆盖 7 个业务线,其中最大的业务线是度假玩乐。 目前单份数据存储总量是 56 T,考虑到 HDFS 三份拷贝,所以总存储量大约 182 T,数据规模达到 300 亿条左右。最大的 Cube 来自于火车票业务,一天最大的数据是 28 亿,一天次构建最大的结果集在 13 T 左右。 查询次数比较固定,基本上是 20 万查询/天,通过 Kylin 的查询日志分析下来,90% 的查询可以达到 300 ms 左右。
下图是 OLAP 的架构图,在携程主打的 OLAP 采用 Spark、Presto 和 Kylin,Hive 慢慢被 Spark 给替代。Kylin 服务两个业务产品,一块是 Artnova BI 分析工具,还有其他的业务部门报表产品,也会接入 Kylin。存储层是 HBase、HDFS 等等。
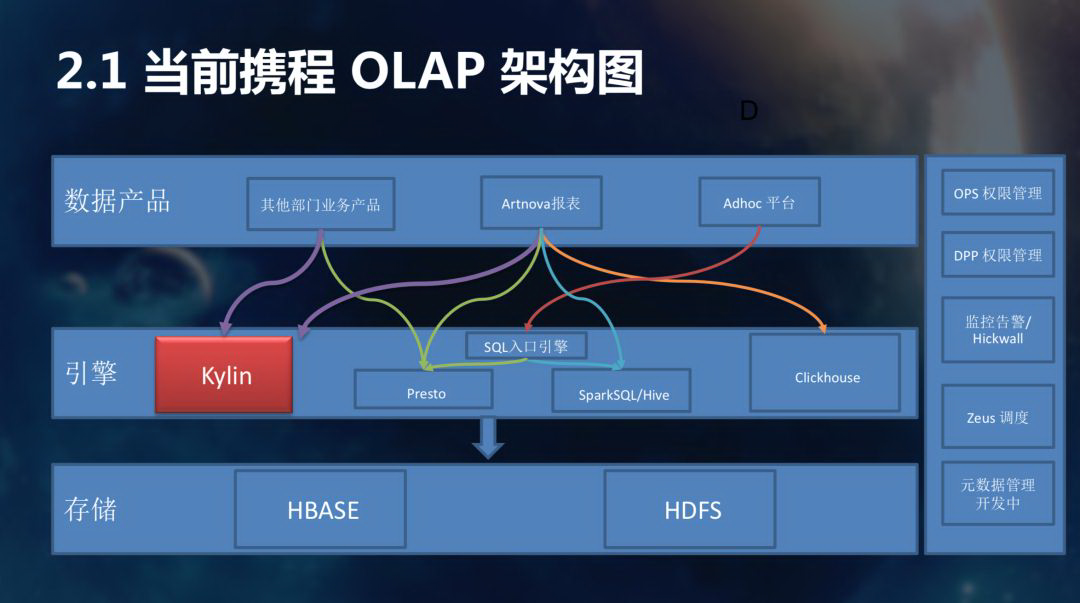
这里顺便提到元数据的管理,目前正在做这块的开发,其中包含字段的血缘分析、表的特征分析,后期 Kylin 会根据分析的结果自动替用户构建 Cube。 打个比方:某些表,用户频繁的访问,或者在维度很固定的情况下,Kylin 就会自动配置一个对应的 Cube。前端的报表自动就匹配了 Kylin 作为查询引擎,对用户来说,之前每次要 20 s 才能展示的报表,突然有一天只需要 500 ms 就可以展示了。
另外,我们计划将 Kylin 接入规则引擎,从而给数据产品提供统一的入口。并且提供查询自动降级等对用户友好的功能。
我们再看下 Kylin 部署图:
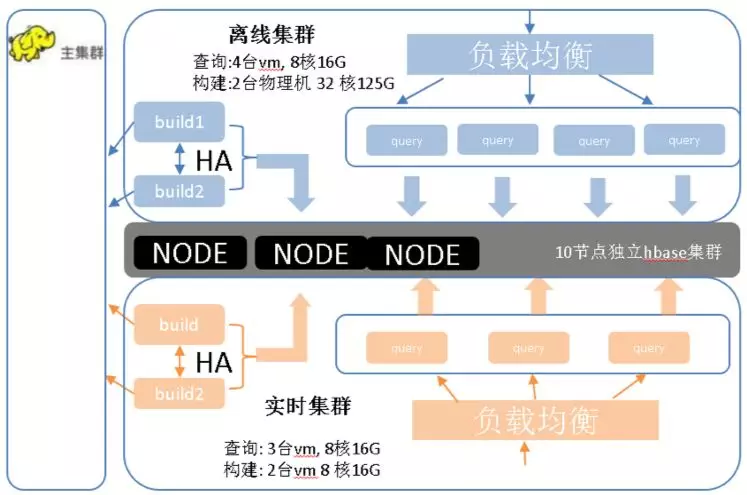
1 两套集群
主要考虑到 MR 构建的性能。目前在大集群上跑 MR, 由于 Hadoop 在高峰时期持续到中午都非常繁忙,计算资源基本上是满负荷。一次 MR 任务的调度需要等待 20 秒左右才跑起来,对于准实时的构建性能影响非常大,很难满足用户的准实时数据落地的需求。虽然目前暂时把任务优先级别调高,但提升也是比较有限的。
2 负载均衡
负载均衡是为了防止单机宕机对用户产生的影响,是出于稳定性的考虑。
3 独立的 HBase + HDFS 查询集群
脱离线上大集群,单独构建 HBase + HDFS 集群, 可以大大减少其他因素对于查询性能的影响。
4 共享的计算集群
在我们接收 Kylin 之前,整个 Kylin 的部署是 7 个业务线,7 个 Kylin 的 Instance,比方说火车票这个 Instance 只有 2 个 Cube,每天的查询量几百次。单个节点放在那里很多时间都是空闲的,浪费资源不说,维护成本也高。
为什么要读写分离? 因为 Kylin 是典型的适用于一次写、多次查询的场景,对于查询,最好是其他不相关的干扰因素越少越好。在之前的构建和查询混杂在一起的情况下,查询性能受制于构建任务,互相制约,难以保证服务的稳定性。
监控
我们自己开发了一套 Kylin 集群的监控系统。
1 Kylin HBase 集群的监控,把握 HBase 的负载
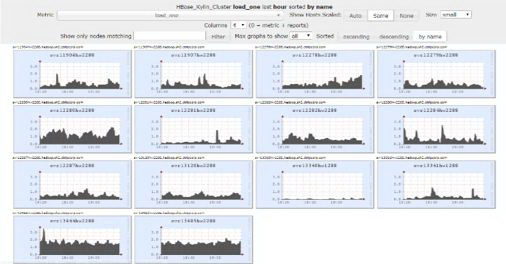
这里我们说个故事。几个月前,Kylin 出现了一个很大的与 Kylin HBase 相关的问题。因为 HBase Master 进程和 ZooKeeper 失联了,然后 HMaster 两个都失联,全部挂了之后,整个 HBase Master 出现宕机状态。我们最后是通过上图的页面发现当时 HMaster 系统的 CPU 特别高,然后顺藤摸瓜,找出问题的根源。
2 查询性能监控
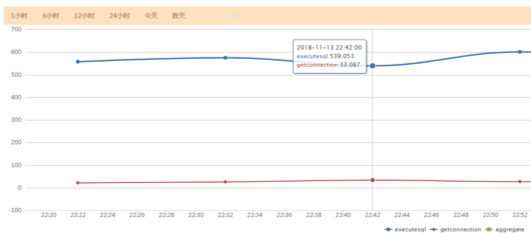
可以更加实时地看到各个时段平均查询的响应速度,我们每次优化之后都能通过这个页面看到优化的效果是否明显。
3 清理合并任务的运行状态监控告警
通过这套监控系统,我们可以实时把握 Kylin 的垃圾清理状态。Kylin 中数据垃圾的堆积是灾难性的, 如果不监控,积少成多的失败会导致灾难性的后果。
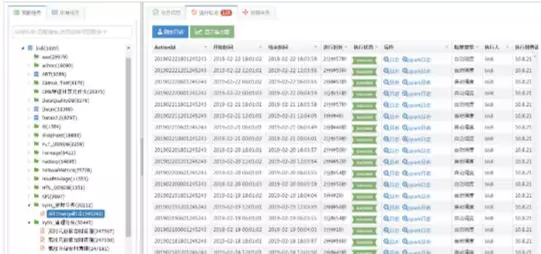
这里说个故事。之前由于合并清理任务没有及时地被监控,导致长时间的失败,我们都没有在意,后果是什么呢?HBase 的 Region 数量暴增到 5 万以上,导致 HBase 的压力特别大,最后无法支撑,从而挂机,这是个惨痛的代价。
经验分享
1 维度组合优化
像度假部门,他们很多的场景需要 20、30 个维度。在这种场景下,我们需要确定强制维度。为什么使用强制维度?比方说:用户门票分析,有些维度是必需的,比如性别、姓名、身份证。通过优化其实可以将原先 30 个维度的场景减少到 14 个以内。
2 高基字典
如果在 Kylin 上面配高基 dict,fact distinct 这个步骤就会对于高基的字典生成一个很大的如下 Sequence File,如果这个文件达到 700 MB,Hadoop 初始化 StreamBuffer 时就会抛出异常。
1.4G hdfs://ns/kylin/kylin_metadata/kylin-a2696e1c-1516-4ff1-800e-5f7b940d203a/C_PaymentCR_Flat_clone/fact_distinct_columns/V_OLAPPAY_CONVERTRATE_FLAT.SITE
异常详情与解决方法见:https://plumbr.io/outofmemoryerror/requested-array-size-exceeds-vm-limit
3 MR 内存分配
精确去重时,Kylin 会做全局字典,在 MR 构建过程中,全局字典在 Kylin 里会被切分成很多 Slice,构建过程中这些 Slice 存放在缓存中。由于缓存需要控制大小,所以通过不停地换入换出,保证缓存的大小可控。由于每个数据其实都需要访问其中一个 Slice,我们遇到的问题是:因为内存太少,整个全局字典 Slice 换入换出太频繁,一条数据过来之后,找不到 Slice,会从 HDFS 中加载。整个过程非常缓慢,当我们把内存调高了一倍之后,构建速度明显改善。
4 构建调度缓慢
Kylin 依赖 Scheduler 的实现去调度 Job 构建任务,在 Streaming 的构建场景下,会积累大量的历史 Job 信息。Scheduler 在每个步骤调度的间隔会去扫描 Job 历史,从而获取哪些 Job 需要继续被构建下去。在这个过程中,Scheduler 会一个一个 RPC 请求访问 HBase。如果 Job 历史超过 1 万个,1 万次 RPC 的请求耗时大概有 1 分钟左右,这样大大影响 Scheduler 的调度性能。我们这里通过缓存需要被调度的 Job 信息,减少了 99% 的无用的 HBase RPC 调用,从而提高了整体调度间隔消耗的时间。
5 Merge 上传无效字典
用过 Kylin 的人都知道,在 Kylin 构建过程中,有很多的 Segments 之后,要把它们 merge。Streaming 产生新 Segments 的频率很高,因此,可能 5 分钟就出现一个 Segment。一天里,一个 Cube 就可以产生 1440 个 Segments。在 merge 的过程中,即使 merge 两个 Segments,Kylin 也会上传 1440 个 Segments 的元信息。这块我们已经进行优化,并且成功合并到了 Kylin 2.6.0 之后的版本:https://issues.apache.org/jira/browse/KYLIN-3826。
6 数据安全
当我们迁移到统一的公用集群之后,我们要考虑数据安全,每一个用户仅仅对自己的 Cube 可见,所以我们在 Kylin 2.3.1 版本上,加了用户隔离的逻辑。对于用户来说,这样可以直接看到自己业务相关的 Cube。
7 节点自动探知
去年,我们出现了一个事故。当时,凌晨一个查询节点出现岩机器宕机故障。由于 Kylin 配置中 kylin.rest.servers 指明了所有同步节点的 Host,导致即使出现一个节点宕机,同步请求依然会不停地发向这个节点,最后所有同步的线程被阻塞。读写分离的集群出现了灾难性的数据不同步情况。
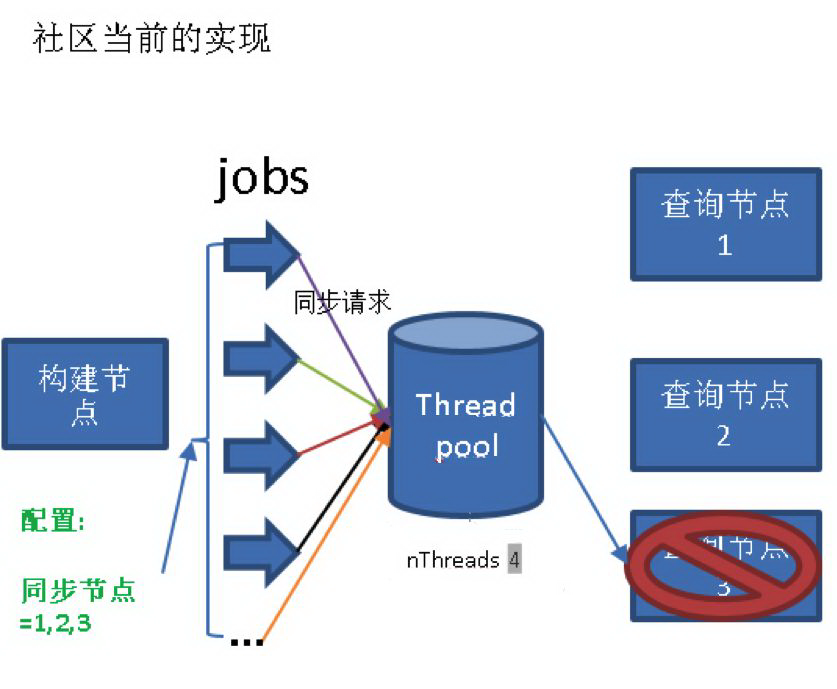
我们的方案:引进了服务发现组建 ZooKeeper。详见:
https://issues.apache.org/jira/browse/KYLIN-3810。
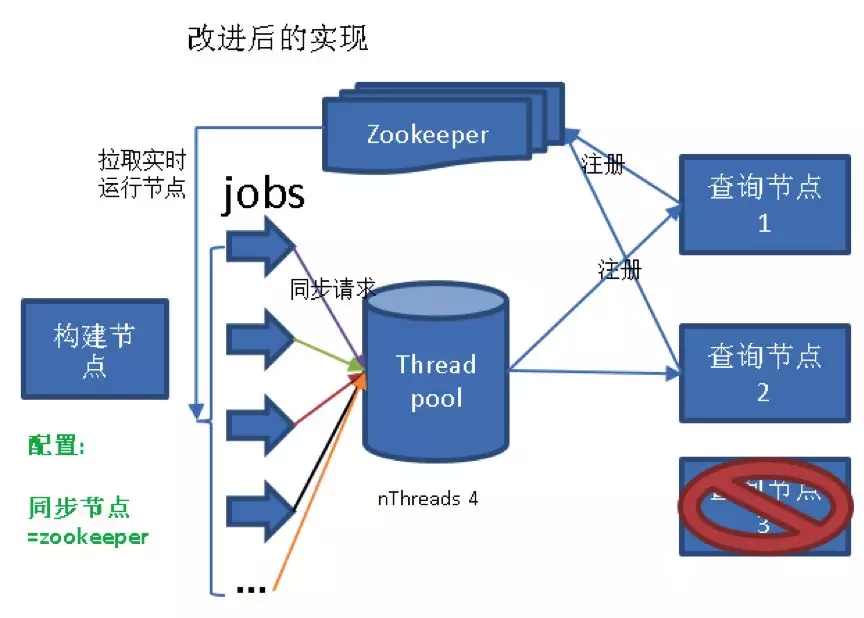
8 独立 HBase 的 HA 模式
去年,我们 HBase NameNode 主备切换导致 Kylin 无法正常工作的问题。我们实现了通过 namespace 的方式来访问 HDFS,并将相关的改进提交到社区:
https://issues.apache.org/jira/browse/KYLIN-3811。
9 设置 kylin.storage.hbase.max-region-count
控制 hbase.max-region-count 其实可以有效地控制生成 HFile 过程中对于 DataNode 的写压力。比如说:在 HDFS 集群比较有限的情况下,大量的 MR 写操作,会给 HDFS 系统带来很大的压力,减少这个值可以有效地控制 MR 写 HFile 的并发度,但也会影响构建性能,这个需要权衡。
本文转载自公众号 apachekylin(ID:ApacheKylin)。
原文链接:




