
7 月 12 日,第 13 届 PostgreSQL 中国技术大会在杭州举办。这是 PostgreSQL 中文社区陪伴中国 PG 技术栈实践者和生态贡献者走过的第 13 载,而 PostgreSQL 中国技术大会已然成为国内数据库领域最具影响力的技术风向标。本次大会上,质变科技 AI 数据云布道师、云原生领域资深人士陆元飞受邀作主题演讲《从 Relyt-V 客户实践揭示云原生向量数据库的设计与创新》。
以下内容根据嘉宾陆元飞在 PostgreSQL 中文社区演讲整理。
向量数据库典型客户实践
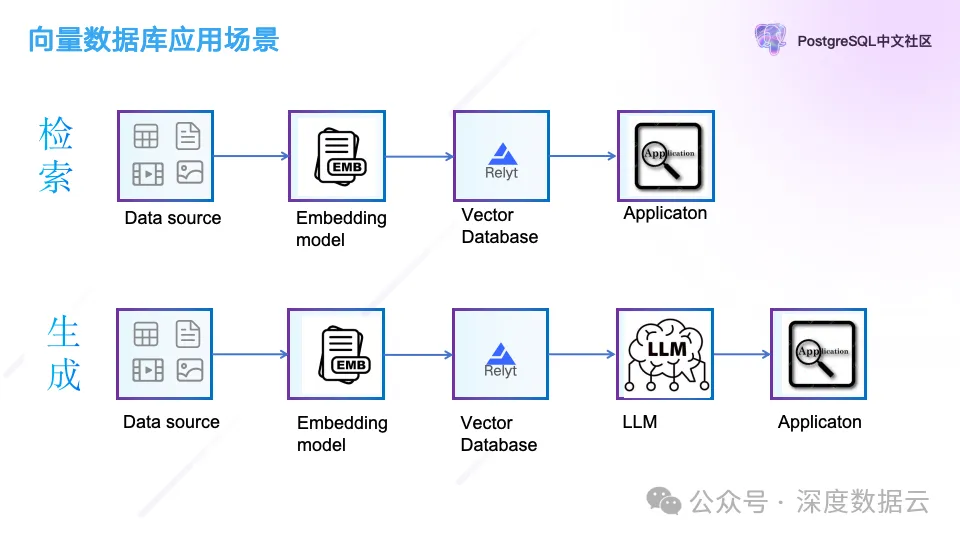
向量数据库的应用场景主要在向量检索和 AIGC,他们的数据流如上图所示。
在检索场景中,数据通过 Embedding Model 做完向量编码后,把结构化数据和向量保存到向量数据库,应用程序根据结构化和向量到向量数据库中来检索。
在 AIGC 场景中,文本和图像也会通过 Embedding Model 做完向量编码后保存到向量数据库,应用使用的时候先向量数据库检索到用户语义相关联的文本,以 Context 的方式或者 Prompt,和用户的问题一起发送给大语言模型(LLM),再把问题结果返回给应用。通过这种方式解决了用户使用大语言模型遇到的数据私有化问题以及大语言模型的“幻觉”问题。
下面我们从 Relyt 的 2 个典型客户应用来分析上述 2 个场景。
检索场景
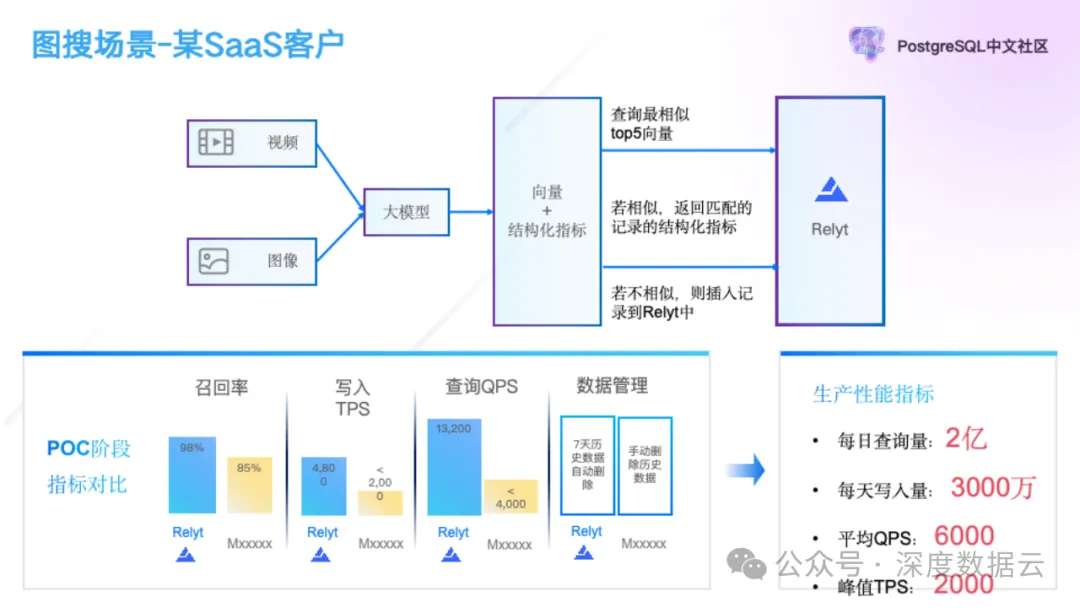
作为全球最早从事实时全索引数据仓库产品研发的团队,质变科技服务了某大型在线传媒企业的实时舆情、实时内容校验、实时多维度分析等多元业务分析场景,稳定支撑客户每日 2 亿次查询,3000 万写入,平均 6000 QPS,2000 峰值 TPS,平均延迟 10ms。其中,在图片搜索场景中,客户把爬取到的视频和图片经过大模型推理后生成向量,并把图片向量和结构化数据存储到 Relyt 中。
与普通的应用不同的是,这个客户在写入的时候,首先会使用写入的向量做查询,并返回最相似的 Top5 条数据,如果返回的数据的相似度超过一定的阈值,说明同类图片已经插入,则跳过,不需要插入,如果没有找到相似的图片这个时候才把向量和结构化数据插入。这个场景对向量数据库的考点主要集中在下面几个点。
1. 高召回率。如果召回低会存在 2 个问题,一个是写入数据会膨胀,另外一个是查询找相似记录会漏掉结果,影响上层业务的逻辑判断;
2. 高并发,写入 TPS 峰值在 2000,查询峰值到 1.3 万 QPS。
3. 自动化的数据管理。客户的数据按天存储,保存 7 天数据,7 天后自动淘汰。
在这个场景中,Relyt-V 在 98%召回的条件下,写入性能和查询性能是友商 2~3 倍,并提供了 TTL 数据管理能力,赢得了客户的信任。
AIGC 场景
另外一个是 AIGC 场景。
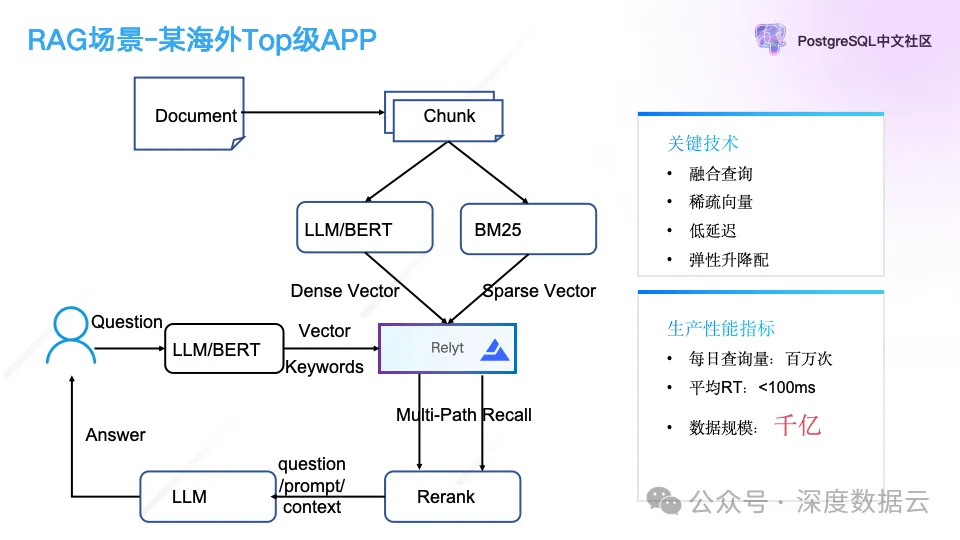
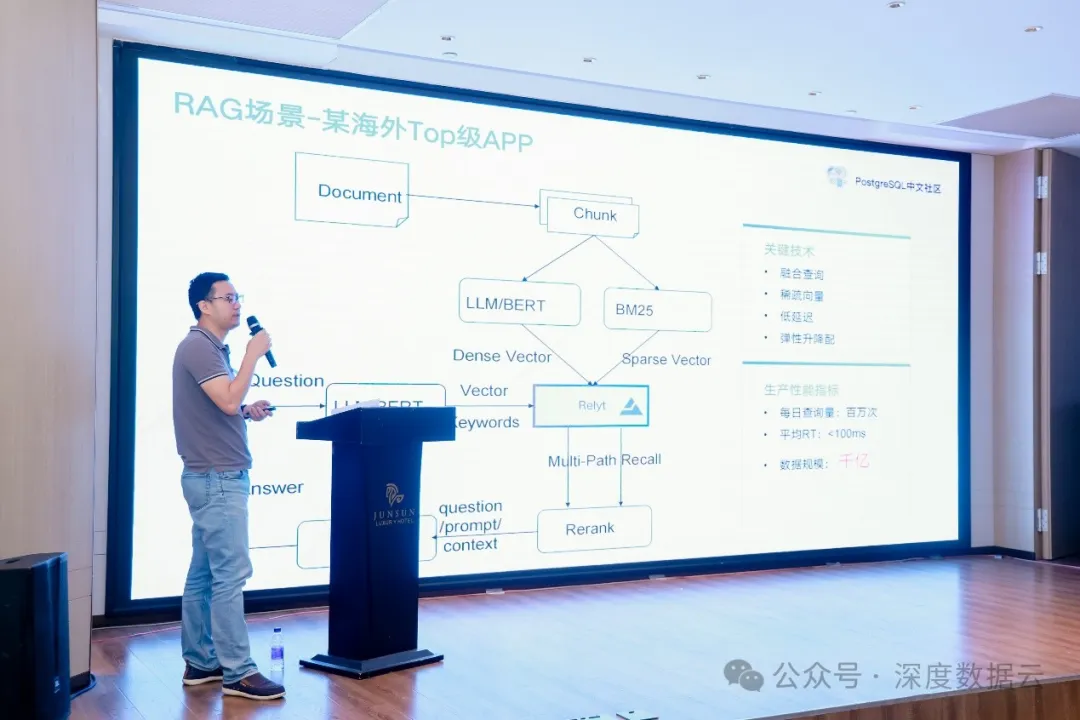
这个客户是 Will’s GenAI 产品出海 Top50 的一个客户,数据规模达到千亿级别,每日查询量达百万次,是一个典型的 RAG 应用。
用户把文档切片成块(Chunk),把文档块通过大模型转成稠密向量,同时也会通过 BM25 转成稀疏向量保存到向量数据库,用户在查询的时候会做多路召回,通过大语言模型的向量和关键词同时对向量数据库做查询,再把得到的语义近似或者关键词排名靠前的文本结果做重排序,之后再使用重排的结果作为大语言模型的上下文输入大语言模型,并返回给客户。
这个场景对我们的考验主要在于大规模下的低成本要求,客户的向量数据存储在千亿的规模,按业内的定价模型,千亿向量数据的存储和检索成本在千万/月的规模,我们通过云原生能力,提供弹性升降配的方案,做到百万/月的目录价。
下面再介绍一下 Relyt-V 的内部实现。
Relyt-V 内核揭秘
客户需要什么样的向量数据库
在介绍 Relyt-V 之前,我们先介绍一下作者接触到的不同时间点的客户都需要什么样的向量数据库。
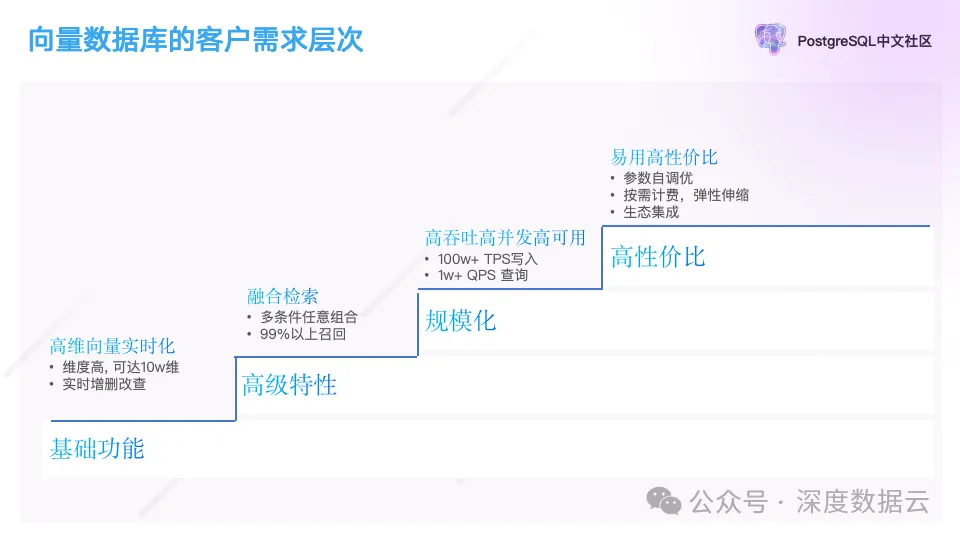
在作者 2018 年刚开始实现向量数据库的时候,客户的需求比较低,只需要提供向量检索的基础功能即可,再随着业务的持续深入,客户对类似结构化和非结构化融合查询提出了更高的要求,随着客户的业务规模的扩展,更看重规模化能力,例如高并发,高可用能力。时间回到 2013 年,每个数据库都提供了向量检索的功能,这个时候客户对高性价比提出了更高的要求。
作者在研发向量数据库的过程也基本随着客户的需求一步步做的架构演进。下面是作者在 PostgreSQL 架构上实现向量数据库架构升级的一个大概的时间线。
这个时间线大概可以分成 4 段:
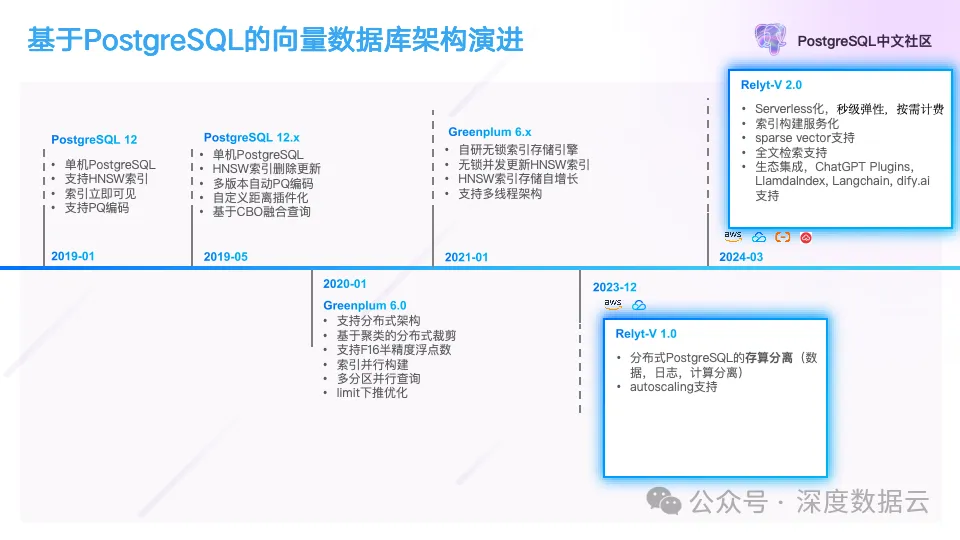
2019-01:在 PostgreSQL 上实现了类似 pgvector 的向量索引插件,支持了高维向量的高效检索,支持了向量数据的实时更新等基础功能;这个版本具备了基本的商业化能力,能解决客户部分场景下的业务问题;
2019-05:支持了向量数据与结构化数据的融合查询的能力,这个作为向量数据库独有的能力,帮助我们赢得了大量客户;
2020~2021:以 Greenplum 这个 HTAP 的分布式架构实现了分布式向量数据库,为了支持更高的并发请求,实现了基于 Huge-Block 的自研向量索引。性能相比 PostgreSQL 段页式的存储提升了 5 倍。支撑了客户数据规模化上量。
2023~2024:实现了分布式 PostgreSQL 存算分离和 Serverless,并把向量索引做了服务化。进一步支持了 Sparse Vector 等高级特性。并做了对各种 LLM 开发框架的支持,例如集成到 LlamdaIndex、Langchain、dify.ai 中。
下面我们简单介绍一下如何在 PostgreSQL 上实现向量检索。
基于段页式存储的 HNSW 索引
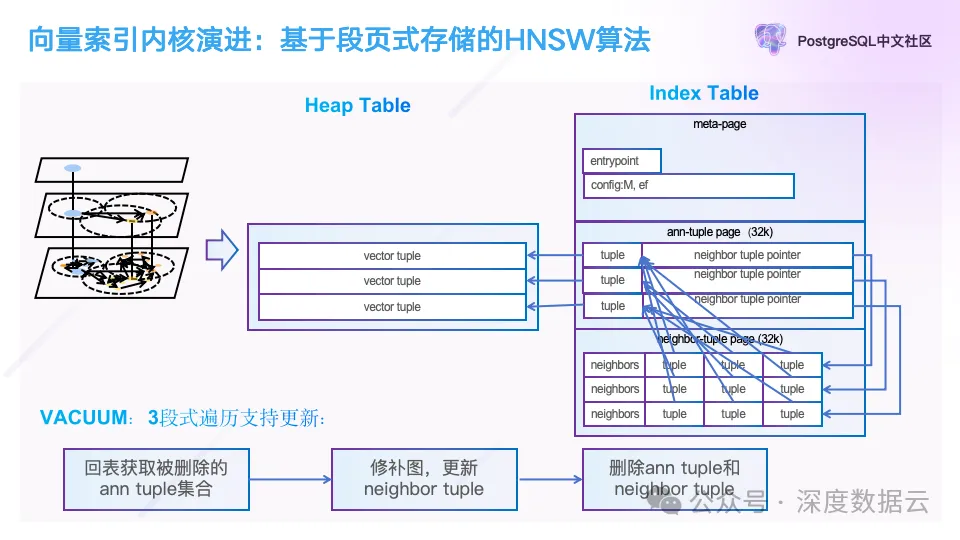
这张图概要的介绍了如何在 PostgreSQL 上实现一个向量索引,对照蚂蚁集团在 PASE: PostgreSQL Ultra-High-Dimensional Approximate Nearest Neighbor Search Extension 论文中算法,这里我们介绍 HNSW 这种索引算法实现。
图的左边是一个 HNSW 算法的示意图,它的核心是一个最近邻图算法。我们使用堆表行存来保存向量数据,对于向量索引,我们把它的 Page 分成 3 种类型,一种 Meta Page,用来保存图检索的入口点信息,以及图的配置参数。
另一种是图上的顶点信息,我们叫做 Ann Tuple Page,这里我们记录了图的向量信息,与 pgvector 的实现不一样的是,我们没有在这里保存完整的向量数据,只保存了向量的 PQ 编码,内存占用只有原始向量的 1/10,图上的点的邻居信息我们保存在 Ann Neighbor Page 中,这里保存的是向量的位置,在 PostgreSQL 中我们记作 CTID。
为了支持图的更新,与 pgvector 一样,我们也在 Vacuum 的时候通过 3 次遍历图索引来实现。
第一次遍历:遍历 Ann Tuple Page 找到向量在堆表中存储的位置并回表判断向量是否已经被标记删除了。并把这些被标记删除的向量数据记录下来;
第二次遍历:遍历邻居信息,如果邻居中,点已经被删除,需要把这条向量的邻居做补齐,这个过程就是修补图;
第三次遍历:这次遍历,我们会直接清理被删除的点和它对应的邻居信息。
之所以需要三次遍历的原因在于,修补图的过程我们还需要依赖被删除的点的数据来构建图,如果提前把对应数据点删除了,那么就无法保证图的连通性,修补的时候图遍历就无法找到对应的邻居。
这个架构实现的优势是,我们只做了非常少的工作,基于 PostgreSQL 本身强大的插件扩展能力就实现了一个数据管理功能完备的向量数据库。包括它的高可用能力,高可靠架构,以及数据库、表、文件等管理功能。
基于 Huge-Block 自研向量索引引擎
但是这个架构也带来比较大的问题,我们发现在检索的时候,PostgreSQL 的段页式存储带来的加锁访问开销占据了整个执行时间的 1/3,因为 HNSW 是一个图算法,他会随机访问图上的每个点,我们统计一次图的查询,它会随机访问 5000 个 Page,造成大量 Shared Buffer 页面申请淘汰。所以我们在 21 年自研了基于 Huge-Block 的向量索引存储引擎。它的架构如下所示:
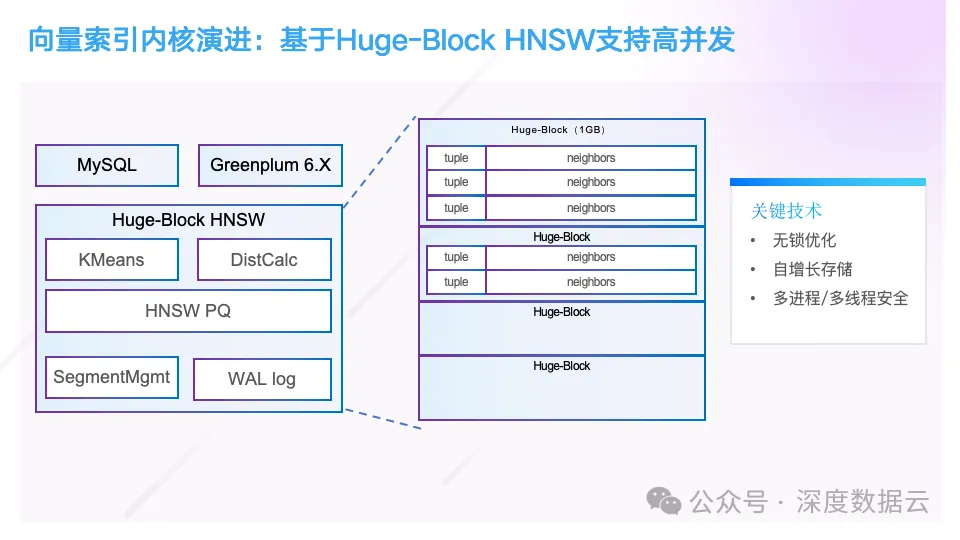
这里的核心是我们把向量索引的数据按照 1GB 大小为一块来申请,当前写入的数据如果已经写满 1GB,则申请下一个数据块,数据块的数据按 Tuple 和 Neighbor 的方式来组织,因为访问一个点之后,需要立即访问它的邻居数据,通过 Prefetch 指令,预加载内存到 Cache。这里另外一个创新点在于,我们为了让这个向量索引引擎同时支持多线程和多进程架构,我们对图上的插入和更新实现了无锁操作。
具体实现的原理也非常简单。我们为每条向量分配了一个 8 字节自增 ID,在插入向量数据的时候,会先检查这个位置是否已经有数据插入,如果这个插入的位置已经有其它并发插入,则我们会插入下一个位置,直到成功,插入后,我们就得到这条数据的写入权限,当然上述的每个操作都需要使用原子语义的 API 接口来实现;其次在更新邻居的时候,我们也通过原子操作来更新,即使有 2 个线程并发更新同一条数据的邻居,也没有关系,因为 Ann 索引并不严格要求对每个邻居有准确性的依赖。
做完这个事情后,我们的性能比段页式存储提升了 5 倍,与业内竞品 PK 的时候,性能不至于落后。但是这个架构还有一个比较大的问题在于每次扩容的时候,时间都是以天为单位。
原因在于 Greenplum 扩缩容的原理是把原来表的数据拷贝一份重新分发到新的节点,并重建索引,而 HNSW 算法的查询性能非常好,但是写入性能非常慢,只有 100 条每秒每核。而 Greenplum 这 Share-Nothing 架构导致每个节点分配的资源都是有限,所以在集群节点超过 1 实例时,我们通常需要向客户申请 1~2 天时间来扩容,在扩容期间整个数据库处于不可用的状态,这种情况在线下输出环境是可以容忍的,但是对于云上,特别是云上服务于在线业务的客户是不可接受的,例如典型的 RAG 场景。
这个问题促使我们重新思考整个云的架构,是否可以通过云的资源池化能力和云的按需使用来解决这个问题。下面我重点介绍一下 Relyt 的架构,以及我们如何通过云原生化来解决这些问题。
Relyt-V 架构和实现
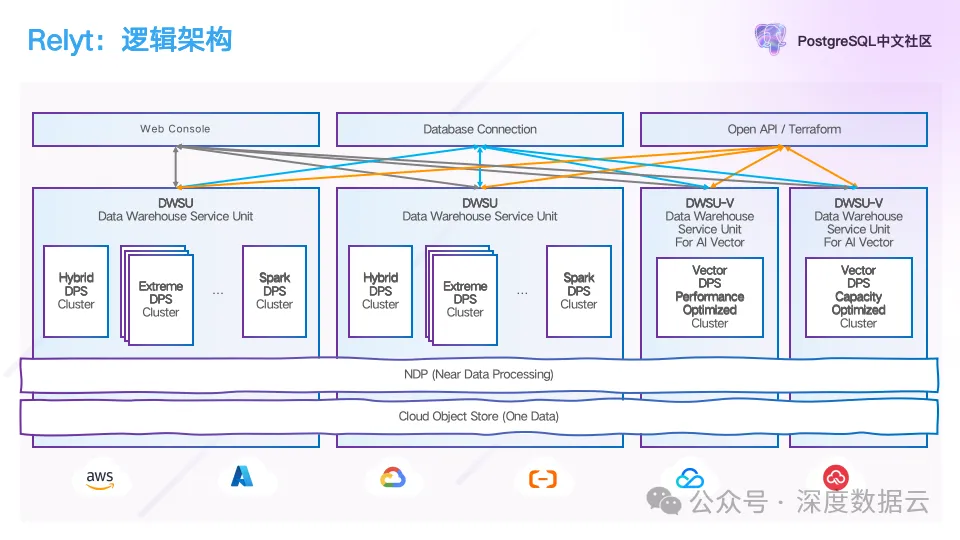
上面是 Relyt 的逻辑架构,我们把公共云的 IaaS 层能力抽象成拥有无穷无尽的存储和计算资源,并且这些资源是可以按需使用,按量计费。
我们把不同云厂商的 IaaS 层资源做了一层抽象,在这些基础资源上提供 DWSU 的服务,一个 DWSU 是一个数仓服务单元,可以包含多种 DPS,即数据处理服务集群,这些 DPS 共享一份数据,我们根据 Workload 的不同,划分成不同类型的 DPS,例如 Hybrid DPS 提供了数据实时写入,实时分析的能力,Extreme DPS 提供了极速 Ad Hoc 查询,交互式分析能力,Spark DPS 提供了离线分析,以及 Vector DPS 提供向量和全文的检索能力。
为了解决对象存储和计算节点间的 overlap,我们在对象存储和计算中间抽象出 NDP 近存储计算层,提供数据的缓存和计算加速服务,计算加速包含下推,索引,以及硬件加速的编解码能力。而对于不同的用户 Workload,我们提供 PostgreSQL 兼容 SQL 作为查询语言,提供一份数据,任意分析的能力。
我们把 Vector DPS 进一步打开,它的逻辑架构如下所示:
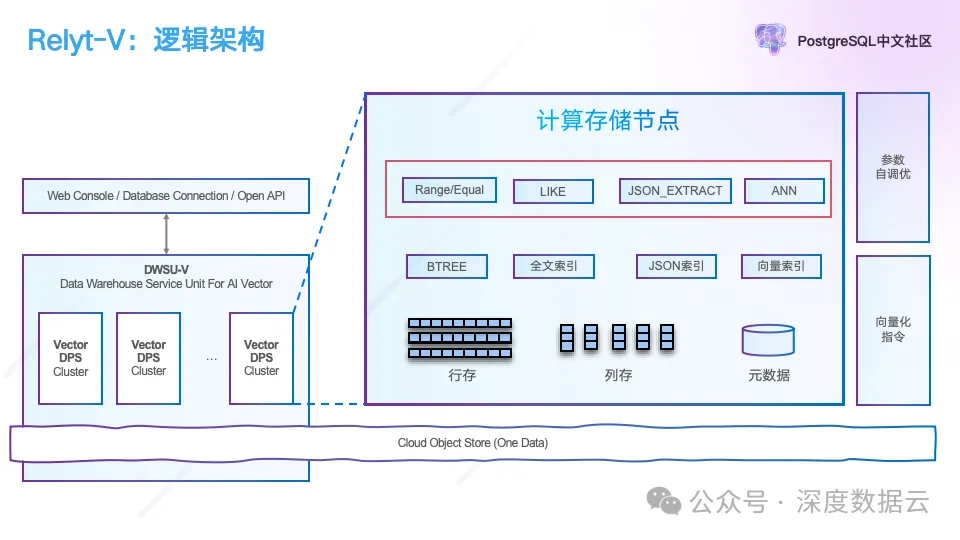
用户可以有一个 DWSU-V 数仓服务单元,可以申请多个 Vector DPS,其中一个 DPS 为读写集群,其它 DPS 为只读集群,在读多写少情况下,读的线性扩展能力,这些 DPS 共享一份数据。
Vector DPS 打开后它的逻辑架构就是一个典型的数据库架构,包含各种 SQL 计算和存储的实现,中间是 Vector DPS 支持的索引,包含 B-tree、全文、JSON 和向量索引。在算法层面,我们也引入了 SIMD 指令做加速。
我们再来了解一下 Relyt-V 的部署架构。
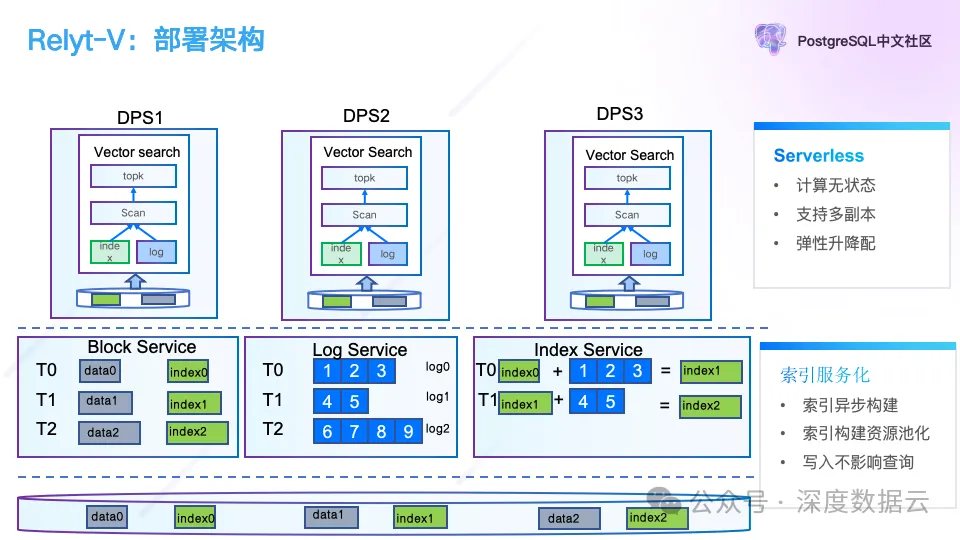
最上面为计算层,部署的是 PostgreSQL 集群,负责向量的写入和查询,中间的 Block Service 提供 PostgreSQL 的 Page 回放和读服务,Log Service 提供 WAL 日志的持久化服务,Index Service 提供向量索引的构建服务。最底下为对象存储,提供数据的持久化能力。上述的每个服务都可以由 1 个或者多个节点组成,实现处理能力的线性扩展。
这个架构的好处在于,我们实现了 PostgreSQL 的存储和计算分离,存储和计算可以独立扩缩容和按需使用,并且通过索引的服务化能力,提供索引的异步构建能力,同时索引构建不会影响上层计算的读写请求。并且在这个存算分离的基础上,我们实现了存储计算的 Serverless 化,支持用户无感的弹性升降配。
我们进一步把 PostgreSQL 计算节点打开,我们看如何在 PostgreSQL 基础上实现上述的存算分离架构:
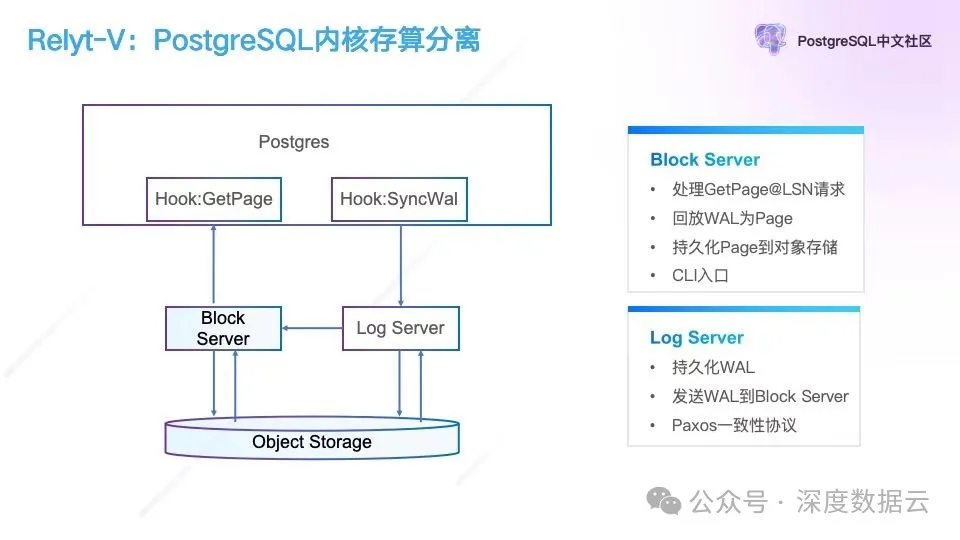
为了实现 PostgreSQL 的存储计算分离,我们从它的 WAL 日志做了 Hook,把 WAL 日志路由到 Log Server,并通过 Paxos 协议保证 WAL 日志的高可靠,我们在 PostgreSQL 读写 Page 做了 Hook,读 Page 路由到 Block Server,Block Server 从 Log Server 拉取 WAL 日志会回放成 Page,按需提供给 PostgreSQL 计算层。Log Server 和 Block Server 定期会把自己的数据同步到对象存储持久化,等持久化完成后,Log Server 和 Block Server 就可以安全的清理自己的 WAL 日志和本地文件,避免本地存储膨胀。
这个架构解决了 PostgreSQL 存算分离的问题,能够提供存储和计算的按需弹性能力。对于 Block Server 的迁移来说,在 PostgreSQL 的 Page 读 Hook 的实现中,通过重试读取 Page 就可以让用户无感的实现 Block Server 的迁移(迁移主要是为了实现弹性调度,把读从一个高负载节点调度到低负载的节点)。对于 Log Server 来说也是可以通过多副本的增减实现副本跨节点的迁移,但是对于 Postgres 节点,由于它本身是有状态的服务,当它的迁移造成网络中断,进程重启都会导致用户有感。所以我们通过 QEMU 和 VXLAN 来解决 Postgres 计算节点的无缝迁移,使它具备 Serverless 的能力。
如下图所示,我们通过 QEMU 实现的虚拟机实现进程的迁移,通过 VXLAN 的网络虚拟化能力,解决迁移过程中网络不中断的问题。
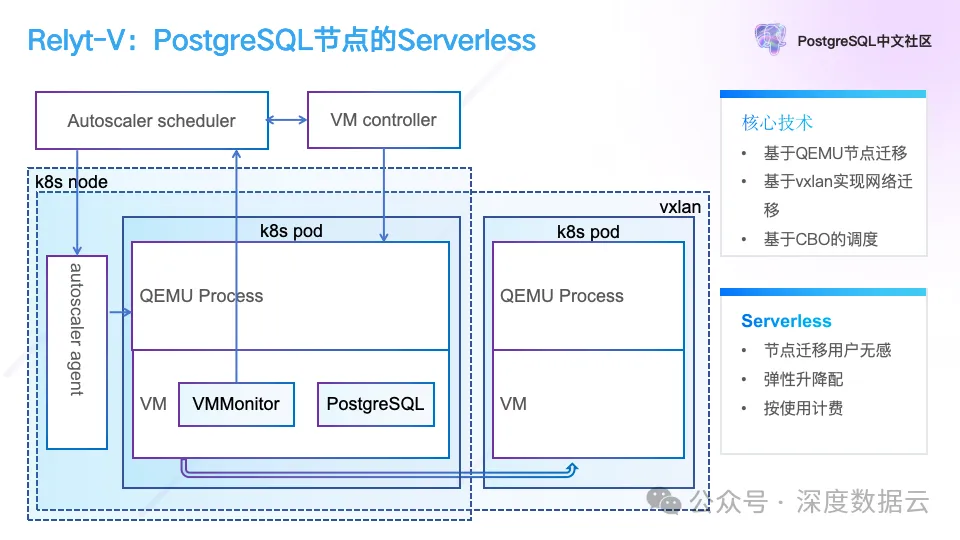
我们在 k8s pod 内部署了一个 QEMU,PostgreSQL 和 VMMonitor 进程运行在 QEMU 启动的虚拟机中,其中 VMMonitor 负载探测当前的负载并上报到 Autoscaler Scheduler,当系统资源不够时触发迁移,Autoscaler Scheduler 调度 VM Controller 来实现迁移,VM Controller 直接与 QEMU 交互,实现进程在虚拟机的迁移,进程迁移完成后,为了保证迁移后的 IP 地址不变,我们在 k8s 的网络上叠加了一层 VXLAN 网络。
这点稍微复杂的地方在于,Relyt-V 是一个分布式 PostgreSQL,所以我们配置 PostgreSQL 的各个节点间的通信都使用 VXLAN 网络,Coordinator 协调节点与外网通过 Autoscaler Agent(简称 Agent)也走 VXLAN 网络连接,Agent 同时提供 k8s 网络与 VXLAN 网络交换网关的功能,也就是外部应用通过 Agent 走 k8s 网络连接,Agent 再通过网关转为 VXLAN 网络与协调节点连接,再具体的讲就是 Agent 在网络协议层通过修改 TCP/IP 5 元组的源和目的 IP 端口,实现对 Coordinator 节点的网络访问。
通过上述的 QEMU 和 VXLAN 的技术我们实现了 PostgreSQL 计算节点的无缝迁移,在是否迁移的问题上,我们在 Autoscaler Scheduler 实现了基于 CBO 的调度算法,决定是否调度。
通过上述的存储计算分离、QEMU 虚拟机和 VXLAN 网络虚拟化技术,我们实现了 PostgreSQL 的弹性伸缩,无缝迁移,但是我们还是没有解决分布式 PostgreSQL 在扩缩容的时候带来的向量索引重新构建时间以天为单位计算的问题。
为了解决向量索引的构建问题,我们先来了解一下向量索引的算法,我们实现了一个类似 LSM 的向量索引算法。
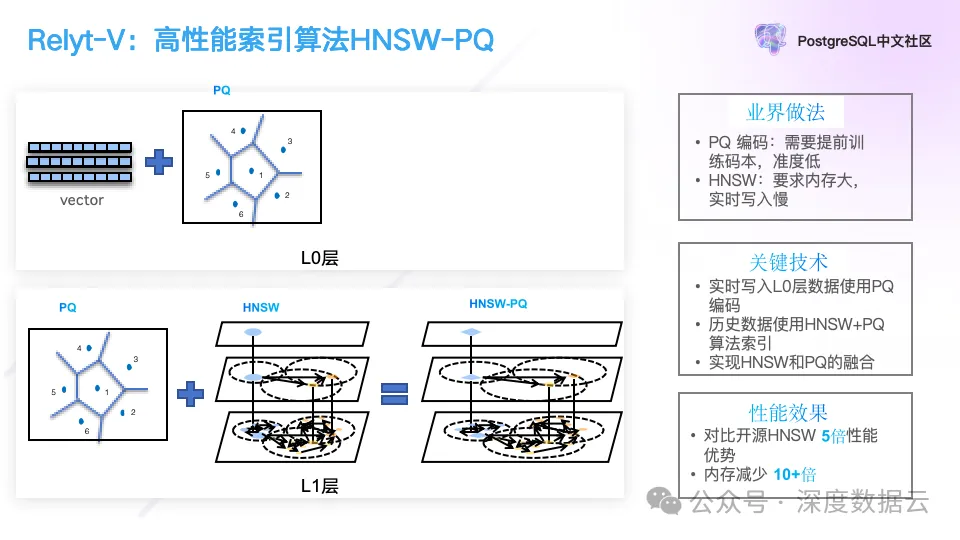
刚写入的向量我们直接使用原始向量做查询,当积累到一定数据,我们会后台训练出它的 PQ 编码,使用 PQ 编码来做加速,这些数据在内存中以 Log 的方式存在,积累到一定数据量,我们会落到磁盘,并通过 HNSW+PQ 的算法来构建索引。这个算法与之前在单机 PostgreSQL 上实现算法基本相同,不同的点在于,在索引存储引擎的差异,我们引入 LSM-Tree 的存储引擎。
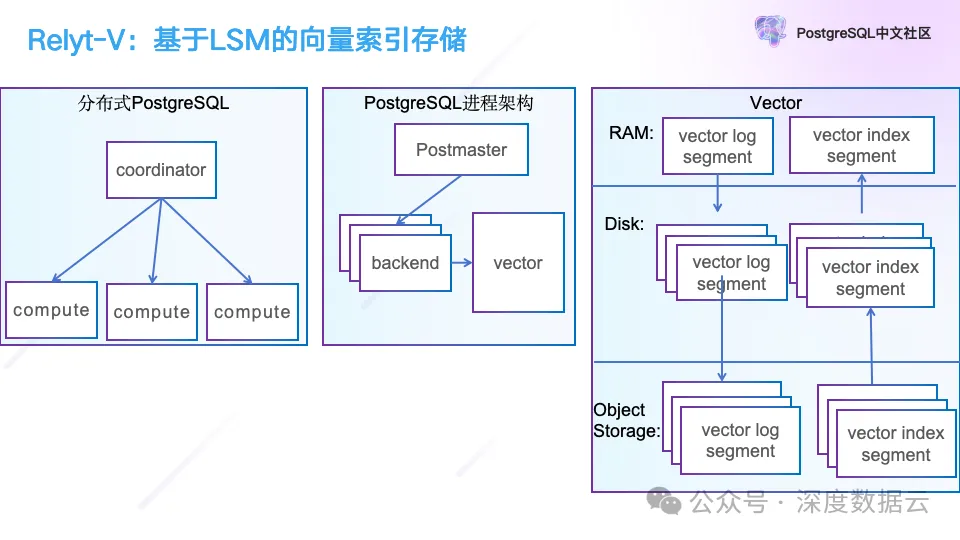
最右边就是我们使用的 LSM 的向量索引存储引擎,刚写入的数据会保存成 Vector Log Segment 中,这部分数据就是我们之前提到的 L0 层,如果这个时候已经训练出 PQ 码本,我们会把 PQ 码一起保存在 Vector Log Segment 中,如果没有训练出 PQ 码本,这个时候就直接保存向量数据,当 Vector Log Segment 数据达到一定数据量或者超过一定时间,我们会把它从内存写入磁盘,并通过上述的 HNSW PQ 算法构建向量索引,构建好的索引我们称之为 Vector Log Segment。构建好后对应的索引数据会立即加载到内存中提供查询服务。此外我们也会异步的把 Vector Log Segment 与 Vector Log Segment 上传到对象存储中。
这个架构的好处在于遵循了“the log is database”的设计思想,写入的向量数据都是 Immutable 的,这样对对象存储非常友好,数据同步到对象存储后,避免了因为节点故障而导致索引数据的丢失,重新构建索引带来的不可用,而另一个好处在于,同步到对象存储后可以方便的帮助我们实现索引构建的服务化。
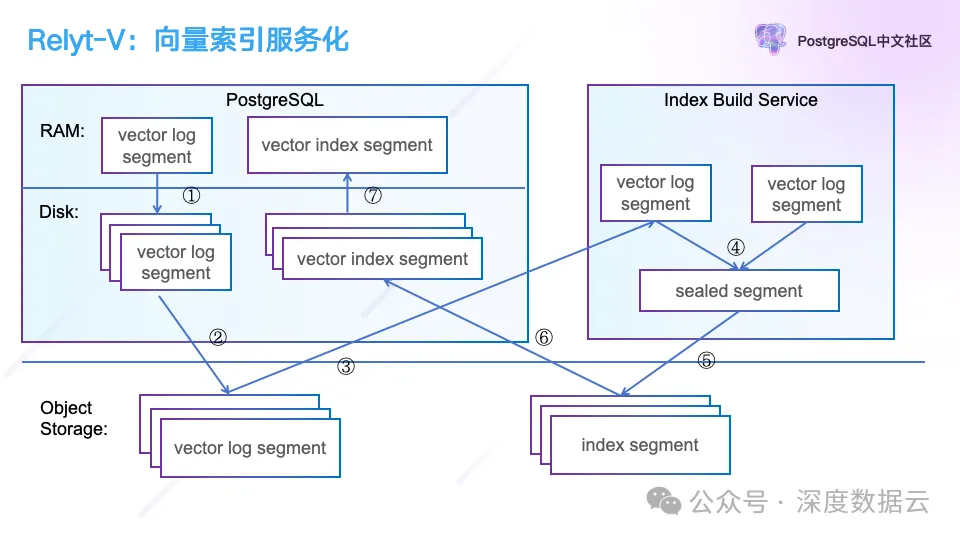
如图右边所示,我们可以按需拉起 Index Build Service,通过从对象存储同步 Vector 数据来实现向量索引的构建,这个帮助我们解决把分布式 PostgreSQL 在扩缩容的时候向量索引重建时间以天为单位缩短到分钟级别。
在分布式 PostgreSQL 扩容的时候,我们实现上图单机 PostgreSQL 节点数据的分裂,Index Build Service 在扩容前可以提前做好规划,把分裂后的向量索引构建好,并同步到对象存储上,分布式 PostgreSQL 的节点扩容完成后,从对象存储上按需拉取自己的向量索引文件,既可完成扩缩容,通过云上无限的计算资源,我们可以极大的缩短 Index Build 的时间。
最后再介绍一下我们在融合查询上的工作。
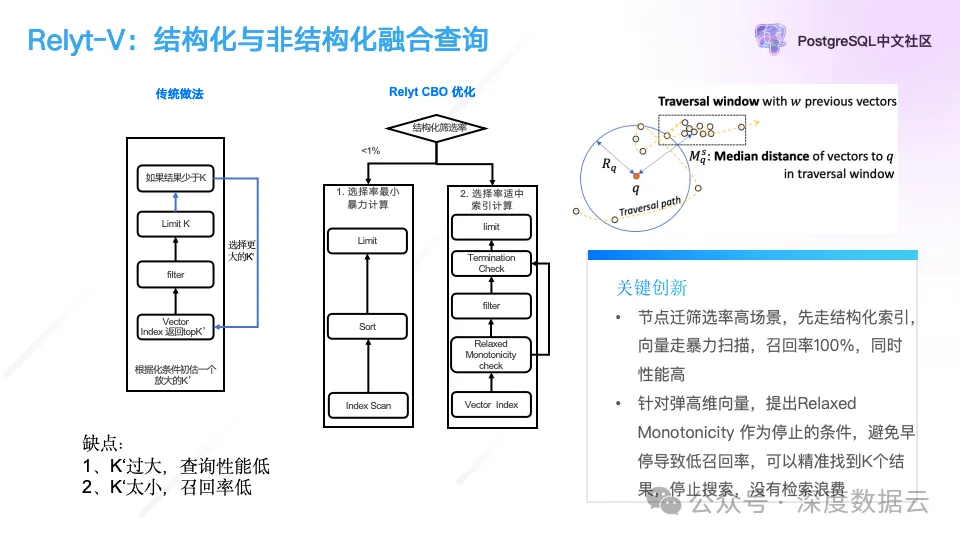
与其它一样,我们实现了基于 CBO 的优化器来选择向量检索的执行计划,如果结构化条件选择率小,通过结构化索引条件检索出向量数据,然后直接做暴力计算,当结构化选择条件适中,我们会走向量索引扫描的执行计划。
与传统的向量索引扫描,一边在图上做过滤,一边做扫描相比,我们通过图遍历过程中的 Relaxed Monotonicity 规则,设计了一个早停的条件,避免无效扫描,在保证查询召回的情况下,提升查询性能。
Relaxed Monotonicity 规则简单来讲就是我们在图上遍历的过程中,是大概遵循一个从图的中间点,逐渐向周围扩散的原则,随着我们不断在图上扫描,我们会离中心点越来越远,它不是严格遵循单调线性递减,而是 Relaxed 的,有一定灵活的递减,而当我们发现它递减到一定程度无法找到更近的邻居,那么就可以终止图上的遍历了。
为了得到这个终止条件,我们在遍历过程中,系统维护两个队列:
smallestQueue:一个优先队列,大小为 E,存储到目前为止访问到的与 q(query 查询向量)最近的 E 个向量。
recentQueue:一个最近访问的节点队列,大小为 w,存储最近访问的 w 个向量,用于计算中值距离。
Relaxed Monotonicity Check,在遍历的每一步,系统执行以下检查:
计算 Rq,即 q 的最近邻域半径,定义为 smallestQueue 中第 E 个最近向量到 q 的距离。
计算 Msq,即当前遍历位置到 q 的中值距离,基于 recentQueue 中的向量。
终止条件计算方法:如果对于某一步 s,Msq 大于 Rq(即 Mtq ≥ Rq 对于所有 t ≥ s),则满足 Relaxed Monotonicity 条件。这意味着进一步的遍历不太可能找到比 smallestQueue 中已有的更接近 q 的向量。
通过上述基于 CBO 的查询优化器,和基于 Relaxed Monotonicity 的早停图遍历算法,我们在保证召回的情况下,进一步提升了查询的性能。
下面我们对 Relyt-V 简单做一下总结。
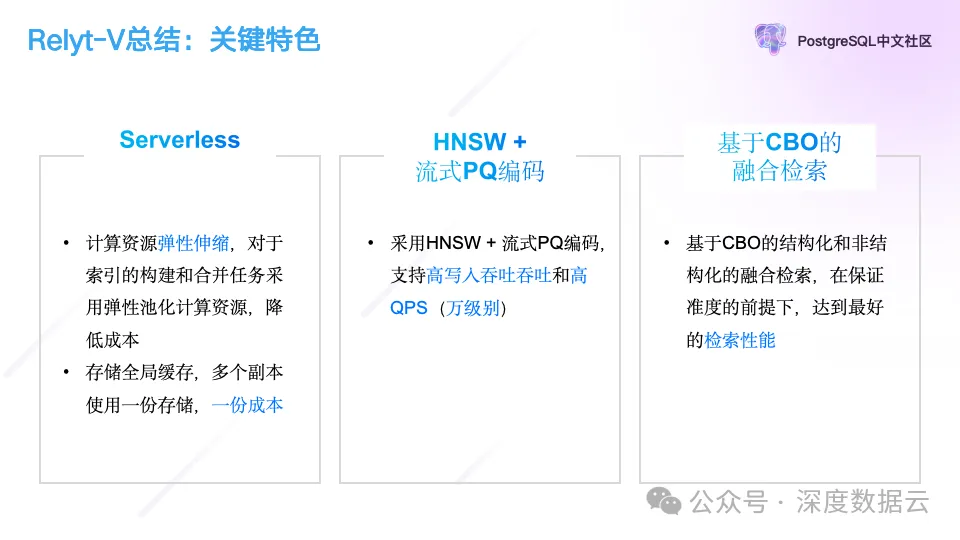
Relyt-V 的核心关键点在于下面 3 个:
Serverless:支持计算存储资源的弹性伸缩,对于索引的构建通过从计算资源池按需拉起的方式,降低用户成本。
高效向量索引算法:支持 HNSW+PQ 的向量索引算法,在提供高性能查询的同时,降低使用的内存。
高性能的融合查询:基于 CBO 优化器帮助我们选择最优执行计划,在向量索引扫描的查询实现中,通过 Relaxed Monotonicity 早停机制,降低了图上一边遍历一边扫描造成的性能损失。
极致性能
最后我们再分享一下 Relyt-V 的极致性能。
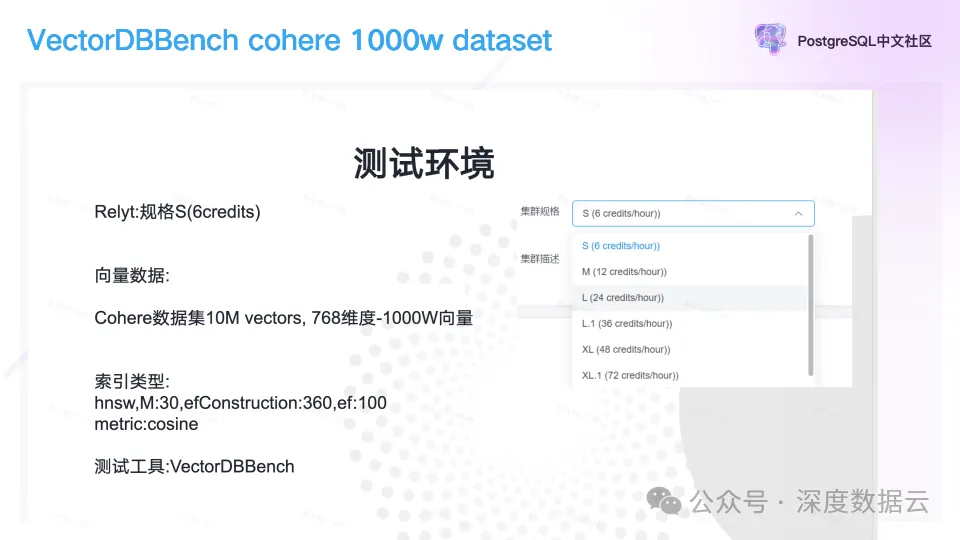
我们以金山云上 S 规格的向量实例为例,它的目录价是 6800 元/月,和其它产品价格上基本对齐。
测试的工具我们使用开源的 VectorDBBench,并在开源 VectorDBBench 对 PostgreSQL 的测试程序做了一些优化,主要有下面几点:
1. 使用了 prepare 的 SQL 语法。避免每次走优化器生成执行计划。
2. 向量从文本改成二进制。避免了 float 转成文本放大的问题。
测试的用例使用 cohere 1000w 768 维向量数据。
下面是我们的 QPS 测试结果:
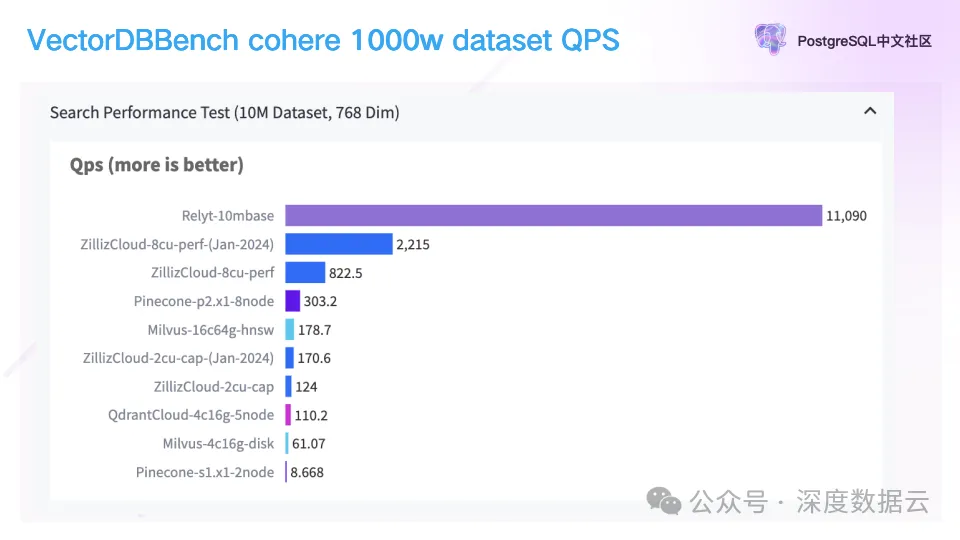
从上图可以看到 Relyt-V 的 QPS 是第二名的 5 倍。
这一页是 top 100 情况下的召回率。
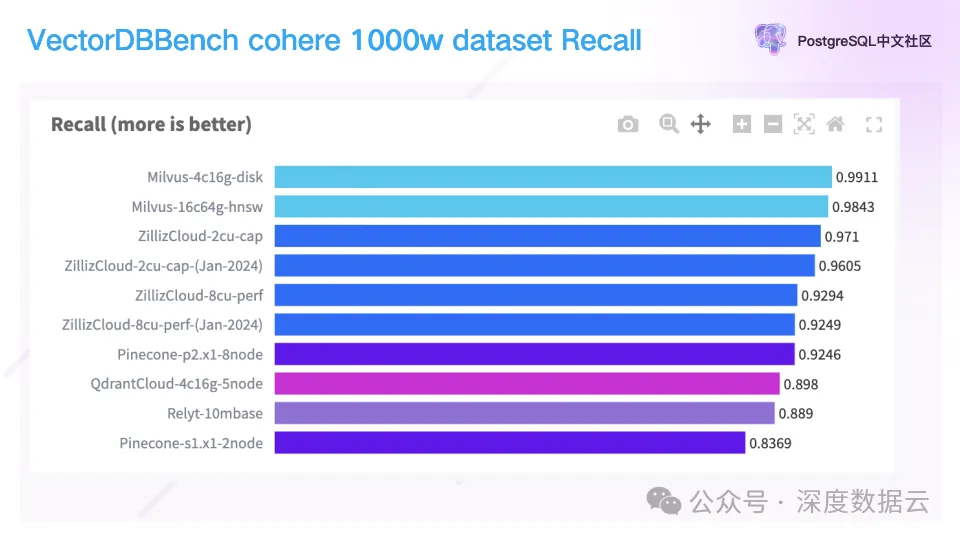
可以看到 Relyt-V 的召回是 88.9%,较之业内平均召回 92.85%相差不大,还在进一步提升。
我们再来看数据加载的时间。
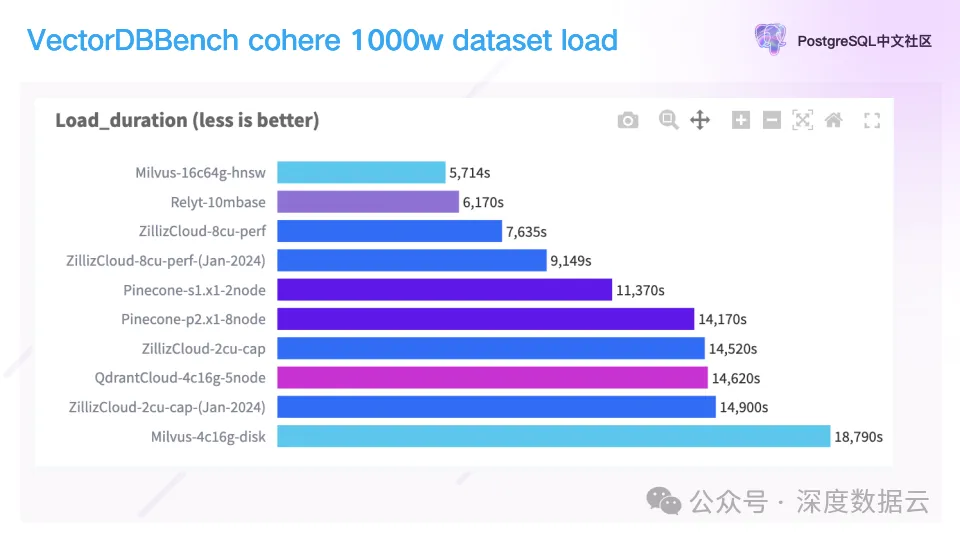
Relyt-V 的加载时间是 6170 秒,基本做到引领业内。
最后我们看 99%的查询的 RT。
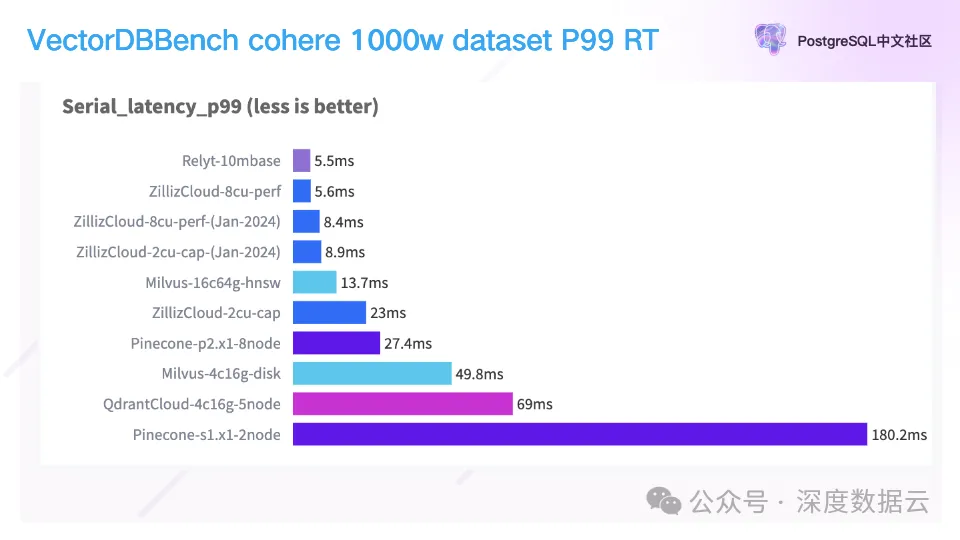
Relyt-V 的 RT 在 5.5ms,做到业内引领。综上所述,Relyt-V 在 RT、QPS、加载时间,都领先业内。
嘉宾介绍:
陆元飞,质变科技 AI 数据云布道师。华为 10 年基础软件研发经验,曾负责 Taurus 数据库的一致性存储协议开发。2018 年加入阿里云,从事向量数据库和 AnalyticDB 存算分离云原生架构的研发;完成 AnalyticDB 向量版从 0 到 1 的研发工作,并在顶级数据库会议 VLDB 发表论文: AnalyticDB-V: A hybrid analytical engine towards query fusion for structured and unstructured data;产品在城市大脑、图片搜索、个性化推荐、大语言模型等场景得到广泛应用。
当前就职于杭州质变科技有限公司,AI 数据云产品 Relyt 元数据、实时和向量负责人。完成 Relyt 存储的架构设计和核心模块研发,从 0 到 1 构建云原生向量数据库产品 Relyt-V。




