
近日,谷歌的人工智能研究实验室 DeepMind 发表了关于训练 AI 模型的新研究——多模态对比学习与联合示例选择(JEST)。
JEST 算法可以将训练速度和能源效率提高一个数量级。DeepMind 声称,“我们的方法超越了最先进的模型,迭代次数减少了 13 倍,计算量减少了 10 倍。”
论文链接:
https://arxiv.org/pdf/2406.17711
有网友激动地表示:“我没想到它来得这么快。对于模型来说,选择训练数据的能力是很强大的,因为这可以使得训练变得十分容易。你不需要再去猜测什么是高质量的训练数据,因为你有一个专门学习它的模型。”
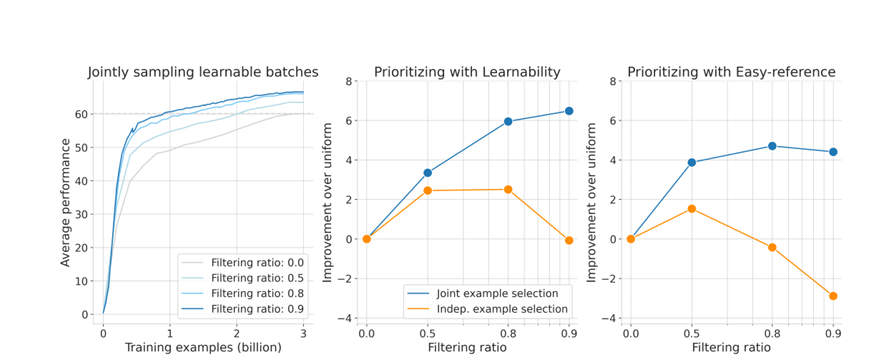
JEST 算法以一种简单的方式打破了传统的 AI 模型训练技术。典型的训练方法侧重于对单个数据点的学习和训练,而 JEST 则是对整个批次进行训练,优化了数据的整体学习效果。
多模态对比学习能够直接揭示数据之间的交互,通过选择高质量的子批次显著提高训练效率。
多模态数据交互:利用不同模态(图像、文本等)间的相互作用增强数据的表征力。例如,将图像中的对象与其描述文本相匹配,增强模型的理解。
对比目标:最大化相同概念的不同模态表示(如图像和对应文本)之间的相似度,同时最小化不相关模态之间的相似度。通过 sigmoid-contrastive loss 等对比损失函数实现。
学习效率的提升:多模态学习方法使 JEST 算法从数据交互中学习到更复杂的数据表示,提高了学习效率和模型性能。
联合示例选择通过评估数据子批次的整体可学习性,从大批次中选择出最有学习价值的子批次。
可学习性评分:结合当前模型的损失和预训练模型的损失,优先选择当前模型尚未学会但预训练模型已学会的数据。
评分函数:结合预训练模型的易学性评分和当前学习模型的难学性评分,得到综合的可学习性评分。
但是,这个系统完全依赖于其训练数据的质量,如果没有高质量的数据集,引导技术就会分崩离析。对于业余爱好者或者业余 AI 开发者来说,JEST 比其他方法要更难以掌控。
近年来,人工智能技术迅猛发展,大规模语言模型(LLM)如 ChatGPT 的应用日益广泛。然而,这些模型的训练和运行消耗了大量能源。研究称,微软用水量从 2021 年到 22 年飙升了 34%,ChatGPT 每处理 5-50 个提示就会消耗接近半升水。在这样的背景下,JEST 技术的出现显得尤为重要。
参考链接:




