
专题介绍
2009 年,Spark 诞生于加州大学伯克利分校的 AMP 实验室(the Algorithms, Machines and People lab),并于 2010 年开源。2013 年,Spark 捐献给阿帕奇软件基金会(Apache Software Foundation),并于 2014 年成为 Apache 顶级项目。
如今,十年光景已过,Spark 成为了大大小小企业与研究机构的常用工具之一,依旧深受不少开发人员的喜爱。如果你是初入江湖且希望了解、学习 Spark 的“小虾米”,那么 InfoQ 与 FreeWheel 技术专家吴磊合作的专题系列文章——《深入浅出 Spark:原理详解与开发实践》一定适合你!
本文系专题系列第三篇。
令狐冲:“我要退出江湖,从此不问江湖之事。”
任我行:“这个世界有人的地方就有恩怨,有恩怨就有江湖,人就是江湖,你怎么退出?”
感谢各位看官在百忙之中来听我说书,真是太给面子啦!前文书《内存计算的由来 ——DAG》咱们说到 DAGScheduler 以首尾倒置的方式从后向前回溯 DAG 计算图,沿途以 Shuffle 为边界划分 Stages。那么,这些 Stages 划分出来之后有什么用呢?DAGScheduler 如何将 DAG 划分出的 Stages 转化为可执行的分布式任务?本期“权力的游戏”将带您走进 Spark 调度系统,笔者将竭尽全力与您一起揭开 Spark 调度系统的神秘面纱。
在本段书正式开始之前,咱们先得铺垫铺垫,毕竟保不齐有刚入座的看官头一次来咱们书棚,咱们都得照顾到不是。在讲 Spark 调度系统之前,咱们先来简单回顾一下 Spark 分布式系统架构和重要概念。
Spark 是典型的主从型(M/S,Master/Slave)架构,从系统的角度来看,Spark 分布式系统的核心进程只有两种:Driver 和 Executor,分别对应主从架构的 Master 和 Slave。显而易见,在 Spark 分布式系统中,Driver 只有一个,而 Executor 可以有多个。Driver 提供 SparkContext(SparkSession)上下文环境,而上下文环境提供了 Spark 分布式系统所有的核心组件,如 RPC 系统、调度系统、存储系统、内存管理、Shuffle 管理等。Driver 正是通过这些核心组件来对分布式任务进行拆解、调度、分发、追踪与维护,俗称“指挥的”。相比 Driver,Executor 进程要简单的多,主要负责分布式任务的执行和状态反馈,俗称“干活儿的”。
那么问题来了,这两种核心进程分别运行在哪里呢?既然是分布式系统,我们就绕不开部署模式,Driver 和 Executor 运行在哪里,取决于我们采用哪种分布式部署模式。到目前为止,Spark 支持三种部署模式,每种部署模式对应着不同的资源管理器(Cluster Manager,即 Spark 内置的 Standalone、HadoopYARN 和 Mesos),资源管理器用于管理、协调集群中的硬件资源。我们以 Standalone 模式为例,来看看 Driver 和 Executor 的运行时部署。
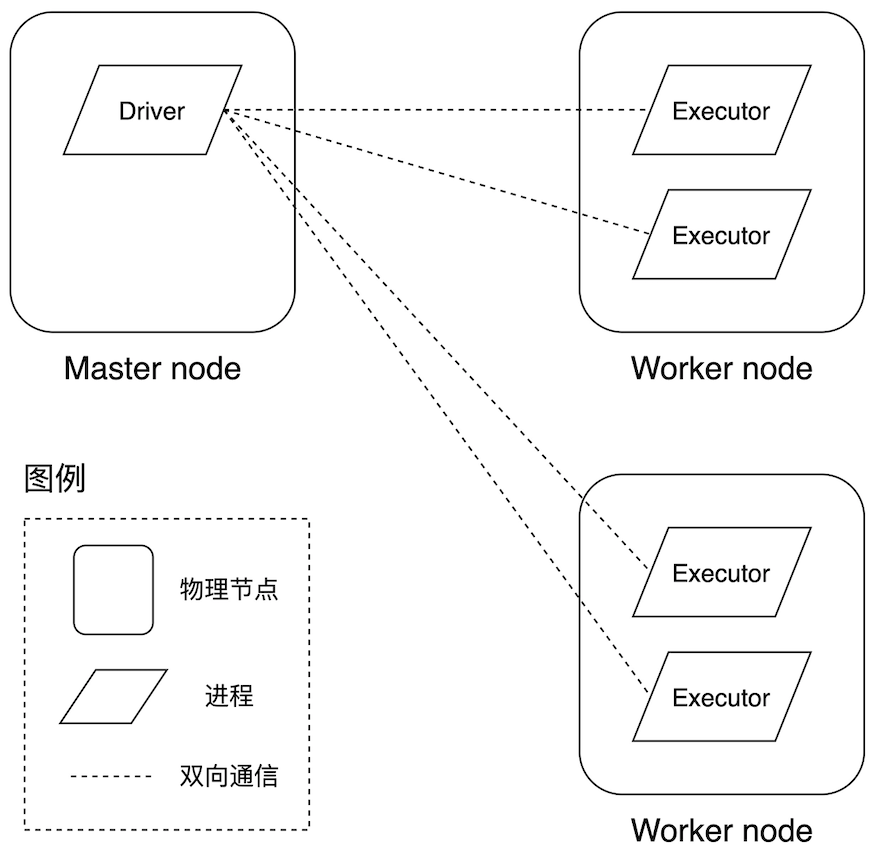
Standalone 模式与进程部署
如上图所示,在 Spark 内置的 Standalone 资源管理器中,物理节点的角色被划分为 Master 和 Worker,Driver 进程运行于 Master 节点,而 Executor 则运行在 Worker 节点中。在 Standalone 模式下,计算资源以 Executor 为粒度用于任务调度,一个 Executor 包含若干 CPU core 和计算内存,一般来说,CPU core 的数量限定了 Executor 内的任务并行度。在 Spark 源码实现中,Executor 有个别名,唤作 Worker Offer,听上去简单直接:“Worker 节点提供的用于任务计算的硬件资源 Offer”。再说回 Driver,Driver 进程中的 SparkContext(SparkSession)就像是潘多拉的盒子,一旦开启,宛如三十六天罡临凡、七十二地煞降世,牛鬼蛇神各显神通,我们的故事便是从这里开始。
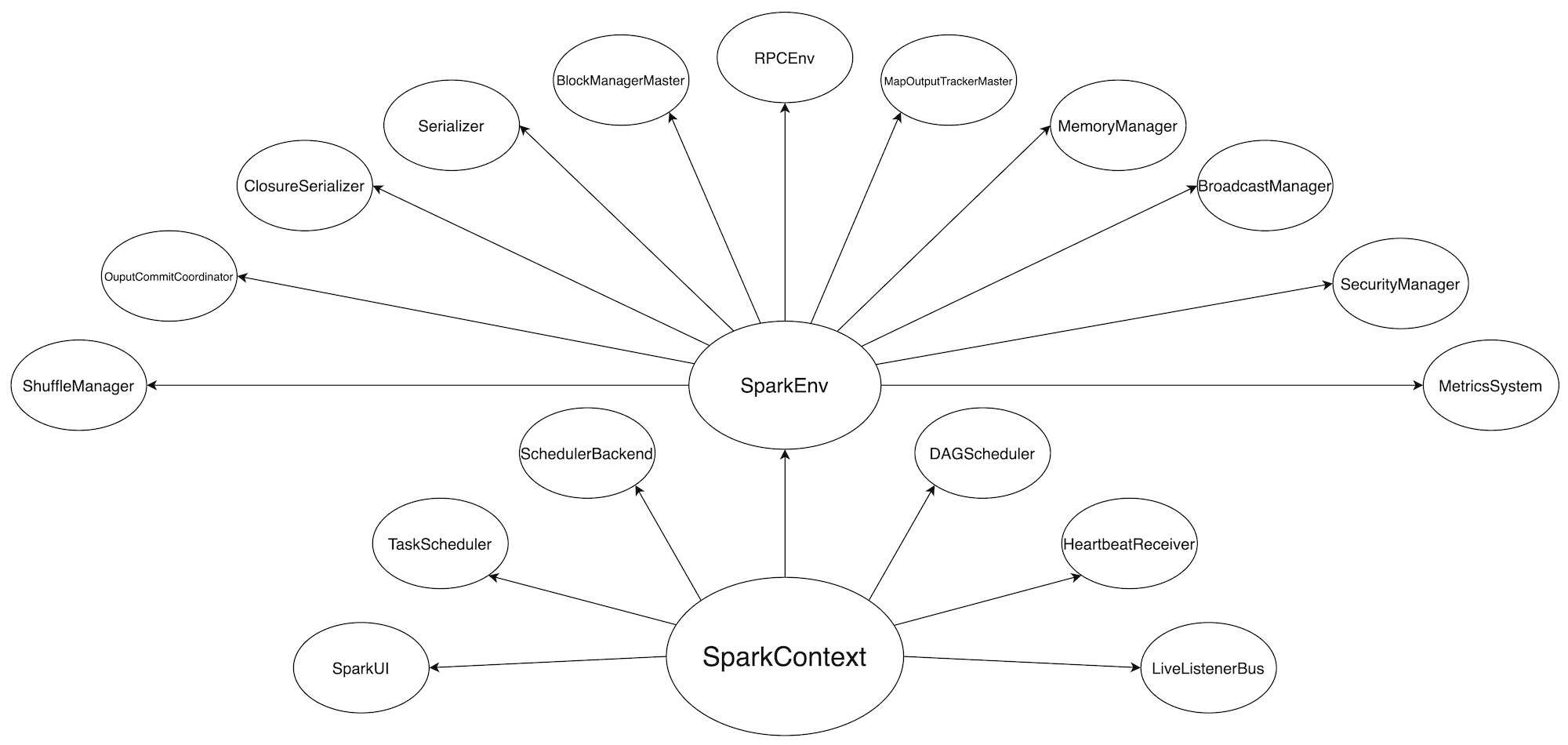
SparkContext 初始化
聚义厅的头三把交椅
职业摄影师之所以能够持续产出高品质的作品,关键在于他们善于因地制宜、根据场景的变化灵活地切换视角。为了更好地理解 Spark 这个复杂而精密的分布式系统,我们不妨把它想象成一家建筑集团公司 —— Driver 是总公司,Executor 是分公司。我们暂且给这家集团公司取名为“斯巴克”,斯巴克公司的主要服务对象是建筑设计师,设计师负责提供设计图纸,而斯巴克公司的主营业务是将图纸落地、建造起一栋栋高楼大厦。很显然,把图纸变成大厦可不是一件容易的事情,需要很多人分工协作方能完成。
首先,公司需要能够看懂图纸并将其转化为建筑项目的架构师,斯巴克公司从友商那里挖角了行业知名架构师“戴格”(DAGScheduler)。集团公司给戴格安排的角色是总公司的空降领导,并要求两位创始元老“塔斯克”和“拜肯德”竭尽全力配合戴格的工作。塔斯克(TaskScheduler)一毕业即加入斯巴克公司,现任总公司施工经理,成功指挥完成了多个大大小小的工程项目,业绩突出,深得公司赏识。拜肯德(SchedulerBackend)和塔斯克大学的时候就是上下铺,关系好得穿一条裤子,现任总公司人力资源总监,负责与分公司协调、安排人力资源。从公司的安排来看,三位老板的分工还是比较明确的。
斯巴克建筑公司的三位大佬
简单介绍了斯巴克建筑公司,我们再说回 Spark,在上一篇《内存计算的由来—— DAG》中我们讲到 DAGScheduler 如何将 DAG 拆分为 Stages。Stages 拆分只是 Spark 分布式任务调度的第一步,要将 Stages 进一步转化为可执行的分布式任务,Driver 需要众多的对象组件来进行任务拆解、计算资源协调、任务进度跟踪等工作,如 TaskScheduler、TaskSetManager、TaskResultGetter、MapOutputTracker、SchedulerBackend 等对象,这其中,最重要的两个对象就是 TaskScheduler 和 SchedulerBackend。所有这些对象,都是伴随着 Driver 进程中 SparkContext(或 SparkSession)的初始化而创建的。
之所以说塔斯克和拜肯德是公司元老,原因在于,在 SparkContext 的初始化中,TaskScheduler 和 SchedulerBackend 是最早且同时被创建的两个服务于 Spark 调度系统的接口抽象。两者的关系非常微妙,SchedulerBackend 在构造方法中引用 TaskScheduler,而 TaskScheduler 在初始化时会引用 SchedulerBackend。SchedulerBackend 接口抽象的创建基于 Spark 的 MasterURL,也即各位看官在使用 spark-submit 或 spark-shell 时指定的--master 参数,如--master spark://ip:host(Standalone 模式)、--master yarn(YARN 模式)。
为了支持多样的资源调度模式(Standalone、YARN、Mesos),SchedulerBackend 提供了与之对应的多个实现类,类之间的依赖与继承关系如下图所示。因此,Spark 采用哪种实现类来创建 SchedulerBackend,完全取决于开发者提供的 MasterURL,SchedulerBackend 与资源管理器强绑定,是资源管理器在 Spark 中的代理。硬件资源与人力资源一样,都是“干活儿的”,如果用人力资源来类比硬件资源,那么“拜肯德”(SchedulerBackend)就是名副其实的人力资源总监。
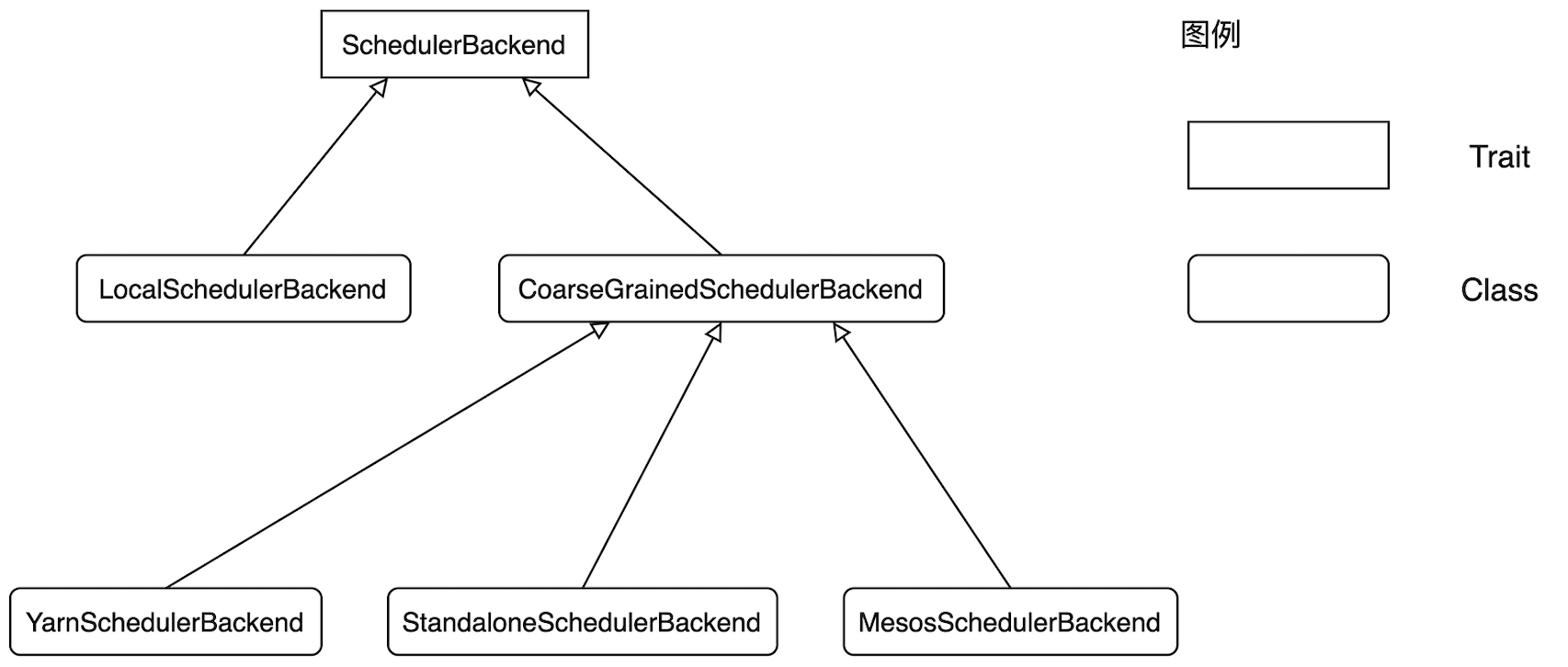
SchedulerBackend 类图
对于划分的每一个 Stage,DAGScheduler 会为之创建对应的任务集合 TaskSet。DAGScheduler 以 TaskSet 为粒度向 TaskScheduler 提交任务调度请求。TaskScheduler 在初始化的过程中,除了引用 SchedulerBackend 之外,还会创建任务调度队列。任务调度队列用于缓存 DAGScheduler 提交的 TaskSet,TaskScheduler 结合 SchedulerBackend 提供的 Worker Offer,按照预先设置的调度策略(FIFO 或 FAIR)依次对队列中的任务进行调度。简言之,DAGScheduler 手里有“活儿”,SchedulerBackend 手里有“人力”,TaskScheduler 的核心职能就是把合适的“活儿”派发到合适的“人”手里,所谓把专业的事情交给专业的人去做。
由此可见,TaskScheduler 是承上启下、上通下达的关键角色,这也是为什么我们将塔斯克视为斯巴克建筑公司元老之一的原因。空降的架构师戴格在两位元老的协助下,可以说工作开展得相当顺利,然而,冰层之下,暗流涌动,表面的祥和与心悦诚服之间还远远画不上等号,空降领导想要获得创始元老的认可,还有很长的路要走。
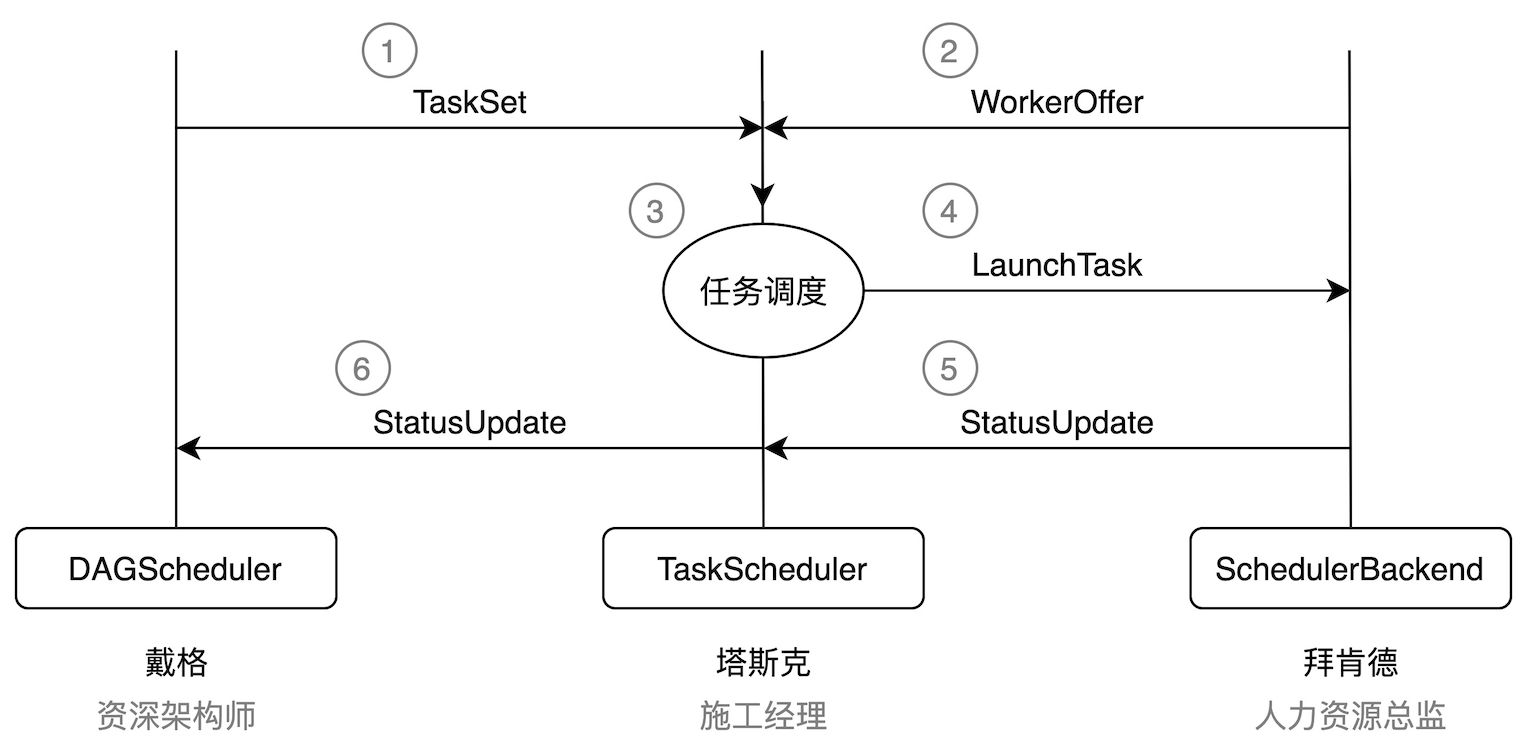
三位大佬分工协作的简易流程图
元老派
提起塔斯克和拜肯德,公司里无人不知、无人不晓,两位老板一个是管事的头儿,一个是管人的头儿。既然是老板,自然不能什么事情都事必躬亲,塔斯克和拜肯德麾下都有一众小弟来负责具体事务。塔斯克手下有三位举足轻重的直级下属,分别是秘书 SchedulableBuilder、施工副经理 TaskSetManager 和验收员 TaskResultGetter,三位虽说都是塔斯克的嫡系,早已与塔斯克达成默契,但副经理 TaskSetManager 对于自己老大的位子一直蠢蠢欲动,觊觎已久。
塔斯克作为老大高高在上,看的明明白白,对于三位下属的脾气秉性和利益诉求了然于胸,自然会察觉到 TaskSetManager 日渐突出的“脑后反骨”。忌惮于 TaskSetManager 的野心,工于权术的塔斯克自然不会无动于衷,为了防患于未然,塔斯克首先通过“分权”来制衡 TaskSetManager。所谓“分权”,指的是每一个 TaskSetManager 都和 TaskSet 一一对应、绑定,形象地说,领到砌墙任务的副经理只负责盯着干活的人砌墙,而领到浇筑钢筋混凝土任务的副经理只负责看着工人把钢筋混凝土浇筑牢固,副经理与副经理之间没有半点交集,所有副经理都是直线向上汇报。
教会徒弟、饿死师傅,为了彻底免去后顾之忧,塔斯克决定对于施工副经理 TaskSetManager 的聘用采用外包制度,也即取消常驻施工副经理一职,有活儿(TaskSet)的时候才临时招聘 TaskSetManager 上岗负责实施,一旦工人们把活儿干完了,则立即取消 TaskSetManager 的劳动关系。可以这么说,塔斯克对于 TaskSetManager 是召之即来、挥之即去,说是始乱终弃也不为过。树大招风风撼树,人为名高名丧人,可悲可惜可叹,TaskSetManager 的狼子野心最终葬送了自己的大好前程。
然而,TaskSetManager 的悲惨命运还远未结束,除了受制于老板塔斯克,自己负责的活儿(TaskSet)能不能尽快找到合适的工人(WorkerOffer)施工,还要看老板秘书—— SchedulableBuilder 的脸色。
说起秘书 SchedulableBuilder,就不得不提 Schedulable,顾名思义,Schedulable 就是“可调度的(对象)”,实现为 Scala Trait,定义了可调度对象接口。Schedulable 有两个具体实现类,一个就是刚刚提到的施工副经理 TaskSetManager,另一个是 Pool —— 调度池。每个调度池都维护一个调度队列,这个队列存储的元素是一个个 Schedulable,可以是 TaskSetManager,也可以是 Pool。
显然,调度队列最终构成的是一个层级嵌套结构,这就好比往一个容器里装水,除了装水之外还会放其他容器,而这些容器里除了盛水之外也还可能再容纳另外的容器,以此类推。不过,无论层级多么深、嵌套多么复杂,如果将这种层级嵌套结构展平(Flatten),得到的都是 TaskSetManager 数组。回到刚才容器盛水的类比,如果把所有嵌套的容器都去掉,那么只会留下一种元素—— 水。由此可见,TaskSetManager 是 Spark 调度系统的基本调度单元,Pool 是基于一定规则和策略对 TaskSetManager 进行排列组合的层级嵌套队列。
那么问题来了,对于两个不同的 TaskSetManager,Spark 如何决定优先调度谁呢?对于有依赖关系的任务集,比如前文书提到的砌墙与浇筑钢筋混凝土,Spark 一定是先执行“砌墙”的任务集,再处理“浇筑钢筋混凝土”。对于不存在依赖关系的任务集,如“铺地瓷”和“吊顶”,很明显,两种任务可以互不妨碍地同时进行—— 此时便轮到秘书 SchedulableBuilder 大显身手了。SchedulableBuilder 也被实现为 Scala Trait,同时它也有两个具体实现,一个是 FIFOSchedulableBuilder,另一个是 FairSchedulableBuilder。两个实现类都需要做两件事情:构建调度池和添加 TaskSetManager。
FIFOSchedulableBuilder 与 FairSchedulableBuilder 的区别与联系
FIFOSchedulableBuilder 的处理逻辑相当简单,首先对于调度池的构建,它不需要做任何事,仅仅是获得构造方法中传进来的调度池的引用而已;addTaskSetManager 也仅仅是根据“先到先得”的原则向队列中追加 TaskSetManager,这也是 FIFO 名字的由来。
FairSchedulableBuilder 需要做的事情则复杂得多,对于调度池构建,它需要读取 fairscheduler.xml(或自定义配置文件)中关于层级队列的配置来对应地创建层级嵌套的队列结构;添加 TaskSetManager 的逻辑也会麻烦一些,首先需要找到插入该 TaskSetManager 的目标队列,如果不存在还需另行创建并把该队列追加到已有的层级队列中,然后再把 TaskSetManager 塞入到该目标队列。
顾名思义,Fair 是公平的意思,之所以称为公平调度,是因为 FairSchedulableBuilder 所依赖的 fairscheduler.xml 规范文件将分布式集群计算资源按照层级嵌套的规则划分为多个子集,每个子集都根据一组参数划定可以占用的计算资源配额。
具体来说,在 FairSchedulableBuilder 中,有两个关键参数用于划定计算资源配比,即 weight、minShare。
weight 和 minShare 的含义
我们以 Apache Spark 官网给出的 fairscheduler.xml 为例,该示例定义了 3 个调度池,3 个调度池之间的关系是采用公平的方式按照配额划分计算资源。这里 3 个调度池的 weight 都是 1(最后一个没有指定 weight 则采用默认值),minShare 指定每个调度池所必需的最小 CPU 个数,如果没有指定,默认为 1。有意思的是,每个调度池还可以指定自己内部的调度模式,在这个例子中,3 个调度池内部的调度算法都是 FIFO,也就是说,虽然 3 个调度池之间是“公平”地抢占资源,但是在各个调度池内部,还是按照先到先得的原则来调度任务。

例子来源:https://github.com/apache/spark/blob/master/core/src/test/resources/fairscheduler.xml
相比塔斯克,拜肯德老板的下属要忠心的多,ExecutorBackend 作为拜肯德的唯一下属,远远地戍守在分公司,定期向老板汇报分公司的人力资源状态。由于离权力中心较远,ExecutorBackend 对于老大的地位构不成任何威胁,也正因为如此,拜肯德对于小弟 ExecutorBackend 可以说是充分放权,能下放的事情尽量下放,自己则稳坐高阁、逍遥自在。
元老派人员构成
空降派
面对根深蒂固的元老派,戴格作为职场老手自然也不会光杆司令一个人单打独挑。在入职总公司的当天,戴格即将自己多年的亲信 EventProcessLoop 招致麾下。EventProcessLoop 作为贴身秘书,对于戴格的想法和意图心领神会,对于戴格的处境更是心照不宣。自合作以来,EventProcessLoop 一直扮演着老黄牛的角色,按部就班、有条不紊地执行老板交代的一项又一项任务,戴格对其自然信任有加,手里的大小事务几乎都交由 EventProcessLoop 代理。
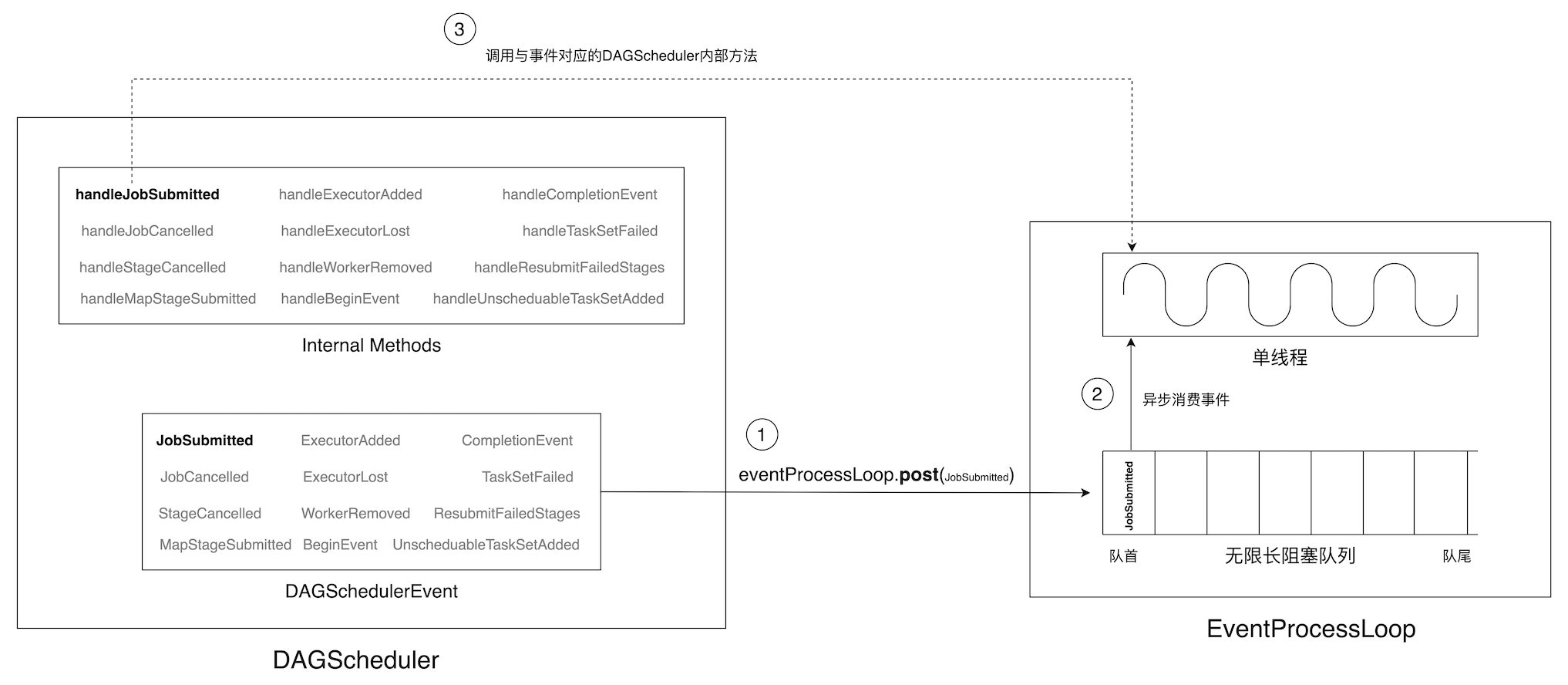
DAGScheduler 与 EventProcessLoop 之间的方法调用
每当 DAGScheduler 有新事件(DAGSchedulerEvent)需要处理时,都会调用 EventProcessLoop 的 post 方法将其塞入 EventProcessLoop 的无限长阻塞队列。EventProcessLoop 的异步单线程以循环的方式(Loop 命名的由来)不断从队首读取并消费事件,通过调用与事件对应的方法(由 DAGScheduler 提供)来执行相应的任务。
从上图中不难发现,事件类型与处理方法都由 DAGScheduler 定义、提供,EventProcessLoop 的主要职责在于提供单线程执行环境、接收 DAGSchedulerEvent、调用对应的 Handler 方法、以循环的方式异步执行处理逻辑。换句话说,做什么(What)、怎么做(How),由戴老板明确示下,贴身秘书 EventProcessLoop 则按照老板的指示全天候、24 小时、马不停蹄地撸起袖子加油干。
然而,尽管有得力干将 EventProcessLoop 分忧,作为全公司的一把手,戴格一方面需要处理好与平级塔斯克和拜肯德之间的关系,另一方面又要事无巨细地摸清公司的“事儿”与“人”。另外,作为一名空降的领导,戴老板也不得不时不时地亲自“露两手”来赢得平级、下属以及全公司的认可和信任。除了交予 EventProcessLoop 的“活儿”,还有很多事情需要戴老板亲自跟进:
o DAG 解析、Stage 拆解(参考上一篇《内存计算的由来 —— DAG》)
o 生成 TaskSet,获取 Tasks 的偏好位置(Preferred Locations)
o 不同 Stage 之间的失败重试与容错
在权力场,老大联合老三打压老二是常见的策略,所谓远交近攻,但是坐第三把交椅的拜肯德对空降老大戴格的态度是:吃冰棍、拉冰棍—— 没话(化)!关于人力资源和任务执行的情况,戴老板拿到的信息都是塔斯克传递的二手信息,拜肯德从来不直接向戴格汇报工作。一句话,在我拜肯德眼里,你戴格是空气般的存在,塔斯克才是斯巴克建筑公司的唯一首领。真真是“江湖你拜哥,人狠话不多”。
对于戴格的空降,塔斯克更是如鲠在喉—— 我塔斯克为公司服役这么多年,承接、实施了多少建筑工程项目,早已成为全公司事实上的一把手,公司在这个节骨眼把戴格招进来当老大,到底是何用意?面对这样的平级关系,戴格自然是如履薄冰。
不过,元老派也不是铁板一块,组织架构中原本已经固化的阶层关系因为戴格的到来产生了微妙的变化。不仅如此,公司为了进一步制衡两位创始元老,分别招聘了工程进度总监(MapOutputTrackerMaster)和工程监理总监(BlockManagerMaster)来协助戴格更好地开展工作。
MapOutputTrackerMaster 负责维护不同 Stage 间 Shuffle 任务的中间状态,一旦出现 Shuffle 中间结果不可获取的情况,DAGScheduler 便通过 post 方法将 ResubmitFailedStages 事件递交给 EventProcessLoop 从而进行 Stage 之间的失败重试。BlockManagerMaster 则负责维护所有与数据存储有关的元信息,如 HDFS 数据分片所在地址、Shuffle 中间文件的输出路径等,DAGScheduler 需要调用 BlockManagerMaster 的 getLocations 方法来获取 TaskSet 中 Tasks 的位置偏好。
空降派人员构成
到此,Spark 调度系统中的主要角色基本都已浮出水面,咱们用一张“航拍”鸟瞰图,来完整地刻画不同角色的派系、立场、职责与定位。
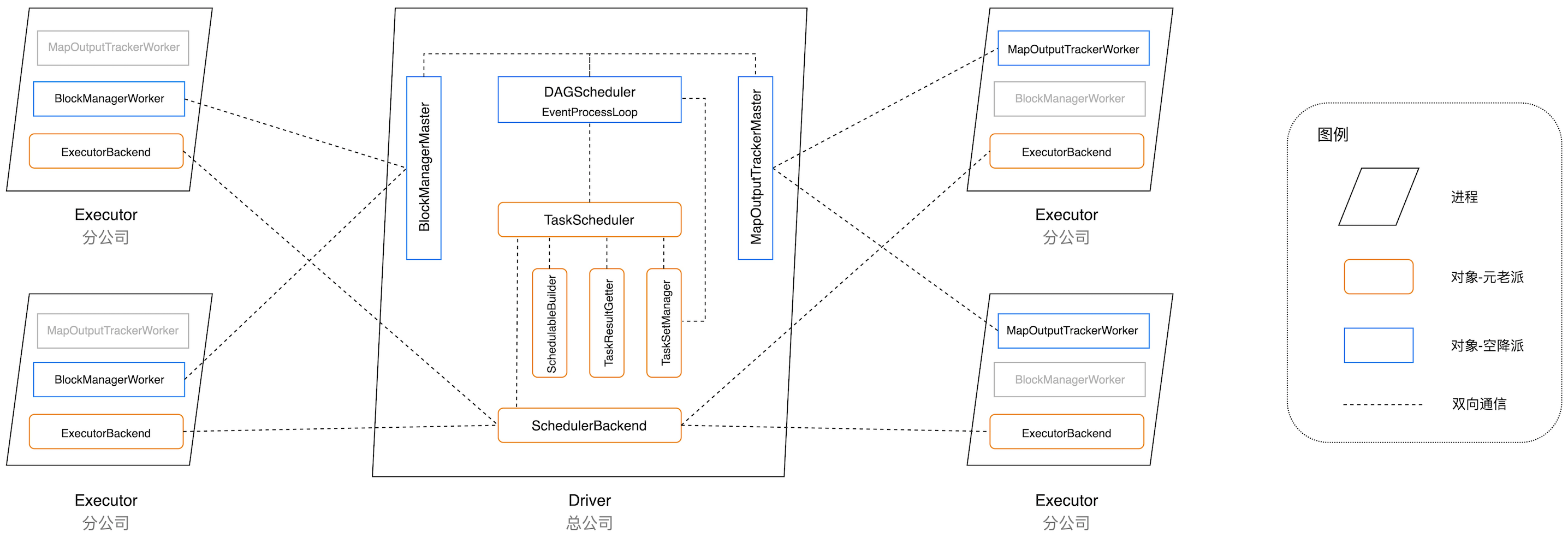
Spark 调度系统的权力角色
任务提交的代码调用
抛开错综复杂的权力纠葛不谈,我们来看看 Spark 调度系统端到端是如何运作的。我们最关心的莫过于开发者在调用 Action 算子、触发任务提交之后,Spark 调度系统如何在分布式环境中进行任务调度、“数据不动代码动”到底是如何实现的?下面的这张代码调用流程图看上去未免过于压力山大,咱们不如像庖丁宰牛那样,一块块地给它分解开来,这样不同的环节看上去也会更明了一些。
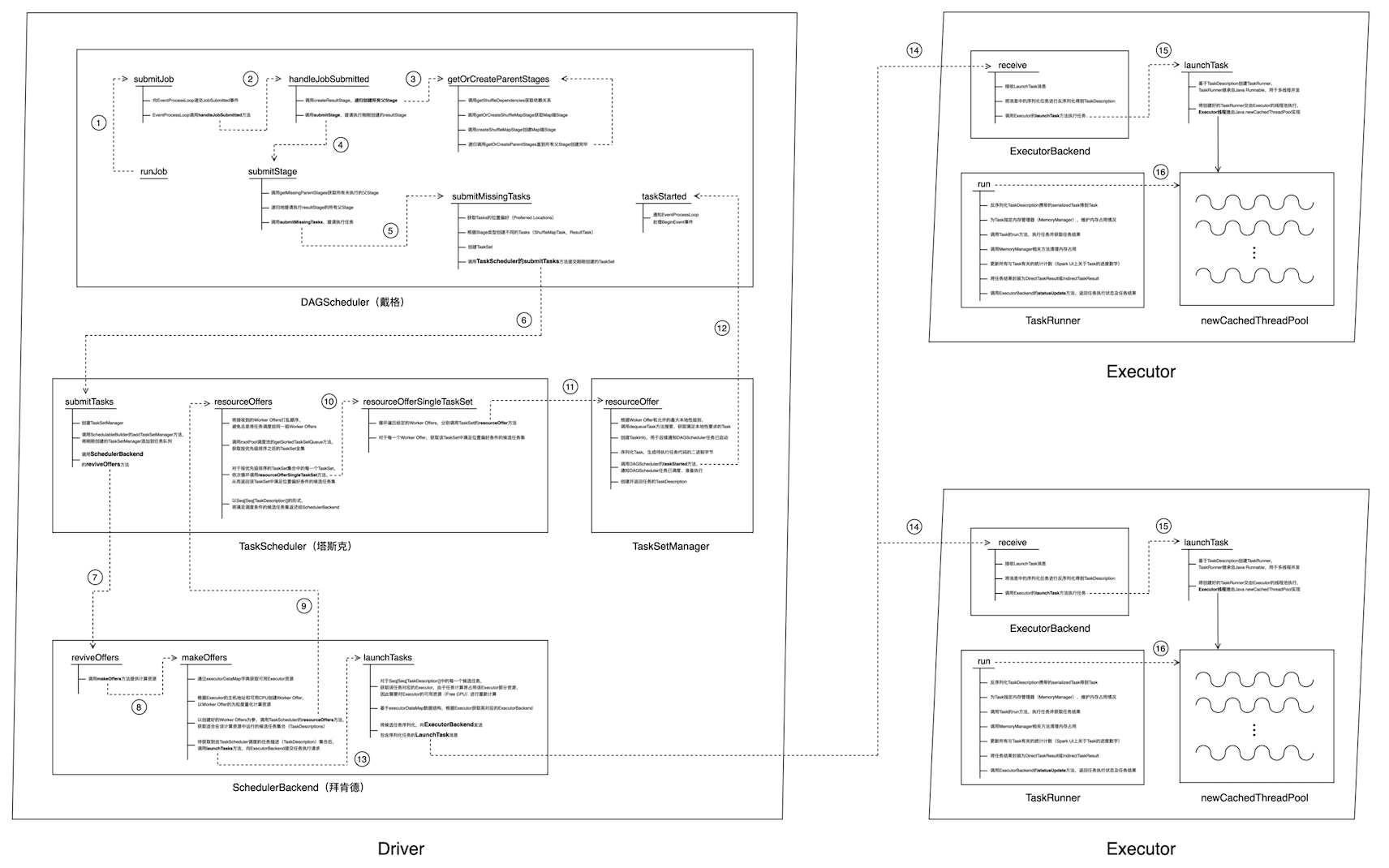
任务提交代码调用流程图
仔细观察上面的流程图,我们会发现整个分布式任务调度与执行的流程可以分为 3 个阶段,也即老大戴格和老二塔斯克之间的交互阶段、老二塔斯克与好基友拜肯德的交互阶段、老三拜肯德与小弟之间的交互阶段。咱们来分别看看这 3 个阶段之中都发生了哪些有趣的事情。
貌合神离 —— 戴格与塔斯克
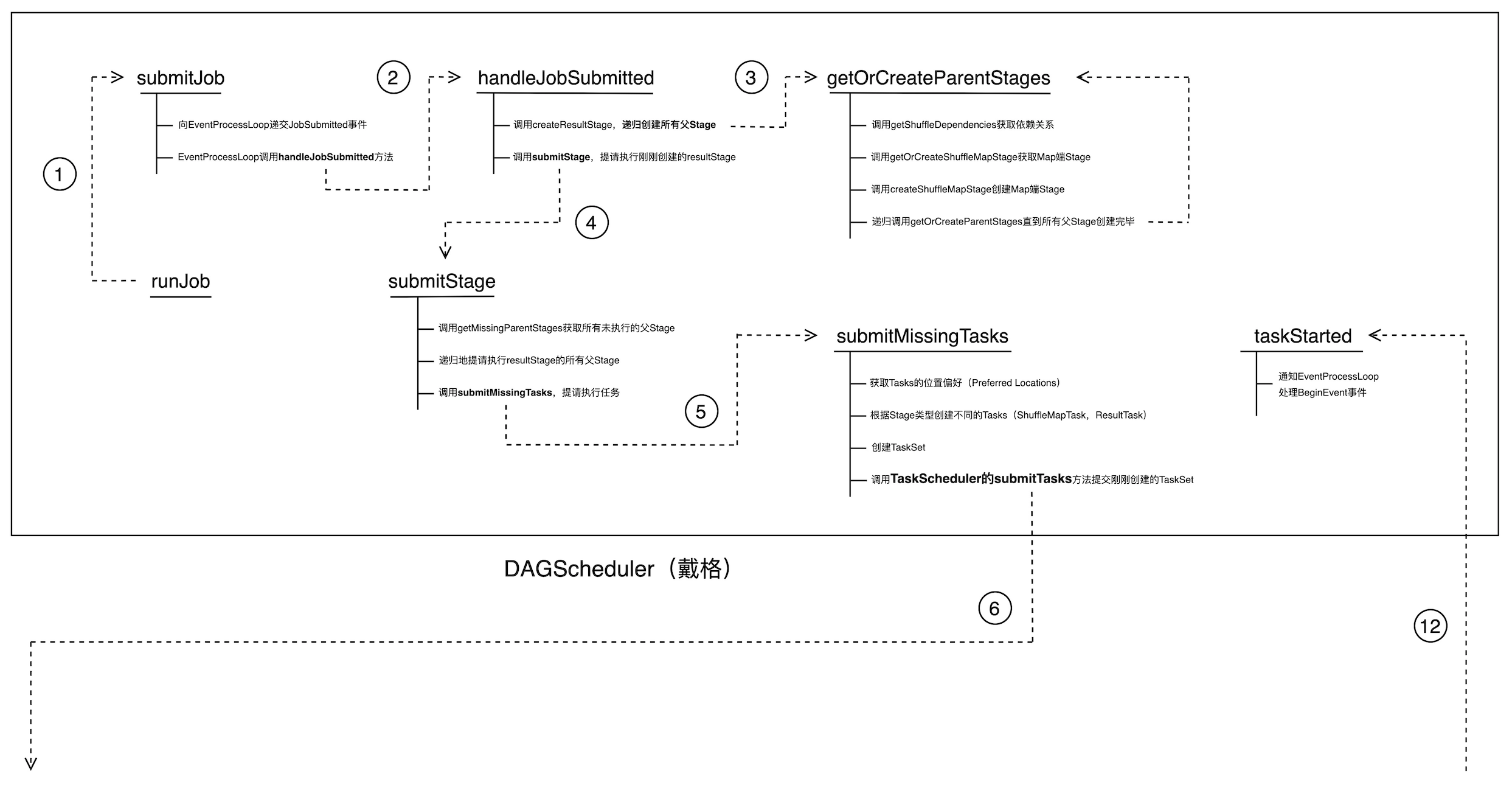
任务提交代码调用流程图 —— DAGScheduler 内部调用
在 Spark 应用开发中,我们用一系列 Transformations 算子和 Actions 算子来构建应用程序,每一个 Actions 算子都会触发 SparkContext 的 runJob 函数调用,从而开启一段分布式调度之旅。
千里之行始于足下,SparkContext 的 runJob 函数仅仅是向前迈出一小步,主要作用是调用 DAGScheduler 的 runJob 函数,DAGScheduler 内部的函数调用则被囊括到上面的流程图中。
首先,runJob 通过调用 submitJob 向 EventProcessLoop 递交 JobSubmitted 事件,EventProcessLoop 则调用 DAGScheduler 的 handleJobSubmitted 方法以递归的方式创建所有 Stages。说到这里,各位看官是否觉得似曾相识呢?没错!getOrCreateParentStages 这个环节对应的正是上一篇《内存计算的由来—— DAG》最后 DAGScheduler 创建 Stages 的过程。
Stages 创建完毕后,通过调用 submitStage 来提交 ResultStage。值得注意的是,在 submitStage 中,DAGScheduler 会先检查待执行 Stage 所依赖的父 Stages 是否已执行完毕,如果没有则递归地提请执行所有未执行的父 Stages。对于当下需要执行的 Stage,调用 submitMissingTasks 提请进行任务调度。submitMissingTasks 是这段代码调用的关键,主要进行如下 4 项操作:
o 计算每一个 missing task 的位置偏好(这个时候就需要 BlockManagerMaster 来打配合)
o 根据 Stage 类型的不同分别创建 ShuffleMapTask 和 ResultTask
o 创建 TaskSet(注意,TaskSet 由 DAGScheduler 创建,而可调度对象 TaskSetManager 则由 TaskScheduler 创建)
o 调用 TaskScheduler 的 submitTasks 方法提交刚刚创建的 TaskSet
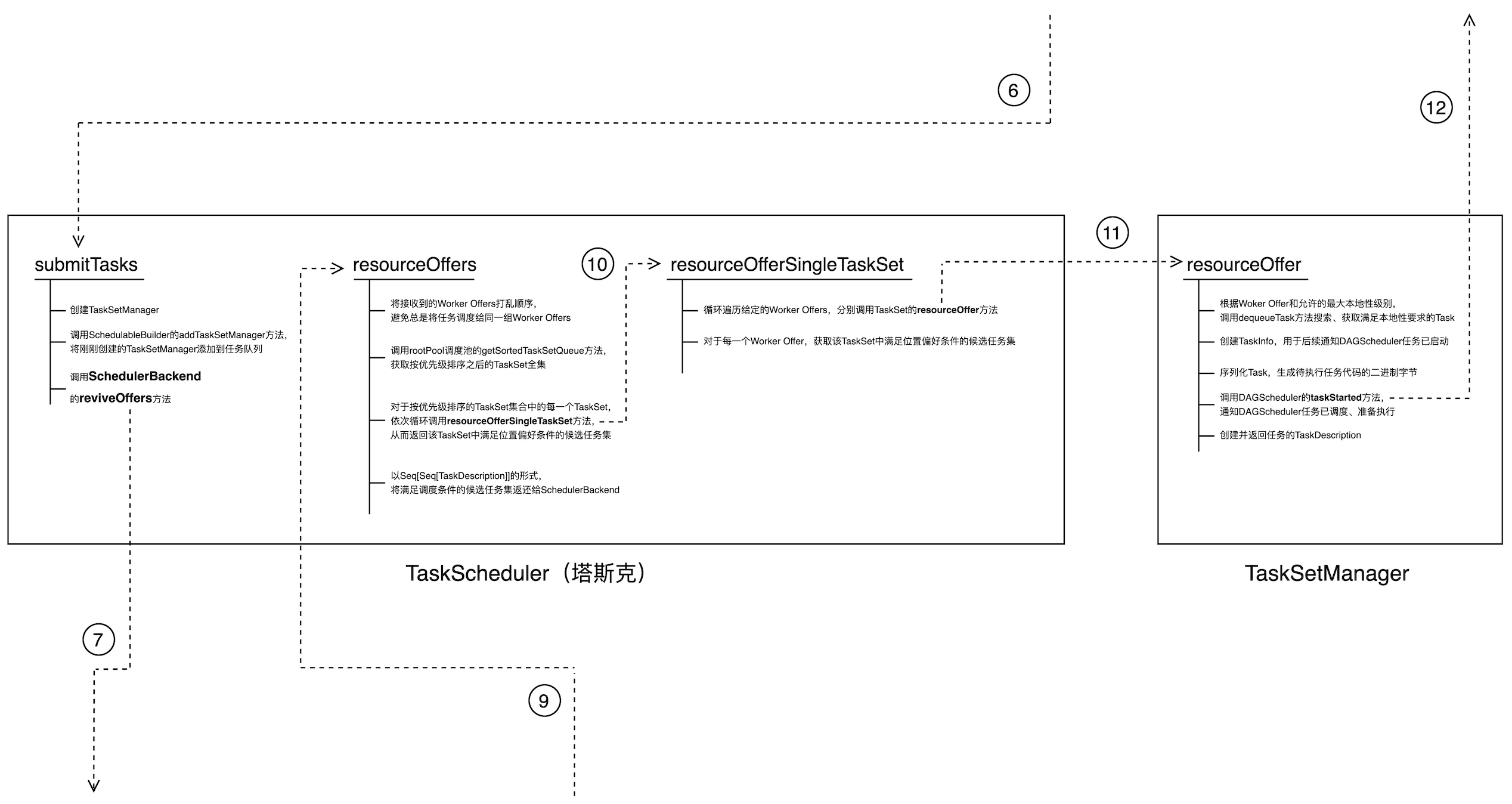
任务提交代码调用流程图 —— TaskScheduler 内部调用
从代码调用的角度,我们发现 TaskScheduler 是与外部交互(外连虚线个数)最多的一个模块,塔斯克在公司的地位由此可见一斑。
TaskScheduler 接收到 DAGScheduler 创建的 TaskSet 后,第一步就是招聘施工副经理 —— 创建 TaskSetManager,随即通知秘书把施工副经理安排在合适的位置,SchedulableBuilder 即调用 addTaskSetManager 方法将刚刚创建的 TaskSetManager 追加到任务队列中。
在 submitTasks 的最后,TaskScheduler 调用 SchedulerBackend 的 reviveOffers 方法请求计算资源,这一步本质上是塔斯克向好基友拜肯德征集“能干体力活儿”的人力资源。分公司的那些小弟们—— ExecutorBackend 每时每刻都在向老板拜肯德汇报麾下可用的人力状况,拜老板将这些情况汇总,统一反馈给死党塔斯克。在第 9 步,在拜老板提供了可用的人力资源(WorkerOffer)后,塔斯克需要有针对性地“派活儿”,也即把砌墙分给瓦工、把吊顶分给木工。
回到代码调用,resourceOffers 的主要职责是根据 SchedulerBackend 提供的 Worker Offers,将满足调度条件的任务集以 TaskDescription 序列的形式返还给 SchedulerBackend,后者将 TaskDescription 分发给对应的 ExecutorBackend 用于执行 —— 这是后话,咱们暂且不提。
resourceOffers 首先将得到的 Worker Offers 的顺序打乱,从而避免总是将“活儿”分派给同一个劳力的尴尬局面,然后调用调度池(rootPool)的 getSortedTaskSetQueue 方法,获取按照 FIFO 规则(FIFOSchedulingAlgorithm)或 FAIR 规则(FairSchedulingAlgorithm)排序后的 TaskSetManager 集合。这里的排序规则与 SchedulableBuilder 的构建规则是一一对应的,如果是 FIFO 队列,则根据 TaskSetManager 的优先级来进行排序;如果是 Fair 队列,则同时考虑已调度任务数、weight、minShare 等因素对 TaskSetManager 进行排序。
总之,调用 rootPool 的 getSortedTaskSetQueue 方法获得的是按照预先定义的调度规则排序后的 TaskSetManager 序列。一旦施工副经理们排好了队,塔斯克即按照顺序把到手的人力资源信息依次传达、告知,那么,排在队伍前面的施工副经理们自然是近水楼台先得月,所管辖的施工工程任务自然大概率优先被执行。
为什么说是“大概率”而不是“一定”呢?这是因为咱们的建筑工人多少有些傲娇和任性—— “挑活儿”!瓦工只干砌墙、浇筑钢筋混凝土;木工只干吊顶、安橱柜、安门窗,让他帮忙顺带着铺个地磁都是推三阻四不乐意。不过这也难怪,毕竟现在劳动市场人力资源紧张,工人们是按照小时计费的,因此时薪低的活儿人家自然是不乐意干的。
回答刚刚“大概率”的问题,SchedulerBackend 返回给 TaskScheduler 的 WorkerOffer,都标记了最大本地性级别,不知道各位看官对于计算的本地性是否还有印象,我们在第一篇《内存计算的由来 —— RDD》中有简略提及。本地性级别的编号是从小到大,对应的本地性越来越差,顺序依次是:
Process Local
因此最大本地性级别可以直接理解为可以容忍的最差的本地性级别,也就是说最大本地性级别标注了这份计算资源所能接受的所分配任务的“底线”,有点绕,咱们来举个例子:
对于某个 Worker Offer,假设它的最大本地性级别是 Node Local,这就意味着分配给该 Worker Offer 的任务至少可以保证 Node Local 这个级别的本地性(任务的执行不必跨节点拉取数据);换句话说,如果某个排在队伍前面的 TaskSetManager 所管辖的任务都无法保证这个本地性级别,那么这个 TaskSetManager 里面的任务是不会被调度到这个 Worker Offer 上去执行的,那么,它不得不把这次任务调度的机会拱手让给排在后面的其他 TaskSetManager。
至于一个 TaskSetManager 中的任务哪些满足最大本地性级别、哪些不满足,则完全仰仗咱们的施工副经理,TaskScheduler 也是通过调用 resourceOfferSingleTaskSet 来调用 TaskSetManager 的 resourceOffer 方法最终获得满足条件的任务集合(TaskDescription 集合)。
我们重点看看 TaskSetManager 在 resourceOffer 方法中都做了哪些事情。
第一步,就是通过内部的 dequeueTask 方法来获得满足本地性条件的任务集合;然后,将满足条件的任务依次进行序列化、生成二进制字节序列;最后,将序列化的任务封装为 TaskDescription,把所有封装的 TaskDescription 以序列的形式返回给 TaskScheduler。
按理说,到此为止施工副经理的工作做得相当到位、得体,老板交代的事情完成得相当漂亮,塔斯克应该很满意才对,没有道理对下属心墙高筑。坏就坏在 TaskSetManager 自作聪明,为了表现自己积极能干,每次都是活儿还没干完、老板塔斯克要的东西还没交差,就越级向空降老大戴格事无巨细地汇报自己的工作进展:手里负责的哪些施工任务交给了哪些工人去实施,等等。
我们都知道,在职场之中,越级汇报是大忌,作为老板,如果列位看官您是塔斯克本人,下属三天两头向自己的直属领导汇报工作,您作何感想?前文书咱们说过,虽然塔斯克对于施工副经理的越级汇报是睁一只眼闭一只眼,但沉稳老练的塔斯克早就想到了通过变更聘用制度来釜底抽薪、防患于未然。
TaskSetManager 在将自己负责的 TaskSet 中的任务集全部调度完毕之后,即被 TaskScheduler 踢出调度池,随即进入僵尸(Zombie)状态,等候他们的命运是被垃圾回收器(Garbage Collector)清理,想通过跟老大戴格勾搭连环实现上位的幻想也随之化作泡影。狠不狠?绝不绝?论心机与城府,笔者只服塔斯克。
心有灵犀 —— 塔斯克与拜肯德
不需言语,只要一个眼神、一个动作即可领会彼此的意图,塔斯克与拜肯德之间的默契大抵如此。
在第 7 步 TaskScheduler 通过调用 reviveOffers 来请求计算资源后,BackendScheduler 随即调动一切可以调动的力量通过 makeOffers 来协调计算资源。为了能够快速响应 TaskScheduler 的请求,拜老板用一个“小册子”来记录所有可用计算资源的状态,这个小册子就是 executorDataMap。
executorDataMap 是类型为 HashMap[String,ExecutorData]的数据结构,其中类型为 String 的 Key 记录 ExecutorID,类型为 ExecutorData 的 Value 则记录每一个 Executor 的 Profile,包括 Executor 的 RPCEndpoint、RPC 地址、主机地址、当前可用 CPU cores、满配 CPU cores 数量,等等。拜老板正是根据 executorDataMap 中 Executor 的主机地址和可用 CPU cores 来创建 Worker Offer,并以 Worker Offer 为粒度量化计算资源。
在第 9 步,BackendScheduler 将所创建的 Worker Offers 打包并通过 TaskScheduler 的 resourceOffers 方法发送给 TaskScheduler,尝试获取所有适合在提供的 Worker Offers 上执行的任务集合(Seq[Seq[TaskDescription]])。
前文书在塔斯克与 TaskSetManager 的恩怨纠葛中,咱们已经介绍过任务集的遴选过程,最终 TaskScheduler 在 TaskSetManager 的协助下将满足条件的、包含序列化任务代码的 Seq[Seq[TaskDescription]]返回给 SchedulerBackend。
拿到任务描述序列的 SchedulerBackend 随即调用 launchTasks 方法尝试把每一个任务分发到对应的 Executor 上,真正开启分布式任务执行的流程。对于拿到的每一个 TaskDescription,launchTask 首先获取其对应的 Executor,然后根据 executorDataMap 获取该 Executor 的 ExecutorBackend,最后通过向 ExecutorBackend 发送包含序列化任务的 LaunchTask 消息来分发待执行的任务代码。
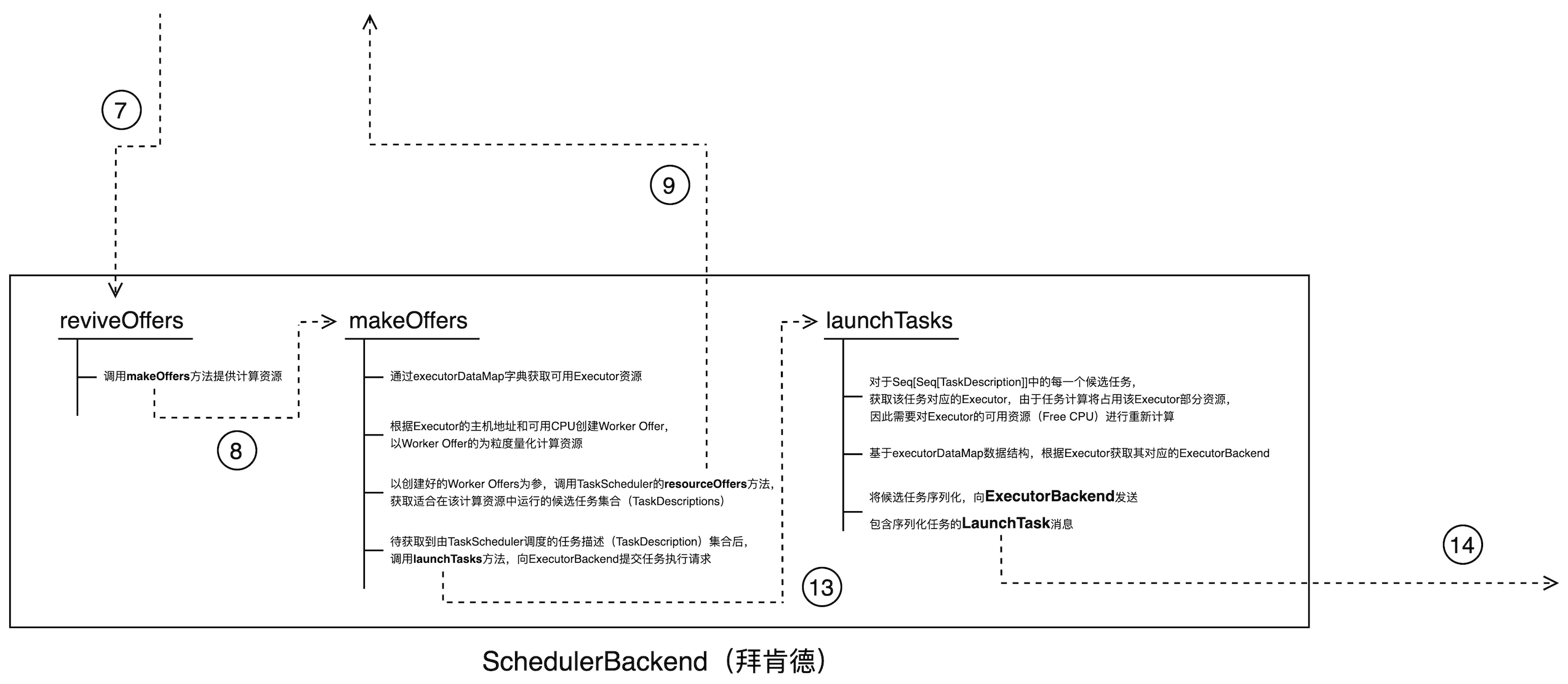
任务提交代码调用流程图 —— SchedulerBackend 内部调用
到第 14 步为止,Spark 调度系统对于任务提交阶段的支持基本告一段落,我们来回顾一下从第 7 步到第 14 步,主要经历了哪些重要环节:
o TaskScheduler 请求分布式计算资源
o SchedulerBackend 搜集可用计算资源,并以 Worker Offers 的形式反馈给 TaskScheduler
o TaskScheduler 根据获得的 Worker Offers,根据调度规则(FIFO 或 Fair)和本地性的限制,搜集适合调度的任务集合,并以 TaskDescriptions 的形式反馈给 SchedulerBackend
o 对于获取到的 TaskDescriptions,SchedulerBackend 将其中封装的任务代码分发到对应的 Executors 上,开启分布式任务执行流程
这 4 个环节的拆解更加直观地阐释了分布式计算中“数据不动代码动”的计算模式,在这种计算模式下,我们倾向于让数据“待在”它本来存储的地方、尽量保持不动,同时为了完成分布式计算,我们尽可能地把代码(任务)通过网络分发到它应该去的地方,而“它应该去的地方”正是有需要它处理的数据的地方。“数据不动代码动”的初衷之一在于从计算模式上减少数据的分发,降低分布式网络 I/O 开销从而在整体上提升执行性能。毕竟,分发代码的成本要比分发数据的代价低的多得多。
追随者众 —— 拜老板的小弟们
严格来说,从第 14 步往后已经超出了分布式系统调度的范畴,不过,为了还原一个分布式系统调度与执行的全貌,咱们接着往下说。
前文书咱们说到,拜老板有一众忠心追随的小弟们—— ExecutorBackend,ExecutorBackend 作为驻扎在分公司的“人力资源经理”,时刻搜集 Executor 的可用资源状态并随时向老板拜肯德汇报,拜老板正是基于这些小弟掌握的信息来从上帝视角更新、维护手里的“小册子”—— executorDataMap,并根据 executorDataMap 中记录的信息来快速响应塔斯克他老人家的用人需求。
在第 14 步中,拜老板将每个 TaskDescription 通过 LaunchTask 消息分发到与其对应的 Executor 中,众小弟在接收到老板的 LaunchTask 消息后立即调用 Executor 的 launchTask 方法开始干活。launchTask 首先把 TaskDescription 封装为 TaskRunner(TaskRunner 实现了 Java Runnable 接口,用于多线程并发),随即将封装好的 TaskRunner 交由 Executor 线程池,线程池则调用 TaskRunner 的 run 方法来执行任务。Java 并发编程规范提供了多种线程池支持,例如 newFixedThreadPool、newCachedThreadPool,Spark Executor 的实现选择了后者。
不同的线程池有不同的应用场景,不同开发者对于不同的线程池也有自己的理解和偏好,不过,采用线程池来实现高并发的特性是没什么太多争议的。抛开不同线程池的优劣对比不谈,咱们重点来说说 TaskRunner 的 run 方法都做了哪些事情。
首先,TaskRunner 先对 TaskDescription 中的 serializedTask 进行反序列化得到 Task;然后,为该 Task 指定内存管理器 MemoryManager,MemoryManager 维护一个 Executor 中所有 Tasks 的内存占用以及回收情况。接着调用 Task 的 run 方法来执行任务并获取任务结果,TaskRunner 最终将任务结果封装为 DirectTaskResult 或 IndirectTaskResult 并通过调用 ExecutorBackend 的 statusUpdate 方法将执行状态和结果返回。
到此为止,任务提交阶段的调度与执行就走完了,不过,结束即开始,一个阶段的终结意味着另一个阶段的开始,statusUpdate 以相反的方向、沿着权力越来越集中的方向一路北上,直到触达权力的最核心。statusUpdate 的整条调用路径会涉及 ExecutorBackend 的 statusUpdate 方法、SchedulerBackend 处理 StatusUpdate 消息、SchedulerBackend 尝试 makeOffers、TaskScheduler 的 statusUpdate 方法、TaskResultGetter 的 enqueue(Successful/Failed)Task 方法、TaskScheduler 的 handleTaskGettingResult 方法、最终调用到 TaskSetManager 的 handleTaskGettingResult 方法,TaskSetManager 在对任务状态进行维护之后随即通过调用 DAGScheduler 的 taskGettingResult 通知 DAGScheduler 获取任务结果。
鉴于篇幅的限制,statusUpdate 代码调用的完整路径以及路上发生的故事,咱们就不再详细展开了,这块留给感兴趣的看官们去深入探索(笔者厚着脸皮赤裸裸地准备开始偷懒了[允悲])。
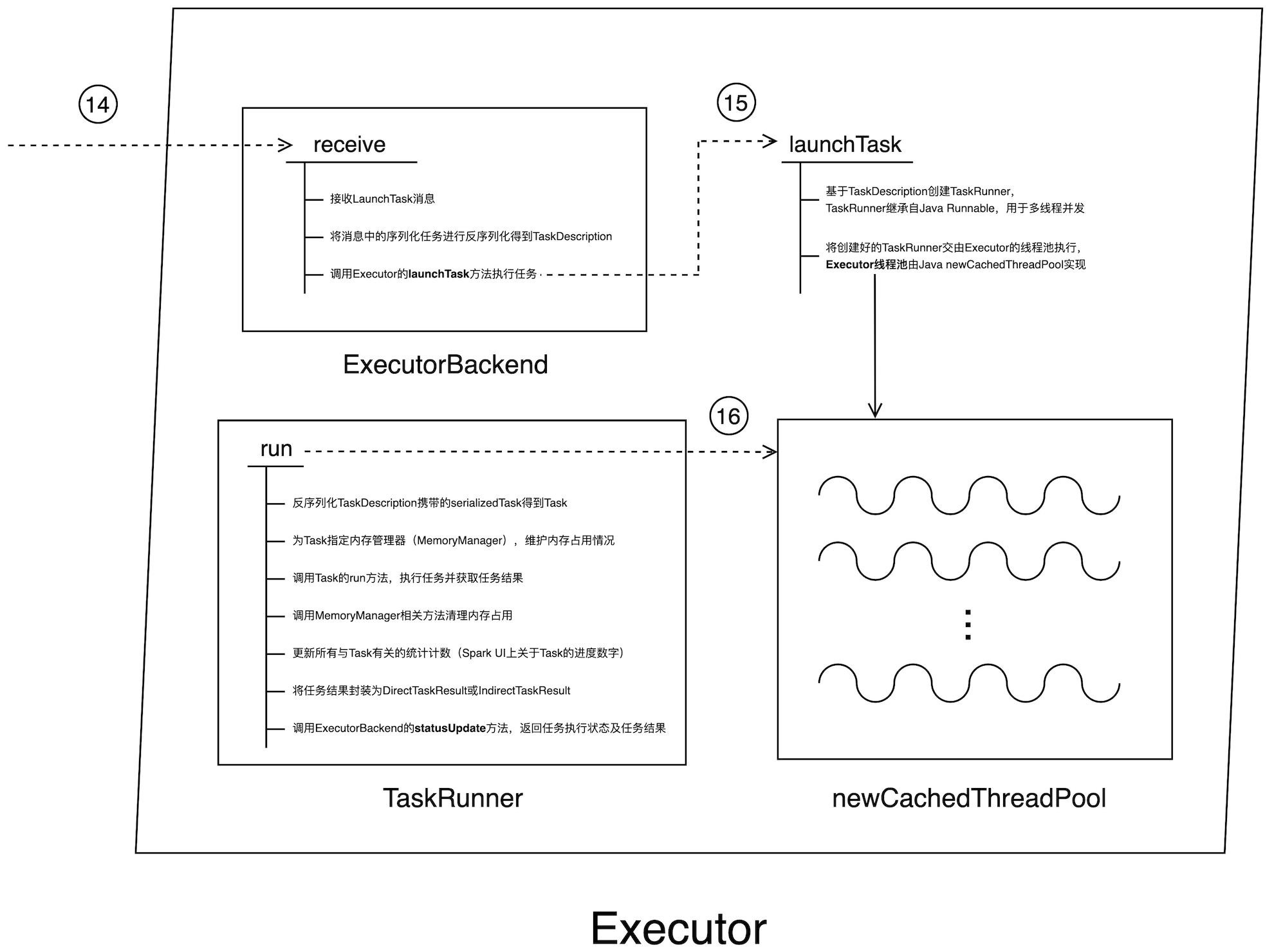
任务提交代码调用流程图 —— Executor 内部调用
Postscript
本篇是《深入浅出 Spark:原理详解与开发实践》的第三篇,笔者学浅才疏、疏漏难免。如果您有任何疑问,或是觉得文章中的描述有所遗漏或不妥,欢迎在评论区留言、讨论。掌握一门技术,书本中的知识往往只占两成,三成靠讨论,五成靠实践。更多的讨论能激发更多的观点、视角与洞察,也只有这样,对于一门技术的认知与理解才能更深入、牢固。
在本篇博文中,我们先通过虚构的斯巴克国际建筑集团公司以及公司里的各位大佬介绍了 Spark 调度系统中的主要角色:DAGScheduler、TaskScheduler 和 SchedulerBackend,然后通过派系的划分和立场带出了辅佐三位大佬的各种秘书、助手如 EventProcessLoop、SchedulableBuilder、TasSetManager、ExecutorBackend 等等。Spark 调度系统中涉及的对象、角色多如繁星,笔者反复思考如何以更好的方式把他们之间复杂而微妙的联系说清楚,真心希望斯巴克国际建筑集团公司“权力争斗”的故事能帮您更好地理解 Spark 调度系统。
如果您觉得斯巴克公司的类比过于牵强亦或是哪里用力过猛,欢迎您随时拍砖,更欢迎您一起讨论从而让故事的逻辑更加自洽。在后续的专栏文章中,我们会继续对 Spark 的核心概念与原理进行探讨,尽可能地还原 Spark 分布式内存计算引擎的全貌。
权力的游戏远未结束,分布式任务调度仅仅是冰山一角,毕竟不知 MapOutputTrackerMaster 和 BlockManagerMaster 如何协助老大戴格制衡塔斯克与拜肯德,且听下回分解。
作者简介
吴磊,Spark Summit China 2017 讲师、World AI Conference 2020 讲师,曾任职于 IBM、联想研究院、新浪微博,具备丰富的数据库、数据仓库、大数据开发与调优经验,主导基于海量数据的大规模机器学习框架的设计与实现。现担任 Comcast Freewheel 机器学习团队负责人,负责计算广告业务中机器学习应用的实践、落地与推广。热爱技术分享,热衷于从生活的视角解读技术,曾于《IBM developerWorks》和《程序员》杂志发表多篇技术文章,并在极客时间发表了两个专栏《零基础入门Spark》和《Spark 性能调优实战》,内容深入浅出、风趣幽默。




