
在 Uber,令人惊叹的客户体验依赖于准确的预计到达时间(ETA)。我们利用 ETA 来计算票价,估计接载时间,为乘客和司机牵线搭桥,安排送货,等等。传统的路由引擎计算是通过将道路网络划分为若干个小的路段(由图中的加权边表示)来计算 ETA。它们利用最短路径算法来寻找通过该图的最佳路径,然后将权重相加计算出来 ETA。但是大家都清楚,地图并非地形:道路图仅仅是一个模型,并不能很好地反映出地表的状况。另外,我们也不知道具体的乘客和司机将会选择哪条路线到达目的地。基于道路图预测,对机器学习模型进行了训练,并将历史数据和实时信号结合起来,对 ETA 进行了完善,使其能够更好地预测真实世界的结果。
在过去的数年中,Uber 利用梯度提升决策树对 ETA 的预测进行了改进。ETA 模型及其训练数据随着每个版本的发布而稳步增长。为了跟上这个增长的步伐,Uber 的 Apache Spark™ 团队对 XGBoost 进行了上游改进,使模型不断深入发展,成为当时世界上最大、最深的 XGBoost 组合之一。最终,我们达到了一个点,即使用 XGBoost 增加数据集和模型的大小变得难以维持。为了继续扩大模型的规模并提高准确性,我们决定深入研究深度学习,因为使用数据并行的 SGD 相对容易扩展到大数据集。为了证明转向深度学习的合理性,我们需要克服三个主要挑战:
延迟性:该模型必须在最多几毫秒内返回 ETA。
准确性:平均绝对误差(MAE)必须比现有的 XGBoost 模型有明显改善。
通用性:该模型必须在全球范围内提供 ETA 预测,包括 Uber 的所有业务线,如移动和交付。为了应对这些挑战,Uber AI 与 Uber 的地图团队合作开展了一个名为 DeepETA 的项目,为全球 ETA 预测开发一种低延迟的深度神经网络架构。在这篇博文中,我们将带领大家了解一些帮助 DeepETA 成为 Uber 新的生产 ETA 模型的经验和设计选择。
问题陈述
近年来,人们对世界的物理模型与深度学习相结合的系统产生了浓厚的兴趣。我们在 Uber 也采取了类似的方法来预测 ETA。我们的物理模型是一个路由引擎,它使用地图数据和实时交通测量来预测 ETA,作为两点之间最佳路径的分段遍历时间的总和。然后,我们利用机器学习来预测路由引擎 ETA 和现实世界观测结果之间的残差。我们称这种混合方法为 ETA 后处理,而 DeepETA 是后处理模型的一个例子。从实用的角度来看,通过更新后处理模型来吸纳新的数据源,并适应快速变化的业务需求,通常比重构路由引擎本身更容易。
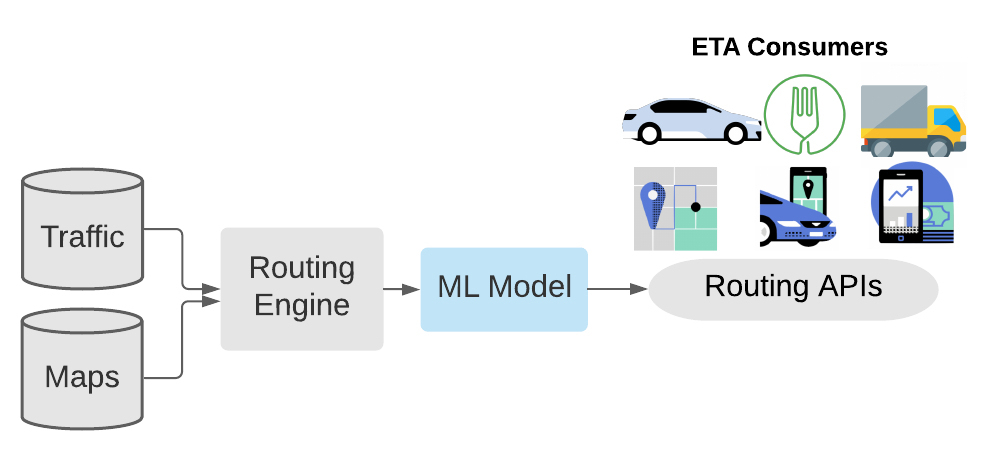
图 1:基于机器学习模型的 ETA 后处理混合方法
为了能够预测 ETA 残差,一个后处理的机器学习模型考虑到了空间和时间特征,例如请求的出发地、目的地和时间,以及实时交通信息和请求的性质,例如是上门送货还是搭车接人,如图 1 所示。这个后处理模型是 Uber 最高的 QPS(queries per second,每秒查询次数)模型。这个模型需要快速,以免给 ETA 请求增加太多的延迟,而且它们需要提高 ETA 的准确性,这是由不同段数据的平均绝对误差(mean absolute error,MAE)衡量的。
我们如何使它准确?
DeepETA 团队对 7 种不同的神经网络架构进行了测试,并对其进行了优化:MLP、NODE、TabNet、Sparsely Gated Mixture-of-Experts、HyperNetworks、Transformer 和 Linear Transformer。我们发现,具有自注意力的编码器-解码器架构能够提供最好的准确性。图 2 显示了我们所设计的高级架构。此外,我们测试了不同的特征编码,结果表明,将所有的输入离散化并嵌入到模型中,其效果明显要好于替代方案。

图 2:DeepETA 模型管道概述
具有自注意力的编码器
由于 Transformer 在自然语言处理和计算机视觉中的应用,许多人对其体系结构很熟悉,但是 Transformer 在诸如 ETA 预测这样的表格数据问题上的应用并不是很清楚。Transformer 的决定性创新是自注意力机制。自注意力是一个序列到序列的运算,它接收一个向量序列并产生一个重新加权的向量序列。详情可参阅 Transformer 论文。
在语言模型中,每个向量代表一个单词标记,而在 DeepETA 中,每个向量代表一个特征,如行程的起点或者一天中的时间。自注意力通过明确计算成对点积的 K*K 注意力矩阵,再利用这些缩放点积的 softmax 对特征进行重新加权,从而发现表格数据集中的 K 个特征之间的成对互动关系。当自注意力层处理每个特征时,它查看输入中的每一个其他特征的线索,并将这个特征的表示输出为所有特征的加权和。这个过程如图 3 所示。通过这种方式,我们可以将对所有时间和空间特征的理解烘托到当前正在处理的一个特征中,并将注意力集中在重要的特征上。与语言模型相比,由于特征的顺序并不重要,所以 DeepETA 不存在位置编码。
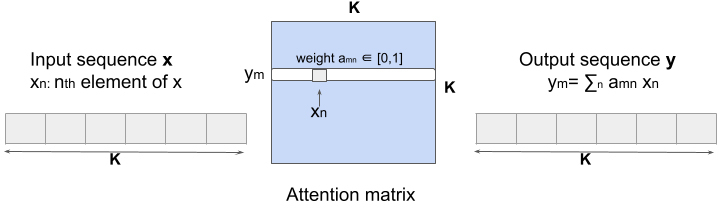
图 3:自注意力的注意力矩阵
以一次从出发地 A 到目的地 B 的行程为例,自注意力层根据一天中的时间、出发地和目的地、交通状况等因素来衡量特征的重要性。图 4 显示了自注意力的可视化(由 Tensor2Tensor 生成),8 种颜色对应于 8 个注意力头,所占份额对应于随机生成的注意力权重。

图 4:输入特征的成对点积的说明:颜色对应于注意力头,颜色份额对应于随机生成的注意力权重。
特征编码
连续和分类的特征
DeepETA 模型嵌入了所有的分类特征,并在嵌入之前对所有的连续特征进行了桶化。有点反直觉的是,连续特征的桶化导致了比直接使用连续特征更好的准确性。虽然桶化并不是严格必要的,因为神经网络可以学习任何非线性的不连续函数,但具有桶化特征的网络可能有一个优势,因为无需花费任何参数运算,就可以学会如何划分输入空间。就像梯度增强决策树神经网络的论文一样,我们发现使用分位桶比等宽桶具有更高的准确性。我们认为,分位桶之所以能够表现很好,是因为它们将熵最大化:对于任何固定数量的桶,分位桶传递的关于原始特征的信息都比任何其他的桶要多(以比特为单位)。
地理空间嵌入
后处理模型以纬度和经度的形式接收行程的起点和终点。因为这些起点和终点对于预测 ETA 非常重要,DeepETA 对它们的编码与其他连续特征不同。位置数据在全球范围内的分布非常不均匀,并且包含多种空间分辨率的信息。因此,我们将地点分位为基于经纬度的多个分辨率网格。随着分辨率的提高,不同网格单元的数量呈指数级增长,而每个网格单元的平均数据量则成比例减少。我们探索了三种不同的策略来将这些网格映射到嵌入中:
精确索引,它将每个网格单元映射到一个专门的嵌入。这占用了最多的空间。
特征哈希,它使用哈希函数将每个网格单元映射到一个紧凑的仓位范围。缓冲区的数量比精确索引要小得多。
多重特征哈希,通过使用独立的哈希函数将每个网格单元映射到多个紧凑的 bin 范围,从而扩展了特征哈希。见图 5:
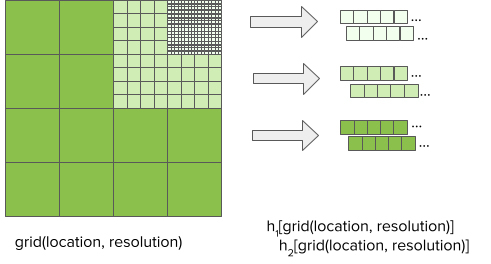
图 5:利用独立哈希函数 H1 和 H2 进行多要素哈希的多分辨率位置格网的图示
实验结果显示,尽管与精确索引相比,特征哈希节省了空间,但是由于网格的分辨率不同,其准确度也会有一定的差别。这可能是因为哈希碰撞导致一些信息丢失。与精确索引相比,多特征哈希提供了最好的准确性和延迟,同时仍然节省了空间。这意味着网络能够结合来自多个独立哈希桶的信息,以消除单桶碰撞的负面影响。
我们是如何让它变得快速的
DeepETA 对服务延迟的要求十分苛刻。尽管可以利用专用的硬件或者经过训练的优化来加快推理速度,但在本节中,我们将会介绍如何帮助 DeepETA 最小化延迟的架构设计决策。
快速 Transformer
尽管基于 Transformer 的编码器可以达到最好的准确性,但是对于在线实时服务的延迟要求来说,它的速度还是太慢了。原始的自注意力模型具有二次复杂度,因为它从 K 个输入计算出 K 个注意矩阵。已经有多个研究工作将自注意力计算线性化,例如线性 Transformer、Linformer、Performer。通过实验,我们选择了线性 Transformer,它使用内核技巧来避免计算注意力矩阵。
为了说明时间复杂度,我们用下面的例子来说明:假设我们有 K 个维度为 d 的输入,原始 Transformer 的时间复杂度为 :
$$O(K^2d)$$
而线性 Transformer 的时间复杂度为
$$O(Kd^2)$$
如果我们有 40 个特征都有 8 个维度,即
$$K=40,d=8,K2d=12800$$
而
$$Kd^2=2560$$
很明显,只要 :
$$K>d$$
线性 Transformer 就会更快。
更多的嵌入,更少的层数
另外一个让 DeepETA 迅速发展的秘诀就是利用特征稀疏性。尽管该模型包含数以亿计的参数,但任何一个预测都只触及其中很小的一部分,大约是 0.25%。我们是如何做到这一点的呢?
首先,模型本身是比较浅的,只有少数几层。绝大多数的参数都存在于嵌入的查找表中。通过将输入离散化并将其映射到嵌入,我们避免了对未使用的嵌入表参数进行评估。
相对于其他实现方式,输入的离散化给我们带来了明显的速度优势。以图 5 中的地理空间嵌入为例。为了将经度和纬度映射到嵌入,DeepETA 简单地将坐标进行分位并执行哈希查询,这需要
$$O(1)$$
的时间。相比之下,在树状数据结构中存储嵌入需要
$$O(log N)$$
的查找时间,而使用全连接的层来学习相同的映射需要
$$O(N^2)$$
的查找时间。从这个角度看,离散化和嵌入输入只是计算机科学中经典的空间与时间权衡的一个实例:通过以训练中学习的大型嵌入表的形式对部分答案进行预计算,从而减少了服务时间所需的计算量。
我们是如何做到通用的
DeepETA 的设计目标之一是提供一个通用的 ETA 模型,为 Uber 在全球的所有业务线服务。由于不同业务线的需求和数据分布情况不同,因此这将成为一项具有挑战性的工作。整体模型结构如下图 6 所示。
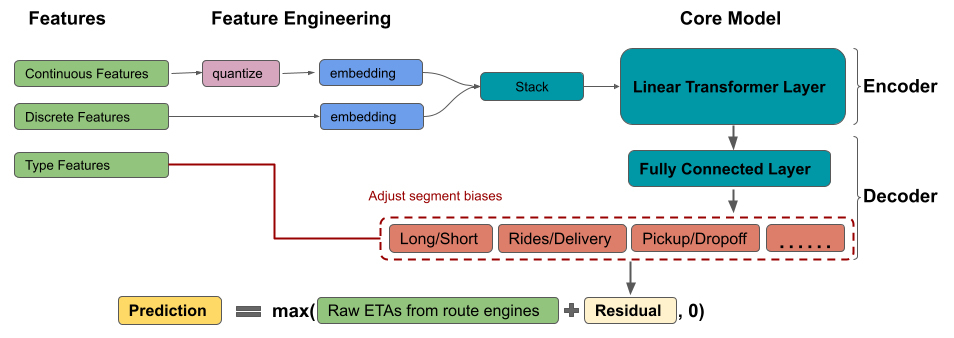
图 6:DeepETA 模型结构图解
偏置调整解码器
一旦我们学会了有意义的特征表征,下一步就是对它们进行解码并进行预测。在我们的案例中,解码器是一种全连接神经网络,它具有分段偏置调整层。绝对误差的分布在送货行程与乘车行程、长行程与短行程、上客行程与下客行程之间有很大的不同,在全球大区域之间也是如此。添加偏差调整层来调整每个不同细分市场的原始预测,可以考虑到它们的自然变化,反过来提高 MAE。这种方法比简单地在模型中添加分段特征表现得更好。我们之所以实施偏见调整层而非多任务解码器,是因为延时的限制。我们还运用了一些技巧,例如在输出端使用 ReLU 来强制预测 ETA 为正,并通过钳制来降低极端值的影响,从而进一步提高预测的准确性。
非对称 Huber 损失
不同的业务用例需要不同类型的 ETA 点估计,并且在其数据中也会有不同比例的离群值。例如,我们想估计一个用于计算票价的平均 ETA,但需要控制离群值的影响。其他用例可能需要 ETA 分布的特定分位数。为了适应这种多样性,DeepETA 使用了一个参数化的损失函数,即非对称的 Huber 损失,它对离群值具有健壮性,可以支持一系列常用的点估计。
非对称 Huber 损失有两个参数,delta 和 omega,分别控制对离群值的稳健程度和不对称程度。通过改变 delta(如图 7 所示),平方误差和绝对误差可以平滑地插值,后者对离群值不太敏感。通过改变 omega,你可以控制预测不足与预测过度的相对成本,这在晚一分钟比早一分钟更糟糕的情况下很有用。这些参数不仅可以模仿其他常用的回归损失函数,而且还可以对模型产生的点估计进行调整,以满足不同的业务目标。
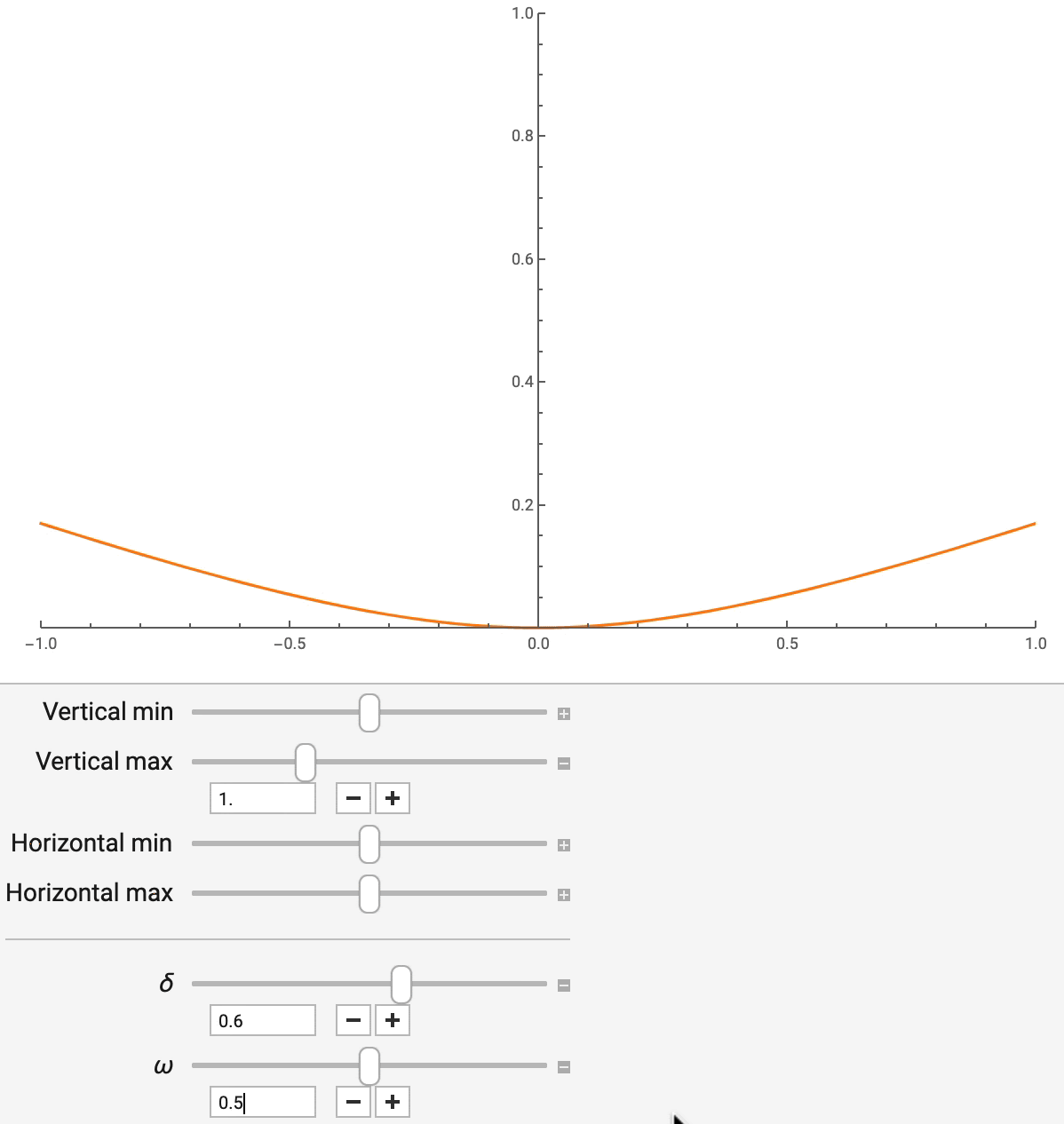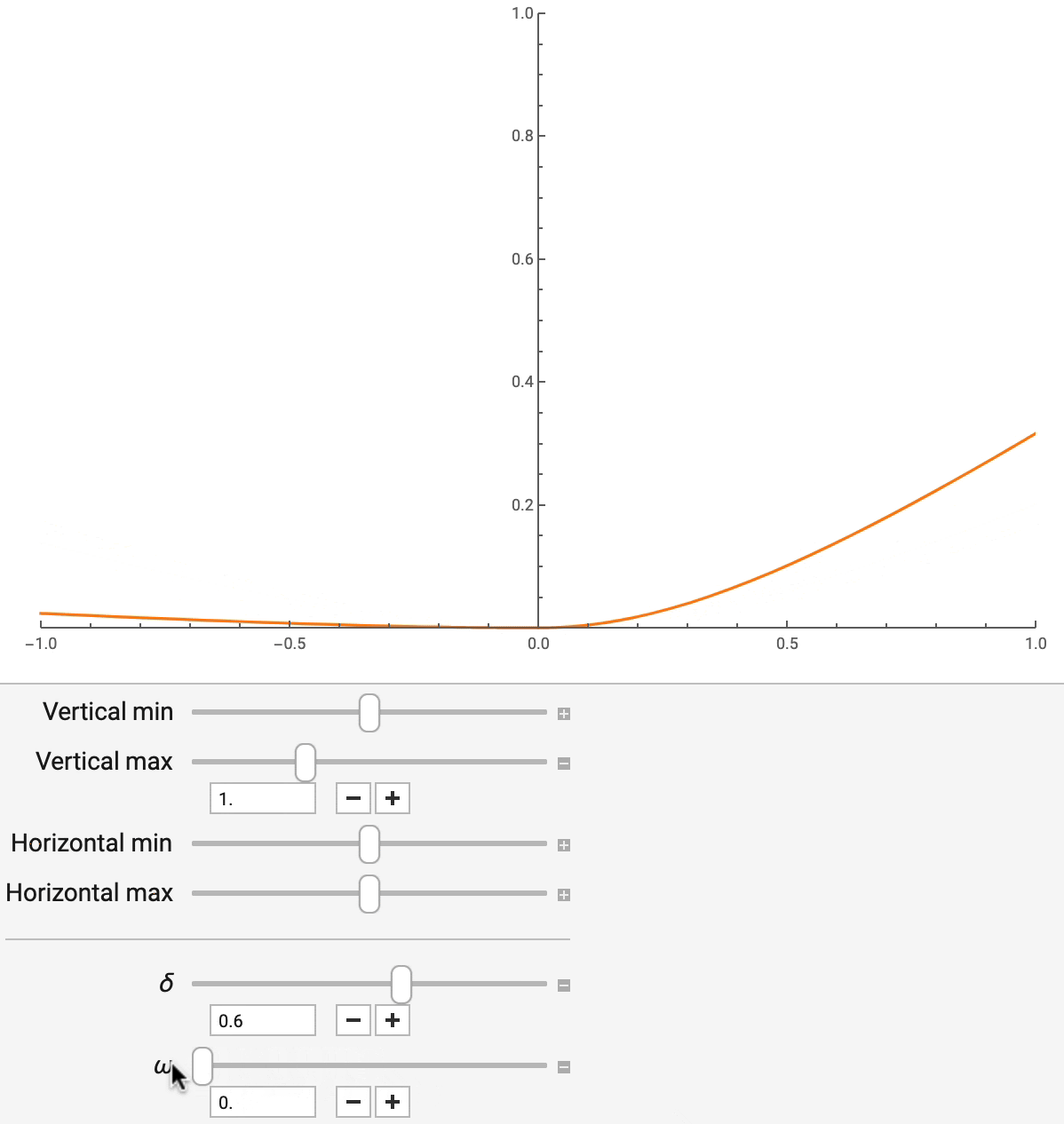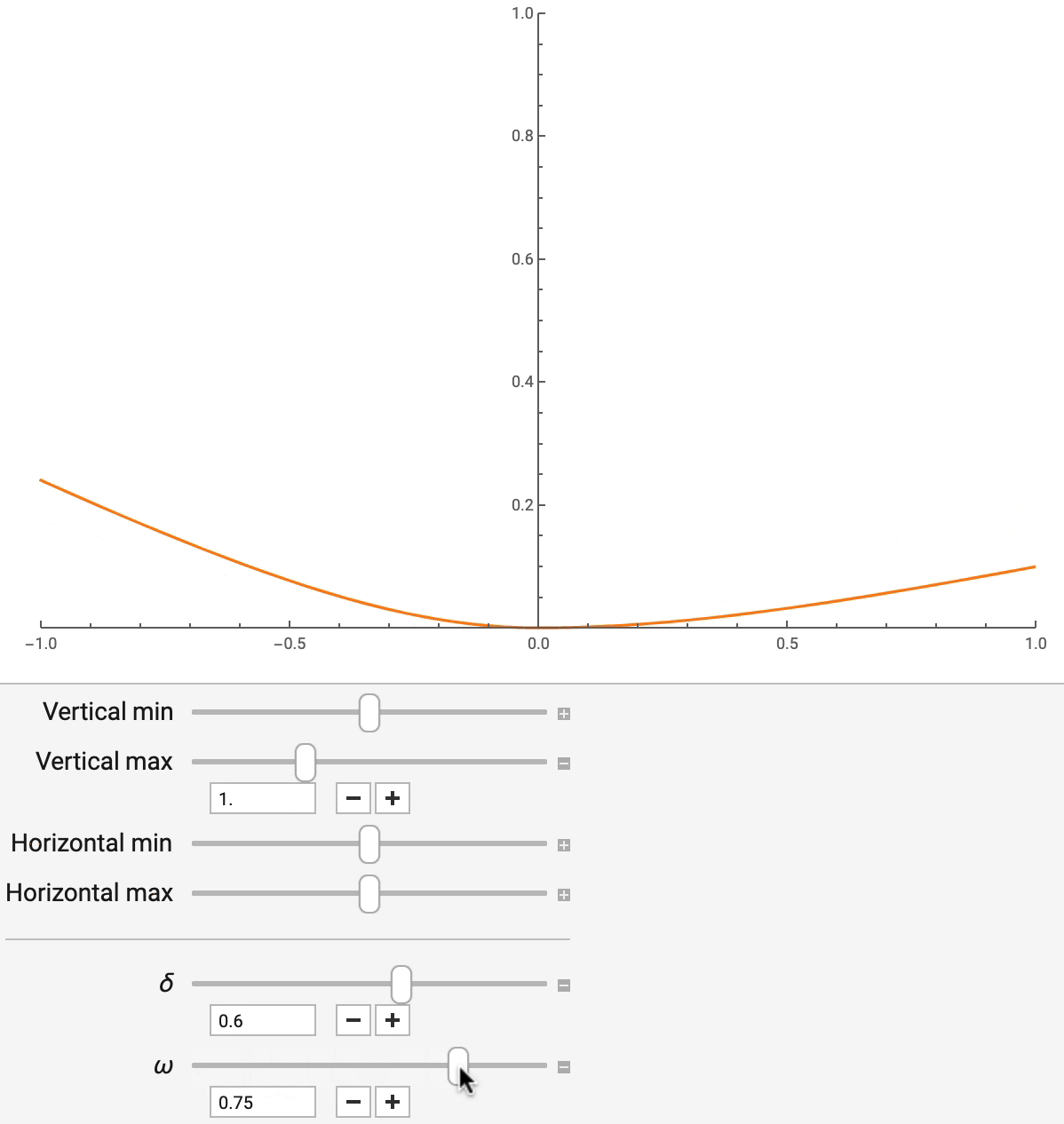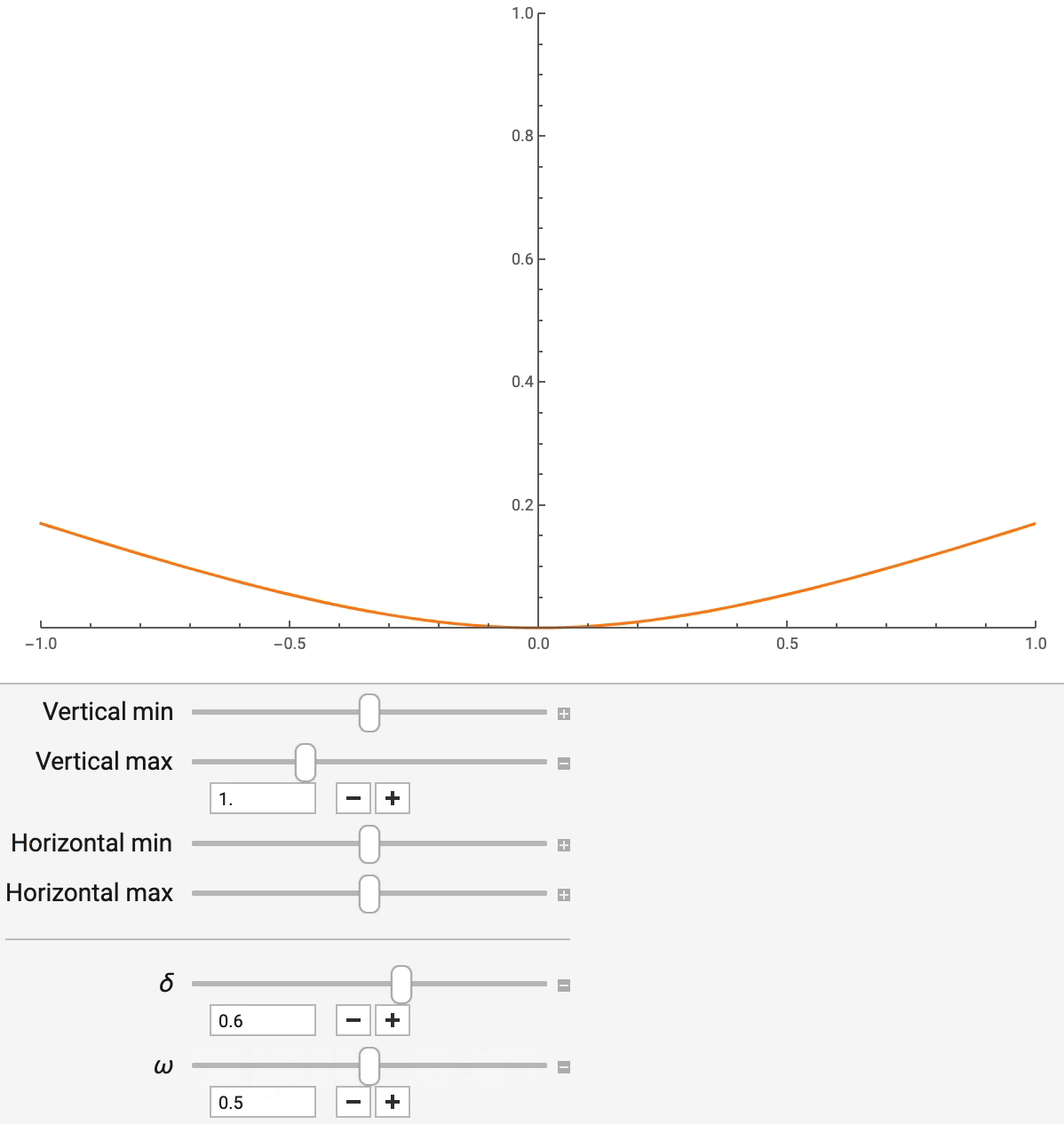
图 7:非对称 Huber 损失
我们如何训练和服务模型
我们使用了 Uber 的机器学习平台的 Canvas 框架,即 Michelangelo,对模型进行了训练和部署。我们的原型的具体架构基本在图 8 中描述。在模型经过训练并部署到 Michelangelo 之后,我们就需要将这些预测结果提供给用户,以便进行实时 ETA 预测。高级架构如下图 9 所示。Uber 消费者的请求通过各种服务被路由到 uRoute 服务。uRoute 服务作为所有路由查询的前端。它向路由引擎提出请求,以产生路由线和 ETA。它使用这个 ETA 和其他模型特征向 Michelangelo 在线预测服务提出请求,以获得来自 DeepETA 模型的预测结果。定期的自动再训练工作流程被设置为再训练和验证模型。
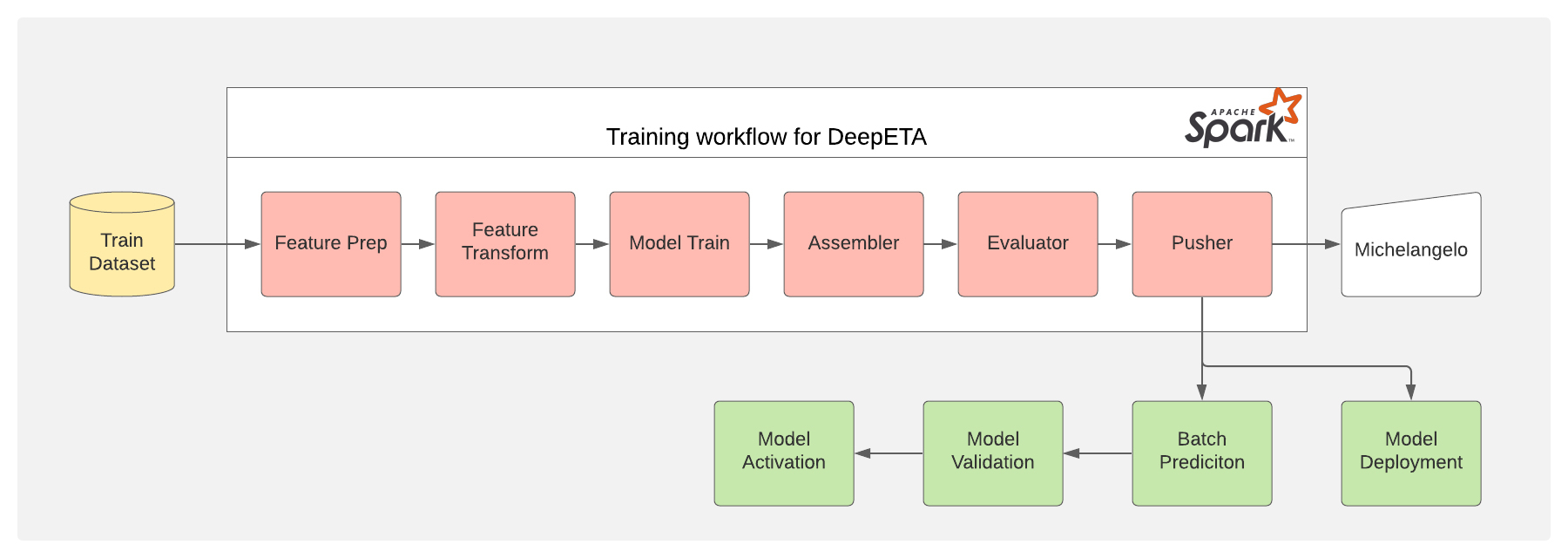
图 8:模型再训练和部署管道
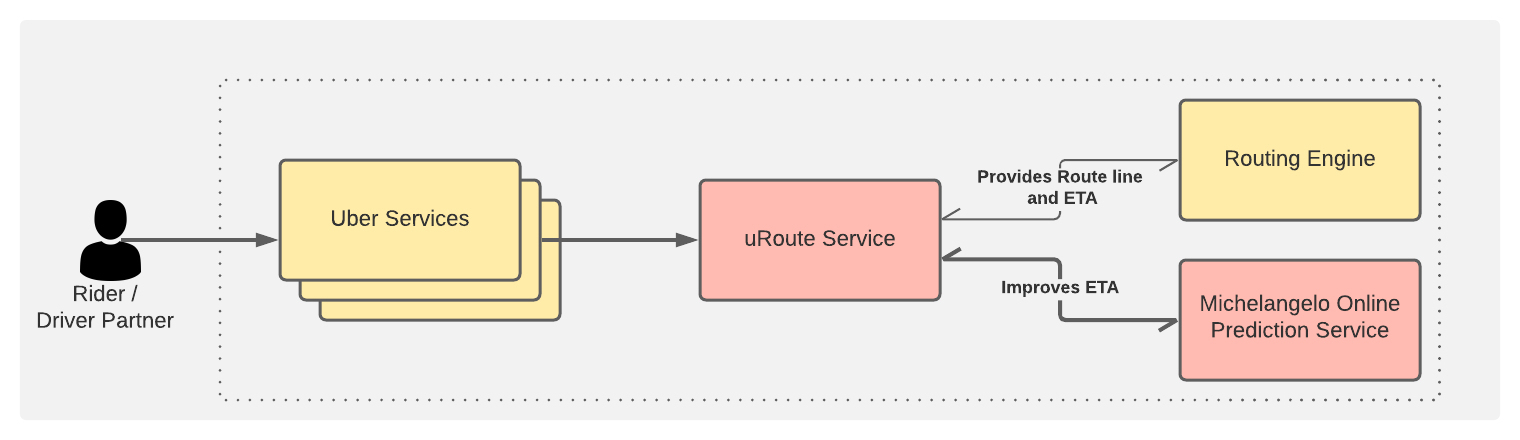
图 9:在线服务的高级系统图
总结与展望
我们已经将这个 DeepETA 模型投入生产,用于全球汽车 ETA 预测。DeepETA 模型的推出使训练和服务大规模的深度学习模型成为可能,而且效率很高,这些模型对 ETA 的预测比 XGBoost 方法更好。DeepETA 为生产中的指标提供了直接的改善,并建立了一个可以重复使用的模型基础,用于多个消费者用例。
DeepETA 使 ETA 团队能够探索不同的模型架构,并输出多种 ETA,为每个消费者量身定做。更多的工作进行中,通过研究建模过程的各个方面,包括数据集、特征、转换、模型架构、训练算法、损失函数和工具/基础设施的改进,进一步扩大它所能提供的准确性。在未来,该团队将探索增强功能,如连续的、增量的训练,这样 ETA 就可以利用更新鲜的数据进行训练。
作者介绍:
Xinyu Hu,Uber AI 的高级研究员,专注于大规模机器学习在时空问题和因果推理方面的应用。拥有哥伦比亚大学生物统计学博士学位。
Olcay ciri,Uber AI 的研究员,主要研究机器学习系统和大规模的深度学习问题。曾在谷歌从事广告定位工作。
Tanmay Binaykiya,地图 ETA 预测团队的高级软件工程师,专注于机器学习和系统交叉的项目。
Ramit Hora,Uber AI & Maps 的技术项目管理主管,致力于推动 Uber 技术系统和产品体验的创新。
原文链接:
https://eng.uber.com/deepeta-how-uber-predicts-arrival-times/




