
在《网易数帆基于 DPDK 的高性能四层负载均衡实践》一文中,我们介绍了网易数帆四层负载均衡对 DPVS 项目在云化网络场景设计和资源隔离等各方面增强的深层思考,本文再通过网易数帆在 DPVS 项目上所进行的大量功能开发和优化实践,讲述网易数帆在负载均衡的高性能和监控运维增强方面,如何实现我们的负载均衡组件的改造和优化。
对于负载均衡组件来说,DPVS 这套基于 DPDK 加速的方案,其远超依赖 Linux 内核的软件(如 HAProxy,LVS)的高性能,相比于纯硬件(如 F5)的性价比和灵活性,相比于通用组件(如 OVS)的专业性,都是网易数帆将其作为基础进行改造实现与自身云计算业务匹配的高性能解决方案的充分理由。我们基于此实现了单台极限性能千万级并发、百万级新建连接的高性能负载均衡组件,大大减少了负载均衡的设备资源消耗,增强了系统稳定性。
高性能四层负载均衡的改造优化
首先具体讲述一下我们对 DPVS 方案的改造之路:
从功能上讲,DPVS 提供了大多数的四层负载均衡所需要的功能,其继承于 LVS 的负载均衡框架也使其稳定性有较好的保障。但对于云化场景来说,它还缺少了云化网络 tunnel(vxlan)的封装 / 解封装,VIP 级别的 QoS 服务,6to4 快速转发路径的支持,更多防护和资源配置优化,以及很多监控运维手段的丰富。
从架构上讲,master 核上承载了控制命令下发处理和 kni 通道两大功能,kni 通道有 BGP 流量,和健康检查流量,命令下发和 kni 通道两者形成了强烈的性能和稳定性制约,大大降低了系统的稳定性,所以分核处理两种事务才是更优的选择。而且健康检查方案我们使用了自研的健康检查程序,通过 kni 通道后,与业务流量走过的路径相同的解决方案,最大限度地保证健康检查的准确性。
从性能上讲,DPVS 上下行同核的独立的流量无锁化模型,其性能已经在 bps、pps、新建连接能力、并发能力各方面都有很突出的表现,但是其原有 tunnel 路径有点长且重复,全局 rte flow 规则相比 FDIR 更方便且功能更多,新建连接能力方面也仍有进一步优化提升的空间,并且内存占用方面也有相当大的优化空间,并且 qos 模块的性能优化也花了不少功夫。
VIP 级别的 QoS 服务
DPVS 原生的 QoS 是一个独立的模块,和 ipvs 负载均衡的功能没有任何联系,需要单独配置报文匹配规则(qos classify)、带宽限速参数和算法(qos sched)。这倒还不是问题的关键,问题的关键在于 DPVS 原生 QoS cls 在数据面进行保文规则匹配时,效率非常低下:它是一条一条规则进行顺序比较,直到完全匹配到规则,就用匹配规则里设置的对应配置对报文进行 QoS schedule 操作。而且由于匹配效率低下,也设置了最大 reclassify 的值,进行 8 次比较还没完全匹配上的话,就直接 drop 这个包了。所以对于新四层负载均衡的 vip 级别的限速需求,由于匹配规则条目非常多,规则匹配效率很低下,非常影响性能,是不能满足 vip 级别的众多 VIP 时的限速需求的。
所以需要自己重新开发了一套适合网易数帆云计算业务的 VIP 级的 QoS 服务,提供:
VIP 级别的 inbound、outbond 两个方向的 bps 限速;
VIP 级别的 inbound、outbond 两个方向的 pps 限速;
VIP 级别的新建连接限速;
VIP 级别的最大并发连接数限制;
所以这套 VIP QoS 服务是嵌入进 ipvs 负载均衡处理流程的,每种限速都独立,支持 3000 个量级的 VIP 的各类限速,并且设计了一套配置命令,以及 vip 级别的各种统计。
VIP 级别 QoS 服务开发中的最大难点就在于 QoS 多核处理。如果是单纯的单核 qos 限速,其实普通令牌桶限速算法就已经足够。但由于 VIP 级别 QoS 的每个 VIP 中的各连接流量是在多核上同时运行的,所有业务流量的每个包都进行限速操作,对令牌桶操作的 cache 一致性或者加锁都将严重消耗 cpu 性能,多核大流量下性能惨不忍睹。
基于以上令牌桶算法的缺点,因此又开发了增量限速算法,此算法比较简单粗暴,但破除了令牌桶的多核限制,使其性能损耗大大降低,达到了业务的需求。但是此算法精确度差得有点多,并且其原理决定了要丢包时就会一个时间计算间隔的后段集中丢包,对业务连接的损伤比较大,所以使用一段时间后效果也不是很好,只能达到勉强可用的程度。
基于以上增量限速算法的缺点,因此最终开发了带 cache 的令牌桶限速算法,稍微牺牲了一点点精确度,但是带来了性能损耗的大幅降低,且比增量限速算法还是精确度高不少,同时其原理的实时计算决定了对业务丢包的友好,不会存在一个时间计算间隔的后段集中丢包的缺点,终于解决了 VIP 级别 QoS 服务多核处理的难题。
健康检查通道
网易数帆的健康检查方案是通过依赖内核运行的专用健康检查程序发出的报文通过 kni 通道到数据面,走完负载均衡的全流程,进行 vxlan tunnel 的封装,从下联口发往后端,回来时也是走完负载均衡全流程后,由上联口的 kni 通道发往内核的健康检查程序。这样,同一个健康检查程序既可以用于云化网络,也可以用于经典网络,内核态的健康检查程序无需任何改动即可做到,无需在内核态进行后端网络的封装,全由数据面本身的处理来进行。
这方案使其健康检查流量经过了业务从入口到后端的相同的负载均衡逻辑,这样的健康检查才是最能反映真实的业务实际走向的连通性,且配置方式与实际业务差不多,甚至在云化网络和经典网络混部下,也仍旧可使用同一个健康检查程序,灵活又统一管理。
重要流量及控制下发的核分离的框架改造
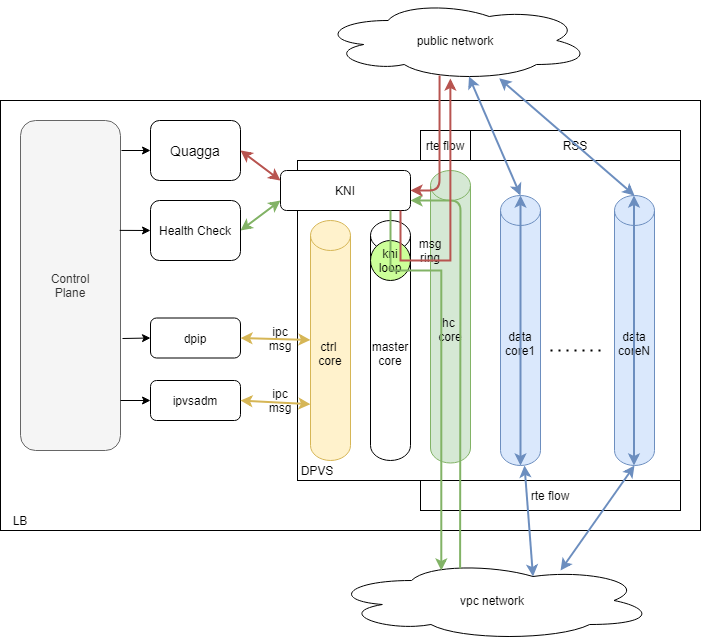
DPVS 的 master 核的处理了两部分功能:控制命令下发处理、kni 通道与内核态程序联系。网易数帆负载均衡组件的内核态程序有两个需要经过 kni 通道由传统 linux 程序处理:Quagga 程序的 BGP 流量,健康检查程序的流量。BGP 流量关系着 VIP 发布,健康检查流量关系着后端的存活,这两种流量都是极其重要的流量,既不能被业务流量影响,也不能被控制命令下发处理影响。
DPVS 原来的 kni 通道性能非常差,差到几千个后端的健康检查流量都支撑不了。究其原因,其实是由于控制命令下发处理的 socket 机制很大地影响了 kni 通道的性能和稳定性。Ipvsadm 这套继承于 LVS 的配置方式很符合用户习惯,但基于 ipc msg 机制而不是 rte_ring 的方式传递信息还是对性能有较大影响,不过配置命令对性能要求不高,所以也没关系,但对 kni 通道的性能下降太大还是对健康检查流量和 BGP 流量产生了影响,所以分核处理势在必行。
所以在原来架构的基础上增加了控制下发核这个专用核,专门用于处理命令下发处理;而 master 核则用于处理 kni 通道的流量转发。这样就做到了控制下发与数据流量的完全隔离。并且将重要的 BGP/OSPF 流量和健康检查流量指定到特定的单独核来处理,做到两种重要流量既与控制下发处理隔离,也与业务流量隔离,在业务流量达到性能极限的情况下也能保证 BGP/OSPF 流量和健康检查流量不断流不抖动,控制下发处理核独立进行无干扰,稳定安全,大大增强了系统稳定性。
rte flow 在每核独立处理负载均衡中的应用
而 rte flow 就方便很多,全局的规则,在系统启动时就可以设置好,而且灵活。在 fnat 模式下,本地地址池按核数使各核的端口资源固定,回流通过 rte flow 规则按端口号分发到正向报文所在的同一处理核上;在 dnat 模式下,通过对 vxlan 内层 mac 地址中赋予 cpu 号,后端的 ovs 对 mac 地址记录,回包中内层 mac 地址的 cpu 号就可以通过 rte flow 规则分发到与正向报文所在的同一处理核上。
并且 rte flow 还能对外网口的 bgp 和 ospf 流量指定特定核所对应的队列,并对外网业务流量的 rss hash 进行限制,使业务流量不流向 bgp 或 ospf 流量所在核的队列,从而使 bgp 或 ospf 流量运行在无业务流量的特定核上。
云化网络数据路径优化和资源分配优化
对 Tunnel 的封装解封装,我们遵循的是越简单迅速,对性能影响越小,对用户配置越友好越好的原则。很多开源项目和商业软件都会把 tunnel 接口创建出来,报文路由到这接口来封装解封装 tunnel,这样流程长既浪费性能又繁琐,后端级别的 vxlan tunnel 数量很多,用户配置和查看也蛮麻烦。所以我们将 vxlan tunnel 信息与后端信息强绑定,在配置后端时一起配置 vxlan tunnel,无 tunnel 接口创建删除流程,天然绑定后端,无需路由到 tunnel 接口,既减少了处理流程,提高了性能,又大大方便了用户配置和维护。
FNAT 模式下的本地地址和端口资源的分配在原生版本上其实也是个比较繁琐的流程,使用额外的独立配置,又有资源浪费的问题,而且也有锁的问题影响性能。所以我们对这方面也做了很多优化工作,不需要再对各个监听配置单独又无法共用的地址池,通过结构和流程的改变简化了配置流程,充分利用资源,方便高效,使用户无需关心如何分配资源,也就不会误操作,并且也不因为这些配置操作的锁而影响性能,并消除用户之间的影响。既方便了用户使用,充分利用资源,也增强了新建连接性能。并且每个核独立的端口资源在内存消耗上,也还有很大优化空间,优化后大大节省了不必要的内存资源开销。
性能表现
经过上述深度改造,以及一些重要细节上的优化,使得四层负载均衡的性能得到了更进一步的提升,同时增强了系统稳定性。改造和优化之后,网易数帆高性能负载均衡单台性能如下:
性能测试环境:
网关内外网网卡类型:MLXCx425G bond mode4
网关 CPU 类型:Intel(R) Xeon(R) CPU E5-2670 v3
单台性能测试结果:

丰富的监控运维功能
一个稳定的系统,不仅需要功能强大、性能卓越,也需要在监控运维方面提供丰富的手段,使问题排查和日常监控能更方便地进行。我们不仅在功能、架构、性能方面对基于 DPVS 的高性能四层负载均衡进行了大量的开发和优化,在监控运维功能方面也花了很多功夫进行了大量的增强。
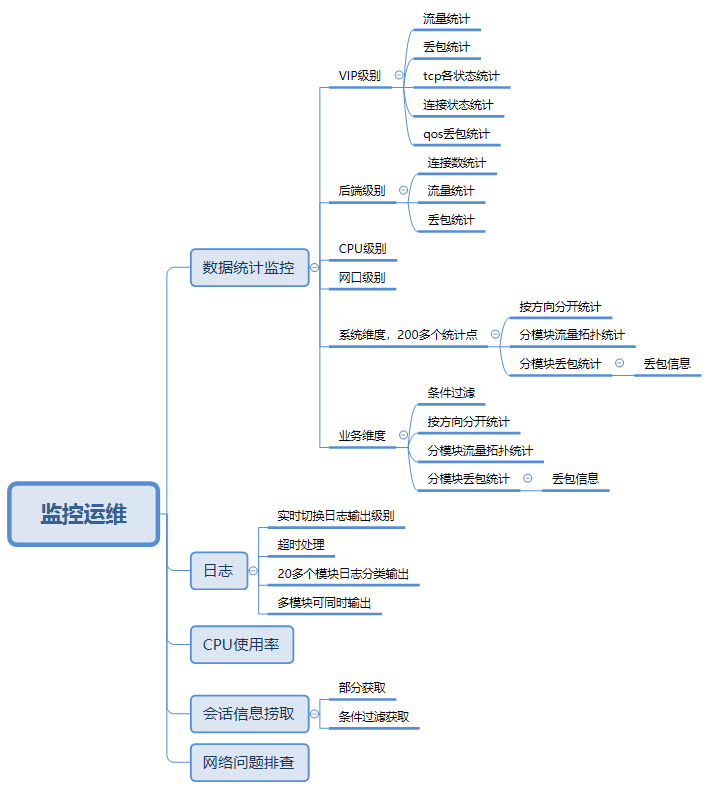
监控运维的手段包括各个维度的数据统计、分级分模块的日志、CPU 使用率、会话信息捞取、网络问题排查等。
1)监控数据统计的维度包括:VIP 级别的各类统计、后端级别的各类统计、cpu 级别的各类统计、系统整体维度的各类统计、带条件过滤的业务维度的各类统计。各类统计都包括流量统计和丢包统计,并且按 port 或方向分开统计,使上下行分开统计,清晰明了。而丢包统计中还包含了最新丢包的具体信息。
系统维度的统计点新增多达 200 多个,并按十几个模块进行划分,大大丰富了监控运维信息,使监控和排查变得方便很多。并且还可以针对某个用户的流量进行条件过滤的业务维度统计,更精确地锁定监控对象,进行更精细地排查和监控。
VIP 级别统计是新增的一个维度的统计,对流量和丢包,以及 QoS 的流量和丢包,连接状态,和 tcp 的各个状态都有统计;后端级别也增加了包括连接数和部分丢包统计在内的统计。
2)日志系统进行了多方面的信息梳理,调整日志级别,安全打印有用的信息。并且日志系统现在做到可以实时切换日志级别,方便出问题时暂时调到低级别的日志打印出有用的信息方便排查,并且有超时机制防止误操作;划分了二十几个模块,并可以按模块单个或多个模块同时输出,方便精细地调查某个或几个模块的错误。
3)对 CPU 使用率的监控,其实基于 DPDK 技术的用户态高性能项目,都是需要做些改动才能得到的。其实就是空转率在整个 loop 次数中的占比来决定的,并且各个不同包的处理流程也不一样,消耗的 ticks 也不一样,所以不能单纯地只算次数,而是要计算 ticks。经过改造后,可以较为准确地获取当前系统的 cpu 使用率,极限性能测试和监控告警时都很有用。
4)会话信息捞取可以按五元组自由设置条件,有条件地获取具体想要的会话信息。
5)并且我们还对因为网络问题,或 client,或后端导致业务不通的情况,在 DPVS 中开发了一些手段进行问题排查,能够做到确定是否非负载均衡节点问题导致,是哪方出问题导致。
总结
负载均衡作为流量关键入口,其性能和稳定性越来越成为各厂商的关注所在。通过在功能、架构、性能上各方面的改造和优化,在监控运维手段的大量增强,经过线上各个业务的考验,网易数帆基于开源的 DPVS 结合自身云计算架构,得到了广泛落地,取得了显著的成果。随着业务的不断增加和拓展,负载均衡组件将面临更多的考验,将对我们的性能和稳定性提出更高的要求。
作者简介
顾云,网易杭州研究院云计算资深系统开发工程师,14 年软件开发工作经验,长期从事系统底层、高性能网络数据面的开发优化,对基于 DPDK 的网络加速技术有很多年的耕耘,具有多年云计算开发、优化经验,在高性能网关、负载均衡、网络性能优化、云原生、服务网格、用户态协议栈等方面有较多实践经验。
张晓龙,网易技术委员会委员,网易数帆轻舟事业部技术总监,2012 年浙江大学博士毕业后加入网易杭州研究院,负责基础设施研发 / 运维至今。在虚拟化、网络、容器、大规模基础设施管理以及分布式系统等技术架构有多年经验,当前主要兴趣点在云原生技术方向。




