
背景
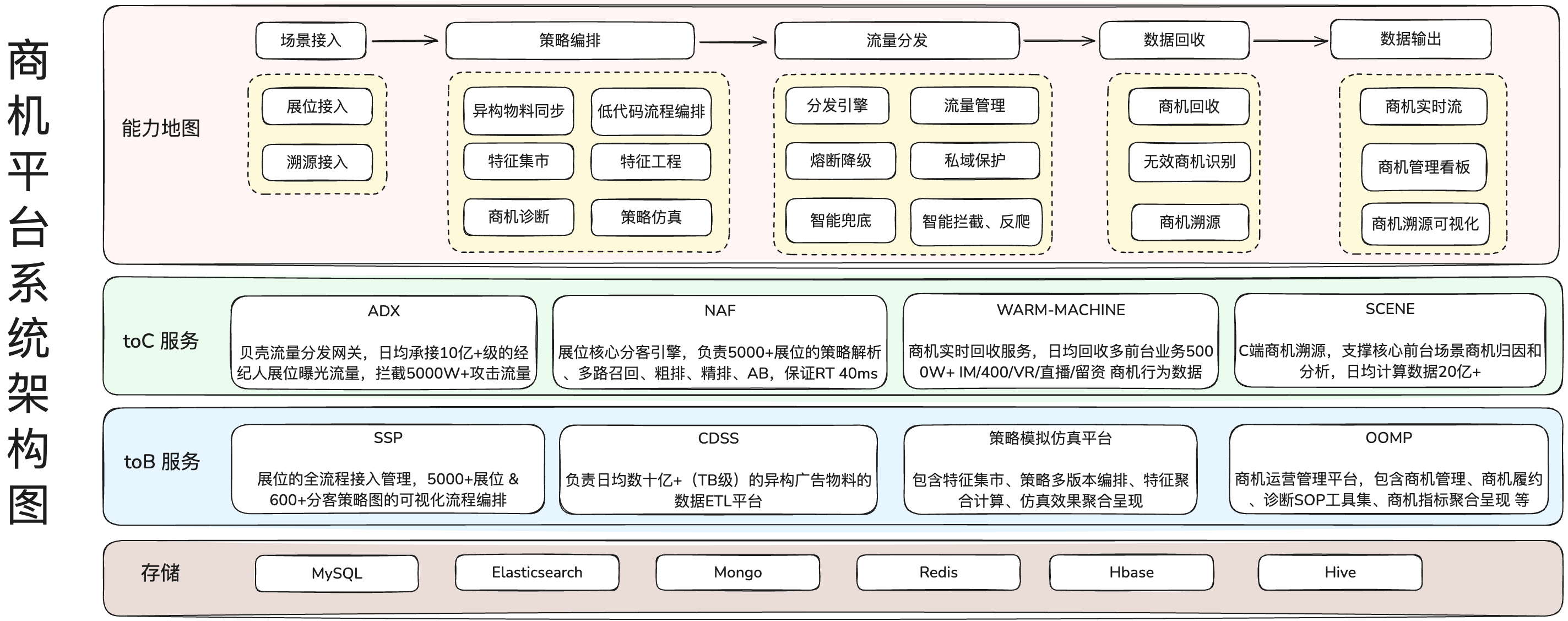
贝壳商机平台,为日均 15 亿+用户浏览流量提供 经纪人 &房源 &客户 的匹配,用户可通过 IM、400 通话、留资 等方式联系经纪人,并产生日均约百万左右的商机。商机作为平台的基础资源,每一次故障对公司来说都是一笔不小的损失。在该背景下,我们需要真正通过技术手段,来帮助每一位贝壳用户和经纪人获得最好的体验。
1.1 why 全链路压测?
ADX 与 NAF 两个服务作为 toC 服务链路中的"基石",直接面向 C 端用户流量提供经纪人推荐功能,假若发生故障,便是直接中断了客户和经纪人之间的连接,造成商机浪费和影响用户体验。因此,toC 服务全链路稳定性的重要程度不言而喻。
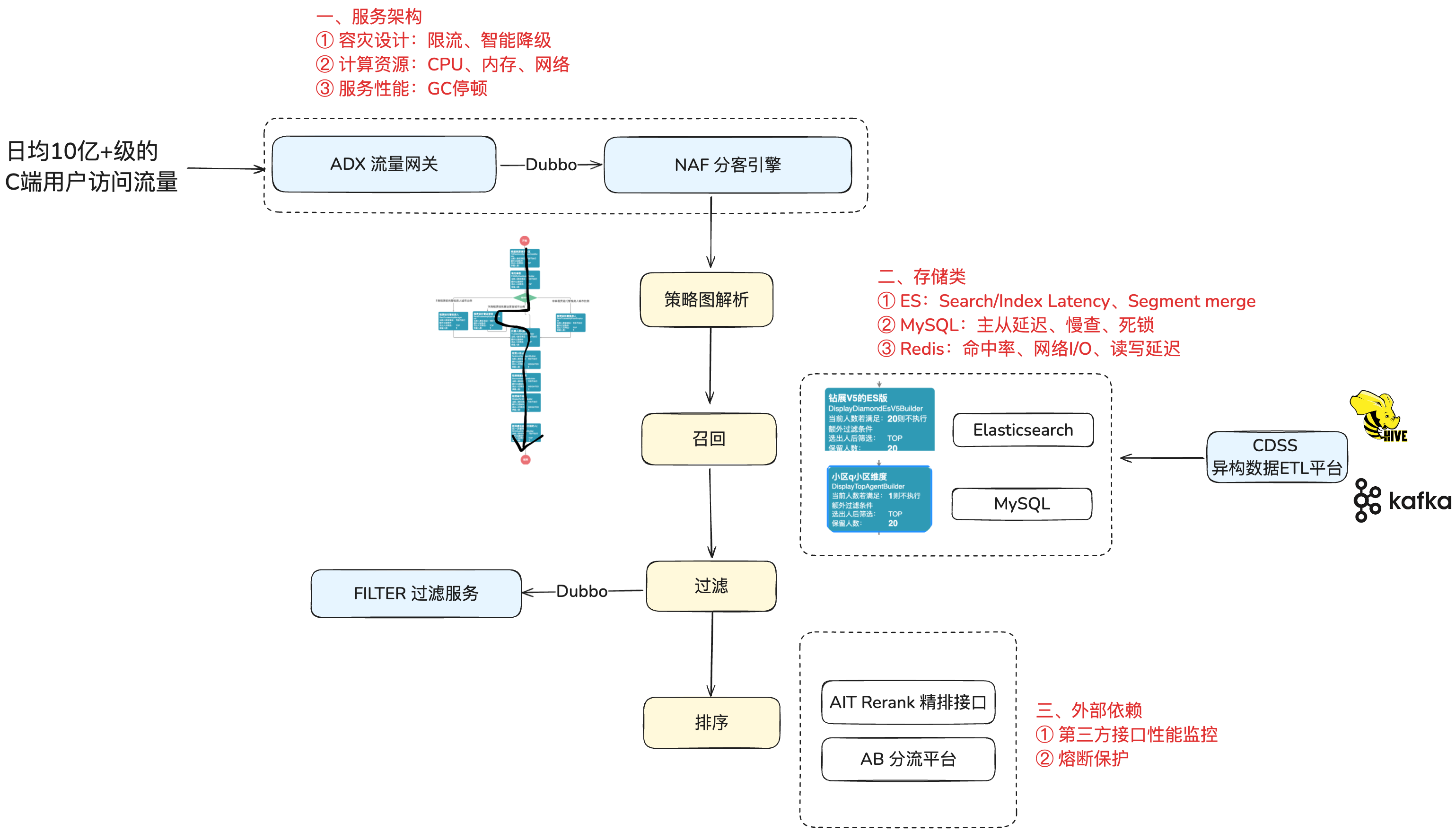
但是,toC 服务调用链路较长(涉及 10+服务),依赖的存储资源多(ES、MySQL、Mongo、Redis...)、存在许多第三方依赖(AIT 模型接口、AB 分流平台),如何确定系统全链路中的瓶颈点并做针对性优化呢?答案就是全链路压测,基于线上真实环境和实际业务场景,通过模拟海量的用户请求,帮助发现系统的"病根",比如:
1)服务架构
容灾设计是否需要完善?比如熔断限流、反爬、自动降级机制 等...
服务性能是否存在提升空间?比如存在内存泄露、CPU 过高、GC 停顿过长 等...
2)存储
MySQL 是否有瓶颈?慢查、死锁、连接池不够用 等...
ES 是否有瓶颈?慢查、分片倾斜、流量放大 等...
Redis 是否有瓶颈? 大 key、网卡负载过高 等...
3)外部依赖
下游接口是否有瓶颈?下游接口因扛不住流量而报错 等...
1.2 目标
经过本次全链路压测后,我们的预期目标是:
1)发现整体系统的性能瓶颈点
探查出各关键环节的瓶颈点、隐患点。
2)针对性的性能优化
降低 CPU、RT、9999 线指标,缩容降本。
3)可复用的测试方法,降低底层基础变更所带来的测试成本与系统变更风险
沉淀通用的、可验证的 case,加入到系统灰度上线对比阶段。
全链路压测方案设计
2.1 压测前置准备
a)场景设计
压测数据的构造,直接影响了压测结果的准确性。为了让压测结果更贴近真实情况,随机采样了近 1 天内随机 10w+线上真实流量请求,作为服务压测的请求数据。
b)压测流量染色
流量染色:加上压测流量标识,和线上流量区分开。
下游接口方改造:下游业务方在识别到是压测流量时,抛弃不处理。
自身服务改造:根据自身系统特性,采用影子表或 mock 数据避免写流量造成的数据污染。
C)压力设置
在目前流行的压测框架中,都会提供下列发压模式:
atOnceUsers: 同时注入指定数量的用户。
rampUsers(x).during(x): 指定的持续时间内均匀注入指定数量的用户。
constantUsersPerSec(x).during(t): 指定的持续时间内以恒定速率(每秒用户数)注入用户。
rampUsersPerSec(x).to(y).during(t): 在指定的持续时间内,从起始速率注入到目标速率(每秒用户数)。
结合自身系统流量特性,选择一种合适的发压模式来压测系统,以观测最真实的系统状态。
2.2 压测框架选型
目前,压测框架百花齐放,各有千秋。Galting、JMeter、Lucoust 作为比较火热的三种框架,在此我们做了一个简答的对比:
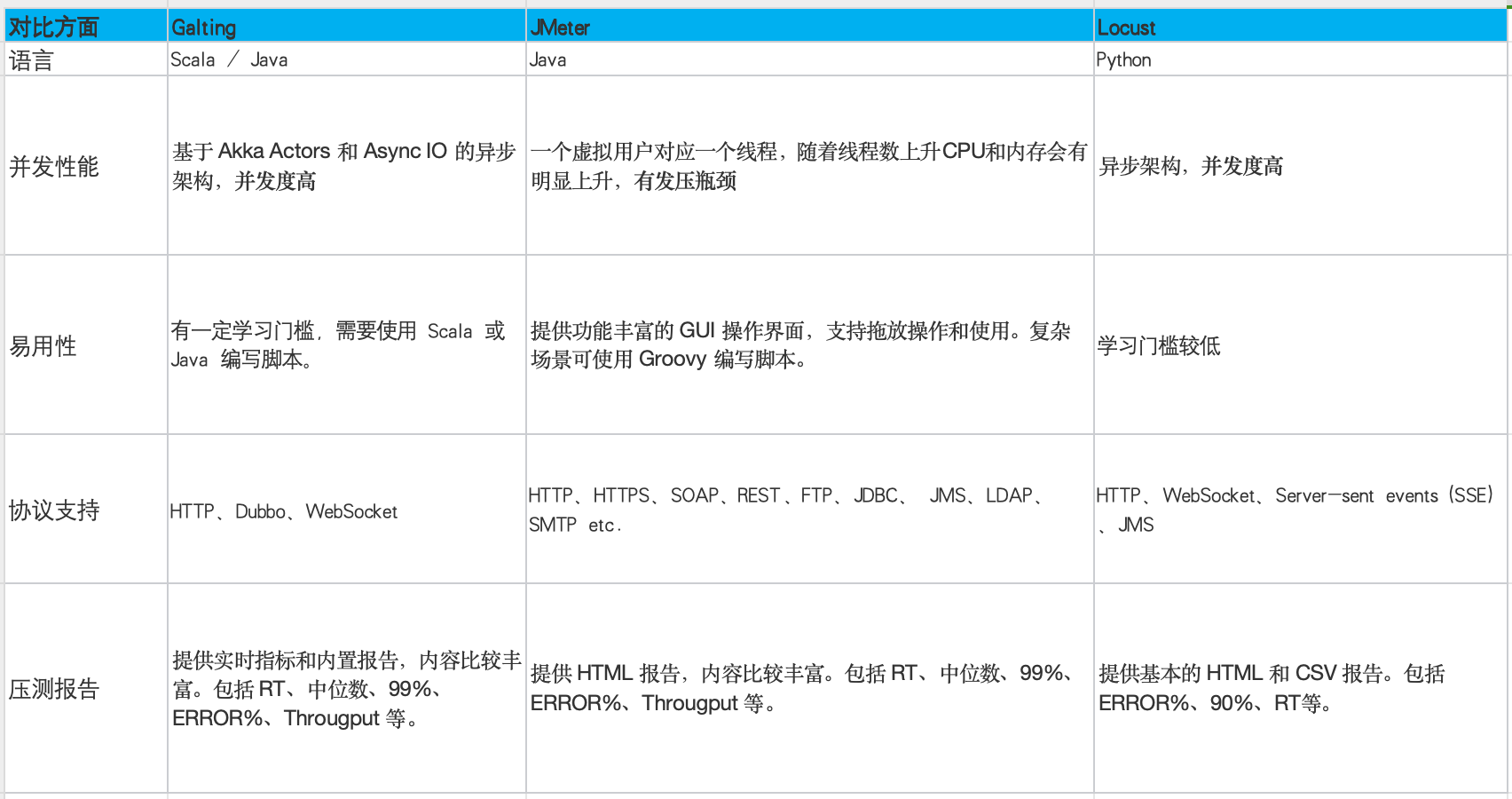
JMeter,因为其存在发压性能瓶颈,不适用于 toC 大流量高并发系统的压力测试,首先被淘汰。Locust,更适合于需要快速开始测试的小型项目场景,压测报告中,性能指标相对偏少,也未考虑。
Galting,能支持高并发度、且提供比较丰富的性能指标报告,显然更是适合流量分发系统的场景,因此最终选择了 Galitng。
2.3 单机压测和集群压测
在全链路压测中,单机压测和集群压测都很重要:
1)单机压测
目标:评估单机最大 QPS,识别单机性能瓶颈,比如 CPU、内存、磁盘和网络等。
2)集群压测
目标:评估系统 RT、吞吐量、9999%,有效识别系统全链路性能瓶颈,比如 上下游接口性能瓶颈、硬件、中间件(Redis、ES、MySQL、Mongo、Kafka、Hbase ...)。
2.4 全链路性能监控
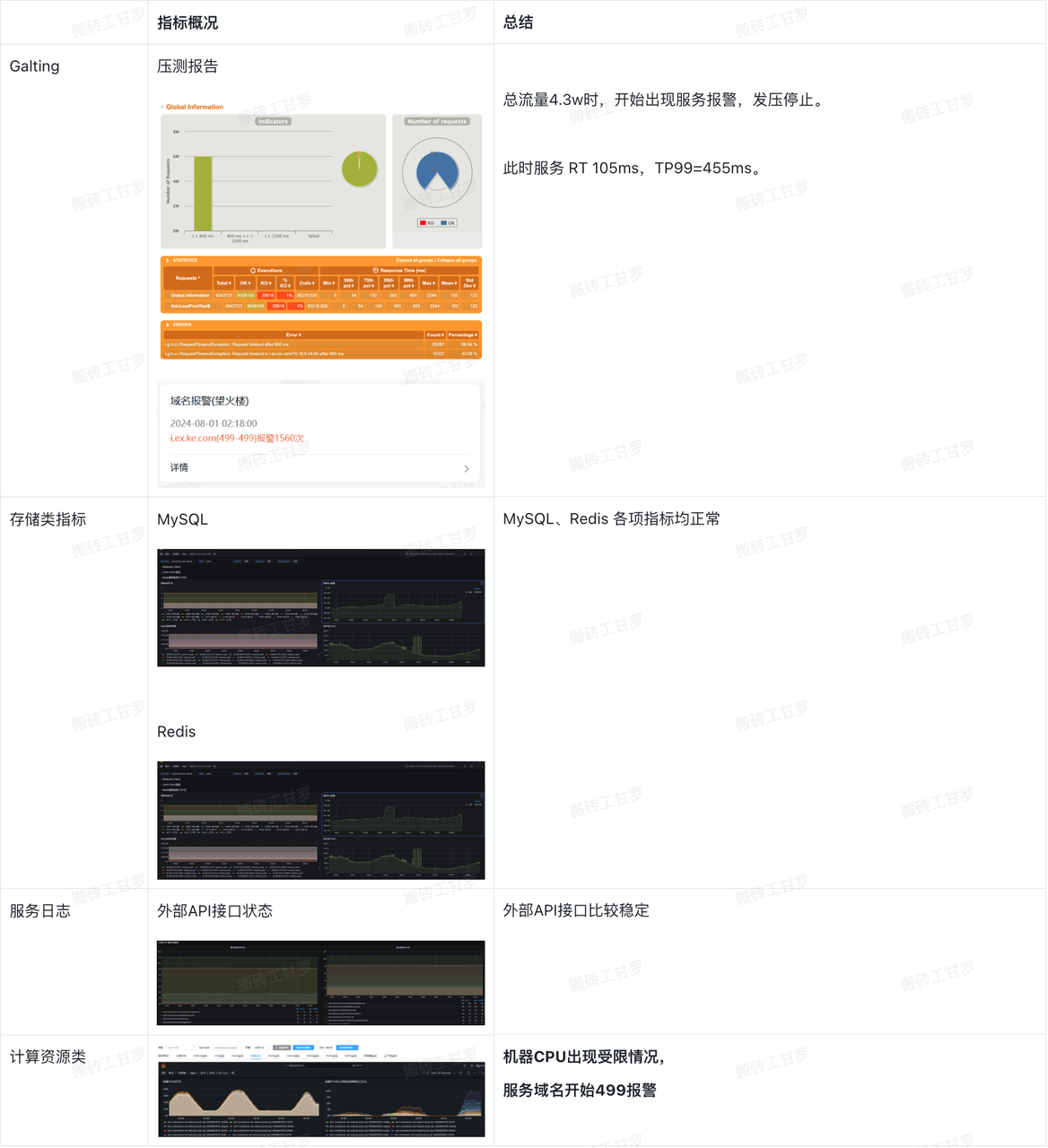
在压测过程中,我们需要密切关注系统全链路情况,防止系统超载而影响线上业务正常运行:

2.5 压测结果分析
流量分发系统瓶颈分析与解决方案
3.1 CPU
压测中,观察到 CPU 先负载打满, 分析重点放在 CPU 上
分析利器:火焰图
基于采样的性能分析,核心思想是通过定时采样的方式,记录 Java 虚拟机(JVM)线程的调用栈信息,并将这些调用栈数据处理后生成可视化的火焰图。这种方式可以低开销地分析 Java 应用的性能瓶颈。不仅支持 Java 层,还能分析 JVM 和原生方法的调用情况。
火焰图中的每个矩形块表示一个函数或方法调用。
横向的宽度表示该方法在所有采样事件中所占的比例,也即消耗的 CPU 或内存等资源的占比。
纵向的堆叠关系表示调用链,越高的层级表示被其他方法调用。
不同颜色的块通常只是为了区分不同的函数或方法
(Java 方法 , JVM,本地方法)
优势:火焰图提供了一种直观的方式来展示程序的 性能热点,便于开发者快速定位 CPU 瓶颈
局限:基于采样,小的或者偶尔出现的问题无法发现 2. 展示的是累积数据,不能分析趋势/单次调用消耗 3. 不满足进一步的搜索聚合操作(可以自己抓取原始数据,解析聚合)
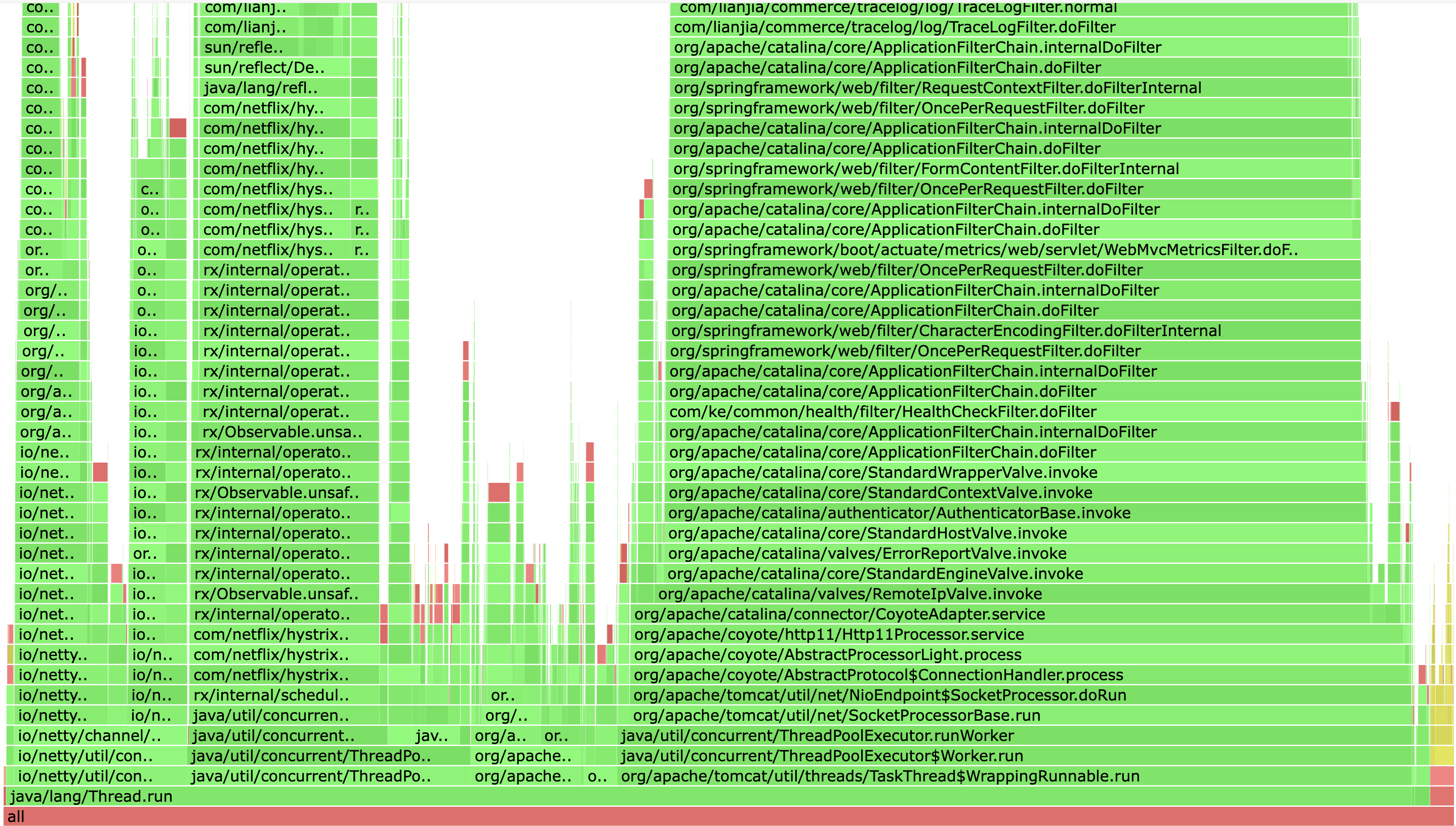
服务 CPU 消耗概览
以 adx 为例,CPU 消耗主要集中在以下几个方面:核心业务处理、熔断和切面消耗最高,占据 68%;线程调度和请求处理占 12.91%;Dubbo 和 IO 操作占 8.5%;垃圾回收(GC)消耗为 4.8%。
发现问题:
整体排查常见的 CPU 消耗(异常,GC)
遍历所有堆栈( DFS >0.1%), 记录应用耗时分布以及可以的耗时,用于进一步排查(需要对框架和业务了解)
CPU 问题分析
工程视角,综合考虑可维护性,ROI 决定最终的解决方案。

优化措施及效果
1)JDK 及 springBoot 版本升级
经过调查,得出结论,JDK 和 SpringBoot 的问题在官方后续版本已经得到了解决,而且版本跨度不大(8.232 -> 8.441, spring5.1 -> spring5.2),所以决定直接升级对应的版本解决。
JDK Issue:
https://bugs.openjdk.org/browse/JDK-8035424
https://github.com/spring-projects/spring-framework/commit/72119ac076f52bfe5ec0f9d66a966d582254db49
2)BeanCopy 改造
Jodd 依赖反射机制,性能较差。而 MapStruct 是编译是生成代码,在字节码编译期间生成 setter/getter 的代码,避免了反射带来的运行时开销,因此执行效率更高。它基于注解进行对象映射,结合命令式和声明式编程,简化了 Java Bean 的映射过程,不仅提升了性能,非常适合高效对象复制。
但是,Jodd 或 Spring 等 BeanCopy 框架并非没有优点,如果系统是不太在意链路延迟的 toB 系统,那 Jodd 等 BeanCopy 框架能明显的提升代码开发效率与代码整洁度。
各 BeanCopy 框架耗时比较:

改造方式:用 MapStruct 替换代码中 Jodd 与 Spring 包下的对象拷贝。
3.2 内存
在分析完 CPU 后,紧接着便是分析服务内存情况,于是对服务的线程、内存占用、大对象等方面进行分析:
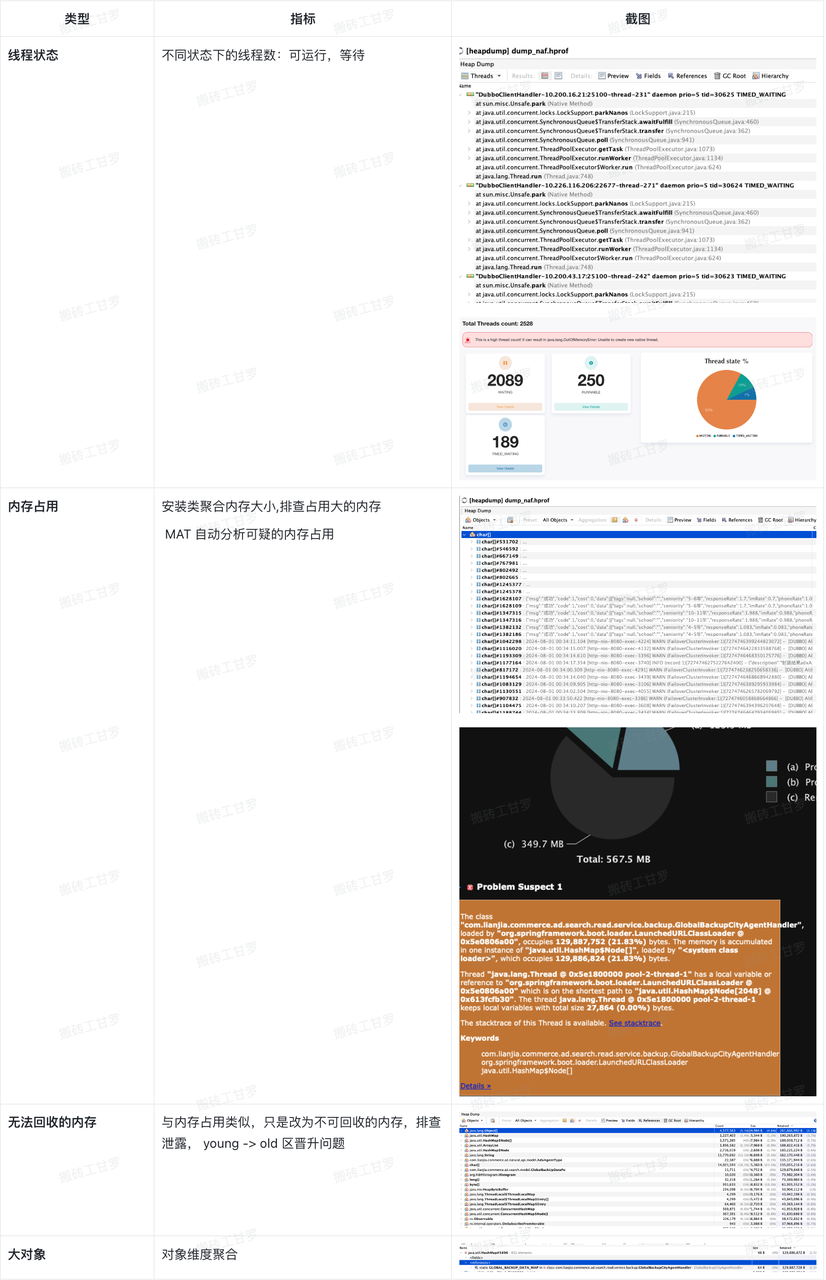
分析结论
1)线程
现象:单服务线程数 2500+,其中 2k 的线程在线程中等待。这部分线程主要是 dubbo 和 hystrix 核心线程(只要线程数小于核心线程数每提交一个任务,都会创建新线程,不管其他核心线程是否空闲)。存在线程过多问题,会有额外的内存开销和少量 CPU 开销。
优化措施:设置日常够用的核心线程数减少额外开销,设置足够的最大线程数应对突发流量。但是量级较少,优先级较低,且不是影响链路本期暂未不处理。
2)内存
未发现异常数据。(其中有大对象占用 100M,排查为 ADX 服务正常业务兜底数据)
3.3 JVM GC
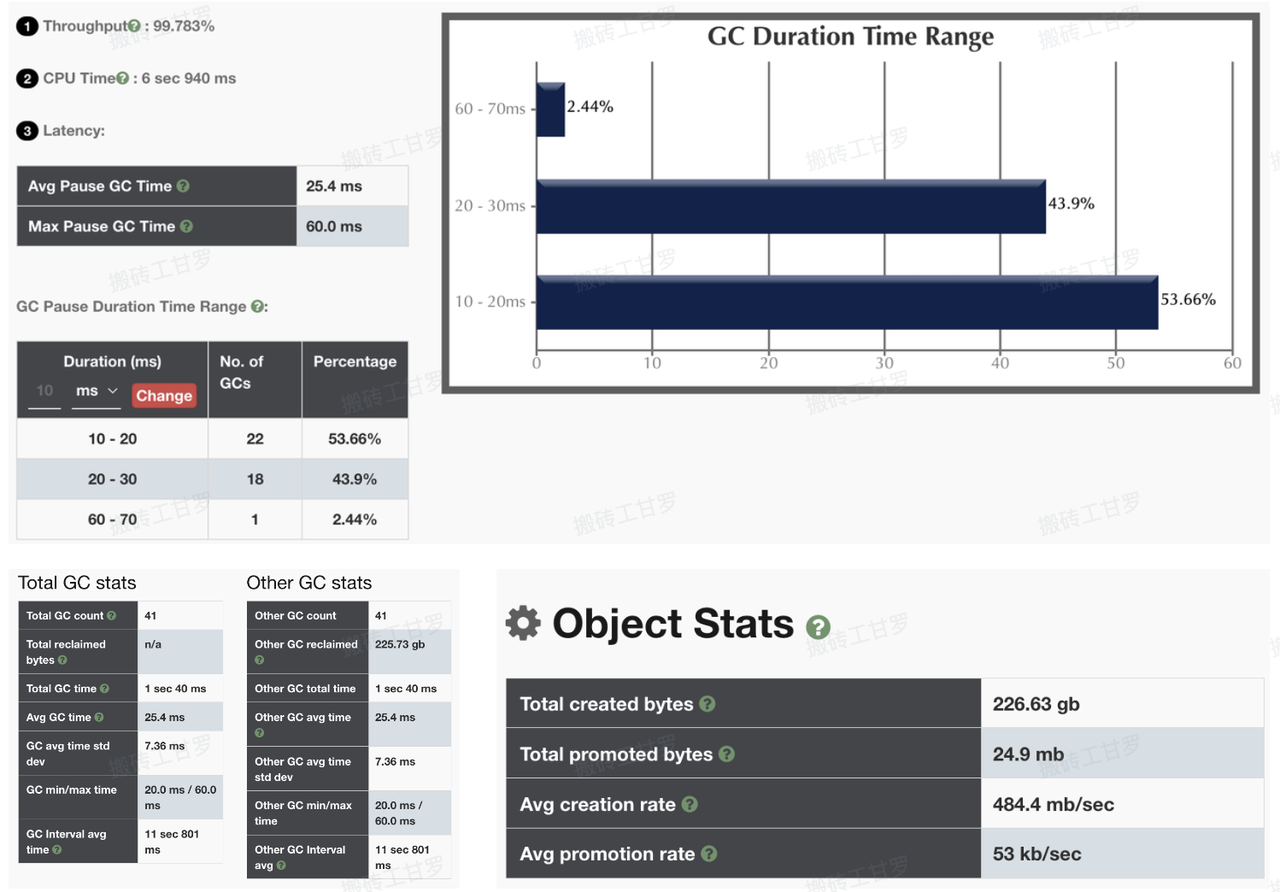
GC 日志是 Java 虚拟机 (JVM) 运行时生成的详细记录,显示了垃圾回收(GC)活动的相关信息。服务重吞吐,计算逻辑复杂,线上选用的垃圾回收为 G1,最大停顿时间为 30ms,堆内存配置为 8G(最大)和 4G(最小)。根据以下关注点,采集 GC 打印日志:
垃圾回收的次数和耗时
每次垃圾回收的具体时间点、耗时以及频率都会在日志中详细记录下来。这些信息能帮助判断垃圾回收是否过于频繁,是否有影响到应用的性能。
GC 类型
通过日志了解每次垃圾回收的类型,Young GC 和 Mixed GC。了解垃圾回收的压力是否主要集中在年轻代或是否需要回收老年代的内存。是否有频繁的 Mixed GC,以及是否触发 Full GC。
GC 暂停时间
每次垃圾回收的“Stop-The-World”暂停时间也会在日志中记录下来。帮助判断垃圾回收对响应时间的影响。
回收前后的堆使用情况
GC 日志会显示每次回收前后堆内存的使用情况,涵盖年轻代、老年代和元空间。这些数据可以帮助你看出内存的使用模式,比如是不是某些对象没有及时回收,或者老年代内存持续增加,可能意味着内存泄漏。
分代内存的使用
日志可以帮你看到年轻代(Eden、Survivor 区)和老年代内存的占用情况。如果年轻代满了,GC 会把对象晋升到老年代,所以通过这些数据可以分析对象的生命周期。
常用 GC 日志参数:
-Xloggc:
:指定 GC 日志输出文件。 -XX:+PrintGCDetails:输出详细的 GC 日志。
-XX:+PrintGCTimeStamps:为每条 GC 日志添加时间戳。
-XX:+PrintGCApplicationStoppedTime:记录 GC 造成的应用程序暂停时间。
-XX:+PrintTenuringDistribution:输出对象晋升年龄分布信息。
GC 分析
通过采集 8 分钟左右的线上 GC 日志,对 GC 内存占用、吞吐等情况进行详细分析,并根据机器 24hGC 日志,观察 mix GC 情况。
分析工具:Universal JVM GC analyzer - Java Garbage collection log analysis made easy
GC 问题与优化举措
问题 1) young GC 过于频繁、持续时间较长且对象晋升过多
问题 2) 尽管最大堆大小设置为 8G,线上实际堆内存大小仍保持在 4G(最小堆内存配置)
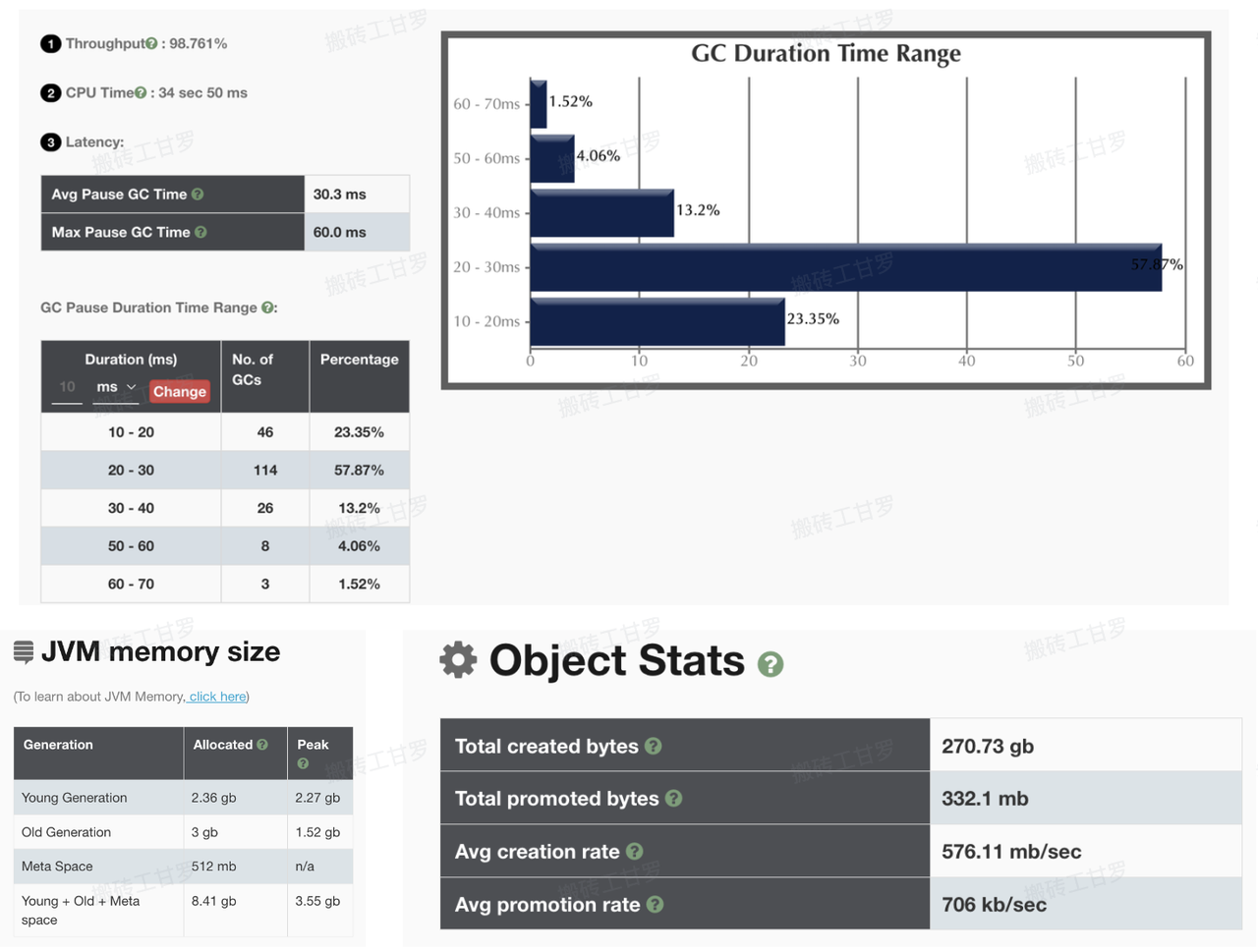
可用方案与优化措施:
增加堆大小:通过调整 JVM 堆大小参数(-Xmx)提升老年代容量,从而减少 GC 的频率。
措施:将最小堆内存大小增至 8G,与最大堆内存一致。
优化对象分配:避免不必要的对象创建,尤其是短生命周期的对象,减少垃圾回收的压力。
措施: jdk 版本升级,减少每次请求中产生的两个以上熔断异常对象。
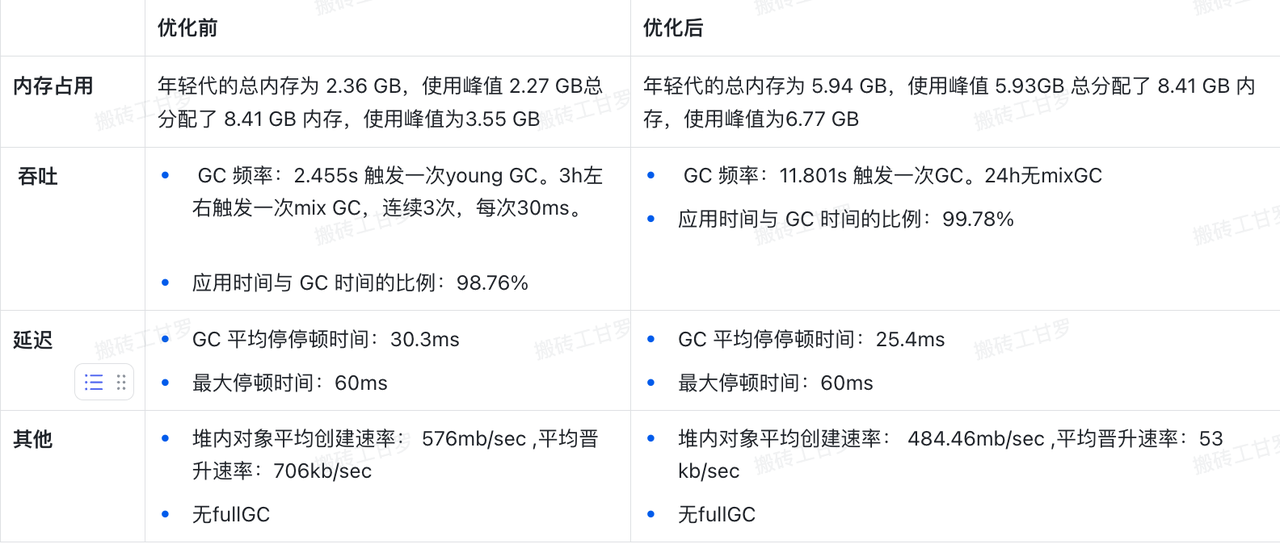
优化后效果
优化后,垃圾回收的频率大幅降低 5 倍,young gc 平均停顿时间时间降低 17%,mix GC 频率降低 8 倍以上,使得应用程序能够有更多的时间专注于业务逻辑执行。应用的吞吐量提升 1%,垃圾回收对应用性能的影响进一步减少。GC 的平均停顿时间显著缩短,系统的响应速度提升,减少了长时间停顿的风险。
架构改造功能验证
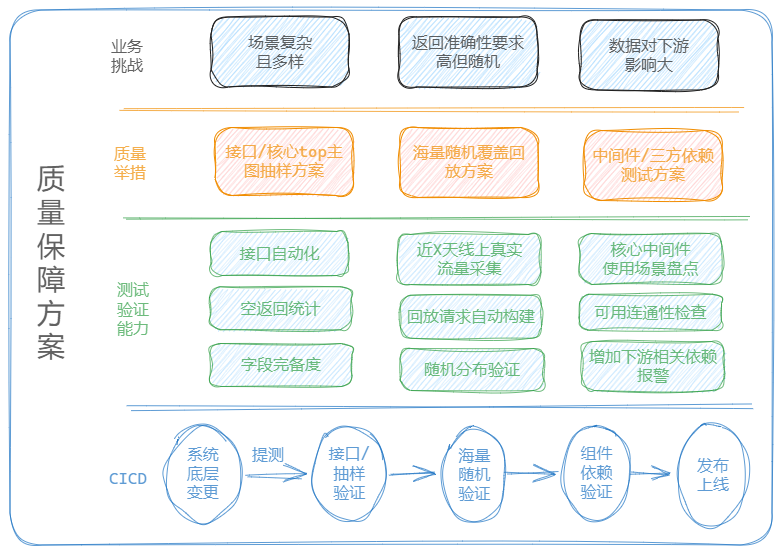
商机平台分发引擎的架构升级专项,从质量风险角度分析,风险极高,尤其是涉及版本升级兼容性的全面评估与覆盖,需考虑对全部功能进行测试验证覆盖,因此需要设计一套全量功能的质量保障方案。
4.1 服务风险分析
服务功能特性
支撑贝壳一体三翼的流量分发,15 亿级流量一旦分配出现错误,直接中断 B/C 端交互、严重影响经纪人的获客公平及平台的成交转化收入,直接 AB 级故障。
服务特点
接口参数复杂性:接口的参数(100+)组合极为复杂且多样(如 adid 枚举值 1000+),难以通过传统穷举测试方法全面覆盖。
返回字段的准确性 &完备性:接口返回的字段直接影响到经纪人在 C 端的展示,以及后续的人客商机回收链路。返回字段的准确性和信息的完备性对于业务流程至关重要。
返回信息的随机性:接口返回的信息具有一定的随机性,即使在相同参数的请求下,所命中的策略分布会有变化。然而,这种变化并非完全无序,而是遵循一定的规律性。需要确保在服务升级前后,策略的总体分布保持一致。
服务数据直接影响下游:核心链路依赖多种中间件,直接影响商机如何分配给对应经纪人,并决定是否上报 digv 信息以用于商机回收。
改造影响
JDK 及 springBoot 版本升级: jdk8.232 -> 8.441, spring5.1 -> spring5.2
--版本升级需要覆盖服务很多兼容性
BeanCopy 改造:用 MapStruct 替换代码中 Jodd 与 Spring 包下的对象拷贝
--影响服务的所有接口参数解析
GC 参数调优-增加堆大小:通过调整 JVM 堆大小参数(-Xmx)提升老年代容量减少 GC 的频率
--服务高负载下 GC 频率??(待修改)
4.2 质量保障方案
结合具体改造内容与服务特性风险分析内容,设计服务系统功能质量保障方案,如下图:
单接口/核心抽样验证
首先要获取服务全部接口有哪些?通过公司日志监控平台(Fast)导出全量接口请求进行分析,也可根据实际业务场景具体评估测试覆盖 TOPN。
测试方式:自动化回放脚本+手工测试相结合。
验证场景:
不同请求类型的验证:确保接口能够正确处理各种类型的请求。
返回字段完备度:验证返回字段的结构和明细是否完整;验证业务核心字段非空。
涉及写操作相关的接口,如会调用第三方获取虚拟号资源的以及 dubbo 协议接口等,这部分接口通过分析筛选出来,采用常规测试环境手工接口测试验证。
海量随机覆盖验证
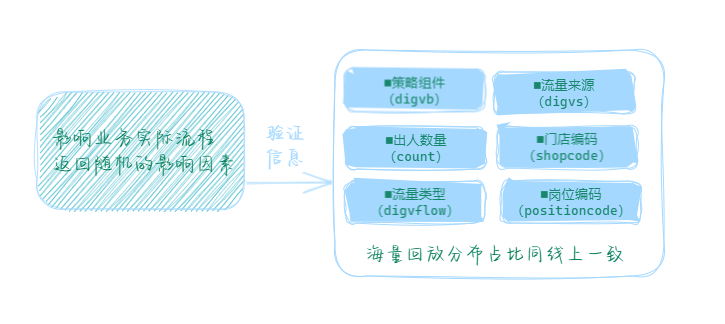
为验证我们业务特有的返回随机特性,我们采用海量线上真实请求回放对比,来保证升级改造后的功能质量,其中接口返回随机验证的标准,参考我们服务线上已有的策略分客效果来设定,校验服务链路中上下游依赖的分发关键信息的分布情况同线上是否一致。
如何来确定验证标准:这里根据影响我们业务实际流程,返回随机的影响因素来确认验证哪些内容的分布要同线上的分布一致。
海量随机覆盖测试方法:包含三步 [ 数据准备 - - >回放测试 -->结果分析 ]
数据准备:
基于如下规则 1,借助公司日志监控平台抽样采集线上近 7 天内的真实流量,分析并二次补充首次采集未覆盖到的核心站位流量;基于规则 2 进行采集数据的过滤,避免影响线上真实留资业务,最终采样出线上 100w+真实请求数据,将这些原始数据进行 trace 标识,确保回放数据同线上数据隔离。

回放测试:
灰度 pod 摘流后,prod 发送相同请求,设置不同的 diff 规则,将返回数据及可能的异常数据记录。
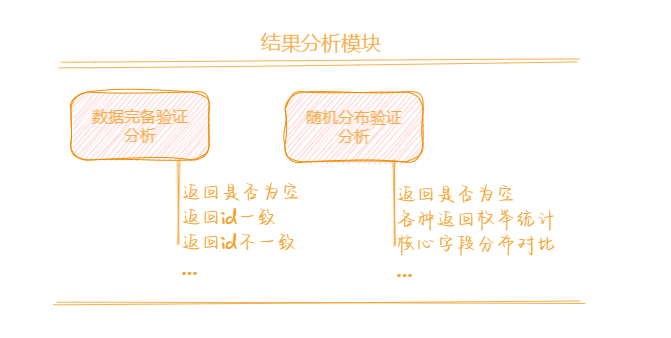
结果分析:
针对回放返回结果做数据完备度验证以及核心分发信息的随机分布验证。
【数据完备验证】
经纪人 ID 一致性检查: 如果回放与线上返回的经纪人 ID 一致,深入对比返回的 data 数据明细,记录不一致的字段信息。
经纪人 ID 不一致性分析: 如果回放与线上返回的经纪人 ID 不一致,对比返回的 data 结构,记录空字段信息
【随机分布验证】
空返回处理: 对于回放返回为空而线上不为空的情况,记录详细的请求信息,以便进一步分析。
空返回统计: 统计回放不为空而线上返回为空的请求个数,以及两者均返回为空的请求个数,并记录相关请求信息。
字段分布对比: 记录相同请求在回放和线上的返回信息,统计并对比两者返回字段的分布占比,以评估接口返回数据的一致性和准确性。
通过以上的数据准备,回放 diff 规则及结果分析,来确保所有接口请求无问题,返回核心字段的准确性。
中间件/三方依赖验证从我们的系统架构可以看出,服务链路中依赖很多存储资源,这些信息直接关联业务下游使用,本次升级改造后需要确保中间件使用联通无问题,首先我们盘点出所有中间件的使用场景,然后分别针对这些应用场景做相关连通性验证的开发与测试验收。【应用场景】
MongoDB:存储兜底物料,应用于兜底策略查询,需确保兜底物料查询正常
Redis:服务链路中涉及很多 redis 分客关键信息存储,需确保 redis 信息正常更新
Elasticsearch (ES):服务链路中涉及大量分客组件物料信息查询,需确保 es 数据查询正常
Kafka:服务链路中涉及发送核心分客 digv 实时流,直接用于下游商机回收,需要测试 kafka 信息发送正常以及单台压测检测服务 digv 实时流 producer 速率,确保无延迟。【测试验收】
中间件连通性测试(存储依赖):测试方式:预览及线上灰度通过中间件可用性检测接口验证验证内容:redis 查询、修改功能;Mongo/ES/Mysql 的查询功能
中间件性能测试(kafka)单台机器 digv 实时流性能摸底压测:单台摘流后使用虚拟展位 mock 发压数据执行
发布验证为确保新版本的稳定性,在完成功能质量验证后的发布环节,我们将发布流程设定为包含灰度,蓝绿梯度推进多个阶段; 同一套验收方法应用于不同发布阶段的验收指标口径,逐步推进,省时省力。
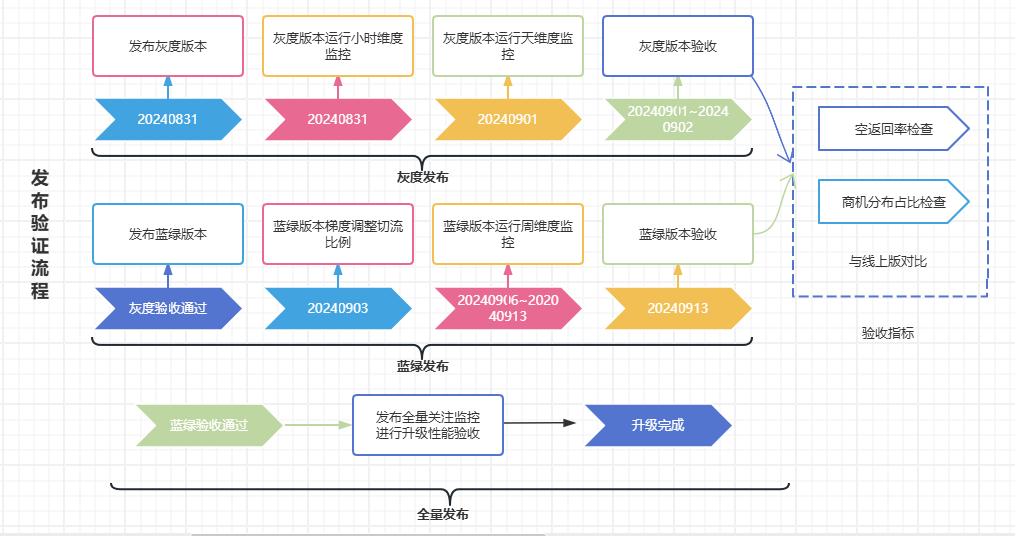
说明:1)灰度发布分为两个阶段,第一阶段为小时维度灰度,持续 2 小时,第二阶段为天维度灰度,持续 1、2 天。2)蓝绿发布按照切流比例逐步增加新版本流量,比例为 5%-10%-20%-50%-100%。
展望:最后在应用以上测试方案完成本次架构改造的过程中,当前沉淀的这些测试验证能力,是完全可以复用于后续我们服务的任何底层变更的测试的,接下来我们将逐步完善到 CI/CD 的流程中。
总结服务性能指标
QPS:升级后单台最大 QPS=2950 ,升级前 QPS=2750,提升约 7.3%。
CPU:平均 CPU 利用率降低约 12%(15.38 %-->13.55%) 。
RT:RT 约提升 7% 左右。
9999%:326ms 缩短到了 276ms,降低了 15.3%。
服务缩容收益
服务器成本:ADX 缩容 40 台->25 台,NAF 60 台 -> 50 台,节约成本 2w。
以上就是本篇分享的全部内容了。未来,贝壳商机平台还会带来关于 Elasticsearch、Dubbo、hystrix 等线上真实场景问题定位、调优相关的实践。
作者简介:
穆云浩,研发工程师,贝壳经纪技术中心·基础业务平台研发部
王 凡,研发工程师,贝壳经纪技术中心·基础业务平台研发部
陈振宇,研发工程师,贝壳经纪技术中心·基础业务平台研发部
姜璐璐,测试工程师,技术效能中心·经纪技术质量部
陈玄玄,测试工程师,技术效能中心·经纪技术质量部




