
在演讲之前,我想首先代表 eBay 祝贺 Apache Kylin 成立 5 周年。Apache Kylin 是出色的 OLAP 产品,希望 Apache Kylin 社区在未来能够带来更多了不起的功能,并对行业产生更大的影响。
今天的议程包括:
介绍 eBay 的开源文化
Apache Kylin 在 eBay 中的发展历程
Kylin 在 eBay 中的应用
eBay 未来的计划
01 eBay 的开源文化
eBay 是一家拥有 30 年历史的电子商务公司,为全球的买卖双方提供线上市场。我们的业务发展速度极快,通过进行巨大的技术转型和发展,后端技术团队在促进 eBay 业务实现方面发挥着非常重要的作用。在过去的十年中,核心技术团队推动着开源文化成为了我们的 DNA,给我们带来了巨大的改变和丰硕的成果。

eBay 鼓励开源内部项目。正如大家在 eBay 公共 GitHub 上看到的那样,eBay 有 100 多个开源项目,并且会越来越多。我们认为,他们值得与社区分享,使更多的用户从中受益。eBay 的一些重要产品,例如 Kylin,Eagle,Griffin 等,有着更大的社区影响力,目前他们都已经贡献到了 Apache 软件基金会。
除了鼓励内部项目开源之外,eBay 还参与并使用了大量外部开源产品来重建我们的基础架构和平台。我们利用 Kubernetes 构建了我们的第三代云平台。我们还使用了 Apache Hadoop 和 Spark 来支持大量数据处理和即席查询。我们也利用了 Kafka 和 Flink 来构建托管的实时数据平台。在使用这些产品的同时,我们也为它们做出了贡献。在 eBay 这样的大型环境中,我们检测出了许多问题,贡献了数千项对原有项目的改进,并以此回馈社区。
开源文化就是我们的 DNA,我们也非常高兴我们的技术能与所有行业中领先的技术相结合。
02 Kylin 在 eBay 的发展历程
接下来让我谈谈 Kylin 在 eBay 上的发展历程。
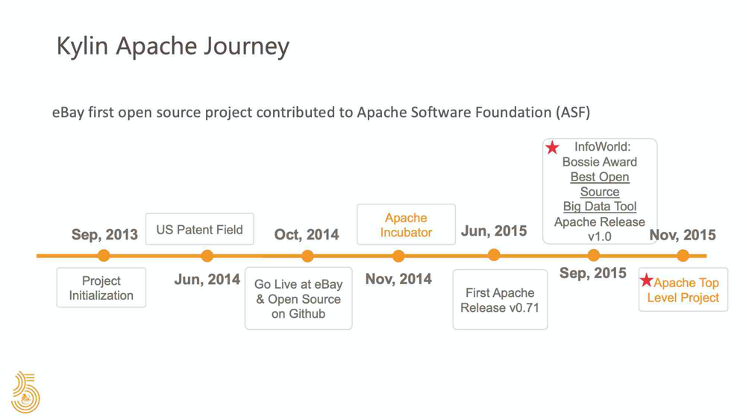
eBay 和 Apache Kylin 有着悠久的历史与关系。2013 年,为了解决在 Hadoop 大型数据集上的 OLAP 查询性能需求, Kylin 项目在 eBay CCOE 中启动。它基于多维数据集技术构建,可以在亚秒级内响应查询。经过一年的发展,Kylin 成为 Apache 孵化器项目,并最终在 2015 年 11 月毕业成为 Apache 顶级项目。这是 eBay 团队的一项重大创新,并且在今天给更多的社区用户带来了益处。
Cube Planner
eBay 一直与 Apache Kylin 社区紧密合作,持续地贡献了有关功能改进以及错误修复的相关代码。在 Kylin 2.3.0 版本中的 Cube Planner 就是来自 eBay 贡献的一项主要功能。
OLAP 解决方案权衡了在线查询速度和离线 Cube 构建成本,即构建 Cube 的计算资源,以及用于保存 Cube 数据的存储资源。资源效率是 OLAP 引擎最重要的能力。为了达到这个目的,选择性地只预构建那些最有价值的 Cube 是至关重要的。
Kylin 拥有的 aggregation group 聚合组的功能可以减少 cuboid 的数量。借助 Cube Planner 能使 Apache Kylin 的资源利用率更高。它可以智能地构建 partial cube,以最大程度地降低构建 Cube 的成本,同时最大程度地为最终用户查询提供符合预期的服务,在运行时从查询中学习其模式和规律,并相应地动态地推荐 cuboids。
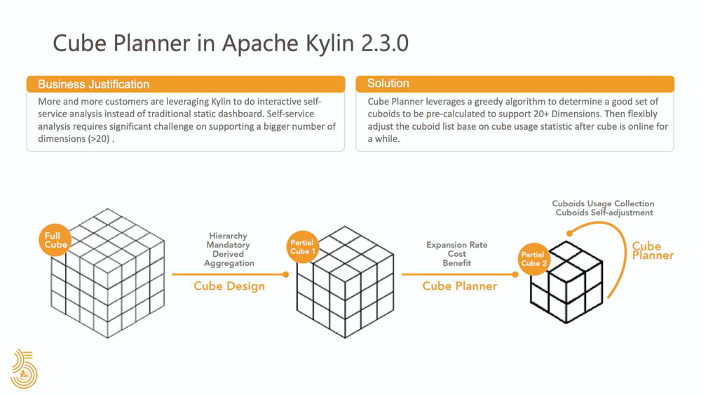
在图中大家可以看到,在第 1 阶段中,Cube Planner 可以在构建 Cube 之前根据估计的 cuboid 大小来列出建议构建的 cuboid,在第 2 阶段中,可以根据查询统计信息为现有的 Cube 对 cuboid 列表作出建议。Cube 需要在线一段时间去获得足够的查询命中率,然后 Cube Planner 才能足够智能并且给出建议。
此功能在 2.5.0 中默认启用,极多维度的 Cube 构建就可以从中受益。更多关于 Cuboid 剪枝优化和 Cube Planner 的介绍👉 Kylin 新手必看:Cube 越用越好,存储越用越少
实时 OLAP
Kylin 还在 Kylin 3.0 中提供了实时 OLAP 功能。有了这个功能,我们可以实时在生成数据后进行决策。
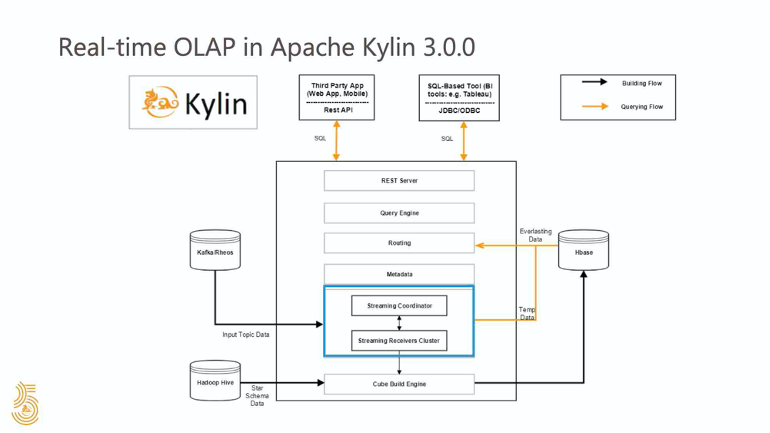
大家可以看到,在 Kylin 架构中,为了实现实时功能,我们添加了蓝色方框中的两个组件。一个是 Streaming coordinator,另一个是 Streaming receiver。Streaming coordinator 负责管理接收器的操作。Streaming receiver 负责从流式数据源获取数据并回答实时数据查询。
实时段数据首先存储在内存中,然后以列式存储的片段文件形式刷新到接收器的本地磁盘,并且当磁盘上的片段过多时,它们将被自动合并,最后移交到完整的 Cube 构建阶段。无论 cube segment 的数据在哪里,查询都可以随时被回答。
我们扩展了 Query Engine 查询引擎和 Build Engine 构建引擎,以支持实时数据查询和 Cube 构建。
在这里概述几个要点:
数据准备只是毫秒级延迟 :一旦 Kylin Streaming Receiver 接收了流数据,Cube 的预计算就会在内存中进行,那时实时 Cube 已经能够回答查询请求;
支持 Lambda 架构 :实时数据通常不可靠,这可能是由多种原因引起的,例如,上游处理系统存在错误,或者数据一段时间后需要更改等。我们支持 Lambda 架构,从批处理源(例如 Hive)刷新 Cube 历史记录;
更少的 MR 作业和 HBase 表 :在 Kylin 1.6 中,社区提供了一种流解决方案,该解决方案允许用户使用 MR 作业(如几分钟内的微批次)来摄入 Kafka 数据。它将导致系统中存在大量的 Hadoop 作业和小的 HBase 表,增加 Hadoop 系统的负载和发生潜在问题的可能性。
此功能已在 eBay 中使用,我认为它对于实时场景应该非常有吸引力。
03 Kylin 在 eBay 中的应用
目前在 eBay 中,Kylin 平台是为决策分析用户案例提供支持的主要服务。 我们在多个数据中心设置 Kylin 服务,以与 Hadoop 基础架构和业务数据分布保持一致。数据能够以精心设计的安全方式从 Hadoop 和 Rheos 中提取。我们拥有专用的 HBase 集群来稳定服务器的查询延迟。此外,作为平台团队,我们提供 24 * 7 紧急事件响应和技术支持。

分享一些重点如下:
我们在 40 个项目中分配了 300 多个 Cube。
最大的 Cube 在源表中具有 1.18 万亿个原始数据,最终的 Cube 大小为 96.2 TB。
平均构建时间为 16 s/MB 源数据,平均 Cube 膨胀率为 0.46。
我们每天处理大约 80 万条查询,平均延迟时间约为 0.68 秒。
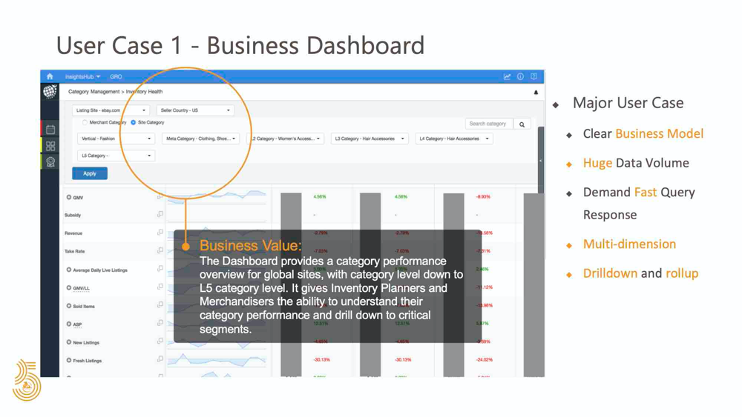
eBay 中有一些典型的使用模式。 第一种模式即最主要的模式,是为决策提供支撑 。通常,这些用例具有精心设计的业务模型,例如星型模式或雪花模式,它具有清晰的过滤维度和按维度分组以及目标度量。这种模型需要庞大的数据集作为分析基础,以便对每周,每月,甚至每年的趋势进行比较。同时,企业所有者还需要深入分析和汇总分析的功能,并期望他们的决策案例能得到快速响应。这里是一个用例。此案例为库存计划员和采购员提供了类别表现的概述。他们可以进行站点过滤和类别深入分析以及汇总分析,以获取深刻的见解。
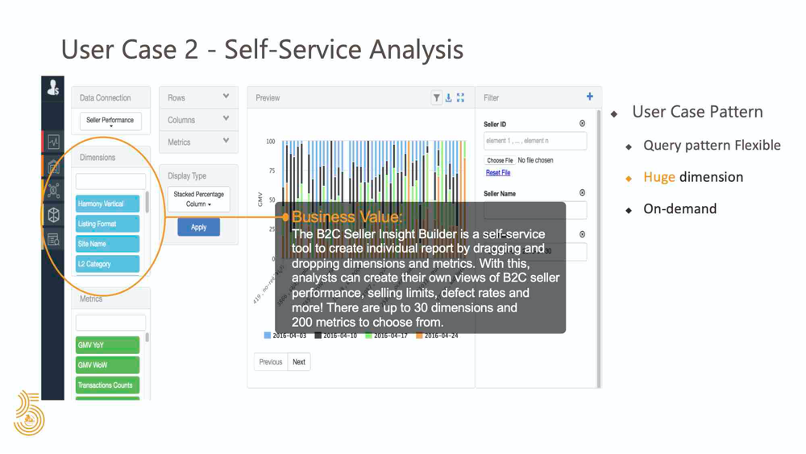
第二种模式是为分析师提供 eBay 自助服务分析指导,以探索更多的商机 。用户案例所有者(如 eBay 数据服务和解决方案团队)将在 IDL 数据集上构建 Cube。IDL 是集成数据层,它是一组用通用业务逻辑进行了转换的表,可以为一个域或跨域内的一个或多个业务流程提供服务。基于这些数据的 Cube 具有许多相关的度量和维度。统一的 UI 解决方案为最终用户提供了灵活性,可以轻松地拖放不同的维度和度量组合以进行特定分析。这是一个用例,最终用户可以从 30 个维度和 200 个度量中选择一种组合来分析 B2C 业务绩效。
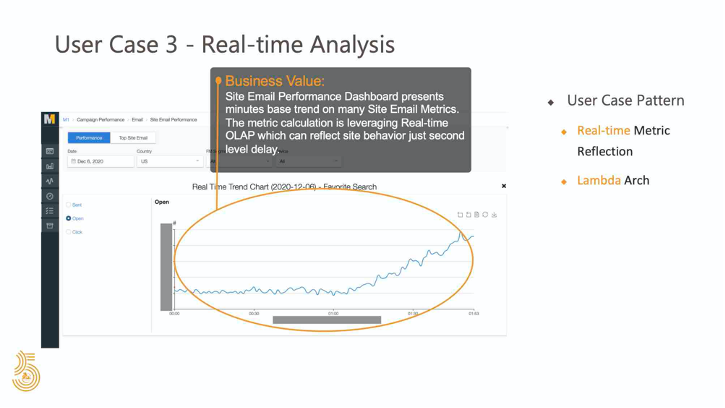
第三种模式是实时 OLAP 。最重要的需求是数据处理后的度量的实时反映。而且,由于实时事件管道中存在一些不确定性,用户要求 Lambda 架构从 ETL 流中调整度量精度。这是 BU 需要实时监视站点电子邮件号码以了解其性能的一个示例。同时他们还需要回顾庞大数据集中的逐年指标。
04 eBay 未来计划
由于 eBay 朝着向目标用户(如分析师和业务部门)提供更多自助服务和智能数据分析功能的方向发展,我们的数据服务和解决方案团队正在构建增强版分析解决方案,该解决方案需要更多来自 Kylin 平台的灵活性和弹性支持,例如从多个 Hadoop 群集中提取数据,对庞大查询量的系统弹性,以及构建高维 Cube 的灵活性和性能。因此,建立更高的灵活性和弹性系统将是我们明年的首要任务。
此外,我们还在考虑替代 HBase 的存储解决方案。Kylin 社区已经开始了一项重大计划,也就是使用 Parquet 提供轻量,列式存储,云友好的解决方案。我们明年也计划对存储解决方案部分进行一些调研。
在过去的两年中,我们的团队致力于一项重大计划,该计划通过在 SparkSQL 上进行大量软件优化来提供对 Hadoop 数据的快速特定查询体验。我们也会考虑将 Kylin 用作整个蓝图中的加速层之一。
作者介绍:
Lisa Li,在 eBay 中国研发中心大数据平台部门担任研发主管。带领的团队主要负责 SQL on Hadoop 的方案,给使用 SQL 查询语言的数据分析师在开源的 Hadoop 数据平台上提供更加快速稳定的数据处理和查询体验。主要包括 Kylin 和 Spark 两个软件产品的深度开发和服务运维工作。
本文转载自公众号 apachekylin(ID:ApacheKylin)。
原文链接:




