
“整个中国,P7 及以上的高级 ETL 工程师数量非常有限,可能总共也就四五百人。”在大数据领域深耕了二十多年的周卫林说道。
周卫林曾经从零建立了蚂蚁的数据平台体系,是蚂蚁集团数据技术的主要奠基人之一。是否通过技术创新来模拟这些工程师的能力,让每个行业都能“养得起”很多这样的高级人才?带着对数据工程发展的全新思考,2021 年初的周卫林与蚂蚁原数据平台部的核心成员一起建立了专注消除数据管理技术瓶颈的 Aloudata。
他们理念的核心就是用智能化的解决方案取代传统由工程师驱动的 ETL 作业模式,即“NoETL”,通过 ETL 智能体(ETL Agent)来驱动数据处理和管理。
传统 ETL 怎么不行了?
ETL(Extract, Transform, Load) 的概念最早由“数据仓库之父”William H. Inmon 提出。在数据仓库发展初期,企业需要将分散在不同系统、不同格式的数据整合到一个统一的数据仓库中,以支持业务分析和决策。为了解决数据整合和清洗的问题,ETL 工具应运而生,成为处理大量数据的重要工具。
ETL 受益于数据爆炸式增长和企业对数据驱动决策需求的增加,同样随着数据规模和复杂度的不断增加,传统 ETL 技术也开始难以应对。具体来说,传统的 ETL 面临着以下现实挑战:
技术挑战。随着链路的增多,搬运和处理工作也日渐增多,再加上数据每天要更新,所以每个任务都必须经历排期、研发、测试、上线发布等步骤。查询性能的要求各不相同,当需求变得越来越动态时就迫切需要进行性能优化,有些需求等不及系统优化,则会导致无序开发,进而影响整个链路的管理和治理。
成本失控。难以平衡需求满意度和成本,是数据平台部门负责人一直面临的难题。需求的灵活性导致刚提出时需求往往无法立即满足,只能预先计算可能会被使用的数据,然后再提供给用户,这意味着更高的成本和更低的边际收益。现实中,这会导致许多用户需求满足度下降、业务方不断被 IT 部门追问目标、利益和 ROI 而感到沮丧。
ETL 工程师能力有限。个人可以管理的任务量和处理的系统复杂度都是有限的,而数据仓库系统是一个综合分析系统,系统内部的数据只增不减,使得管理的复杂度越来越高。另外,由于高频变化的研发,目录的人工维护变得极为困难,这导致数据管理失效。
周卫林认为,现有的 ETL 工程体系不可持续,必须采用全新的思维方式、新的架构和新的技术来应对这一挑战。
实际上,新的数据集成和处理方法也在不断涌现,例如 ELT(Extract, Load, Transform)、流式处理、实时数据集成等,那 Aloudata 提出的“NoETL”是如何解决上述问题的呢?
NoETL 是什么?
不同于“ETL 是一种企业 IT 活动”的说法,“NoETL”是一种企业业务能力,旨在寻找一种不再依赖于传统 ETL 工程师驱动的方法,从而实现数据生产力的可持续和大规模增长。
根据周卫林介绍,“NoETL”模式有四个特点:去管道,无需关心数据位置;免运维,无需操心任务运维;自优化,无需担心查询性能;主动元数据,从被动到主动,实现数据管理的“自动驾驶”。
而要实现上述四大特性,关键是构建三大引擎能力:数据语义引擎、数据虚拟化引擎和主动元数据引擎,三大引擎能力背后分别提供了全新的数据交互界面、数据集成方案和数据管理模式。
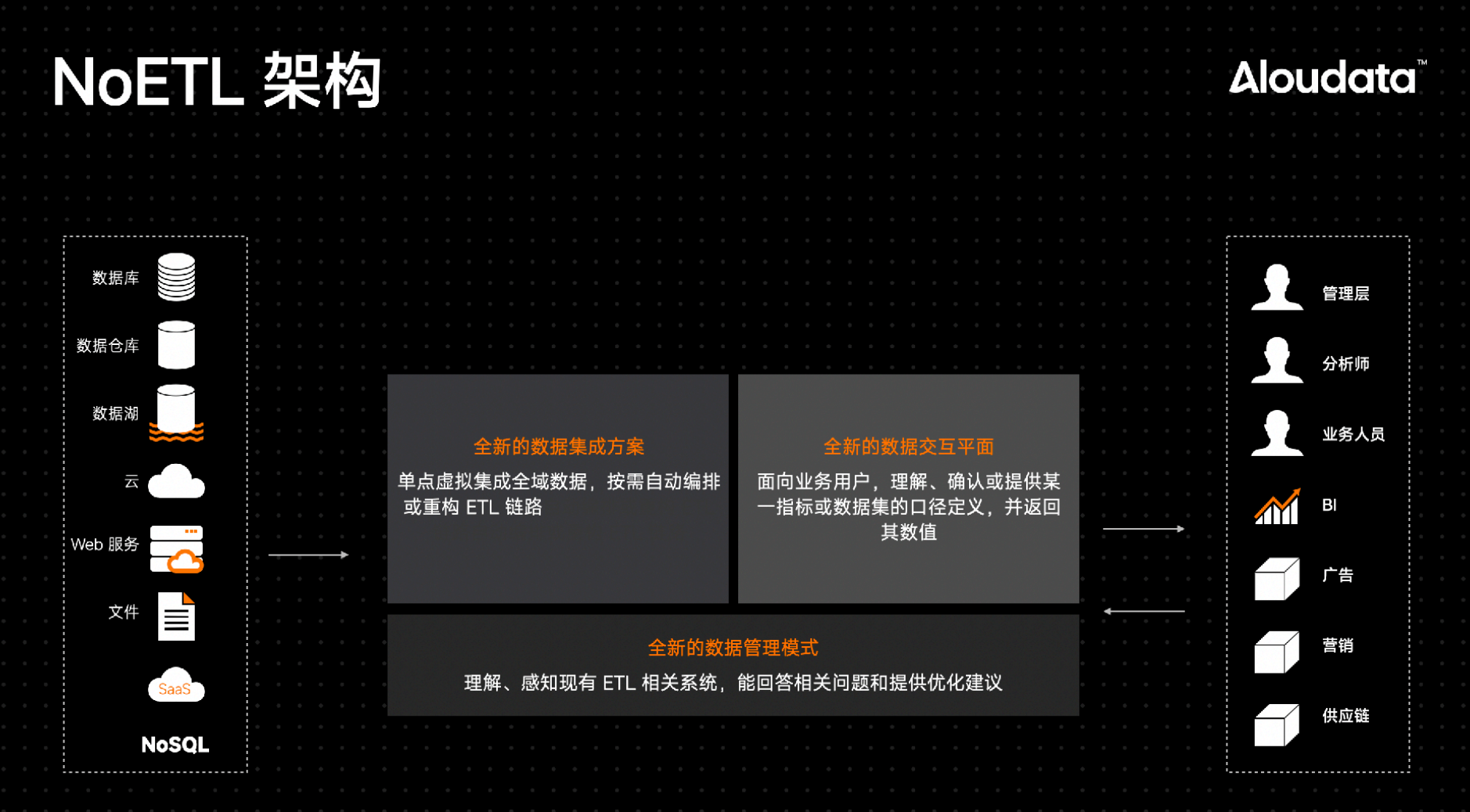
在全新的数据交互界面中,不仅仅包含报表。底层业务人员需要的不仅是报表,而是更细粒度的数据集和口径明确的指标。实际操作中,用户不需要知道表格存放的具体位置,但要清楚理解指标的口径,以及这些口径背后的值。总的来说,业务人员需要做两件事:明确指标的定义,以及确保这些指标是他们所需要的。
对于全新的数据集成方式,则使用逻辑方式进行数据集成和自动化重构 ETL 链路的新方法,无需物理集中,即可连接和集成全域数据,同时通过自适应加速技术实现更加高效的数据准备和链路编排。可以用淘宝模式类比:商家首先发布商品,消费者通过添加购物车、下单来完成交易,下单后商家再发物流,物流再进行配送。这与传统的“先补货再销售”的模式截然不同。
全新的数据管理模式,即基于主动元数据驱动的管理。Aloudata 实现了一套能够实时感知全局信息的主动元数据系统,通过国际上最为精细的血缘解析能力和数据语义挖掘技术,在数据发现、生产、消费和管理等各环节提供全面准确的元数据及高置信智能建议,从而让复杂数据链路看得清、管得住、治得动。
Aloudata 的 NoETL 架构通过数据语义引擎提供全新的交互界面,通过数据虚拟化引擎实现逻辑数据集成与自动化构建 ETL 链路,通过主动元数据引擎实现数据治理的辅助驾驶(Copilot)。
根据 Aloudata 说法,通过这一全新的架构,实际业务中的需求交付周期可以从按周或按月变为按天或按小时交付,存储和计算成本降低 50%以上。
NoETL 实践
在现今的数据架构下,Aloudata 推出了三款主要产品:逻辑数据平台 Aloudata AIR、实现算子级解析的主动元数据平台 AloudataBIG 和自动化指标平台 Aloudata CAN。
Aloudata AIR 基于 Data Fabric 架构,通过虚拟化集成多源异构数据,无需实际搬运数据,类似于淘宝提供集中购物平台的模式。此外,其自动化物化链路编排和智能查询下推技术,实现了自适应查询加速,显著提高处理效率。
Aloudata BIG 作为主动元数据平台,拥有算子级血缘解析能力,可以精确理解线上 SQL 代码逻辑,实现真正实时、精准的数据理解和更高效的产品应用。此外,该平台能将代码翻译成自然语言,使用户更易理解,为模型治理、链路保障、综合安全合规检查等方面提供价值。
Aloudata CAN 颠覆了传统指标管理模式,用户在平台定义指标后,系统可以自动进行指标开发,实现定义即生产、一致性和自动化下线资源回收。这种自动化生产过程大幅简化了 ETL 工作量,降低了 IT 参与度。
在 Aloudata 现有客户里,招商银行与蚂蚁类似,都有十万亿量级的数据管理需求。之前,招商银行采用数据仓库方案通过物理方式实现数据的汇总和加工,进而为分析场景提供数据准备。面对不同场景的多次物理搬运与 ETL 工程不仅成本高昂,而且会导致重复导数、数据安全、数据时效性差、数据灵活性和使用效率较低等问题,招商银行引入了 Aloudata 的整套服务。
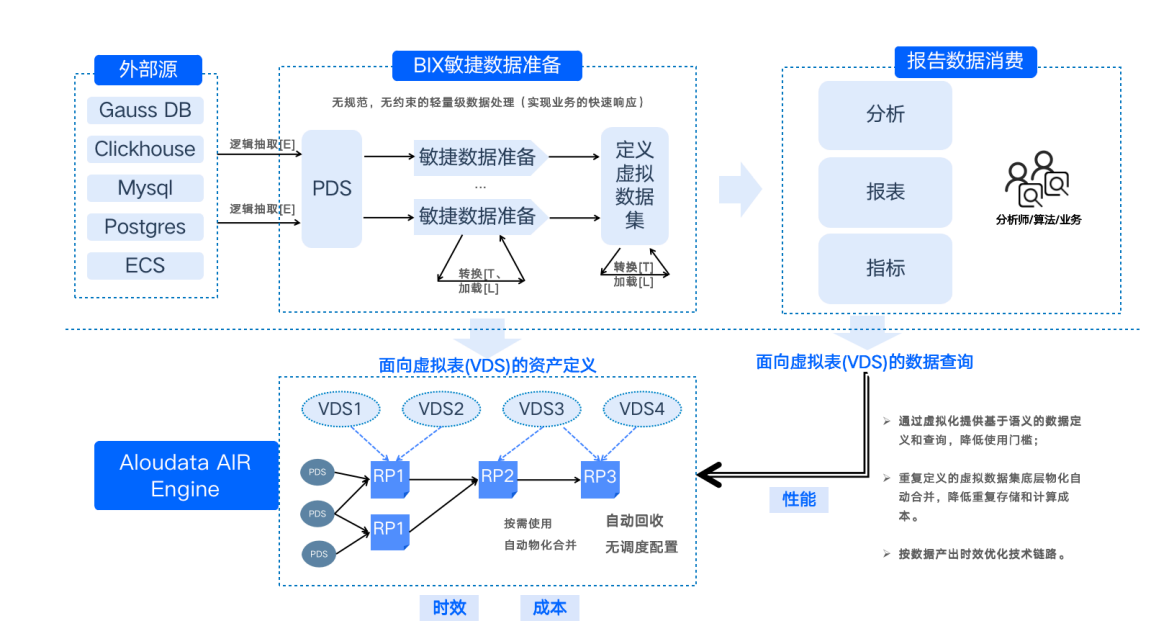
该方案首先通过虚拟化手段将 ClickHouse、MySQL、Postgres 等引擎中的海量数据进行逻辑整合,构建出一个统一的逻辑数据资产层,进而让 BIX 平台可以对用户提供更加灵活的自助式数据准备和自助式数据服务的取数用数方式。
自适应物化加速方面,基于用户的查询历史以及数据编排逻辑,进行 SQL Pattern 的抽取,通过抽取算子模板引用关系统计、计算和存储成本、访问次数以及压缩比等因子,计算出有价值、且复用度高的模板,对模板进行泛化和关系投影(Relational Proiection)的创建,以实现数据预计算链路的物理编排,保障每日十亿级数据量下的查询性能。
数据显示,新方案的数据准备周期从原来的两周缩短至 1 天,总体存储计算成本较之前降低超过 50%。
“我们的使命不仅仅是解决人才短缺的问题,而是更彻底地改变数据的生产方式,让数据随时就绪。”周卫林说道。




