
OCR 从流程上包括两步:文本检测和文本识别,即将图片输入到文本检测算法中得到一个个的文本框,将每个文本框分别送入到文本识别算法中得到识别结果。
1. 基于深度学习的文本检测算法大致分为两类:基于候选框回归的算法*和*基于分割的算法。
基于候选框回归的文本检测,是源于目标检测算法,然后结合文本框的特点改造而成的,包括 CTPN、EAST 和 Seglink 算法等。CTPN 是基于 faster RCNN 改进的算法,在 CNN 后加入 RNN 网络,主要思想是把文本行切分成小的细长矩形进行检测再拼接起来;SegLink 算法的检测思路与 CTPN 类似,也是先检测文本行的小块然后拼起来,但网络结构上采取了 SSD 的思路,在多个特征图尺度上进行文本检测,然后将多尺度的结果融合起来,另外输出中加入了角度信息的回归;EAST 算法,它是直接回归的整个文本行的坐标,而不是细长矩形拼接,网络结构上利用了 Unet 的上采样结构来提取特征,融入了浅层和深层的信息,并且在输出层回归了角度信息,可以检测斜框。
基于分割的文本检测,其基本思路是通过分割网络进行像素级别的语义分割,再基于分割的结果构建文本行,包括 PixelLink、Psenet 和 Craft 算法等。PixelLink 算法,网络结构上采用 FCN 提取特征,直接通过实例分割结果中提取文本位置,输出的特征图包括像素分类特征图和像素 link 特征图。Psenet 算法,网络结构上采用 FPN 特征金字塔提取特征,对每个分割区域预测出多个分割结果,然后提出一种新颖的渐进扩展算法,将多个分割的结果进行融合。Craft 算法,网络结构上采用 UNet 的结构,输出的特征图包括 Region score 特征图和像素 Affinity score 特征图,另外特征图中使用了高斯函数,将预测像素点分类的问题转成了像素点的回归问题,能更好的适应文字没有严格包围边界的特点。
2. 基于深度学习的文本识别算法则相对较为统一,一般都采用 CNN+RNN+CTC 的结构,俗称 CRNN 结构,因为这种结构的识别效果很好,且泛化性好,工业上大多都用的这种结构,然后在该框架上做一些改进,如更换 CNN 主干网络,缩减卷积层以提高速度缩减空间,或者改进 RNN 加入 Attention 结构等。
本文主要介绍了我们在生产上使用的文本检测和文本识别算法。算法的训练流程一般包括以下步骤:
1. 准备训练数据,有的是需要标注(如文本检测中),有的主要是造数据(如文本识别中);
2. 定义算法网络,这里主要是明确输入和输出;
3. 准备好 batch 数据集,这里主要是处理输入的图片和标签数据,标签数据结构与第 2 步中的网络输出对应,例如 craft 要进行高斯函数计算等,而文本识别中则无需处理,直接将造好的数据输入即可;
4. 定义 loss,优化器和学习率等参数;
5. 训练,这里主要是定义每批次数据训练的操作策略,如保存策略,日志策略,测试策略等。
OCR 文本检测
我们在文本定位中采用的是 Craft 算法,它是一种基于分割的算法,无需进行大量候选框的回归,也无需进行 NMS 后处理,因此极大提升了速度,并且它是字符级别的文本检测器,定位的是字符,对于尺寸缩放不敏感,无需多尺度训练和预测来解决尺度方差问题,最后其泛化性能也能达到 SOTA 的水平。
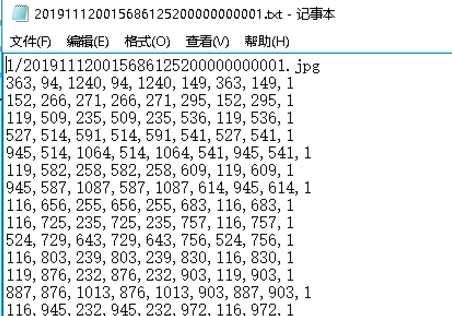
1、训练数据标注
该方法是基于分割的,背景文字是指的原本就在票据上的文字,如“姓名”、“出生年月”等文字,前景文字是指的待识别的文字,也就是用户后填进去的内容。标注步骤就是将这些文字框出来,标上相应的类别。我们采用自己开发的标注工具,这里也可以使用开源的 labelme 工具,生成的标注文件如下所示,第一行是图片所在路径,从第二行开始就是坐标框信息,最后一位是类别。
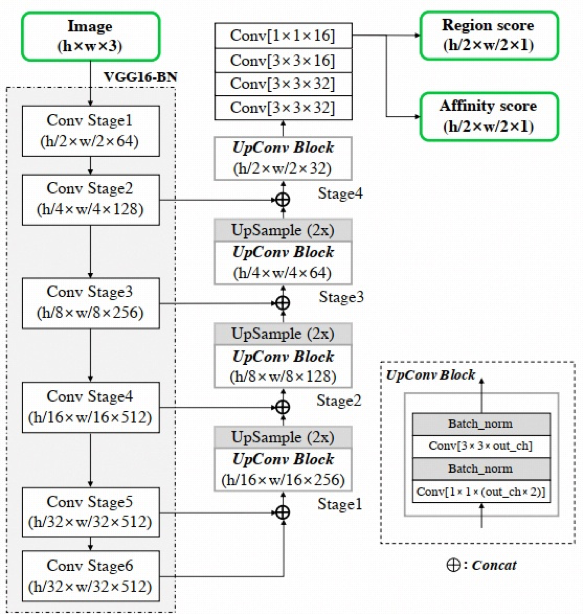
2、网络设计
下图是网络结构图,整体采用了 Unet 的主结构,主干网络用的 vgg16,输入图片首先经过 vgg16 后,接 UNet 的上采样结构,其作用是使得深层和浅层的特征图进行拼接作为输出。然后再接一系列的卷积操作,充分提取特征。最后输出的特征图包括 Region score 特征图和像素 Affinity score 特征图。
网络的代码如下所示:
class CRAFT(nn.Module): def __init__(self, pretrained=False, freeze=False, phase='test'): super(CRAFT, self).__init__() """ Base network """ self.basenet = vgg16_bn(pretrained, freeze) """ 固定部分参数,用于迁移学习""" if phase == 'train': for p in self.parameters(): p.requires_grad=False """ U network """ self.upconv1 = double_conv(1024, 512, 256) self.upconv2 = double_conv(512, 256, 128) self.upconv3 = double_conv(256, 128, 64) self.upconv4 = double_conv(128, 64, 32) num_class = 2 self.conv_cls = nn.Sequential( nn.Conv2d(32, 32, kernel_size=3, padding=1), nn.ReLU(inplace=True), nn.Conv2d(32, 32, kernel_size=3, padding=1), nn.ReLU(inplace=True), nn.Conv2d(32, 16, kernel_size=3, padding=1), nn.ReLU(inplace=True), nn.Conv2d(16, 16, kernel_size=1), nn.ReLU(inplace=True), nn.Conv2d(16, num_class, kernel_size=1), ) init_weights(self.upconv1.modules()) init_weights(self.upconv2.modules()) init_weights(self.upconv3.modules()) init_weights(self.upconv4.modules()) init_weights(self.conv_cls.modules()) def forward(self, x): """ Base network """ sources = self.basenet(x) """ U network """ y = torch.cat([sources[0], sources[1]], dim=1) y = self.upconv1(y) y = F.interpolate(y, size=sources[2].size()[2:], mode='bilinear', align_corners=False) y = torch.cat([y, sources[2]], dim=1) y = self.upconv2(y) y = F.interpolate(y, size=sources[3].size()[2:], mode='bilinear', align_corners=False) y = torch.cat([y, sources[3]], dim=1) y = self.upconv3(y) y = F.interpolate(y, size=sources[4].size()[2:], mode='bilinear', align_corners=False) y = torch.cat([y, sources[4]], dim=1) feature = self.upconv4(y) y = self.conv_cls(feature) return y.permute(0,2,3,1), feature我们也从代码中把网络结构打印出来,可以看到最后一层输出的结构,最终网络的输出结构是(batchsize, 2, w, h),即通道数为 2 的特征图。

3、训练标签生成
图片的标签数据包括 region_score 和 affinity_score 两个特征图,region_score 表示给定的像素是字符中心的概率,affinity_score 表示相邻两个字符中间空白区域中心的概率。其特征图不像二进制分割图那样用离散方式标记每个像素,本文使用高斯热图对字符中心的概率进行编码,将分类问题转化为回归问题,另外采用高斯热度图的好处是它能很好地处理没有严格包围的边界区域,因为文字不像传统目标检测的物体,它没有明确的轮廓边界。生成高斯热图的流程图如下所示:
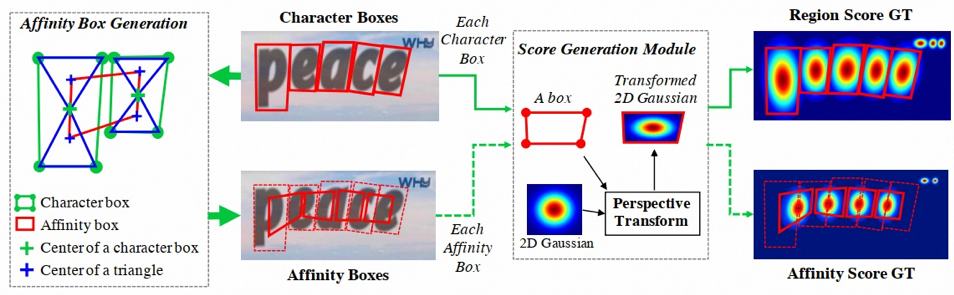
高斯热图的生成代码如下所示:
def generate_transformed_gaussian_kernel(h, w, points): ''' 使用透视变换的高斯核建模region或affinity h:图像的高 w:图像的宽 points:维度(4,2) ''' # 生成高斯核 minX, minY = points[0] maxX, maxY = points[0] for i in range(1,4): minX = min(points[i][0],minX) minY = min(points[i][1],minY) maxX = max(points[i][0],maxX) maxY = max(points[i][1],maxY) kernel_w = int((maxX - minX + 1) // 2 * 2) kernel_h = int((maxY - minY + 1) // 2 * 2) kernel_size = 31 kernel = np.zeros((kernel_size, kernel_size)) kernel[kernel_size//2, kernel_size//2] = 1 kernel = gaussian_filter(kernel, 10, mode='constant') kernel_size = max(kernel_h, kernel_w) kernel = cv2.resize(kernel,(kernel_size,kernel_size)) # 将高斯核透视变换,坐标(列,行) src = np.float32([(0,0),(0,kernel_size),(kernel_size,kernel_size),(kernel_size,0)]) # 左上,左下,右下,右上 tgt = np.float32(points) M = cv2.getPerspectiveTransform(src, tgt) dst = cv2.warpPerspective(kernel, M, (w,h)) # 转换到[0.001,1]之间 mini = dst[np.where(dst>0)].min() maxi = dst[np.where(dst>0)].max() h = 1 l = 0.001 # 与预训练模型的分布保持一致 dst[np.where(dst>0)] = ((h-l)*dst[np.where(dst>0)]-h*mini+l*maxi) / (maxi-mini) return dst调用上述函数计算好 region_map 和 affinity_map 的结果,用 .npy 格式保存起来,然后在数据类中调用,自定义数据类的代码如下所示:
class MyDataset(Dataset): def __init__(self, root): self.root = root self.imglist = [f.split('.')[0] for f in os.listdir(os.path.join(root, 'img'))] def __getitem__(self, index): # read img, region_map, affinity_map img_path = os.path.join(self.root, 'img', self.imglist[index]+'.jpg')# img = plt.imread(img_path) img = np.array(plt.imread(img_path)) region_path = os.path.join(self.root, 'region', self.imglist[index].split('_')[0]+'_region_' +self.imglist[index].split('_')[1]+'.npy') region_map = np.load(region_path).astype(np.float32) affinity_path = os.path.join(self.root, 'affinity', self.imglist[index].split('_')[0]+'_affinity_' +self.imglist[index].split('_')[1]+'.npy') affinity_map = np.load(affinity_path).astype(np.float32) # 保证图像长和宽是2的倍数 h, w, c = img.shape if h % 2 != 0 or w % 2 != 0: h = int(h // 2 * 2) w = int(w // 2 * 2) img = cv2.resize(img, (w, h)) region_map = cv2.resize(region_map, (w, h)) affinity_map = cv2.resize(affinity_map, (w, h)) # preprocess img = normalizeMeanVariance(img) img = torch.from_numpy(img).permute(2, 0, 1) # [h, w, c] to [c, h, w] region_map = cv2.resize(region_map, (w//2, h//2)) region_map = torch.tensor(region_map).unsqueeze(2) affinity_map = cv2.resize(affinity_map, (w//2, h//2)) affinity_map = torch.tensor(affinity_map).unsqueeze(2) gt_map = torch.cat((region_map,affinity_map), dim=2) return {'img':img, 'gt':gt_map} def __len__(self): return len(self.imglist)4、损失函数设计
由于输出的特征图采用高斯函数构建,因此分割的损失函数也由交叉熵损失函数换成了回归用的 MSE 损失函数,优化器选用经典的 SGD。代码如下所示,
criterion=nn.MSELoss(size_average=False).to(device)optimizer=torch.optim.SGD(filter(lambda p: p.requires_grad, net.parameters()),1e-7, momentum=0.95, weight_decay=0)5、网络训练设计
由于文字定位需要的数据量极大,而真实数据集通常很少,标注也较困难,这里使用的是 finetune 方式,即载入预训练权值然后微调训练的方式,用较少的训练集就能达到很好的效果。代码如下所示:
if __name__ == '__main__': """参数设置""" device = 'cuda' # cpu 或 cuda dataset_path = './data' # 自己数据集的路径 pretrained_path = './pretrained/craft_mlt_25k.pth' # 预训练模型的存放路径 model_path = './models' # 现在训练的模型要存储的路径 dataset = MyDataset(dataset_path) loader = DataLoader(dataset, batch_size=1, shuffle=True) net = CRAFT(phase='train').to(device) net.load_state_dict(copyStateDict(torch.load(pretrained_path, map_location=device))) criterion=nn.MSELoss(size_average=False).to(device) optimizer=torch.optim.SGD(filter(lambda p: p.requires_grad, net.parameters()),1e-7, momentum=0.95, weight_decay=0) if not os.path.exists(model_path): os.mkdir(model_path) for epoch in range(500): epoch_loss = 0 for i, data in enumerate(loader): img = data['img'].to(device) gt = data['gt'].to(device) # forward y, _ = net(img) loss = criterion(y, gt) optimizer.zero_grad() loss.backward() optimizer.step() epoch_loss += loss.detach() print('epoch loss_'+str(epoch),':',epoch_loss/len(loader)) torch.save(net.state_dict(), os.path.join(model_path,str(epoch)+'.pth'))6、测试结果
测试结果如下图所示,其中左图是预测出的高斯热图,为了便于进行一系列的图像操作,所以统一 resize 成了正方形,右图是由高斯热图转化出的矩形框图,也就是最终可以放入识别模型中的切片框图,为了保护隐私信息做了模糊处理。可以看到,票据中的字被不同颜色的框给框出来了,并且分好了类别,其中红色的为背景字,蓝色的为前景字。
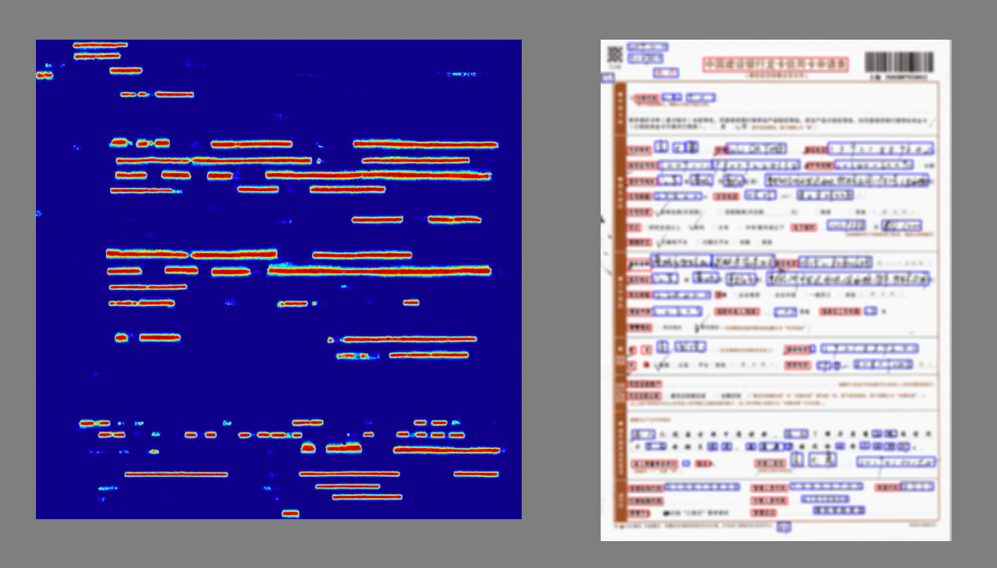
OCR 文本识别
我们在文本识别中采用的是 CRNN 算法,它结构非常简单,就是 CNN+RNN+CTC 的结构,CNN 用来提取图像特征,RNN 用来提取文字的序列特征,CTC 用来对齐输出与标签来计算 loss。
1、训练数据生成
在之前的《 OCR 数据处理篇》已经介绍过如何生成训练数据,生成的图像如下所示。
训练数据的生成有两种方式,离线生成和在线生成,离线方式意思是先将图片数据生成好存入硬盘中,然后读取;在线方式是指:在每个 batch 的训练开始前动态的生成训练图片,从而不会保存图片。
OCR 识别模型的训练需要大量的数据,通常需要的数据量是字符集的 1000 倍,例如要训练一个能认 5000 字的模型,至少需要 500 万条数据才能训练,这么多的小图片数据存入内存中,一是占用内存,二是小文件的读取会非常慢。因此在 OCR 识别模型的训练时通常会采用在线的方法。
生成训练数据前需要先准备字符集,将字符集处理成如下的 txt 文件,一行为一个字。

在线生成数据的代码如下,主要就是自定义一个 pytorch 的 Dataset 类,它自带的__getitem__方法是个迭代器, 每个 batch 载入数据时会自动调用该方法,取出 batch_size 大小的数据,然后定义好字符集、字体、背景、颜色等信息就可以了,也可以制定一些随机策略生成。
char_name = 'chinese_word.txt'data_set = Generator(cfg.word.get_charset(char_name), args.direction, char_name = char_name, word_times = 1000)if args.distributed: val_sampler = torch.utils.data.distributed.DistributedSampler(val_set)else: val_sampler = torch.utils.data.RandomSampler(val_set)data_loader = DataLoader(data_set, batch_size=args.batch_size, sampler=train_sampler, num_workers=args.workers)class Generator(Dataset): def __init__(self, alpha, direction='horizontal', char_name = 'chinese_word.txt', word_times = 100): """ :param alpha: 所有字符 :param direction: 文字方向:horizontal|vertical """ super(Generator, self).__init__() self.alpha = alpha self.direction = direction self.alpha_list = list(alpha) self.min_len = 5 self.max_len_list = [16, 19, 24, 26] self.max_len = max(self.max_len_list) self.font_size_list = [30, 25, 20, 18] self.font_path_list = list(FONT_CHARS_DICT.keys()) self.font_list = [] # 二位列表[size,font] self.word_times = word_times for size in self.font_size_list: self.font_list.append([ImageFont.truetype(font_path, size=size) for font_path in self.font_path_list]) if self.direction == 'horizontal': self.im_h = 32 self.im_w = 512 else: self.im_h = 512 self.im_w = 32 def get_allchar(): f = codecs.open(os.path.join('./data', char_name), mode='r', encoding='utf-8') lines = f.readlines() f.close() charlist = [l.strip() for l in lines] return charlist self.charlist = get_allchar()def __getitem__(self, item): image, indices, target_len = self.gen_image() if self.direction == 'horizontal': image = np.transpose(image[:, :, np.newaxis], axes=(2, 1, 0)) # [H,W,C]=>[C,W,H] else: image = np.transpose(image[:, :, np.newaxis], axes=(2, 0, 1)) # [H,W,C]=>[C,H,W] # 标准化 image = image.astype(np.float32) / 255. image -= 0.5 image /= 0.5 target = np.zeros(shape=(self.max_len,), dtype=np.long) target[:target_len] = indices if self.direction == 'horizontal': input_len = self.im_w // 4 - 3 else: input_len = self.im_w // 16 - 1 return image, target, input_len, target_lendef __len__(self):return len(self.alpha) * self.word_times2、网络设计
是由 cnn+rnn 组成,代码如下所示:
class CRNN(nn.Module): def __init__(self, num_classes, **kwargs): super(CRNN, self).__init__(**kwargs) self.cnn = nn.Sequential(OrderedDict([ ('conv_block_1', _ConvBlock(1, 64)), # [B,64,W,32] ('max_pool_1', nn.MaxPool2d(2, 2)), # [B,64,W/2,16] ('conv_block_2', _ConvBlock(64, 128)), # [B,128,W/2,16] ('max_pool_2', nn.MaxPool2d(2, 2)), # [B,128,W/4,8] ('conv_block_3_1', _ConvBlock(128, 256)), # [B,256,W/4,8] ('conv_block_3_2', _ConvBlock(256, 256)), # [B,256,W/4,8] ('max_pool_3', nn.MaxPool2d((2, 2), (1, 2))), # [B,256,W/4,4] ('conv_block_4_1', _ConvBlock(256, 512, bn=True)), # [B,512,W/4,4] ('conv_block_4_2', _ConvBlock(512, 512, bn=True)), # [B,512,W/4,4] ('max_pool_4', nn.MaxPool2d((2, 2), (1, 2))), # [B,512,W/4,2] ('conv_block_5', _ConvBlock(512, 512, kernel_size=2, padding=0)) # [B,512,W/4,1] ])) self.rnn1 = nn.GRU(512, 256, batch_first=True, bidirectional=True) self.rnn2 = nn.GRU(512, 256, batch_first=True, bidirectional=True) self.transcript = nn.Linear(512, num_classes)def forward(self, x): """ :param x: [B, 1, W, 32] :return: [B, W,num_classes] """ x = self.cnn(x) # [B,512,W/16,1] x = torch.squeeze(x, 3) # [B,512,W] x = x.permute([0, 2, 1]) # [B,W,512] x, h1 = self.rnn1(x) x, h2 = self.rnn2(x, h1) x = self.transcript(x) return x自定义一个 pytorch 的 Module 类,cnn 层这里用的结构是 vgg16,ConvBlock 结构如下所示,就是卷积,batchNormalization 加 relu。这里也可以根据需要换成 resnet 或者 densenet 主干网络。
class _ConvBlock(nn.Sequential): def __init__(self, in_channels, out_channels, kernel_size=3, stride=1, padding=1, bn=False): super(_ConvBlock, self).__init__() self.add_module('conv', nn.Conv2d(in_channels, out_channels, kernel_size, stride, padding)) if bn: self.add_module('norm', nn.BatchNorm2d(out_channels)) self.add_module('relu', nn.ReLU(inplace=True))然后 rnn 层是一个双向的 rnn,这里为了加速用的 gru 代替 lstm,最后接一个线性层,最终输出为(batchsize, unit, class_num),其中 unit 是根据识别的切片长度不同而变化的,class_num 是字符集的个数,因为最后是计算 softmax。
3、损失函数的设计
在上述 rnn 的输出单元 units 后,因为每个切片的字符数量不同,字体大小样式不同,导致每个 unit 的输出与结果的字符并不是一一对应的,因此采用了 CTC_loss 的损失函数。用的 torch.nn.CTCLoss(),是 pytorch 自带的函数。代码如下所示:
model = crnn.CRNN(len(data_set.alpha))model = model.to(device)criterion = CTCLoss()criterion = criterion.to(device)4、网络训练设计
每个 epoch 的训练过程如下:输入图片—》预测—》计算损失—》反向传播更新参数—》保存模型,pytorch 可以动态的把整个训练步骤用代码形式写出来,因此很容易编写和调试中间步骤。
def train_one_epoch(model, criterion, optimizer, data_loader, val_set, device, epoch, args): model.train() epoch_loss = 0.0 # for image, target, input_len, target_len in tqdm(data_loader): for i, sample_batched in enumerate(data_loader): image, target, input_len, target_len = sample_batched image = image.to(device) # print(target, target_len, input_len) outputs = model(image.to(torch.float32)) # [B,N,C] outputs = torch.log_softmax(outputs, dim=2) outputs = outputs.permute([1, 0, 2]) # [N,B,C] loss = criterion(outputs[:], target, input_len, target_len) # 梯度更新 model.zero_grad() loss.backward() optimizer.step() # 当前轮的loss epoch_loss += loss.item() * image.size(0) # 每训练一个batch打印一次 loss 和 acc if i % 100 == 0: print('[epoch:%d, %d | %d] Loss: %.03f' % (epoch, i, len(data_loader), epoch_loss / (i + 1))) if np.isnan(loss.item()): print(target, input_len, target_len) epoch_loss = epoch_loss / len(data_loader.dataset) # 打印日志,保存权重print('Epoch: {}/{} loss: {:03f}'.format(epoch + 1, args.epochs, epoch_loss))5、结果展示
测试代码如下,主要就是模型的加载调用和预测结果的处理。
def inference_image(net, alpha, image_path): image = load_image(image_path) image = torch.FloatTensor(image) predict = net(image)[0].detach().numpy() # [W,num_classes] label = np.argmax(predict[:], axis=1) label = [alpha[class_id] for class_id in label] label = [k for k, g in itertools.groupby(list(label))] label = ''.join(label).replace(' ', '')return labeldef main(args): alpha = cfg.word.get_charset('chinese_word.txt') if args.direction == 'horizontal': net = crnn.CRNN(num_classes=len(alpha)) else: net = crnn.CRNNV(num_classes=len(alpha)) net.load_state_dict(torch.load(args.weight_path, map_location='cpu')['model']) net.eval() # load image if args.image_dir: image_path_list = [os.path.join(args.image_dir, n) for n in os.listdir(args.image_dir)] image_path_list.sort() for image_path in image_path_list: label = inference_image(net, alpha, image_path) print("image_path:{},label:{}".format(image_path, label)) else: label = inference_image(net, alpha, args.image_path) print("image_path:{},label:{}".format(args.image_path, label))测试准确率在 98% 左右,测试的样例结果如下所示,3 张全部识别正确。

文章转载自:金科优源汇(ID:jkyyh2020)
原文链接:OCR模型训练




