
在此前的大模型技术实践中,我们介绍了加速并行框架 Accelerate、DeepSpeed 及 Megatron-LM。得益于这些框架的助力,大模型的分布式训练得以化繁为简。
然而,如何将训练完成的模型实际应用部署,持续优化服务吞吐性能,成为企业所面临的问题。我们不仅要考量模型底层的推理效率,还需从请求处理的调度策略上着手,确保每一环节都能发挥出最佳效能。
本期内容,优刻得将为大家带来 vLLM [1],一款高性能推理服务框架的相关内容。vLLM 于近期推出了 0.6.0 版本 [2],那么,相比旧版本推出了什么新功能,又做了哪些优化呢?

优刻得模型服务平台 UModelVerse 现已同步上线 vLLM0.6.0。仅需点击几下,就能即刻畅享新版 vLLM 带来的极速推理体验,文末带来详细的使用教程。
1 API 服务端-推理引擎进程分离
推理服务框架需要考虑服务部署的两个要素:面向客户请求的服务端,以及背后的模型推理端。在 vLLM 中,分别由 API 服务端 (API Server)和模型推理引擎 (vLLM Engine)执行相应任务。
1.1 进程共用 vs. 进程分离
根据旧版 vLLM 设计,负责处理请求的 API 服务端与负责模型推理的推理引擎,共用同一个 python 进程;
0.6.0 版本将 API 服务端和推理引擎分离,分别由两个 python 进程运行。进程之间的信息交互由 ZeroMQ socket 进行传输 [3]。
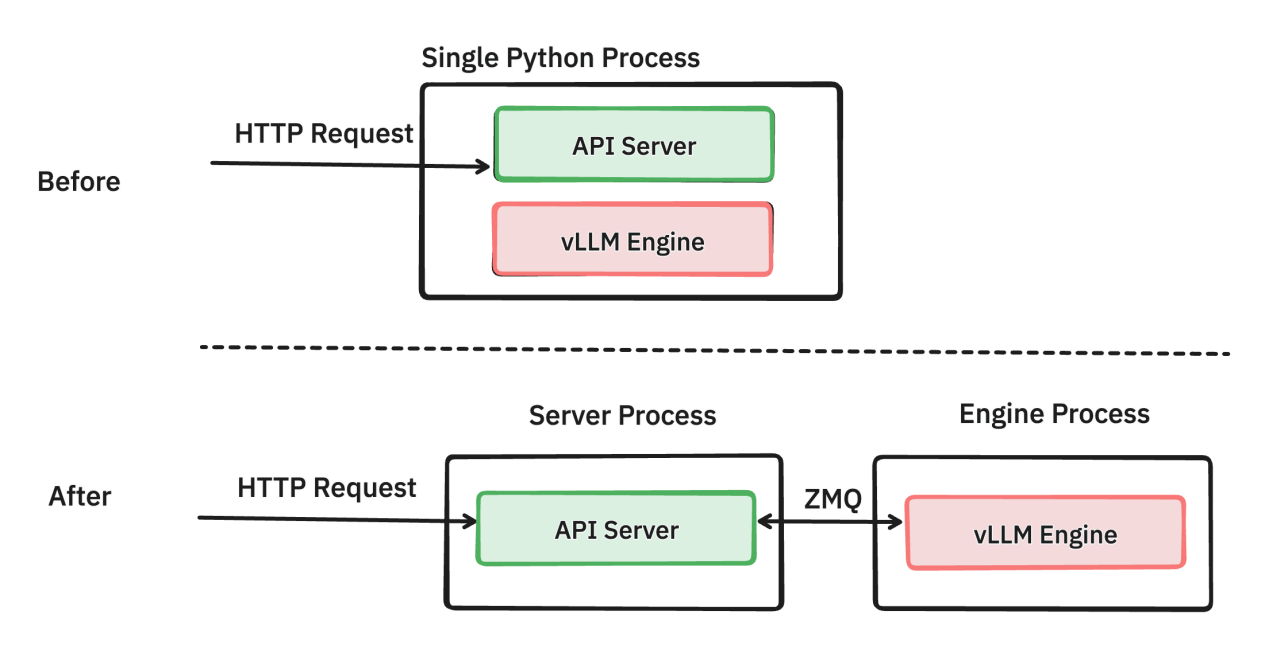
上:旧版,API 服务端与推理引擎共用同一个 python 进程; 下:新版,API 服务端与推理引擎各自独用 python 进程。
API 服务端需要承担一系列处理 HTTP 请求等任务。通过对旧版本的性能分析,vLLM 团队发现 API 服务端消耗大量 CPU 资源。
举个例子,在推理引擎端,轻负载下使用 Llama3 8B 模型推理生成 1 个 token 的耗时约为 13ms;而相对应地,API 服务端需要能够每秒处理 76 个 token 才能跟上推理引擎的速度。由于 python GIL 的存在,推理引擎还会与服务端争抢 CPU 资源。CPU 端负载巨大无法及时处理计算,则会使得 GPU 端因等待 CPU 而产生空闲,无法充分利用性能 [3]。
在 0.6.0 版本中,将 API 服务端与推理引擎端分离为两个进程后,两个进程可以各自专注于份内职责,而不会受 GIL 的影响。而在分离后,团队后续可以更好地对两端分别进行更细致的性能优化和打磨。
1.2 TTFT,TPOT 和 ITL
在进入测试对比前,先了解一下衡量语言模型服务推理效率通常参照的三个指标,即:
首个 token 响应时长 (Time to first token, TTFT)
每个 token 输出时长 (Time per output token, TPOT)
跨 token 延迟 (Inter-token latency, ITL)
TTFT 顾名思义,就是从客户端发出请求后开始计时,直到服务端返回第一个输出 token 的耗时。过程中,由服务端收到请求后着手处理,交由调度器准备推理。推理引擎需要完成 prefill 任务。基于 prefill 得到的 kv 值,decode 得到第一个输出 token 后返回。
而 TPOT 和 ITL 概念相对接近,表达的都是后续一连串 decode 的耗时。根据 vLLM 测试代码 [4],我们定义如下:
TPOT 是在一个请求从发出后,不纳入 TTFT 的耗时 (主要是为了排除 prefill 耗时),到所有 token 全部 decode 完成并返回的整体耗时除以一共返回的 token 数量,即每个 token 输出的平均时长;
而 ITL 是在计算每次请求返回部分 token 时所需的时长,即服务端每次 decode 后返回一个或一批 token 所需的时长。举个例子,如果每次服务端返回 1 个 token,则 ITL 耗时应与 TPOT 接近;而当每次服务端返回 5 个 token,则 ITL 耗时应接近于 5 倍的 TPOT 耗时 (因为 ITL 计算单次的时长,而 TPOT 计算单 token 的时长)。
1.3 测试 &对比
在优刻得云主机上开展对比测试。
利用 vLLM 官方提供的 benchmark_serving 基准测试,我们可以模拟真实的客户端请求,从而对比 vLLM 0.6.0 与旧版 vLLM (0.5.5)在进程分离上的优化导致的性能差异。关闭其他优化方法后,在保持其他参数不变的情况下,在 opt-125m 模型上开展测试。在服务端,我们分别在 0.6.0 和旧版本上使用以下的参数:
Bash #vLLM 0.5.5(共用进程) vllm serve facebook/opt-125m \ --max-model-len 2048 \ --use-v2-block-manager #vLLM 0.6.0(分离进程) vllm serve facebook/opt-125m \ --max-model-len 2048 \ --use-v2-block-manager \ --disable-async-output-proc #关闭0.6.0的新优化方法:异步输出处理。下文有详解~而在客户端,我们统一采用以下脚本。我们模拟 100 个请求同时发出,请求数据随机取自 ShareGPT v3 数据集。
Bashpython vllm/benchmarks/benchmark_serving.py \ --backend vllm \ --model facebook/opt-125m \ --tokenizer facebook/opt-125m \ --request-rate inf \ #所有请求无间隔同时发送 --num-prompts 100 \ #共100条请求发出 --dataset-name sharegpt \ --dataset-path dataset/ShareGPT_V3_unfiltered_cleaned_split.json \ --sharegpt-output-len 1024 \ --seed 42 #固定种子控制变量经过测试,结果如下 (左旧版本 0.5.5;右新版本 0.6.0):
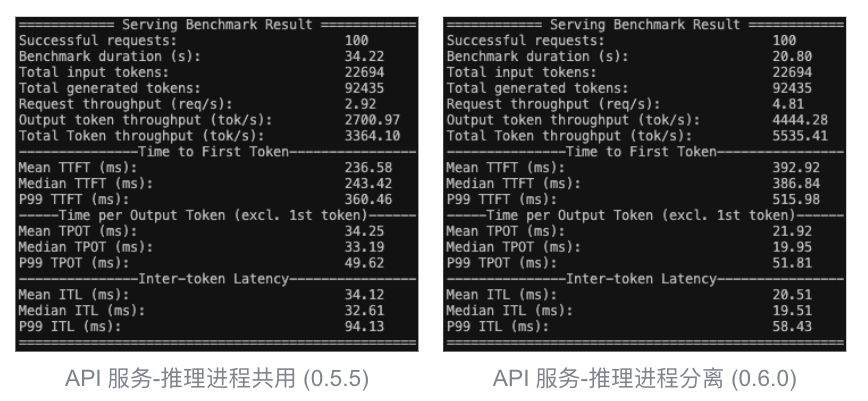
进程分离以牺牲 TTFT 指标为代价 (笔者推测进程间 ZeroMQ 通信带来开销),测试整体时长(Benchmark duration)比进程共用快近 14 秒,提速约 40%。该模型参数量较小,GPU 压力较小,瓶颈主要在于 CPU。进程分离消除了 CPU 争抢造成的开销。
2 多步调度 (Multi-step scheduling)
在请求调度层面,vLLM 0.6.0 的更新中引入了多步调度 (Multi-step scheduling)的方法 [2],使得请求处理的调度更高效。为了更好地理解多步调度的意义,我们简单了解一下 vLLM 调度器。
2.1 调度器 (Scheduler)
vLLM 推理引擎 LLMEngine 中存在调度器 (Scheduler)的概念。调度器控制来自服务端的输入请求会以什么顺序送入模型执行推理。对于一个输入请求,我们需要首先对输入的句子执行 prefill 计算,并基于 prefill 得到的 kv 值开展 decode 计算,即预测下一个 token。而调度器的职责就是以合理的调度策略,安排模型执行 prefill 或是 decode 的顺序 (篇幅限制,具体调度细节这里不展开)。
2.2 单步调度 vs. 多步调度
在旧版 vLLM 中,每次调度器只会为下一次的模型推理安排优先顺序,即每次调度对应一次模型推理。该方法被称为单步推理;
0.6.0 引入多步推理,每次调度器调度会安排接下来的多次模型推理,即每次调度对应 n 次推理。多步推理可以减少调度次数,降低 CPU 开销,从而让模型推理充分利用 GPU 资源,尽量保持运行。
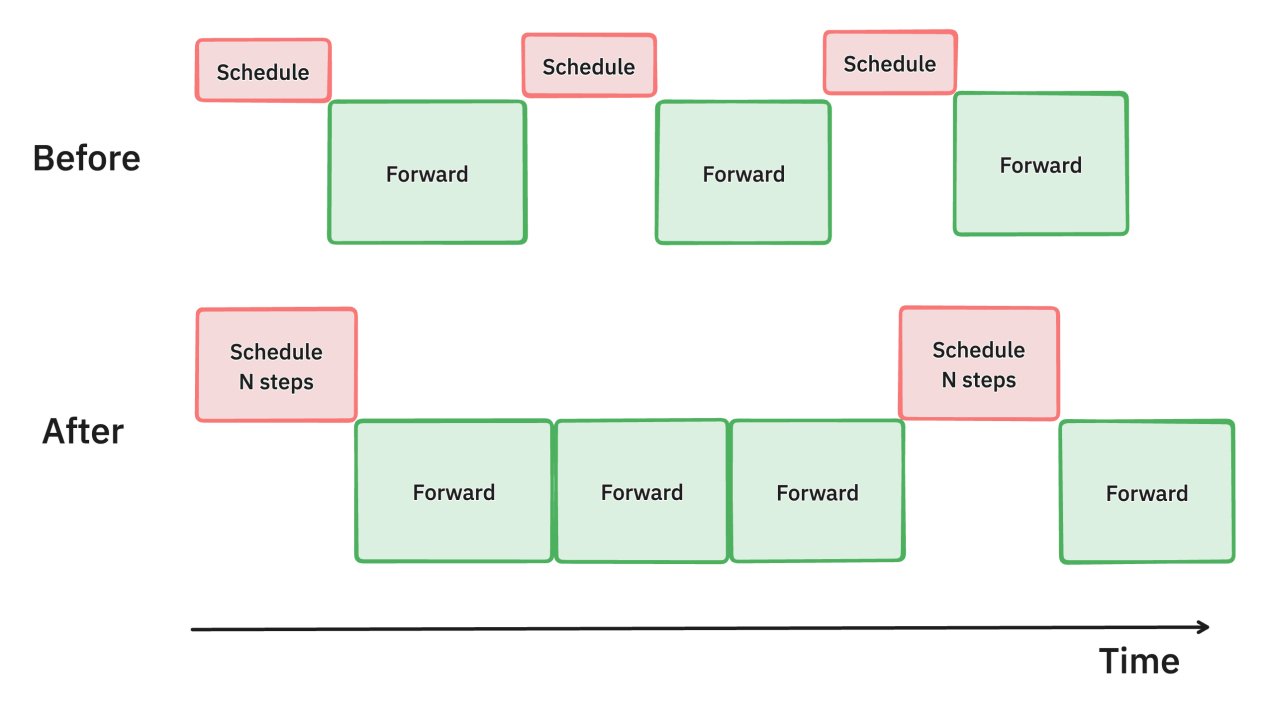
上:一次调度后执行 1 步推理; 下:一次调度后执行 3 步推理。
据 vLLM 团队测试,4 张 H100 环境下运行 Llama 70B,多步推理的吞吐量比单步推理提升了 28% [3]。
2.3 测试 &对比
利用上述基准测试,对比单步调度与多步调度的性能差异。这次我们统一使用 0.6.0 版本。在保持其他设置相同的情况下,设置服务端启动参数分别如下。而客户端方面设置与上文相同,在此不再赘述。
#单步/多步调度 vllm serve facebook/opt-125m \ --max-model-len 2048 \ --use-v2-block-manager \ --disable-async-output-proc \ #关闭异步输出处理 --num-scheduler-steps 1/10 #每次调度1步/10步以下为测试结果 (左单步调度,右多步调度 step=10):
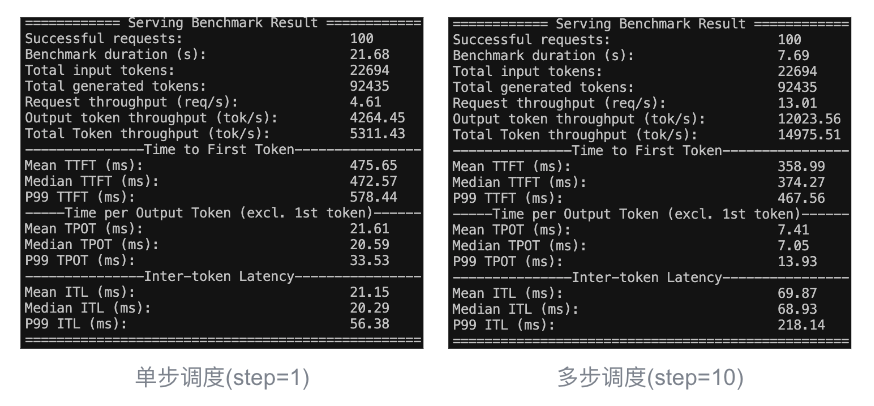
多步调度(step=10)的情况下,基准测试仅耗时 7.69 秒;而单步调度耗时 21.68 秒,整体速度上快近 3 倍。
使用 NVIDIA Nsight systems [5]进一步分析 profile (NVTX 中绿色块表明执行调度)。多步调度中每个绿色块之间有 10 组 CPU epoll_pwait 和 read,即执行 10 次 GPU 上的模型推理,并读取结果;而单步推理中每个绿色块之间仅有 1 组 epoll_pwait 和 read,即 1 次模型推理。

多步调度(step=10)

单步调度(step=1)
细心的同学可能发现了,上述测试中,尽管多步调度的整体耗时降低了很多,但是 ITL 远大于单步调度。这是因为多步调度(step=10)将 10 步推理整合到了一起。因此,ITL (69.87 秒)正好约为 10 倍 TPOT (7.41 秒)。增加一场多步调度(step=5)的测试进行验证,可以看到 ITL 约为 41.76 秒,约 5 倍于 TPOT 的 8.79 秒。
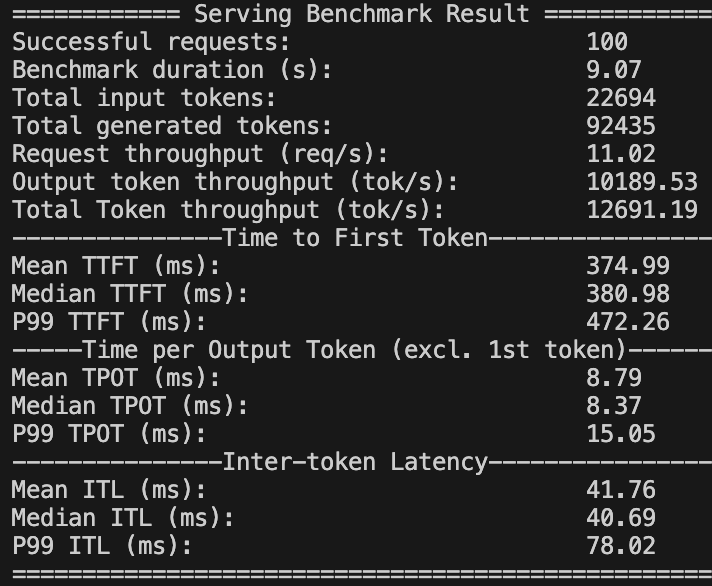
多步调度(step=5)
3 异步输出处理 (Async output processing)
在旧版 vLLM 中,GPU 端模型推理输出 token 后,必须在 CPU 端对输出 token 进行处理并判断是否符合停止条件 (stopping criteria),从而决定是否继续推理,这个操作会产生时间开销;
新版 vLLM 引入了异步输出处理,使得模型推理和输出处理异步进行,从而重叠计算的时间 [3]。
3.1 异步输出处理
在异步输出处理中,我们把模型输出从 GPU 端取到 CPU 端进行停止条件判定时,并不会让模型停止推理,等待判定结果从而导致空闲。在 CPU 端对第 n 个输出进行处理并判定是否停止的同时,我们在 GPU 端假设第 n 个输出尚不符合停止条件,并继续推理预测第 n+1 个输出。这样的设计可能会使得每条请求都多了一次推理,造成些许耗时,但与 GPU 空闲等待所浪费的时间相比就显得很划算了。
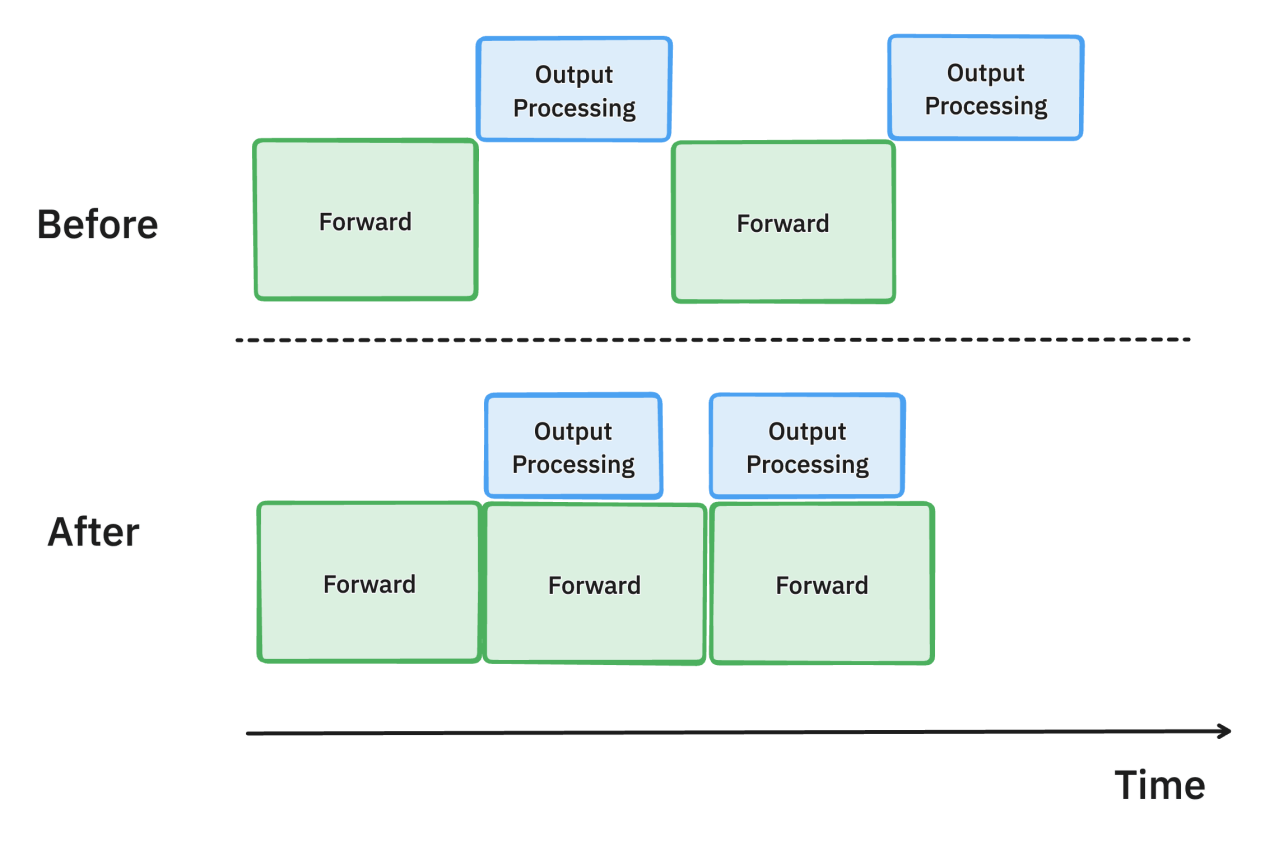
上:不启用异步输出处理; 下:启用异步输出处理。
据 vLLM 团队测试,4 张 H100 环境下运行 Llama 70B,异步输出处理的 TPOT 指标比禁用快了 8.7% [3]。
3.2 测试 &对比
我们对比启用和禁用异步输出处理的性能差异。在保持其他设置相同的情况下,设置服务端启动参数分别如下。vLLM 0.6.0 中默认启用该功能,可以通过设置参数--disable-async-output-proc 来手动关闭。
Bash #禁用/启用异步输出处理 vllm serve facebook/opt-125m \ --max-model-len 2048 \ --use-v2-block-manager \ --disable-async-output-proc #移除该参数则默认启用以下为测试结果 (左禁用异步输出处理,右启用异步输出处理):
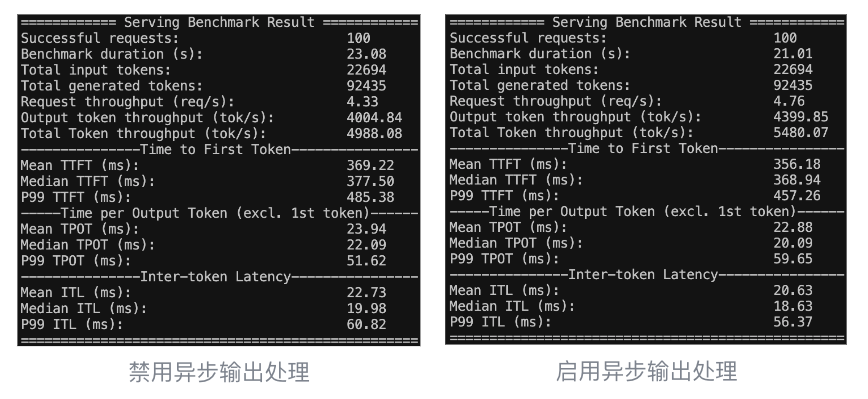
异步输出处理可以获得一些细微的性能提升,主要体现在 TPOT 和 ITL 上,约 5%左右,基本符合预期。
4 在优刻得模型服务平台-UModelVerse 体验新版 vLLM
4.1 创建并启动服务
打开 UCloud 控制台 (https://console.ucloud.cn/),登录账号。点击左上角的“全部产品”,从中找到“模型服务平台 UModelVerse”。
点击进入后,点击左侧栏目中的“服务部署”,并点击“创建服务”。
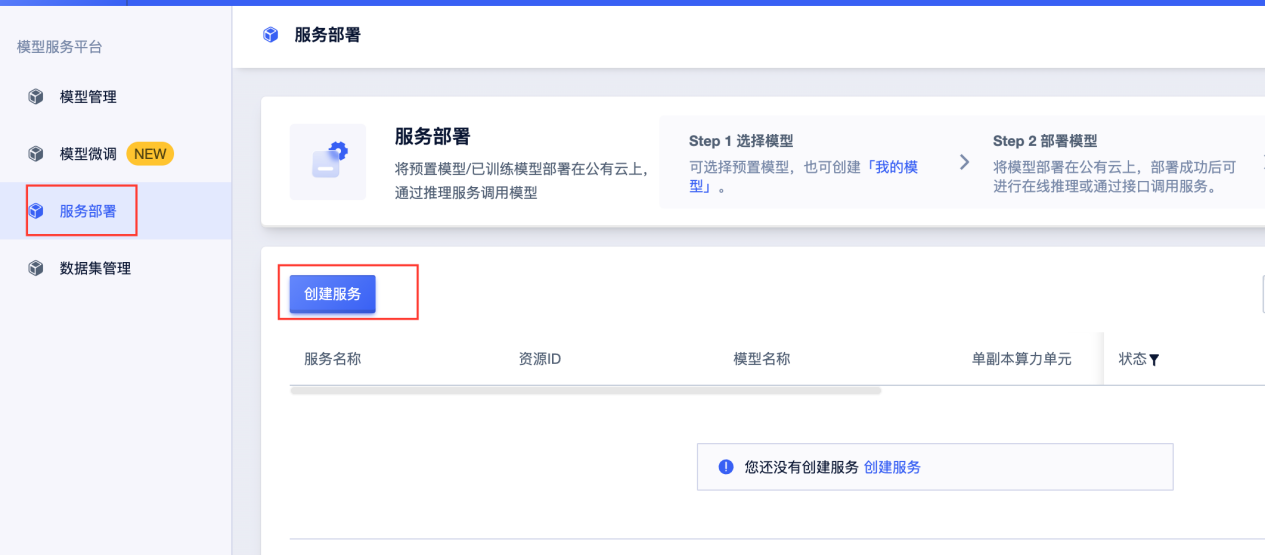
进入界面后,设置想要使用的模型并添加服务名称后,在右侧选择合适的支付方式,并点击“立即购买”,系统自动跳转到支付页面。
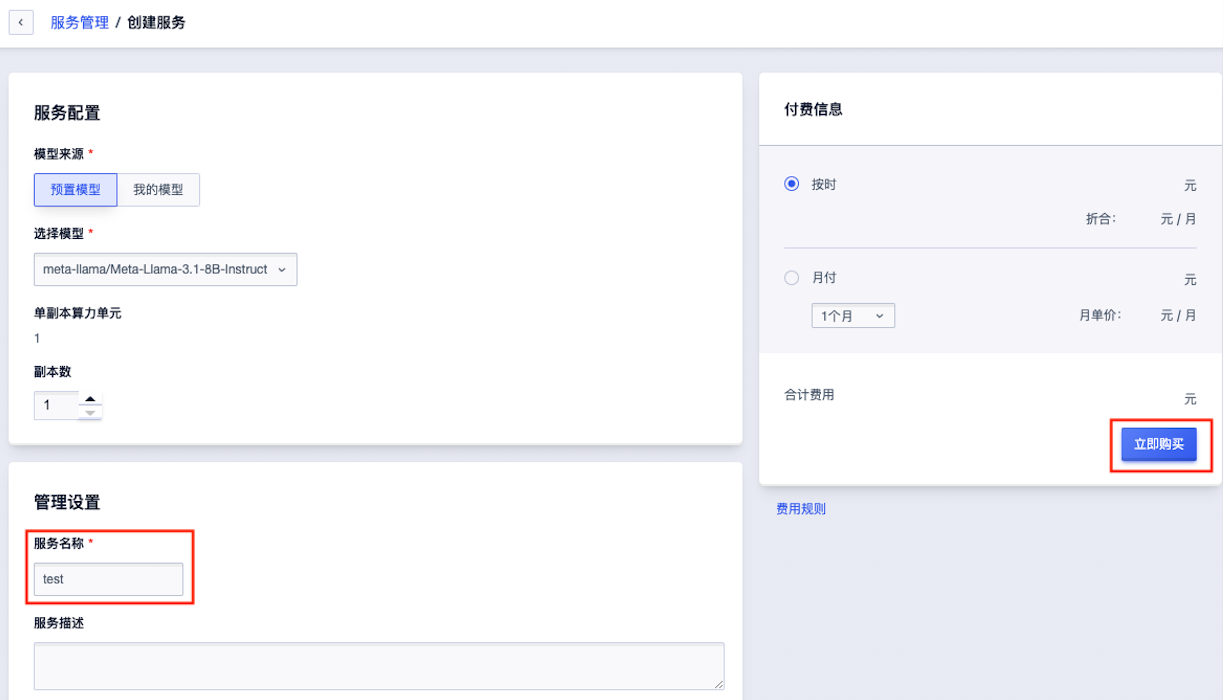
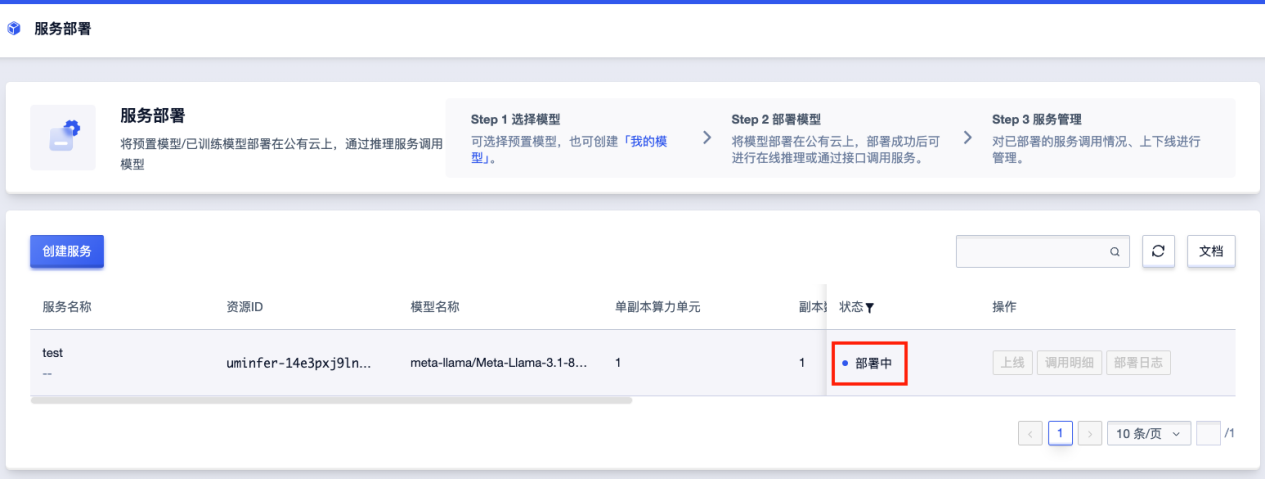
完成支付后,页面回到“服务部署”。可以看到我们购买的服务正处于“部署中”的状态,稍作等待......
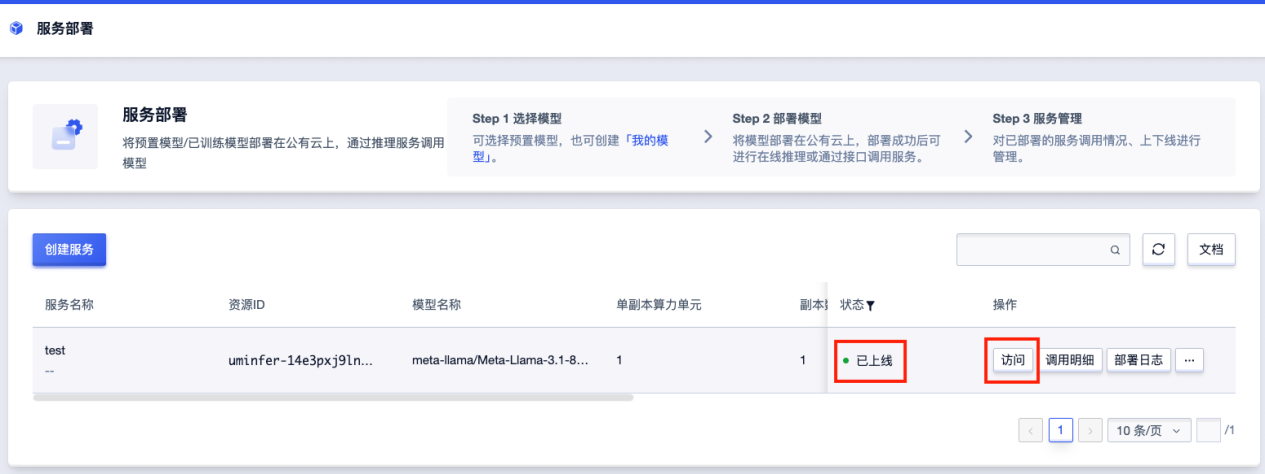
待状态转为“已上线”后,即可点击“访问”打开网页图形界面,或通过 API 调用。
4.2 使用服务
4.2.1 通过网页图形界面
点击“访问”即可进入与 chatbot 的图形对话页面:
4.2.2 通过 API 接口
当然,我们也可以通过 API 接口进行对话。以下是调用代码样例。调用的 API 参数可以在服务列表中找到。其中:
undefined API_KEY:即 API Key;
undefined BASE_URL:为 API 地址;
undefined MODEL:为模型的名称。


Pythonfrom openai import OpenAIAPI_KEY = 'aDZ39J204akIPPhmqQtLuf64CBA7ZbyQ0Ov88VzlPuBRjdvP' # API KeyBASE_URL = 'https://ai.modelverse.cn/uminfer-14e3pxj9lnfc/v1' # 模型URLMODEL = "meta-llama/Meta-Llama-3.1-8B-Instruct" # 模型名client = OpenAI( api_key=API_KEY, base_url=BASE_URL)# 调用模型生成文本response = client.chat.completions.create( model=MODEL, # 选择模型 temperature=0.5, # 温度,模型输出结果的随机性 max_tokens=512, # 最大tokens长度 messages=[ {"role": "user", "content": "你好呀,可以给我讲个笑话嘛?"}, ])# 获取并打印 AI 生成的回复print(response.choices[0].message.content)相关资料
[1] vLLM: https://github.com/vllm-project/vllm
[2] vLLM Highlights: https://github.com/vllm-project/vllm/releases/v0.6.0
[3] vLLM v0.6.0: 2.7x Throughput Improvement and 5x Latency Reduction: https://blog.vllm.ai/2024/09/05/perf-update.html
[4] vLLM benchmark source code: https://github.com/vllm-project/vllm/blob/b67feb12749ef8c01ef77142c3cd534bb3d87eda/benchmarks/backend_request_func.py#L283
[5]NVIDIA Nsight Systems: https://developer.nvidia.com/nsight-systems




