
前不久,我在 LearnML 子论坛上看到一篇帖子。楼主在这篇帖子中提到,他需要为自己的机器学习项目抓取网页数据。很多人在回帖中给出了自己的方法,主要是学习如何使用 BeautifulSoup 和 Selenium。
我曾在一些 数据科学项目中使用过 BeautifulSoup 和 Selenium。在本文中,我将告诉你如何用一些有用的数据抓取一个网页,并将其转换成 pandas 数据结构(DataFrame)。
为什么要将其转换成数据结构呢?这是因为大部分机器学习库都能处理 pandas 数据结构,并且只需少量修改就可对你的模型进行编辑。
首先,我们要在维基百科上找到一个表来转换成数据结构。我抓取的这张表,展示的是维基百科上浏览量最大的运动员数据。
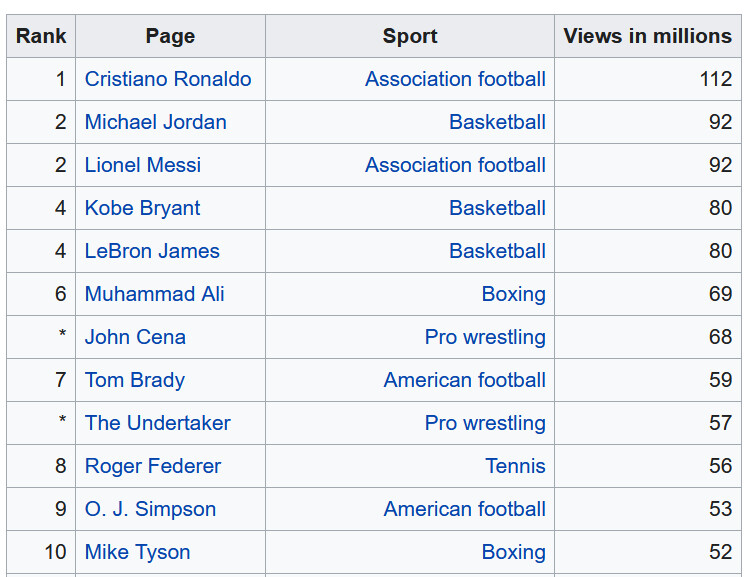
其中一项大量的工作就是,通过浏览 HTML 树来得到我们需要的表。
通过 request 和 regex 库,我们开始使用 BeautifulSoup。
from bs4 import BeautifulSoupimport requestsimport reimport pandas as pd
下面,我们将从网页中提取 HTML 代码:
website_url = requests.get('https://en.wikipedia.org/wiki/Wikipedia:Multiyear_ranking_of_most_viewed_pages').textsoup = BeautifulSoup(website_url, 'lxml')print(soup.prettify())</a></li><li id="footer-places-disclaimer"><a href="/wiki/Wikipedia:General_disclaimer" title="Wikipedia:General disclaimer">Disclaimers</a></li><li id="footer-places-contact"><a href="//en.wikipedia.org/wiki/Wikipedia:Contact_us">Contact Wikipedia</a></li><li id="footer-places-mobileview"><a class="noprint stopMobileRedirectTog
从语料库中收集所有的表,我们有一个较小的表面区域来搜索。
wiki_tables = soup.find_all('table', class_='wikitable')wiki_tables
因为存在很多表,所以需要一种过滤它们的方法。
据我们所知,Cristiano Ronaldo(也就是葡萄牙足球运动员 C 罗)有一个锚标记,这可能在几个表中是独一无二的。
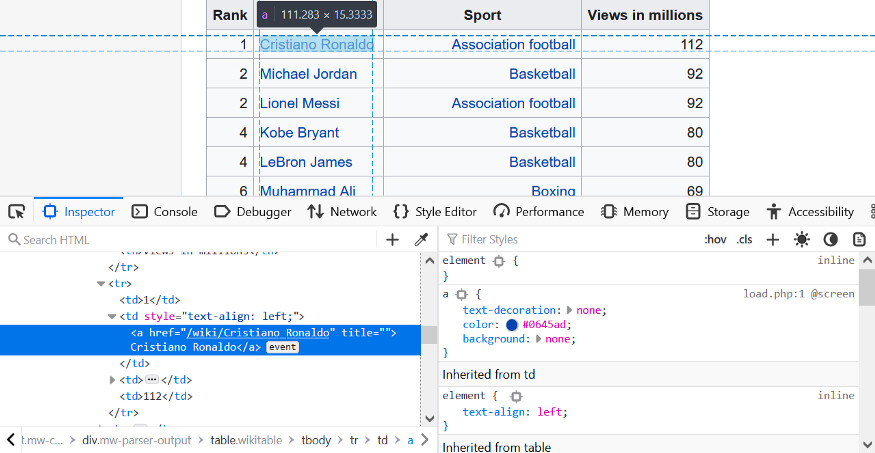
通过 Cristiano Ronaldo 文本,我们可以过滤那些被锚标记的表。此外,我们还发现一些包含这个锚标记的父元素。
links = []for table in wiki_tables:_table = table.find('a', string=re.compile('Cristiano Ronaldo'))if not _table:continueprint(_table)_parent = _table.parentprint(_parent)links.append(_parent)<a href="/wiki/Cristiano_Ronaldo" title="Cristiano Ronaldo">Cristiano Ronaldo</a><td style="text-align: left;"><a href="/wiki/Cristiano_Ronaldo" title="Cristiano Ronaldo">Cristiano Ronaldo</a></td><a href="/wiki/Cristiano_Ronaldo" title="Cristiano Ronaldo">Cristiano Ronaldo</a><td style="text-align: left;"><a href="/wiki/Cristiano_Ronaldo" title="Cristiano Ronaldo">Cristiano Ronaldo</a></td><a href="/wiki/Cristiano_Ronaldo" title="Cristiano Ronaldo">Cristiano Ronaldo</a><td style="text-align: left;"><a href="/wiki/Cristiano_Ronaldo" title="Cristiano Ronaldo">Cristiano Ronaldo</a></td>
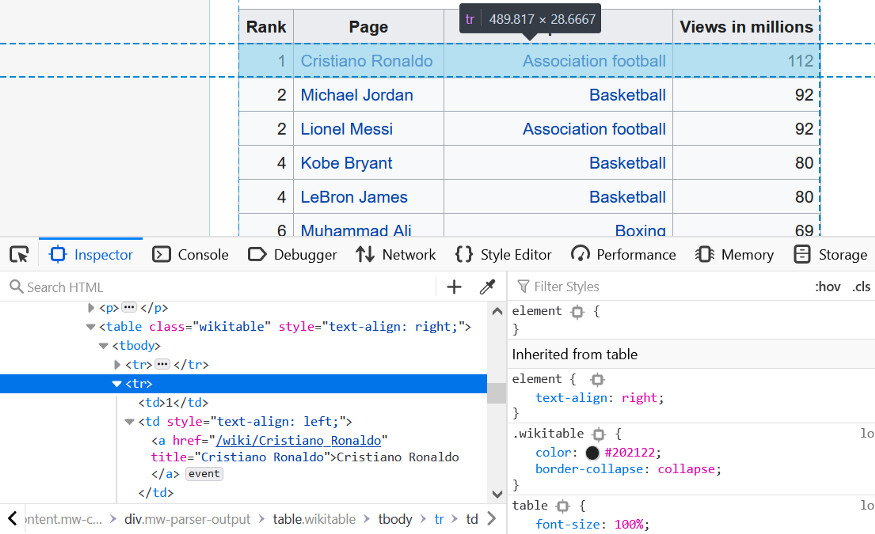
父元素只显示单元格。
这是一个带有浏览器 web 开发工具的单元格。
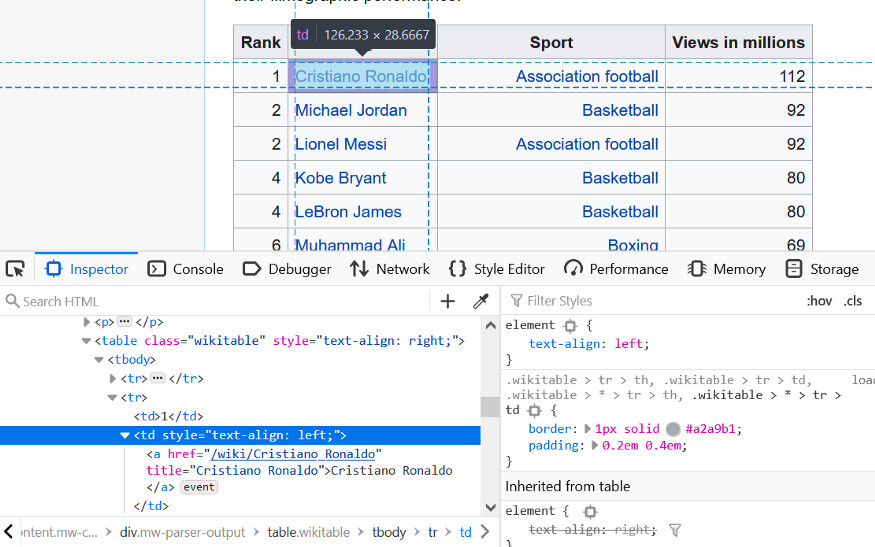
parent_lst = []for anchor in links: _ = anchor.find_parents('tbody') print(_) parent_lst.append(_)利用 tbody,我们可以返回包含以前的锚标记的其他表。
为进一步过滤,我们可以在以下表中的不同标题进行搜索:
for i in parent_lst: print(i[0].find('tr'))tr><th>Rank*</th><th>Page</th><th>Views in millions</th></tr><tr><th>Rank</th><th>Page</th><th>Views in millions</th></tr><tr><th>Rank</th><th>Page</th><th>Sport</th><th>Views in millions</th></tr>
第三张看起来很像我们所需要的表。
接下来,我们开始创建必要的逻辑来提取并清理我们需要的细节。
sports_table = parent_lst[2]complete_row = []for i in sports_table: rows = i.find_all('tr') print('\n--------row--------\n') print(rows) for row in rows: cells = row.find_all('td') print('\n-------cells--------\n') print(cells) if not cells: continue rank = cells[0].text.strip('\n') page_name = cells[1].find('a').text sport = cells[2].find('a').text views = cells[3].text.strip('\n') print('\n-------CLEAN--------\n') print(rank) print(page_name) print(sport) print(views) complete_row.append([rank, page_name, sport, views]) for i in complete_row: print(i)分解一下:
sports_table = parent_lst[2]complete_row = []
下面我们从上面的列表中选择第三个元素。这就是我们需要的表。
接下来创建一个空列表,用于存储每行的详细信息。在遍历这个表的时候,建立一个循环,遍历表中的每一行,并将其保存到 rows 变量中。
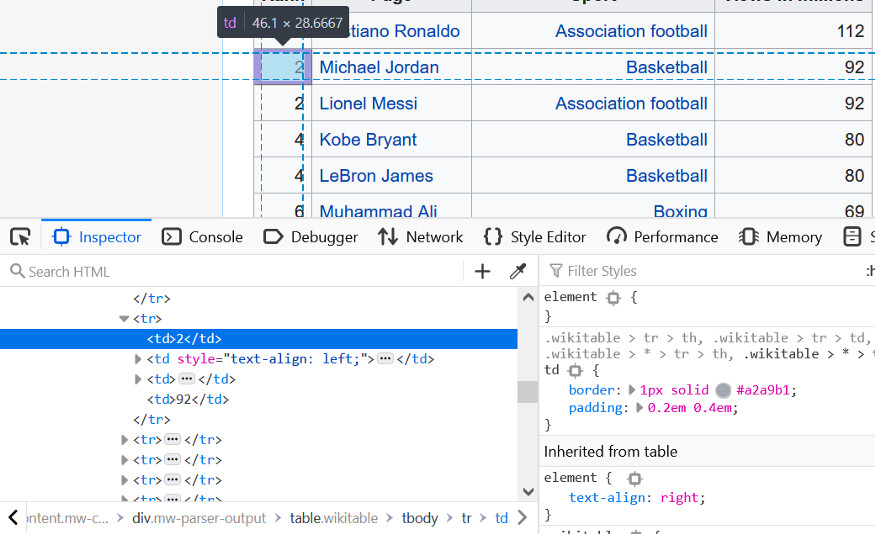
for i in sports_table: rows = i.find_all('tr') print('\n--------row--------\n') print(rows)
for row in rows: cells = row.find_all('td') print('\n-------cells--------\n') print(cells)
建立了嵌套的循环。遍历上一个循环中保存的每个行。在遍历这些单元格时,我们将每个单元格保存在一个新的变量。
if not cells: continue
这段简短的代码允许我们在从单元格中提取文本时,避免空单元格并防止发生错误。
rank = cells[0].text.strip('\n')page_name = cells[1].find('a').textsport = cells[2].find('a').textviews = cells[3].text.strip('\n')
在此,我们将各种单元格清理为纯文本格式。清除后的值保存在其列名下的变量中。
print('\n-------CLEAN--------\n')print(rank)print(page_name)print(sport)print(views)complete_row.append([rank, page_name, sport, views])
此处,我们向行列表添加这些值。然后输出清理后的值。
-------cells--------[<td>13</td>, <td style="text-align: left;"><a href="/wiki/Conor_McGregor" title="Conor McGregor">Conor McGregor</a></td>, <td><a href="/wiki/Mixed_martial_arts" title="Mixed martial arts">Mixed martial arts</a></td>, <td>43</td>]-------CLEAN--------13Conor McGregorMixed martial arts43
下面将其转换为数据结构:
headers = ['Rank', 'Name', 'Sport', 'Views Mil']df = pd.DataFrame(complete_row, columns=headers)df

现在你可以在机器学习项目中使用的 pandas 数据结构了。你可以使用自己喜欢的库来拟合模型数据。
作者介绍:
Tobi Olabode,对技术感兴趣,目前主要关注机器学习。
原文链接:
https://blog.devgenius.io/how-to-scrape-a-website-for-your-ml-project-c3a4d6f160c7




