
项目背景
代码审查是软件质量保证(software quality assurance)中至关重要的流程。通过代码审查,可以及早发现项目中存在的问题,规避项目风险,并保障项目的顺利进行。

一个具有普遍性的代码审查流程通常有下图所示的几个步骤:上传代码、预警系统检查、评审代码检查、系统集成测试等。
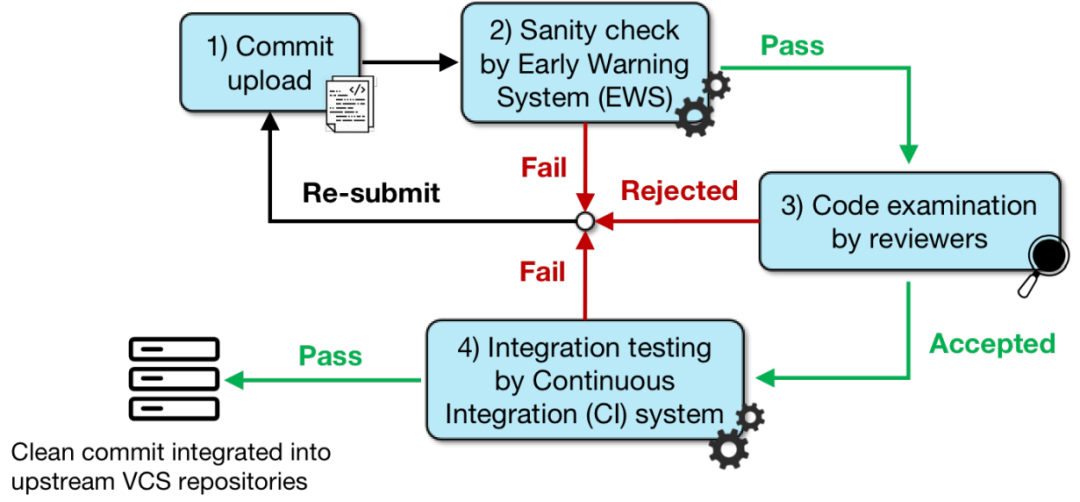
当开发者提交一次 commit 时,这个 commit 在被加入到主分支之前会经过多道自动或人工审查工序,若其中任何一道工序发现了问题,这次 commit 都会被退回开发者进行修改。上图中第三步,通常需要引入有经验的开发者对提交的代码进行人工审查,不仅成本高,速度也受限。
研究者们因此提出了即时缺陷预测(JIT-DP),旨在进行人工审查之前自动预测提交代码中存在缺陷的可能性,以合理分配和节省人力资源。
现存的 JIT-DP 方法
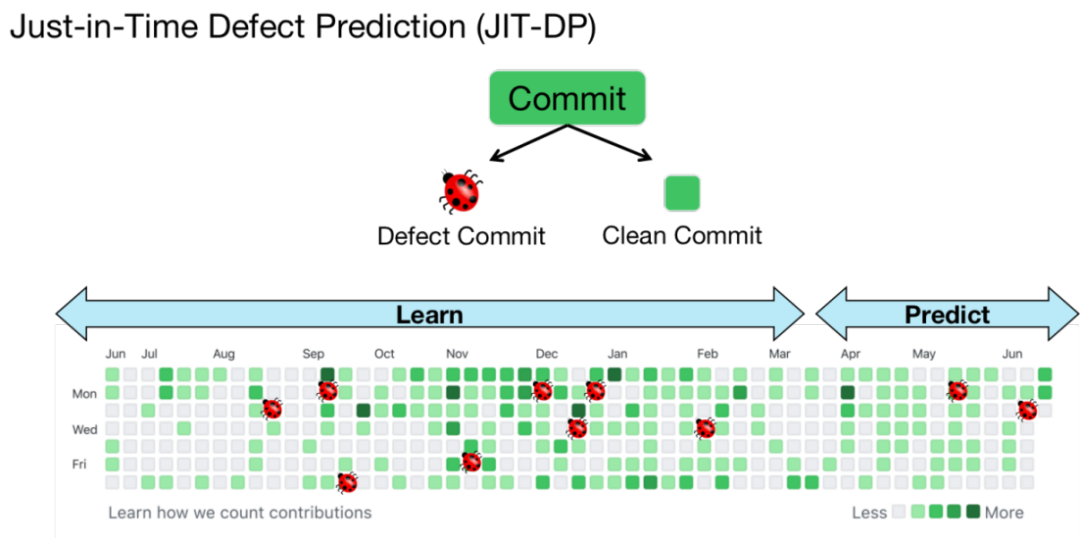
上图展示了进行即时缺陷预测的标准方法。其中,即时(Just-In-Time)表示进行缺陷预测的单位为一次 commit。在该方法中,每个历史 commit 会被标记为有缺陷(Defect)或无缺陷(Clean)。然后我们就可以在大量历史 commit 数据上训练一个机器学习模型用以预测未来的 commit 是否有缺陷。

此前,研究人员已经提出了各式各样的模型应用于 JIT-DP,其中最经典的是 Kamei et al 提出的 LR-JIT,他们从 commit 中提取了 14 种基础特征,例如 NF(修改文件数)、LA(增加代码行数)和 EXP(开发者经验)。在为每个 commit 提取出这些特征后,便可用 Logistic 回归分类器来对 commit 进行分类。
在 LR-JIT 的基础上,Yang et al 在特征和分类器之间添加了一层深度置信网络(DBN),用以提取 commit 特征更高维度的向量表示。
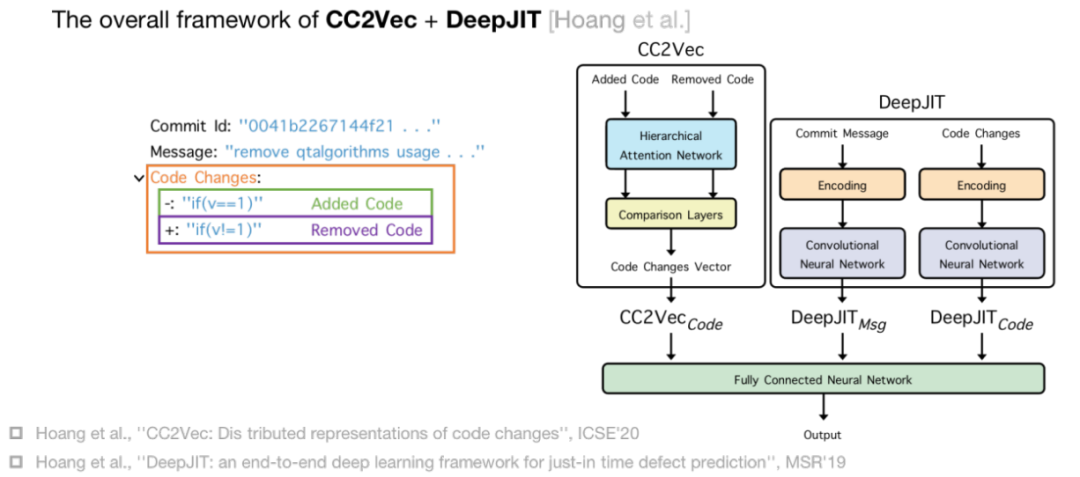
不同于前面两种基于人工特征提取的传统方法,近年来提出的深度学习方法多使用神经网络自动地从 commit 中提取信息,例如上图中的 CC2Vec 和 DeepJIT。
DeepJIT 以 commit 的 Message 和 Code Changes 作为输入,然后用两个卷积神经网络从向量化后的 Commit Message 和 Code Changes 中提取特征。
CC2Vec 则保留了 Code Changes 的结构信息。首先 CC2Vec 把 Code Change 分为 Added Code 和 Removed Code,再用一个层次注意力网络(HAN)分别提取 Added Code 和 Removed Code 的向量特征。然后用一个 Comparison Layers 对比 Added Code 和 Removed Code 的向量特征并生成总的 Code Changes 向量特征。最后,CC2Vec 和 DeepJIT 的特征可以结合起来以获得一个更强大的 JIT-DP 模型。
研究问题
CC2Vec 和 DeepJIT 在先前的研究中展示了超越 LR-JIT 和 DBN-JIT 的优异性能。但是由于先前的研究只采用了很小的数据集,并不能很好地展示 CC2Vec 和 DeepJIT 的泛用能力。
为了能对当前 JIT-DP 的进展进行详尽的评估,本文重点研究以下 4 个问题:
为什么 DeepJIT 和 CC2Vec 有用?
DeepJIT 和 CC2Vec 在更大的数据集下的表现如何?
传统的缺陷预测特性对 JIT-DP 的性能如何?
一个简单的方法能比 DeepJIT/CC2Vec 更好吗?
实验和分析
RQ1: 为什么 DeepJIT 和 CC2Vec 有用?
对于 RQ1,我们对 DeepJIT 和 CC2Vec 的三种输入的有效性进行了研究,即 CC2VecCode DeepJITMsg 和 DeepJITCode 。

为了研究 DeepJITMsg 的有效性,我们应用了 Grad-CAM 来可视化每个 Commit Message 单词对预测结果的贡献,如上图例子中单词的颜色越深则对结果的贡献越大。接着,我们对数据集中出现过多次的单词的贡献度进行加权平均并排序,可以发现“task-number”,“fix”,“bug”等词在所有 10000 个单词中排名相对较高。基于以上结果,我们可以推测 DeepJIT 和 CC2Vec 可以从 Commit Message 中提取 commit 的意图来协助进行缺陷预测。

而在研究 DeepJITCode 的有效性时,我们发现 DeepJIT 的实现并没有如原论文所描述的采用完整的 Code Changes,而是采用了一种抽象的 Code Changes 形式。如上图 Figure 3 中的例子,更改的源代码被 7 行 “added _ code removed _ code” 代替。
为了验证这两种 Code Changes 的有效性,我们把完整 Code Changes 训练的模型加了 Paper 后缀,把抽象 Code Changes 训练的模型加了 Github 后缀,并用这两种模型进行了复现实验。从表中的结果可以发现 DeepJITGithub 的 AUC 分数比 DeepJITPaper 高,对于 CC2Vec 也是如此。

为了验证 CC2VecCode 的有效性。我们对 CC2Vec 的三种输入特征进行了消融实验。
表 4 的前三行表示只采用单个 feature 的结果,后三行表示只移除单个 feature 的结果。
根据表 4 的结果我们发现 DeepJITMsg 和 DeepJITCode 对 JIT-DP 结果的贡献比 CC2VecCode 大。
RQ2: DeepJIT 和 CC2Vec 在更大的数据集下的表现如何?
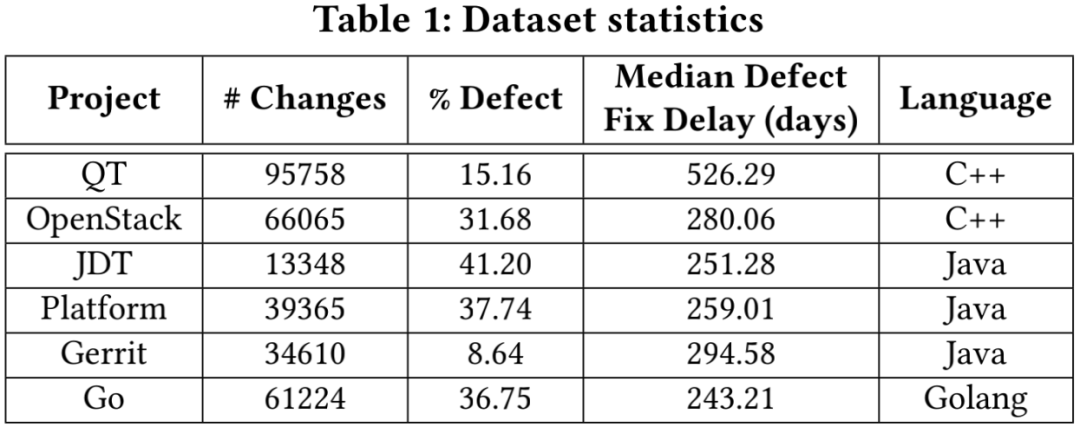
对于 RQ2,我们首先采用了 Kim et al. 和 McIntosh et al. 的数据处理流程(与 CC2Vec 和 DeepJIT 一致)收集了一个总共包含 310,370 个真实 commit 和 81,300 个缺陷的大型数据集。接着在该数据集上验证了 4 种 JIT-DP 方法在 within-project(WP)和 cross-project(CP) 场景下的性能。

对于表 5 的结果,我们可以观察到,CC2Vec 无法在大多数项目中保持与 DeepJIT 相比的性能优势,如 JDT,Platform 和 Gerrit。因此,我们认为 CC2Vec 在扩展的数据集中不能显著地优于 DeepJIT。另外,我们也发现即使 DeepJIT 和 CC2Vec 的平均结果要优于 LR-JIT 和 DBN-JIT,但在 OpenStack 中 LR-JIT 和 DBN-JIT 的 AUC 结果确要优于 DeepJIT 和 CC2Vec,因此 DeepJIT 和 CC2Vec 不能保证全面优于传统方法。
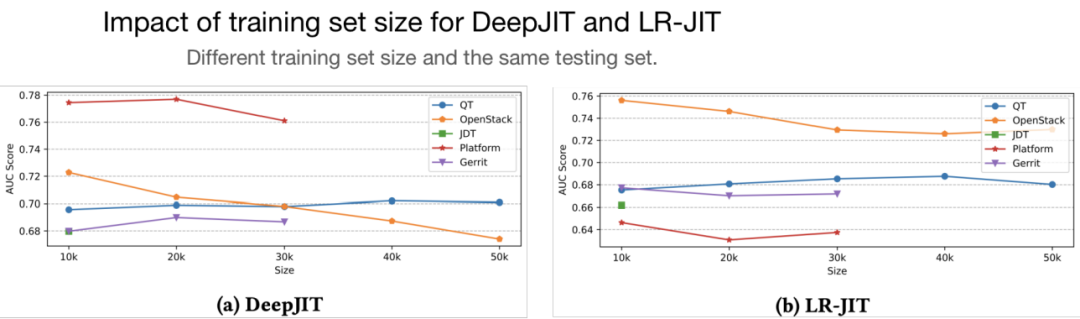
为了探究软件迭代过程中缺陷模式变动对 JIT-DP 的影响,我们进一步研究了 JIT-DP 模型在不同大小的训练集下的性能差异。
上图表示了 DeepJIT 和 LR-JIT 在不同大小的训练集下 AUC 变化趋势。总的来说,随着训练集的增大,两种方法的预测准确度呈现出波动状态。该实验结果表明简单的引入更多历史数据来增大训练集大小并不能保证 JIT-DP 模型性能的提升。
RQ3: 传统的缺陷预测特性对 JIT-DP 的性能如何?
RQ1 和 RQ2 的实验发现展示了一下几个事实
DeepJITCode 对预测结果的贡献最大。
在 CC2Vec 中,更多的输入特征有时甚至会导致性能下降。
基于深度学习的方法并不能保证在所有的实验项目中都优于传统方法。
这些事实表明,JIT-DP 传统方法中的不同特征的有效性还没有被充分研究。因此,我们在上图展示了每个具有代表性的传统特征在 JIT-DP 中的性能。
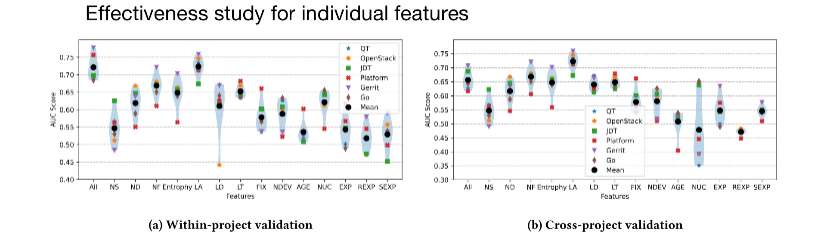
从图中我们可以发现只用“LA”特征的模型在 QT,OpenStack 和 Go 上优于采用所有特征“ALL”的模型。并且在 cross-project 场景下,“LA”特征模型的性能下降要小于采用其他特征的模型。这意味着只采用“LA”特征就可以构建一个准确度高且稳定的 JIT-DP 模型。
RQ4: 一个简单的方法能比 DeepJIT/CC2Vec 更好吗?
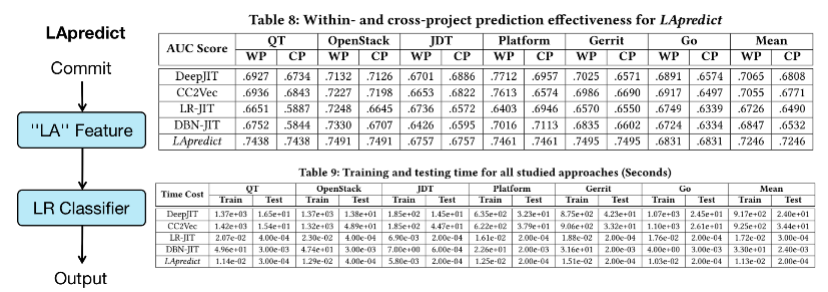
基于先前的发现,我们提出了一个简单的 JIT-DP 方法 LApredict,该方法简单的采用了“LA”特征和 Logistic 回归模型来进行 JIT-DP。并在扩展数据集上进行了验证。
表 8 中的结果表明 LApredict 在基本上优于其它 4 种方法。表 9 中的结果表明由于极简结构,LApredict 的训练时间和测试时间几乎可以忽略不计。因此,LApredict 可以在性能和效率上都优于深度学习的 JIT-DP 方法。
影响和讨论
本研究为未来 JIT-DP 研究提供了以下重要且实用的指导方针:
深度学习并不总是有帮助
研究显示,尽管深度 JIT-DP 方法在某些情况下可以取得进展,但它们相当依赖于数据,在不同的数据集 / 场景下效果有限。此外,深度学习技术的速度可能比传统分类器慢几个数量级。我们强烈建议研究人员 / 开发人员对未来的深度 JIT-DP 方法进行全面评估。
简单的特征也能有很好的效果
研究表明,简单的“LA”特征加上简单的分类器就能够取得很优异的结果,这种简单的方法应该作为一个基准被所有未来的 JIT-DP 研究所考虑。
Commit Message 对 JIT-DP 是有帮助的
研究结果表明,Commit Message 中的某些关键词对于深度 JIT-DP 有相当大的帮助,因为它们可以传达特定代码的意图。这表明,对 JIT-DP 感兴趣的开发者/团队应该保持严格的规则来起草提交消息,以助于 JIT-DP 的研究。
训练数据的选择十分重要
研究表明,简单地增加训练数据并不能提高传统或深度 JIT-DP 方法的预测精度。另一方面,在不同的基准 / 场景下,想要人工选择信息量最大的训练集以优化预测精度是相当有挑战性的。因此,我们建议研究人员 / 开发人员考虑完全自动化训练数据的选择方法。
未来的研究中需要考虑 Cross-Project 验证
实验结果显示,现有的传统 / 深度 JIT-DP 方法在转为 Cross-Project 验证时,性能有所下降,这样的结果激励着未来的研究人员提出更多稳健的 JIT-DP 方法。
论文链接:




