
有报道称,卡塔尔世界杯可能是压垮 Twitter 的最后一根稻草。一位离职的 Twitter 员工对外媒表示,Twitter 有 50%的概率会在为期 29 天的世界杯期间发生重大服务中断。他认为,Twitter 在世界杯期间肯定会发生一些事故,比如服务响应缓慢或错误,用户能看到的概率有 90%。
当被问及 Twitter 有什么计划来解决世界杯期间可能出现的问题时,他说:“据我所知没有。我们本应该在几周前就开始准备了。”
关键运行团队离开,Twitter 故障问题初显
曾应对过 2014 年世界杯的 Twitter 前软件工程师 John Ioannidis 表示,即使拥有最好的设备和硬件,突然涌入的流量也会造成问题。根据 Ioannidis 介绍,2014 年巴西世界杯时, Twitter 一直在监控自己的基础设施,以确保整个世界杯期间保持在线。据悉,2010 年世界杯期间,Twitter 就因无法应对高流量而下线。
对比赛期间可能出现的高流量,萨里大学网络安全教授 Alan Woodward 感到十分担忧,“Twitter 现在似乎在赌运气,根据我的经验,这不是一种可靠的方法。”
而实际上,在世界杯开始前,已经有迹象表明 Twitter 背后错综复杂的基础设施已经出现问题,如转发无法正常使用、双重身份验证报错致难以登陆、保存的草稿莫名被删除等。
当然,造成这些担忧和问题的直接原因就是现在的 Twitter 确实没有足够的工程师来进行准备和维护工作。据媒体称,Twitter 负责流量高峰期管理网站的团队已经有三分之一的工程师离职,另外 Twitter 核心系统库的团队也已经解散,有前员工形容“没有这个团队,你就无法运营 Twitter。”其他如前端团队、API 团队等也都没有幸免于难。
“我知道有六个关键系统(比如推送的关键系统)已经没有任何工程师了”,有 Twitter 的前员工表示,“这个系统甚至不再有骨干人员。它会继续自动运行,直到遇到什么东西,然后就会停下来。”
实际上,在3500 名员工被裁、2000 多人主动离职后,Twitter 原来维护网站正常运行的几个关键团队都部分或全部解散。其中,在马斯克发出“最后通牒”后辞职的员工中,许多人是 Twitter 最有经验的员工,甚至有些人在 Twitter 工作的时间是这家公司存在时间的一半。
有 Twitter 员工透露,由于目前维护关键服务的全天候轮班员工不够用,这部分员工已经开始外出“借人”,试图通过培训公司其他部门的同事来帮助减轻工作量。另一方面,马斯克的“铁血裁员”也落下了帷幕,目前开始正在招聘工程师和广告销售人员。“在关键的招聘方面,我想说那些擅长编写软件的人是最优先的。”马斯克在最近的全体员工大会上表示。
“最优秀的人都留下来了,所以我不是特别担心。”马斯克 18 日发推说道。
虽然马斯克很乐观,但网上很多开发者认为 Twitter 出现故障在所难免。“他(马斯克)有从根本上改变堆栈的宏伟愿景。他的更改不会有适当的测试,因为所有高级工程师都离开了,他的 SRE 员工不在那里监控新功能或进行容量规划。所以剩下的很多将是拥有 H1B 签证的工程师,他们不能离开,无法反驳马斯克的要求,而且会过度劳累,变得足够‘硬核’,无情地工作、精疲力尽、不做应有的努力。Twitter 将出现一些重大中断,过去处理过这些事件的大多数人都离开了。因此,这将比我们以往看到的任何情况都更严重、持续时间更长。”
当然也有开发者表示,“如果什么都不改变,那么什么都不会破坏。我想如果有什么问题的话,他们会在部署新东西同时不破坏其他功能时遇到问题。问题将发生在开发服务器上,而不是生产服务器上。”
伦敦大学教授 Steven Murdoch 认为,Twitter 将难以处理复杂的故障。他表示,即使公司雇用新员工或重新分配现有员工的任务,而且交接过程顺利,这些人了解相关系统的工作方式也可能需要几个月的时间。
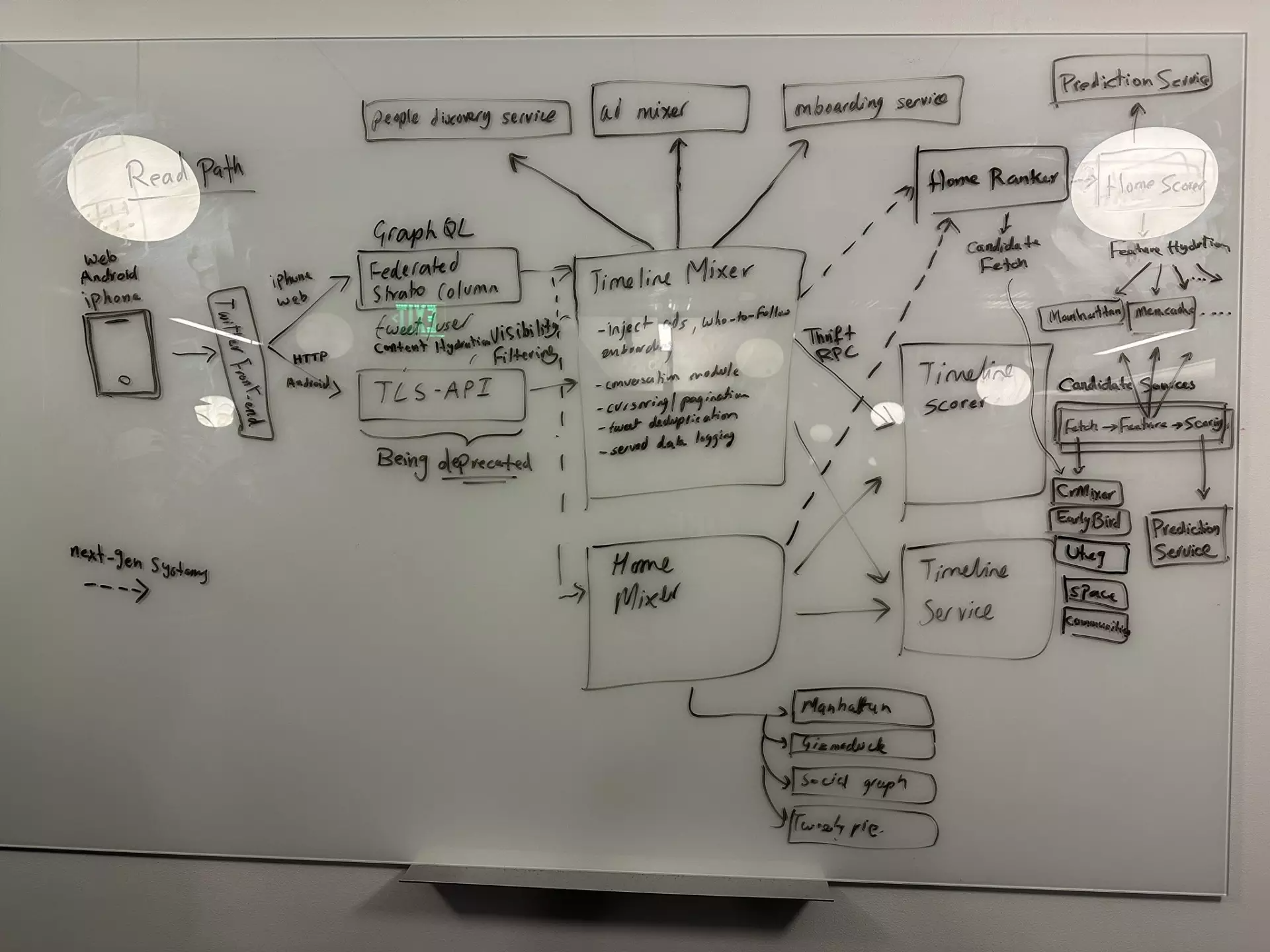
马斯克发布的 Twitter“架构图”
为什么还没有宕机?
从硬件到软件/代码,可能导致 Twitter 宕机的原因有很多。一位拥有 10 年以上行业经验的 SRE 总结了五十多个影响因素,包括简单错误代码问题、硬盘驱动器已满,到大型活动、外部攻击等等。
虽然现在有问题出现,但 Twitter 还可以继续运行,新的推文仍不断涌现。在 Twitter 工作五年的站点可靠性工程师(SRE) Matthew Tejo 在自己的文章中介绍了 Twitter 至今没有宕机的原因:前期大量投入的自动化设施。Matthew 有四年的时间是 Twitter 缓存团队里的唯一 SRE,负责自动化、可靠性和运营工作,设计并实现了大部分保持功能运行的工具。
缓存承载着用户在网站上看到的大部分内容。推文、所有时间线、直接消息、广告、身份验证等,都是由缓存团队的服务器负责提供。一旦缓存出现问题,用户会立刻受到显性影响。
Matthew 加入团队后的第一个项目,就是将退役的旧设备换成新机器。当时根本就没有相应的工具或者自动化选项,Matthew 拿到的只有一份标记着服务器名称的电子表格。不过现在好缓存团队的运营已经升级完毕,不再像当初那么粗糙。
Matthew 介绍,Twitter 保证缓存运行的头号大事,就是把它们放在 Mesos 上以 Aurora 作业的形式运行。Aurora 会找到运行应用程序的服务器,Mesos 则将所有服务器聚合起来以供 Aurora 感知。Aurora 还会在应用程序启动后保持其运行。如果说一个缓存集群需要 100 台服务器,那 Aurora 就会尽量保持这 100 台全部运行。
如果服务器出于某种原因而断开,Mesos 能及时检测到问题,将有问题的服务器从聚合池中删除,这时候 Aurora 会知道只有 99 台缓存服务器在运行。于是,Aurora 会自动再找台服务器接入,将总数恢复到 100。整个流程全面自动化,无需任何人为参与。
在 Twitter 数据中心,服务器被安置在机架当中。机架上的服务器通过交换机设备与其他服务器连接。再往外走,这些设备再通过交换机和路由器继续扩展,最终建立起完整的复杂系统、接入互联网。单个机架可以容纳 20 到 30 台服务器。其中机架可能发生故障、交换机可能损坏、电源也可能宕掉,导致全部 20 台服务器陷入停机。
Aurora 和 Mesos 另一大优势就是确保不会把太多应用程序放进同一个机架。这样即使整个机架突然停转,Aurora 和 Mesos 也能找到新的服务器并把应用负载转移过去,不致影响到用户感受。
“在我之前提到的电子表格里,还记录着机架上的服务器数量。能感受到,前任管理员在努力保证每个机架上别塞进太多服务器。而现在我们有了更强大的工具,能够持续追踪每一台新接入的服务器,所以整个流程就更顺畅了。这些工具能够确保团队在各机架上均衡部署物理服务器,而且一切都会以故障发生时不致引起大麻烦的方式进行排布。”Matthew 表示。
不过,Mesos 没办法切实检测到每一项服务器故障,所以 Matthew 团队还得对硬件问题进行额外的监控,关注磁盘和内存损坏之类的问题。这些情况不一定会拖垮整台服务器,但却往往导致其运行缓慢。“我们有一个警报仪表板,可以扫描损坏的服务器。一旦检测到某服务器发生问题,我们会自动创建一项修复任务,引导数据中心的运维人员前往查看。”
缓存团队还掌握着另一款重要软件(服务)用于跟踪缓存集群时间。如果在短时间内有大量服务器被标记为宕机,则要求关闭缓存的新任务将被拒绝,直到恢复安全。Matthew 团队希望通过这种方式避免整个缓存集群被关闭,进而拖垮受其保护的服务体系。
他们还解决了警报太多而无法快速关闭、无法通过一次维护解决的大规模报错、Aurora 找不到足够的新服务器来容纳旧任务等各类问题。“要为检测到的损坏服务器创建修复任务,我们首先会检查这项服务来确定能否安全删除其中的作业。在损坏服务器被清空之后,即会获得安全标记,由数据中心技术人员前往处理。处置完成、标记切换为已修复之后,我们会再次使用工具查找并自动激活该服务器,让它重新承载和运行作业。整个流程中,唯一需要的人手就是数据中心内的运维技术人员(不知道他们还在不在岗)。”Matthew 介绍道。
另外,重复申请的问题也得到了解决。之前的一些 bug 会导致无法重新添加新的缓存服务器(启动时出现了竞争条件),有时候可能需要长达 10 分钟才能重新添加服务器(O(n^n) 逻辑)。有了自动化系统处理后,团队不致于被迫选择手动操作。当然,还有其他自动修复设计,例如在某些应用程序指标(例如延迟)处于异常值时自动重启任务。
Matthew 表示,“缓存团队每周大概会积累下一页的故障报告,但几乎不出过什么大问题。大多数情况下,我们就在那里静静值班、静静下班,啥事都没发生。”
容量规划也是 Twitter 平台仍在正常运行的重要原因之一。Twitter 有两个持续运行的数据中心,负责承载整个站点的故障。Twitter 的每一项重要服务都可以在其中一处数据中心内单独运行,意味着随时都有 200%的可用容量储备。当然,这是在灾难恢复的场景下;大部分时间里,两处数据中心会把闲置资源拿来承载业务流量,且利用率最多不超过 50%。
即使如此,整个运行实践也非常繁忙。当 Matthew 团队计算自己的容量需求时,要先确定一处数据中心需要多少设备来承载全部流量,再以此为基础额外增加净空。所以只要不在故障转移期内,就会有大量服务器空间用于承载额外流量。数据中心发生整体故障的情况非常罕见,Matthew 任职的五年中只经历过一次。
缓存团队还把缓存集群剥离开来,并没有选择用单一多租户集群来承载所有服务,而是在应用程序层级进行隔离。这点非常重要,因为一旦某个集群出现问题,它的爆炸半径也只在自身范围内,即仅影响处于同一位置的部分服务器。同样地,Aurora 会提供缓存分布,尽可能控制影响范围,最终监控并及时加以修复。
“所以大家应该知道了,我们这帮家伙可没有偷懒。我们跟缓存即服务团队随时交流,尽量推动自动化流程,研究了不少有趣的性能问题,尝试引入能改善体验的技术,并推动了一系列大型成本节约项目。我们进行容量规划、确定需要订购的服务器数量,总之挺忙的。反正,我们不像很多人想象的那样天天摸鱼、打游戏就能拿高薪。”Matthew 在文章最后打趣道。
“恰恰相反,该网站在如此大规模裁员后仍能全面运行这一事实证明了参与维护基础设施的每一位专业人员都表现卓越!”有网友评价道。
参考链接:
https://threadreaderapp.com/thread/1593541177965678592.html
https://matthewtejo.substack.com/p/why-twitter-didnt-go-down-from-a




