
Stable Diffusion 2.0 和 Meta 的 Galactica 或许体现了人工智能的两个异端。
“即时工程”与“生成式人工智能”风靡一时,那为什么 OpenAI、Stability AI 等其他公司的创始人都如此痛恨它们呢?通过探寻近期新闻,我们会对关键词描述和生成式人工智能背后的东西有些深入了解。
Stable Diffusion 2.0
昨天发布的 Stable Diffusion 2.0 引发了不小的 高潮。除了新增的像素提高、修复及深度引导功能外,SD2 相比 SD1 要更强调 FID 和 CLIP 分数曲线的优化。
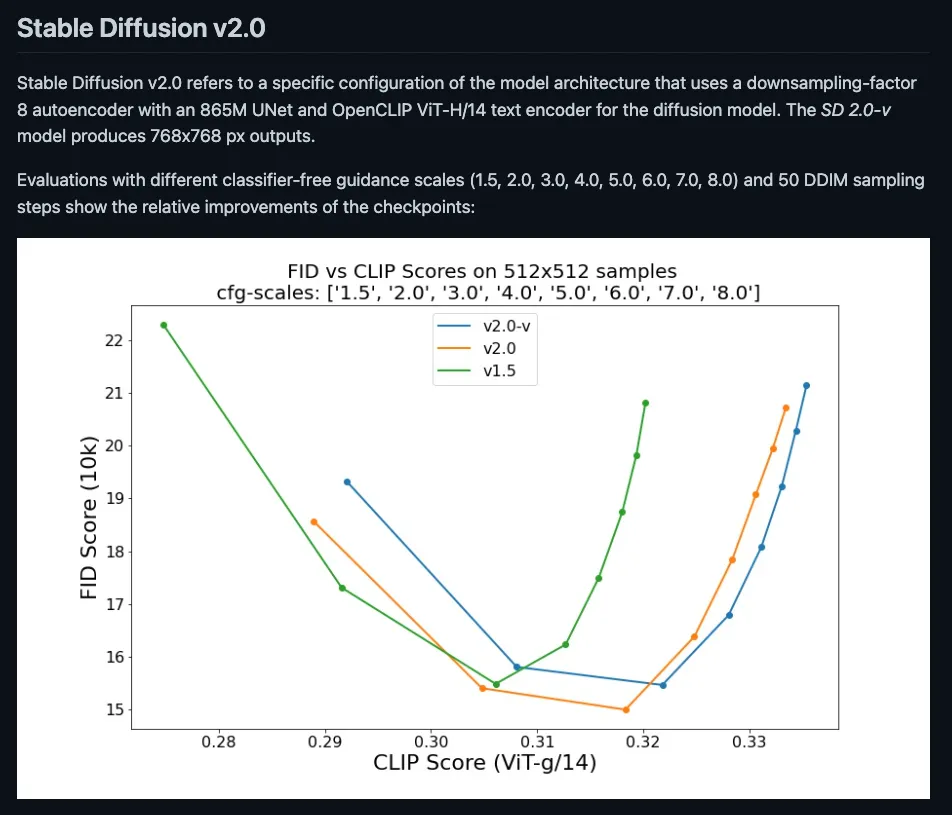
图源 GitHub 上 Stable Diffusion 2.0 的 README
但实际使用的用户却有不同的看法:
他们削弱了模型。
不明白为什么 2.0 发布的评论区那么激动做什么。这是退后的一大步,SD 可能再也恢复不过来了。
2.0 发布的评论区都没有见过 2.0 出的结果,在公告的博文中几乎没有任何配图。然后大家都以为这次肯定很强,就因为 2.0 是比 1.5 要大的数字。
新 SD 模型是失败的。他们搞砸了关键词、阉割了所有版权相关、有名的,以及稍微沾边黄暴的东西。如果在他们最初撤回 1.5 权重是还没看见墙上的字,那你现在应该能看见了。下一个竞品什么时候来?
看起来最糟糕的是 Stability 不尊重他们的用户,用户花了好几个月练习使用关键字描述,结果现在却毫无预警地直接被干掉了。
你得开始把即时工程看做是一种编程语言。没有哪个想发布一种编程语言的、脑袋正常的公司会在最初的成功之后完全毫无预警地把它给干掉。
红迪 和 推特 上都有对主要功能的解读,但他们最大的变化是先前 OpenAI 的 CLIP-L14 模型(发布于 2021 年一月)切换为 LAION 的 OpenCLIP Vit-H14(发布于 2022 年九月,“polar bear Hong Kong UFO”LAION 的先导图片,2022 年五月训练于 LAION-5B)。也就说,我们从一个属性无从得知的黑盒(比如某张生成的图片有多少波兰艺术家“greg rutkowski”的成分),换成了带有 CLIP 检索(以及“我是否被用作了训练”),但同时也打破了不少期望【注 1】。
当然,对于多数的 Stable Diffusion 用户来说,只要能有结果生成,他们并不关心其中具体细节。因此,在感恩节期间,人们还是尽心尽力地在生成 SD1 和 SD2 的对比图。
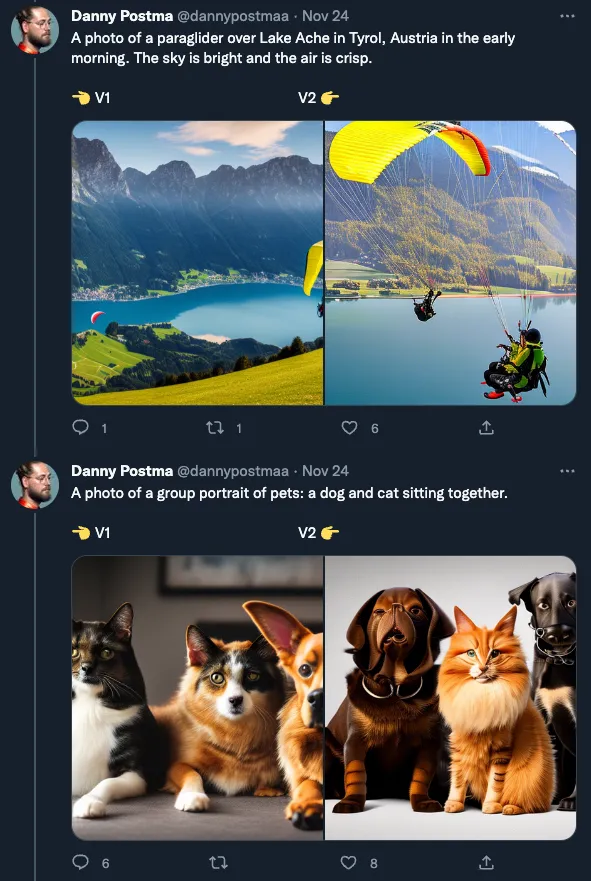
@dannypostmaa
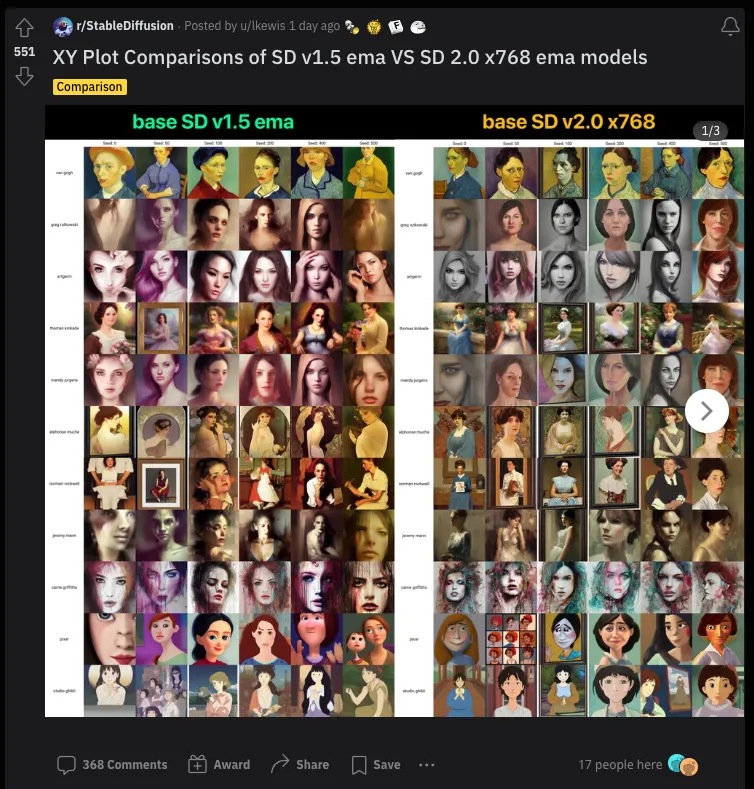
/u/lkewis

@AddyOsmani
如果你在仔细看了半天还是找不出来 SD2 到底比 SD1 强在哪,你不是一个人。别忘了,SD 2.0 的官方公告封面就是一张风景图,可能在暗示这次 Stability 的宣发重点,也可能是想把公众注意力移开这次不太好的区域,比如黄暴的、名人,以及可能会被当代画手起诉 Stability AI 公司的部分。
既然如此:
判断一张生成图像的“好坏”是非常主观的,而且很难在字面意义上无边无界的隐空间内量化。目前来说 FID 分数是最好的手段了。
关键词描述是移动的靶子。同样一句话能在 SD1、Midjourney 3、Midjourney 4、Dall-E 2,以及 SD2 上生成不同的东西,用户会找到各种能提升结果的神奇关键词以及更好的训练方式(更多地使用 负面词汇,但这点 在 SD1 里就已经存在 了。11 月 29 日更新:Minimaxir 上更多内容)。也就是说,虽然 SD2 现在看起来“不如”SD1,但或许随着用户的学习使用,情况会有所改善。
SD2 大概只会被当作是另一个完全不同的模型,而不是 SD1 的更新版。部分 SD 应用已经“回退到 SD1”,希望 SD2 能被添加到越来越长的“SD 变种”清单上(单子很长建议到 我的这篇文章 里看)。
“即时工程”是个异味项目
用户的不满时可以理解的,但切换模型导致关键词”不好使“这件事对任何有技术基础的人来说都不应该是个新鲜事。这是由于我们不知道或者无法去沟通我们真正想要的东西,以及模型无法从低带宽的文本中推断人类意图,从而造成的默认的、偶发复杂性的现象【注 2】。
这对一般爱好者而言仅仅是不顺心,但在商业层面来说却能带来严重威胁:
如果你的人工智能产品是基于“小时 / 天 / 周”的即时工程,那三个月后的另一款热门 AI 一发布,你的知识产权就可能要完蛋了【注 3】
更糟的情况是,你的 IP 遭到 关键词注入攻击 而泄露。目前这点只影响 GTP,但 SD2 明显在文本渲染方面有所提升,也许未来 SD3 或其他混合模型也能做到全文本渲染,从而导致关键字知识产权的泄露
也可能只是暴露了你在尝试搞出政治正确的输出时的 笨拙过程,让你尴尬而已
在当初 GPT-3 的狂潮中,Karpathy 将即时工程命名为“Software 3.0”,但最近风向有所偏转:
“即时编程难在表达你想要的东西,这是一种玄学,比如“在 artstation 上流行 + 虚幻引擎 + 超高分辨率”。Software 3.0 上这些明确的指示直接就能用。”— Gwern Branwen
以及:
“在五年后我不认为我们还会继续做即时工程……希望我们骇入即时工程的方式不是通过在句尾加上一个能改变一切的神奇关键词。真正有意义的应该是明白你想要什么。艺术家们擅长图片生成不是因为他们找到了那个句尾的关键词,而是因为他们能用我所没有的创造性眼光来阐述自己想要的。— Sam Altman
以及:
“即时工程就像是在泰坦尼克号的甲板上排列桌椅。人们越早加入我和 @ylecun,就越能意识到真正的智能不会只来自于 #GPT-3。”— Gary Marcus
以及更平衡的观点:
不断迭代关键字直到模型能给出一个满意的结果,这种行为是默认了模型的失败。随着模型变得普遍智能,它们会拥有无需人类介入控制输入,就能达成预期的能力。……另外,我们其实也见过这情形:关键字几乎就是另一种形式的超参数调整。当初用 sklearn 调整超参数,从而让传统机器学习派上作用,现在随着模型本身愈发优秀,这种方法基本已经没落了。— Joseph Nelson
彻底抛弃关键词实质上是在解决一个有限子集的对齐问题,又称作 强人工智能困难。不过,或许我们能有办法巧妙地把关键词隐藏起来。
GitHub Copilot 的成功中有一个被低估的因素(见播客),那就是团队是花费了数月时间才找到影响因素的正确形式:零次学习,内嵌式,默认体验中上下文感知自动完成而无需任何按键的同时,可以按需提供可探索的备选边栏。
Nathan Baschez 的 Lex.page 对文本有类似的处理,不过使用了 ++ 键来触发迭代,除此之外没有单独的提示文本框。这两个例子告诉我,将提示包含在用户界面之中,让“隐形”成为可能的同时,尽可能地针对文本上下文对输出精调,让这个功能更有用。延迟很重要,成本很重要,但这些往往是“常规工程”那一类的问题,而不是人工智能问题。
被低估了潜力的“生成式人工智能”
生成式人工智能这一热词正给我们带来了不少优秀梗图:

生成式人工智能这,生成式人工智能那,你怎么不先生成点利润呢?
恰恰相反,生成式人工智能确实在赚钱:小道消息 称,近期宣布 其 15 亿美元 A 轮融资的 Jasper 有 8 千万美元 ARR;Midjourney 有 5 千万美元 ARR;Stability 则是 4 千万美元 ARR【注 4】。
尽管如此,它的主要受益者们仍对“生成式人工智能”这一词不太感冒,这现象大概是非常的罕见了。
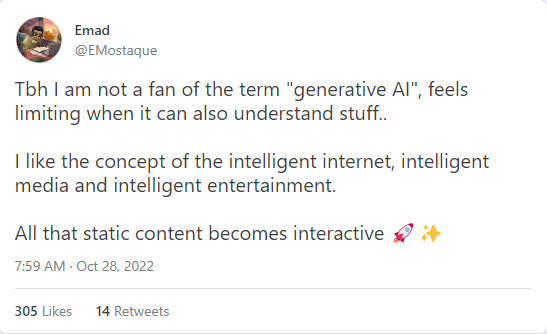
老实说我不太喜欢“生成式人工智能”这词,这个词感觉很有限,实际它是能有理解力的。我喜欢智能网络、智能媒体以及智能娱乐这些概念。让所有这些静态内容都能互动了。
科技界的山寨造图厂(Base10,Sequoia,a16z)大概是要失望了,尽管生成式人工智能在今年大放异彩,但商业界熵减少的用例是要超熵增加的【注 5】。世界已经受够了“哈!你刚看到的一切都是 AI 写的!是不是很好玩!骗到你咯!”这类骗局,人们本来就一直对政府官方和新闻媒体的真实图片抱有怀疑,不需要人工智能生成的假图再来添把火了。
最知名的“生成性人工智能”反噬案例刚好也发生在上周,Meta 的 Galactica 模型在发布后被大肆炒作,仅仅三天便被迫下架。
或许它只是产品化和市场化的野心大过了头,但 一周前刚刚推出 的 Metaphor Search 却没有这样的惨遇,后者功能仅限于预测链接而不是直接给出结果。篇幅受限,我不会深入讨论 Galactica 的事实和伦理,如果你对更多辩论感兴趣,可参见 HN1、HN2 以及 推特。
看初来乍到的人们沉浸于 语言模型的幻觉 中很有意思,但对于那些靠生成式模型工作的人来说却很累人,更何况这种事实基本会永久存在。人们需要笨重且昂贵的模型级联,以及 一个用来给模型纠错的“法官”模型。消除幻觉(新增物理学、心智理论、概念构成等等)又是 强人工智能困难,是实用主义者不感兴趣的领域。
随着生成式人工智能登顶技术成熟度曲线,又由于其明显缺陷而跌落,也许我们可以关注下其他语言模型产品化的建造者:代理式人工智能 以及 RLHF。
注:
这一缺点 可想而知地引发了反抗活动,Stability 很可能是生成式人工智能风险决策的出格标志。
2.我最有趣的一次人工智能体验是近期参加的,在旧金山举办的第一届 OpenAI 黑客马拉松 关键词大战。主持人 笑我们那些充满稳定扩散性质的关键词,“嘿,单词顺序对 Dall-E 没区别!”我们都在不知不觉中内化了受我们个人经验所影响的即时工程原则。
3.要说 所有 知识产权都会在下个模型中完蛋其实是有些过于夸大其词的,但这在某种程度上也是 所有 新兴科技领域早期的情况:你必须要承担愚蠢的风险,去做没有规模化的事,才能拥有宽广且长远的经验,知别人所不知,建立持久的成果。等到人工智能产品指导手册都写得清清楚楚的时候,再开始为它定位就可能太晚了。数以万计的创始人已经在寻找潜在的人工智能产品空间,他们可不需要任何长久的计划才会开始。
4.我不相信 Copilot 的一亿美元 ARR,因为 GitHub 最近也才超过 10 亿美元 ARR。但我们也可以用这些公开的统计做个 Fermi 估算:数十万用户,其中 50% 的付费用户,每个用户每年一百美元,算起来至少一年一千万美元
承认“生成式人工智能”的存在不意味着“熵增加”,总结抽象“生成式人工智能”的方式有很多。可以说,扩散模型只是通过用 CLIP 指导减少熵来“变得有用”这点,没有覆盖全部,但也不是完全没用。
原文链接:
https://lspace.swyx.io/p/why-prompt-engineering-and-generative




