
近期,腾讯 TEG 数据平部 MQ 团队开发部署了一套底层运维指标性能分析系统(本文简称 Data 项目) ,目前作为通用基础设施服务整个腾讯集团。该系统旨在收集性能指标、上报数据以用于业务的运维监控,后续也将延用至前后端实时分析场景。
腾讯 Data 项目选用 Apache Pulsar 作为消息系统,其服务端采用 CVM 服务器(Cloud Virtual Machine,CVM)部署,并将生产者和消费者部署在 Kubernetes 上,该项目 Pulsar 集群是腾讯数据平台部 MQ 团队接入的消息量最大的 Pulsar 集群。在整个项目中,我们在 Apache Pulsar 大规模集群运维过程中遇到了一些问题和挑战。本文将对这些问题展开描述分析,并分享对应处理方案,同时也会解析涉及到的相关 Apache Pulsar 设计原理。
希望本文能够对面临同类场景的用户与开发者提供参考。
业务消息量大,对生产与消费耗时指标敏感
Data 项目的业务场景,具有非常明显的特点。首先,业务系统运行过程中,消息的生产、消费量都非常大,而且生产消息的 QPS(每秒查询率)波动性不明显,即业务会在近乎固定的 QPS 生产和消费数据。
其次,业务方对系统的可靠性、生产耗时、消费耗时这几个指标项比较敏感,需要在比较低的延迟基础上完成业务处理流程。像 Data 项目这样的业务场景和需求,对集群的部署、运营和系统稳定性都提出了非常高的要求。
Data 项目集群最大的特点是消息量大、节点多,一个订阅里可高达数千消费者。虽然 Data 项目当前 Topic 总量并不多,但单个 Topic 对应的客户端比较多,每个分区要对应 100+ 个生产者和 10000+ 个消费者。在对消息系统选型时,团队将消息系统的低延迟、高吞吐设为关键指标。经过综合对比市面上常见的消息系统,Apache Pulsar 凭借其功能和性能胜出。
Apache Pulsar 提供了诸多消费模型如独占、故障转移、共享(Shared)和键共享(Key_Shared),其中在 Key_Shared 和 Shared 订阅下可以支撑大量消费者节点。其他消息流系统如 Kafka,因为消费者节点受限于分区个数,导致其在多分区时性能相对较低。(编者注:Pulsar 和 Kafka 的最新性能测评,敬请期待 StreamNative 即将发布的 2022 版报告)
超大 Pulsar 集群:单分区最大消费者数量超 8K
目前 Data 项目业务数据接入两套 Pulsar 集群,分为 T-1 和 T-2。其中,T-1 对接的业务的客户端 Pod(分为生产者和消费者,且不在同一个 Pod 上,部署在腾讯云容器化平台 (STKE) ,与 Pulsar 集群在相同机房;T-2 对接业务的客户端 Pod 与 Pulsar 集群不在相同的机房(注:机房之间的数据时延相比同机房内部略高)。
服务器侧相关参数
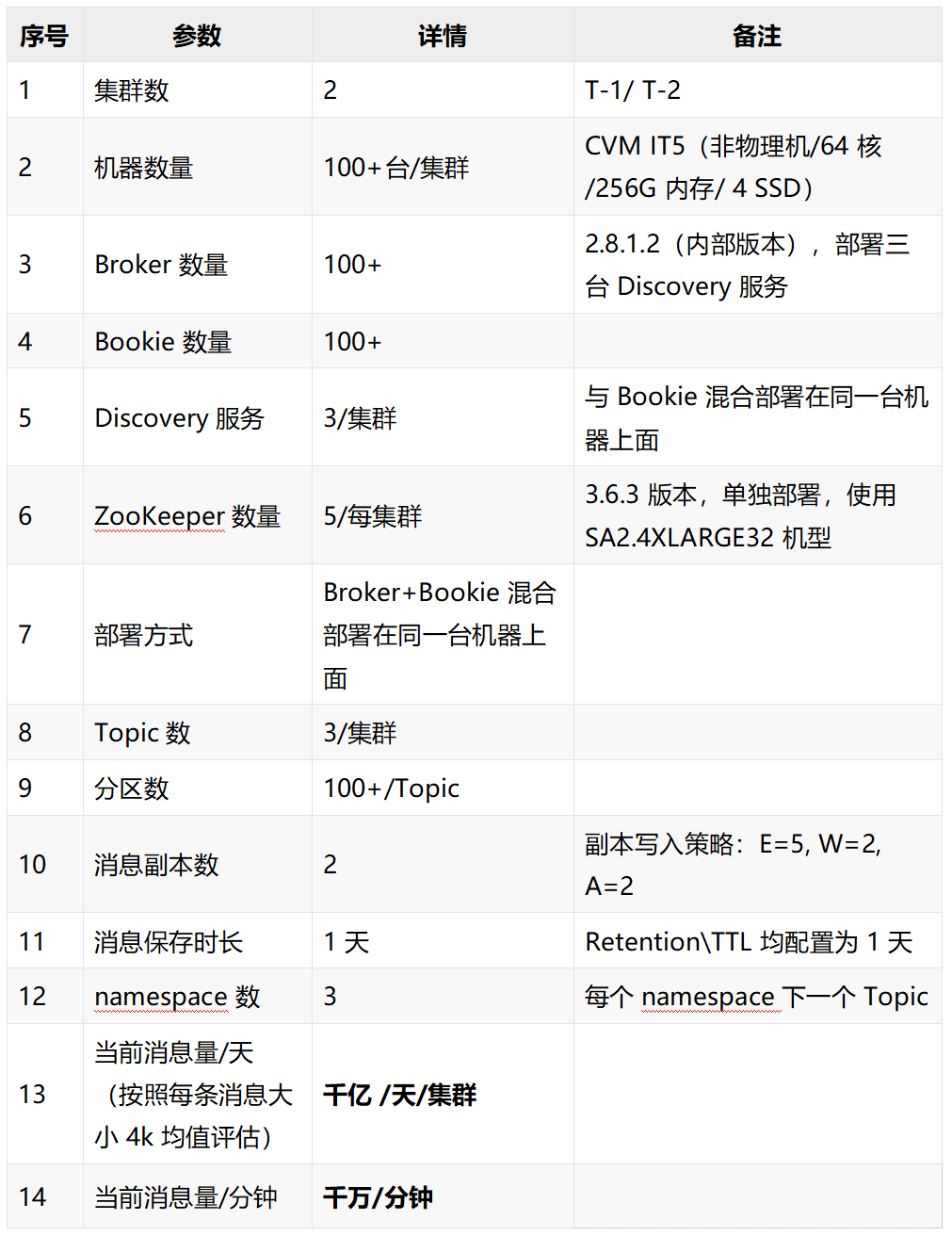
业务侧相关参数
Data 项目业务侧使用 Go 语言开发,接入 Pulsar 集群使用 Pulsar Go Client 社区 Master 分支的最新版本。使用云梯 STKE 容器方式部署。
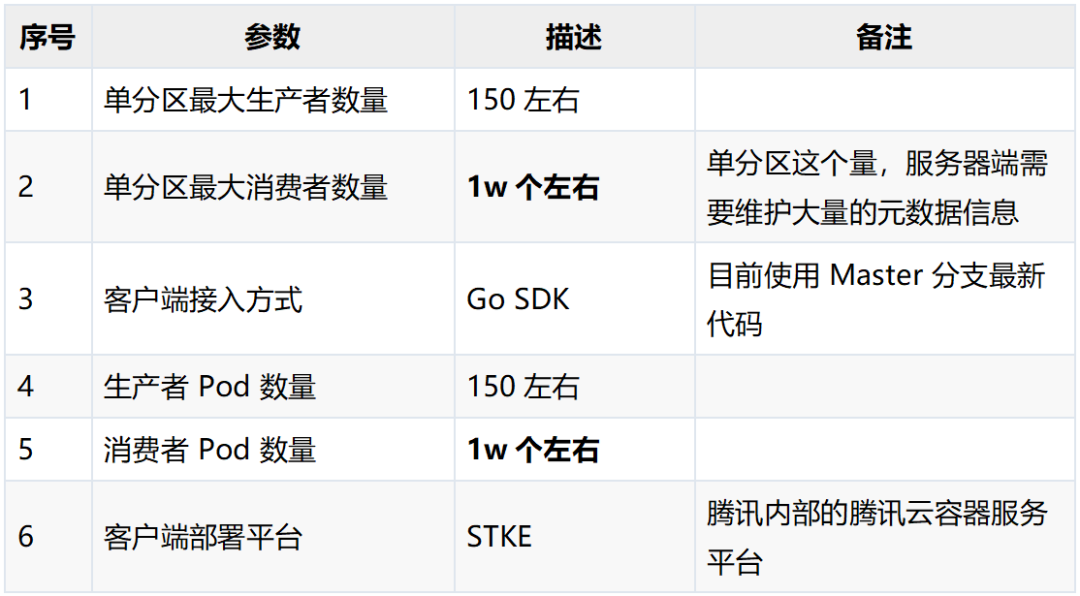
本文接下来将介绍 Pulsar 客户端在多种场景下的性能调优,分别针对项目在使用 Pulsar 的过程中遇到的客户端生产超时、客户端频繁断开等情况进行原因解析,并提供我们的解决方案,供大家参考。
客戶端性能调优:问题与方案
调优一:客户端生产超时,服务器端排查
在大集群下,导致客户端生产消息耗时较长或生产超时的原因有很多,我们先来看几个服务器端的原因,包括:
消息确认信息过大(确认空洞)
Pulsar-io 线程卡死
Ledger 切换耗时过长
BookKeeper-io 单线程耗时过长
DEBUG 级别日志影响
Topic 分区数据分布不均
接下来,针对每个可能的服务器端原因,我们逐个进行解析。
解析 1:消费确认信息过大(确认空洞)
与 Kafka、RocketMQ、TubeMQ 等不同,Apache Pulsar 不仅仅会针对每个订阅的消费进度保存一个最小的确认位置(即这个位置之前的消息都已经被确认已消费),也会针对这个位置之后且已经收到确认响应的消息,用 range 区间段的方式保存确认信息。
如下图所示:
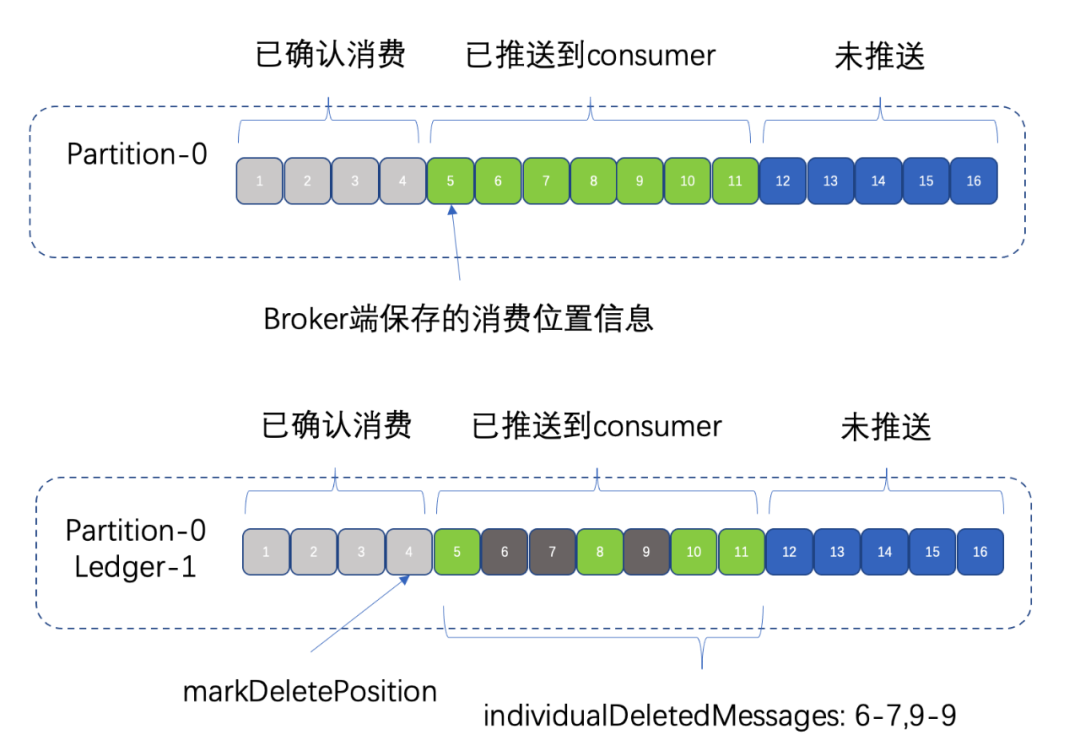
另外,由于 Pulsar 的每个分区都会对应一个订阅组下的所有消费者。Broker 向客户端推送消息的时候,通过轮询的方式(此处指 Shared 共享订阅;Key_Shared 订阅是通过 key 与一个消费者做关联来进行推送)给每个消费者推送一部分消息。每个消费者分别确认一部分消息后,Broker 端可能会保存很多这种确认区段信息。如下图所示:

确认空洞是两个连续区间之间的点,用于表示确认信息的区间段的个数。确认空洞受相同订阅组下消费者个数的多少、消费者消费进度的快慢等因素的影响。空洞较多或特别多即表示消费确认的信息非常大。
Pulsar 会周期性地将每个消费组的确认信息组成一个 Entry,写入到 Bookie 中进行存储,写入流程与普通消息写入流程一样。因此当消费组的消费确认空洞比较多、消费确认信息比较大、写入比较频繁的时候,会对系统的整体响应机制产生压力,在客户端体现为生产耗时增长、生产超时增多、耗时毛刺明显等现象。
在此情况下,可以通过减少消费者个数、提高消费者消费速率、调整保存确认信息的频率和保存的 range 段的个数等方式处理确认空洞。
解析 2:Pulsar-io 线程卡死
Pulsar-io 线程池是 Pulsar Broker 端用于处理客户端请求的线程池。当这里的线程处理慢或卡住的时候,会导致客户端生产超时、连接断连等。Pulsar-io 线程池的问题,可以通过 jstack 信息进行分析,在 Broker 端体现为存在大量的 CLOSE_WAIT 状态的连接,如下图所示:
Pulsar-io 线程池卡住的现象,一般为服务器端代码 bug 导致,目前处理过的有:
部分并发场景产生的死锁;
异步编程 Future 异常分支未处理结束等。
除了程序自身的 bug 外,配置也可能引起线程池卡住。如果 Pulsar-io 线程池的线程长时间处于运行状态,在机器 CPU 资源足够的情况下,可以通过变更 broker.conf 中的 numioThreads 参数来调整 Pulsar-io 线程池中的工作线程个数,来提高程序的并行处理性能。
注意:Pulsar-io 线程池繁忙,本身并不会导致问题。 但是,Broker 端有一个后台线程,会周期的判断每一个 Channel(连接)有没有在阈值时间内收到客户端的请求信息。如果没有收到,Broker 会主动的关闭这个连接(相反,客户端 SDK 中也有类似的逻辑)。因此,当 Pulsar-io 线程池被卡住或者处理慢的时候,客户端会出现频繁的断连 - 重联的现象。
解析 3:Ledger 切换耗时过长
Ledger 作为 Pulsar 单个分区消息的一个逻辑组织单位,每个 Ledger 下包含一定大小和数量的 Entry,而每个 Entry 下会保存至少一条消息( batch 参数开启后,可能是多条)。每个 Ledger 在满足一定的条件时,如包含的 Entry 数量、总的消息大小、存活的时间三个维度中的任何一个超过配置限制,都会触发 Ledger 的切换。
Ledger 切换时间耗时比较长的现象如下:

当 Ledger 发生切换时,Broker 端新接收到或还未处理完的消息会放在 appendingQueue 队列中,当新的 Ledger 创建完成后,会继续处理这个队列中的数据,保证消息不丢失。
因此,当 Ledger 切换过程比较慢时会导致消息生产的耗时比较长甚至超时。这个场景下,一般需要关注下 ZooKeeper 的性能,排查下 ZooKeeper 所在机器的性能和 ZooKeeper 进程的 GC 状况。
解析 4:BookKeeper-io 单线程耗时过长
目前 Pulsar 集群中,BookKeeper 的版本要相对比较稳定,一般通过调整相应的客户端线程个数、保存数据时的 E、QW、QA 等参数可以达到预期的性能。
如果通过 Broker 的 jstack 信息发现 BookKeeper 客户端的 Bookkeeper-io 线程池比较繁忙时或线程池中的单个线程比较繁忙时,首先要排查 ZooKeeper、Bookie 进程的 Full GC 情况。如果没有问题,可以考虑调整 Bookkeeper-io 线程池的线程个数和 Topic 的分区数。
解析 5:Debug 级别日志影响
在日志级别下,影响生产耗时的场景一般出现在 Java 客户端。如客户端业务引入的是 Log4j,使用的是 Log4j 的日志输出方式,同时开启了 Debug 级别的日志则会对 Pulsar Client SDK 的性能有一定的影响。建议使用 Pulsar Java 程序引入 Log4j 或 Log4j + SLF4J 的方式输出日志。同时,针对 Pulsar 包调整日志级别至少到 INFO 或 ERROR 级别。在比较夸张的情况下,Debug 日志影响生产耗时的线程能将生产耗时拉长到秒级别,调整后降低到正常水平(毫秒级)。具体现象如下:
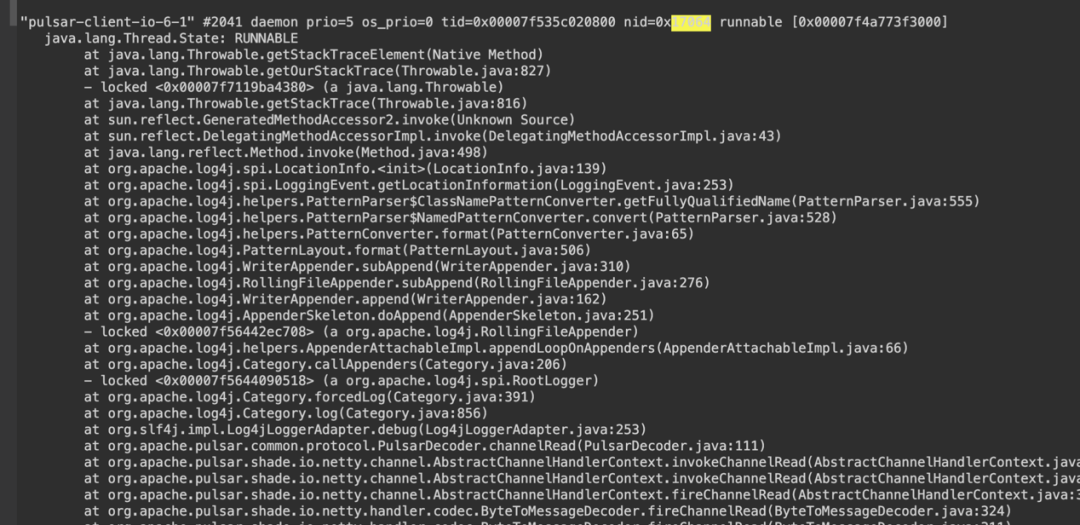
在消息量特别大的场景下,服务器端的 Pulsar 集群需要关闭 Broker、Bookie 端的 Debug 级别的日志打印(建议线网环境),直接将日志调整至 INFO 或 ERROR 级别。
解析 6:Topic 分区分布不均
Pulsar 会在每个 Namespace 级别配置 bundles ,默认 4 个,如下图所示。每个 bundle range 范围会与一个 Broker 关联,而每个 Topic 的每个分区会经过 hash 运算,落到对应的 Broker 进行生产和消费。当过多的 Topic 分区落入到相同的 Broker 上面,会导致这个 Broker 上面的负载过高,影响消息的生产和消费效率。
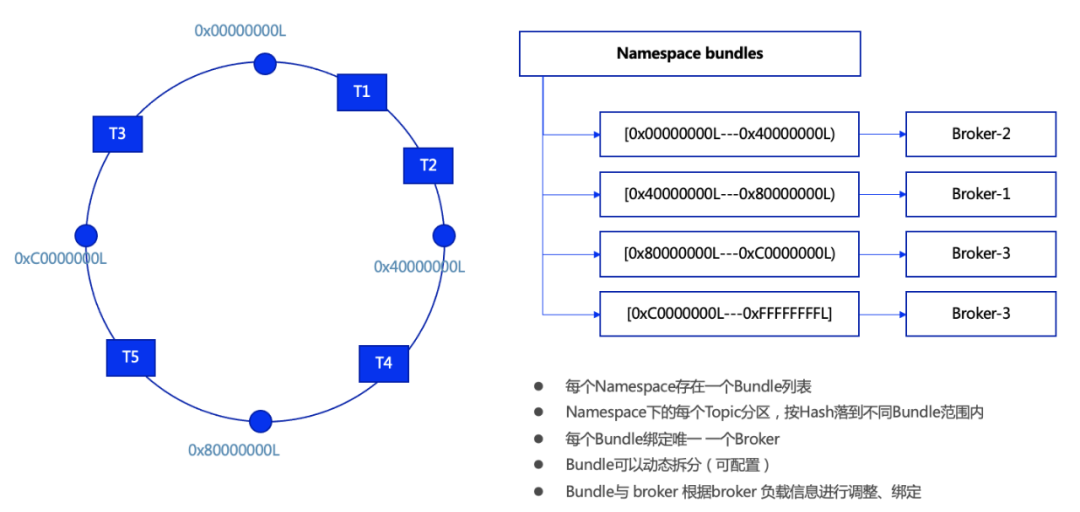
Data 项目在开始部署的时候,每个 Topic 的分区数和每个 Namespace 的 bundle 数都比较少。通过调整 Topic 的分区个数和 bundle 的分割个数,使得 Topic 的分区在 Broker 上面达到逐步均衡分布的目的。
在 bundle 的动态分割和 Topic 的分布调整上,Pulsar 还是有很大的提升空间,需要在 bundle 的分割算法(目前支持 range_equally_divide、topic_count_equally_divide,默认目前支持 range_equally_divide,建议使用 topic_count_equally_divide)、Topic 分区的分布层面,在保证系统稳定、负载均衡的情况下做进一步的提升。
调优二:客户端频繁断开与重连
客户端断连 / 重连的原因有很多,结合腾讯 Data 项目场景,我们总结出客户端 SDK 导致断连的主要有如下几个原因,主要包括:
客户端超时断连 - 重连机制
Go SDK 的异常处理
Go SDK 生产者 sequence id 处理
消费者大量、频繁的创建和销毁
下面依次为大家解析这些问题的原因与解决方案。
解析 1:客户端超时断连 - 重连机制
Pulsar 客户端 SDK 中有与 Broker 端类似逻辑(可参考 # 解析 2 部分内容),周期判断是否在阈值的时间内收到服务器端的数据,如果没有收到则会断开连接。
这种现象,排除服务器端问题的前提下,一般问题出现在客户端的机器资源比较少,且使用率比较高的情况,导致应用程序没有足够的 CPU 能力处理服务器端的数据。此种情况,可以调整客户端的业务逻辑或部署方式,进行规避处理。
解析 2:Go SDK 的异常处理
Pulsar 社区提供多语言的客户端的接入能力,如支持 Java、Go、C++、Python 等。但是除了 Java 和 Go 语言客户端外,其他的语言实现相对要弱一些。Go 语言的 SDK 相对于 Java 语言 SDK 还有很多地方需要完善和细化,比方说在细节处理上与 Java 语言 SDK 相比还不够细腻。
如收到服务器端的异常时,Java SDK 能够区分哪些异常需要销毁连接重连、哪些异常不用销毁连接(如 ServerError_TooManyRequests),但 Go 客户端会直接销毁 Channel ,重新创建。
解析 3:Go SDK 生产者 Sequence id 处理
发送消息后,低版本的 Go SDK 生产者会收到 Broker 的响应。如果响应消息中的 sequenceID 与本端维护的队列头部的 sequenceID 不相等时会直接断开连接——这在部分场景下,会导致误断,需要区分小于和大于等于两种场景。
这里描述的场景和解析 1- 客户端超时中的部分异常场景,已经在高版本 Go SDK 中做了细化和处理,建议大家在选用 Go SDK 时尽量选用新的版本使用。目前,Pulsar Go SDK 也在快速的迭代中,欢迎感兴趣的同学一起参与和贡献。
解析 4:消费者大量且频繁地创建和销毁
集群运维过程中在更新 Topic 的分区数后,消费者会大量且频繁地创建和销毁。针对这个场景,我们已排查到是 SDK bug 导致,该问题会在 Java 2.6.2 版本出现。运维期间,消费者与 Broker 端已经建立了稳定的连接;运维过程中,因业务消息量的增长需求,需要调整 Topic 的分区数。客户端在不需要重启的前提下,感知到了服务器端的调整,开始创建新增分区的消费者,这是因为处理逻辑的 bug,会导致客户端大量且频繁地反复创建消费者。如果你也遇到类似问题,建议升级 Java 客户端的版本。
除了上面的断连 - 重连场景外,在我们腾讯 Data 项目的客户端还遇到过 Pod 频繁重启的问题。经过排查和分析,我们确定是客户端出现异常时,抛出 Panic 错误导致。建议在业务实现时,要考虑相关的容错场景,在实现逻辑层面进行一定程度的规避。
调优三:升级 ZooKeeper
由于我们腾讯 Data 项目中使用的 Pulsar 集群消息量比较大,机器的负载也相对较高。涉及到 ZooKeeper,我们开始使用的是 ZooKeeper 3.4.6 版本。在日常运维过程中,整个集群多次触发 ZooKeeper 的一个 bug,现象如下截图所示:
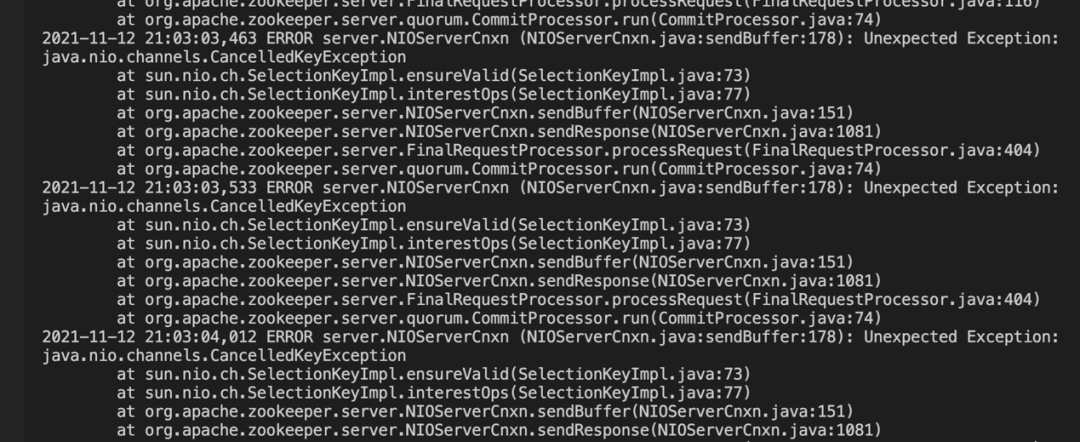
当前,ZooKeeper 项目已经修复该 Bug,感兴趣的小伙伴可以点击该连接查看详情:https://issues.apache.org/jira/browse/ZOOKEEPER-2044。因此,在 Pulsar 集群部署的时候建议打上相应的补丁或升级 ZooKeeper 版本。在腾讯 Data 项目中,我们则是选择将 ZooKeeper 版本升级到 3.6.3 进行了对应处理。
小结:Pulsar 集群运维排查指南
不同的业务有不同的场景和要求,接入和运维 Apache Pulsar 集群时遇到的问题,可能也不太一样,但我们还是能从问题排查角度方面做个梳理,以便找到相应规律提升效率。
针对 Apache Pulsar 集群运维过程中遇到的问题,如生产耗时长、生产超时(timeout)、消息推送慢、消费堆积等,如果日志中没有什么明显的或有价值的异常(Exception)、错误(Error) 之类的信息时,可以从如下几个方面进行排查:
集群资源配置及使用现状
客户端消费状况
消息确认信息
线程状态
日志分析
下面针对每个方面做个简要说明。
1. 集群资源配置及使用现状
首先,需要排查进程的资源配置是否能够满足当前系统负载状况。可以通过 Pulsar 集群监控仪表盘平台查看 Broker、Bookie、ZooKeeper 的 CPU、内存及磁盘 IO 的状态。
其次,查看 Java 进程的 GC 情况(特别是 Full GC 情况),处理 Full GC 频繁的进程。如果是资源配置方面的问题,需要集群管理人员或者运维人员调整集群的资源配置。
2. 客户端消费状况
可以排查消费能力不足引起的反压(背压)。出现背压的现象一般是存在消费者进程,但是收不到消息或缓慢收到消息。
可以通过 Pulsar 管理命令,查看受影响 Topic 的统计信息(stats),可重点关注未确认消息数量数量(unackedMessages)、backlog 数量和消费订阅类型,以及处理未确认消息(unackmessage)比较大的订阅 / 消费者。如果未确认消息(unackmessage)数量过多,会影响 Broker 向客户端的消息分发推送。这类问题一般是业务侧的代码处理有问题,需要业务侧排查是否有异常分支,没有进行消息的 ack 处理。
3. 消息确认信息
如果集群生产耗时比较长或生产耗时毛刺比较多,除了系统资源配置方面排查外,还需要查看是否有过大的消息确认信息。
查看是否有过大的确认空洞信息,可以通过管理命令针对单个 Topic 使用 stats-internal 信息,查看订阅组中的 individuallyDeletedMessages 字段保存的信息大小。
消息确认信息的保存过程与消息的保存过程是一样的,过大的确认信息如果频繁下发存储,则会对集群存储造成压力,进而影响消息的生产耗时。
4. 线程状态
如果经过上面的步骤,问题还没有分析清楚,则需要再排查下 Broker 端的线程状态,主要关注 pulsar-io、bookkeeper-io、bookkeeper-ml-workers-OrderedExecutor 线程池的状态,查看是否有线程池资源不够或者线程池中某个线程被长期占用。
可以使用 top -p PID(具体 pid) H 命令,查看当前 CPU 占用比较大的线程,结合 jstack 信息找到具体的线程。
5. 日志分析
如果经过上面所述步骤仍然没有确认问题来源,就需要进一步查看日志,找到含有有价值的信息,并结合客户端、Broker 和 Bookie 的日志及业务的使用特点、问题出现时的场景、最近的操作等进行综合分析。
回顾与计划
上面我们花了很大篇幅来介绍客户端性能调优的内容,给到客户端生产超时、频繁断开与重连、ZooKeeper 等相应的排查思路与解决方案,并汇总了常见 Pulsar 集群问题排查指南 5 条建议,为在大消息量、多节点、一个订阅里高达数千消费者的 Pulsar 应用场景运维提供参考。
当然,我们对 Pulsar 集群的调优不会停止,也会继续深入并参与社区项目共建。
由于单个 Topic 对应的客户端比较多,每个客户端所在的 Pod、Client 内部会针对每个 Topic 创建大量的生产者和消费者。由此就对 Pulsar SDK 在断连、重连、生产等细节的处理方面的要求比较高,对各种细节处理流程都会非常的敏感。SDK 内部处理比较粗糙的地方会导致大面积的重连,进而影响生产和消费。目前,Pulsar Go SDK 在很多细节方面处理不够细腻,与 Pulsar Java SDK 的处理有很多不一样的地方,需要持续优化和完善。腾讯 TEG 数据平台 MQ 团队也在积极参与到社区,与社区共建逐步完善 Go SDK 版本。
另外,针对腾讯 Data 项目的特大规模和业务特点,Broker 端需要处理大量的元数据信息,后续 Broker 自身的配置仍需要做部分的配置和持续调整。同时,我们除了扩容机器资源外,还计划在 Apache Pulsar 的读 / 写线程数、Entry 缓存大小、Bookie 读 / 写 Cache 配置、Bookie 读写线程数等配置方面做进一步的调优处理。
作者简介:
鲍明宇,腾讯高级软件工程师,目前就职于腾讯 TEG 数据平台部,负责 Apache Pulsar、Apache Inlong、DB 数据采集等项目的开发工作。目前专注于大数据领域,消息中间件、大数据数据接入等方向,拥有 10 年 Java 相关开发经验。
张大伟,腾讯高级软件工程师,Apache Pulsar Committer,目前就职于腾讯 TEG 数据平台部,主要负责 Apache Pulsar 项目相关工作。目前专注于 MQ 和数据实时处理等领域,拥有 6 年大数据平台相关开发经验。
关于 Apache Pulsar
云原生时代消息队列和流融合系统,提供统一的消费模型,支持消息队列和流两种场景,既能为队列场景提供企业级读写服务质量和强一致性保障,又能为流场景提供高吞吐、低延迟;采用存储计算分离架构,支持大集群、多租户、百万级 Topic、跨地域数据复制、持久化存储、分层存储、高可扩展性等企业级和金融级功能。
GitHub 地址:http://github.com/apache/pulsar/




