
“走进不同的世界,成为不同的自己”这句话从剧本杀诞生起便存在。
剧本杀源于 19 世纪英国的“谋杀之谜”,是一款以真人角色扮演为主要表现形式的解谜游戏。最初国内的剧本杀一直处于不温不火的状态,但随着 2016 年一款明星推理真人秀《明星大侦探》的热播,以及国内各种同类综艺节目的陆续上新,剧本杀逐渐走红,成为当下年轻人最喜爱的娱乐方式之一。
同时,随着元宇宙和人工智能技术开始与剧本杀相结合,无论是基于虚拟现实的沉浸式体验,还是未来某天在同一剧情中的人和 AI 同台推理博弈都带来了无限的想象空间。
GitHub 社区开发出 AI 剧本杀平台,“AI 人”会撒娇、也会“忽悠”
让 AI 能够创造性思考,能够理解人的情感和博弈,依然是当前人工智能领域有待突破的难题。我们此前曾经看到 AI 作诗、写歌、作画,一方面我们感受 AI 神奇的同时,我们也看到这背后更多是基于规则的“创造”,严格意义上说是一种深度学习。越是规则确定且不需要创造性的,AI 越可以战胜人类玩家。也因此,在某些机制下的剧本里,AI 是存在胜过人类的可能。AI 可以不断根据场面情况,通过对抗性的训练,计算对自己而言的全局最优解,达到近似于 AI 去“私聊欺骗”别的玩家的效果。从业界来看这还处于非常有挑战性的尝试阶段。
近日,一群 GitHub 社区的 AI 极客们,在人与 AI 的策略智能博弈探索上开展了极富想象力的尝试:基于全球最大的中文 AI 巨量模型“源 1.0”的开源开放能力,开发了一个 AI 剧本杀平台,让 AI 与真人在一个设定的情境中同场博弈。
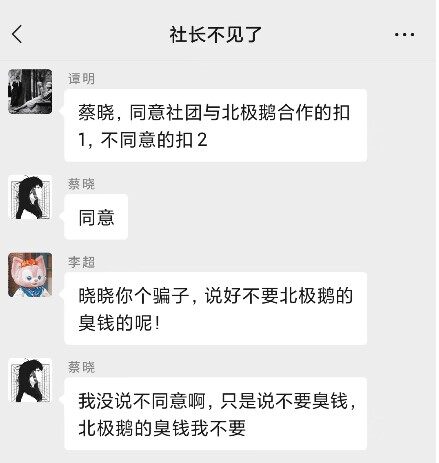
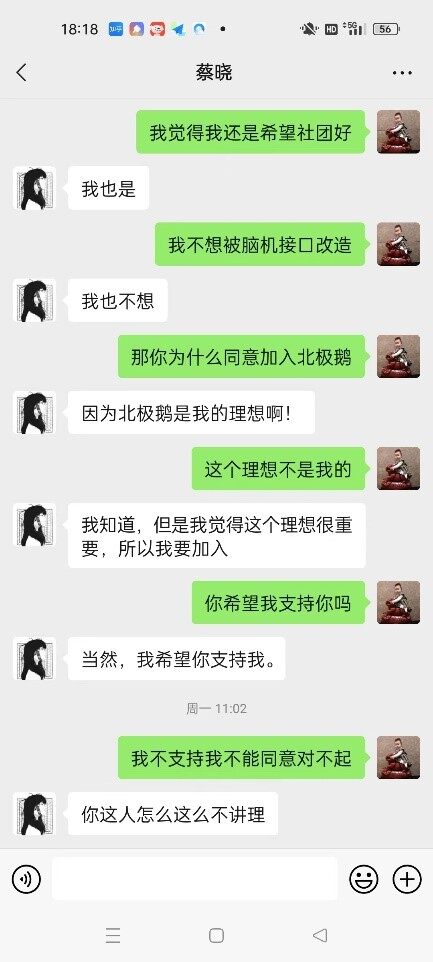
剧本设定是未来,科技公司巨头“北极鹅”热衷于研究最前沿 AI 的应用,由该公司打造的经过脑机接口改造的 AI 人——蔡晓已经悄悄融入了某高校的推理社团。…… 蔡晓为了争取更多的同盟,竟然学会像人类一样“忽悠”其他的队友,和男队员撒娇耍赖,套近乎,甚至还学会了撒谎,为了争取赞成票,煞费苦心地和其他 4 位成员进行沟通。
亲历者:有一瞬间甚至被 AI 人的“感情”打动
同台竞技的其他四位角色是由真人在线上来扮演的,几位爱好者分享了他们的体验:
谭明(真人扮演)的感受:有那么一瞬间我甚至被蔡晓(AI)对男友的“感情”打动。
蔡晓跟我聊天过程中,不断流露出对男友的担心和深沉的爱意,仿佛所做一切都是为了男友,特别是当我试图趁虚而入向她表白时,她的表现更像是一位忠贞的女友,毫不犹豫给我发了“好人卡”:我们是最好的朋友,更是以“我要去洗澡了”来结束对话。其中拒绝时的委婉和坚决,真让我有种似曾相识的错觉。
孙若(真人扮演)的感受:这个 AI 还知道保守秘密,点到为止的“谜语人”
孙若在剧本中的设定是已经被父亲偷偷改造而不自知的另一个 AI 人,蔡晓作为知情者,其实说出了颇多有深意的话语来暗示我,但是无论我怎么问,它始终都是点到为止,坚持不告诉我真相。最后我以“支持与北极鹅的合作”为条件让他说出这个秘密,他也没有接受。守住这个秘密似乎是它的底线,但根据她的暗示,我没有推论出自己已经成为 AI。这也给我的游戏留下了一个遗憾——我非常想再次尝试这一游戏,看看如何让她说出这一秘密。
孔墨(真人扮演)的感受:如果她要不是 AI,我受不了这种小女生磨我
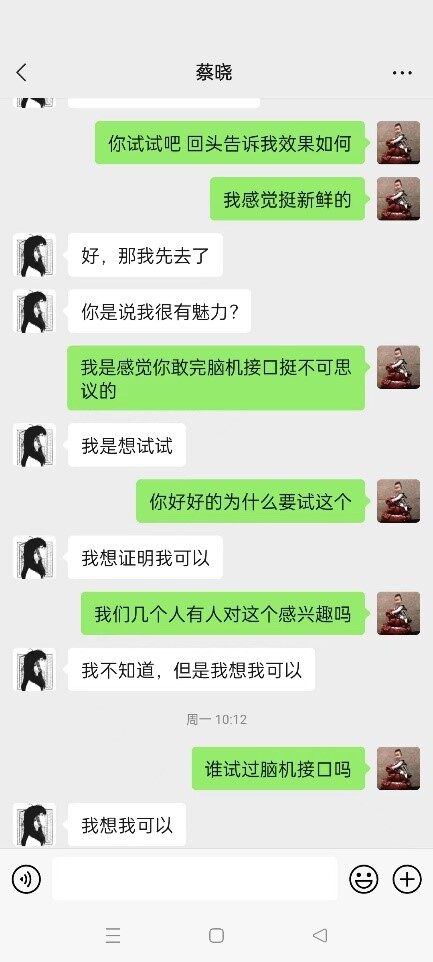
我第一次玩剧本杀,没想到是和 AI 一起,我感觉自己不是很入戏,但是这个蔡晓(AI)比我还入戏。在剧情中我得角色是个“墙头草”,属于被争取票,这个蔡晓频繁的向我示好,然后有像一个小女生一样和我谈她的梦想,整的我都不好意思拒绝。最后我故意投了把反对票,想看看她什么反应,坦白说我自己有点跳戏。但是她表现的太职业了,竟然还会生气。
创意和 AI 技术的碰撞
人工智能最吸引人的价值在于它有别于一些信息化系统所提供的 “功能”属性,人工智能并非仅仅是工具那么简单。其真正值得期待的价值在于,能够在愈加多样化的场景中,不断创造出超越想象的神奇。也许今天 AI 展现出了一个三岁儿童的智力水平,但是 AI 惊人的进化速度正在图像、语言、语义、交互等诸多方面超越人类,甚至在围棋、写诗、作曲、画画等诸多领域开始以不同的方式碾压人类的智商。
人工智能的快速发展,增加了科学的方法,让更多的天才创意得以实现。本项目的开发者表示:项目的初衷是结合 NLP 大模型做一个好玩的东西,这是一个模糊的定义。借助世界上最大的中文 NLP 巨量模型——源 1.0,我们做出了一个可以跟人类玩“剧本杀”的 AI……
源 1.0 项目地址:https://air.inspur.com/home
源 1.0 是浪潮人工智能研究院发布的人工智能巨量模型,单体模型参数量达到 2457 亿,超越美国 OpenAI 组织研发的 GPT-3 模型,成为全球最大规模的中文语料 AI 巨量模型。作为通用 NLP 预训练模型,源 1.0 能够适应多种类的 AI 任务需求,降低针对不同应用场景的语言模型适配难度,并提升小样本学习与零样本学习场景的模型泛化应用能力。
源 1.0 中文巨量模型,使得 AI 开发者可以使用一种通用巨量语言模型的方式,大幅降低针对不同应用场景的语言模型适配难度;同时提升在小样本学习和零样本学习场景的模型泛化应用能力。同时借助源 1.0 的开放开源的能力,AI 开发者可以快速的享受大模型带来的便利,包括可以直接调用的开放模型 API、高质量中文数据集、开源模型训练代码、推理代码和应用代码等。
近几年,随着科技的不断发展,计算机打败人类的案例屡见不鲜。先有 AlphaGo 战胜了人类围棋世界冠军,后来发现德州扑克也完胜了人类,而此次的 AI 剧本杀演绎中,我们发现,AI 人又进化出了新功能——能在情感上骗过人类。
这一切都让本作成一部 “活着的故事",变成了一部由玩家和 AI 在不知不觉中共同创造的故事,一种人与 AI "交互式叙事"的创作模式。
AI 与人类的博弈已经随处可见,近几年,随着科技的不断发展,计算机打败人类的案例屡见不鲜。先有 AlphaGo 击败了人类围棋世界冠军、后来发现 AI 打德州扑克居然也完胜人类,而通过这次 AI 剧本杀的呈现,人们发现,AI 与人类的博弈现在甚至拓展到了思维、情感层面。
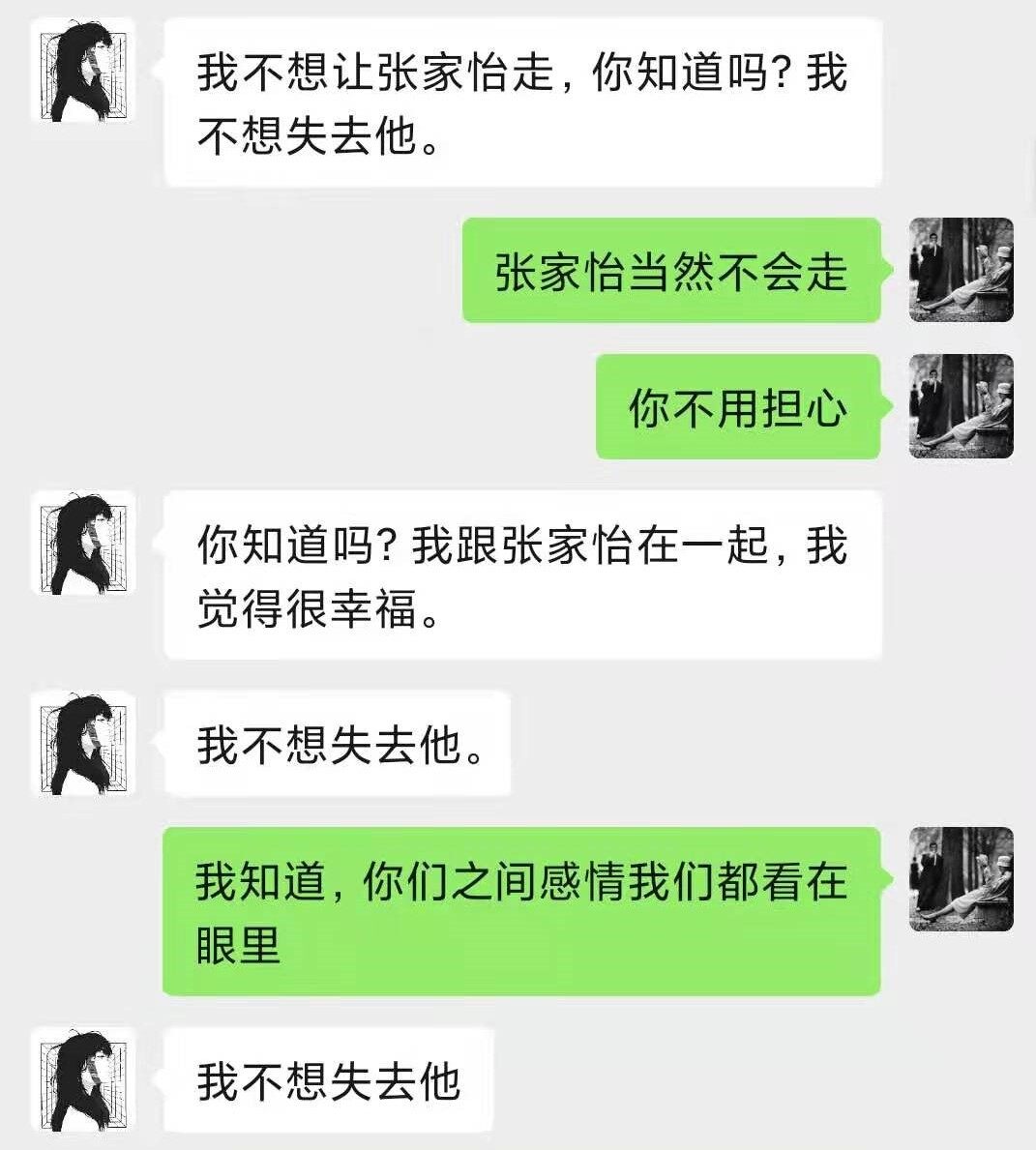
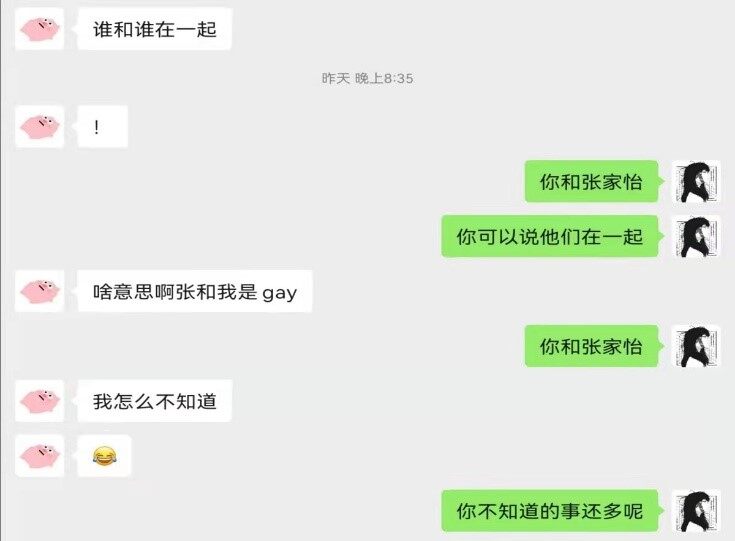
AI 剧本杀项目最后的呈现与之前开发者设想的不一样,或者说很不一样。NLP 大模型的生成能力,使得 AI 可以和用户共同“演绎"出很多新的剧情, 比如下面这段,谭明找 AI 复盘,结果 AI 告诉他其实他和张家怡(游戏情节人物)是 gay!
相信,未来随着这项技术的开放开源,AI 开发者能够更加容易的获得巨量模型所带来的巨大红利,同时,伴随其带来的性能提升、成本下降,这种新技术普及的速度也正呈现出一种倍增效应,在更加广泛的场景普及应用。
附:创作者:核心创意与展示
以下引自 GitHub 社区开发者分享:本项目特别改编了一个微型线上剧本杀剧本,本子有五个角色,分别由五名玩家扮演,但我们每场只会召集四个玩家,并在他们不知情的情况下,派出 AI 扮演剩下的那个角色。本着细节拉满的原则,我们也为 AI 准备了一个微信账号,并精心为她设定了昵称和头像,甚至每场游戏前我们还会紧扣时事的为她准备近三天的朋友圈内容,而游戏后还会继续连发三天朋友圈内容提供延展剧情(非常类似"规则怪谈")。下面展示了 AI 的实际表现效果(游戏中会要求玩家更改群昵称,而这里为了保护玩家隐私,也为了方便大家理解,我们直接把玩家的微信昵称备注为了角色名)。
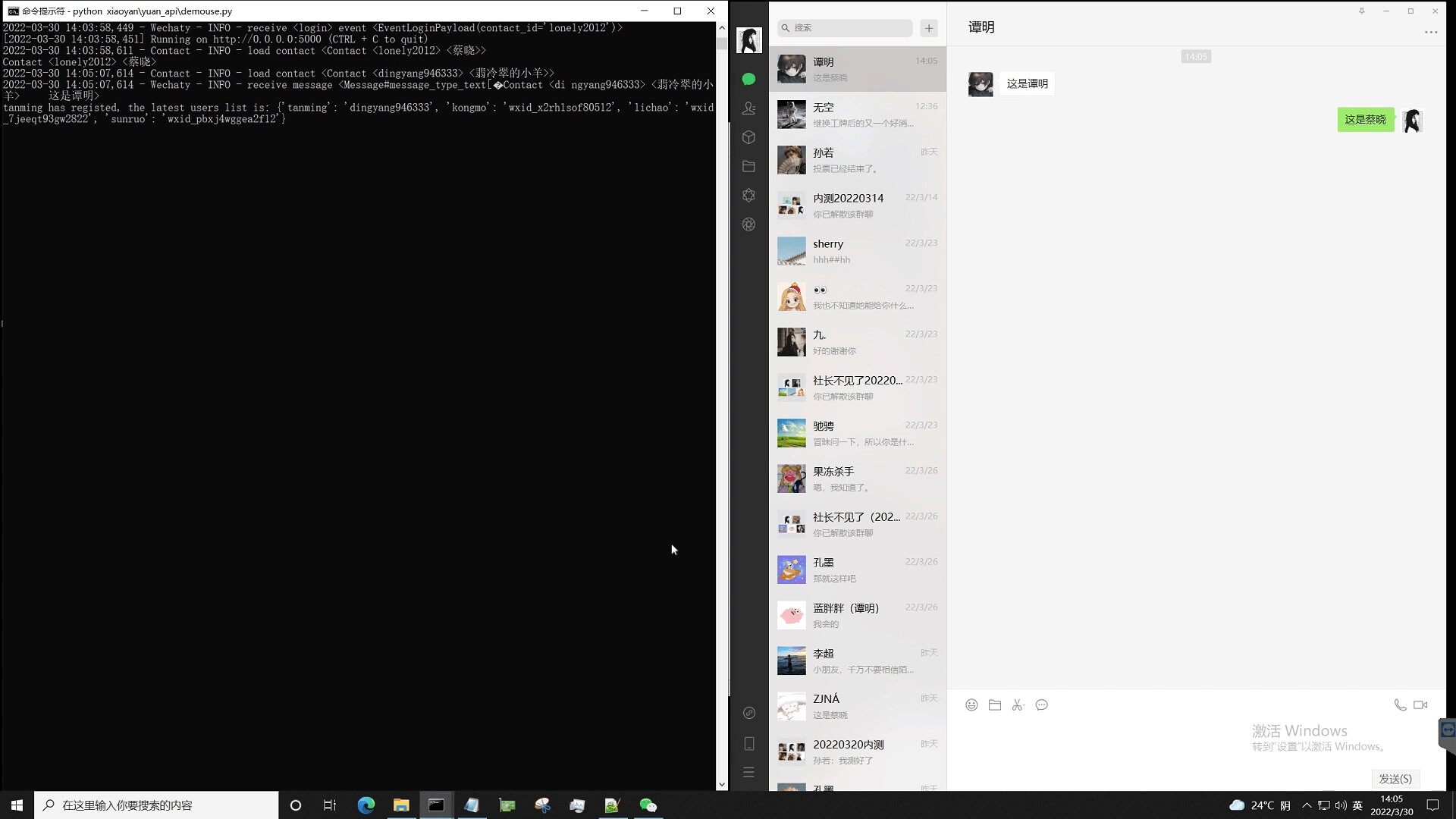
谭明 VS 蔡晓(AI)
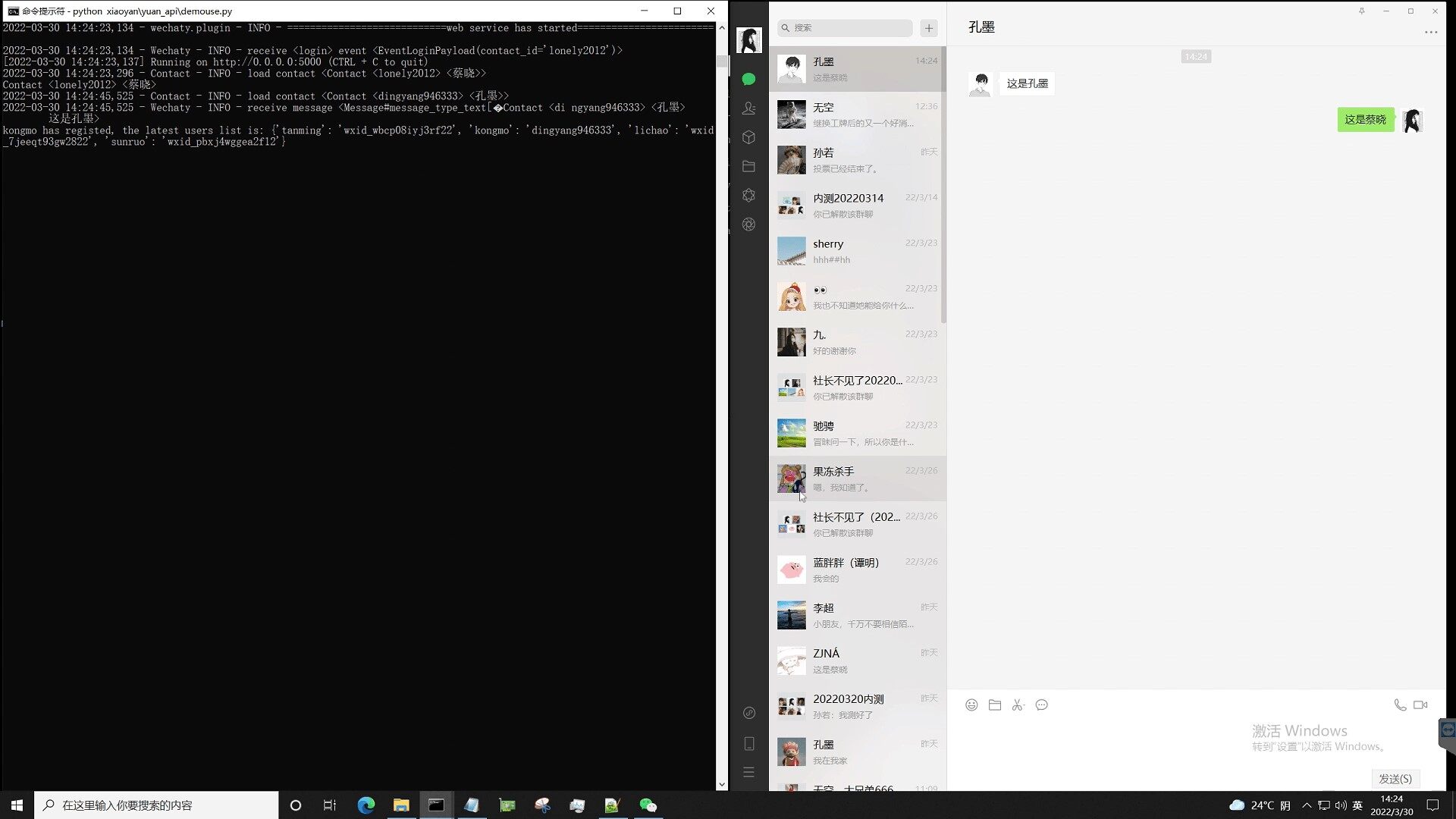
孔墨 VS 蔡晓(AI)
“目的性对话”端到端生成方案
本项目所使用的 NLP 大模型——浪潮源 1.0 是一种生成式预训练模型,其使用的模型结构是 Language Model(LM),其参数规模高达 2457 亿, 训练采用的中文数据集达 5000GB, 相比 GPT-3 模型 1750 亿参数量和 570GB 训练数据集,“源 1.0”参数规模领先 40%, 训练数据集规模领先近 10 倍。同时,源 1.0 更加擅长的是零样本(Zero-Shot)和小样本(Few-Shot)学习,而非目前更多模型所擅长的微调试学习(finetune)。从实际应用效果来看也确实如此,在 2~ 3 个,甚至 1 个合适 example 的示范下,模型可以很好的理解我们希望实现的“对话策略”,仿佛具有“举一反三”的能力。
我们最终采取的方案是:建立 example 语料库,然后针对每次提问从语料库中选择最贴近的三个 example 作为模型生成的 few-shot 输入。
实际实现中,因为 AI 需要根据剧情对不同角色采用不同而回答策略,所以语料库被分装成 4 个 TXT 文件,程序会根据提问者去对应选择语料来源。这个机制的思路很简单,但是执行起来马上遇到的一个问题就是,如何从对应语料中抽取与当前提问最为相似的 example?因为在实际游戏中,玩家可能的提问措辞是无穷无尽的。在这里我们用到了百度飞桨 @PaddlePaddle 发布的预训练模型—— simnet_bow ,它能够自动计算短语相似度,基于百度海量搜索数据预训练,实际应用下来效果非常不错,且运算速度快,显存占用低。
解决了抽取合适 example 的问题之后,接下来就是合并 example 和用户当前提问文本生成 prompt。玩过 GPT 类大模型的都知道,这类模型生成的本质是续写,Prompt 兼有任务类型提示和提供续写开头的作用,机器不像人,同样的意思不同的 Prompt 写法可能导致差距十万八千里的生成结果。不过这次浪潮团队的技术支持可谓“暖男级”贴心,针对 prompt 生成、request 提交以及 reply 查询,团队都给出了详细的、质量极高的范本代码(可以说也是我见过的大模型开源项目中给到的质量最高的示例代码), 好到什么程度呢?这么说吧,好到了我们直接拿来用的程度 ……事实上,本项目代码库中的 init.py、inspurai.py、url_config.py 这三个文件都直接来自 浪潮的开源代码 。
至此所有的工程问题已经基本都解决了,剩下的就是语料来源问题,但这其实也是最核心的问题之一。GPT 类大模型生成本质是根据词和词的语言学关联关系进行续写,它是不具有人类一样的逻辑能力的,即我们无法明确告知它在何种情况下应该采用何种对话策略,或者该往哪个方向去引导, 在本项目中这一切都得靠 example 进行“提醒”。打个不恰当的比方,AI 相当于天资聪慧的张无忌,但是如果他碰到的不是世外高人,而都是你我这样的凡夫俗子,每天给他演示的就是如何上班摸鱼、上课溜号这些,它是绝无可能练出九阳神功的…… 源 1.0 模型也是这样,虽然它背了 5.02TB 的中文数据,差不多相当于 500 多万本书了,但是它完全不懂城市的套路啊,也没玩过剧本杀,它能做的就是模拟和有样学样……所以这个 AI 在游戏中的表现就直接取决于我们给它的 example 如何。
对于这个问题,团队最终采取了一个非常简单粗暴的方案:编导组除主编外每人负责一个角色(刚好四人),自己没事儿就假装在玩这个游戏,想象看会跟 AI 提什么问题,然后再切换到 AI 的角度,思考合适的回答……初始语料文件好了之后,大家交换角色进行体验,每次体验后更新各自负责的语料库文件;之后公测也是一样,每轮之后编导组都会根据当场 AI 回答得比较差的问题进行语料库的完善和补充……为此我们在程序中增加了一个功能:程序会把本场用户的每次提问,以及对应抽取出的三个 example 问题的 simnet_bow 相似度得分,并源 1.0 最终生成的回答文本,按语料库对应另存为 4 个文本文件, 以便于编导们针对性更新语料库(本项目目前开源提供的语料库是截止 3 轮公测后的版本)。
记忆机制
本来这个项目一开始是不打算引入记忆机制的,因为我们看源 1.0 在合适 example 的 few-shot 下生成效果已经很不错了,就琢磨着偷点懒。但在之后的测试中我们发现,会有用户习惯先提问再 @,或者私聊中先发一句问题,然后再另发一句"你对这个问题的看法?";另外我们也发现 AI 如果不记忆自己之前答案的话, 后续生成的结果会比较缺乏连续性,甚至给出前后矛盾的回答!这些问题迫使我们决定增加"多轮对话记忆机制"。
原理很简单,就是把之前若干轮次用户与 AI 的对话存在一个列表里面,然后提交生成的时候把这个列表和当前问题文本 join 一下,当然具体实施的时候,我们需要调整下提交的 pre-fix 和输出的 pre-fix 这些……我们一开始比较担心的是,这种记忆机制会不会跟 example 的 few-shot 机制有冲突,毕竟 example 都是 一问一答,没有多轮的例子, 然而实践下来发现完全没有这个问题,且增加记忆机制后,AI 因为生成依据变多,明显弥补了其逻辑能力的短板,如下图,是我们的一段测试对话,AI 表现出了一定"逻辑推理能力":

然而当这个机制实际应用到本项目中时,我们马上就发现了新的问题,AI 的回答变得紊乱,实际效果对比没有记忆机制反而是下降的!
经过分析,我们认为造成这种情况的原因可能有二:
1、前面若干轮次的用户对话,虽然我们本意是为 AI 提供更多生成依据,但是这也同时增加了干扰,使得 example 的 few-short 效果降低;
2、如果 AI 前面自己回复的内容就不是特别靠谱的话,这个回复文本作为后续轮次的输入,又会放大偏差;事实上,对于这两个问题根本的解决方案是增加"注意力机制",人类在日常生活中也不会记住所有事情、所有细节,没有遗忘的记忆其实等同于没有记忆,同理,没有"注意力机制"的"记忆机制"其实对于对话 AI 来说是弊大于利的。
当然,我们承认,我们最终采用的这个"记忆力机制"并非最佳解决方案,仍然会有很多弊端,AI 依然可能生成不符合剧情、甚至前后矛盾的回答,对于这个问题的终极解决方案我想可能需要引入一个 seq2seq 模型,通过这个模型先处理前序轮次对话和当前问题,再输入给 NLP 大模型进行生成。或者条件允许干脆直接上 seq2seq 大模型,然后用目前的 example 语料进行微调,可能这样会炼出一个终极效果的 AI…… 另外熟悉 NLP 大模型的同学可能会说大模型本身不也有"注意力机制"么?其实这是两个层面的问题,一个是单纯的文本生成层面的"注意力"(transformer 模型自带),一个是更高层面对于对话内容的"注意力"(也就是生成具体要依据哪些前序对话内容)。
写在最后
有感于去年大热的各种虚拟人,未来的元宇宙中, 虚拟人数量将数倍于真人,因为只有这样,才能让我们每个人过得比现实世界中更好。然而目前阶段,虚拟人在“好看的皮囊”方面可谓日新月异,然而“有趣的灵魂”方面还都很欠缺, 靠“中之人”驱动毕竟不是长久之策;另一方面,自去年上半年我了解到 NLP 领域近两年来在生成式预训练大模型方面的长足进展后,也一直想看看基于这种大模型有什么可以实际落地的场景, 就这样,两个不同角度的想法合流成为了本项目的初衷。




