
本文将着重介绍开发者如何在腾讯云智能 TI 平台上快速的搭建 Angel 任务模型,快速的落地自己的业务场景。
分为以下三个主题:
智能钛机器学习平台(TI-ONE)介绍,介绍一下解决的问题和搭建使用的流程
Angel on TI-ONE,介绍 TI 平台对 Angel 的支持
快速搭建一个图算法任务流,具体实例演示图算法搭建
什么是 TI-ONE
智能钛机器学习平台 ( TI-ONE ) 是为 AI 工程师打造的一站式机器学习服务平台,为用户提供从数据预处理、模型构建、模型训练到模型评估的全流程开发支持。智能钛机器学习平台内置丰富的算法组件,支持多种算法框架,满足 AI 从业者各种应用场景的需求,包括今天分享的主题,对 Angel 的支持。
对一个 AI 从业者来说,TI-ONE 平台提供给其的价值能够匹配其所期望的搭建机器学习算法模型而面临的困境。
算法 AI、算法工程师在搭建模型时需要考虑的问题非常多,例如对个人开发者而言:
足够的 GPU 资源难以获得;
由于框架日新月异,维护各种算法框架的繁琐性高;
机器学习和深度学习的算法学习和搭建的门槛很高;
调参和对比算法效果费时费力;
实际业务复杂多变,版本更迭需要加快;
总之,由于上述各种原因,上线产品变成了费时且成本高昂的过程,TI-ONE 就是为了针对的解决问题,由此应运而生。智能钛机器学习平台 ( TI-ONE ) 是为 AI 工程师打造的一站式机器学习服务平台,为用户提供从数据预处理、模型构建、模型训练到模型评估的全流程开发支持。智能钛机器学习平台内置丰富的算法组件,支持多种算法框架,满足 AI 从业者各种应用场景的需求,包括今天分享的主题,对 Angel 的支持。
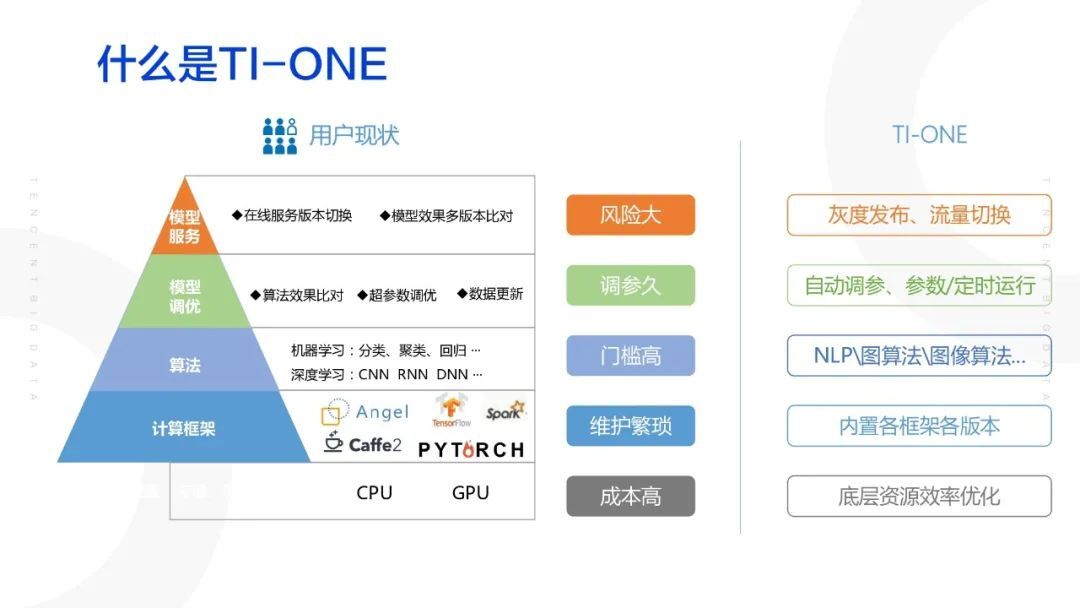
针对上面的问题,TI-ONE 平台提供了下列解决方案:
算力即购即用,可针对单次任务购买算力资源,多余算力随时随退;
拖拽式任务设计流程,自由根据任务绘制任务流;
集成了业界常见机器(深度)学习框架,例如 pytorch,tensorflow,pyspark,Angel 等等,并进行了优化,缩短了用户训练调试时间;
内置了业界常见的算法框架,例如 CNN,RNN,LPA,聚类,可视化等等,大大降低了 AI 应用落地的门槛,能够让更多的从业者享受 AI 带来的红利;
运行模式灵活,支持手工、定时、批量参数和重跑等模式,确保参数调整的即快又好;
支持一键部署,便于对外提供服务;
集成 Notebook 交互式建模十分便捷,助力开发者进行建模探索。
此外,我们也提供一些开源数据集资源,利于快速建模。

可视化建模
这里着重介绍可视化建模部分画布:
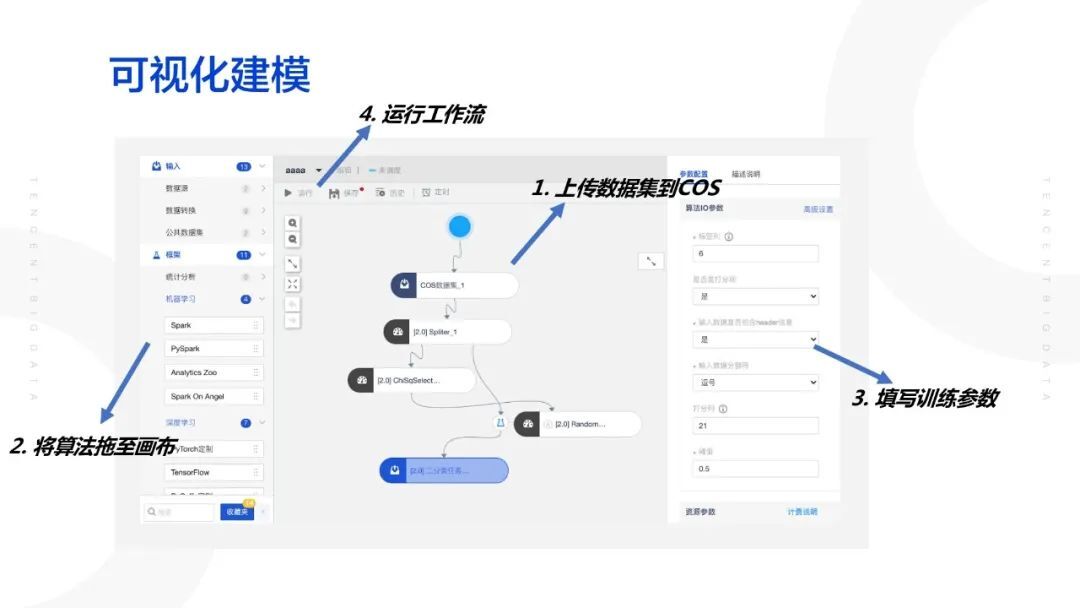
如此图所示,从左到右依次是算法框架组件,用户可以选用自己所需要的算法模块,包括输入,框架,可视化等等;中间画布是可视化画布图,用户将左侧选中的算法模块拖入,平台会帮助用户自动连线生成流程图,用户如果不满意,也可以自主修改流程图步骤;每点击一个中间画布的算法模块,右侧会生成菜单栏,包括此算法模块所有可以自定义的参数;最后用户只需要运行此流程图,平台就会根据流程图产生相应的结果,我们也可以看到运行日志和一些中间结果数据等等。
Angel on TI-ONE
1. TI-ONE 内置的 Angel 算法
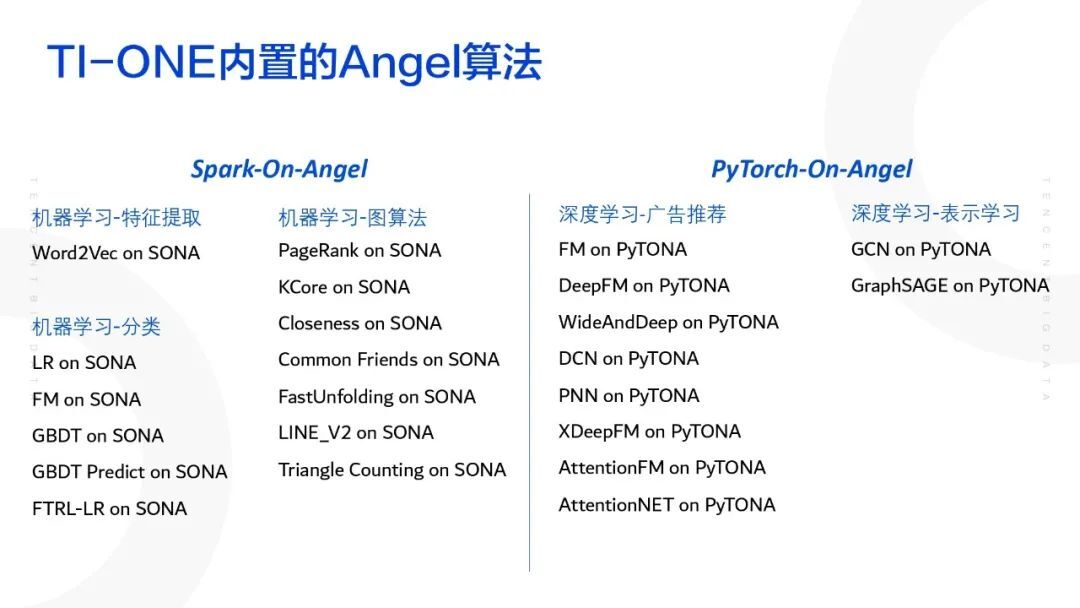
TI-ONE 平台中含有两种 Angel 算法模块,一是 Spark on Angel 框架,二是 Angel 算法组件。前者是平台内置框架,运行用户自定义的代码;后者是平台提供的算法组件,分为图算法,PyTONA 算法,机器学习算法。我们可以在说明文档中看到每一种算法的使用说明,参数说明等。我们提供上图中的 Angel 算法,以供用户自由选择使用。
2. 用户自定义代码训练
下面介绍用户自定义代码训练 Angel 算法模块的使用方式:
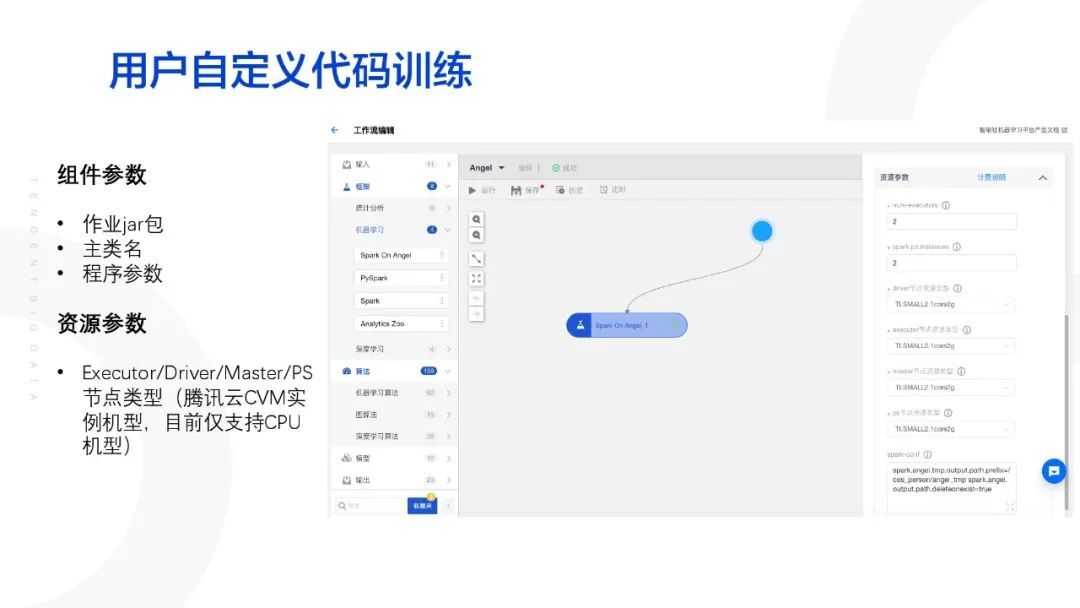
首先用户从左侧拖拽 Spark on Angel 的组件至中间画布,此时点击组件右侧就会出现需要填写的参数,主要分为两类,一是组件参数,包括作业 jar 包,主类名,程序参数,这里就是用户的自定义代码部分,平台也支持从腾讯云中拉取用户代码;二是资源组件,包括 Executor/Driver/Master/PS 节点类型,这是腾讯云 CVM 实例机型,目前仅支持 CPU 机型,所有支持的机型均可以在右侧下拉框内看到。相比于传统的代码提交,本平台的方式显得十分简明直观。平台也提供了统一的日志查看入口,我们可以通过腾讯云 CVM 实例查看训练日志。
快速搭建一个图算法任务流
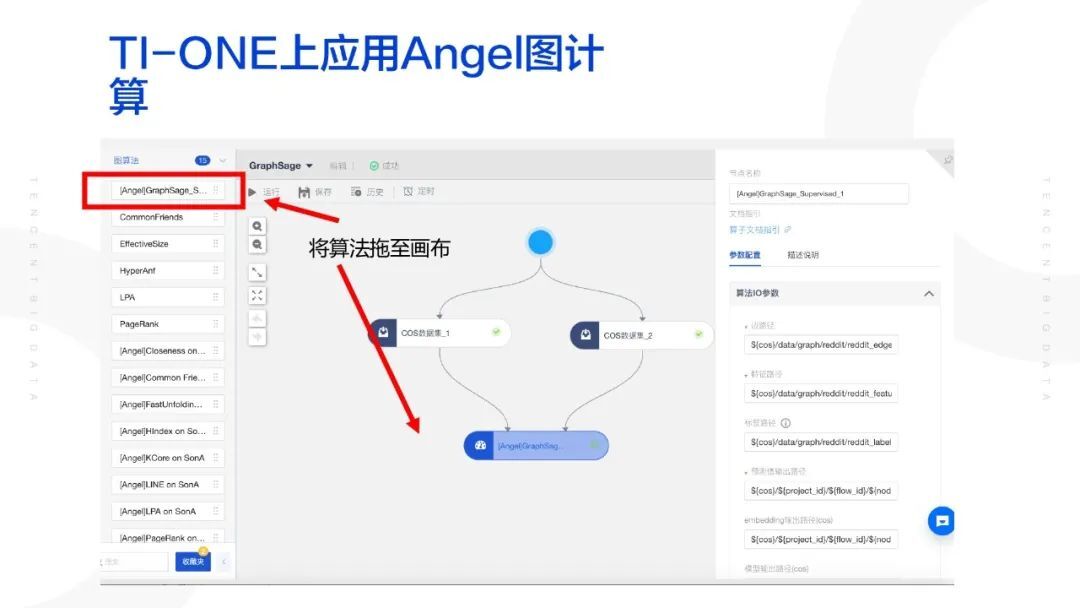
这里以 GraphSage 为例,展示如何在 TI-ONE 上应用 Angel 图计算。我们将该算法模块拖入中间画布,当然 COS 数据集需要提前拖入,平台将自动连接两者;右侧是我们拖入的 GraphSage 可以配置的参数,以及算法说明文档链接,我们可以根据此说明文件看到该算法在平台上的详细用法说明。算法 IO 参数就是我们所需要填写的参数类型,每一种参数类型的样例和维度等信息,我们都可以从说明文档中得知。

GraphSage 算法 IO 参数,包括:边路径,特征路径,标签路径,预测值输出路径,embedding 输出路径,模型输出路径,验证标签路径,都支持自定义。除了上述 IO 参数,我们也支持自定义算法本身参数,常见的包括:batchSize,学习率,数据分区数,Ps 分区数,均衡分区,Epoch,验证集比例,特征格式,采样邻居个数等等。资源参数也是可以自定义的参数,包括 num-executors,spark.ps.instances,driver 节点资源类型等等,从最小的 2 核 4G 到 64 核 256G 都支持用户申请,使用结束后,这些资源也将自动释放,不需要手动维护资源。
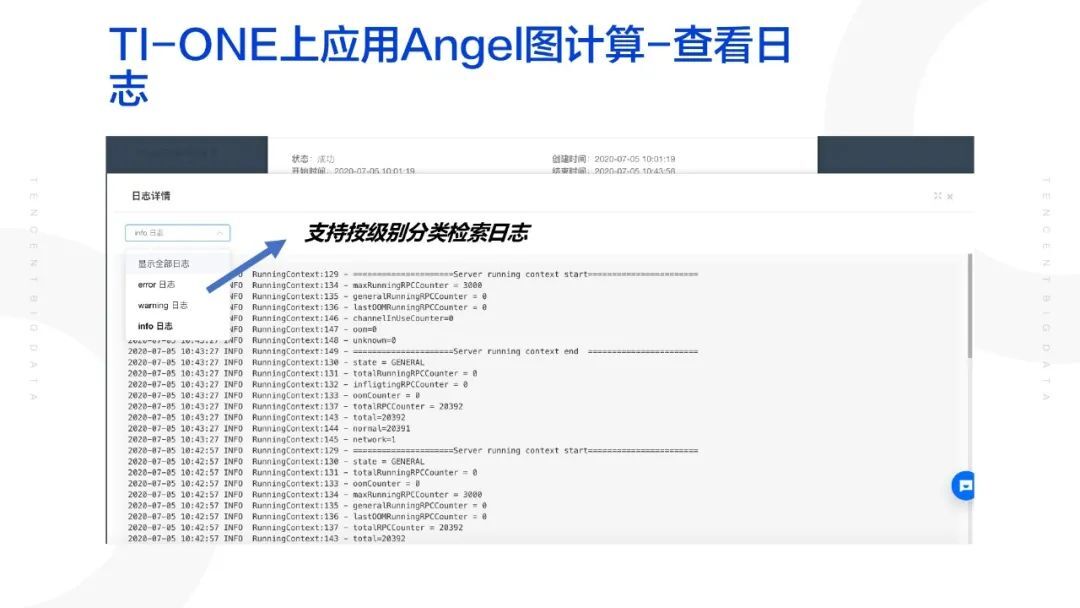
跑完算法模型之后,我们可以查看日志,也支持根据日志的类型级别取查看各种日志;关于模型结果,我们将提供模型链接,直达用户 COS。
总结下,从数据的上传到算法的选择和自定义、参数的填写、流程图的建立、日志的保存、模型的构建、结果的展示,都可以在 TI-ONE 平台上使用。
今天的分享就到这里,谢谢大家。
嘉宾介绍:
姚冕,腾讯云智能钛高级工程师
本文转载自:DataFunTalk(ID:datafuntalk)




