
来源 | 字节跳动基础架构团队
开源 | github.com/kubewharf/godel-scheduler
本文解读了字节跳动基础架构编排调度团队发表在国际云计算顶级会议 SoCC 2023 上的论文“Gödel: Unified Large-Scale Resource Managment and Scheduling at Bytedance”。

论文链接: dl.acm.org/doi/proceedings/10.1145/3620678
论文介绍了字节跳动内部基于 Kubernetes 提出的一套支持在线任务和离线任务混部的高吞吐任务调度系统,旨在有效解决大规模数据中心中不同类型任务的资源分配问题,提高数据中心的资源利用率、弹性和调度吞吐率。
目前,该调度系统支持管理着数万节点的超大规模集群,提供包括微服务、batch、流式任务、AI 在内的多种类型任务的资源并池能力。自 2022 年开始在字节跳动内部各数据中心批量部署,Gödel 调度器已经被验证可以在高峰期提供 >60%的 CPU 利用率和 >95%的 GPU 利用率,峰值调度吞吐率接近 5,000 pods/sec。
引言
在过去的几年里,随着字节跳动各业务线的高速发展,公司内部的业务种类也越来越丰富,包括微服务、推广搜(推荐/广告/搜索)、大数据、机器学习、存储等业务规模迅速扩大,其所需的计算资源体量也在飞速膨胀。
早期字节跳动的在线业务和离线业务有独立的资源池,业务之间采用分池管理。为了应对重要节日和重大活动时在线业务请求的爆炸性增长,基础设施团队往往需要提前做预案,将部分离线业务的资源拆借到在线业务的资源池中。虽然这种方法可以应对一时之需,但不同资源池之间的资源拆借流程长,操作复杂,效率很低。同时,独立的资源池导致在离线业务之间混部成本很高,资源利用率提升的天花板也非常有限。
为了应对这一问题,论文中提出了在离线统一调度器 Gödel,旨在使用同一套调度器来统一调度和管理在离线业务,实现资源并池,从而在提升资源利用率和资源弹性的同时,优化业务成本和体验,降低运维压力。Gödel 调度器基于 Kubernetes 平台,可以无缝替换 Kubernetes 的原生调度器,在性能和功能上优于 Kubernetes 原生调度器和社区中其他调度器。
开发动机
字节跳动运营着数十个超大规模的多集群数据中心,每天有数以千万计容器化的任务被创建和删除,晚高峰时单个集群的平均任务吞吐 >1000 pods/sec。这些任务的业务优先级、运行模式和资源需求各不相同,如何高效、合理地调度这些任务,在保证高优任务 SLA 和不同任务资源需求的同时维持较高的资源利用率和弹性是一项很有挑战的工作。
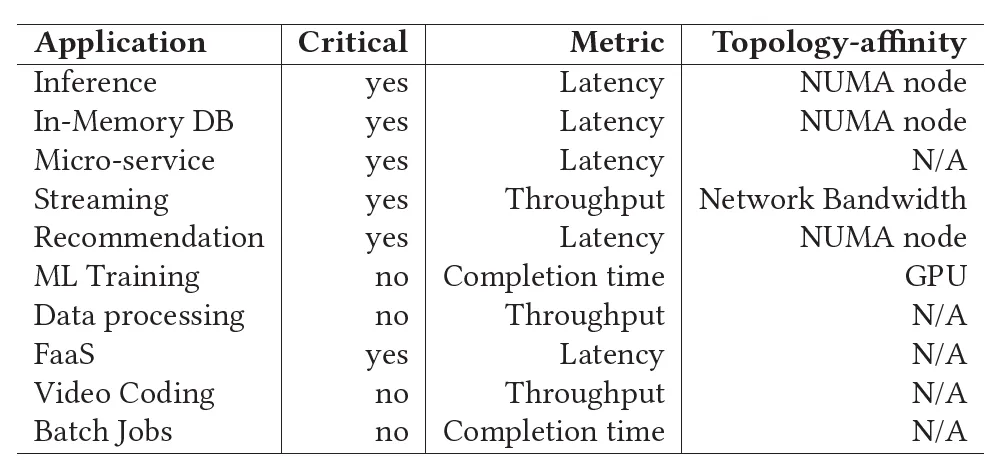
通过调研,目前社区常用的集群调度器都不能很好地满足字节跳动的要求:
Kubernetes 原生调度器虽然很适合微服务调度,也提供多种灵活的调度语义,但是它对离线业务的支持不尽如人意,同时因为 Kubernetes 原生调度器调度吞吐率低(< 200 pods/sec),支持的集群规模也有限(通常 <= 5000 nodes),它也无法满足字节跳动内部庞大的在线业务调度需求。
CNCF 社区的 Volcano 是一款主要针对离线业务的调度器,可以满足离线业务(e.g. batch, offline training 等)的调度需求(e.g. Gang scheduling)。但是其调度吞吐率也比较低,而且不能同时支持在线业务。
YARN 是另一款比较流行的集群资源管理工具,在过去很长一段时间一直是离线业务调度的首选。它不仅对 batch、offline training 等离线业务所需的调度语义有很好的支持,而且调度吞吐率也很高,可以支持很大规模的集群。但其主要弊端是对微服务等在线业务的支持不好,不能同时满足在线和离线业务的调度需求。

因此,字节跳动希望能够开发一款结合 Kubernetes 和 YARN 优点的调度器来打通资源池、统一管理所有类型的业务。基于上述讨论,该调度器被期望具有下述特点:
Unified Resource Pool
集群中的所有计算资源对在线和离线的各种任务均可见、可分配。降低资源碎片率,和集群的运维成本。
Improved Resource Utilization
在集群和节点维度混部不同类型、不同优先级的任务,提高集群资源的利用率。
High Resource Elasticiy
在集群和节点维度,计算资源可以在不同优先级的业务之间灵活且迅速地流转。在提高资源利用率的同时,任何时候都保证高优业务的资源优先分配权和 SLA。
High Scheduling Throughput
相比于 Kubernetes 原生调度器和社区的 Volcano 调度器,不论是在线还是离线业务都要大幅提高调度吞吐率。满足 > 1000 pods/sec 的业务需求。
Topology-aware Scheduling
在做调度决策时而不是 kubelet admit 时就识别到候选节点的资源微拓扑,并根据业务需求选择合适的节点进行调度。
Gödel 介绍
Gödel Scheduler 是一个应用于 Kubernetes 集群环境、能统一调度在线和离线业务的分布式调度器,能在满足在离线业务功能和性能需求的前提下,提供良好的扩展性和调度质量。
如下图所示,Gödel Scheduler 和 Kubernetes 原生调度器的结构类似,由三个组件组成:Dispatcher、Scheduler 和 Binder。不一样的是,为了支持更大规模的集群和提供更高的调度吞吐,它的 Scheduler 组件可以是多实例的,采用乐观并发调度, Dispatcher 和 Binder 则是单实例运行。
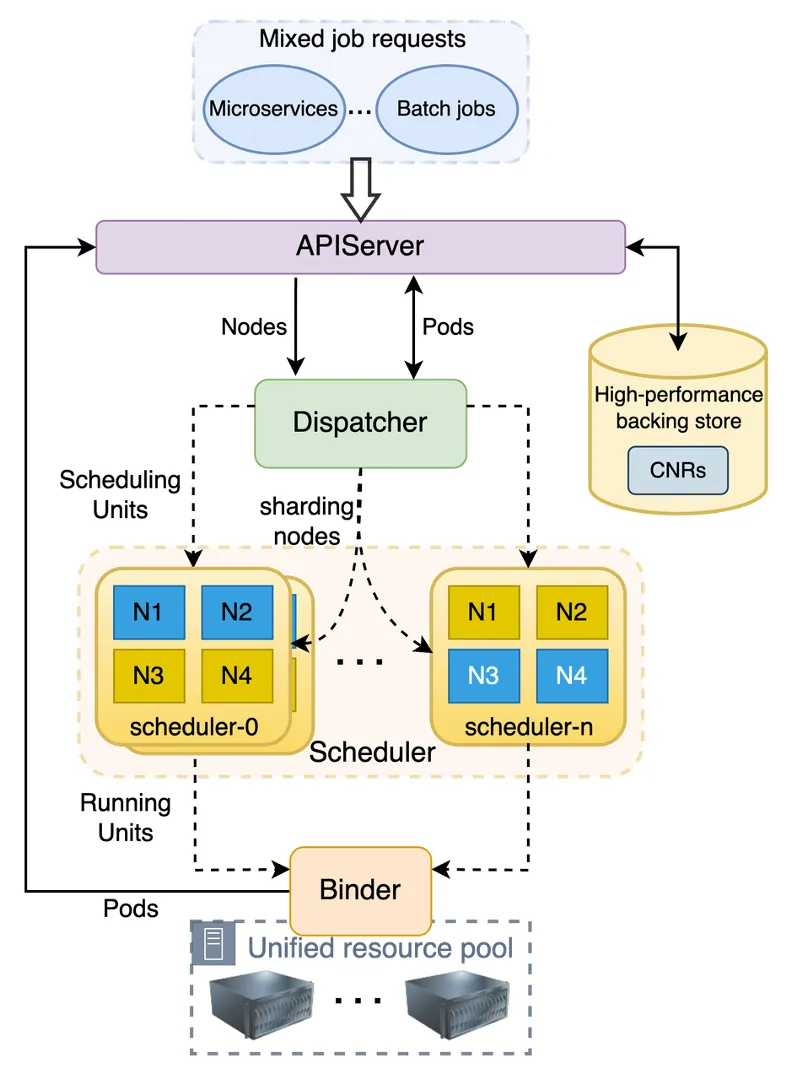
核心组件
Dispatcher 是整个调度流程的入口,主要负责任务排队、任务分发、节点分区等工作。它主要由几个部分构成:Sorting Policy Manager、Dispatching Policy Manager、Node Shuffler、Scheduler Maintainer。
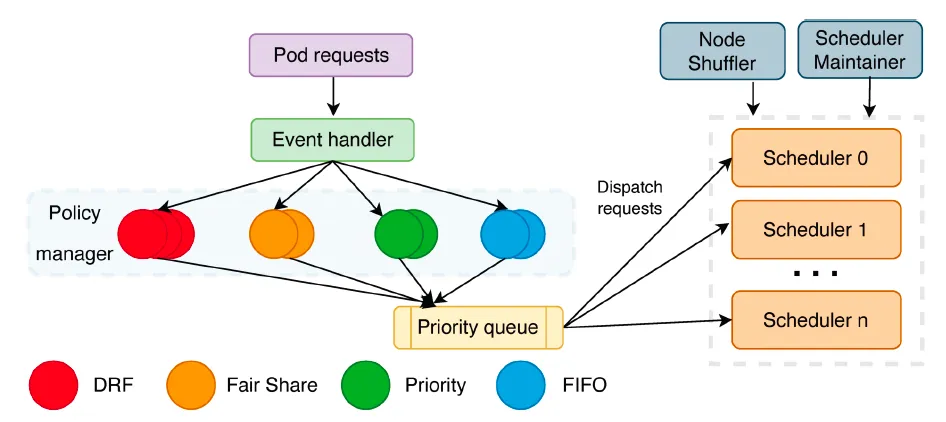
Sort Policy Manager:主要负责对任务进行排队,现在实现了 FIFO、DRF、FairShare 等排队策略,未来会添加更多排队策略,如:priority value based 等。
Dispatching Policy Manager:主要负责分发任务到不同的 Scheduler 实例,通过插件化配置支持不同的分发策略。现阶段的默认策略是基于 LoadBalance。
Node Shuffler:主要负责基于 Scheduler 实例个数,对集群节点进行 Partition 分片。每个节点只能在一个 Partition 里面。每个 Scheduler 实例对应一个 Partition,一个 Scheduler 实例工作的时候会优先选择自己 Partition 内的节点,没有找到符合要求的节点时才会去找其他 Partition 的节点。如果集群状态发生变化,例如增加或者删除节点,又或者 Scheduler 个数改变,node shuffle 会基于实际情况重新划分节点。
Scheduler Maintainer:主要负责对每个 Scheduler 实例状态进行维护,包括 Scheduler 实例健康状况、负载情况、Partition 节点数等。
Scheduler 从 Dispatcher 接收任务请求,负责为任务做出具体的调度和抢占决策,但是不真正执行。和 Kubernetes 原生调度器一样,Gödel 的 Scheduler 也是通过一系列不同环节上的 plugins 来决定一个调度决策,例如通过下面两个 plugins 来寻找符合要求的节点。
Filtering plugins:基于任务的资源请求,过滤掉不符合要求的节点;
Scoring plugins:对上面筛选出来的节点进行打分,选出最合适的节点。
和 Kubernetes 原生调度器不同的是,Gödel 的 Scheduler 允许多实例分布式运行。对于超大规模的集群和对高吞吐有要求的场景,我们可以配置多个 scheduler 实例来满足需求。此时每个 scheduler 实例独立、并行地进行调度,选择节点时,优先从该实例所属的 partition 中选择,这样性能更好,但只能保证局部最优;本地 partition 没有合适的节点时,会从其他实例的 partition 中选择节点,但这可能会引起 conflict,即多个 scheduler 实例同时选中同一个节点,scheduler 实例数量越多,发生 conflict 的几率越大。因此,要合理设置实例的数量,不是越多越好。
另外,为了同时支持在线和离线任务,Gödel Scheduler 采用了两层调度语义,即支持代表 Pod Group 或 ReplicaSet 等业务部署的 Scheduling Unit 和 Pod 的 Running Unit 的两级调度。具体用法将在后面介绍。
Binder 主要负责乐观冲突检查,执行具体的抢占操作,进行任务绑定前的准备工作,比如动态创建存储卷等,以及最终执行绑定操作。总的来说,它和 Kubernetes 的 Binder 工作流程类似,但在 Gödel 中,Binder 要处理更多由于多 Scheduler 实例导致的冲突。一旦发现冲突,立即打回,重新调度。对于抢占操作,Binder 检查是否存在多个 Schduler 实例尝试抢占同一个实例(i.e. Victim Pod)。如果存在这样的问题,Binder 只处理第一个抢占并拒绝其余 Schduler 实例发出的抢占诉求。对于 Gang/Co-scheduling 而言,Binder 必须为 Pod Group 中的所有 Pod 处理冲突(如果存在的话)。要么所有 Pod 的冲突都得到解决,分别绑定每个 Pod;要么拒绝整个 Pod Group 的调度。
CNR 代表 Custom Node Resource,是字节跳动为补充节点实时信息创建的一个 CRD。它虽然本身不是 Gödel Scheduler 的一部分,但可以增强 Gödel 的调度语义。该 CRD 不仅定义了一个节点的资源量和状态,还定义了资源的微拓扑,比如 dual-socket 节点上每个 socket 上的 CPU/Memory 消耗量和资源剩余量。使得调度器在调度有微拓扑亲和需求的任务时,可以根据 CNR 描述的节点状态筛选合适的节点。
相比于只使用 topology-manager 的原生 Kubernetes,使用 CNR 可以避免将 Pod 调度到不满足 topology 限制的节点上时 kubelet 碰到的 scheduling failure。如果一个 Pod 成功地在节点上创建,CNR 将会被隶属于 Katalyst 的 node agent 更新。
相关阅读:《Katalyst:字节跳动云原生成本优化实践》
两层调度
字节跳动在设计 Gödel 之初,一个主要的目标就是能够同时满足在线和离线业务的调度需求。为了实现这一目标,Gödel 引入了两层调度语义,即 Scheduling Unit 和 Running Unit。
前者对应一个部署的 job,由一个或多个 Running Unit 组成。例如,当用户通过 Kubernetes Deployment 部署一个 job 时,这个 job 映射为一个 Scheduling Unit,每个运行 task 的 Pod 对应一个 Running Unit。和原生 Kubernetes 直接面向 Pod 的调度不同,Gödel 的两级调度框架会始终以 Scheduling Unit 的整体状态为准入原则。当一个 Scheduling Unit 被认为可调度时,其包含的 Running Unit(i.e. Pod)才会被依次调度。
判断一个 Scheduling Unit 是否可调度的规则是有 >= Min_Member 个 Running Unit 满足调度条件,即调度器能够为一个 job 中足够多的 Pod 找到符合资源要求的节点时,该 job 被认为是可以被调度的。此时,每个 Pod 才会被调度器依次调度到指定的节点上。否则,所有的 Pod 均不会被调度,整个 job 部署被拒绝。
可以看出,Scheduling Unit 的 Min_Member 是一个非常重要的参数。设置不同的 Min_Member 可以应对不同场景的需求。Min_Member 的取值范围是[1, Number of Running Units]。
比如,当面向微服务的业务时,Min_Member 设置为 1。每个 Scheduling Unit 中只要有一个 Running Unit/Pod 的资源申请能够被满足,即可进行调度。此时,Gödel 调度器的运行和原生 Kubernetes 调度器基本一致。
当面向诸如 Batch、offline training 等需要 Gang 语义的离线业务时,Min_Member 的值等于 Running Unit/Pod 的个数(有些业务也可以根据实际需求调整为 1 到 Number of Running Units 之间的某个值),即所有 Pod 都能满足资源请求时才开始调度。Min_Member 的值会根据业务类型和业务部署 template 中的参数被自动设置。
性能优化
因为字节跳动自身业务的需求,对调度吞吐的要求很高。Gödel 的设计目标之一就是提供高吞吐。为此,Gödel 调度器把最耗时的筛选节点部分放在可并发运行的多实例 Scheduler 中。一方面因为多实例会碰到 conflict 的原因,Schduler 的实例数量不是越多越好;另一方面仅仅多实例带来的性能提高不足以应对字节单一集群上晚高峰 1000 - 2000 pods/s 的吞吐要求。为了进一步提高调度效率,Gödel 在以下几个方面做了进一步优化。
缓存候选节点
在筛选节点的过程中,Filter 和 Prioritize 是最耗时的两个部分。前者根据资源请求筛选可用的节点,后者给候选节点打分寻找最适宜的节点。如果这两个部分的运行速度能够提高,则整个调度周期会被大幅压缩。
字节跳动开发团队观察到,虽然计算资源被来自不同业务部门的不同应用所使用,但是来自某一个业务用户的某个应用的所有或者大部分 Pods 通常有着相同的资源诉求。
例:某个社交 APP 申请创建 20,000 个 HTTP Server,每个 Server 需要 4 CPU core 和 8GB 内存。某个 Big Data 团队需要运行一个拥有 10,000 个子任务的数据分析程序,每个子任务需要 1 CPU core 和 4GB 内存。
这些大量创建的任务中多数 Pod 拥有相同的资源申请、相同的网段和设备亲和等需求。那么 Filter Plugin 筛选出来的候选节点符合第一个 Pod 的需求,也大概率满足该任务其他 Pod 的需求。
因此,Gödel 调度器会在调度第一个 Pod 后缓存候选节点,并在下一轮调度中优先从缓存中搜索可用的节点。除非集群状态发生变化(增加或删除节点)或者碰到不同资源诉求的 Pod,不需要每一轮都重新扫描集群中的节点。在调度的过程中没有资源可分配的节点会被移除缓存,并根据集群状态调整排序。这一优化可以明显优化节点筛选的过程,当调度同一个业务用户的一组 Pod 时,理想情况下可以把时间复杂度从 O(n) 降低到 O(1)。
降低扫描节点的比例
虽然上述优化可以降低候选节点的构建过程,但是如果集群状态或者资源申请发生变化,还是要重新扫描集群所有节点。
为了进一步降低时间开销,Gödel 调整了候选列表的扫描比例,用局部最优解作为全局最优解的近似替代。因为调度过程中需要为所有 Running Units/Pods 找到足够的候选节点,Gödel 至少会扫描 # of Running Units 个数的节点,根据历史数据的分析,Gödel 默认扫描 # of Running Units + 50 个节点来寻找候选节点。如果没有找到合适的,会再扫描相同的个数。该方法结合候选节点缓存,会大大降低调度器为 Pod 寻找合适节点的时间开销。
优化数据结构和算法
除了上述两个优化外,Gödel 调度器还不断对数据结构和算法进行优化:
为了可以低成本地维护候选节点列表,避免频繁重建节点列表产生的开销。Gödel 重构了原生 Kubernetes 调度器的 NodeList 维护机制,通过离散化节点列表的方式解决了超大规模生产集群出现的性能问题,并以更低的开销获得了更好的节点离散效果;
为了提高整体资源利用率,字节跳动将高优的在线任务和低优的离线任务混合部署。由于业务的潮汐特点,晚高峰时伴随着大量在线业务的返场,往往需要高频地抢占低优的离线业务。抢占过程涉及到大量的搜索计算,频繁抢占严重地影响了调度器的整体工作效率。为了解决这一问题,Gödel 调度器引入了基于 Pod 和 Nodes 的多维剪枝策略,使得抢占吞吐能够快速回升、抢占时延大幅降低。
实验结果
论文评估了 Gödel 调度器在调度吞吐、集群规模等方面的性能。
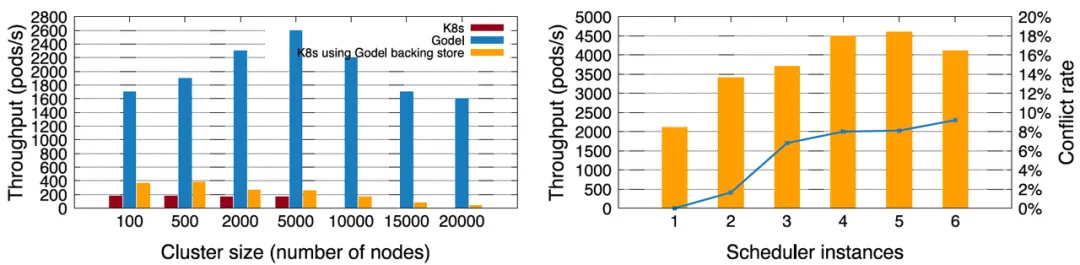
首先,对于微服务业务,字节跳动将 Gödel(单实例)与 Kubernetes 原生调度器进行了对比。在集群规模上,原生 Kubernetes 默认最大只能支持 5,000 节点的集群,最大调度吞吐小于 200 Pods/s。在使用字节开源的高性能 key-value store - KubeBrain 后,原生 Kubernetes 可以支持更大规模的集群,调度吞吐也明显提高。但 Kubernetes + KubeBrain 组合后的性能仍然远小于 Gödel。Gödel 在 5,000 节点规模的集群上可以达到 2,600 Pods/s 的性能,即使在 20,000 节点时仍然有约 2,000 Pods/s,是原生 Kubernetes 调度器性能的 10 倍以上。
为了取得更高的调度吞吐,Gödel 可以开启多实例。下面右图中描述的是 10,000 节点的集群中依次开启 1-6 个 调度器实例,开始阶段吞吐逐渐增加,峰值可以达到约 4,600 Pods/s。但当实例数超过 5 个后,性能有所下降,原因是实例越多,实例间的冲突越多,影响了调度效率。所以,并不是调度实例越多越好。
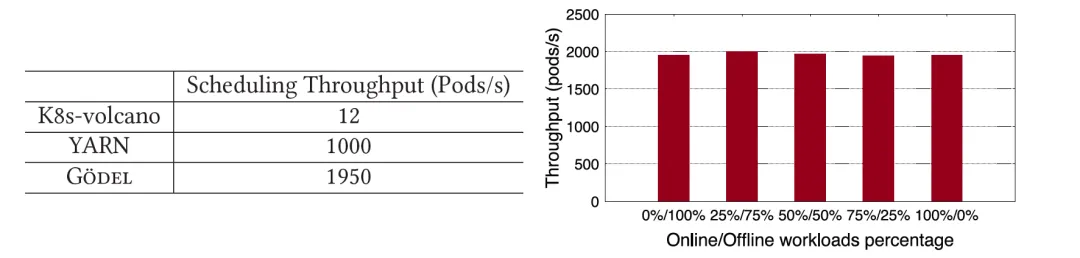
对于有 Gang 语义需求的离线任务,论文将 Gödel 和开源社区常用的 YARN 和 K8s-volcano 进行对比。可以明显看出,Gödel 的性能不但远远高于 K8s-volcano,也接近两倍于 YARN。Gödel 支持同时调度在线和离线任务,论文通过改变系统中提交的在离线任务的比例来模拟不同业务混部时的场景。可以看出,不论在离线业务的比例如何,Gödel 的性能都比较稳定,吞吐维持在 2,000 Pods/s 左右。
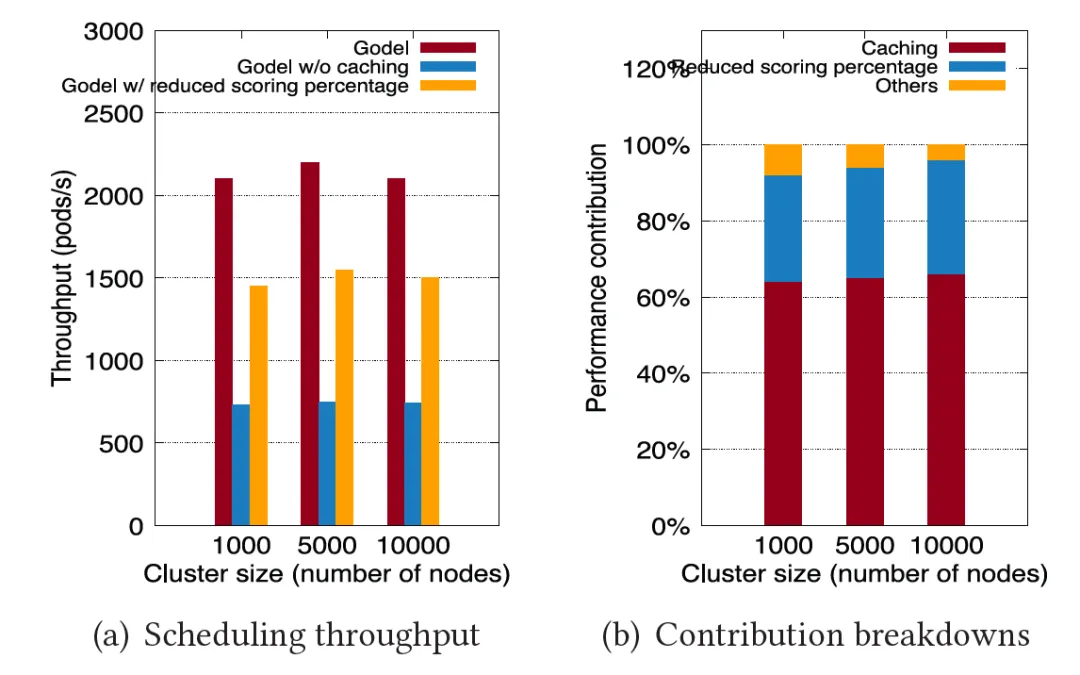
为了论证为什么 Gödel 会有如此大的性能提高,论文着重分析了两个主要的优化“缓存候选节点”和“降低扫描比例”产生的贡献。如下图所示,依次使用完整版 Gödel、只开启节点缓存优化的 Gödel 和只开启降低扫描比例的 Gödel 来重复前面的实验,实验结果证明,这两个主要的优化项分别贡献了约 60% 和 30% 的性能提升。
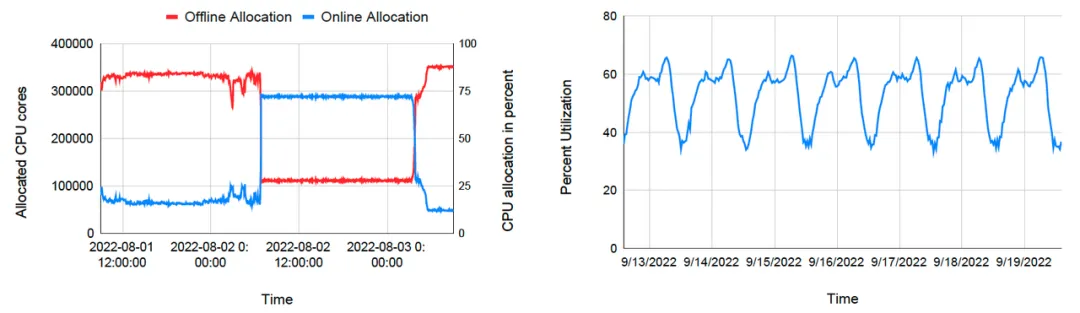
除了用 benchmark 来评估 Gödel 的极限性能,论文还展示了字节跳动在生产环境中使用 Gödel 调度器带来的实际体验,表现出 Gödel 在资源并池、弹性和流转方面具备良好的能力。
下面左图描述的是某集群在某段时间内在线任务和离线任务的资源分配情况。开始阶段,在线任务消耗的资源不多,大量计算资源被分配给优先级较低的离线任务。当在线任务由于某个特殊事件(突发事件、热搜等)导致资源需求激增后,Gödel 立刻把资源分配给在线任务,离线任务的资源分配量迅速减少。当高峰过后,在线任务开始降低资源请求,调度器再次把资源转向离线任务。通过在离线并池和动态资源流转,字节跳动可以一直维持较高的资源利用率。晚高峰时间,集群的平均资源率达到 60%以上,白天波谷阶段也可以维持在 40% 左右。
总结及未来展望
论文介绍了字节跳动编排调度团队设计和开发的统一在离线资源池的调度系统 Gödel。该调度系统支持在超大规模集群中同时调度在线和离线任务,支持资源并池、弹性和流转,并拥有很高的调度吞吐。Gödel 自 2022 年在字节跳动自有数据中心批量上线以来,满足了内场绝大部分业务的混部需求,实现了晚高峰 60% 以上的平均资源利用率和约 5,000 Pods/s 的调度吞吐。
未来,编排调度团队会继续推进 Gödel 调度器的扩展和优化工作,进一步丰富调度语义,提高系统响应能力,降低多实例情况下的冲突概率,并且会在优化初次调度的同时,构建和加强系统重调度的能力,设计和开发 Gödel Rescheduler。通过 Gödel Scheduler 和 Rescheduler 的协同工作,实现全周期内集群资源的合理分配。
Gödel 调度器目前已开源,真诚欢迎社区开发者和企业加入社区,与我们一起参与项目共建,项目地址:github.com/kubewharf/godel-scheduler
文章专题推荐:字节跳动云原生创新实践与开源之路




