
Lambda 架构已经成为一种流行的架构风格,它通过使用批处理和流式处理的混合方法来保证数据处理的速度和准确性。但它也有一些缺点,比如额外的复杂性和开发/运维开销。LinkedIn 高级会员有一个功能,就是可以查看谁浏览过你的个人资料(Who Viewed Your Profile,WVYP),这个功能曾在一段时间内采用了 Lambda 架构。支持这一功能的后端系统在过去的几年中经历了几次架构迭代:从 Kafka 客户端处理单个 Kafka 主题开始,最终演变为具有更复杂处理逻辑的 Lambda 架构。然而,为了追求更快的产品迭代和更低的运维开销,我们最近把它变成无 Lambda 的。在这篇文章中,我们将分享一些在采用 Lambda 架构时的经验教训、过渡到无 Lambda 时所做的决定,以及经历这个过渡所必需的转换工作。
这个系统是如何运作的
WVYP 系统依靠一些不同的输入源向会员提供最近浏览过其个人资料的记录:
捕获浏览信息并进行除重;
计算浏览源(例如,通过搜索、资料页面浏览等);
浏览相关性(例如,一位高级人员查看了你的资料);
根据会员的隐私设置查看模糊信息。
下图显示了使用 Lambda 架构的系统简化图。
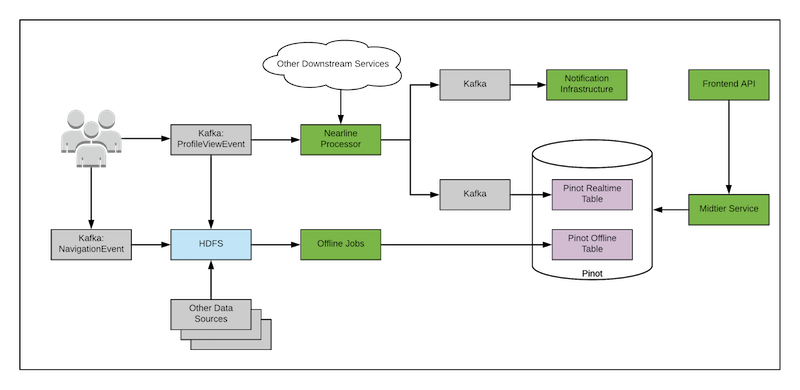
首先,我们有一个 Kafka 客户端,可以近实时地处理并提供会员资料视图活动。当一个会员查看另一个会员的个人资料时,会生成一个叫作 ProfileVieweEvent 的事件,并发送到 Kafka 主题。处理作业将消费这个 ProfileVieweEvent 并调用大约 10 个其他在线服务来获取额外的信息,如会员概要数据、工作申请信息、会员网络距离(一度、二度连接)等。然后,该作业将处理后的消息写入另一个 Kafka 主题,这个主题的消息将被 Pinot(一个分布式 OLAP 数据存储,https://pinot.apache.org)消费。Pinot 将处理后的消息追加到实时中。Pinot 可以处理离线和实时数据,所以非常适合被用在这个地方。
与此同时,还有一组离线的 Hadoop MapReduce 作业在不同的技术栈中执行上述操作,使用的是 ETL 过的 ProfileViewEvent 和上述服务处理过的相应数据集。这些作业每天加载这些数据集,并执行数据转换操作,如过滤、分组和连接。此外,如上图所示,离线作业还将处理实时作业不处理的 NavigationEvent,这个事件可以告诉我们浏览者是如何找到被浏览资料的。处理后的数据集被插入到 Pinot 的离线表中。
Pinot 数据库负责处理来自实时表和离线表的数据。中间层服务通过查询 Pinot 获取处理过的会员资料信息,并根据前端 API 的查询参数(如时间范围、职业等)对数据进行切片和切块。
这就实现了 Lambda 架构:
实时作业侧重速度,进行不完整信息的快速计算;
Hadoop 离线作业侧重批处理,旨在提高准确性和吞吐量;
Pinot 数据存储是服务层,将批处理和实时处理的视图合并起来。
Lambda 架构为我们带来了很多优势,这要得益于实时处理的快速和批处理的准确性及可再处理性。然而,这也伴随着大量的运维开销。随着我们不断迭代产品并增加更多的复杂性,是时候做出改变了。
我们的挑战
众所周知,Lambda 架构带来了饱受诟病的运维开销,违反了“不要重复你自己”(DRY)原则。更具体地说,WVYP 系统面临以下几个挑战:
开发人员必须构建、部署和维护两个管道,这两个管道产生数据大部分是相同的;
这两个处理管道需要在业务逻辑方面保持同步。
上述的两个挑战占用了开发人员大量的时间。
导致系统的演化有很多不同的原因,包括特性增强、bug 修复、合规性或安全性的变更、数据迁移等。WYVP 的所有这些变更都需要付出双倍的成本,部分原因是因为 Lambda 架构。更糟糕的是,Lambda 架构还带来了额外的问题,因为我们是基于两个不同的技术栈实现大部分的特性,所以新的 bug 可能会在批处理或实时处理中出现。此外,随着 LinkedIn 工具和技术栈的不断演化,我们需要不断地跟进,以便能够保持在最新状态。例如,在最近的一次 GEO 位置数据迁移过程中,我们发现了一些不必要的复杂性。Lambda 架构的分层带来了运维上的负担。例如,实时作业在处理消息是会出现延迟,离线作业有时会失败——这两种情况我们都太熟悉了。最终我们发现,这种开销是不值得的,因为它显著降低了开发速度。因此,我们开始努力重新改造 WVYP 的 Lambda 架构。
无 Lambda 架构
我们开始简化架构,移除全部离线批处理作业,并使用 Samza 开发新的实时消息处理器。我们之所以选择移除离线作业并保留实时处理,主要原因是产品需要近实时的会员资料浏览通知。批处理更适合用在其他一些场景中,例如在 A/B 测试中计算业务指标影响。
新架构如下图所示。
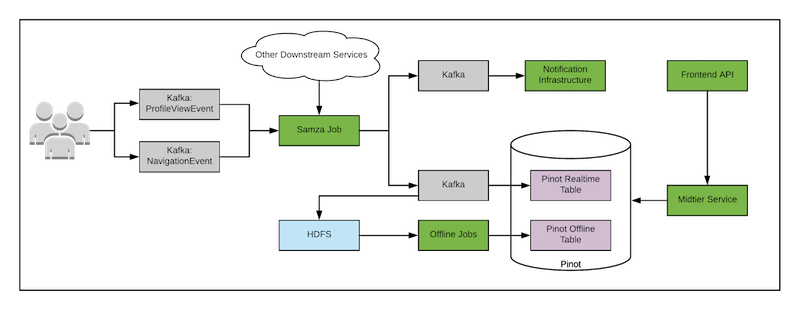
新架构的两个主要变化:
创建了一个新的 Samza 作业,用来消费 ProfileVieweEvent 和 NavigationEvent,旧的消费者客户端只消费 ProfileVieweEvent。
所有的离线作业都被移除,并创建了一个单独的作业,我们稍后将讨论这个作业。
Samza 作业
Samza 最初由 LinkedIn 开发,是 LinkedIn 的分布式流式处理服务,现在是 Apache 的一个项目。我们选择将现有的实时处理器作业迁移到 Samza 有很多原因。
首先,Samza 支持各种编程模型,包括 Beam 编程模型。Samza 实现了 Beam API(https://beam.apache.org):我们可以用它轻松地创建数据处理单元管道,包括过滤、转换、连接等。例如,在我们的例子中,我们可以很容易地加入 PageVieweEvent 和 NavigationEvent,近乎实时地计算出视图的来源——这在旧处理器中是不容易做到的。其次,在 LinkedIn 部署和维护 Samza 作业非常简单,因为它们运行在由 Samza 团队维护的 YARN 集群上。开发团队仍然需要处理伸缩、性能等问题,但在定期维护方面确实有很大帮助(例如,不需要担心机器发生故障)。最后,Samza 与 LinkedIn 的其他工具和环境进行了很好的集成。
新的离线作业
有些人可能会问,为什么我们仍然在无 Lambda 架构使用离线作业。事实上,从架构转换的角度来看,这并不是必要的。但是,如上图所示,离线作业会读取 HDFS 里经过 ETL 的数据,这些数据是由 Samza 作业通过 Kafka 主题间接产生的。离线作业的唯一目的是将所有写入 Pinot 实时表的数据复制到离线表。这样做有两个原因:1)由于数据的组织方式,离线表有更好的性能(离线表的数据段比实时表要少得多,查询速度更快)。2)处理过的视图数据将保留 90 天,而实时表只保留几天的数据,并通过自动数据清除功能进行清除。新离线作业与旧离线作业的一个关键区别是,新作业在处理逻辑上与实时作业没有重叠,它没有实现 Samza 作业中已经实现的逻辑。当 Pinot 能够自动支持从实时表到离线表的文件整合时,我们就可以移除这个作业。
消息再处理
天底下没有无 bug 的软件,一切事物仍然会以不同的方式出错。对于 WVYP,使用错误的逻辑处理过的事件会一直保留在数据库中,直到被重新处理和修复。此外,一些意想不到的问题会在系统可控范围之外发生(例如,数据源被破坏)。批处理的一个重要作用是进行再处理。如果作业失败,它可以重新运行,并生成相同的数据。如果源数据被损坏,它可以重新处理数据。
在进行流式处理时,这个会更具挑战性,特别是当处理过程依赖其他有状态的在线服务提供额外的数据时。消息处理变成非幂等的。WVYP 在状态方面依赖在线服务,在消息被处理时需要向会员发送通知(但我们不想发送重复的通知)。如果所选择的数据存储不支持随机更新,比如 Pinot,那么我们就需要一个重复数据删除机制。
我们意识到,要解决这个问题,并没有什么灵丹妙药。我们决定以不同的方式对待每个问题,并使用不同的策略来缓解问题:
如果我们要对处理过的消息做一些微小的改动,最好的方法是写一个一次性离线作业,读取 HDFS 中已处理的消息(就像新架构中的离线作业那样),进行必要的处理,再推送到 Pinot,覆盖掉之前的数据文件。
如果出现重大的处理错误,或者 Samza 作业处理大量事件失败,我们可以将当前的处理偏移量倒回到前一个位置。
如果作业只在某段时间内降级,例如视图相关性的计算失败,我们将跳过某些视图。对于这种情况,系统将在这段时间内降低容量。
去重
重复处理发生在各种场景中。一个是上面提到的,我们显式地想要重新处理数据。另一个是 Samza 固有的,为了确保消息的至少一次处理。当 Samza 容器重新启动时,它可能会再次处理一些消息,因为它读取的检查点可能不是它处理的最后一条消息。我们可以在两个地方解决去重问题:
服务层:当中间层服务从 Pinot 表中读取数据时,它会进行去重,并选择具有最新处理时间的视图。
通知层:通知基础设施确保我们不会在指定的时间段内向会员发送重复的通知。
价值
Lambda 架构已经存在了很多年,并得到了相当多的赞扬和批评。在迁移 WVYP 的过程中,我们获得了以下这些好处:
通过将大部分的开发时间减半,开发速度得到了显著的提升,维护开销也减少了一半以上(实时流程的维护开销比批处理流程少)。
提升了会员的用户体验。现在在开发过程中引入错误的可能性降低了。我们也有了更好的实时计算(例如,视图源的快速计算,这在以前是不可用的),可以更快地为会员提供 WVYP 信息。
通过释放开发人员的时间,我们现在能够进行更快的迭代,并将精力放到其他地方。在这篇文章中,我们分享了 WVYP 系统的开发、运行和重新改造过程,希望我们的一些收获能够帮助那些在使用 Lambda 架构时面临类似问题的人做出更好的决策。
原文链接:
https://engineering.linkedin.com/blog/2020/lambda-to-lambda-less-architecture




