
近日,被称为 GPT-4o 平替的 ChatTTS 文本转语音开源项目爆火。没多久,字节跳动也推出了自己的语音生成模型 Seed-TTS,能生成与人类语音几乎没有区别的语音,支持多种语言包括英语、中文,能够进行同语言生成和跨语言生成。
不过让人没想到的是,6 月 4 日,字节刚公开发布相关论文后,市面上立马就出现了不止一个山寨 Seed-TTS 的网站,而其中部分山寨网站实际项目套壳了 ChatTTS。目前,AI 前线至少发现了三个山寨网站,分别是:
其中,最后一个网站曾直接 link 到了 ChatTTS 开源仓库。
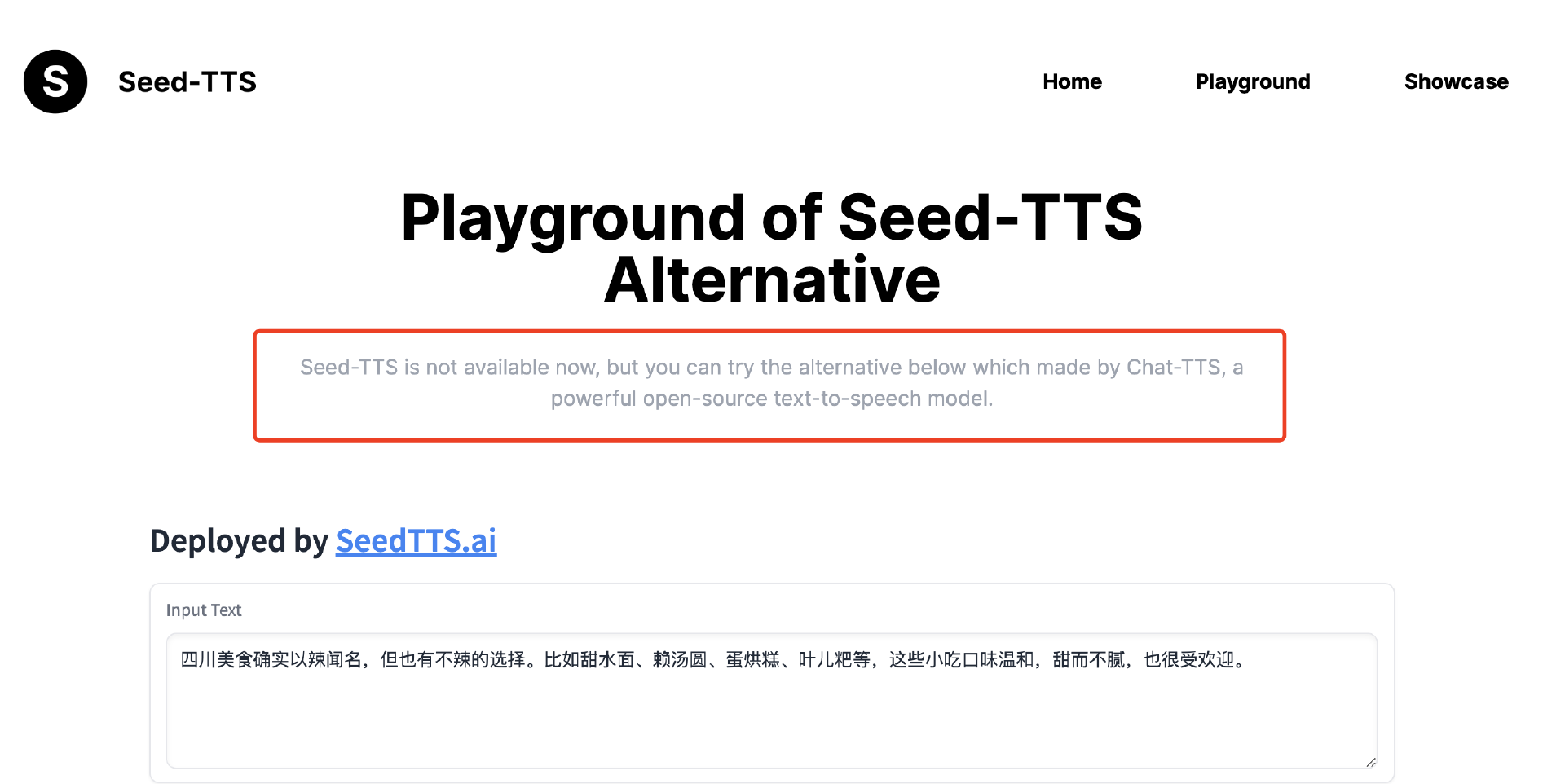
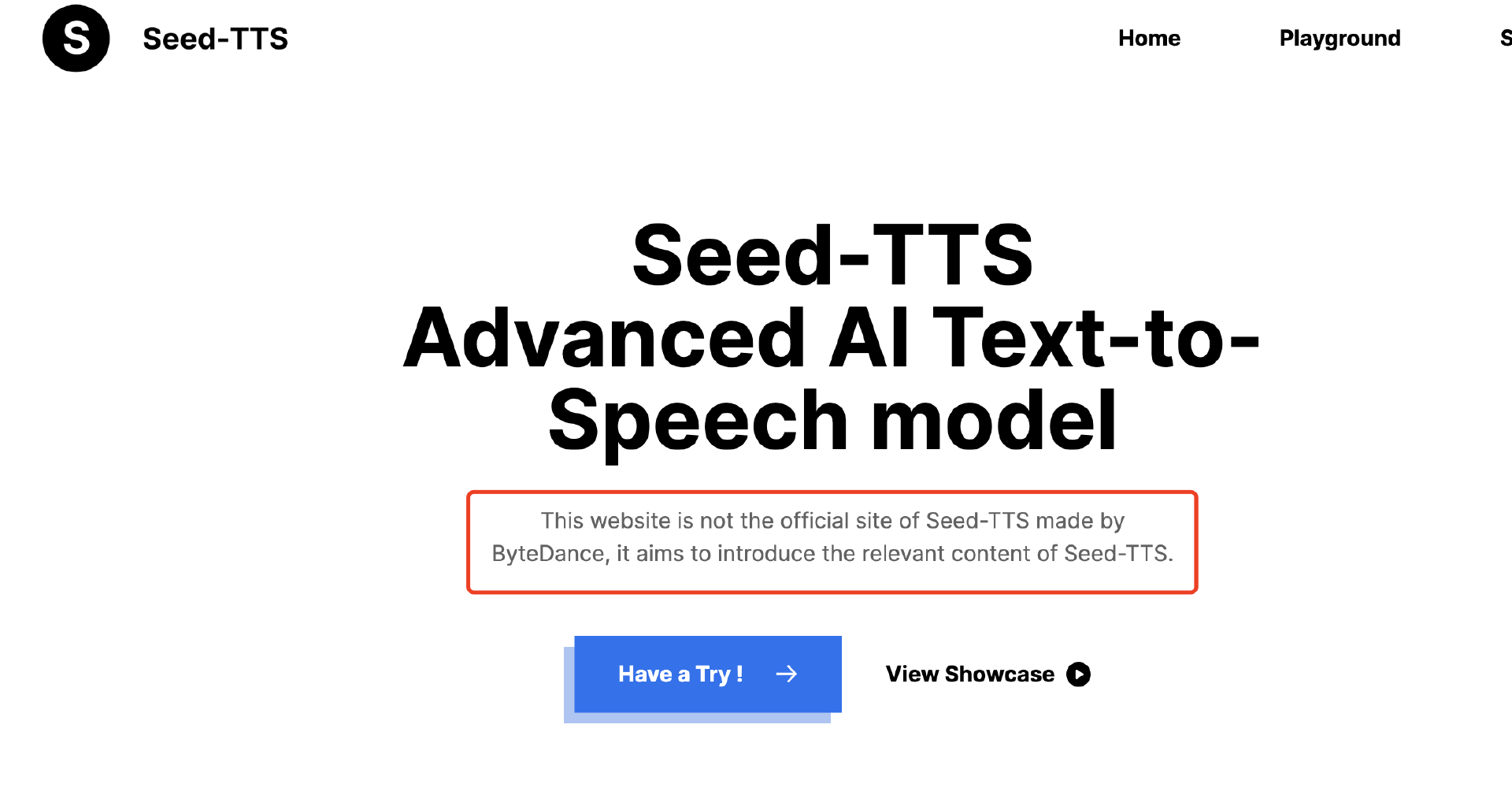
不过截至本文成稿时,https://seedtts.ai/ 网站已经增加了“非字节跳动官方网站”的文字说明,并且点击跳转打开的页面也注明了可以尝试使用 ChatTTS 项目。
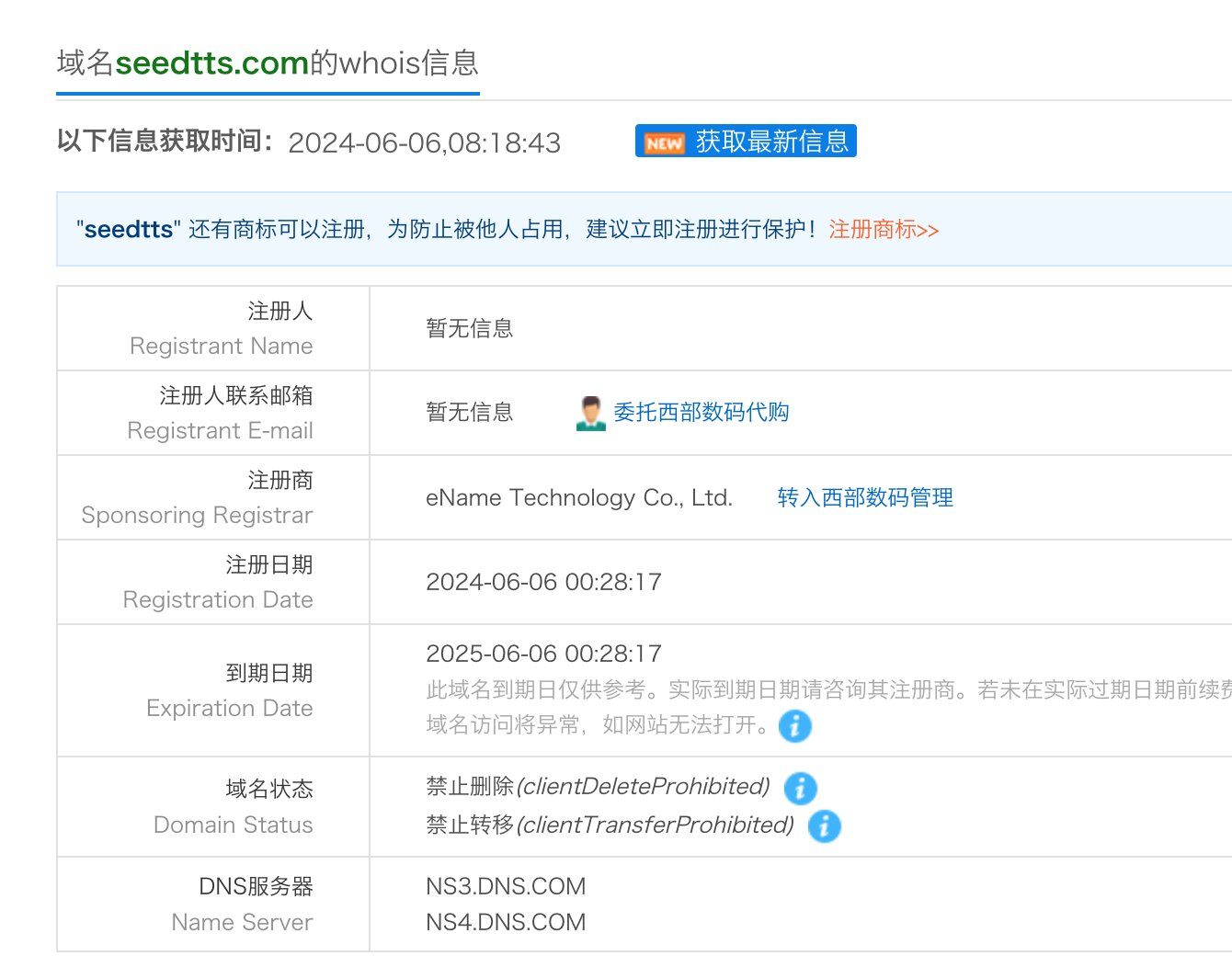
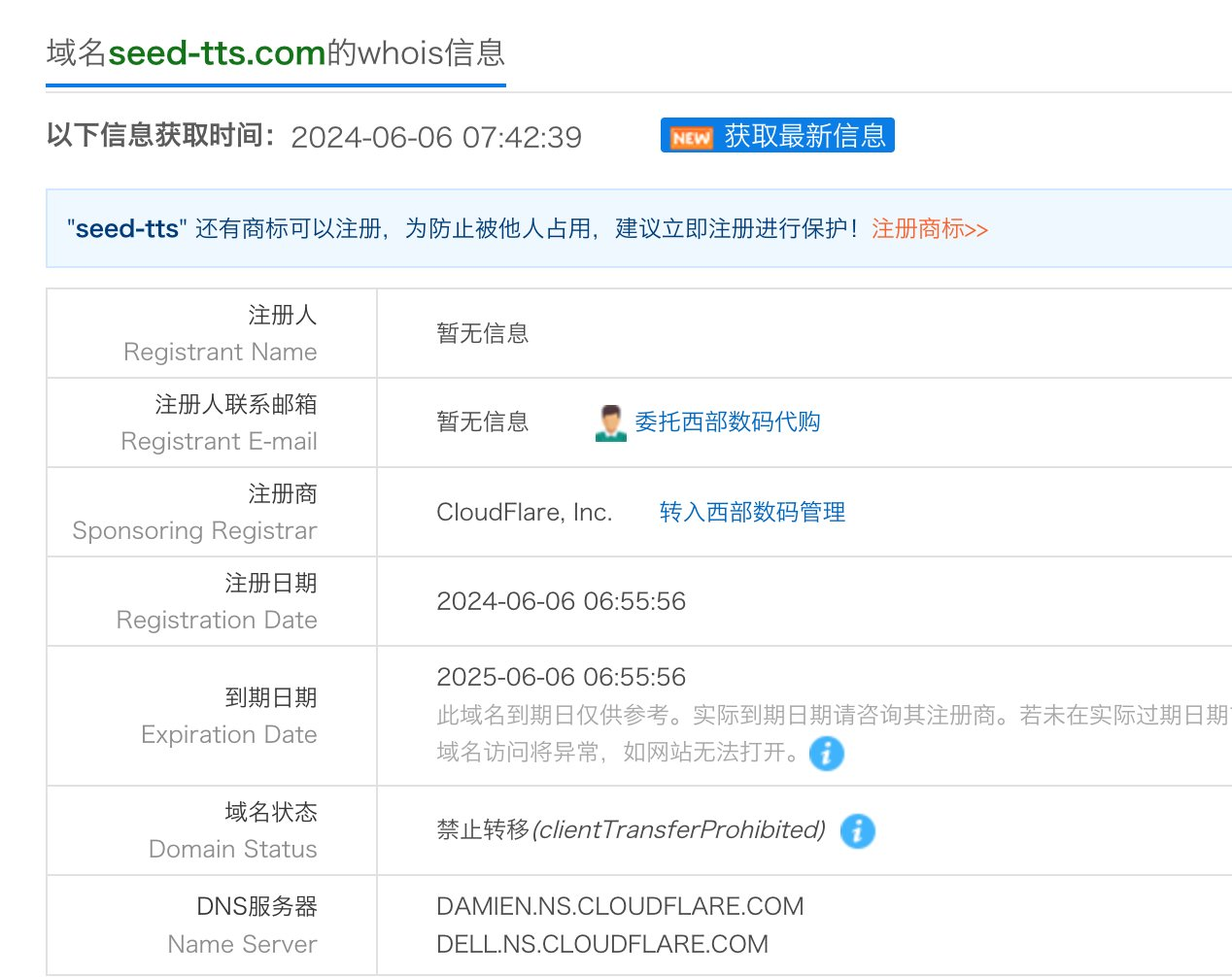
下面是网友爆料的域名注册信息:
“这世界真是离谱,技术报告才发表了一天,山寨 Seed-TTS 的网站就出现了。 套壳 ChatTTS 说是 Seed-TTS。”字节跳动 Seed-TTS 作者之一的陈卓表示。
陈卓明确道,考虑到安全问题,Seed-TTS 模型不会开源,但是团队提供了一些评测数据集和测量工具作为 benchmark 使用。
另外让陈卓比较气愤的点是,山寨的人同时还在推特上宣传 Seed-TTS 就是 ChatTTS 的套壳。他表示,目前这件事已经上升到了公司的法务部门。
Seed-TTS 效果这么好?
会被迅速山寨,那肯定是实现了不错的效果。我们先看下官方给出的示例,这是不同情绪下的声音效果:
这是根据文字生成的声音效果:
零样本上下文学习的声音效果:
跨语言内容创作能力:
Seed-TTS 一经推出就收到了网友们的好评,StabilityAI 研究员 Tanishq Mathew Abraham 也转发了其论文。不过也有网友表示需要自己上手,担心被官方展示欺骗。
不过,Seed-TTS 目前只提供了技术论文和官方 Demo,暂未开放使用地址。对此,陈卓表示,希望体验 Seed-TTS 的用户可以使用字节语音技术支持的各个产品,比如抖音、剪映等,Seed-TTS 都会逐渐提供支持。
Github:
https://bytedancespeech.github.io/seedtts_tech_report/…
论文:
https://arxiv.org/abs/2406.02430
根据目前官网展示的效果,Seed-TTS 可以应用在虚拟助手、视频配音、电影和游戏配音、新闻和播客制作等场景。
模型的独特性是什么
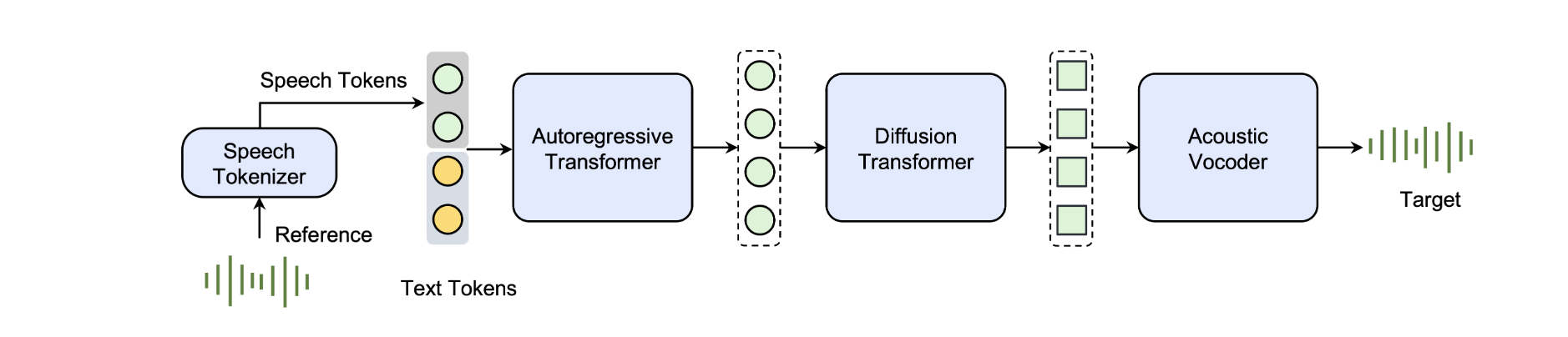
根据介绍,Seed-TTS 该模型基于自回归和扩散架构,首先使用一个 speech tokenizer 将输入的语音信号转换成一系列离散的语音 tokens。之后,Seed-TTS 的自回归语言模型根据输入的文本和语音标记生成目标语音的标记序列。这个过程依赖于模型对语言结构和语音特性的理解,确保生成的语音标记序列在语义和语法上与输入文本相匹配。
接着,生成的语音标记序列随后被送入一个扩散变换器(diffusion transformer)模型。这个模型负责将离散的语音标记转换成连续的语音表示,这个过程是逐步细化的,从粗糙到精细,以生成平滑且自然的语音波形。
最后,连续的语音表示被送入负责将这些表示转换成可听高质量语音的 Acoustic Vocoder。Acoustic Vocoder 通常使用深度学习技术来模拟人类声道产生语音的过程。
Seed-TTS 模型基于大量数据进行预训练,学习语言和语音的基本规律。之后,可以通过微调来适应特定的说话者或语音风格,进一步提升语音的自然度和表现力。
Seed-TTS 还采用了自我蒸馏方法来实现语音属性的分解,如音色分离,以及使用强化学习技术来增强模型的鲁棒性、说话者相似性和可控性。
对于非自回归的变体 Seed-TTSDiT,它采用完全基于扩散的架构,直接从文本到语音的端到端处理,不依赖预先估计的音素持续时间。
研发团队表示,与之前的模型相⽐,Seed-TTS 有两⼤优势。
⾸先,Seed-TTS 在各种场景中的语⾳合成能⼒都表现出了很好的⾃然度和表现⼒,包括喊叫、哭泣或情绪激动的语⾳等具有挑战性的场景。
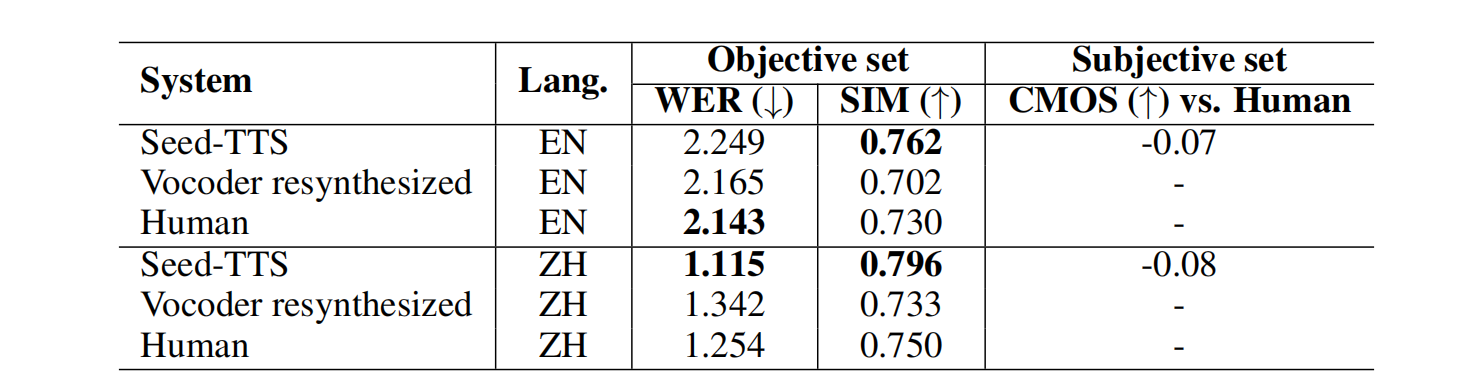
Seed-TTS 与重新合成和真实⼈类语⾳的评估结果
其次,Seed-TTS 解决了基于语⾔模型的 TTS 系统中普遍存在的稳定性问题,这些问题阻碍了它们在现实世界中的部署。稳定性是团队通过改进 token 和模型设计、增强训练和推理策略、数据增强和强化训练后实现的。因此,Seed-TTS 在测试集上实现了显著更好的稳健性。
不过团队也指出,尽管 Seed-TTS 功能强⼤,但它也存在局限性,比如在需要细微情感和情境理解的场景中存在局限性。此外,尽管使⽤⼤量数据进⾏训练,但在场景覆盖⽅⾯仍有改进空间。 例如,当前的 Seed-TTS 模型在唱歌或给出包含背景⾳乐或过多噪⾳的提⽰时表现不佳。
语音生成的安全问题
OpenAI 发布 GPT-4o 之后,文本转语音模型大火,但相关争议也不断。最为有名的可能就是 OpenAI 与斯嘉丽的争执。
美国演员斯嘉丽·约翰逊质疑 OpenAI 聊天机器人使用酷似她声音的 Sky 语音。根据斯嘉丽此前的说法,奥特曼在去年 9 月找到她,希望她为 ChatGPT 配音,她拒绝了,但近期她发现 OpenAI Sky 系统声音跟她很像。
“那不是约翰逊的声音,不应该是这样的。对于声音的相似程度,人们会有不同的看法,但我们不认为那是她的声音。”奥特曼否定道。受质疑后,OpenAI 同意删除相关语音。
此事件也给业内敲响了警钟。
为了限制 ChatTTS 的使用,团队在 40,000 小时模型的训练过程中添加了少量高频噪音,并使用 MP3 格式尽可能压缩音频质量,以防止恶意行为者将其用于犯罪目的。同时,团队内部训练了一个检测模型,并计划在未来将其开源。HuggingFace 上的开源版本则是一个 40,000 小时的预训练模型,没有 SFT。
而字节跳动团队也明确了这一点。“Seed-TTS 的功能和局限性在多媒体和安全应⽤中带来了重⼤⽽新颖的挑战,我们认为在考虑其潜在的社会影响时必须仔细研究这些挑战。”团队在论文中提到。
根据介绍,考虑到滥⽤可能会产⽣有害的社会影响,字节跳动团队在相关产品中实施了多项安全程序,以防⽌在开发和部署此模型的整个过程中出现滥⽤。例如,团队开发了⼀种多步骤验证⽅法,⽤于验证语⾳内容和说话者⾳⾊,以确保注册⾳频仅包含授权用户的声⾳。此外,团队还实施了⼀种多级⽔印⽅案,该⽅案强制包含在创建内容的各个级别,例如视频背景⽔印和内容描述中的⽔印。




