
一、背景介绍
近年来随着经济和社会的飞速发展,人们的生活节奏明显加快,地铁、车站以及机场等各种交通枢纽,每时每刻都在高速运转,将乘客安全的送达他们的目的地。现如今,这些交通枢纽早已经成为了城市中不可分割的一部分,与百姓的日常生活息息相关。
地铁作为城市发展的一项标志,也体现了城市现代化的程度,作为市内出行的首选方式,地铁每年的旅客输送数量更加庞大。日本拥有着世界上最复杂的地铁交通枢纽系统,据统计 2019 年仅日本大东京地区地铁输送旅客数量高达 136 亿人次。对于如此繁忙的交通运输系统,一旦出现安全事故,将对人们的生命和财产造成严重的威胁。
近几十年来,世界各地的交通安全事故频发,其中大部分都是由于人为原因所造成;例如 1995 年,日本东京地铁发生沙林毒气事件,直接导致 12 人死亡,5500 人受伤;2003 年,韩国大邱市发发生一起地铁纵火事件,导致 198 人死亡,147 人受伤,并对韩国的国际形象造成了极大地影响;2004 年莫斯科地铁发生一起恶性爆炸事件,共造成 40 人死亡,超过 100 人受伤;2014 年中国昆明市火车站发生了一起针对平民的恶性事件,致使 31 名平民死亡,近 200 人受伤。2016 年土耳其伊斯坦布尔阿塔图尔克国际机场 2 号航站楼发生多爆炸和枪击事件,此次恐怖袭击事件直接导致 42 人死亡,239 人受伤,机场大量基础设施受到严重损毁。
受到这些事故的影响,世界各个国家都加强了对机场、地铁、火车站等交通枢纽安全检查级别,并派出大量警力维持治安。
随着技术的不断发展,各项新型技术不断在安全检查领域中应用。基于 CT 成像的 X-Ray 安检设备目前已经大量部署于各类交通枢纽之中。X-Ray 安检设备能够对旅客的行李进行快速扫描,并且根据行李中不同材质的物体重构出相应的画面,并且能够有效的解决物体间相互的遮挡问题。随着城市的日益扩大,交通和物流也都呈现出爆发式增长的态势,X-Ray 安检仪与安检员的方式已经逐渐无法因对日益增长的客流。
长时间高强度的工作,必然会导致安检员疲惫,造成一些漏检或误检,从而产生一定的安全隐患。随着人工智能、深度学习以及深度神经网络的飞速发展,基于上述方法的计算机视觉技术正在多个领域中大量使用,如自动驾驶、无人监控、人脸识别等。
因此,将基于人工智能和计算机视觉技术的“违禁品检测技术”应用于 X-Ray 安检设备中,使用算法自动化的从 X-Ray 安检设备的成像图片可自动地判断是否包含违禁品、违禁品的位置和种类信息。然后安检员根据算法提供的信息,即可有针对性的对乘客的行李进行开箱检测;由于案件人员事先知道了违禁品的位置和种类,因此可以极大地加安检的效率。
基于人工智能的违禁品检测技术,可以 7*24 小时不间断运行;并且可用使用计算机并行技术,使用一套算法来同时监控多个 X-Ray 安检设备,既提高了违禁品的检测效率和精度,也节约了大量的人力成本。
为了解决上述问题,并结合 X-Ray 安检仪自身特点,我们提出了一个自动化从 X 光扫描图像中检测违禁品的系统。该系统使用深度学习模型,从模型设计、特征提取、自动边框回归以及模型部署等多个维度进行研究,使用准确率(Precision)、召回率(Recall)、AP 和 mAP 等多个指标分析。
二、项目难点
针对 X 光违禁品检测这一场景,经过调研和探索,发现实际中存在大量需要解决的问题,现总结如下:
1) 违禁品尺度变化大:
在所需检测的违禁品中,目标尺度变化较大;如“刀”这一类别中,既包括体积较大的“长刀”,也有体积较小的“水果刀”、“折叠刀”等。为了可以精确的检测出这种尺度变化极大的目标,需要设计的检测器具有较好的泛化性。
具体如图 1 所示,其中的“刀”的整体尺度较大,但是“枪”的尺寸相对较小。
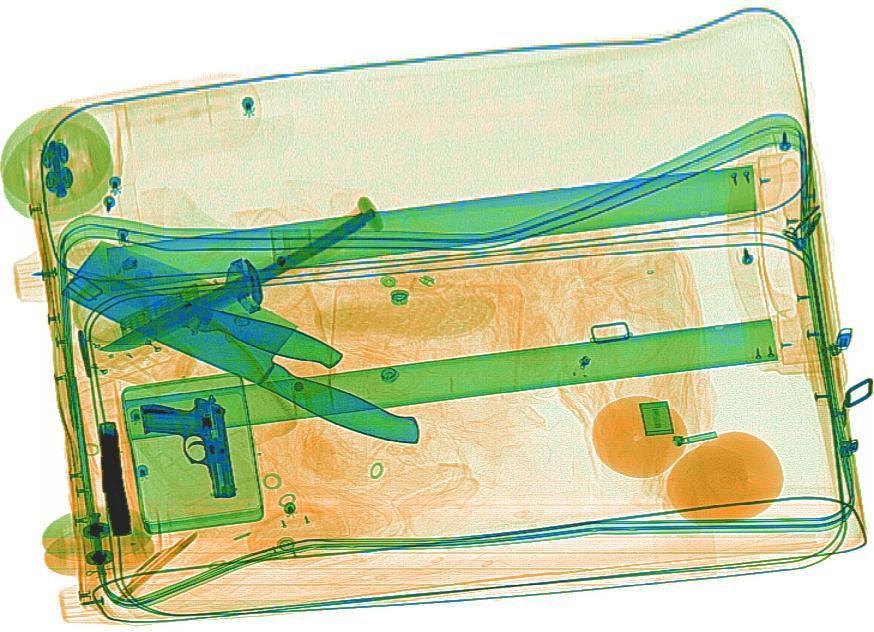
图 1 多尺度目标
2) 检测目标长宽比差异大:
基于深度学习的目标检测算法按照 Anchor 生成的方式可以分为单阶段目标检测算法和两阶段目标检测算法。这两种类型的算法都需要预先对检测目标的长宽比进行统计,然后根据不同的比例对检测框进行设定。基于 X 光的违禁品检测中,目标的长宽比变化极大,有近似于 1:1 的“枪”等目标,也有差异化极大的“刀”等目标。
为了使模型可以很好的适用于违禁品检测这一实际应用场景,需要设定一种自适应的 Anchor 来提目标检测的精度。
图 2 显示了多种不同长宽比的检测目标,“刀”这一类别的长宽比差异较大。
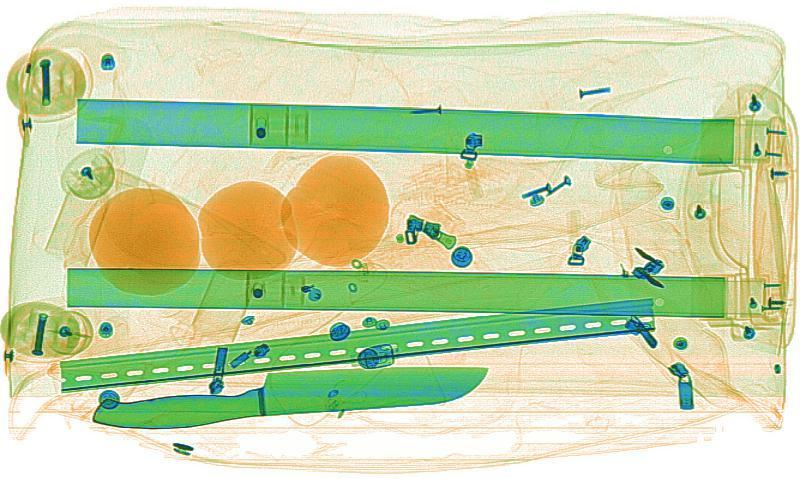
图 2 长宽比例不同的目标检测物体
3) 目标重叠:
物品的形状在 X 光扫描图片中会有较严重失真,行李中物品放置的位置随机,不同的目标之间存在严重的遮挡,增加了违禁品检测和识别的难度。
图 3 是行李箱中物品相互重叠的示意图,从中可以看出有多个物品相互重叠。

图 3 物体重叠
4) 背景复杂:
X 光对不同材料的穿透性不同,因此不同的材质的物品在 X 光扫描图片中呈现出不同的颜色,但是非违禁品的材料和形状与违禁品相似时,会对算法造成严重的干扰,从而降低检测的精度。
5) 速度和精度平衡:
总的来说,深度学习模型的参数量和运算量越大,模型的特征提取能力越强,算法的检测精度越高,但是运行速度也会变慢。是适用于实际尝尽中的违禁品检测算法,需要在保证检测精度的情况下,尽可能的提升运行的速度。
三、方法设计
在本章节中,我们提出了一种基于改进 YOLO V3 的违禁品检测算法,该算法以 YOLO V3 通用目标检测算法为基础,从特征提取模型、Bounding Box 生成方式等方面进行优化。
此外,我们还将 FPN 特征融合模块、GIoU Loss 引入到训练框架中,进一步提升了模型精度。为了提升模型的运行速度,我们还引入的模型量化技术和 TensorRT 部署技术,极大地提升了模型的运行速度。
我们将所提出的算法与目前常用的目标检测算法进行对比,实验结果显示我们所提出的方法在精度和速度上都远超同类算法,在违禁品检测任务中取得了目前最好的效果。
为了验证算法的实际运行效果,我们将算法部署到嵌入式设备中,并在实际环境下进行测试,数据显示我们所提出方法的检测准确率为 99.6%,因此具有较强的实用价值。接下来,本文将从多个方面来对 YOLO V3 算法进行改进和优化。
1) 数据增广:
数据增广是深度学习中一种常用的来提升模型性能的训练手段,该方式主要是通过对图像进行一些形态学上的变换,来增强模型的泛化性,从而获得更好的训练效果。
常用的图像增广方式有:对称、平移、旋转、尺寸放缩、颜色转换、边框扰动、亮度调整以及图像模糊与混叠等。受到 CutMix 与 MixUp 数据增广方式的启发,我们将广泛应用于图像识别的 Mosaic 增广方法引入到目标检测中。
Mosaic 方式是指,我们在进行模型训练时,将多张图像进行拼接,每一张图片都有其对应的框框,拼接之后就获得一张新的图片,同时也获得这张图片对应的框框,然后我们将这样一张新的图片传入到神经网络当中去学习,相当于一下子传入四张图片进行学习了。通过这种方法我们可以无限量的增加训练样本,并且可以强迫模型去学习多尺度的目标。
此外,模型中的 BatchNorm 层可以在训练时可以见到多的训练数据,有助于网络的快速收敛。在使用 Mosaic 进行数据增广时,我们仍然可以使用标准的数据增广算法对合成的图片进行处理,进一步增加数据的多样性。使用 Mosaic 增广后的训样本如图 4 所示。

图 4 Mosaic 增广后的训练样本
2) 自适应 Anchor 增广算法:
Anchor 是目标检测算法常用的一种提绳模型检测精度的方法,在 Faster RCNN、SSD 以及 YOLO 系列等多算法中广泛使用。YOLO V3 所统计出的九种 Anchor 尺度,虽然覆盖了目标检测领域中的大部分场景,但是在我们关注的违禁品检测任务中并不适用。为了解决这一问题,我们在项目中使用了一种自适应的 Anchor 生成算法,与 YOLO V3 中使用固定 Anchor 的方式不同,我们将 Anchor 中的边缘坐标
改变为可以可以学习的参数,模型可以在训练过程中自动的对 Anchor 大小进行调整,从而获得更加恰当的 Anchor,提升模型训俩效率和检测精度。
为了解决这一问题,我们在项目中使用了一种自适应的 Anchor 生成算法,与 YOLO V3 中使用固定 Anchor 的方式不同,我们将 Anchor 中的边缘坐标改变为可以可以学习的参数,模型可以在训练过程中自动的对 Anchor 大小进行调整,从而获得更加恰当的 Anchor,提升模型训俩效率和检测精度。
3) GIoU-Loss:
目标检测算法中的 Loss 函数一直是研究人员的讨论重点,YOLO V3 在 YOLO V2 的基础上,将原来分类任务的 Softmax-Loss 转换为 BEC-Loss,增强了模型在识别中的性能。
但是在 Bounding Box 回归方面一直使用 Smooth L1-Loss,该 Loss 函数对于目标物体的尺度不敏感,但是在目标检测任务中物体的尺度多变,因此 Smooth L1-Loss 并不是一种非常恰当的函数。本文收到图像分割领域中对目标尺度特征的处理方法,引入了 GIoU Loss 作为边框回归的损失函数。具体如公式 1 所示。
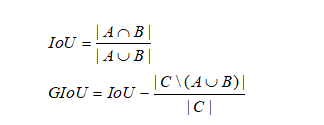
四、实验分析
经过上述从数据增广方法、损失函数等方面的优化,我们开始用在真实数据集上进行实验分析,并从速度、精度、模型运算量和参数量等多个方方面进行对比。
1) 模型精度对比
在本节中,我们将所提出改进 YOLO V3 算法与原始的 YOLO V3、SSD、Faster RCNN 等常用的目标检测算法在 X-Ray 数据集上进行训练和测试,具体结果如表 1 所示。
表 1 实验对比结果:
从表中我们可以看出,我们所提出的方法结果的无论是在精度还是速度上都远优于现有的方法。其中 tiny、mid、large 分别表示使用不同大小的特征提取网络,其中模型体积越大,实际效果越好。从检测结果来看,我们的 mid 模型在各项指标上均优于 Faster RCNN 等方法,并且在速度上是 Faster RCNN 的 4.5 倍,tiny 模型在速度上更具优势,是 Faster RCNN 的 7.2 倍。我们提出的 large 模型,与原始的 SSD 算法相比,在 mAP 这一指标上有 20.4%的提升,模型的体积更小、运行速度更快。
2) 细分类结果
我们还分别测试了不同模型在具体细分类上的表现,表 2 是 mid 模型的结果。
表 2 mid 模型细分类测试结果
3) 结果展示
我们在图 5 中展示了模型的部分检测结果。从结果的展示来看,我们发现所提出的方法可以检测到大部分违禁物品。

图 5 实验结果展示
五、总结
为了将人工智能算法应用到违禁品检测领域中,我们提出了一种基于 YOLO V3 的改进的违禁品检测算法,我们通过改进和优化数据增广方式、检测框架的 Loss 函数等方法,较好的提升了模型的检测精度和运行效率。
作者介绍
沙宇洋,中科院计算所工程师,目前主要从事人脸识别以及无人驾驶等相关方向的研究和实际产品开发;
陈扬,中科苏州智能计算技术研究院,目前从事缺陷检测以及三维重建等相关方向的研究和实际产品开发。




