
普林斯顿大学和耶鲁大学的研究人员发表了一项关于大语言模型(LLM)中思维链(Chain-of-Thought,CoT)推理的案例研究,该研究显示了记忆和真实推理的证据。他们还发现,即使提示(prompt)中给出的示例不正确,CoT 也可以工作。
这项研究的动机是研究界一直在争论的 LLM 是否真的可以推理,或者它们的输出是否只是基于启发式和记忆的。该团队使用了一个简单的任务,即解码移位密码,作为他们的案例研究。他们发现,LLM 使用 CoT 提示的表现取决于记忆和团队所说的“嘈杂”推理的混合,以及正确输出的总体概率。根据研究人员的说法:
我们发现有证据表明,CoT 的效果从根本上取决于生成单词的序列,这些单词序列在给定条件下会增加正确答案的概率;只要是这种情况,即使提示中的演示无效,CoT 也可以成功。在关于 LLM 是推理还是记忆的持续争论中,我们的结果因此支持一个合理的中间立场:LLM 行为既表现出了记忆,又表现出了推理,也反映了这些模型的概率起源。
该团队选择了解码移位密码的任务,因为它的复杂性与其用于训练 LLM 的互联网资源中的使用频率之间存在着“明显的分离”。偏移值越大,任务就越困难;然而,最困难的案例也是互联网上最常用的案例:rot-13。如果 LLM 只是简单地记忆,那么它们在 rot-13 上的表现会比真正使用推理更好。相比之下,如果它们真的有推理能力,它们在 rot-1 和 rot-25 上的表现会是最好的,而在 rot-13 上的表现最差。
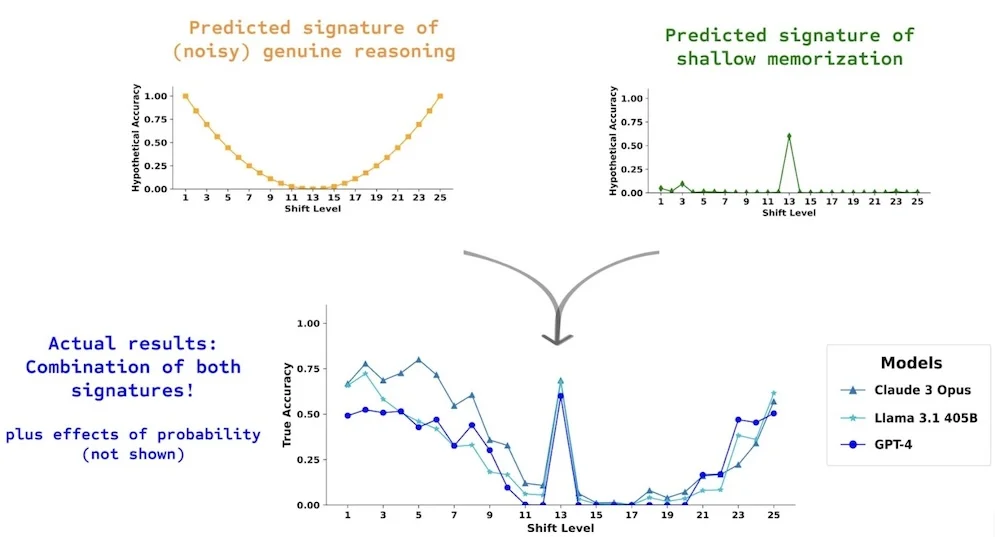
预期结果和实际结果
该团队创建了一个由 7 个字母组成的单词数据集,GPT-4 也将这些单词标记为 2 个 token。他们还计算了 GPT-2 使用每个单词来完成句子“这个单词是”(the word is)的概率。这使得研究人员能够简单地根据概率来控制 LLM 输出它的可能性。然后,他们制作了这些单词的移位版本,并进行了 GPT-4、Claude 3 和 Llama-3.1-405B-Instruct的实验。
该团队还进行了一项实验,其中要求模型使用算术而不是单词来解码数字序列。该任务与移位密码任务“同构”,但只使用数字。作者发现,在这项任务中,GPT-4 的表现“近乎完美”,并得出结论,它“具有对所有移位值准确执行移位密码任务所需的核心推理能力”。但事实并非如此,他们得出结论,CoT“不是纯粹的符号推理”。然而,他们确实注意到,与“标准”提示相比,CoT 提高了性能,因此 CoT 不是“简单的记忆”。
耶鲁大学教授、研究小组成员 R.Thomas McCoy 在 X 上发布了有关这项工作的信息。在回答另一位用户的问题(该用户想知道不同的 CoT 提示是否会产生不同的结果)时,他写道:
是的,我认为那里有很多值得探索的地方!合著者 Akshara Prabhakar 确实进行了一些很酷的实验,包括在 CoT 中将字母转换为数字。这通常会提高性能,也能得到了一个质量相似的图表。所以这是一个类似的案例。但很可能还有其他情况会给出不同的趋势!
该研究的实验代码和数据可在 GitHub 上找到。
原文链接:




