
文 | 付涛 王强强
背景介绍
语音合成是将文字内容转化成人耳可感知音频的技术手段,传统的语音合成方案有两类:基于波形串联拼接的方法和基于统计参数的方法。随着深度学习的发展以及计算能力的不断提升,基于神经网络的语音合成方案逐步成为语音合成领域的研究热点。
相较于传统的语音合成方案来说,基于神经网络的语音合成技术最大的特点就是结构简单。端到端的语音合成方案可以直接输入文本或者字符,合成系统就能将与之对应的音频波形直接输出,降低了开发者对语言学和声学知识的掌握要求,同时该方案下生成的音频无论拟人化程度,还是对原始录音数据情感风格的还原情况都远优于传统方案。
基于神经网络的合成方案除了有如上提及的各种优势,其自身同样也存在一定的问题,也是任何基于深度学习技术都离不开的问题——需要大量高质量的数据!
虽然随着技术的不断迭代和发展,基于神经网络端到端的语音合法方案已经能很大程度的缩小人类真实录音和合成音频在音质、情感和韵律等多方面的差距。但这些性能的提升都离不开需要大量文本与语音匹配的高质语音作为训练数据,而通常搭建一个优质合成模型的数据量需要 10 小时甚至更多的数据。
在某些实际应用场景中,如果需要针对特定的 IP 角色定制音色的话,收集大量优质数据也是可行的;但在某些场景下,收集大量语音数据是不现实的。能不能通过降低优质数据的量级门槛来实现一个优质的合成模型呢?今天我们就来介绍一下当下语音合成技术针对小数据量的解决方案[1],同时也介绍下作业帮自己的解决方案。
小数据量语音合成技术介绍
在语音合成领域,我们在收集数据的过程中,<文本,音频>配套的优质数据是我们最喜欢的,但实际情况下此类数据通常难以获取,即便有数据总量也是寥寥无几。但对于<文本,音频>不配套的情况,无论是优质音频还是优质文本,相对来说就有点手到擒来的意思了。在介绍少数据量、低资源的合成方案时,我们也将从数据是否配套两方面来介绍。
<文本,音频> 不匹配
对于此类数据情况,当前的解决方案主要有两类:
一类是利用不匹配的文本或音频通过半监督的方案,先对合成模型的文本编码及频谱解码部分做预训练或辅助训练,再利用少量的匹配数据对预训练模型进行调整。通过利用在大量文本数据下迭代的 BERT 模型来对训练时输入的文本数据进行编码,可以有效辅助文本编码器的训练[2],甚至可以直接作为合成模型的文本编码器而大幅提升合成模型的文本编码能力[3]。而利用矢量量化技术,将频谱数据离散映射到文本空间,利用间接的文本数据和直接的频谱数据能有效的实现频谱解码部分的预训练任务[4][5][6][7]。
另一类这是通过利用语音识别技术(ASR,Automatic Speech Recognize)和语音合成(TTS,Text To Speech)的对偶关系,在不断的对偶学习中,利用 ASR 模型给没有文本标注的音频识别文本,利用 TTS 给只有文本没有音频的数据合成音频数据,不断的优化彼此,最后在利用少量的匹配数据对合成模型进行调整[8][9][10];
<文本,音频> 匹配
对于少量的、低资源的语音配对数据,当下的解决方案也可以分为两类:
一类是借助人类语言发声器官、发音方式和语义结构的相似性,通过跨语言的方案策略,利用某些易获取、资源丰富的数据集对合成模型进行预训练,再利用低资源的数据集进行模型微调。
该方案下最大的问题是不同的语音通常是有着不同的音素集合,故目前的方案则是希望利用同一套音素集来整合不同语言,通常的方案包括:国际音标(IPA,International Phonetic Alphabet)方案[11]和字节表示方案[12](将所有语音统一转化为 UFT-8 编码,利用 UTF-8 编码的范围设定一个伪音素表);或者设计一个网络结构解决源语言符号和目标语言符号之间的映射关系[13];又或者在文本编码模块,针对每一种语言都引入属于自己的编码模块[14];更为暴力的方案是直接通过在音素 Embedding 层后引入一个新的线性层或卷积层,当利用跨语言数据完成基础模型训练后,直接抛弃跨语言的音素 Embedding 层,进而引入与少数据量数据对应的音素 Embedding 层,最后利用低资源数据对模型进行微调[11]。
另一类则是在同一语种的条件下,尽可能利用该语种中其他高资源、大数据量说话人来提升低资源数据的合成质量,主要方案包括利用语音转换技术(音频质量的合成能力源于大数据量说话人,而音色则来源于小数据量说话人)[15][16][17]和模型的训练方案及策略(包括模型结构的优化[18][19][20]及微调模型时的训练方案[21]);
以上罗列的技术便是当前针对低资源、少数据量语音合成问题的解决方案,各个方案都有一定的道理和可以借鉴使用的地方。实际使用时,还是需要考虑数据的具体情况来决定采用哪种小数据量语音合成技术。那么对于作业帮来说,针对小数据量、低资源说话人数据又是如何解决的呢?我们一起来看看吧。
作业帮的语音合成技术方案主要是以 Fastspeech2[22]+MultibandMelGAN[23]作为技术基底,并以此为出发点,引入多说话人策略初步实现针对少量数据说话人合成模型。
Fastspeech2 通过非自回归技术方案解决基于神经网络语音合成速度慢的问题,同时在模型中对 Pitch、Energy 等声学特征的引入,进一步提升了声学模型从文本到频谱的建模能力;选择 MultibandMelGAN 作为声码器(Vocoder)一方面是通过多频带、多尺度方案对音频优秀的还原能力,另一方面则是其在 CPU 机器上实时率的优异表现。
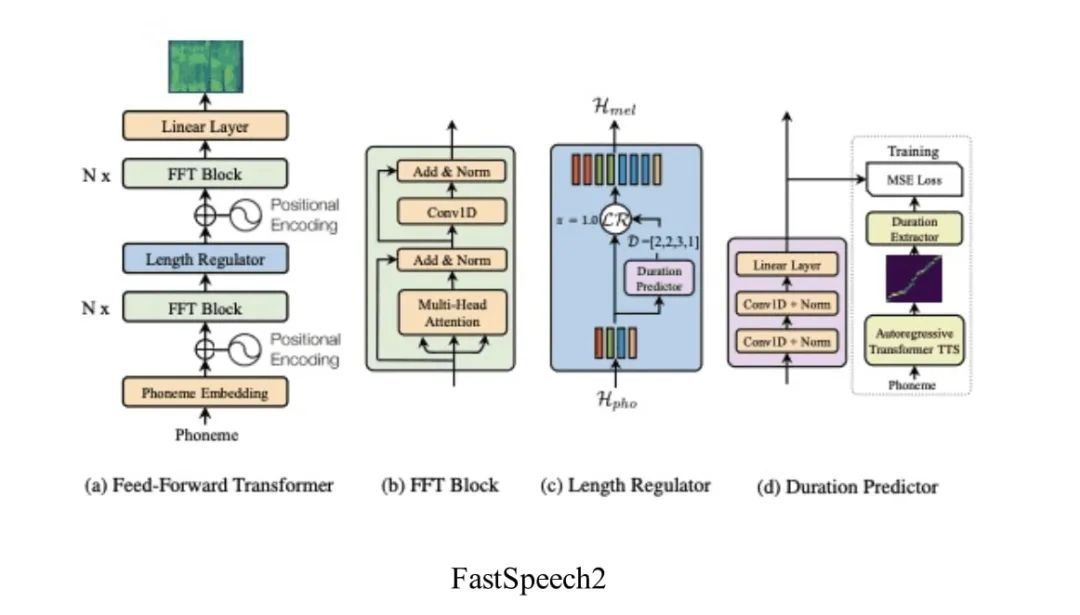
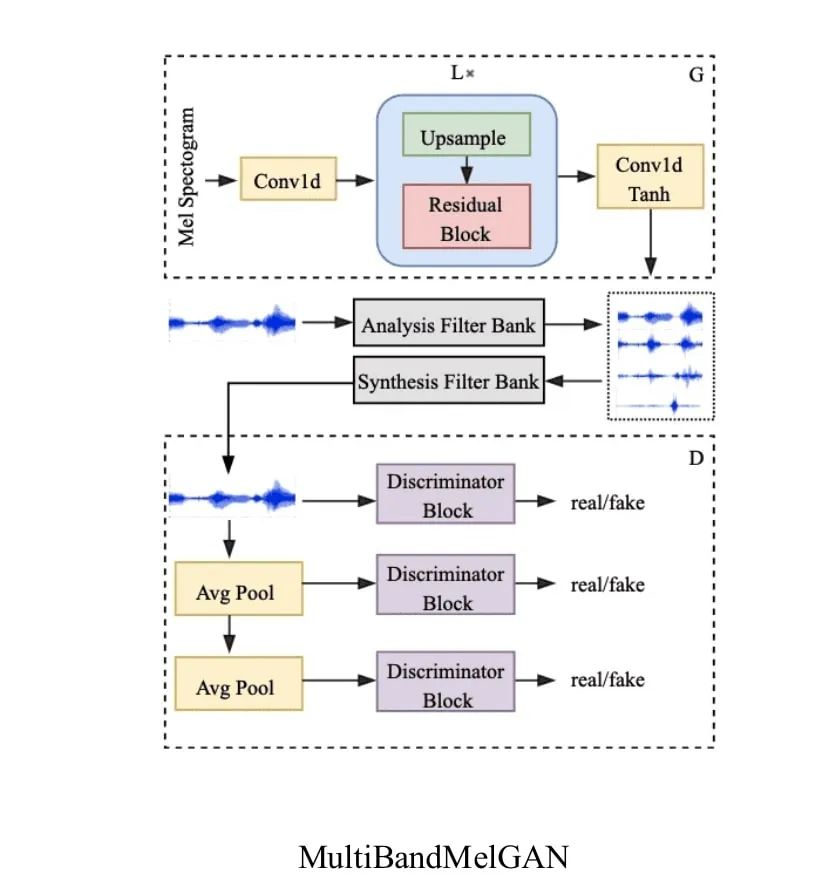
针对 Speaker Embedding 和模型结构的优化
如何基于这套方案发展小数据量语音合成技术呢?由于声码器的本质就是对给定频谱进行相位还原预测,任务相对声学模型来说相对简单,故不对声码器做进一步优化;针对声学模型,我们首先引入说话人表征信息,即通过增加 Speaker Embedding 层,随模型的迭代进行自动优化,具体如下图:
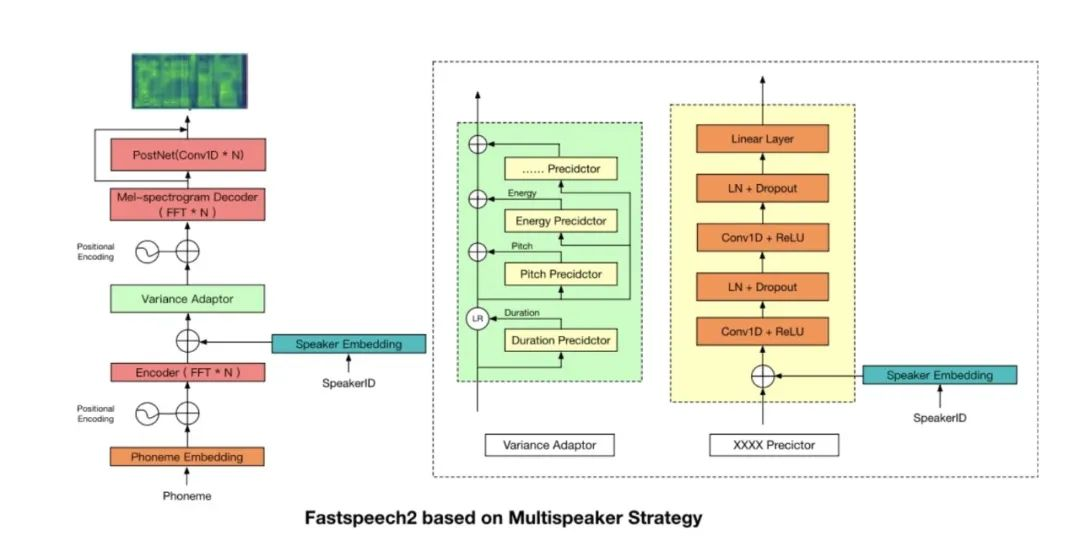
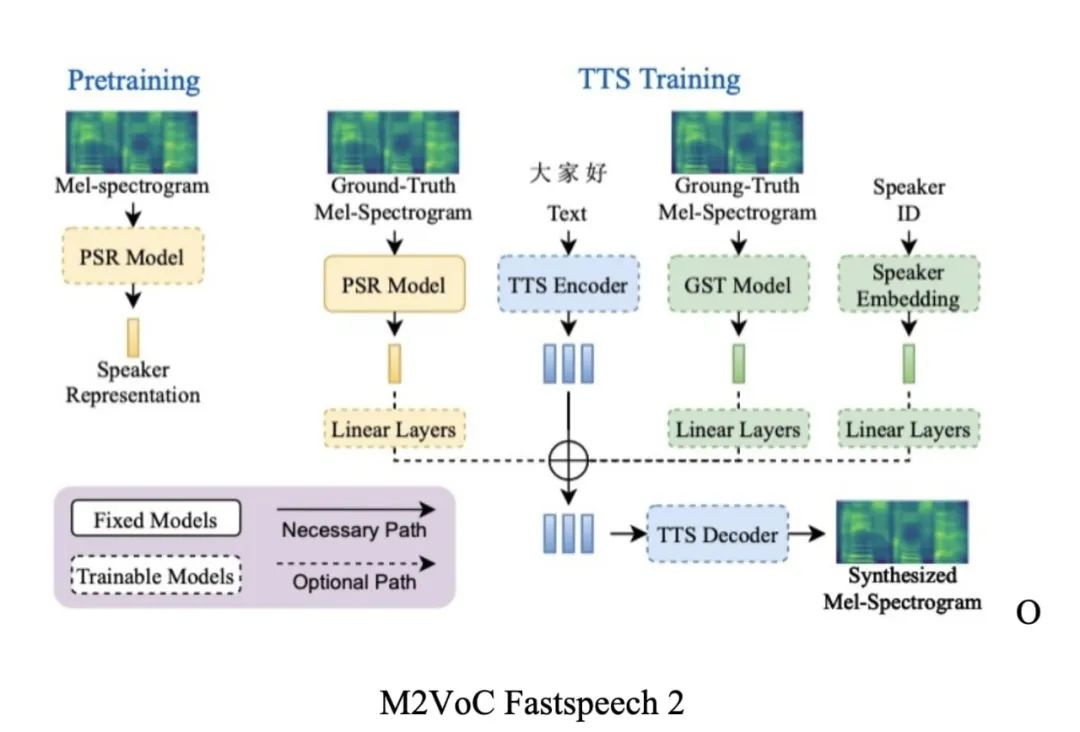
此时针对大于 1 小时的说话人数据效果已有较大提升,而小于 1 小时的效果依旧较差。随后我们针对模型的说话人表征策略,借鉴 M2VoC(多说话人、多风格语音任务竞赛)获奖方案[21],针对说话人表征策略进行了修改,区别于原方案中同时引入多种说话人表征(X_VECTOR、D_VECTOR、AdaInVC_VECTOR、GST_Encoder、SpeakerEmbedding),我们只选择了额外引入了 D_VECTOR,且非论文中基于 GE2E[24] 策略训练得到的说话人表征向量,而是效果更优的基于 ECAPA[25] 的说话人表征策略。
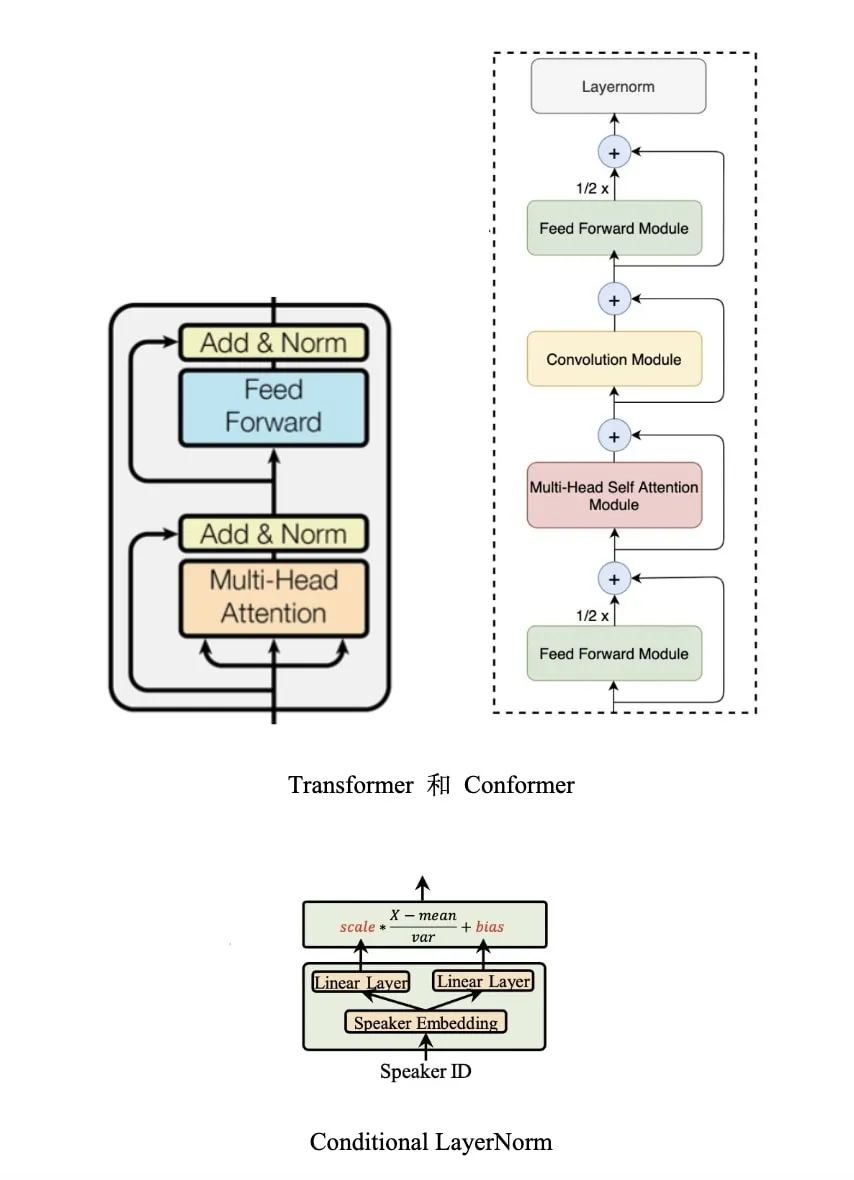
Conformer 探索
同时为了提升模型的建模能力,我们将 Fastspeech2 中原始的 Transformer 结构优化为了 Conformer[26] ,Conformer 是 ASR 中提出的一种针对声学模型中局部特征和全局特征进行更好结合的网络结构,经过我们的验证,其在 TTS 中亦能起到比 Transformer 更好的建模效果。
此外,我们也参照 Adaspeech[22] 中,将 Fastspeech2 中使用的 LayerNorm 网络层全部重构为 ConditionLayerNorm 层,通过将说话人信息引入 ConditionLayerNorm 层,使得我们可以基于大数据量训练完成的基础模型对不同的少数据量、低资源说话人完成模型微调,这也使得我们在部署模型时能节省更多的内存资源。
业务收益
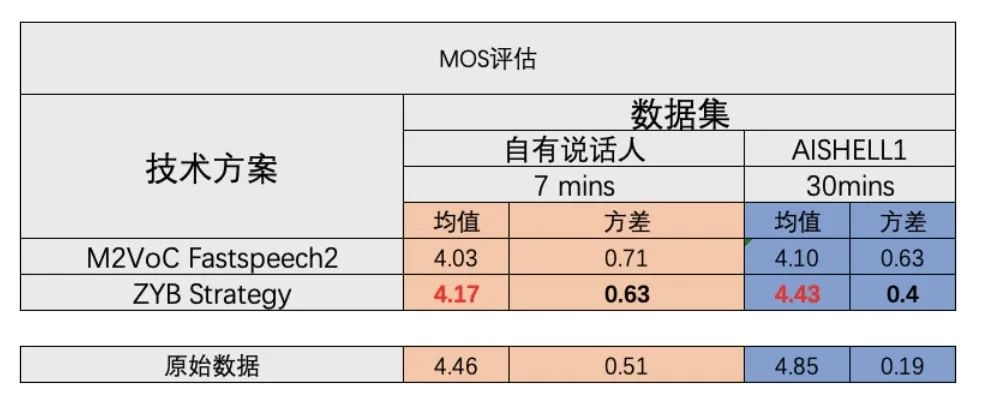
至此,我们针对小数据量、低资源的说话人数据优化也告一段落了,我们针对 30 分钟的 aishell 说话人已经能较好还原说话人原始录音数据的效果,同时合成模型还在一定程度上克服了原始数据中如停顿异常、音量大小不一致的问题。
在基于多说话人实验中,我们在一个说话人数量为 751,数据时长约 600 小时的数据集上,对比了基于自研说话人方案与 M2VoC Fastspeech 2 方案针对小数据量(训练数据约 30 分钟)和极小数据量(训练数据集约 7 分钟)上的建模表现,下图即为此次实验的 MOS 评估结果。
展望
需要强调的,虽然针对少数据量、低资源的说话人数据我们已经取得了一定的成果,但针对极少数据量,几句话、几分钟的数据资源,我们的模型依旧还有较大提升空间。所以对于我们来说未来还有很多的东西可以去做,例如数据的积累、优质数据的筛查、以及更高效的建模策略,甚至是否可以通过优化声码器进一步提升我们的建模能力都值得继续探索和研究。
参考文献
[1] Xu Tan, Tao Qin, Frank Soong, Tie-Yan Liu. A Survey on Neural Speech Synthesis. . arXiv preprint arXiv: 2106.15561, 2021.
[2] Wei Fang, Yu-An Chung, and James Glass. Towards transfer learning for end-to-end speech synthesis from deep pre-trained language models. arXiv preprint arXiv:1906.07307, 2019.
[3] Ye Jia, Heiga Zen, Jonathan Shen, Yu Zhang, and Yonghui Wu. Png bert: Augmented bert on phonemes and graphemes for neural tts. arXiv preprint arXiv:2103.15060, 2021.
[4] Andros Tjandra, Berrak Sisman, Mingyang Zhang, Sakriani Sakti, Haizhou Li, and Satoshi Nakamura. Vqvae unsupervised unit discovery and multi-scale code2spec inverter for ze- rospeech challenge 2019. Proc. Interspeech 2019, pages 1118–1122, 2019.
[5] Alexander H Liu, Tao Tu, Hung-yi Lee, and Lin-shan Lee. Towards unsupervised speech recognition and synthesis with quantized speech representation learning. In ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 7259–7263. IEEE, 2020.
[6] Tao Tu, Yuan-Jui Chen, Alexander H Liu, and Hung-yi Lee. Semi-supervised learning for multi-speaker text-to-speech synthesis using discrete speech representation. Proc. Interspeech 2020, pages 3191–3195, 2020.
[7] Haitong Zhang and Yue Lin. Unsupervised learning for sequence-to-sequence text-to-speech for low-resource languages. Proc. Interspeech 2020, pages 3161–3165, 2020.
[8] Yi Ren, Xu Tan, Tao Qin, Sheng Zhao, Zhou Zhao, and Tie-Yan Liu. Almost unsupervised text to speech and automatic speech recognition. In International Conference on Machine Learning, pages 5410–5419. PMLR, 2019.
[9] Andros Tjandra, Sakriani Sakti, and Satoshi Nakamura. Listening while speaking: Speech chain by deep learning. In 2017 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), pages 301–308. IEEE, 2017.
[10] Jin Xu, Xu Tan, Yi Ren, Tao Qin, Jian Li, Sheng Zhao, and Tie-Yan Liu. Lrspeech: Extremely low-resource speech synthesis and recognition. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, pages 2802–2812, 2020.
[11] Hamed Hemati and Damian Borth. Using ipa-based tacotron for data efficient cross-lingual speaker adaptation and pronunciation enhancement. arXiv preprint arXiv:2011.06392, 2020.
[12] Mutian He, Jingzhou Yang, and Lei He. Multilingual byte2speech text-to-speech models are few-shot spoken language learners. arXiv preprint arXiv:2103.03541, 2021.
[13] Yuan-Jui Chen, Tao Tu, Cheng-chieh Yeh, and Hung-Yi Lee. End-to-end text-to-speech for low-resource languages by cross-lingual transfer learning. Proc. Interspeech 2019, pages 2075–2079, 2019.
[14] Marcel de Korte, Jaebok Kim, and Esther Klabbers. Efficient neural speech synthesis for low- resource languages through multilingual modeling. Proc. Interspeech 2020, pages 2967–2971, 2020.
[15] Kaizhi Qian, Yang Zhang, Shiyu Chang, Xuesong Yang, Mark Hasegawa-Johnson. AUTOVC: Zero-Shot Voice Style Transfer with Only Autoencoder Loss. arXiv preprint arXiv: 1905.05879, 2019.
[16] Ju-chieh Chou, Cheng-chieh Yeh, Hung-yi Lee. One-shot Voice Conversion by Separating Speaker and Content Representations with Instance Normalization. arXiv preprint arXiv: 1904.05742, 2019.
[17] Disong Wang, Liqun Deng, Yu Ting Yeung, Xiao Chen, Xunying Liu, Helen Meng. VQMIVC: Vector Quantization and Mutual Information-Based Unsupervised Speech Representation Disentanglement for One-shot Voice Conversion. arXiv preprint arXiv: 2106.10132, 2021.
[18] Yuzi Yan, Xu Tan, Bohan Li, Tao Qin, Sheng Zhao, Yuan Shen, and Tie-Yan Liu. Adaspeech 2: Adaptive text to speech with untranscribed data. In 2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2021.
[19] Yuzi Yan, Xu Tan, Bohan Li, Guangyan Zhang, Tao Qin, Sheng Zhao, Yuan Shen, Wei-Qiang Zhang, and Tie-Yan Liu. Adaspeech 3: Adaptive text to speech for spontaneous style. In INTERSPEECH, 2021.
[20] Chung-Ming Chien, Jheng-Hao Lin, Chien-yu Huang, Po-chun Hsu, Hung-yi Lee. INVESTIGATING ON INCORPORATING PRETRAINED AND LEARNABLE SPEAKER REPRESENTATIONS FOR MULTI-SPEAKER MULTI-STYLE TEXT-TO-SPEECH. arXiv preprint arXiv: 2103.04088, 2021.
[21] Mingjian Chen, Xu Tan, Bohan Li, Yanqing Liu, Tao Qin, sheng zhao, and Tie-Yan Liu. Adaspeech: Adaptive text to speech for custom voice. In International Conference on Learning Representations, 2021. URLhttps://openreview.net/forum?id=Drynvt7gg4L.
[22] Yi Ren, Chenxu Hu, Xu Tan, Tao Qin, Sheng Zhao, Zhou Zhao, and Tie-Yan Liu. Fastspeech 2: Fast and high-quality end-to-end text-to-speech. In ICLR, 2021.
[23] Geng Yang, Shan Yang, Kai Liu, Peng Fang, Wei Chen, Lei Xie. Multi-band MelGAN: Faster Waveform Generation for High-Quality Text-to-Speech. arXiv preprint arXiv: 2005.05106, 2020.
[24] Li Wan, Quan Wang, Alan Papir, Ignacio Lopez Moreno. Generalized End-to-End Loss for Speaker Verification. arXiv preprint arXiv: 1710.10467, 2017.
[25] Brecht Desplanques, Jenthe Thienpondt, Kris Demuynck. ECAPA-TDNN: Emphasized Channel Attention, Propagation and Aggregation in TDNN Based Speaker Verification. arXiv preprint arXiv: 2005.07143, 2020.
[26] Anmol Gulati, James Qin, Chung-Cheng Chiu, Niki Parmar, Yu Zhang, Jiahui Yu, Wei Han, Shibo Wang, Zhengdong Zhang, Yonghui Wu, Ruoming Pang. Conformer: Convolution-augmented Transformer for Speech Recognition. arXiv preprint arXiv: 2005.08100, 2020.




