
要监控服务,而不是服务器或者容器什么的。
在之前的文章中,我们介绍了 SRE 应该围绕 SLO 展开运维工作,我们也知道了监控是获得 SLO 相关第一手数据的重要手段。SRE 所希望的监控,是直接从服务的关键路径上获取的状态信息;从运行服务的服务器或者容器的获得的状态信息在,只能间接说明服务的状态,这就是本文开头那句话的含义。
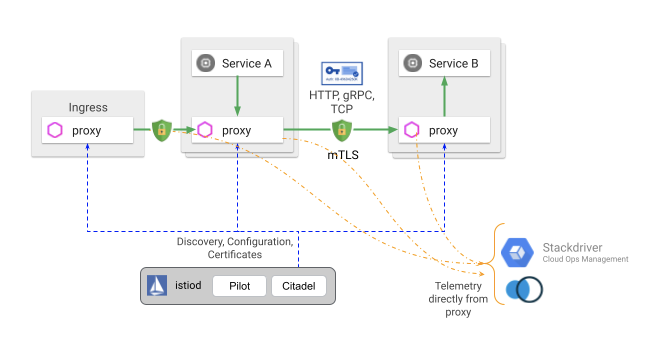
服务网格
对于一个基于 HTTP 的业务来说,直接拿到每个请求的返回代码,无疑是一个核心的监控措施。从架构上说,通过负载均衡器是可以非常客观的获得后端服务的这个监控指标的。
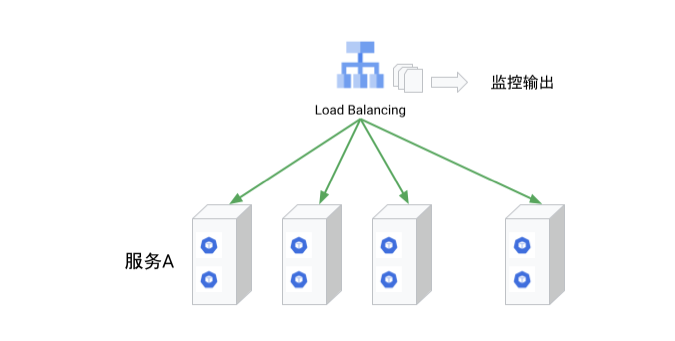
随着业务的逐渐复杂,通过负载均衡器来访问服务的不仅仅是最终客户,也可能是另一个服务:
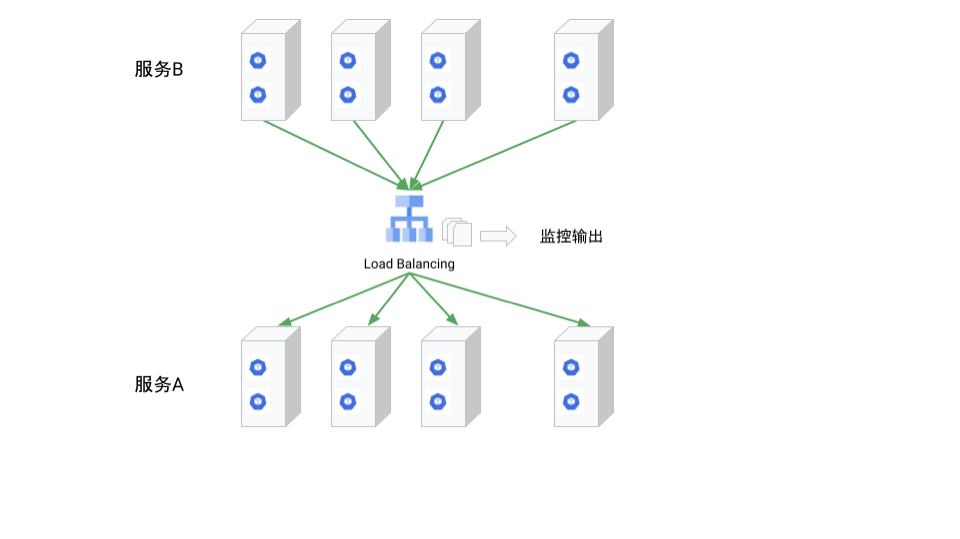
随着流量的上升,我们希望负载均衡器也能一起水平扩展:
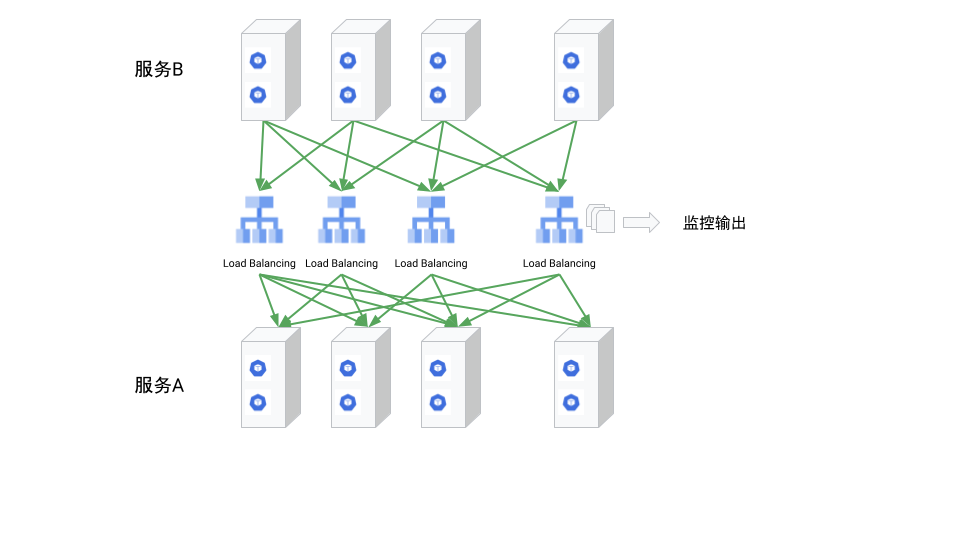
显然,负载均衡器的数量没有必要比服务 B 的数量还多,如果我们将负载均衡的功能直接集成到服务 B 中呢?
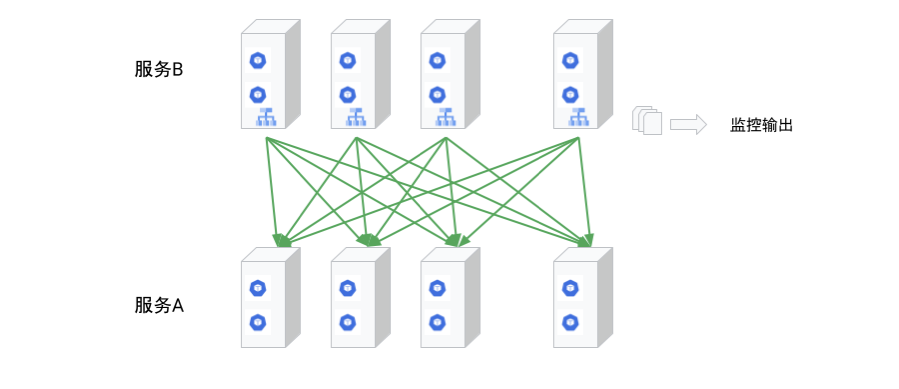
于是我们就获得了一个服务网格。
通过这种方式,我们还可以把下列功能集成进去:
流量控制:对应负载均衡器的流量导向
服务发现:让负载均衡器的后端更灵活,更易于管理
链路跟踪:通过向流量中注入追踪信标,可以更容易的流量的来龙去脉进行跟踪并分析服务瓶颈
安全与权限控制:通过对流量进行加密和注入权限控制属性,可以更方便地进行安全管理跟 Kubernetes 的 sidecar 技术结合,以上工作都可以在应用程序无感的前提下实现,这个就是著名的 Istio。
SRE 工作中的服务网格
监控数据收集和使用
在 Google Cloud 上,我们提供一个强大的运维工具 Stackdriver,而 Istio 则可以通过 Telemetry 的接口将 Istio 收集的各个组件的监控数据发送给 Stackdriver。
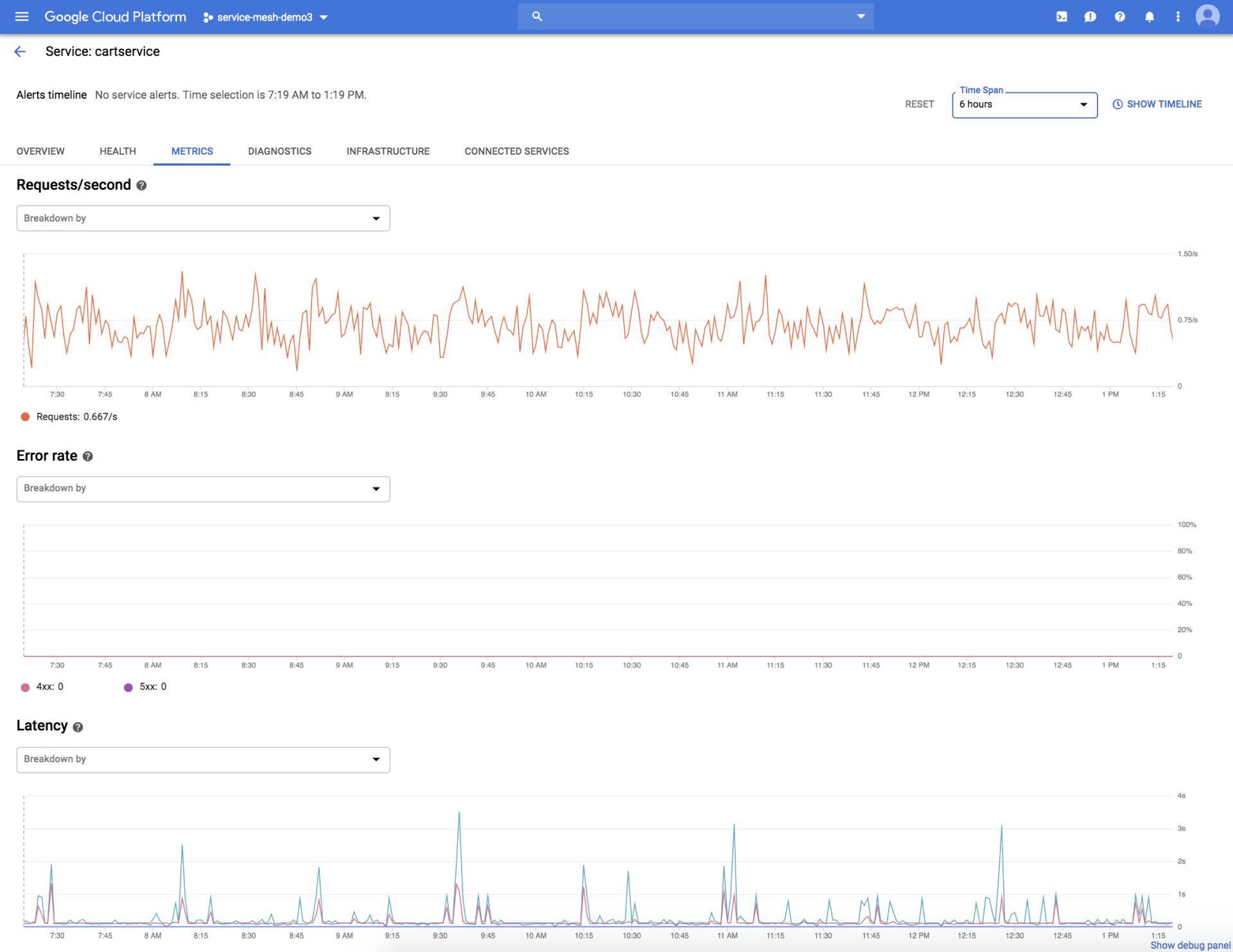
在 Stackdriver 中,可以直接查看服务的监控信息:
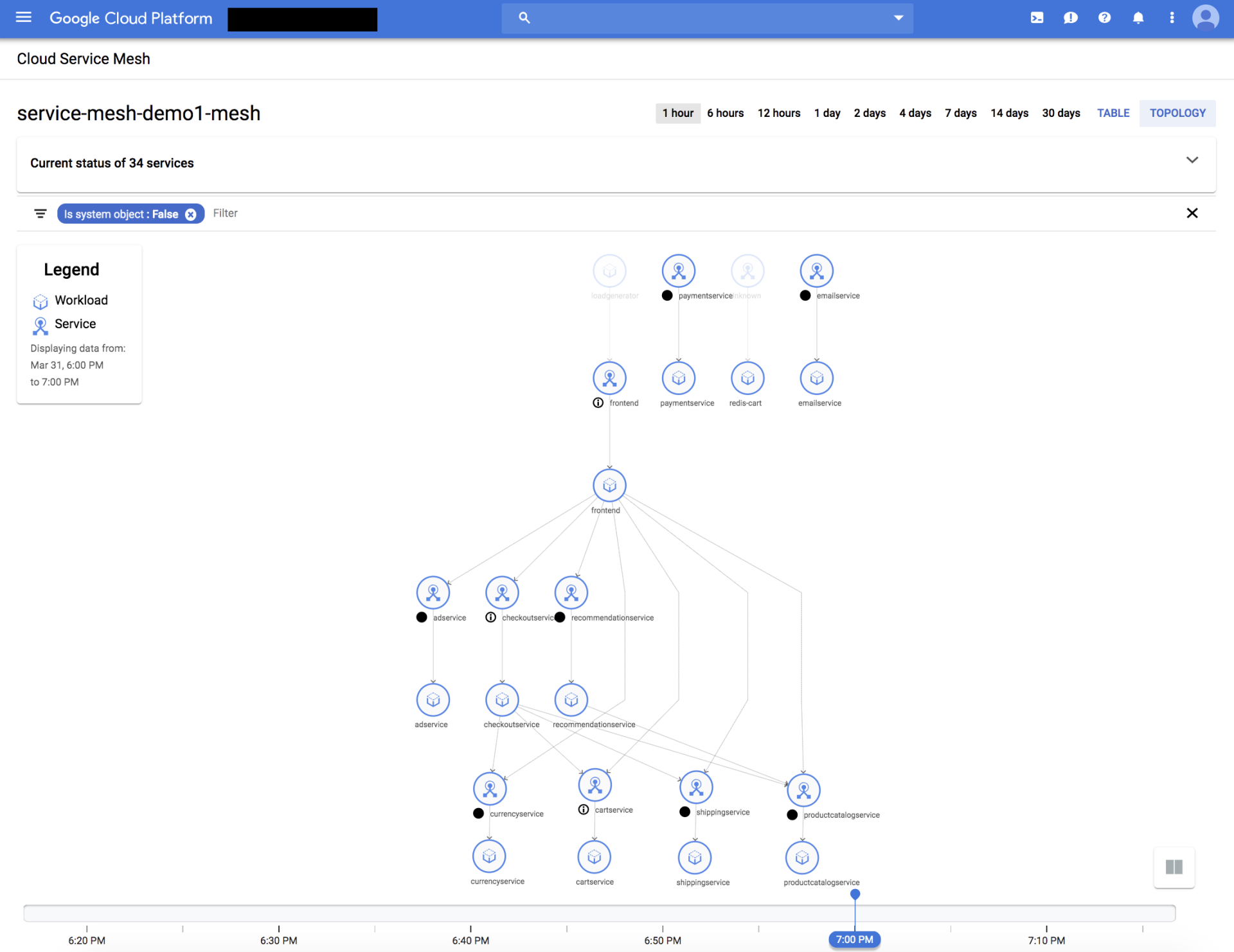
也可以查看服务组件之间的调用关系:
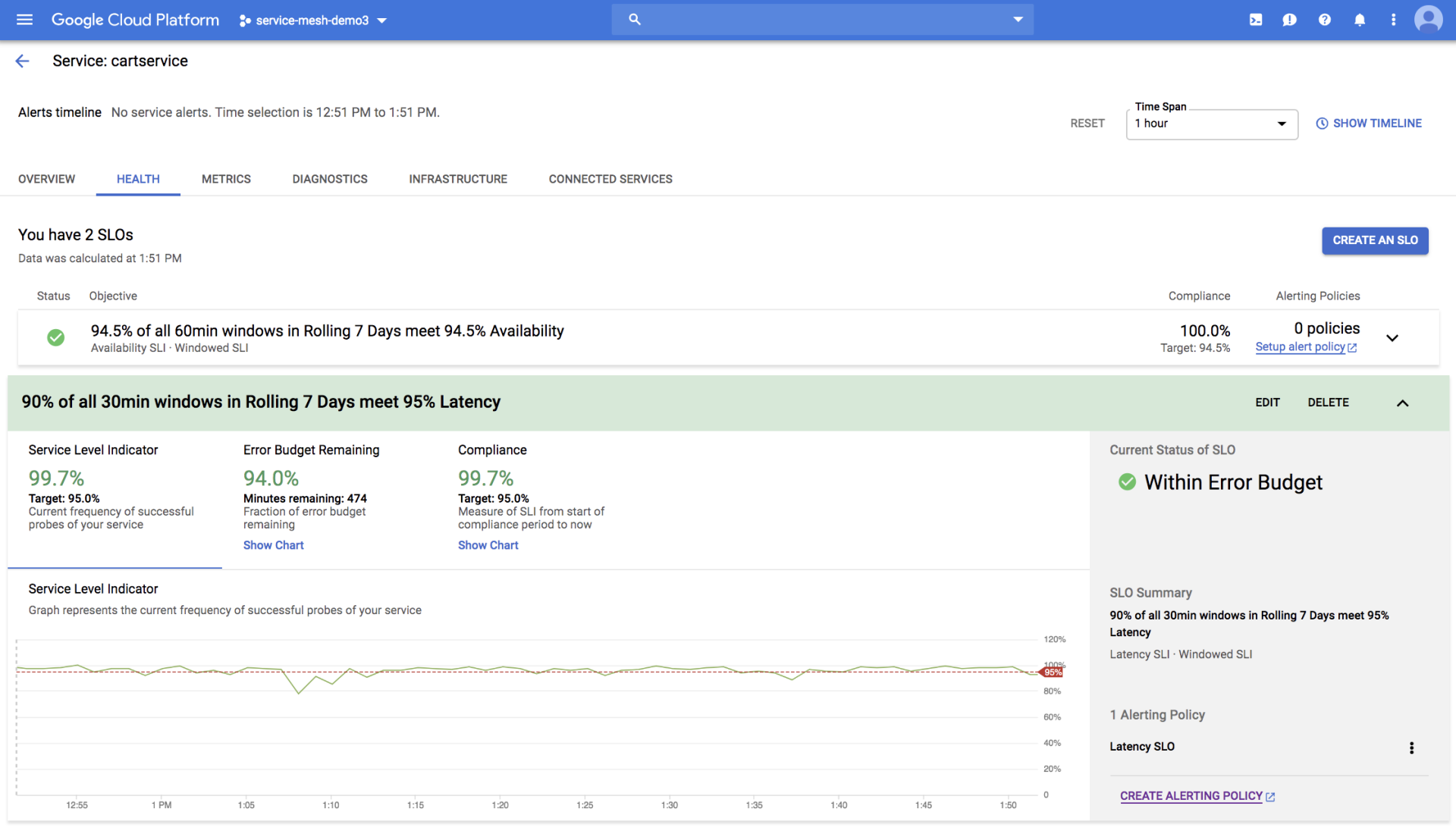
Stackdriver 的 SLO 监控面板可以直接提供与 SLO、错误预算相关的数据:
在 SLO 监控下完成新版本发布
在服务网格(或者更直接点,Istio)的帮助下,SRE 工程师可以通过直接更新 VirtualService 实现流量切换的办法完成升级。
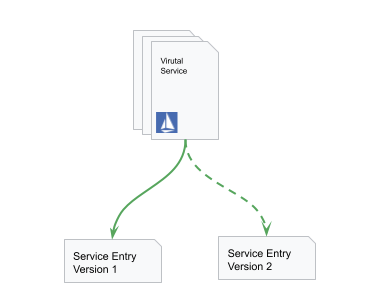
因为切换流量的执行速度非常快,整个升级过程将会很平顺。
更进一步,我们可以使用流量分配功能,将部分流量引导到新版本:
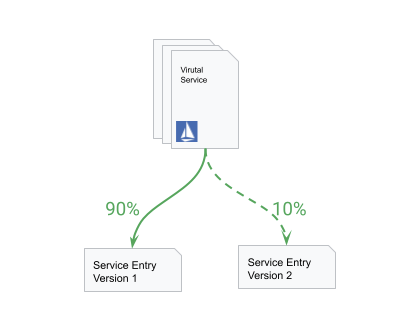
由于只分配了部分流量到新版本,那么即使新版本有瑕疵,也只会消耗一小部分错误预算。我们可以重复这个过程:
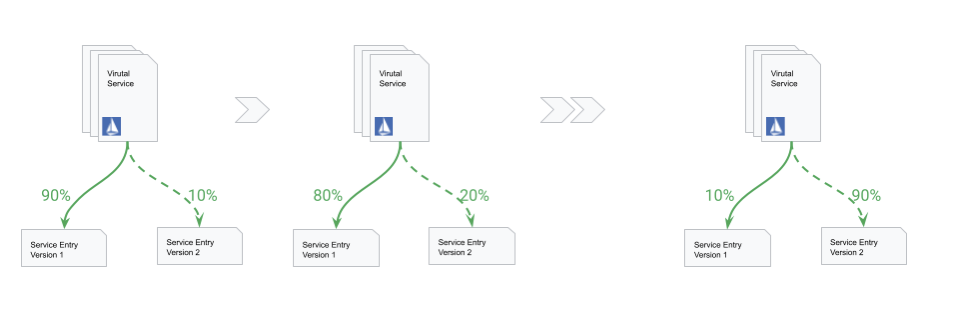
在这个过程中,我们可以一边监控错误预算的消耗,一边控制流量的转移,并可以设定条件,如果错误预算的消耗超过某个阈值就回滚到初始状态:
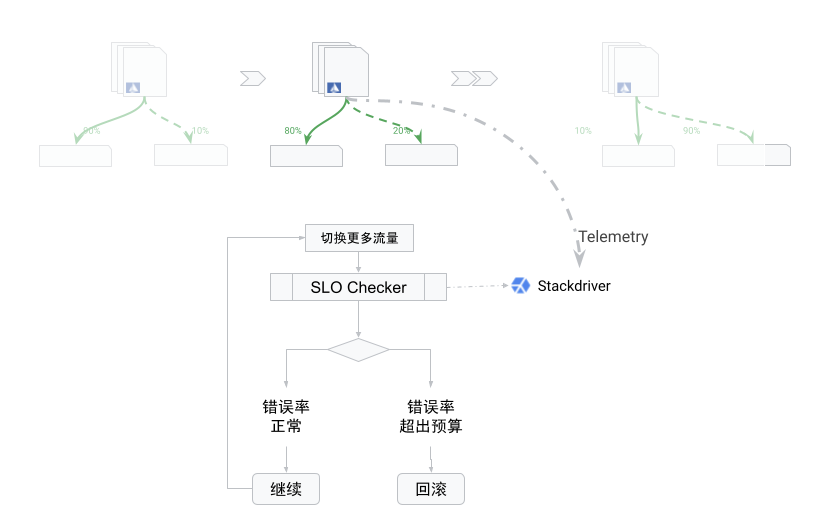
这样,服务网格就能帮助 SRE 完成灰度发布。
Anthos 服务网格(ASM)产品
ASM 作为谷歌云托管的服务网格解决方案产品,在开源的 Istio 的基础上,主要还提供了以下的能力:
控制平面托管
托管的指标收集器:ASM 可以观察服务的运行状况和性能。依赖于 Sidecar 代理,拦截到工作负载的所有入站和出站 HTTP 流量,并将数据报告给 ASM。 从而,开发人员无需注入任何代码即可收集遥测指标数据。
托管的 CA:ASM 提供 Google 全托管的 CA(Certificate authority)服务,可以帮助你配置 Service Mesh 的 CA 服务。
Traffic Director:是一个用于服务网格的完全托管且生产可用的流量控制平面。 使用 Traffic Director,您可以轻松地在多个区域中的群集和 VM 实例之间部署 Global 负载平衡,减轻服务代理的运行状况检查的压力,以及配置复杂的流量控制策略。
开箱即用的服务管理能力
日志,监控指标,链路追踪,SLO 指标监控告警等
提供服务的认证与鉴权,策略管理等安全管控的能力
服务路由,负载均衡,流量控制管理,限流,降级,故障注入和断路器等




