
本文最初发表于 Dev Genius 博客,经原作者 Mohammed Lutfalla 授权,InfoQ 中文站翻译并分享。
数据处理是一项密集型任务,尤其是对于计算单元,因为读写操作需要大量的资源。如果你有合适的工具,你可以很容易地实现这项任务。比如,我通过 AWS Lambda,在几分钟内就处理了 50 万个事务。通过本文,我将向你们分享我是如何做到这一点的以及我的经验。这个过程非常简单,同时也非常复杂。
几年前,我的经理告诉我要考虑一个处理架构,可以处理大量的记录,但不是那么繁重的操作。比如 80 万行的数据,有 16 列,每行需要做的工作量并不复杂。
我处理过许多问题,例如如何处理 Lambda 中的有限资源,如何处理由于超时和操作系统错误而丢失的问题。一位在 AWS 中东(巴林)区域担任高级顾问的朋友,帮助我获得了实现这一有希望的想法的工具。在处理 AWS 资源时,这是我获得的最好的体验之一。
闲话少叙,让我们来准备一张图示吧。
解决方案图
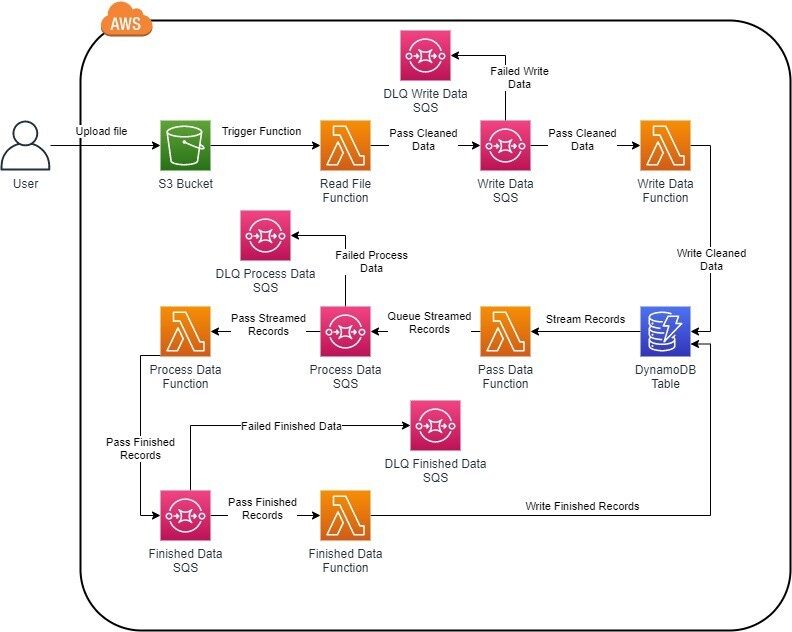
图示看起来很可怕?其实并不可怕,相信我。
请允许我将其分为几个步骤来解释:
1.启动流程
由于我采用的是无服务器架构,这意味着事件驱动事件,如果有事件发生,事件将根据它采取操作,并在流程结束之前触发另一个操作。
在我们的例子中,就是 S3 Put 请求。文件上载到 S3 后,它就会把文件放到一个桶中,当文件完全上传到桶中时,S3 有效负载将触发 Lambda。我们的第一步刚刚完成。接下来要做什么?
2.数据清洗
由于我们有一个 csv 文件,一些列和行,可能包含空格,以及一些可能损坏代码的特殊字符。所以,需要把它清洗一下。
对这些记录进行清洗,以便插入。因为我们有许多记录,并且该函数可能会失败,那么如何跟踪添加的内容和剩余的内容?
3.将清洗后的数据添加到队列中
我们将清洗后的记录添加到一个队列中。这是因为你要跟踪哪些已经被添加,哪些没有被添加。本质上,SQS 将充当一个组织者。这会把小批量记录发送给 Lambda,Lambda 将其添加到 DynamoDB 中,然后它会将成功消息返回到 SQS,并从队列中删除。
如果记录失败, SQS 会尝试重试 3 次,根据我的配置,尝试插入操作。若三次尝试均失败,则将其移至死信队列(Dead Letter Queue,DLQ),这是另外一个 SQS 队列,其中包含失败记录。这样,你就可以调试这些记录为何从未进入到 DynamoDB,并且可以再次处理或者拒绝它。
4.DynamoDB
由于我们要处理大量的数据,所以需要某种能处理极端负载或记录的数据库。DynamoDB 解决了这个问题。由于写入能够处理每单位 1 kb 的数据,所以在如何处理记录的数量和如何处理有限的读写吞吐量方面进行了大量的实验。因此,DynamoDB 的按需服务解决了这个问题。
根据 AWS 文档,在无法预测工作负载时,可以选择按需使用 DynamoDB 吞吐量。因为它将准备最大的吞吐量,以备不时之需。
将记录从 csv 转移到 DynamoDB,然后呢?
5.Stream 记录到 SQS
对于 Lambda 来说,DynamoDB 是非常好的事件执行器。启用 Stream 时,你可以指定一个 Lambda 函数,以响应从该函数传递的有效负载。优点在于,你需要根据记录的类型来采取操作。现在我们要处理的是新添加的记录。因此,在验证标记时,我们将记录添加到另一个 SQS 中。
这个队列的原因是记录传递的一致性。你只需要添加一次记录,捕获它,并将其添加到队列中,这样你就可以处理它。若不能,则必须扫描该表,获取未处理的记录,并进行处理。
6.处理数据
通过这个架构,我们达到了记录生命周期的最新阶段。当它到达 Process 队列时,它批量地传递记录,对其进行处理,然后将其传递到另一个队列。就像我前面所阐述的,为了保持一致性。
7.更新已处理的记录
最后,从 Finished 队列获得记录,并将其传递给 Lambda 函数,它将用已处理的信息更新记录。若无法传递记录, DLQ 将收集这些记录,以便进一步调试和操作。
挑战
上述这些操作看起来简单明了,但事实并非如此。以下是遇到的一些问题,以及相应的解决方案。
1.Lambda Lambda Lambda
Lambda 是这里的关键角色,我们需要在有限的时间内执行代码逻辑。怎样确保记录是红色的、清楚的,并添加到队列中?虽然很难,但是你需要的是速度。做法就是在 Python 上编写程序,并使用 Multiprocessing 库进行加速。
在 Lambda 中,我使用了 Multiprocessing Process 函数,以使用每个可能的处理单元。这一操作使我的进程在 1 分钟 30 秒内清洗了 55.8 万个事务(在某些测试中)。这个速度真快。
Lambda 在分配最大内存时能处理大约 500 个进程,其他任何进程都会触发 “OS Error 38: Too many files open”。为何要面对这个问题?因为我加入了所有运行中的进程,但它并没有关闭已完成的进程。因此,我运行一般的批处理,然后循环使用正在运行的进程,要是完成了,我就会强制关闭。事情解决了。
2.关注 CloudWatch
我犯了一个大错误,甚至当我运行大量处理时,我还是将事件变量传递到 CloudWatch 中。由于做了大量测试,所以这导致写到 6.6TB 的数据。CloudWatch put 日志操作的成本很高,因此请谨慎使用它。
3.DynamoDB 按需服务是关键词
在准备 DynamoDB 时,我首先对预测的工作负载进行配置,将读写吞吐量设置为 5。问题是,在 55.8 万条记录中,只有 1 千条插入了我的表格。虽然我将其提高到 100 的吞吐量,但是仍然有至少 60% 的文件丢失而没有添加!之后,我重新阅读了文档,注意到 DynamoDB 按需服务是针对不可预测的负载的解决方案。于是,我很快在 5 分钟内添加了 55.8 万条记录。
4.SQS 可能很棘手
SQS 是一项很棒的服务,有很多选择和机会。不过,你需要知道你每次传递的批处理的大小是多少,以及你对批处理完成的预测时间。这是因为在你告诉 SQS 等待 x 秒之后,该批处理可能会被多次处理,然后再一次进行处理。理解你的代码和数据,测试,测试,再测试,然后配置大量的工作负载。
这几个观点是我最关心的问题,S3 很有趣,但并没有我想像中的那么复杂。但是主要的问题是,这值得吗?
生活中的一切都取决于条件,如果你不想管理实例,或者你想用最小的努力来管理实例,那么这种情况对你来说是有效的。请记住,调试这些用例可能会有些麻烦,因为它们是相关的,而且一个步骤中的错误会影响接下来的步骤。
注意安全!
作者介绍:
Mohammed Lutfalla,着眼于未来,认为技术是他灵魂的核心。足球爱好者。
原文链接:




