
在不断发展的企业级 Java 应用中,高效的数据集成和持久化对于构建健壮和可扩展的系统至关重要。Jakarta Data 规范有助于进行数据处理。该框架简化了数据集成,支持混合持久化(polyglot persistence),并统一了 Jakarta EE 技术。与不同风格数据库的无缝交互使得开发人员能够专注于核心业务逻辑,并加快应用程序的开发。欢迎加入我们,一起探讨新 Jakarta EE 规范的功能、优势以及在现代企业架构中的实际应用。
需要强调的是,目前正在开发的规范仍需最终确定并集成到 Jakarta EE 平台中。该规范会在 2023 年 11 月份发布 GA 版本,它代表了企业级 Java 应用在数据处理方面迈出了重要的一步。随着进一步开发和完善,它在简化数据集成、支持混合持久化以及统一 Jakarta EE 技术方面的潜力会更加引人关注。
我们对 Jakarta EE 规范的探索将有助于你深入理解它在现代企业架构中的功能、优势和实际应用。开发人员可以预见,Jakarta EE 规范一旦最终发布,它的通用性和开源的特点将会使其成为构建各种尖端应用程序的有用工具,范围涵盖从关系型数据库到基于文档的 NoSQL 解决方案。
数据库的演进和混合持久化的兴起
数据库的历史对软件行业的发展起着举足轻重的作用,它从简单的数据存储系统发展到了驱动现代应用程序的复杂引擎。
在早期,数据库的运维成本很高,因此人们主要关注如何最大限度地降低存储成本。这一重点催生了致力于减少冗余和优化数据存储的标准化(normalization)过程。
随着技术的进步,存储的成本降低了,但是新的挑战出现了。如今,软件行业需要具有高吞吐和低延迟的快速应用,从而推动了多样化数据库解决方案的需求。
在当前的情况下,开发人员不再局限于“一刀切”式的数据存储方式。相反,他们可以从各种数据库风格中选择适合其应用程序独特需求的数据库。这种现象导致了混合持久化的出现,即应用程序栈中的不同微服务可能会采用不同的数据库技术。
关系型数据库擅长处理具有复杂关系的结构化数据,NoSQL 数据库为非结构化数据提供了卓越的可扩展性,而分布式 SQL(也成为 NewSQL )数据库则结合了这两种数据库的优点。目前,市场上有 400 多种可选的数据库方案。
过多的数据库选择给应用开发人员带来了巨大的挑战。他们该如何高效地管理和集成来自不同源(这些源具有独特的特征和访问模式)的数据呢?这时,一个独特的解决方案出现了,它提供了标准化的 API,可以毫不费力地驾驭混合持久化的复杂性。通过抽象出各种数据库技术的复杂性,该解决方案能够让开发人员专注于业务逻辑和数据建模,而不必为不同持久化解决方案的复杂性所困扰。
在下一节中,我们将会探讨该 API 如何解决现代数据集成所面临的挑战,使企业能够拥抱混合持久化,同时确保微服务及其不同数据源之间能够无缝、高效地交互。
我们为何需要 Jakarta Data?
在快节奏的企业级应用开发中,数据持久化的无缝集成和高效管理已成为成功的关键因素。Jakarta Data 规范的推出就是为了应对这些挑战,并提升 Jakarta EE 的持久层。该规范的目标是简化集成、提高灵活性并减少使用多种数据库的认知负担。
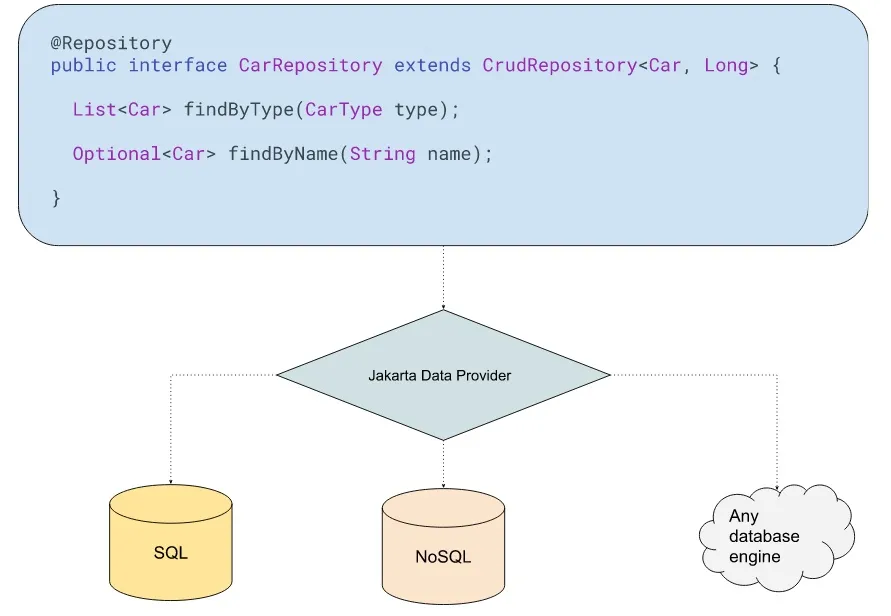
图 1 集成,Java 开发人员可以使用 SQL、NoSQL 等多种数据库引擎
商业方面
在如今激烈竞争的市场中,企业需要灵活和可扩展的解决方案来高效处理各种数据需求。标准化的持久化方法至关重要,它能够让企业专注于核心业务逻辑,而不必被复杂的数据集成任务所困扰。这种解决方案通过提供统一的方式处理各种数据源,简化了开发过程,加快了上市速度,并降低了维护成本。
在企业架构中启用混合持久化
现代应用程序通常依赖多种数据存储方案,比如关系数据库、NoSQL 数据库和基于云的存储。维护多种持久化技术可能会很具挑战性,导致整个应用栈中的数据访问模式不一致。有一种解决方案可以解决这个问题,它提供了一个与供应商无关且可扩展的 API,使得开发人员能够无缝地使用不同的数据存储,而不必受制于特定的供应商或技术。这种混合持久化方式允许企业为每个用例选择最合适的数据存储解决方案,而不会牺牲互操作性。
保证隔离,降低认知负担
开发人员在处理数据库系统、查询语言和数据访问模式时经常会遇到复杂的问题。规范可以抽象掉这些复杂性,提供统一直观的 API。这样,开发人员就可以专注于编写业务逻辑,而无需担心底层数据持久化的细节。这种抽象有助于更好地组织代码,最大限度地减少出错的可能性,并提高代码的可维护性。此外,它还能实现应用逻辑与持久层之间的隔离,允许对其中某层进行变更,而不影响另外一层,从而使开发过程更加顺畅,更易于管理。
该规范的引入标志着 Jakarta EE 应用程序在简化持久层的数据集成方面迈出了重要的一步。它解决了业务的需求,实现了混合持久化,并减少了开发人员的认知负担,使企业能够高效地构建健壮、可扩展的应用程序。在接下来的章节中,我们将深入介绍该规范的技术方面,并探讨其实现策略,重点介绍它如何彻底改变我们在现代企业应用中管理数据的方式。请继续关注我们对这一令人兴奋的规范的更多观点!
下一部分将通过现实世界的微服务场景展示该规范的功能,对其进行实际的检验。我们通过一个实际的样例,展示这一创新的 API 如何简化数据集成并提高微服务的灵活性。通过亲眼见证各种微服务与其数据源之间的无缝交互,你将会看到该规范如何简化持久层,促进高效、可扩展的企业级应用程序开发。
代码展示
本节将通过为一家奇特的啤酒厂构建三个应用来展示特定规范是如何简化混合持久化环境中的数据集成的,所有应用都可以在 Open Liberty 上运行,Open Liberty 是 Jakarta EE 10/11 实现的提供者。
每个应用将会代表不同的数据库风格:使用 Jakarta Persistence 规范定义的注解的关系型数据库、使用 Jakarta NoSQL 规范中定义的注解的基于文档的 NoSQL 数据库,这可以是 Couchbase 或 MongoDB,以及使用 Jakarta NoSQL 注解的 Eclipse Store 应用。通过利用该规范并使用 Open Liberty 作为其实现,我们能够演示应用程序如何与各自的数据库无缝交互,处理 NoSQL 数据库的序列化过程,同时能够从 Eclipse Store 与数据结构的直接交互中受益。该解决方案能够使开发人员能够轻松地驾驭混合持久化的复杂性,在现代企业环境中实现跨不同数据库技术的流畅数据管理和检索。
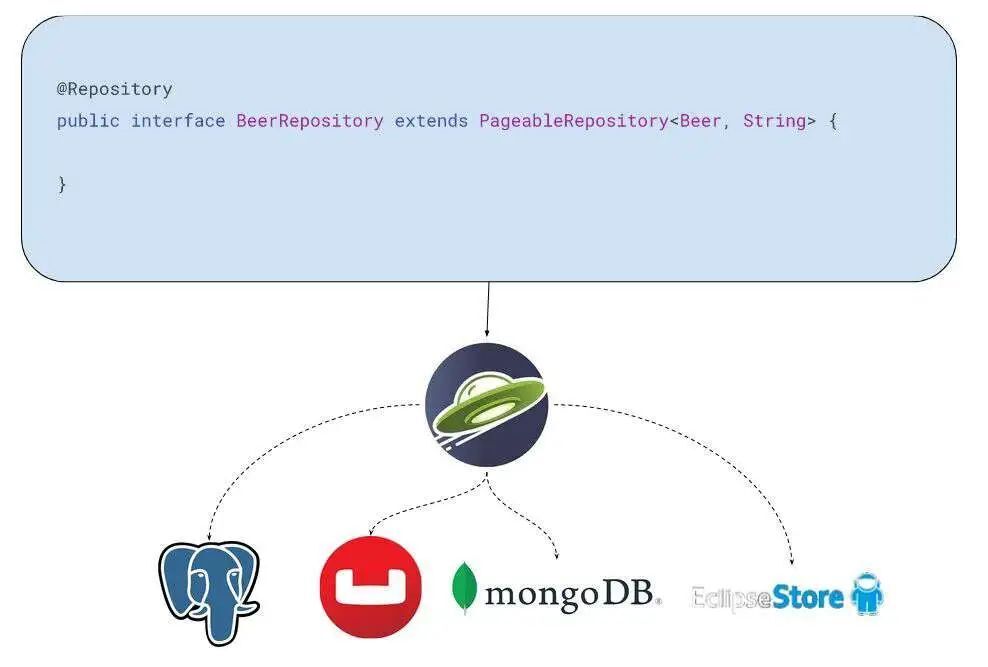
图 2 三个应用程序,分别使用 PostgreSQL 关系型数据库、Eclipse Store 以及 Couchbase 或 MongoDB 的文档 NoSQL
关系型数据库
(Jakarta Persistence 注解)
在第一个应用程序中,我们将使用关系型数据库,为了实现无缝集成,我们将使用 Jakarta Persistence 注解。通过这些注解,可以将 Beer 和 Address 类映射到关系型数据中相应的表上。我们所选择的规范将处理数据访问和操作,包括关系型数据库的序列化过程,它将面向对象的数据转换为适合关系型存储的结构化格式。此外,它还将定义每个用户与其对应的啤酒之间的一对一关系,实现规范化流程,以减少冗余并提高数据完整性。
通过采用这种方式来管理序列化以及应用与关系型数据库之间的交互,开发人员可以使用熟悉的面向对象范式高效地工作,同时确保数据在关系型结构中得到高效地持久化和规范化。
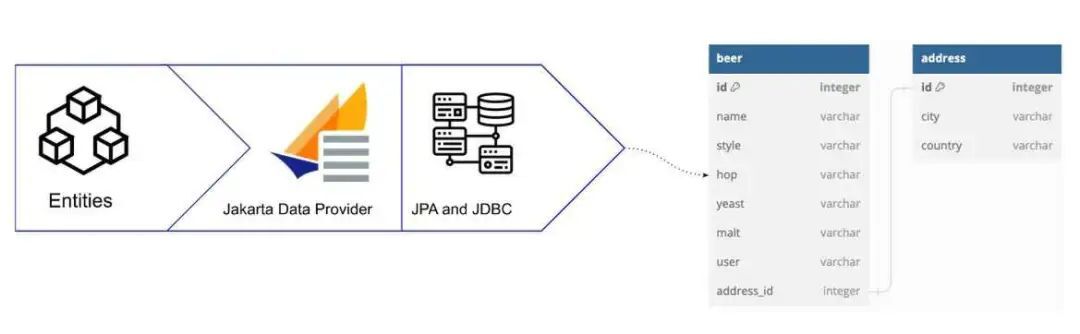
图 3 Jakarta Data 使用 Jakarta Persistence 实现的序列化过程
Beer 类使用了 @Entity 注解,表明它是一个要映射到数据库表的 Jakarta Persistence 实体。我们使用 @Column 注解定义了 name、style、hop、yeast 和 malt 属性,它们代表了表中的各个列。为了与 Address 实体建立一对一的关系,我们使用 @OneToOne 和 @JoinColumn 注解将 beer 表中的 address_id 列与 address 表中的 id 列连接起来。通过 cascade = CascadeType.ALL 配置,Beer 实体中的变更会级联到相应的 Address 实体,以确保数据的一致性。
与之类似,Address 类也使用了 @Entity 注解,代表它是映射到单独数据库表的另一个 Jakarta Persistence 实体。这里使用 @Id 注解声明 id 字段为主键,并且将 @GeneratedValue 设置为 GenerationType.AUTO ,以便于自动生成 ID。我们使用 @Column 注解将 city 和 country 属性映射到 address 表中对应的列。通过使用 Jakarta Persistence 注解,开发人员可以在啤酒和地址之间建立一对一的关系,同时使用规范化确保实现高效的数据管理和检索。
@Entitypublic class Beer { @Id private String id; @Column private String name; @Column private String style; @Column private String hop; @Column private String yeast; @Column private String malt; @OneToOne(cascade = CascadeType.ALL) @JoinColumn(name = "address_id", referencedColumnName = "id") private Address address;}@Entity@JsonbVisibility(FieldVisibilityStrategy.class)public class Address { @Id @GeneratedValue(strategy = GenerationType.AUTO) private Long id; @Column private String city; @Column private String country;}文档 NoSQL 数据库(借助 Jakarta NoSQL 注解使用 Couchbase 或 MongoDB)
在第二个应用中,我们将重点关注基于文档的 NoSQL 数据库,它为非结构化的数据提供了更大灵活性。我们可以选择 Couchbase 或 MongoDB 作为底层的 NoSQL 解决方案。借助相关的 NoSQL 注解,我们将会定义 Beer 和 Address 类的映射,NoSQL 数据库将会处理序列化过程,将数据转换为 JSON 格式进行存储。我们所选择的规范将简化数据的持久化和检索,确保应用程序能够轻松地与所选的 NoSQL 数据库进行交互,而无需关心使用了哪个供应商。
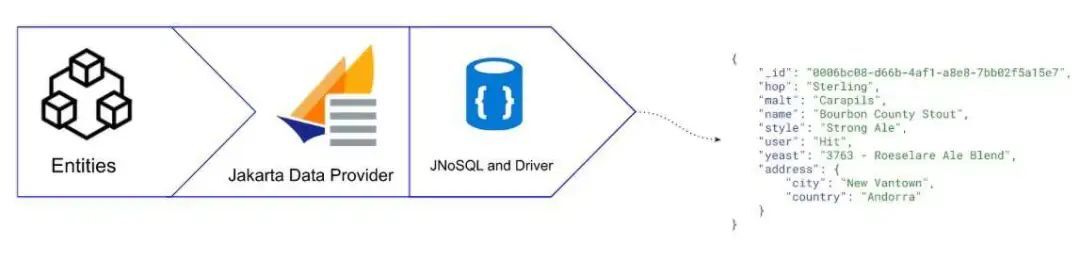
图 4 NoSQL 文档和序列化流程
该应用将会使用 Eclipse JNoSQL 与基于文档的 NoSQL 数据库进行集成,Eclipse JNoSQL 为 Couchbase 和 MongoDB 等 NoSQL 数据库提供了无缝支持。与前文一对一关系的主要区别在于,我们现在将 Address 类建模为 Beer 类中的一个 子文档,而不是保持单独的一对一关系。
在这个更新的模型中,Beer 类依然使用了 @Entity 注解,表示它将映射到 NoSQL 数据库中的 beer 文档。Beer 实体现在以字段的形式包含了一个 Address 对象,并使用了 @Column 注解,这表示它将作为 beer 文档中的子文档。这样,address 文档中的详细信息就直接嵌入到了 beer 文档,无需单独建立一个 address 集合或一对一的关系。
在 Couchbase NoSQL 数据库持久化数据时,存储结构将会采用 JSON 格式,而对于 MongoDB,将会是 BJSON(二进制 JSON)格式。JSON 和 BJSON 都是灵活高效的数据存储格式,可以轻松存储和检索嵌套文档,比如 Beer 实体中的 address 子文档。
借助 Eclipse JNoSQL 来处理集成,开发人员可以专注于构建应用的业务逻辑,而不必担心 NoSQL 数据库交互的复杂性。通过利用子文档和灵活的存储格式,Eclipse JNoSQL 使开发人员能够高效地使用基于文档的 NoSQL 数据库,以增强应用程序内的数据检索和管理。这种方式能够让开发人员充分利用 NoSQL 数据库的独特优势,同时保持直接和高效地数据建模策略。
@Entity("beer")public class Beer { @Id private String id; @Column private String name; @Column private String style; @Column private String hop; @Column private String yeast; @Column private String malt; @Column private Address address; @Column private String user;}@Entitypublic class Address { @Column private String city; @Column private String country;}Eclipse Store 应用(Jakarta NoSQL 注解)
对于第三个应用,我们将利用 Eclipse Store 的独特功能,它是一个专门的 NoSQL 数据库,具有内存存储和对象序列化特性。与之前的数据库不同,Eclipse Store 直接处理对象结构本身,消除了额外的序列化过程。我们依然会使用相关注解将 Beer 和 Address 接口映射到 Eclipse Store。但是,Jakarta Data 将直接处理与对象结构的交互,从而实现无缝、高效地数据持久化和检索。开发人员可以充分利用 Eclipse Store 的内存存储优势,而不必担心序列化的复杂性。
图 5 Eclipse Store 的持久层是三个应用中最轻薄的
在 Microstream 的 Eclipse Store 中,Beer 和 Address 实体的建模方式与 Eclipse JNoSQL、Couchbase 和 MongoDB 类似。但是,序列化过程有着显著的差异。基于文档的 NoSQL 数据库(Couchbase 和 MongoDB)以 JSON 或 BJSON 格式存储数据,而 Eclipse Store 使用实际的 Java 类来存储数据。
这种方式减少了延迟并节省了计算能力,消除了序列化和反序列化相关的开销。Eclipse Store 通过直接与 Java 类协作优化了数据存储和检索,从而提供了快速的应用性能和高效的数据管理。
通过采用 Eclipse Store,开发人员可以享受到独特且简便的数据存储策略,对于那些关注低延迟和高性能的应用程序来说,它是一个极具吸引力的可选方案。建模结构与其他基于文档的 NoSQL 数据库保持一致。同时,存储格式使 Eclipse Store 脱颖而出,它的高效数据持久化和检索,使其成为替代第二个应用程序的强大方案。
适用于各个应用程序的相同 Resource 和 Repository
在这三个应用程序中,都具有通用的架构组件来实现数据集成以及与各自数据库的交互。提供者是现有技术的适配器,如用于关系型数据库的 Jakarta Persistence 和用于基于文档的 NoSQL 数据库的 Jakarta NoSQL。尽管在建模和序列化方面存在差异,但是各个应用程序的类是保持一致的。
BeerRepository 接口是由三个应用程序共享的,并扩展了 PageableRepository。它使用 Pageable 和 Page 接口实现了数据检索的分页。这个 repository 接口利用了按照方法进行查询(query-by-method)的功能,按照约定创建查询,提供者会将这些查询透明地转换为特定数据库的查询。通过使用实体上的注解,提供者可以处理 Java 类和底层数据库之间的映射,从而使 Java 用户可以无缝使用。
@Repositorypublic interface BeerRepository extends PageableRepository<Beer, String> { Page<Beer> findByHopOrderByName(String hope, Pageable pageable); Page<Beer> findByMaltOrderByName(String malt, Pageable pageable); Page<Beer> findByMaltAndHopOrderByName(String malt, String hop, Pageable pageable);}在 BeerResource 类中,常用的 HTTP 动词(如 GET、POST 和 DELETE)用来处理 API 交互。虽然我们的重点不是创建整个 API,但是资源类展示了 Jakarta Persistence 层的功能。BeerResource 类使用了 @ApplicationScoped、@Path、@Produces 和 @Consumes 注解来声明资源端点、响应和请求媒体类型。该类包含根据不同的参数(如 hop、malt 或二者兼而有之)查找啤酒、创建新啤酒、按照 ID 删除啤酒以及生成随机啤酒数据以便于测试的方法。
@ApplicationScoped@Path("beers")@Produces(MediaType.APPLICATION_JSON)@Consumes(MediaType.APPLICATION_JSON)public class BeerResource { private final BeerRepository repository; @Inject public BeerResource(BeerRepository repository) { this.repository = repository; } @Deprecated BeerResource() { this(null); } @GET public List<Beer> findByAll(@BeanParam BeerParam param){ if(param.isMaltAndHopQuery()){ return this.repository.findByMaltAndHopOrderByName(param.malt(), param.hop(), param.page()).content(); } else if(param.isHopQuery()) { return this.repository.findByHopOrderByName(param.hop(), param.page()).content(); } else if(param.isMaltQuery()) { return this.repository.findByMaltOrderByName(param.malt(), param.page()).content(); } return this.repository.findAll(param.page().sortBy(Sort.asc("name"))).content(); } @POST public void create(Beer beer){ this.repository.save(beer); } @DELETE @Path("{id}") public void deleteById(@PathParam("id") String id){ this.repository.deleteById(id); } @Path("random") @POST public void random() { var faker = new Faker(); for (int index = 0; index < 1_000; index++) { var beer = Beer.of(faker); this.repository.save(beer); } }}架构层(包括 Resource 和 Repository)是所有适配器共享的,以确保一致性和代码的可重用性。不同之处在于模型层,每个适配器为各自的数据库实现必要的注解和序列化过程。虽然将实体与特定数据库相关的类隔离开可以提高隔离度,但是这也可能导致层级增多和额外的代码。因此,当前的共享方法在隔离和可维护性之间取得了平衡。

图 6 在这种架构设计中,开发人员可以在不影响数据建模的情况下,将实体域与数据库引擎隔离开
总之,提供者和共享架构组件使开发人员能够高效地利用不同的数据库技术,同时保持一致和标准的数据集成和 API 交互。利用单个类和注解处理不同数据库风格的能力简化了应用程序的开发,并促进了现代企业级应用中的混合持久化。
结论
本规范的引入标志着简化现代 Java 企业级应用中数据集成和持久化的一次尝试。这个规范提供了一个标准 API,可以与其他 Jakarta EE 技术(如 Jakarta Persistence、Jakarta NoSQL、Jakarta Contexts and Dependency Injection(CDI) 和 Jakarta Validation)集成。这种方法的灵活性和适应性使开发人员能够采用混合持久化,利用各种数据库风格的优势,同时保持统一的代码库。
在本文中,我们探讨了从关系型数据库到基于文档的 NoSQL 数据库的三种应用程序,每个应用都使用了不同的数据库风格。能够与这些不同的数据库技术协作表明了它的多功能性和效率,为开发人员简化了数据访问和管理。通过抽象序列化以及与不同数据库交互的复杂性,这种方式能够确保开发人员可以专注于业务逻辑,而不必担心特定数据库复杂的代码。
这种方式的独特优势之一就是它能够与其他 Jakarta EE 规范无缝集成,从而形成一个具有内聚力的、强大的企业级架构,使开发人员能够轻松构建健壮的、可扩展的应用程序,满足各种数据需求。
这种方式的未来值得期待,它计划纳入 Jakarta EE 11 中。作为一个开源项目,开发人员和 Java 爱好者有机会参与有关 Java 持久化未来的讨论。通过积极参与开源社区,开发人员可以帮助塑造这种方式的方向和 Java 的持久化生态,确保其始终满足现代企业应用程序不断发展的需求。
为了探索并亲自体验这种方式,可以在我们的 GitHub 仓库中获取代码样例。如果你有兴趣积极参与或了解更多有关其开发、项目会议和源码的信息,我们邀请你访问相关的规范。




