
最近,Uber 工程团队宣布升级其搜索基础设施,从 Apache Lucene 8.0 升级到 9.5 版本。此次升级提高了 Uber 各项服务的搜索能力、性能和效率。
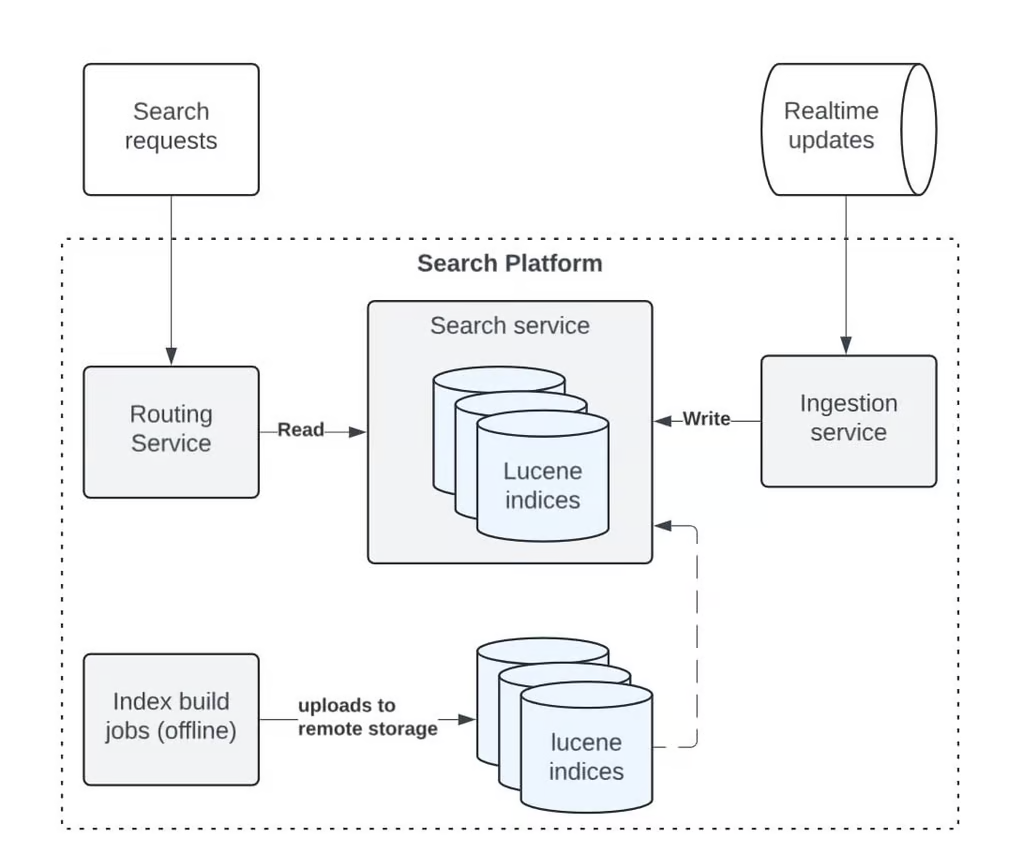
在一篇博文中,来自 Uber 搜索平台和数据工程团队的 Anand Kotriwal、Aparajita Pandey、Charu Jain 和 Yupeng Fu 详细阐述了本次升级工作。Uber 搜索平台有一个可靠的架构,包括服务层(读取路径)和摄取层(写入路径),以及用于离线处理的组件。
服务层负责处理用户查询,并从 Lucene 索引中检索信息。它主要包含两个部分:路由服务和搜索服务,前者将传入的查询定向到适当的搜索节点,并管理负载均衡;后者查询 Lucene 索引,实时检索结果。
当数据发生变化时,摄取层会更新 Lucene 索引。基于 Apache Flink 的摄取服务会处理实时更新,确保搜索索引保持最新。
对于离线处理,Uber 使用离线作业。这些 Apache Spark 作业可以处理批量索引创建和重建,高效地处理大量数据,构建或重建 Lucene 索引。
图片来源:Lucene:Uber 搜索平台版本升级
工程团队修改了一个单独的特性分支,单体存储库中受影响的文件有 400 多个,而这些文件与当前的代码库并不兼容。为了解决这个问题,团队选择了分阶段上线 Lucene 更新。首先,他们将其部署到优先级较低的内部用例中,然后再逐步扩展到更高的层级上。
整个过程耗时约 6 个月,包括全面的代码审查、验证、与客户团队合作以及合并分支前的分级推广。
Apache Lucene 是一个基于 Java 的搜索引擎库。它支持各种搜索需求,包括结构化搜索和全文搜索、分面搜索、最近邻搜索、拼写纠正和查询建议。它还有一个子项目 PyLucene,为 Lucene Core 提供 Python 绑定。
最近,他们发布了第 10 个版本,新增一个预取 APIIndexInput(支持对文档值做稀疏索引),并升级了 Snowball 字典,进而改进了分词。
本次升级提高了 Uber 的搜索速度和效率。搜索运行速度更快,使用的资源更少,也就是说应用程序用户可以更快地获得搜索结果。按照该团队的说法,有些搜索现在比以前快了 30%,使用该应用的乘客和司机都可以获得更好的体验。
这次升级的另一个好处来自对 Uber 基础设施的影响。Uber 的搜索请求严重依赖 CPU 能力,因此降低 CPU 使用率至关重要。这有助于削减基础设施成本,使 Uber 能够减少为多个客户提供服务所需的机器数量。
Uber 升级 Lucene 版本凸显了在技术驱动的大规模运营中保持核心技术与时俱进的重要性。
原文链接:
https://www.infoq.com/news/2024/11/uber-search-infra-lucene-upgrade/




