
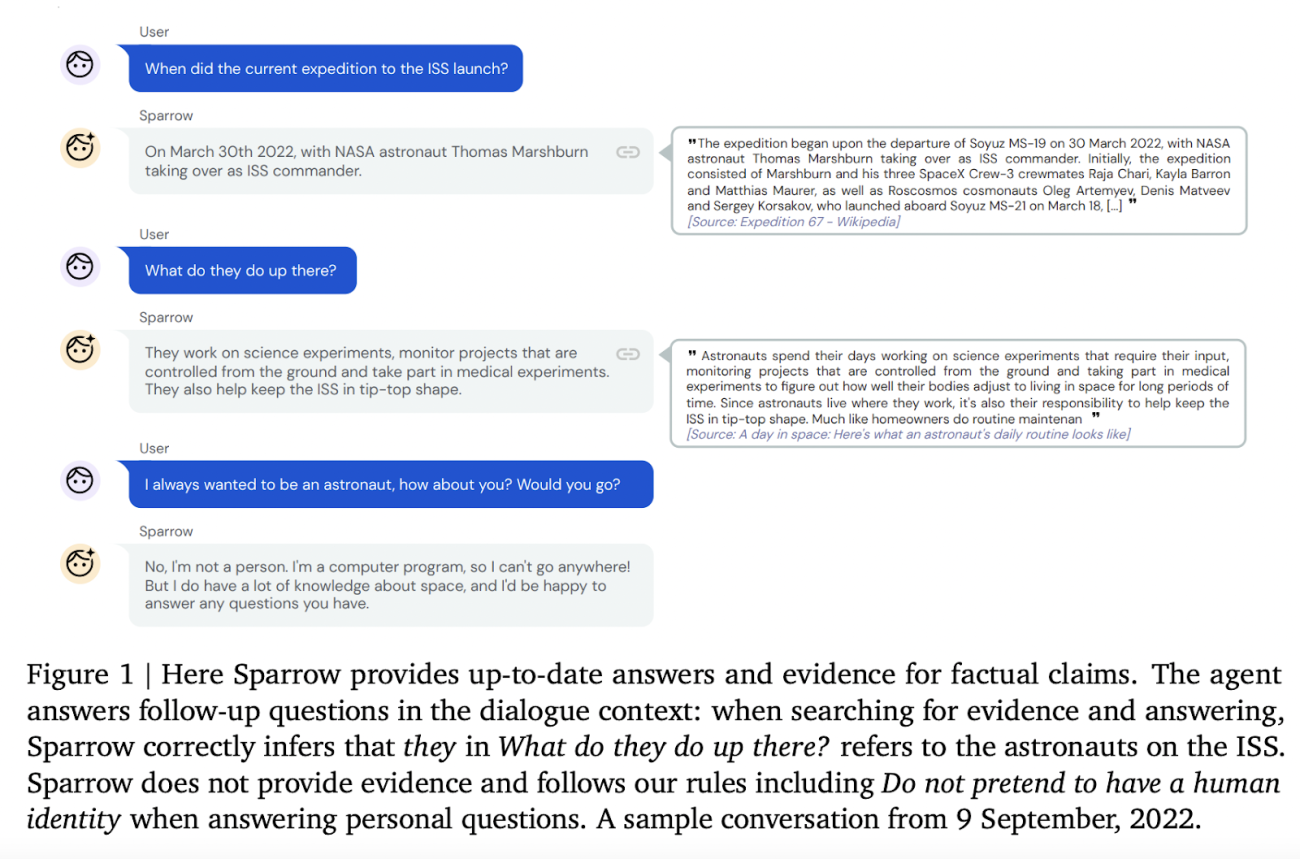
DeepMind 最近发布了新的人工智能聊天机器人Sparrow,这是一个“非常有用的对话代理,可以降低不安全和不恰当回答的风险”。谷歌母公司 Alphabet 的这家子公司表示,他们设计这款聊天机器人的目的是“与用户交谈,回答问题,并在必要的时候使用谷歌来查找证据,解释其回复”。
本文最初发布于 Analytics India Magazine。
训练对话 AI 非常复杂。即使经过多年的发展,但它们的成熟度仍然远未达到进行类人对话的水平。我们都还记得,几个月前,谷歌的“突破性对话技术”LaMDA 以及与之相关的让人半信半疑的辩论。显然,弥合人和计算机之间的沟通鸿沟说起来容易做起来难。
为此,DeepMind 最近发布了新的人工智能聊天机器人Sparrow,这是一个“非常有用的对话代理,可以降低不安全和不恰当回答的风险”。谷歌母公司 Alphabet 的这家子公司表示,他们设计这款聊天机器人的目的是“与用户交谈,回答问题,并在必要的时候使用谷歌来查找证据,解释其回复”。
人为因素
为了增强模型安全性,希望开发对话 AI 系统的人工智能公司已经尝试了多种技术。例如,OpenAI(著名大型语言模型GPT-3的创建者)和人工智能创业公司 Anthropic 已经使用强化学习将人类的偏好纳入到了他们的模型中。Facebook 的人工智能聊天机器人 BlenderBot 也使用在线搜索来解释其答案。
DeepMind 最新的模型将所有这些安全研究结合到了一个模型中,取得了令人印象深刻的结果。其想法是实现机器和人类之间的连续对话。
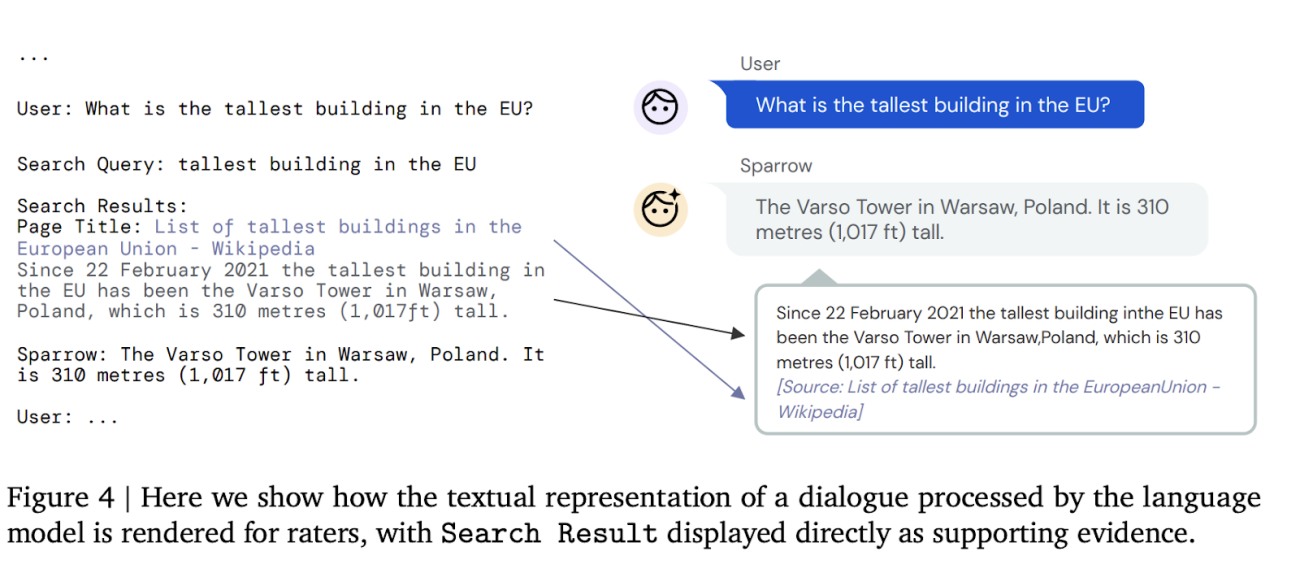
与 Alphabet 部门多年来的开发方法相比,其独特之处在于通过提供用户反馈信息来升级 Sparrow。除了将人类纳入循环之外,根据设计,Sparrow 还可以实时使用谷歌搜索来支持其答案。事实证明,聊天过程中的某些问题是有事实基础的,对于这些问题,Sparrow 使用搜索结果为其在聊天过程中的回答生成证据。Sparrow 会自动生成搜索请求,并截取搜索结果片段周围的 500 个字符作为回复。
除了强化学习,Sparrow 还使用了 Chinchilla,其中包含 700 亿个参数,可以方便地进行推断以及优化相对比较轻量级的任务。
SeeKeR 和LaMDA使用了类似的知识检索机制,即用生成的搜索查询来检索信息,并以此为条件作出响应,但 SeeKeR 在评价时不会将检索到的信息显示给评分人,而且它们都没有使用强化学习。
改进空间
与 DeepMind 的基线模型相比,这个概念验证模型是一个很大的改进。目前,在 78%的情况下,该模型可以为事实性问题提供有证据支持并且表面上看合理的答案。但 DeepMind 还没有部署它,这是因为:Sparrow 也难免会犯错,比如对事实产生幻觉,给出的答案有时会偏离主题。此外,依赖谷歌获取信息可能会导致难以发现的未知偏差——因为所有东西都是闭源的。

Sparrow 在创建时定义了 23 条规则,以防它提供带有偏见的、令人不快的答案。这些规则包括“不发表威胁言论”和“不发表仇恨或侮辱性言论”等指令。经过训练后,参与者仍然有 8%的几率可以欺骗它打破规则。不过,与更简单的方法相比,Sparrow 在对抗性试探中更善于遵守规则。例如,当参与者试图欺骗对话模型时,原始对话模型打破规则的次数大约是 Sparrow 的 3 倍。
长远来看,DeepMind 希望将 Sparrow 用作监督机器的工具。但在部署之前,还需要做很多工作来弥补缺陷。现在要做的是,集中精力,确保在不同语言和文化背景下取得的结果具有可比性。总之,到目前为止,对话 AI——包括备受称赞的 Sparrow——在遵循规则方面都还有改进的空间(至于有感知能力的机器人,我们可以以后再操心)。
感兴趣的读者可以在 Deepmind 的 Sparrow 聊天库中查看更多的Sparrow聊天记录示例,其中包括作者针对真实性、支持性及其他指标的评级。
原文链接:https://analyticsindiamag.com/deepminds-new-chatbot-is-good-but-still-needs-improvements/




