
Surftrace 是由系统运维 SIG 推出的一个 ftrace 封装器和开发编译平台,让用户既能基于 libbpf 快速构建工程进行开发,也能作为 ftrace 的封装器进行 trace 命令编写。
项目包含 Surftrace 工具集和 pylcc、glcc(python or generic C language for libbpf Compiler Collection),提供远程和本地 eBPF 的编译能力。通过对 krobe 和 ftrace 相关功能最大化抽象,同时对各种场景下的追踪能力增强(比如网络协议抓包),使得用户非常快速的上手,对定位问题效率提升 10 倍以上。
另外,现如今火到天际的技术——eBPF,Surftrace 支持通过 libbpf 及 CO-RE 能力,对 bpf 的 map 和 prog 等常用函数进行了封装和抽象,基于此平台开发的 libbpf 程序可以无差别运行在各个主流内核版本上,开发、部署和运行效率提升了一个数量级。
Surftrace 最大的优势在于将当前主流的 trace 技术一并提供给广大开发者,可以通过 ftrace 也可以使用 eBPF,应用场景覆盖内存、IO 等 Linux 各个子系统,特别是在网络协议栈跟踪上面,对 skb 内部数据结构,网络字节序处理做到行云流水。
一、理解 Linux 内核协议栈
定位网络问题是一个软件开发者必备一项基础技能,诸如 ping 连通性、tcpdump 抓包分析等手段,可以对网络问题进行初步定界。然而,当问题深入内核协议栈内部,如何将网络报文与内核协议栈清晰关联起来,精准追踪到关注的报文行进路径呢?
1.1 网络报文分层结构
引用自《TCP/IP 详解》卷一。
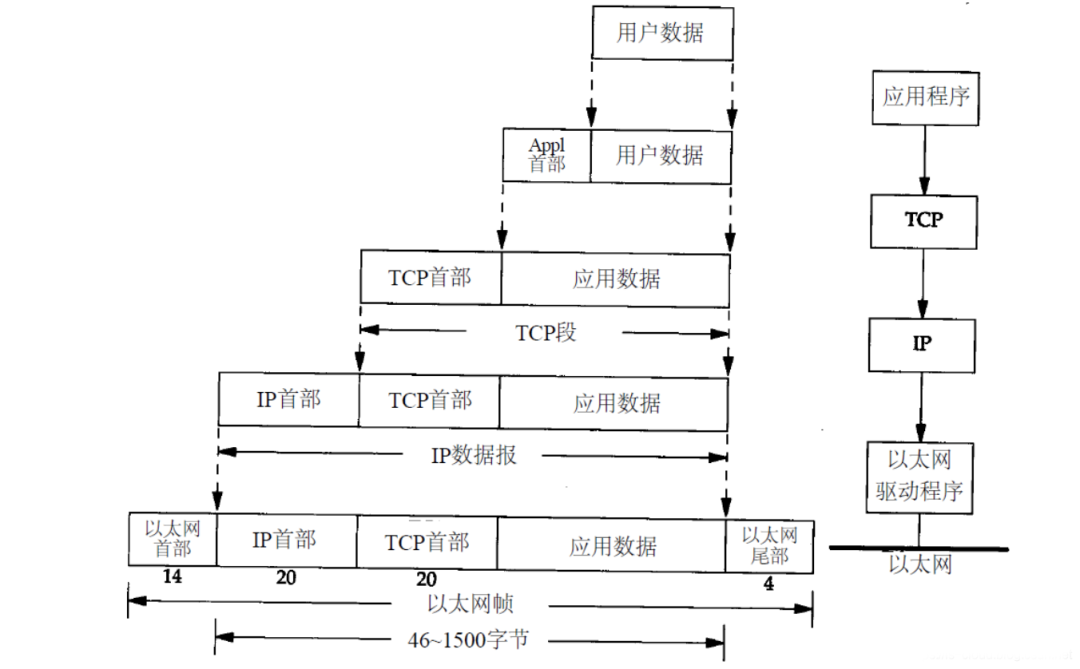
如上图所示,网络报文对数据报文数据在不同层进行封装。不同 OS 均采用一致的报文封装方式,达到跨软件平台通讯的目的。
1.2 sk_buff 结构体
sk_buff 是网络报文在 Linux 内核中的实际承载者,它在 include/linux/skbuff.h 文件中定义,结构体成员较多,本文不逐一展开。
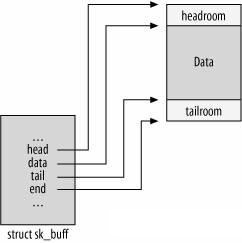
用户需要重点关注下面两个结构体成员:
unsignedchar *head, *data;其中 head 指向了缓冲区开始,data 指向了当前报文处理所在协议层的起始位置,如当前协议处理位于 tcp 层,data 指针就会指向 struct tcphdr。在 IP 层,则指向了 struct iphdr。因此,data 指针成员,是报文在内核处理过程中的关键信标。
1.3 内核网络协议栈地图
下图是协议栈处理地图,可以保存后放大观看。
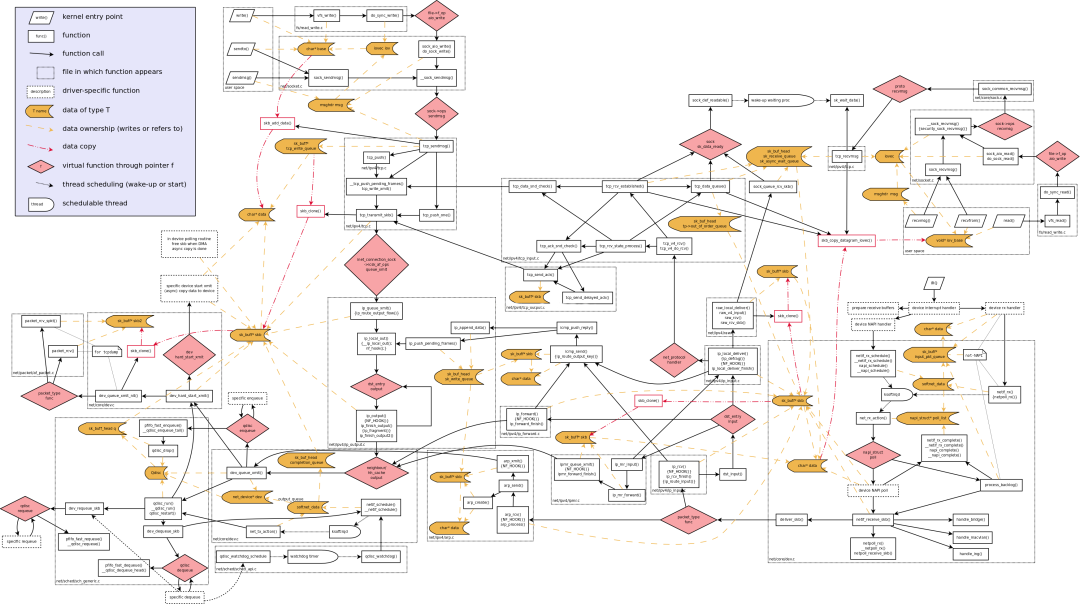
不难发现,上图中几乎所有函数都涉及到 skb 结构体处理,因此要想深入了解网络报文在内核的处理过程,skb->data 应该就是最理想的引路蜂。
二、Surftrace 对网络报文增强处理
Surftrace 基于 ftrace 封装,采用接近于 C 语言的参数语法风格,将原来繁琐的配置流程优化到一行命令语句完成,极大简化了 ftrace 部署步骤,是一款非常方便的内核追踪工具。但是要追踪网络报文,光解析一个 skb->data 指针是远远不够的。存在以下障碍:
skb->data 指针在不同网络层指向的协议头并不固定;
除了获取当前结构内容,还有获取上一层报文内容的需求,比如一个我们在 udphdr 结构体中,是无法直接获取到 udp 报文内容;
源数据呈现不够人性化。如 ipv4 报文 IP 是以一个 u32 数据类型,可读性不佳,过滤器配置困难。
针对上述困难,Surftrace 对 skb 传参做了相应的特殊处理,以达到方便易用的效果。
2.1 网络协议层标记处理
以追踪网协议栈报文接收的入口__netif_receive_skb_core 函数为例,函数原型定义:
staticint__netif_receive_skb_core(struct sk_buff *skb, bool pfmemalloc, struct packet_type **ppt_prev);解析每个 skb 对应报文三层协议成员的方法:
surftrace 'p __netif_receive_skb_core proto=@(struct iphdr *)l3%0->protocol`协议成员获取方法为 @(struct iphdr *)l3%0->protocol。
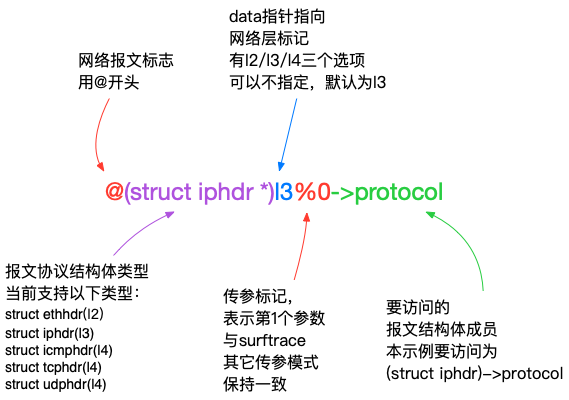
tips:
可以跨协议层向上解析报文结构体,如在 l3 层去分析 struct icmphdr 中的数据成员
不可以跨协议层向下解析报文结构体,如在 l4 层去分析 struct iphdr 中的成员
2.2 扩充下一层报文内容获取方式
surftrace 为 ethhdr、iphdr、icmphdr、udphdr、tcphdr 结构体添加了 xdata 成员,用于获取下一层报文内容。xdata 有以下 5 类类型:
数组下标是按照位宽进行对齐的,比如要提取 icmp 报文中的 2~3 字节内容,组成一个 unsigned short 的数据,可以通过以下方法获取:
data=@(struct icmphdr*)l3%0->sdata[1]2.3 IP 和字节序模式转换
网络报文字节序采取的是大端模式,而我们的操作系统一般采用小端模式。同时,ipv4 采用了一个 unsigned int 数据类型来表示一个 IP,而我们通常习惯采用 1.2.3.4 的方式来表示一个 ipv4 地址。上述差异导致直接去解读网络报文内容的时候非常费力。surftrace 通过往变量增加前缀的方式,在数据呈现以及过滤的时候,将原始数据根据前缀命名规则进行转换,提升可读性和便利性。
2.4 牛刀小试
我们在一个实例上抓到一个非预期的 udp 报文,它会往目标 ip 10.0.1.221 端口号 9988 发送数据,现在想要确定这个报文的发送进程。由于 udp 是一种面向无连接的通讯协议,无法直接通过 netstat 等方式锁定发送者。
用 Surftrace 可以在 ip_output 函数处中下钩子:
intip_output(struct net *net, struct sock *sk, struct sk_buff *skb)追踪表达式:
surftrace 'p ip_output proto=@(struct iphdr*)l3%2->protocol ip_dst=@(struct iphdr*)l3%2->daddr b16_dest=@(struct udphdr*)l3%2->dest comm=$comm body=@(struct udphdr*)l3%2->Sdata[0] f:proto==17&&ip_dst==10.0.1.221&&b16_dest==9988'追踪结果:
surftrace 'p ip_output proto=@(struct iphdr*)l3%2->protocol ip_dst=@(struct iphdr*)l3%2->daddr b16_dest=@(struct udphdr*)l3%2->dest comm=$comm body=@(struct udphdr*)l3%2->Sdata[0] f:proto==17&&ip_dst==10.0.1.221&&b16_dest==9988' echo 'p:f0 ip_output proto=+0x9(+0xe8(%dx)):u8 ip_dst=+0x10(+0xe8(%dx)):u32 b16_dest=+0x16(+0xe8(%dx)):u16 comm=$comm body=+0x1c(+0xe8(%dx)):string' >> /sys/kernel/debug/tracing/kprobe_events echo 'proto==17&&ip_dst==0xdd01000a&&b16_dest==1063' > /sys/kernel/debug/tracing/instances/surftrace/events/kprobes/f0/filter echo 1 > /sys/kernel/debug/tracing/instances/surftrace/events/kprobes/f0/enable echo 0 > /sys/kernel/debug/tracing/instances/surftrace/options/stacktrace echo 1 > /sys/kernel/debug/tracing/instances/surftrace/tracing_on <...>-2733784 [014] .... 12648619.219880: f0: (ip_output+0x0/0xd0) proto=17 ip_dst=10.0.1.221 b16_dest=9988 comm="nc" body="Hello World\! @"通过上述命令,可以确定报文的发送的 pid 为 2733784,进程名为 nc。
三、实战:定位网络问题
接下来我们从一个实际网络网络问题出发,讲述如何采用 Surftrace 定位网络问题。
3.1 问题背景
我们有两个实例通讯存在性能问题,经抓包排查,确认性能上不去的根因是存在丢包导致的。幸运的是,该问题可以通过 ping 对端复现,确认丢包率在 10% 左右。

通过进一步抓包分析,可以明确报文丢失在实例 B 内部。
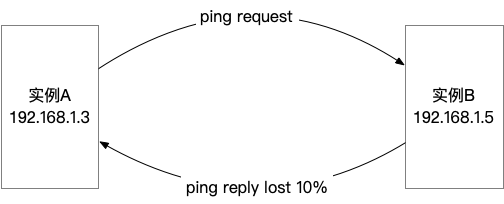
通过检查 /proc/net/snmp 以及分析内核日志,没有发现可疑的地方。
3.2 surftrace 跟踪
在 1.1 节的地图中,我们可以查到网络报文是内核由 dev_queue_xmit 函数将报文推送到网卡驱动。因此,可以在这个出口先进行 probe,过滤 ping 报文,加上 -s 选项,打出调用栈:
surftrace 'p dev_queue_xmit proto=@(struct iphdr *)l2%0->protocol ip_dst=@(struct iphdr *)l2%0->daddr f:proto==1&&ip_dst==192.168.1.3' -s可以获取到以下调用栈:
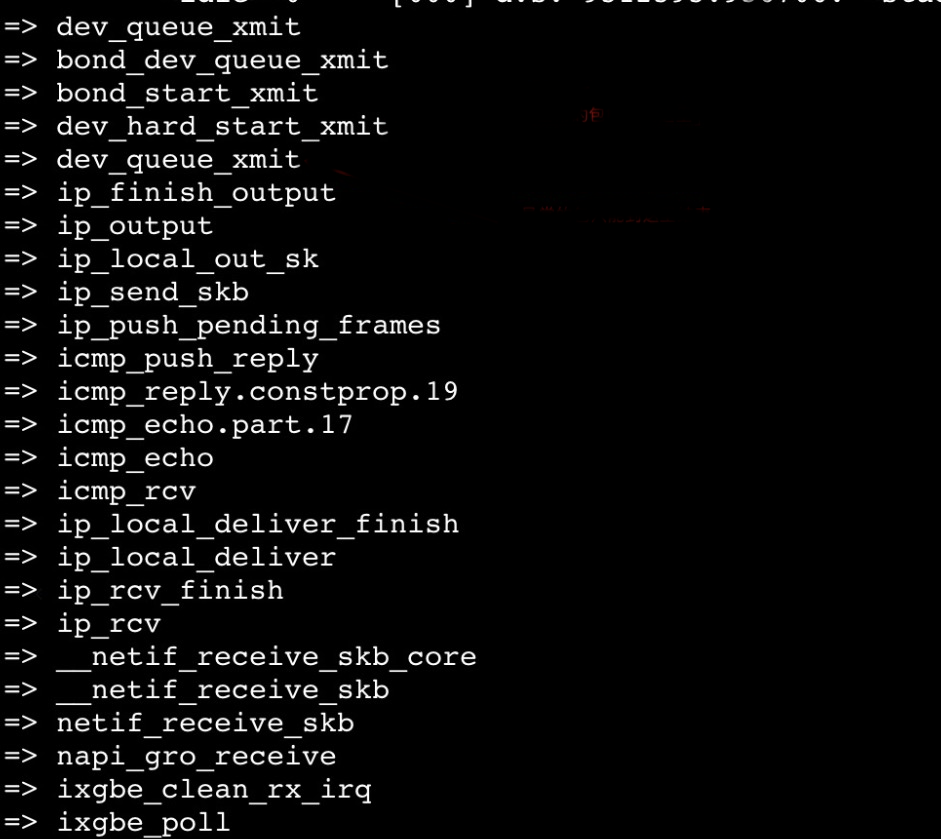
由于问题复现概率比较高,我们可以将怀疑的重点方向先放在包发送流程中,即从 icmp_echo 函数往上,用 Surftrace 在每一个符号都加一个 trace 点,追踪下回包到底消失在哪里。
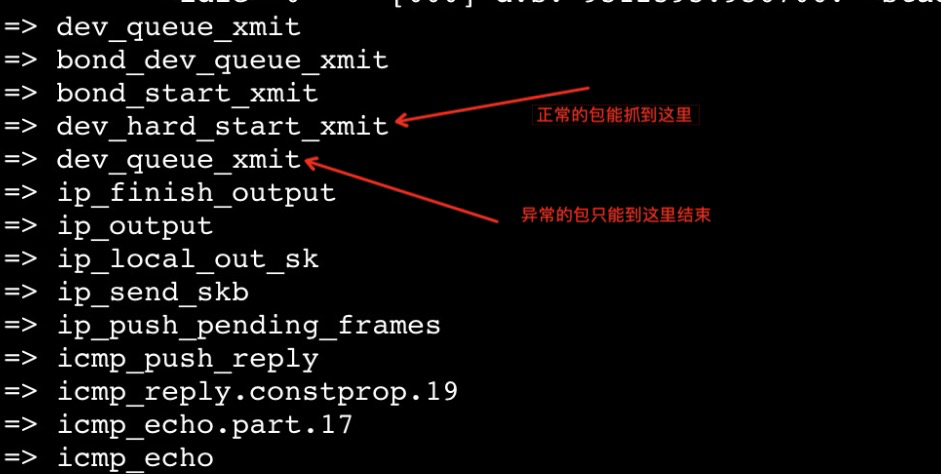
3.3 锁定丢包点
问题追踪到了这里,对于经验丰富的同学应该是可以猜出丢包原因。我们不妨纯粹从代码角度出发,再找一下准确的丢包位置。结合代码分析,我们可以在函数内部找到以下两处 drop 点:
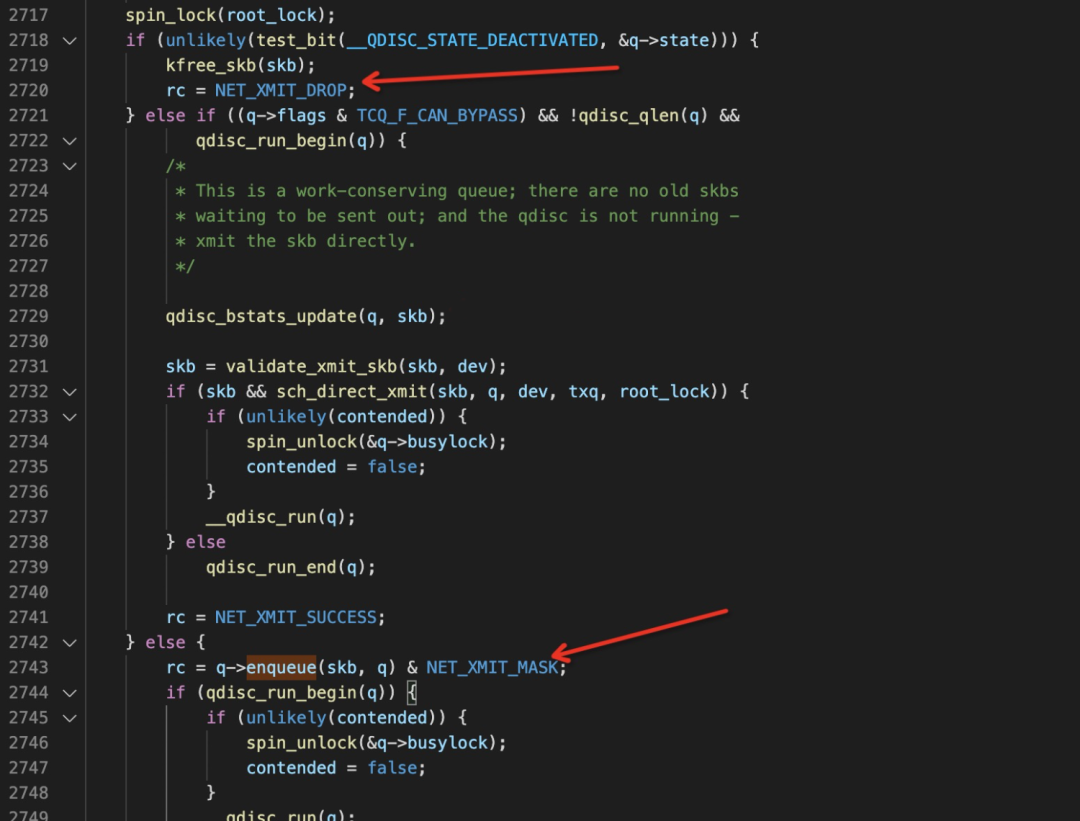
通过 Surftrace 函数内部追踪功能,结合汇编代码信息,可以明确丢包点是出在了 qdisc->enqueue 钩子函数中。
rc = q->enqueue(skb, q, &to_free) & NET_XMIT_MASK;此时,可以结合汇编信息:

找到钩子函数存入的寄存名为 bx,然后通过 surftrace 打印出来。
surftrace 'p dev_queue_xmit+678 pfun=%bx'然后将 pfun 值在 /proc/kallsyms 查找匹配。

至此可以明确是 htb qdisc 导致丢包。确认相关配置存在问题后,将相关配置回退,网络性能得以恢复。
四、总结
Surftrace 在网络层面的增强,使得用户只需要有相关的网络基础和一定的内核知识储备,就可以用较低编码工作量达到精准追踪网络报文在 Linux 内核的完整处理过程。适合用于追踪 Linux 内核协议栈代码、定位深层次网络问题。
参考文献:
【1】《TCP/IP 详解》
【2】《Linux 内核设计与实现》
【3】《深入理解 Linux 网络技术内幕》
【4】surftrace readmde:




